AWS Glue Python Shell×DuckDB×PyIcebergによるETLの実装
はじめに
AWS Community Builderのぺんぎん(@jitepengin)です。
以前、AWS Lambda×DuckDB×PyIcebergによるETLの実装という記事を投稿しました。
今回はLambdaと同様に軽量ETL処理に活用されることの多い、AWS Glue Python ShellをベースにしたApache Iceberg形式に対応したETLを実装したいと思います。
AWS Glue(Spark)やEMRだとコストがかかる、Lambdaだとタイムアウトが気になるといった場合にAWS Glue Python Shellが効果的だと思います。
AWS Glue Python Shellとは
AWS Glue Python Shellは、Apache Sparkを使わずにPythonスクリプトを実行できるAWS Glueの実行環境です。
Lambdaの15分制限に比べると長時間のバッチ処理が可能になります。デフォルトではなんと48時間です!
また、サーバレスで起動できるため、インフラの管理は不要で使った分だけ課金されます。
GlueやEMRと比較するとコストも安く済むケースが多いことから、軽量ETLやデータ変換処理で活用されます。
そんな便利なGlue Python Shellですが、Lamndaと比べるとトリガとなるイベントが少ないというデメリットがあります。
よくイベント駆動の処理で使われるS3のファイル配置トリガについても直接のトリガやEventBridge経由でのトリガも対応していません。
こういった場合のトリガには一般的にはLambdaまたはGlue Workflowを経由して起動されます。
これ以外にも様々な制約がありますが、うまく使いこなせば処理の幅が大きく広がる可能性を秘めたサービスとなります。
今回のアーキテクチャ
今回は、S3にファイルがアップロードされたことをトリガーに、Lambdaを経由してGlue Python Shellを実行し、変換後のデータをApache Iceberg形式でS3に保存します。
LambdaはあくまでもGlue Python Shellの起動だけ行い、ETLをGlue Python Shell側で行うことで処理時間の上限の15分を超える処理を行うことが狙いとなります。

ポイントは下記の各種ライブラリとなります。
- DuckDB:データベースエンジンとして、メモリ内での高速なSQLクエリ処理を実現。
- PyArrow:Arrowフォーマットを使用し、高速なデータの変換・転送をサポート。
- PyIceberg:AWS Glue Catalogを活用して、Iceberg形式のテーブルにアクセス・操作。
DuckDBとは
DuckDBとは、組み込み型のOLAP(オンライン分析処理)向けデータベースエンジンです。
DuckDBは非常に軽量で、インメモリ処理が可能となるためLambdaのようなシンプルな環境でも効率的に動作させることができます。
特にデータ分析やETL処理のようなバッチ処理において強力なパフォーマンスを発揮すると言われています。
PyArrowとは
PyArrowとは、Apache ArrowプロジェクトのPythonバインディングで、メモリ内データの効率的な操作と転送を可能にするライブラリです。
Apache Arrowは、データ解析や分散コンピューティングに特化した高速なカラムナメモリフォーマットを提供します。
PyArrowは、このArrowフォーマットをPythonで利用するためのAPIを提供し、さまざまなデータ操作やデータ間のやり取りを効率的に行うことが可能です。
PyIcebergとは
PyIcebergとは、Apache IcebergのPythonライブラリで、大規模データセットのテーブル管理を容易にするライブラリです。
Apache Icebergは、クラウドネイティブのデータレイクを効率的に扱うために設計されたオープンソースのテーブルフォーマットであり、PyIcebergはそのPython実装を提供します。
PyIcebergを使用することで、Python環境でIcebergテーブルにアクセスし、高度なデータ操作が可能となります。
Additional Python modules pathの設定
Additional Python modules pathには以下を設定してください。
割とライブラリの依存関係にはまりやすいので注意していただければと思います。
pyiceberg[glue]==0.9.1,pydantic==2.5.0,pydantic-core==2.14.1,annotated-types==0.6.0,duckdb==0.9.2,pyarrow==14.0.1,typing-extensions==4.8.0
サンプルコード
Lambdaのトリガー処理
S3のイベントを受けてGlue Python Shellを起動するだけのシンプルな処理です。
import boto3
def lambda_handler(event, context):
glue = boto3.client("glue")
s3_bucket = event['Records'][0]['s3']['bucket']['name']
s3_object_key = event['Records'][0]['s3']['object']['key']
s3_input_path = f"s3://{s3_bucket}/{s3_object_key}"
response = glue.start_job_run(
JobName="Iceberg shell",
Arguments={
"--s3_input": s3_input_path
}
)
print(f"Glue Job started: {response['JobRunId']}")
return response
AWS Glue Python ShellのETL処理
Lambdaから起動され、パラメータをもとにDuckDBでファイルを取得、PyIcebergでS3のIcebergテーブルに書き込む処理です。
DuckDBではVendorID = 1でデータをフィルタリングしています。このようにSQLのような構文でクレンジングやフィルタリングを行うことが可能です。
今回はカタログアクセスにGlueCatalog形式を使っています。
AWS Glue Iceberg RESTエンドポイント方式(REST Catalog)でも同様の処理が可能となりますので、要件に応じて選択いただければと思います。
カタログアクセス方式の違いについては下記を参考にしていただければと思います。
import boto3
import sys
import os
from awsglue.utils import getResolvedOptions
def get_job_parameters():
# get job parameters
try:
required_args = ['s3_input']
args = getResolvedOptions(sys.argv, required_args)
s3_file_path = args['s3_input']
print(f"object: {s3_file_path}")
return s3_file_path
except Exception as e:
print(f"parameters error: {e}")
raise
def setup_duckdb_environment():
# Properly set up the DuckDB environment
try:
home_dir = '/tmp'
duckdb_dir = '/tmp/.duckdb'
extensions_dir = '/tmp/.duckdb/extensions'
os.environ['HOME'] = home_dir
os.environ['DUCKDB_HOME'] = duckdb_dir
os.environ['DUCKDB_CONFIG_PATH'] = duckdb_dir
os.environ['DUCKDB_EXTENSION_DIRECTORY'] = extensions_dir
os.makedirs(duckdb_dir, exist_ok=True)
os.makedirs(extensions_dir, exist_ok=True)
os.chmod(duckdb_dir, 0o755)
os.chmod(extensions_dir, 0o755)
print(f"DuckDB environment setup completed: {duckdb_dir}")
return True
except Exception as e:
print(f"DuckDB environment setup error: {e}")
return False
def read_parquet_with_duckdb(s3_input):
# Read Parquet file from S3 using DuckDB
import duckdb
con = duckdb.connect(':memory:')
try:
con.execute("SET extension_directory='/tmp/.duckdb/extensions';")
con.execute("INSTALL httpfs;")
con.execute("LOAD httpfs;")
session = boto3.Session()
credentials = session.get_credentials()
con.execute(f"SET s3_region='ap-northeast-1';")
con.execute(f"SET s3_access_key_id='{credentials.access_key}';")
con.execute(f"SET s3_secret_access_key='{credentials.secret_key}';")
if credentials.token:
con.execute(f"SET s3_session_token='{credentials.token}';")
print(f"Reading data from S3: {s3_input}")
sql = f"SELECT * FROM read_parquet('{s3_input}') WHERE VendorID = 1"
res = con.execute(sql)
return res.arrow()
except Exception as e:
print(f"DuckDB error: {e}")
raise
finally:
con.close()
def write_iceberg_table(arrow_table):
# Write to an Iceberg table
try:
print("Writing started...")
from pyiceberg.catalog import load_catalog
from pyiceberg.schema import Schema
from pyiceberg.types import NestedField, StringType, IntegerType, DoubleType, TimestampType
catalog_config = {
"type": "glue",
"warehouse": "s3://your-bucket/your-warehouse/", # Adjust to your environment.
"region": "ap-northeast-1"
}
catalog = load_catalog("glue_catalog", **catalog_config)
table_identifier = "icebergdb.yellow_tripdata"
table = catalog.load_table(table_identifier)
print(f"Target data to write: {arrow_table.num_rows:,} rows")
# Write Arrow table to Iceberg table
table.append(arrow_table)
return True
except Exception as e:
print(f"Writing error: {e}")
import traceback
traceback.print_exc()
return False
def main():
# Set up DuckDB environment
if not setup_duckdb_environment():
print("Failed to set up DuckDB environment")
return
try:
import pyiceberg
# Read data
s3_input = get_job_parameters()
arrow_tbl = read_parquet_with_duckdb(s3_input)
print(f"Data read success: {arrow_tbl.shape}")
# Write to Iceberg table
if write_iceberg_table(arrow_tbl):
print("\nWriting fully successful!")
else:
print("Writing failed")
except Exception as e:
print(f"Main error: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
main()
実行結果
サンプルデータは下記から取得しています。(サンプルとしてよく使われるNYCのタクシーのデータです)
実行前

実行後
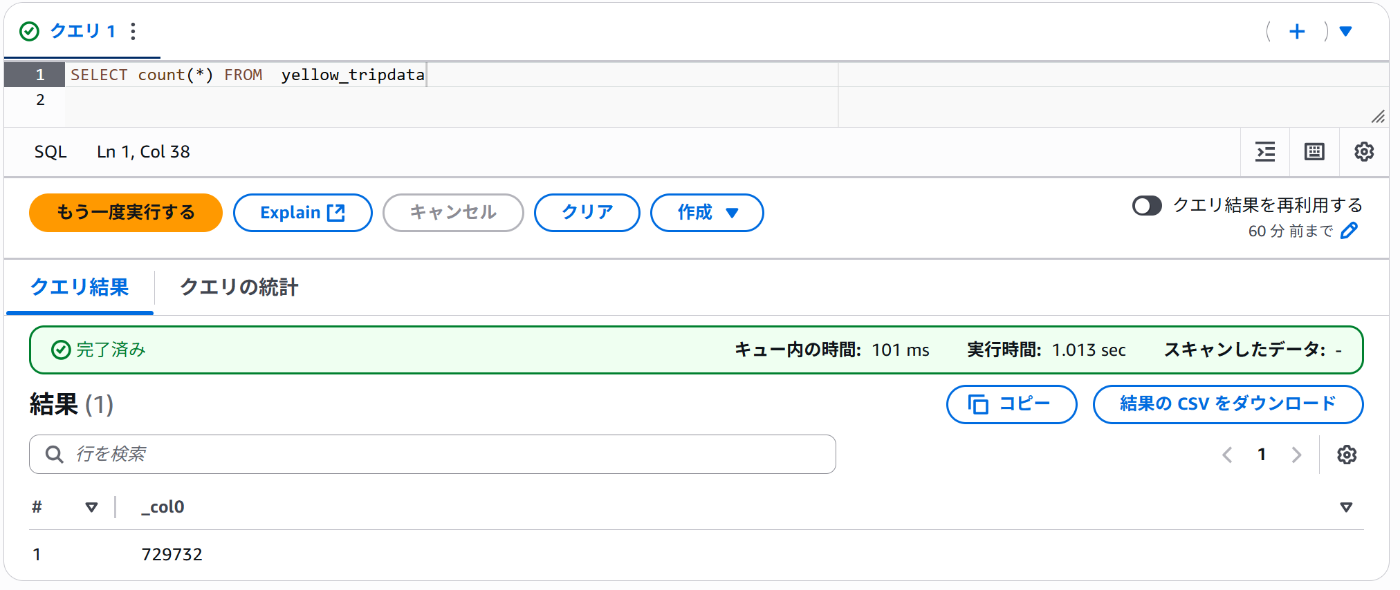
このようにIceberg形式のOTFにデータを登録することができました!
参考:Lambdaでの実装
以前の記事では、Lambda内でDuckDBとPyIcebergを使って直接ETL処理を行いました。
ただし、Lambdaは15分の時間制限があるため、大きなデータや複雑な処理では途中でタイムアウトする可能性やメモリ不足でエラーとなる可能性がありました。
同じライブラリ構成をGlue Python Shellに移すことで制約を回避することが可能となります。
import duckdb
import pyarrow as pa
from pyiceberg.catalog.glue import GlueCatalog
def lambda_handler(event, context):
try:
# Connect to DuckDB and set the home directory
duckdb_connection = duckdb.connect(database=':memory:')
duckdb_connection.execute("SET home_directory='/tmp'")
# Install and load the httpfs extension
duckdb_connection.execute("INSTALL httpfs;")
duckdb_connection.execute("LOAD httpfs;")
# Load data from S3 using DuckDB
s3_bucket = event['Records'][0]['s3']['bucket']['name']
s3_object_key = event['Records'][0]['s3']['object']['key']
s3_input_path = f"s3://{s3_bucket}/{s3_object_key}"
print(f"s3_input_path: {s3_input_path}")
query = f"""
SELECT * FROM read_parquet('{s3_input_path}') WHERE VendorID = 1
"""
# Execute SQL and retrieve results as a PyArrow Table
result_arrow_table = duckdb_connection.execute(query).fetch_arrow_table()
print(f"Number of rows retrieved: {result_arrow_table.num_rows}")
print(f"Data schema: {result_arrow_table.schema}")
# Configure Glue Catalog (to access Iceberg table)
catalog = GlueCatalog(region_name="ap-northeast-1", database="icebergdb", name="my_catalog") # Adjust to your environment.
# Load the table
namespace = "icebergdb" # Adjust to your environment.
table_name = "yellow_tripdata" # Adjust to your environment.
iceberg_table = catalog.load_table(f"{namespace}.{table_name}")
# Append data to the Iceberg table in bulk
iceberg_table.append(result_arrow_table)
print("Data has been appended to S3 in Iceberg format.")
except Exception as e:
print(f"An error occurred: {e}")
AWS Glue Python Shell構成のメリット・デメリット
メリット
- Lambdaより長時間実行でき、大きなファイルも処理可能。
- サーバレスでスケーラビリティが高い。
- DuckDBやPyIcebergなどのPythonのライブラリをそのまま利用可能。
- Iceberg形式での保存によりスナップショットやタイムトラベルが可能。
デメリット
- Lambdaより起動がやや遅く、Start-up timeとしてライブラリの読み込みの時間がかかる。
- その名の通り、Pythonのみ対応し他の言語は使えない。
- Sparkの分散処理が活用できないので大規模データや高負荷となる処理には不向き。
- 依存ライブラリのバージョン管理は工夫が必要。
参考:Lambdaとの料金比較
Lambdaの実行上限の15分で比較しました。
Lambda
メモリは意外と使ってしまうので2048 MBで設定しています。


AWS Glue Python Shell
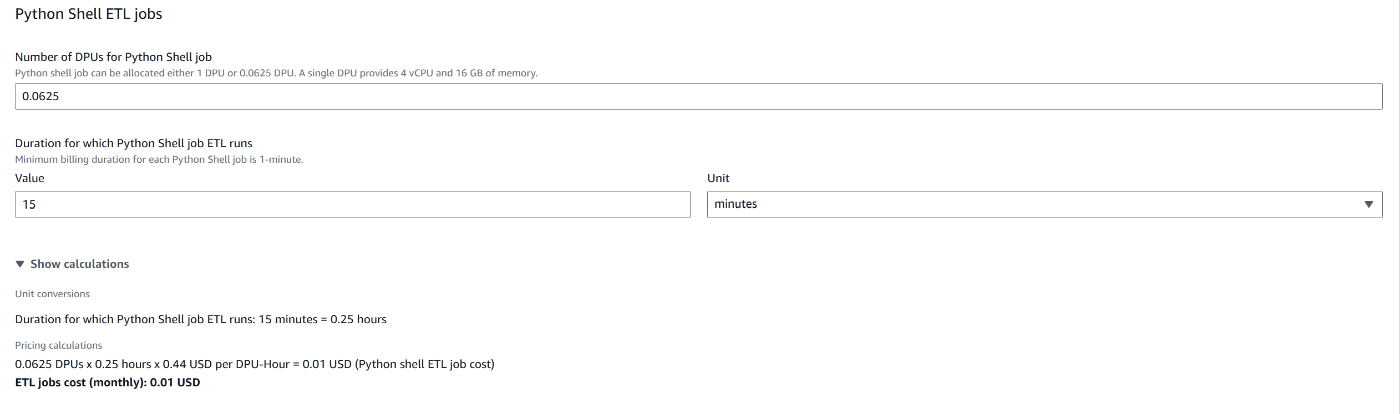
条件によってはAWS Glue Python Shellのほうが安くなる場合もあります。
まとめ
今回はAWS Glue Python Shellを活用してIceberg形式のテーブルに対してETL処理を実装しました。
AWS Glue Python Shellは、LambdaとGlue(Spark)の中間に位置するサーバレス実行環境として、軽量ながら長時間のETL処理を可能にします。
今回のようにDuckDBとPyIcebergを組み合わせれば、低コストで柔軟なデータ処理パイプラインを構築できます。
特に起動時間が長いことに大きなメリットがありますので、Lambdaでは時間が足りないが、Glue(Spark)やEMRはオーバースペックというケースで選択肢になると思います。
Icebergテーブルにはスキーマの進化やタイムトラベル等様々なメリットがあります。
Icebergは、OTFの主流とも言える存在になりつつあり、今後ますます利用される機会が増えると考えられます。
今回の記事が、Icebergテーブルを扱う際の軽量なデータ処理やリアルタイムETLを検討している方の参考になれば幸いです。
Discussion