こんにちは。PharmaXの上野(@ueniki)です
今回は、最近注目しているマルチモーダルモデルを使った音声対話について取り上げたいと思います。
PharmaXのYOJOというサービスについてはこれまで何度かご紹介してきましたが、超簡単に言えば、オンラインで薬剤師に健康や医薬品について相談し、医薬品が購入できるというサービスです。
YOJOは、チャットと通話を主軸にしたサービスなので、LLMとの相性が非常に良く、今後は音声のAI化にも取り組んで行きたいと思っています。
2024年5月のGPT-4oのデモで特に驚きを持って迎えられたのが音声対話でした。
ChatGPTでは、「高度な音声機能」と呼ばれる機能で、その滑らかさと遅延のなさが非常に話題になっていましたね。
今回は、このGPT-4oを題材に、マルチモーダルモデルを使った音声対話の可能性と課題について私が考えていることをシェアしたいと思います。
マルチモーダルモデルの可能性については、多くの人が語っているので、今回はどちらかというと今考え得る応用上の課題について議論したいと思います。
画像や動画については軽く触れますが、今回は深く考察しないことといたしますので、その点ご容赦ください。
また、今回はローカル・マルチモーダルモデルについても深く立ち入らないこととします。ローカルモデルもいくつか試しましたが、マルチモーダル性能については、APIモデルがまだ優勢だと思うので、基本的にはAPI使用前提の話をしたいと思います。
ChatGPTの高度な音声機能とAPIでの提供について
日本では「高度な音声機能」が一部のユーザーには届いているようですが、
私の観測では、日本で使えるようになっている人はまだ多くはないようです。
実際に使っている方の動画をテキトーに見つけて見てみるとよいかと思います。
OpenAIは秋までには、すべてのChatGPT Plusユーザーに展開されるとしていますが、
APIの公開については触れられているのを見たことがないので、提供はさらに遅くなるのではなるのだろうと推測しています。
もしかしたら、今年のOpenAI DevDayで何かしらの発表があるかもしれません。
GPT-5の発表はなく、
APIと開発ツールの進歩、開発者コミュニティがプラットフォームで構築してきたものに焦点を当てる
と述べられているので、APIが発表される可能性は十分にありそうです。
GPT-4oのAPIはすでに公開されているので、
音声などの他のモダリティを取り込んだGPT-4oのAPIを"アップデート版のGPT-4oのAPI"
モデルそのものを指すときは、"アップデート版のGPT-4o"
と呼ぶことにしましょう。
このアップデート版のAPIが使えるようになればプロダクトに盛り込めるので、音声対話のプロダクトが一気に生まれてくる可能性があります。
マルチモーダルとは何か?
大規模言語モデルのことをLLMと呼びますが、今後出現するであろう大規模マルチモーダルモデルのことはLMM(Large Multimodal Model)と呼ぶようです。
この記事での記述はLMMで統一したいと思います。
LLMとLMMは1文字違いで、しかもLとMは響きも似ているので、聞き分けるのが難しそうです。
私のような滑舌の悪い人間が登壇してLMMなどと言った日には、聴講者の皆さまを混乱させるのではと今から戦々恐々としています。
Multimodalとは、「複数の形式の」という意味です。
modalから派生した単語にmodalityという名詞がありますが、特にITの文脈でmodalityと言えば、情報の入出力が行われる経路や形式のことを指します。
マルチモーダルモデルと言うことで、あらゆる入出力の形式に対応しているモデルだというのを表現したいお気持ちなのでしょう。
つまり、下図のように、あらゆる形式の入力を受け付けて、あらゆる形式の出力を返すことの出来るモデルです。
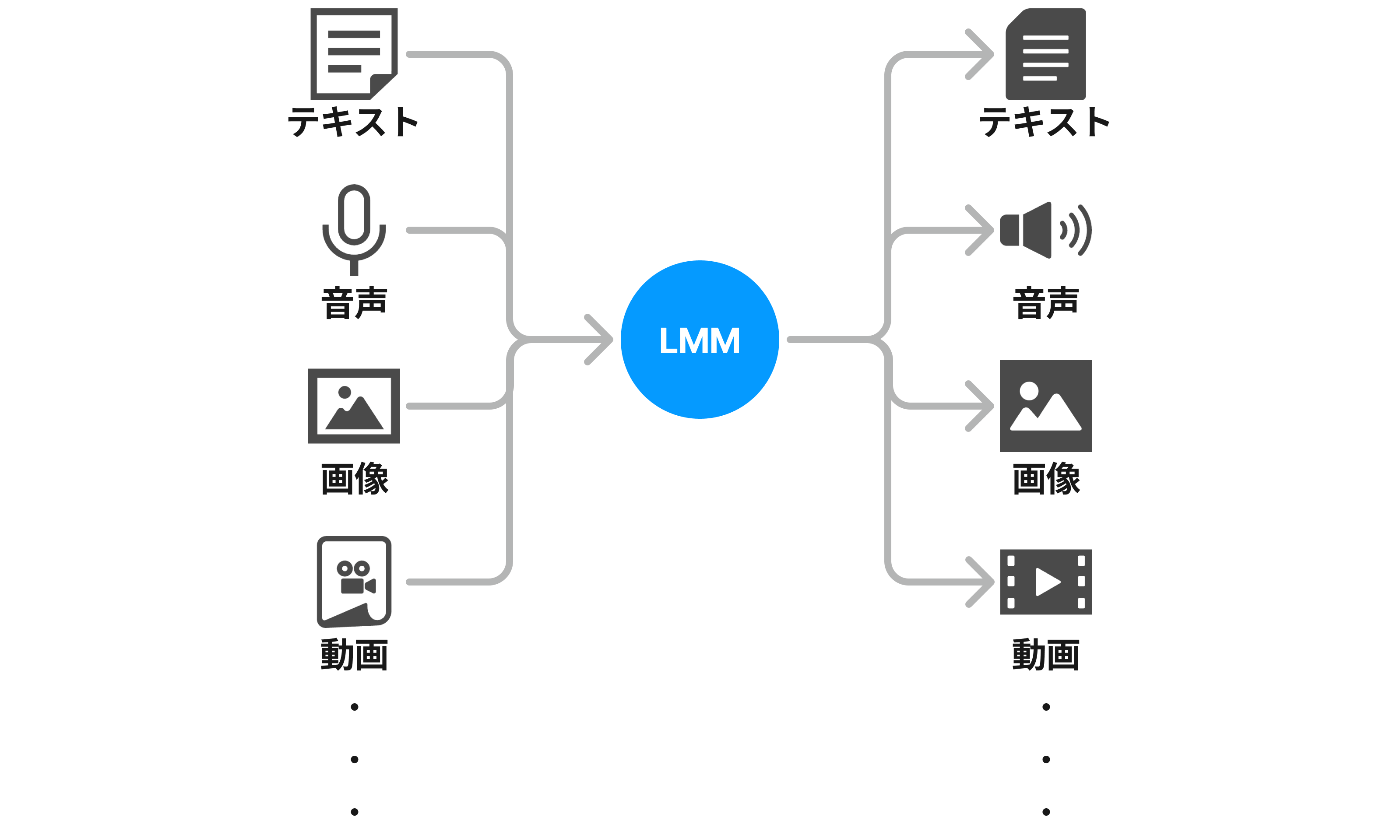
LMMの入出力はあらゆる形式受け付ける
それに対して、狭義のLLMは、テキストを入力としてテキストを返すものを指します。

LLMの入出力はテキスト形式のみ
これまでもGPT-4 Turbo with VisionやGPT-4oは、マルチモーダルと言えばマルチモーダルだったわけですが、入出力の取り得る形式にかなり制限がありました。
そして、旧(高度ではない?)音声機能は、
- ① Speech-to-Textで文字起こしする
- ② 文字起こしした文章を入力として受け取って、LLMで返答文を生成
- ③ 生成された返答文をText-to-Speechで音声生成して、音声で返答する
と段階的に動いていたのに対して、
高度な音声機能は
- ① 音声を入力して、音声を出力する
と、直接音声 to 音声を実現しているのであれだけのレイテンシの低さを実現しているのだろうと言われています。
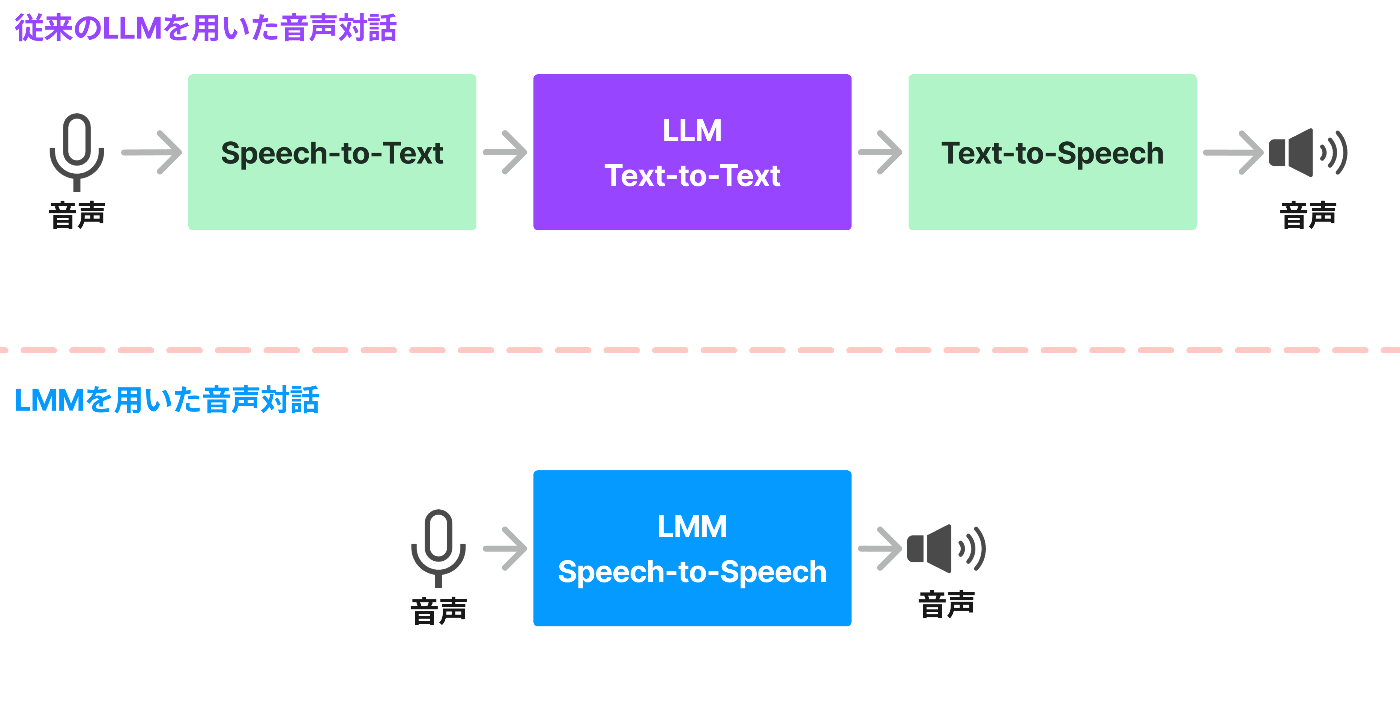
従来のLLMを用いた音声対話とLMMを用いた音声対話
ここでは、LMMの原理については深堀りしませんが、個人的には、LMMの原理について学ぶには下記の動画がオススメです。
メインの解説は画像についてですが、単純なLMMの仕組みがわかりやすく解説されています。
実際のGPT-4oのマルチモーダル対応の仕組みは公開されないでしょうから、旧来のLMMと仕組みがどこまで同じかは分かりませんが、原理的には近しい仕組みで動くものと私は想像しています。
マルチモーダルによって切り拓かれる可能性
冒頭でも述べたようにLLMによってどのような応用可能性があるのかは、多くの人が語っているので、今更私が語る必要のあることは多くないと感じています。
この章は、LMMの可能性については、お前に言われてなくとも分かっているよという方は読み飛ばしていただいても大丈夫です。
前提として、そもそも私は、文字 to 文字のLLMはこれ以上劇的には賢くならないんじゃないか?と考えています。
もちろんハルシネーションを防ぐ等、できる改善はいくらでもありますが、まあ地味といえば地味で。
今のGPT-4oやClaude3.5 sonnetはテキストだけでコミュニケーションできる相手としてはもう十分過ぎるぐらいに賢いのではと感じています。
1.5倍ぐらいとか、2倍ぐらい賢くなる可能性はまだありそうですが、20倍賢くなるかというとそんなことはないだろうと。
ですが、もっと賢くなって欲しい!!と思っている私がいるというのも事実です。
ただ、ここでいう賢いとは、「難しいことを知っている」とか「難しい問題も解ける」という意味ではありません。
どちらかと言えば、"聡い"という言葉のニュアンスの方が近しいでしょうか。
平たく言ってしまえば、「指示に込めたおれの微妙なニュアンスをもっと汲み取ってくれ!!!」というお気持ちです。
もちろん指示の背景や裏の意図まで徹底的に言語化すれば、今のLLMでも十分に理解してくれますが、これはシンプルに面倒くさい。
指示する側にも相当なリテラシーが求められるので、このままでは一般への普及には限界があるでしょう。
ただ、冷静になると「指示に込めたおれの微妙なニュアンスをもっと汲み取ってくれ!!!」という要求には少し無理があります。
なぜならChatGPTなどは、私の置かれている状況を完全に理解はしていないからです。
日々一緒に働いて、文脈を共有しているはずの同僚間でさえ、テキストコミュニケーションで意図がずれてしまったという経験は誰しもがお持ちでしょう。
とすれば、AIが聡く強い仲間になるためには、究極的には日々生活を共にし、私の思考の癖まで理解してもらう必要があるということです。
芥見下々著『呪術廻戦』より
もちろん、この数年でAIが私たちの生活に溶け込み、ありとあらゆる場面を共にするようになれば、コンテクストを正確に理解できるようにもなっていくと思います。
ただ、それにはもう少し時間がかかる。
それ以前にLMMによってもたらされる、今よりも十分便利な発展段階があると思っています。
LMMが私の置かれている状況を完全には理解してくれていなくとも、出力が爆速になり、
「いや、そうじゃなくて、こうなんだよ」という私の反応に素早くレスポンスしてくれるようになればどうでしょうか。
「うーん、、、」と一言言うと、出力を途中でやめて、修正してくれるようなイメージですね。
LMMは、出力に対する私の反応に高速でレスポンスしてくれる結果、最終的に求める解には速くたどり着くという方向性に進化していくのかなと思っています。
もう少しだけ説明してみましょう。
リモートワーク中にテキストコミュニケーションが洒落臭くなって、ちょっとオンラインで喋りましょうかとなった経験もこれまた誰しもがお持ちでしょう。
なぜ人間にとって、ビデオ通話等のコミュニケーション手段がテキストのみのコミュニケーションよりも意思疎通が速いのかといえば、話している内容だけではなく、表情や声のトーンなどからも相手の考え・心情を推し量ることが出来るからです。
「もしかして私の言っていることは、きちんと理解されていないのではないか?」ということも想像することが出来ます。
それさえできれば、相手の発言を待たずとも、説明を変えてみるというアクションがすぐに取れます。
LMMも同じで、マルチモーダル化することで表情とか声のトーンからも自分(=AI)の出力がどう受け取られているのかを読み取れるようになり、「どうやらこいつ(=上野)納得してないな?」というようなことを瞬時に読み取って軌道修正するということもできるようになるでしょう。
ストリーミングで出している途中から出力を軌道修正するということはできなさそうなので、
また一から出力のし直しになるかもしれませがん、それでも今よりは幾分柔軟な対応が可能になるかと思います。
最終的には、人間と同じように相手が発言している最中にも相手が言おうとしていることを想像しながら、自分の返答を考えることができるようになれば、劇的にレスポンスが速くなるでしょう。
一方で、そのためには、入力側も音声や動画をストリーミングで受け取り、かつ出力も途中で変更できる必要が出てくるので、もう数段ブレークスルーが起きなければならないのだろうと推測しています。
このようにLMMを使えば、AIが人間に近づき、よりスムーズにコミュニケーションできるようになる可能性を秘めています。
当然、高度なLMMが実現すれば、人間と同じようなことをAIにさせることができるようになるため、プロダクト開発の可能性は劇的に広がるでしょう。
アップデート版のGPT-4oのAPIに関する疑問
ここからは直近発表されるであろう、アップデート版のGPT-4oのAPIに目を移していきましょう。
アップデート版のGPT-4oのAPIはそう遠くない未来に公開されるかと思いますが、いくつか疑問が残ります。
そのうちの代表的なものには以下のようなものがあるでしょう。
- ① 出力形式を自由に選択できるのか
- ② テキスト以外もストリーミング出力に対応しているか
- ③ 音声 to 音声で返す場合でもプロンプトをテキストで与えることはできるか
- ④ もっと日本人らしい音声を出力できるのか
それぞれを簡単に見てきましょう。
①出力形式を自由に選択できるのか
入力はこちらから送るので自由に選択できるのは当然ですが、出力の形式を自由に選択することは出来るのでしょうか。
例えば、
テキストでの入力に対して音声で返したり(テキスト to 音声)、
音声での入力に対して画像を返したり、
出力の形式を自由に選択することは可能なのでしょうか。
ChatGPTでは、音声モードに入ったら、音声同士で会話していればいいと思うので、音声 to 音声に制限されていても問題ないと思います。
ですが、APIで出力の形式を自由に選択できればかなり応用の幅は広がるでしょう。
むしろ、自由に選択できなければ、用途が限られてしまいますね。
②テキスト以外もストリーミング出力に対応しているか
すでにテキストのストリーミング出力機能はGPT-4oには実装されています。
ChatGPTで、出力された文字が徐々に出てくるあれです。
出力がストリーミングで出でてくることのメリットは、最初の文章が出始めるまでの待ち時間が少ないことと、どんどん文字が出てくるので人間側も情報を逐次処理できることです。
そのため、ストリーミングはチャットサービスにとっては良いUXだと言われています。
当然、音声でもストリーミングで帰ってきて順次再生できれば、ユーザーにとって無駄な待ち時間は劇的に減るでしょう。
ただし、音声をストリーミングで返そうとすると、イントネーションやアクセントに違和感が生まれてしまうようなので、ストリーミングで返すことが必ずしも正とは限らないことにもご注意ください。
ChatGPTの高度な音声機能は裏側でどのような処理が行われているのかは今時点では全く分かりませんが、音声をストリーミングで返さずに、あれだけの処理速度を実現出来ているのだとしたら素晴らしいことです。
どちらにしても、音声もストリーミング出力に対応してくれるのかどうかについては、かなり注目しています。
③音声 to 音声で返す場合でもプロンプトをテキストで与えることはできるか
ChatGPT画像を与える場合は下記のように画像と一緒にプロンプトに与えることが出来ます。
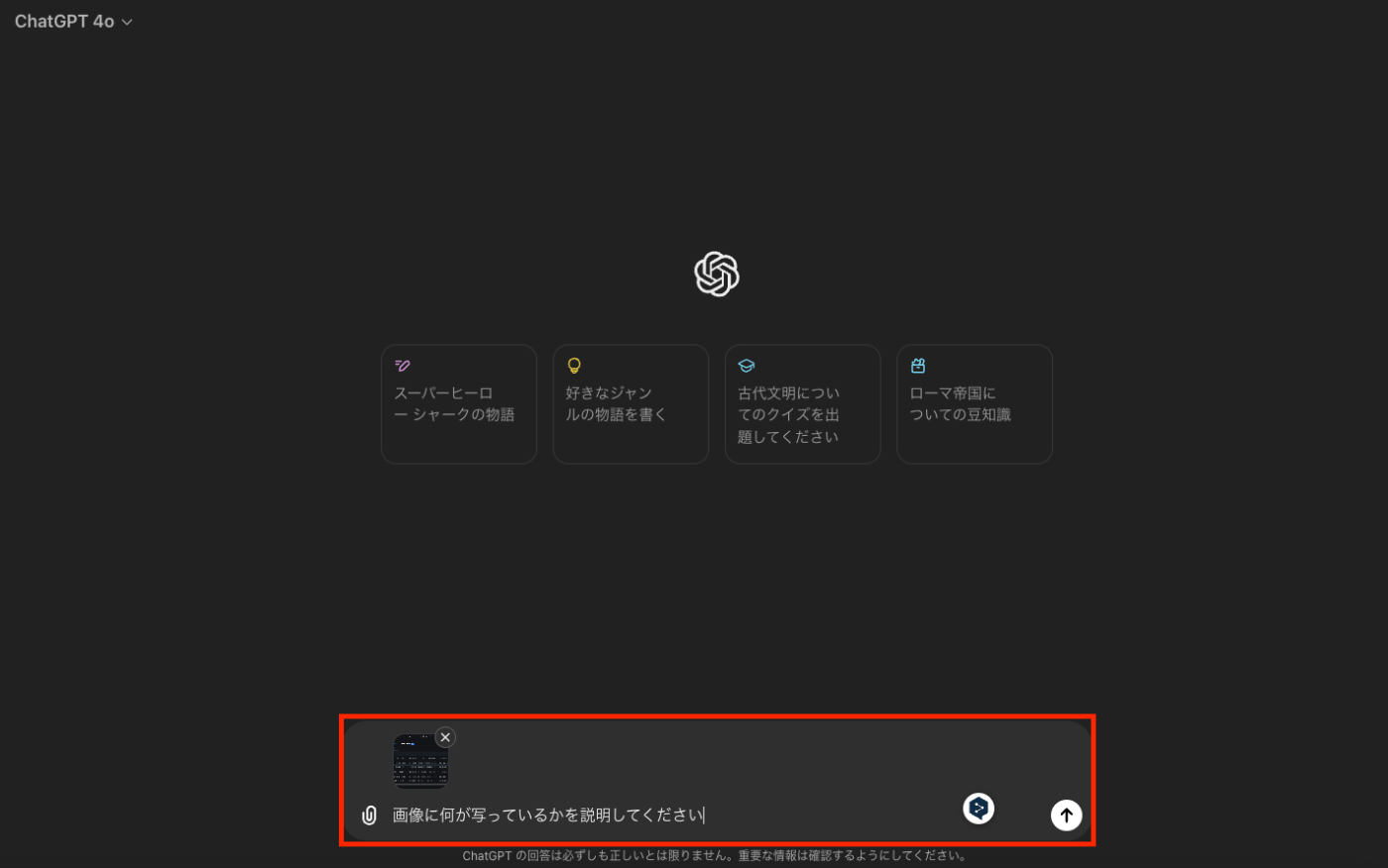
ChatGPTで画像を与えた
APIでもプロンプトと画像を一緒に与えることは可能です。
プロンプトを与えることで、画像を理解して何をすればいいのかを指示することが可能になります。
音声 to 音声で返す場合でもプロンプトを入れることが出来なければ、返答を制御できなくなってしまいます。
LMMの仕組みを考えるにおそらくプロンプトは入れられるようにはなるとは思うのですが、何も触れられていないので想像で語るしかありません。
④もっと日本人らしい音声を出力できるのか
これは書いてみましたが、デモや体験をした方の情報を見ている限りおそらく実際には難しいのでしょう。
聞いたことがある方はお分かりかとは思いますが、GPT-4oは日本語の上手な海外出身の方のようなイントネーションで話します。
API使用する場合でも音声は日本語らしいイントネーションでは返せない気がするので、これをそのままプロダクトとして使うのは正直難しいと思います。
日本語の上手な海外出身の方のようなイントネーションで話していいプロダクトであればいいですが、そのようなプロダクトはあまりないように思います。
例えば、音声会話型おしゃべりAIアプリCotomoの良さは声だと思っています。
使ったことがある方には激しく同意いただけると思いますが、声がとても日本人らしく親しみが持てます。
AIだということを忘れてしまうほどに親しみを感じてしまいます。
声は、人間が相手に対して抱く印象にこれほどまでに大きな影響を与えるのかと改めて気が付かされました。
それに対して、GPT-4oの音声は明らかにAIっぽいと言わざるを得ないでしょう。
この問題を乗り越えようと思うと、いわゆる音声変換技術等が必要になりそうです。
そのことを考えると、初めから音声 to 音声で行うよりも音声→テキスト→音声と変換する旧形式の方が扱いやすいということもあり得るかもしれません。
マルチモーダルモデル音声対話の課題
ここまでは単純に疑問を述べてきましたが、今度はどのようなことが課題になり得るか?という考えをシェアしたいと思います。
課題があるから使い物にならないという話でもなく、適切に乗り越えられるものもあります。
まだ発展余地があるのだと捉えれば、今後の進歩が楽しみになります。
特に大きな課題や今後の発展余地として想定されるのは、
- ① 出力音声を自由に変更できなければ人間(特に日本人)らしさは出せない
- ② リアルタイムに音声 to 音声で出力されてしまうと出力内容を事後的に評価することしか出来ない
- ③ 入力もストリーミングに対応できるか&ストリーミング出力中に後続の出力を変更できるか
あたりでしょうか。
①出力音声を自由に変更できなければ人間(特に日本人)らしさは出せない
これは課題の④もっと日本人らしい音声を出力できるのかでも述べた内容です。
GPT-4oの日本語がお世辞にも上手と言えないのは、OpenAIが学習している音声が欧米諸国の言語に偏っているからという単純な理由なのでしょう。
個人的な希望としては、GPT-4oでできなくとも、後続のモデルで音声のファインチューニングのようなことができれば理想です。
誰かの声で様々な文章を話したデータセットでファインチューニングすれば、その人の声に近い音声が出せるというようになるというイメージです。
もちろん誰かの声に似せるのではなく、パラメータを弄って声色を調整できるというようなことが出来る技術もあるので、その方向性で実装される可能性もあります。
ただし、音声生成・音声合成のライブラリなどをいろいろ試してみていただくと分かるのですが、案外人間らしい声を生成するというのは難しいようです。
特に、日本語が上手になるには、声色だけではなく、イントネーションの自然さが重要でしょうから、
誰かの声でファインチューニングしてイントネーションまで学習しまう方が簡単なのでは?と勝手に想像したりします。
また、下図のようにLMMが出してきた音声を別の音声に音声変換すればいいのでは?という案もありそうです。
確かに、高速に音声変換して理想の声色に近づける技術は日夜進歩しているので、速度、音質共に十分なクオリティを達成することが出来ます。
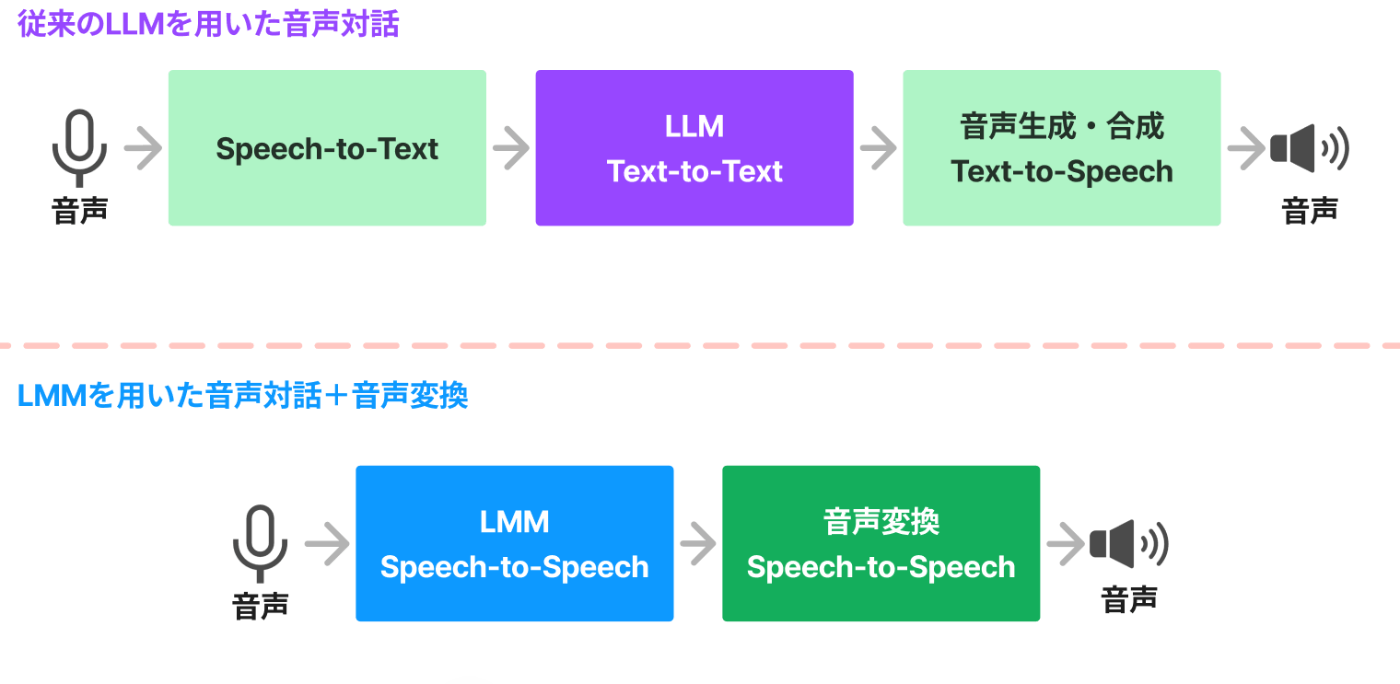
LLMの音声出力の後に音声変換を挟んだ処理
ただし、音声変換技術は、イントネーションはもとの音声のままだったりするので注意が必要です。
LMMの出してきたイントネーションが、日本語らしくなければ、音声を変えたとしても日本人らしくはなりません。
このような制約を考え出すと、一度テキストに変換してから音声合成するほうが結局扱いやすいのかも?と考えたりもします。
②リアルタイムに音声 to 音声で出力されてしまうと出力内容を事後的に評価することしか出来ない
特にセンシティブな内容を発言ししてまう可能性のあるプロダクトでは、できればLMMの出力をリアルタイムで評価したいですよね。
(評価については下記の記事もご覧ください)
PharmaXのYOJOでは、LLMが生成した文章をリアルタイムにLLMで評価(LLM-as-a-Judge)し、一定の水準を下回ったら再生成するというような機能を持っています。
このような場合、一度テキストになっていれば評価をしてから音声を発話させることも可能です。

LLMによるテキスト生成後に評価を挟んだ処理
実際、自社が作ったプロダクトでAIが誤ったことやセンシティブなを言ってしまうという事故が起こってしまうというリスクを恐れる方もいらっしゃるでしょう。
もちろんその分時間はかかってしまいますが、話す内容をリアルタイムに評価してから再生するようなことができれば、ある程度のリスクを防ぐことが出来ます。
少なくとも事故を起こす確率を減らすことはできるはずです。
LMMで音声 to 音声を出力するようになってしまうと、この評価が難しくなります。
下図のように一度音声を出力した後に評価するのでしょうか?

間違った内容を話してしまったと思えば、「すいません、やっぱり今のは違いました、、、」と訂正してもいいですが、それでは許されないプロダクトもあるでしょう。
政治家が事前に準備した原稿を読みたくなる気持ちも分かってしまいますね。
②の課題を考えると、①と同様に、一度テキストに変換した方が扱いやすいという結論になってしまうかもしれません。
③入力もストリーミングに対応できるか&ストリーミング出力中に後続の出力を変更できるか
これもマルチモーダルによって切り拓かれる可能性で述べた内容ですが、入力側も音声や動画をストリーミングで受け取ることができれば、劇的に体験が変わる可能性がありそうです。
入力側も音声や動画をストリーミングで受け取ることができるようになり、人間と同じように相手が発言している最中にも相手が言おうとしていることを想像しながら自分の返答を考えることができるようになれば、劇的にレスポンス測度が速くなりそうです。
さらに、ストリーミングで出力中に追加で受け取った内容を元に、途中から出力内容を変更できれば、より柔軟な対応が可能になります。
つまり、私たち人間が話している途中に相手の表示を読み取って言うことを途中から変えたりするのと同様の十年性を獲得できれば理想です。
ただ、以下のように入力をどんどん渡していき、裏側でそのたびに出力を作っていけば、
擬似的にストリーミングで受け取り、柔軟に出力を変えたかのようなレスポンスが可能になるでしょう。
・ユーザー「こんにちは」 → LLM「こんにちは!」
・ユーザー「こんにちは、私の」 → LLM「こんにちは、何でしょう?」
・ユーザー「こんにちは、私の名前は」 → LLM「こんにちは、お名前はなんですか?」
・ユーザー「こんにちは、私の名前は上野」 → LLM「上野さんこんにちは!」
・ユーザー「こんにちは、私の名前は上野です」 → LLM「上野さんこんにちは!」(終)
相手が話し終わったと判定したタイミングで、生成できている一番新しいメッセージを返せば十分に高速なレスポンスができるもしれませんね。
上記のように最後から2番目の返答はある程度的を得た返答になるので、返答し始める時点でこの最後から2番目の返答を返してしまっても問題ないかもしれませんね。
そう考えれば、必ずしもモデルそのものにStreamで受け取る機能が付いている必要はなく、
モデル使用料が劇的に安くなり(要は必要な計算リソースが小さくなり)、出力が爆速になれば、
上記のような擬似的な実装で、やりたいことは実現可能なのかもしれません。
ただし、ここで私が言っているストリーミングで受け取るというのには、テキストだけではなく、音声や動画も含んでいるので、それらを含むLMMが劇的に安く速くなるのにはまだ数年単位の時間がかかりそうです。
現在でも似たような取り組みはいくつか知られていますね。
もう1年近く前に話題になりましたが、サッカー動画に音声でナレーションを付ける動画で、
実装も公開されています。
実装を見てみると、動画をフレームに分割し、テキストでナレーションを生成して、音声で読み上げているのが分かります。
GPT-4 Vision APIとTTSが使われています。
ただし、この実装では、逐次的に処理しているのではなく、あくまで10フレームに1フレームを抜き出し、一括してGPT-4 Vision APIに送信して、一気にナレーションを生成させています。
つまり、動画を再生しながらリアルタイムで処理しているわけではありません。
あくまで、事前に下記のようなテキストをまとめて生成し、音声で読み上げた音声を動画に被せているだけです。
AND THERE HE GOES, MESSI WITH THE BALL, LIKE A MAGICIAN ON THE FIELD, DODGING ONE, TWO, THREE... UNSTOPPABLE! LOOK AT HIM GO, THE CROWD IS ROARING!!! CAN YOU BELIEVE THIS?? HE'S TAKEN ON THE WHOLE DEFENSE, HE'S A ONE-MAN SHOW LADIES AND GENTLEMEN... HE SHOOTS... GOOOOOOOOOOOOOL!!!! MESSI, MESSI, MESSIIIIII!!! UNBELIEVABLE, WHAT A GOAL, WHAT A GOAL! GLORIOUS, ABSOLUTELY GLORIOUS! THE STADIUM EXPLODES IN JOY! THIS IS FOOTBALL MAGIC AT ITS FINEST! ONLY MESSI, ONLY MESSI! GOL, GOL, GOOOOOOL!!!
また、これぐらいの短い動画でもそれなりの値段はかかるようですね。
一括で画像を投げてナレーションを生成させる際に、「興奮したブラジルのスポーツナレーター」というスタイルを指定し、メッシがゴールを決めるという具体的な情報を与えているので、
ナレーションに一貫性が生まれているのでしょうね。
ここで私が言っているのは、本当の実況中継を実現するには、流れてくる動画をリアルタイムにどんどん処理していき、その場で一貫性のある(前の流れも踏まえた)実況音声を生成するには、まだまだ技術的チャレンジの積み重ねが必要そうですよね?という話でした。
まとめ
今回は、マルチモーダルモデルを使った音声対話への期待と課題について私が考えていることをまとめました。
あまりまとまった文章にはならなかったですが、今時点での考察を置いておくという意味はあったのかなと思います。
ここから数年はマルチモーダルモデルが発展していく世界だと思うので、非常に楽しみですね。
技術がどのように進歩してくれればアツいのかを考えるのはいつだって楽しいものです。
PharmaXでは今後もLLM、LMMに全力投資をしていきます。
マルチモーダルのAPIが出てきたらガンガン使っていきたいですね。
今回は取り上げませんでしたが、もちろんローカルで動くマルチモーダルにも注目をしています。
今後は音声対話AIの開発に力を入れていくので、メンバーも募集しています。
もしご興味があれば、ご連絡いただければ!!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion