AWS Lambda×DuckDB×delta-rsによるETLの実装
はじめに
AWS Community Builderのぺんぎん(@jitepengin)です。
これまでの記事ではApache Icebergにフォーカスしてきました。
IcebergはOTF(Open Table Format)のデファクトスタンダードとなりつつありますが、Delta TableもDatabricks利用時には第一候補として使われる場面が多いです。
今回はAWS上でDatabricksを運用する際、前処理を軽量ETLで処理してコスト削減するアプローチを紹介します。
軽量ETLでBronze層を作成し、Silver層とGold層はDatabricksで集約・分析するワークフローです。
Delta Lakeとは
Delta Lakeは、Apache ParquetをベースにしたACID対応のデータレイクフォーマットです。
主な特徴は以下となります。
- ACIDトランザクション:複数ジョブからの同時書き込みでも整合性を保証
- タイムトラベル:過去のデータ状態を簡単に参照可能
- スキーマ進化:列の追加や型変更が容易
- パフォーマンス最適化:Z-OrderやData Skippingで効率的にクエリ実行
Databricks上で採用される主要なフォーマットで、ETL・BI・MLで幅広く利用可能です。
今回のアーキテクチャ
今回のアーキテクチャは下記となります。
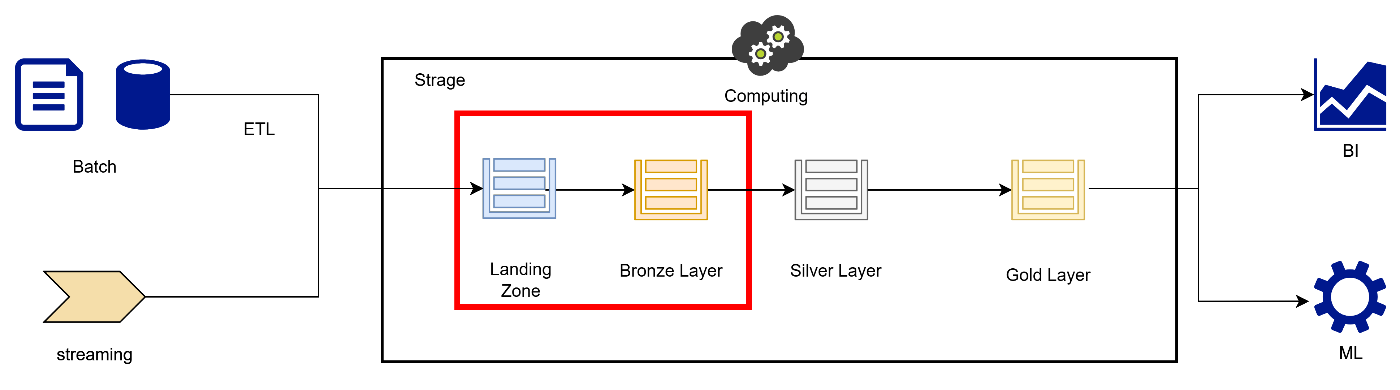
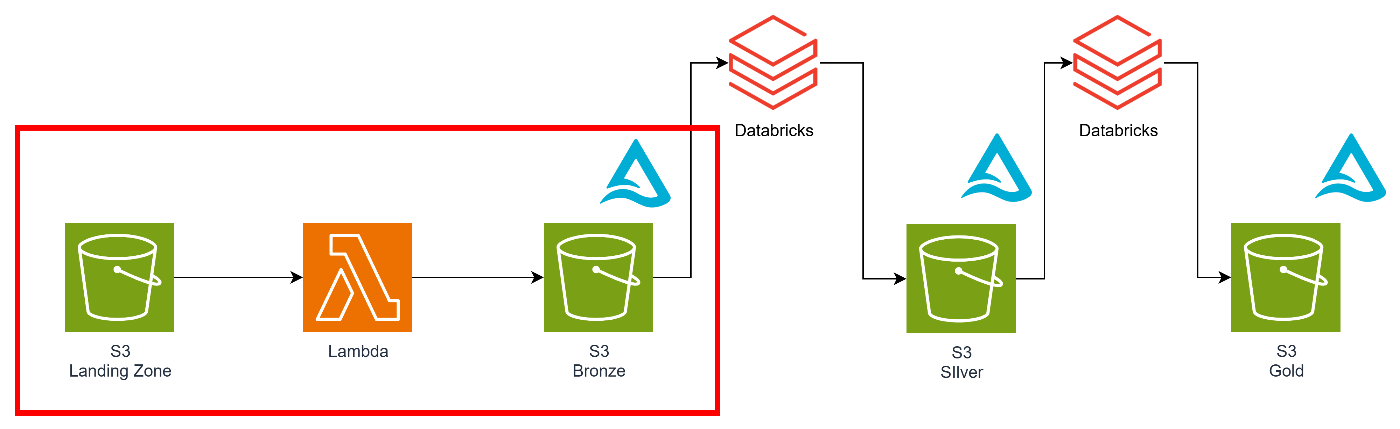
このようにメダリオンアーキテクチャの前処理部分、つまりLanding ZoneからBronzeに書き込む部分をこの軽量ETLが担います。
ここでS3へのファイル配置をトリガーに前処理を実施し、Delta形式に書き込みます。
Bronze以降の処理は高いコンピュートリソースが必要となるため、Databricksが担います。
今回はこの赤枠の部分にフォーカスして説明したいと思います。
- Landing → Bronze:軽量ETLで前処理とDelta化(今回はここにフォーカス)
- Bronze → Silver:Databricksで集計・整形・モデリング
- Silver → Gold:Databricksでビジネス指標作成、データマート化
ポイントはLambdaで使用する各種ライブラリとなります。
- DuckDB:データベースエンジンとして、メモリ内での高速なSQLクエリ処理を実現。
- PyArrow:Arrowフォーマットを使用し、高速なデータの変換・転送をサポート。
- delta-rs:Delta Lake形式の読み書き・更新をサポートするRust/Pythonライブラリ。
DuckDBとは
DuckDBとは、組み込み型のOLAP(オンライン分析処理)向けデータベースエンジンです。
DuckDBは非常に軽量で、インメモリ処理が可能となるためLambdaのようなシンプルな環境でも効率的に動作させることができます。
特にデータ分析やETL処理のようなバッチ処理において強力なパフォーマンスを発揮すると言われています。
PyArrowとは
PyArrowとは、Apache ArrowプロジェクトのPythonバインディングで、メモリ内データの効率的な操作と転送を可能にするライブラリです。
Apache Arrowは、データ解析や分散コンピューティングに特化した高速なカラムナメモリフォーマットを提供します。
PyArrowは、このArrowフォーマットをPythonで利用するためのAPIを提供し、さまざまなデータ操作やデータ間のやり取りを効率的に行うことが可能です。
delta-rsとは
delta-rsとは、Delta LakeフォーマットをRustで実装したライブラリであり、Pythonや他の言語から利用できるバインディングを提供しています。
Delta LakeはDatabricksが開発したACIDトランザクション対応のデータレイクフォーマットであり、スキーマ進化・タイムトラベル・高効率なクエリといった機能を備えています。
Pythonから利用する場合は deltalake パッケージとして提供されており、Delta Tableの作成・書き込み・更新などを簡潔に実装可能です。
事前準備(databricksとAWSの連携)
外部ロケーションの作成
AWSクイックスタートを選択し、バケット情報を入力します

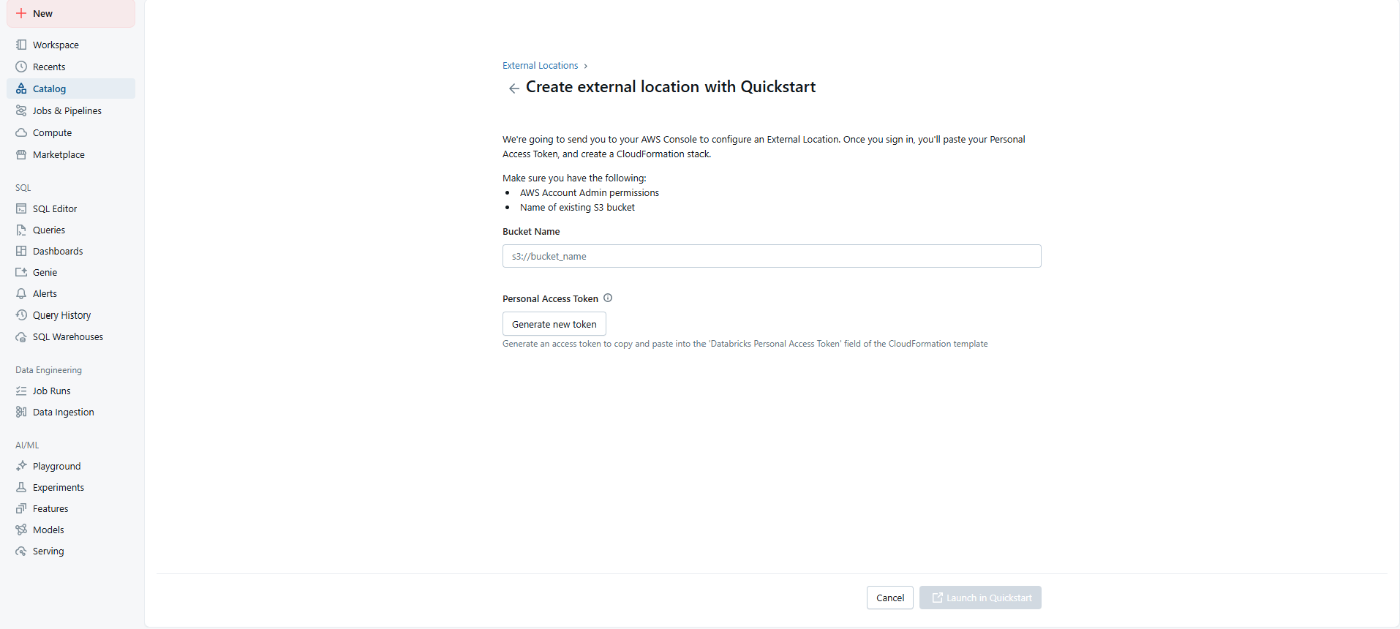
CloudFormationの実行
こちらは外部ロケーションを作成すると自動で行われます。

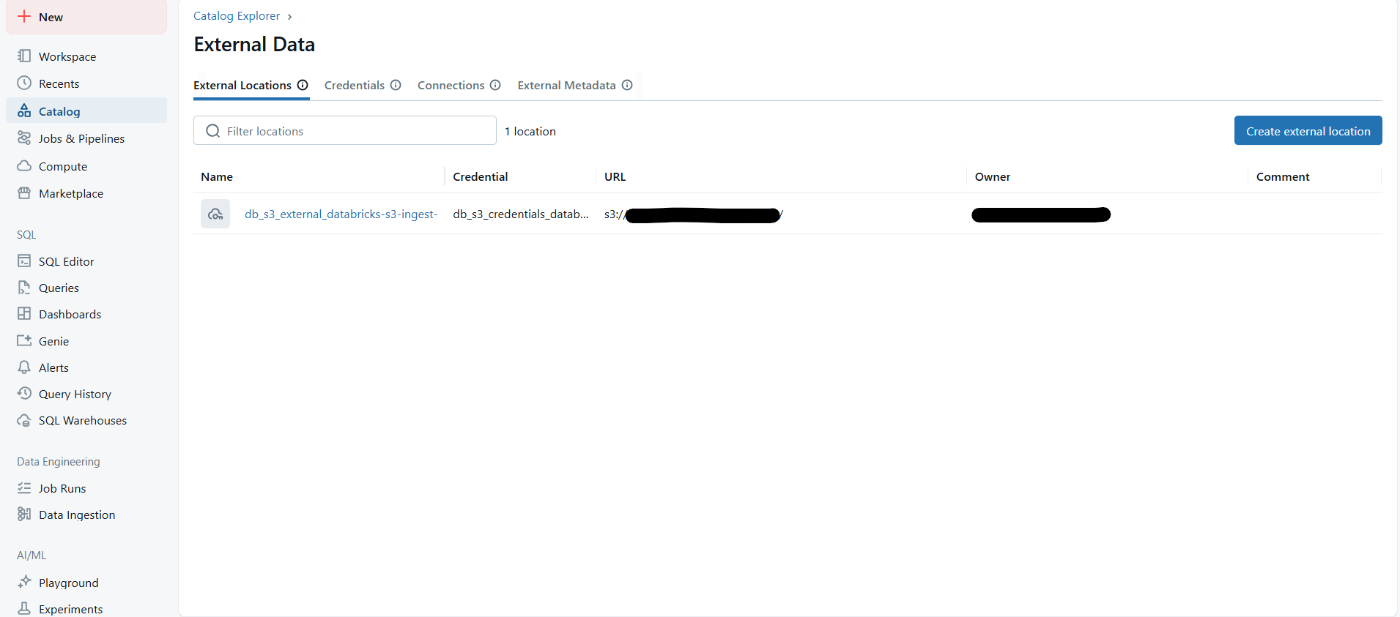
カタログ作成
今回使用するカタログを作成します。


このようにGUIベースで簡単にDatabricksとS3の連携が実現できます。
あとのテーブル作成などもSQLベースで簡単に実施可能です。
Lambdaへの組み込み
今回はライブラリのサイズが大きくなってしまったのでコンテナ形式としました。
dockerfile
# AWS Lambda Python 3.12
FROM public.ecr.aws/lambda/python:3.12
WORKDIR /var/task
COPY requirements.txt .
RUN pip install -r requirements.txt --target "${LAMBDA_TASK_ROOT}"
COPY lambda_function.py .
CMD ["lambda_function.lambda_handler"]
requirements
duckdb
pyarrow
deltalake>=1.1.4
サンプルコード
import duckdb
import pyarrow as pa
from deltalake import write_deltalake
def lambda_handler(event, context):
try:
duckdb_connection = duckdb.connect(database=':memory:')
duckdb_connection.execute("SET home_directory='/tmp'")
duckdb_connection.execute("INSTALL httpfs;")
duckdb_connection.execute("LOAD httpfs;")
# Get input file from S3 event
s3_bucket = event['Records'][0]['s3']['bucket']['name']
s3_key = event['Records'][0]['s3']['object']['key']
s3_input_path = f"s3://{s3_bucket}/{s3_key}"
print(f"s3_input_path: {s3_input_path}")
query = f"""
SELECT *
FROM read_parquet('{s3_input_path}')
WHERE VendorID = 1
"""
result_arrow_table = duckdb_connection.execute(query).fetch_arrow_table()
print(f"Row count: {result_arrow_table.num_rows}")
print(f"Schema: {result_arrow_table.schema}")
# --- Convert timestamp columns ---
schema = []
for field in result_arrow_table.schema:
if pa.types.is_timestamp(field.type) and field.type.tz is None:
# tz-naive timestamp[us] → timestamp[ns, tz="UTC"]
schema.append(pa.field(field.name, pa.timestamp("ns", tz="UTC")))
else:
schema.append(field)
new_schema = pa.schema(schema)
result_arrow_table = result_arrow_table.cast(new_schema)
print(f"Schema after conversion: {result_arrow_table.schema}")
# Delta table output path
s3_output_path = "s3://your-bucket"
# Write to Delta Lake
write_deltalake(
s3_output_path,
result_arrow_table,
mode="append", # or "overwrite"
)
print(f"Successfully wrote to Delta table: {s3_output_path}")
except Exception as e:
print(f"Error occurred: {e}")
注意事項(WriterVersion >= 7 の制約)
Deltaテーブルの WriterVersion が7以上かつtimestamp列がタイムゾーンなし(timestamp[us]) の場合、次のエラーが発生します。
Writer features must be specified for writerversion >= 7, please specify: TimestampWithoutTimezone
これは Delta仕様の制約によるものです。
writerversionが7以上の場合、TimestampWithoutTimezoneを指定する必要があります。
ただし、delta-rsがTimestampWithoutTimezoneの指定に対応していないため、今回のようにスキーマ変換を行う必要があります。
つまり、timestamp[us] を timestamp[ns, tz="UTC"] にキャストしてから書き込むということです。
また、deltalake>=1.1.4でないとうまく動かないことがありますのでこちらも注意が必要です。
実行結果
サンプルデータは下記から取得しています。(サンプルとしてよく使われるNYCのタクシーのデータです)
トリガー起動後
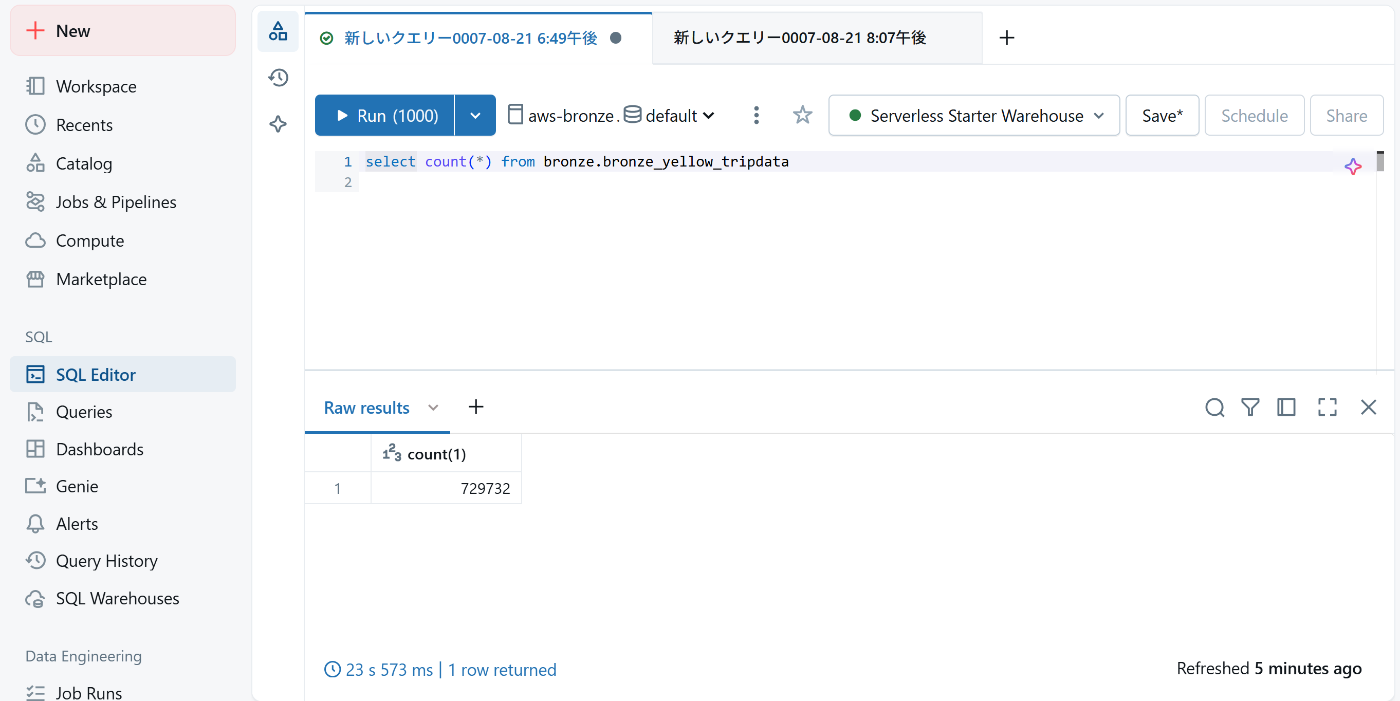
このようにDelta形式のOTFにデータを登録することができました!
参考:Bronze層以降の実装について
Bronze → Silver
Silver層は分析用にデータを整理する層です。
考慮ポイント
- データ正規化や結合で複数ソースを統合する。
- 集計粒度の調整(時間単位、地域単位など)を実施。
- データ品質チェック(欠損値・異常値の処理)を実施。
- モデリング視点(事実テーブル、ディメンションテーブル)で考慮。
Silver層の役割
- Databricksで複雑な変換や集計を担当する。
- 後続Gold層でのビジネス指標作成に向けて最適化を実施する。
Silver → Gold
Gold層は最終的なビジネス指標・データマート層です。
考慮ポイント
- 指標設計(売上合計、平均乗車距離、ピーク時間帯など)を実施する。
- 粒度・集約レベルの最適化を行う。
- BI/MLで即利用可能な形式に整形する。
- Delta形式の維持で変更履歴やタイムトラベルを活用すると便利。
Gold層の役割
- データ分析・意思決定に即活用可能なデータセットとなる。
- 正確性・信頼性の確保が重要。
ワークフローの分担イメージ
| 処理 | 担当 | ポイント |
|---|---|---|
| データ取得・前処理 (Landing → Bronze | Lambda / DuckDB / delta-rs | コストの最小化、S3にDelta形式で保存 |
| 複雑な集計・整形 (Bronze → Silver) | Databricks | Silver層整形、モデリング、統合処理 |
| ビジネス指標・データマート(Silver → Gold) | Databricks | Gold層整形、BI/ML用の最終出力 |
今回の構成のメリット・デメリット
メリット
- コスト効率が高い:GlueやEMR、Databricksを使わず、軽量ETLとすることでコストメリットを高めることが可能。
- Lambdaで簡単に開発可能:各種ライブラリを活用することで簡単に開発が可能。
- SQLライクな処理:SQLの構文(PostgreSQL互換)で簡単に操作できる。
- 効率的な処理が可能:Lambda上でもインメモリ処理により効率的なデータ処理が可能。
- S3トリガーでリアルタイムETL処理が可能:S3トリガーを使うことでファイル格納をトリガーにETL処理を即時実行可能。
デメリット
- 最大メモリサイズの制限がある:Lambdaの制限により最大メモリサイズが10240 MBとなる。場合によってはメモリが枯渇する可能性がある。(この辺りのメモリ効率は未検証なのでどこまで耐えられるかは不明です…)
- 実行時間の制限がある:Lambdaの制限により実行時間は15分が最大となります。大規模データセットの場合、15分を超えてしまう可能性があるため、場合によってはコンテナサービス等も検討する必要があります。
まとめ
今回はdelta-rsを活用した、AWS上でのDelta Lakeをベースとした軽量ETLを紹介しました。 Databricksは分散処理をベースにした高性能なプラットフォームですが、データセットのサイズによってはコスト効率が良くない場合があります。
そんな場面で効果を発揮するのが、今回紹介したような軽量ETLです。
前処理であればそれほど計算リソースが必要ないため、十分活用可能です。
また、Lambdaを利用することで、S3トリガーを活用したリアルタイムETL処理が可能になります。
これを活かすことで軽量でシンプルなデータ処理フローを構築できる点が大きなメリットです。
これ以外にも様々な考慮事項がありますが、要件やコスト効率、パフォーマンスを加味したうえで、採用を検討いただければと思います。
今回の記事が、deltaテーブルを扱う際の軽量なデータ処理やリアルタイムETLを検討している方の参考になれば幸いです。
Discussion