AWS Lambda×AthenaによるIcebergテーブルへのETLの実装
はじめに
AWS Community Builderのぺんぎん(@jitepengin)です。
以前、AWS Lambda×DuckDB×PyIcebergによるETLの実装、AWS Glue Python Shell×DuckDB×PyIcebergによるETLの実装という2つの記事を投稿しました。
AWS Lambda×DuckDB×PyIcebergによるETLの実装
AWS Glue Python Shell×DuckDB×PyIcebergによるETLの実装
それぞれの実装方法ではPyIcebergがデータの登録・更新のポイントとなっていました。
今回はAthenaを活用したPyIcebergを使用しない、よりシンプルな実装を紹介したいと思います。
今回のアーキテクチャ
今回は、S3にファイルがアップロードされたことをトリガーに、Lambdaを起動して、Athenaでクエリを実行し、変換後のデータをApache Iceberg形式でS3に保存します。

ポイント
- LambdaからAthenaを非同期実行することで、処理時間の上限15分を超える処理も可能です。
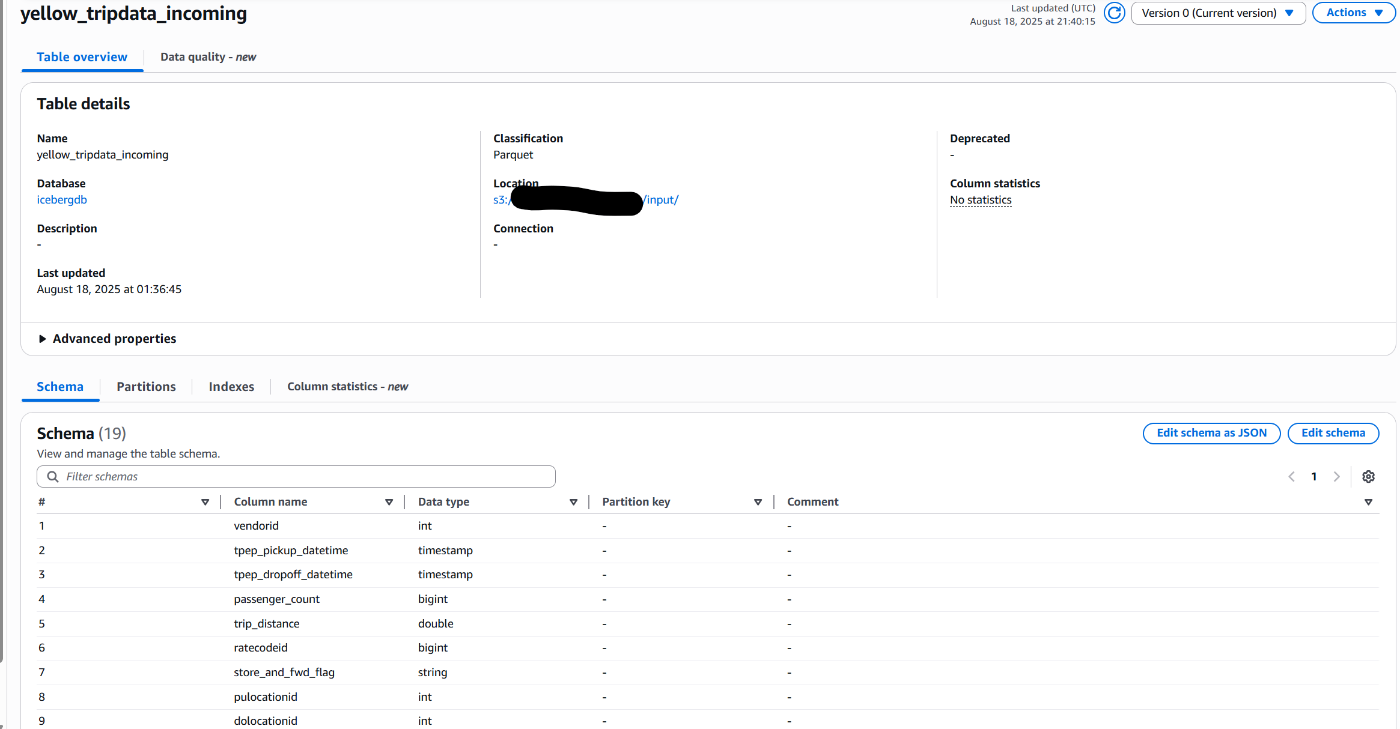
- ファイルアップロード用のS3バケットは外部テーブルとして登録しておく必要があります。
下記のようにClassificationをParquetとして、登録先のIcebergテーブルと同じスキーマでテーブルを作成しておきます。
サンプルコード
同期処理版と非同期処理版両方に対応したものを作成しました。
同期処理版は、Athenaの処理の結果を待機する必要があるため、重い処理ではLambdaの制限時間に抵触する可能性がありますが、エラーハンドリング後の対応が実施しやすいメリットがあります。
非同期処理版は、Athenaの処理の結果を待機しないため、Lambdaの制限時間の影響を受けずに処理を行うことが可能となりますが、エラーハンドリングをどのように行うか検討が必要となります。
同期処理を行いたい場合はwait_for_query_completionをコールいただき、非同期処理を行いたい場合はwait_for_query_completionをコメントアウトいただければと思います。
実装のポイント
-
path列を使うことで、外部テーブルに含まれる他ファイルを誤って取り込むことを防ぐ。 - LambdaはAthenaの実行だけで完結(シンプルな実装を意識)。
- 外部テーブルのスキーマとIceberg テーブルのスキーマは一致させておく必要がある。
import boto3
import json
import time
def lambda_handler(event, context):
try:
athena_client = boto3.client('athena')
DATABASE = 'icebergdb'
OUTPUT_LOCATION = 's3://your-bucket/test/'
# Get bucket name and key from S3 event
s3_bucket = event['Records'][0]['s3']['bucket']['name']
s3_key = event['Records'][0]['s3']['object']['key']
s3_path = f"s3://{s3_bucket}/{s3_key}"
print(f"Processing file: {s3_path}")
query = f"""
INSERT INTO icebergdb.yellow_tripdata
SELECT *
FROM yellow_tripdata_incoming
WHERE "$path" = '{s3_path}'
AND VendorID = 1
"""
# Execute query
response = athena_client.start_query_execution(
QueryString=query,
QueryExecutionContext={'Database': DATABASE},
ResultConfiguration={'OutputLocation': OUTPUT_LOCATION},
WorkGroup='primary'
)
query_execution_id = response['QueryExecutionId']
print(f"Query started: {query_execution_id}")
# Wait for query completion (optional)
wait_for_query_completion(athena_client, query_execution_id)
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Data insertion completed successfully',
'queryExecutionId': query_execution_id,
'processedFile': s3_path
})
}
except Exception as e:
print(f"Error processing file: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps({
'error': str(e),
'message': 'Failed to process file'
})
}
def wait_for_query_completion(athena_client, query_execution_id, max_wait_time=300):
"""Function to wait for query completion"""
start_time = time.time()
while time.time() - start_time < max_wait_time:
response = athena_client.get_query_execution(QueryExecutionId=query_execution_id)
status = response['QueryExecution']['Status']['State']
if status in ['SUCCEEDED']:
print(f"Query {query_execution_id} completed successfully")
return True
elif status in ['FAILED', 'CANCELLED']:
error_message = response['QueryExecution']['Status'].get('StateChangeReason', 'Unknown error')
raise Exception(f"Query failed: {error_message}")
time.sleep(5)
raise Exception(f"Query timeout after {max_wait_time} seconds")
実行結果
サンプルデータは下記から取得しています。(サンプルとしてよく使われるNYCのタクシーのデータです)
実行前
実行後

このようにIceberg形式のOTFにデータを登録することができました!
最適化のポイント
パーティション活用
今回のクエリではyellow_tripdata_incomingに対してSELECTをかけ、結果をINSERTする処理となっています。
このyellow_tripdata_incomingにパーティションを設定することで最適化が図れます。
CREATE EXTERNAL TABLE yellow_tripdata_incoming (
VendorID int,
tpep_pickup_datetime timestamp,
...
)
PARTITIONED BY (
year int,
month int,
day int
)
STORED AS PARQUET
LOCATION 's3://your-bucket/yellow_tripdata/'
SQLの最適化
これはAthenaに限らず、SQLでの最適化テクニックですが、必要な列のみSELECT、早期フィルタリング適用などでも効率化が図れます。
早期フィルタリング適用は今回のようなシンプルなSQLでは活用できませんが、サブクエリで事前にフィルタしてから本処理に渡すようなイメージで考えていただければと思います。
非同期処理
今回のサンプルコードでも使用可能ですが、非同期処理にすることで、Lambdaの実行時間を短縮することができ、コスト最適化が図れます。
ただし、結果をもとに処理をしたい場合、エラーハンドリングを行いたい場合はCloudWatchやEvent Bridgeを使用した実装を検討する必要があります。
運用上の注意点
今回の構成はいくつか注意点があります。
- Input用の外部テーブルとIcebergテーブルの2段構成になるため、2重での管理が必要となります。(スキーマ変更時の対応等)
- 前述したように最適化の検討が必要となり、AthenaのクエリコストやS3スキャン量を意識した設計が重要となります。
他の構成との比較
以前紹介したLambda×PyIceberg、Glue Python Shell×PyIcebergと比較してみます。
それぞれメリット・デメリットがあるので用途や要件に応じて選択いただければと思います。
| 構成 | メリット | デメリット |
|---|---|---|
| Lambda×Athena | ・サーバレスで軽量 ・PyIcebergなどのライブラリ管理不要 |
・非同期実行の場合、クエリ失敗はLambdaで直接捕捉できない ・大量データの細かい加工には不向き |
| Lambda×PyIceberg | ・Lambda内で柔軟にデータ加工が可能 ・Icebergテーブルを直接操作 |
・Lambda実行時間制限に注意が必要 ・ライブラリの管理(PyIcebergモジュール)が必要 |
| Glue Python Shell×PyIceberg | ・Shell内で柔軟にデータ加工が可能 ・長時間バッチやある程度の大規模データに対応 |
・Lambdaより起動時間が長くなる場合がある。(コストに影響) |
まとめ
今回はAWS LambdaとAthenaを組み合わせてIceberg形式のテーブルに対してETL処理を実装しました。
この構成のメリットとしてPyIcebergなどの外部ライブラリを使用せずにシンプルかつ軽量に実装できる点があります。
また、LambdaからAthenaを非同期実行することでLambdaの実行時間制限(15分)を超える処理も可能となり、低コストで柔軟なデータ処理パイプラインを構築できます。
一方で、非同期実行ではAthenaクエリの失敗をLambda側で直接検知できないため、CloudWatchやEventBridge、SNSなどを活用した監視設計が重要です。
また、$pathで対象ファイルを絞り込むことやパーティション設計を適切に行うことで、誤って他のデータを取り込むリスクやクエリコストの増加を防ぐことができます。
これ以外にも様々な考慮は必要ですが、要件によっては十分選択肢になると思います。
今回の記事が、Icebergテーブルを扱う際の軽量なデータ処理やリアルタイムETLを検討している方の参考になれば幸いです。
Discussion