Azure の運用を支える AIOps #2【インシデント管理編】
この記事は「Azure の運用を支える AIOps」シリーズの第2回です。今回は、Microsoft Azure のインシデント管理システムで活用されている AIOps のテクノロジーを紹介します。AIOps の概要や Microsoft と AIOps の関わり方については、第1回をご覧ください。
AIOps と インシデント管理
インシデント管理とは
インシデント管理(Incident Management)とは、システムやサービスに発生した問題(インシデント)を、迅速かつ効果的に解決するためのプロセスです。単にインシデントを解決するだけでなく、その原因を特定し、将来のインシデントを予防するための対策を講じることも含まれます。そのため、インシデント管理は継続的な取り組みであり、IT サービスマネジメントの重要なプロセスの一つとして認識されます。
インシデント管理のフローには、以下のようなステップが含まれます。
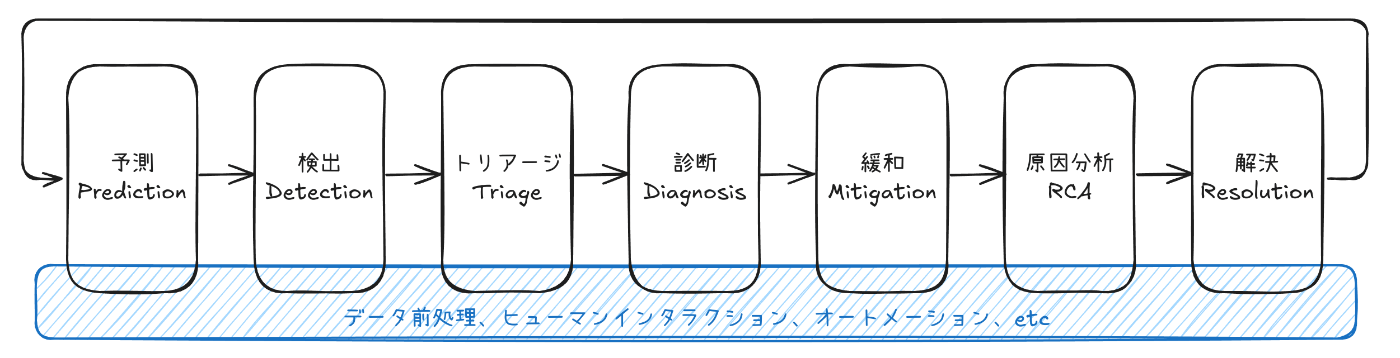
AIOps が取り扱う インシデント管理の流れ
| ステップ | 説明 |
|---|---|
| 予測(Prediction) | 観測データを基に障害の発生を予測します。予測した障害を未然に防ぐ対策を講じるか、障害が発生した場合の対応を事前に計画します。 |
| 検知(Detection) | 発生しているインシデントを検知します。ユーザーからの問い合わせ、監視システムからのアラート、ログの解析など、さまざまな手段でインシデントの発生を把握します。 |
| トリアージ(Triage) | 検知されたインシデントの重要度や影響度を評価し、優先順位(優先度)をつけます。また、インシデントを解決するためのサービスチームやオンコールエンジニア(On-Call Engineer; OCE)を割り当てます。 |
| 診断(Diagnosis) | 緩和策を検討するための情報収集を行います。このステップでは、必ずしも根本原因を特定する必要はなく、インシデントの状況を迅速に把握することが重要です。 |
| 緩和(Mitigation) | システムを安定状態に戻すための措置を講じ、実行します。設定の切り戻し、システムの再起動など、さまざまな手段でインシデントを緩和します。 |
| 根本原因分析(Root Cause Analysis; RCA) | 監視データやコードベースを調査することで、インシデントが発生した根本原因を特定します。また、同じインシデントが再発しないよう対策を講じます。 |
| 解決(Resolution) | ハードウェア交換、パッチ適用、設定変更などにより根本原因が解決されたことを確認し、インシデントをクローズします。 |
AIOps の問題設定(タスク)
基本的に、AIOps で取り組むタスク(解くべき問題)は、インシデント管理のステップに対応します。たとえば、ディスク障害の予兆を検出する場合は「予測」問題を解いています。ただ、フォーカスが特定のステップに当たっていても、実際には複数のステップをカバーすることもしばしばあります。「緩和」の自動化を目的とする場合、通常は「診断」フェーズも含めて自動化するような設計が取られます。
また、上記以外にも、より汎用的なタスクを取り扱うこともあります。たとえば、次のようなものがあります。
- データ前処理: 監視データから重要なインサイトを得るための前処理(例:ログフィルタリング、欠損データ補完)
- インシデント関連付け: 類似するインシデントを発見する(例:トリアージの前準備、同じ障害に起因するサポートリクエストの集約)
- オートメーション: 各種操作をパイプライン化して自動制御できるようにする(トラブルシューティングツールの自動実行)
- ユーザーエクスペリエンス: インシデント対応者が理解しやすい UX を設計する(例: LLM による障害内容の要約、Human-in-the-Loop による検証ステップの確立)
- 可視化: 直感的なシステム状況の把握のためのデータ可視化
指標 (KPI)
インシデント管理で使用される指標には、以下のようなものがあります。
| 指標 | 正式名称 | 説明 |
|---|---|---|
| MTTD | Mean Time to Detect | インシデントが発生してから検知までの平均時間 |
| MTTT | Mean Time to Triage | インシデントが検知されてから適切な対応者にアサインされるまでの平均時間 |
| MTTM | Mean Time to Mitigate | インシデントが検知されてから緩和までの平均時間 |
| MTTR | Mean Time to Resolve | インシデントが検知されてから解決までの平均時間 |
| COGS | Cost of Goods Sold | 売上原価。製品やサービスの提供に直接関連するコストを示し、利益率の計算に使用されます |
AIOps でも最終的に改善する指標は同様です。MTTD や MTTM のような指標の改善を目指します。ただし、機械学習モデルなどが使用される場合、その予測性能も重要な指標です。
Microsoft のインシデント管理
Microsoft のオンラインサービス(例: Azure)のプロダクション環境でも、基本的に先程のフローと同じようなインシデント管理が行われています。インシデントの検知(予測)から解決までのライフサイクルの概要は次の通りです。
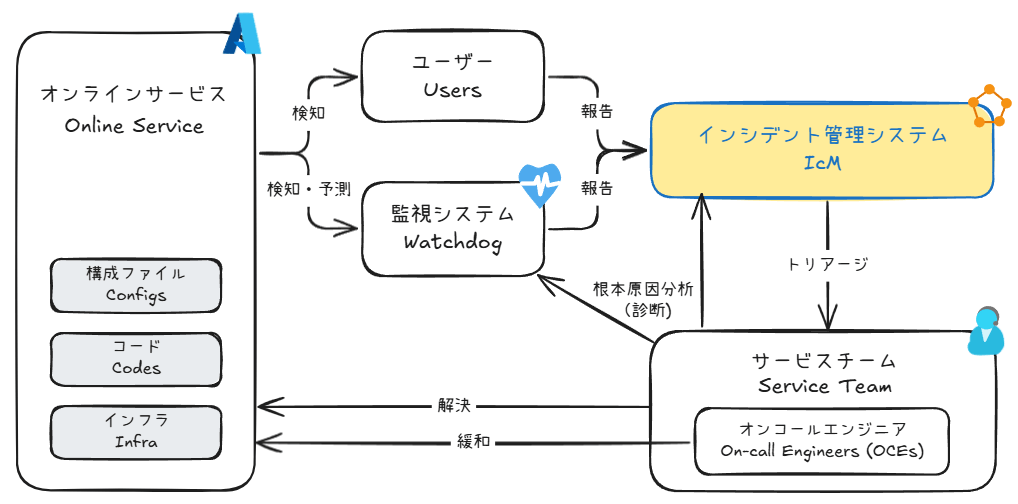
Microsoft のインシデント管理ライフサイクル
ユーザーや監視システムからの報告に応じて、インシデントが作成されます。すべてのインシデントは、インシデント管理システム(IcM)によって一元管理されます。IcM では、インシデントの属性や説明などが記録されているだけでなく、エンジニア同士のディスカッションも実施されます。また、インシデントには 4 段階の緊急度が設定されていて、緊急性が高いものについてはオンコールエンジニア(OCE)が早急に対応にあたり、緩和が試みられます。その後、根本原因分析(RCA)を実施した後、改めてサービスチームからインシデントが解決されます。
AIOps の最適化対象になるのは、主に監視システムや IcM システムです。予測精度の向上、誤検知・検知漏れの防止、より的確な診断情報の提示などにより、緩和や解決までのスピードをあげることに注力します。
詳細が気になる方は、次の文献を参照してみてください。
- An Empirical Investigation of Incident Triage for Online Service Systems - Microsoft Research
- Identifying linked incidents in large-scale online service systems - Microsoft Research
- Towards intelligent incident management: why we need it and how we make it - Microsoft Research
- What bugs cause production cloud incidents? - Microsoft Research
- Fast Outage Analysis of Large-scale Production Clouds with Service Correlation Mining - Microsoft Research
- X-Lifecycle Learning for Cloud Incident Management using LLMs | Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering
Microsoft / Azure のテクノロジー
それでは本題に入ります。ここからは、テーマごとにどのような技術が開発、導入されているのかを見ていきます。
必ずしもすべての技法が Azure の本番環境に取り入れられているわけではありませんが、なるべく導入されているものは明記するように留意しています。また、順番はインシデント管理のフローに添うように並び替えているつもりですが、完全にアラインしている訳ではないのでご承知おきください。
- 障害予測による新たな緩和パラダイム
- AI ワークロード向け GPU ノードの品質検品
- 機械学習を組み込んだ実用的なアラート システム
- 多次元データの属性を活用した異常検知
- 影響範囲が広いインシデントへの対応
- トリアージの効率化
- 類似インシデントの関連付け
- KQL クエリの自動生成
- トラブルシューティングの自動化
- AI エージェントによる根本原因分析
- ログやトレースの有効活用
障害予測による新たな緩和パラダイム
アメリカ建国の父と呼ばれるベンジャミン・フランクは、「百の治療より一の予防(An ounce of prevention is worth a pound of cure)」という言葉を残しました。この言葉は、インシデント管理の世界にも通じるものがあります。
障害が発生する前に異常の予兆をキャッチすることが出来れば、ユーザー影響を大きく軽減し、信頼性を向上することが出来ます。Microsoft が数年にわたって障害予測に注力してきた理由は、まさにここにあります。
Microsoft が障害を予測するターゲットとしてまず選択したのは、仮想マシンをホストする物理サーバー(ノード)と、ノードが利用する物理ディスクでした。ノードや物理ディスクの故障は、仮想マシンに致命的な影響を与える為です。
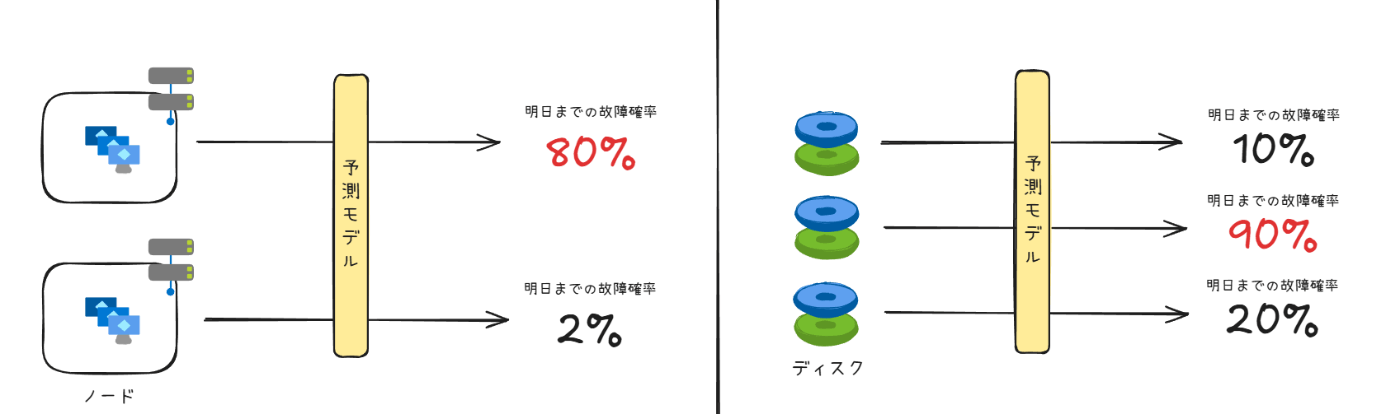
- ノードの障害予測: 2018 年にノード障害予測システム「MING」が導入されました[1]。MING は深層ニューラルネットワークと従来型の機械学習モデルを組み合わせて、時間的なデータとトポロジカルな情報を同時に扱えることが特徴的で、MING で故障率が高いとされた上位のノードは、その 60% が翌日に故障したというデータもあります。また、2024 年には「Uptake」と呼ばれる、ノード障害予測モデルを継続的に改善するための学習手法も開発しています[2]。
- ディスク障害予測: 2018 年に SMART データを活用したディスク障害予測システム「CDEF」が導入され[3]、これをベースに 2021 年に「NTAM」へと改良されました[4]。NTAM では、ディスクごとの情報だけでなく、複数のディスクの情報をまとめて処理することで精度を向上させています。この過程で、ニューラルネットワークを使った特徴量の生成手法[5]や、強化学習により不均衡な学習データを解消する手法[6]も導入しています。
ノードやディスクの障害予測は、予測に基づくプロアクティブな緩和アクションを可能にします。たとえば、Azure の仮想化基盤はライブ マイグレーション機能を持っているので、障害が起きそうなノードの仮想マシンを他ノードに移動させ、影響を最小化できます(仮想マシンのブラックアウトは通常数秒程度)[7]。
そのため、予測的な緩和が出来ることを前提にした、新たな Azure 仮想化基盤の管理システム「Narya」が 2020 年に導入されました[8][9]。
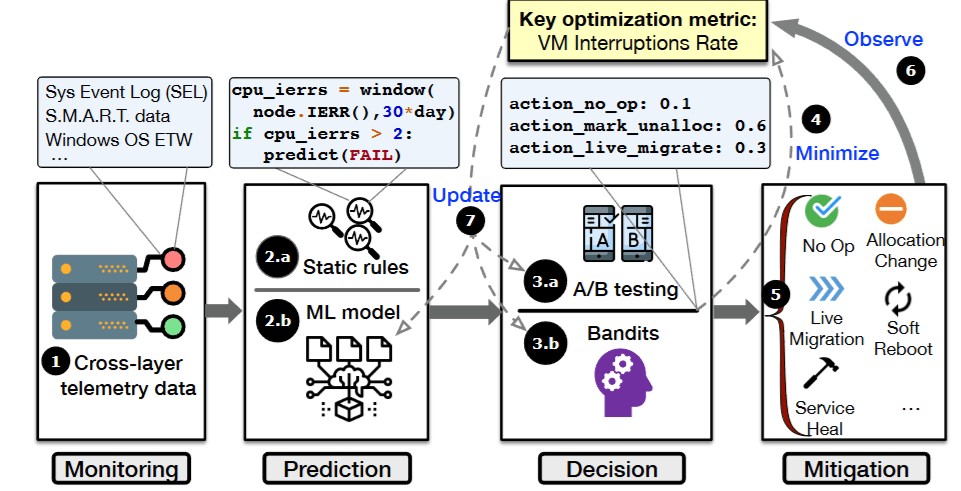
Narya が解決する問題の一つは、アクションポリシーの学習です。様々な状況(例: 予測された故障確率、障害が起きるコンポーネント、ホストしている仮想マシンの台数)に応じて行動を変えたり、過去の行動(失敗)から学ぶような仕組みが必要とされるためです。これは、まさに強化学習の分野で研究されている問題設定で、多腕バンディットと呼ばれる種類の問題/アルゴリズムで Narya はこの課題に対処します。
こうした一連の努力は、仮想マシンの中断回数を大幅に削減し、Azure プラットフォームの信頼性を高めることに大きく貢献しました。第一回の記事で紹介した VM の中断回数を計測する指標(AIR)の観点では、予測後の緩和策を決め打ちしておく単純な方法と比べて、Narya の AIR 削減効果は 26% も高いことが分かっています。
最後に、Narya の成功にインスパイアされる形で、「F3」と呼ばれるオーケストレーション システムも誕生しました[10]。データ ドリフトを検知するモニター、データ不均衡を是正する前処理、予測精度を高める特徴量の追加、そして強化学習ベース推論に基づくアクション ポリシーの学習など、プロアクティブな対応を取るために必要な機能が盛り込まれた監視プラットフォームです。
AI ワークロード向け GPU ノードの品質検品
昨今、Microsoft は AI インフラストラクチャー(例: GPU、専用プロセッサ、インターコネクト)の整備に注力しています[11][12][13][14]。日本でも、国内で展開される AI サービスやクラウド インフラに対して、29 億ドルの投資を行うという声明を 2024 年 4 月に発表して話題になっていました[15]。
ところが、AI インフラではノード故障による障害発生が多いことが分かっています。この理由には、次のような原因が考えられます。
- ハードウェアのリグレッション: AI 向けプロセッサは 1、2 年ごとにリリースされるため、十分にリグレッション テストが実施されていない可能性があります。単純なマイクロベンチマーク(e.g. GEMM、NCCL Tests)では、特定のワークロードでのみ出現するリグレッション[16]を検出しきれません。
- 検証と運用の環境差: ベンダーのテスト環境とクラウド データセンターでは、電力や温度などの要因が異なるため発生する障害の形質も異なります。たとえば Microsoft のデータセンターでも、InfiniBand が要求するビット誤り率(10E-12)を超過する異常リンク数は、熱帯地域だと 35 倍多くなることがわかっています。
- 未熟なソフトウェア スタック: ハードウェアの進化に合わせて、アプリケーションのレイヤーでも更新が必要となります。たとえば、CUDA や ROCm は数ヶ月ごとに新しいバージョンをリリースします。このような状況では、信頼性の高いソフトウェアスタックを確保することは困難です。
また、AI インフラには多くのコンポーネント(例: インターコネクト、GPU)が分散配置されており、かつ複数のレイヤーで冗長性がある(例: NVIDIA GPU の row-remapping[17])ため、グレー障害の形で事象が発現しやすいことや、トラブルシューティングが複雑で時間を要することも事態を深刻化させています。
そのため、故障の発生前に防止することが望ましく、その方法の一つに品質検査(検品)があります。本番投入するノードにベンチマークテストを実行して、正常性を確認する作業です。しかし、AI ワークロードのパターンは無数に存在し、またインフラ費用も高額なため、網羅性のあるベンチマークテストを単純に実行するのは非現実的です。
そこで開発されたのが SuperBench[18]です。SuperBench は、AI インフラとして本番展開する前のノードを効果的にベンチマーク検証することで、障害を防止するシステムです。
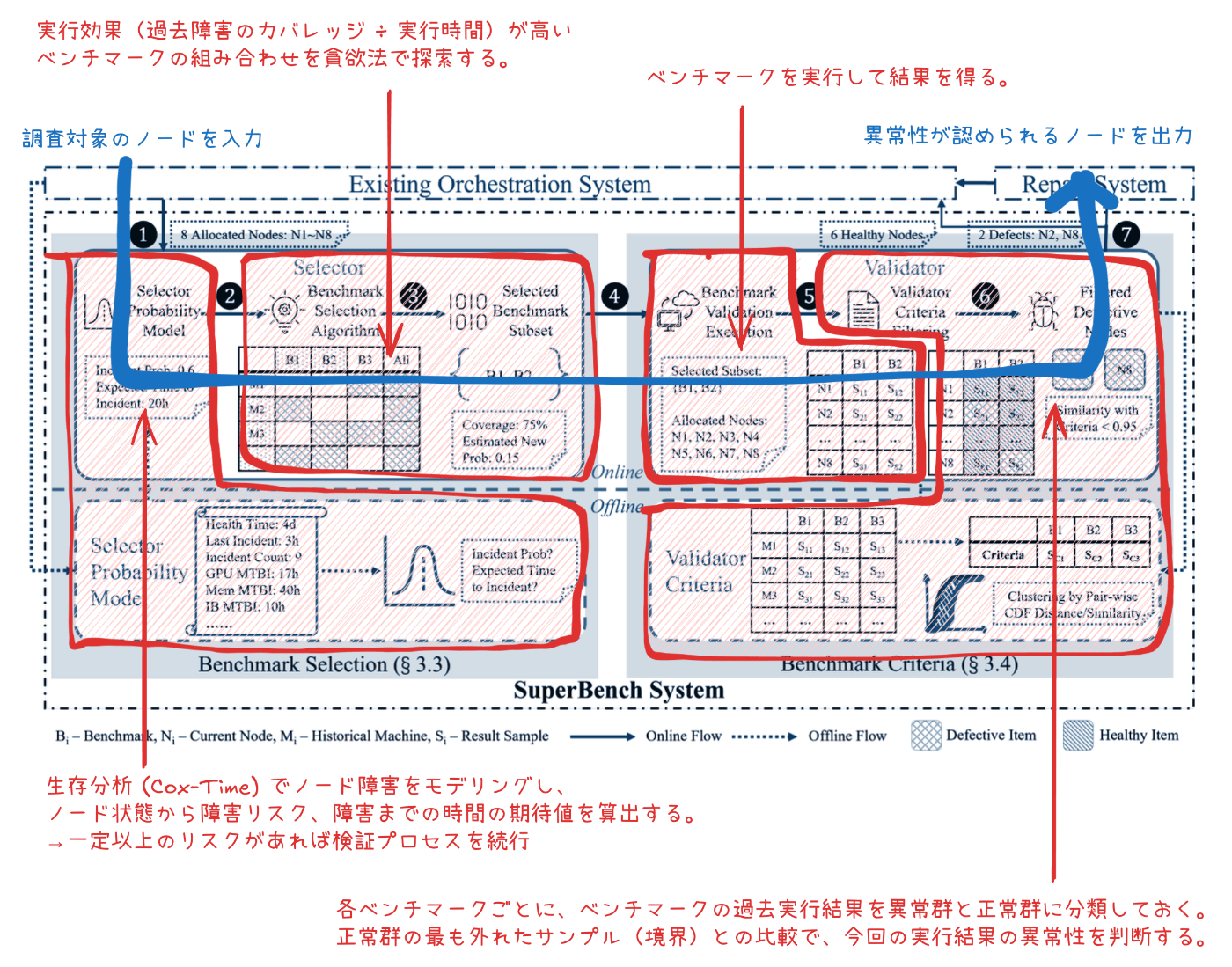
SuperBench の実行フロー
オンボードしたいノードを SuperBench に入力すると、ノード状態を見て故障リスクを予測します。高リスクと判定されると、ノード障害を特定するのに最適なベンチマーク セットが選択されます。そして、機械学習モデルで得られた基準値を基に、ベンチマーク結果の異常性を判断して最終的な結果 (Go/No-go) を出力します。
SuperBench は Azure の本番環境で既に運用され、2 年間の運用を通してノード全体の約 10% について本番展開前に問題があることを特定しました。
機械学習を組み込んだ実用的なアラート システム
障害検知は難しいタスクです。なぜなら、システムの「異常」パターンは無数にあり、適切にアラートを定義することが難しいためです。
Microsoft でも、長年のオンラインサービスの運用と努力にも関わらず、偽検知(検知したが対応する必要がなかったもの)と検知漏れ(影響が出る前にアラート検知できなかったもの)の両方ともに、一定の頻度で発生していることが判明していました[19]。また、検知漏れの主な理由がアラートルールの不備であることも分かっていて、これも「異常」を定義することの困難さを示唆しています。
このような背景から、機械学習のアプローチが盛んに研究され、近年では深層学習(ニューラルネットワーク)を用いた時系列データの異常検知モデルが注目を集めています[20]。ところが、学術界で成功を収めているにもかかわらず、これらのモデルの実応用がさほど進んでいませんでした。その理由を、Microsoft は次の 3 点に集約しました。
- モデルとハイパーパラメータの選択: 時系列データの性質によって適するモデルが異なるため、監視対象のワークロードにあわせて最適なモデルを選択する必要があります。また、モデルのハイパーパラメータを決定する必要もあります。メトリック数が多い場合、人力による選択は非現実的です。
- 異常値の解釈: 一瞬のメトリックのゆらぎでも障害と判断されるものもあれば、そうでないものもあります。実用的な障害検知を行うには、サービス観点で "異常" とみなす波形パターンを特定して管理する仕組みが必要ですが、既存のモデルでは通常そのような解釈性は得られません。
- 概念ドリフトへの対応: モデルはデータ形質の変化とともに常に更新していく必要があります。しかし、モデルを再学習できるのは限られたエンジニア(例: データサイエンティスト)のみで、サービス チーム側でフィードバックを与えることが出来ません。
そこで、これらの課題を克服した実用的なメトリックベースの障害検知(アラート)システム「MonitorAssistant」が導入されました[21]。

MonitorAssistant のアーキテクチャ(図は論文より抜粋)
MonitorAssist は、あらかじめ機械学習モデルをカタログのように登録しておくと、メトリック(時系列データ)に最適なモデルを提案してくれます。また、モデルの解釈性を高めるため、異常のカテゴリ(例: 瞬間的な値の急増)を分類する機能も備えています。さらに、フィードバックをチャットボット(LLM)で受け付けることもできます。これにより、検知の誤作動や漏れなどが発生した際、サービスチーム自らがモデルの調整を行うことが可能です。
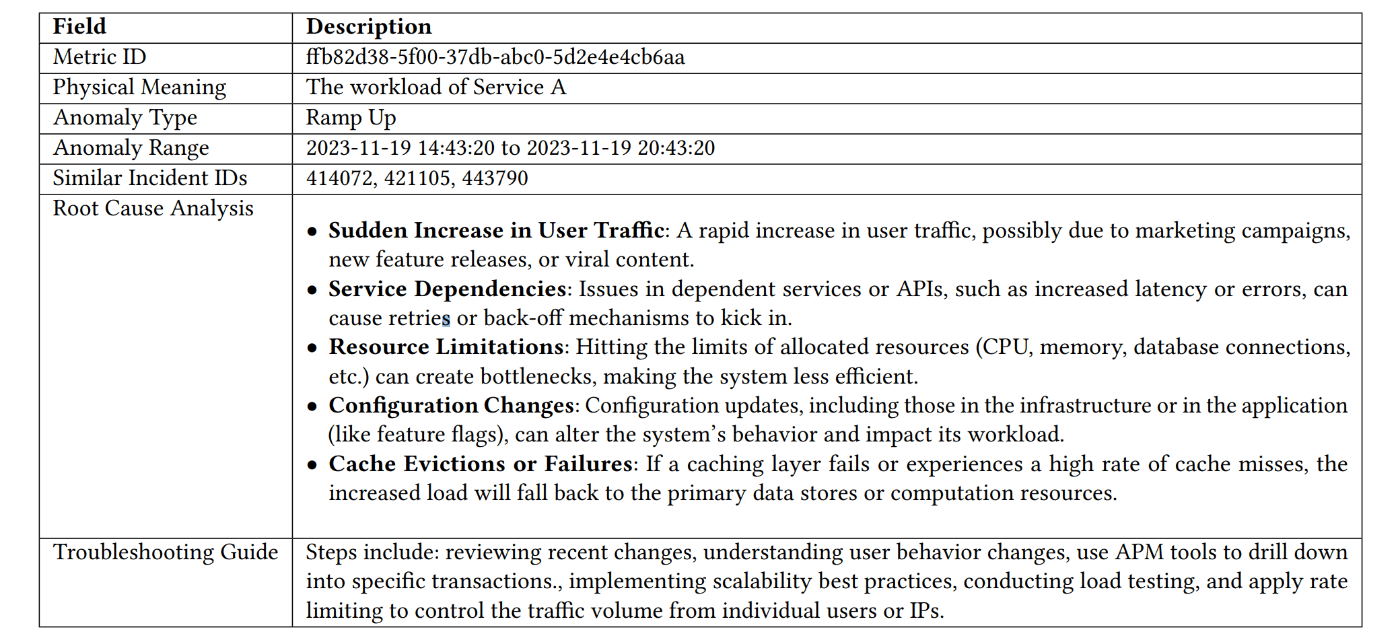
MonitorAssistant が生成するレポートの例(図は論文より抜粋)
多次元データの属性を活用した異常検知
メトリックを活用する上で、観測値に付与されている属性(次元[22])の利用方法は重要です。属性のフィルタリング次第で、見えてくるものが変わるからです。
たとえば、世界中のサーバーからインシデント報告が集まる管理システムを考えます。この報告書にはサーバー名、データセンター名、顧客、国といった様々な属性が付与されて、システムでは報告書の数を時系列データとして管理していました。ここで、インドのデータセンターに展開されている、ある顧客(教育関係)向けのサービスがダウンしたとします。

この時、上図のような属性でフィルターをかけて時系列データを確認すれば、明らかなインシデントの増加が見られるはずです。しかし、属性のフィルターをかけずに同じ時系列データをみても、世界中から送られるインシデントに "ならされて" しまい、異変の特定は困難になります。
このように、多変量データ(多次元データ)の異常検知では、フィルタリングに有効な属性セットを探索することが重要です。通常、この作業は人間の手によって反復的(探索的)に実施されますが、属性数が多くなると組み合わせ爆発によって手に負えなくなります。
そこで、Microsoft は「属性の組み合わせをノードとする木構造上の探索問題」として有効属性の探索を捉え、最適な属性セットを提案するシステム「iDice」を開発しました[23]。さらに、2020 年には、メタヒューリスティックで探索空間を効率的に探索する新たな手法 (MID) にも取り組みます[24]。これらの成果は、AiDice として Azure で活用されることになりました[25]。
目的が少し異なりますが、似たような手法として 2021 年の「HALO」があります[26]。HALO は、サーバーに紐づく多次元メトリック(例: API コールの失敗カウント)を対象に、同じように異変(障害)が起きている属性の集合を獲得する手法です。サーバーの物理的な配置(トポロジカルな情報)を考慮して、特徴量を設計している点が特徴的です。HALO は Azure の Safe Deployment を管理するシステム (Gandalf) にも導入されています。
影響範囲が広いインシデントへの対応
インシデントの中でも、複数のサービスや顧客環境に影響が及ぶ重大なインシデントをアウテージ(outage)と呼びます。日本語だと、大規模障害のようなニュアンスを持つ言葉です。アウテージは、高い優先度で対応が行われ、迅速な解決が求められます。
アウテージ対応は、まず特定することから始まります。もちろん、複数のユーザーから類似の報告が上がってきたらアウテージの発生を疑うことも出来ますが、その時点でかなりの時間が経過してしまっています。ユーザー報告を待たずして、システマチックに検知が出来ることを目指します。
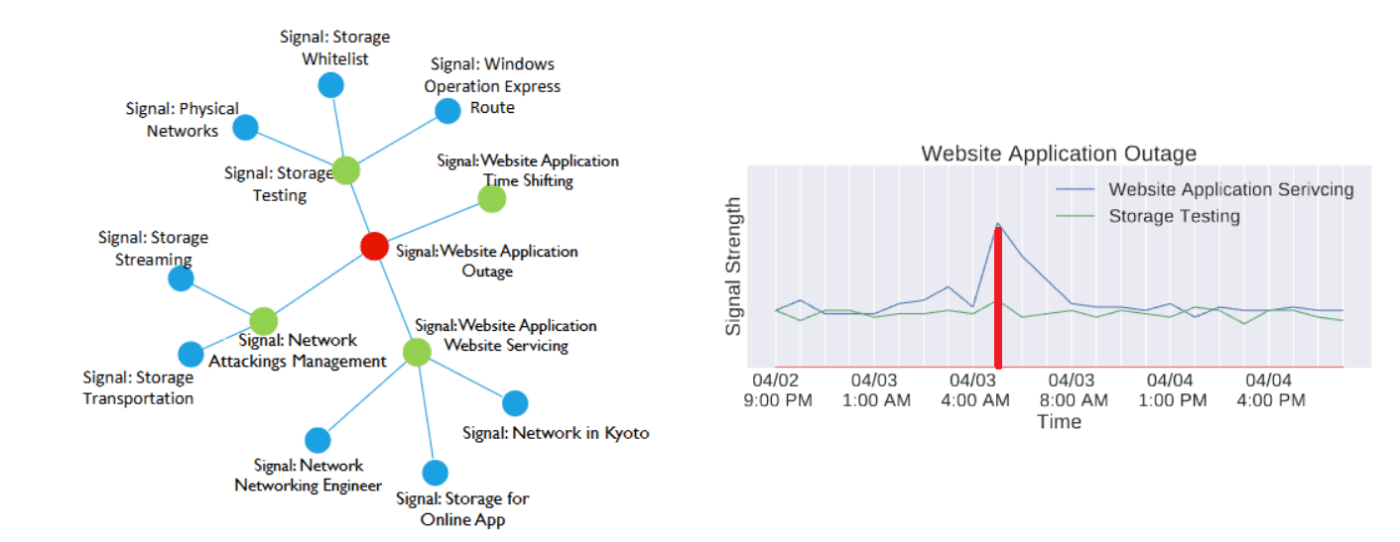
左図: AirAlert により構築されたベイジアンネットワーク. 右図: 最も関係があるとされるメトリックのプロットと予測されたアウテージ
そこで Microsoft がまず取り組んだのは、ベイジアンネットワークを活用したアウテージの検出手法「AirAlert」です[27]。アウテージに関係するシグナル(コンポーネント単位のアラート)同士は連動するという経験則に基づいて、シグナル同士の依存関係を有向非巡回グラフに落とし込みます。するとアウテージに最も関係するシグナルの集合が得られるので、これを使ってアウテージの発生(発生時刻)を推測できます。
また、シグナル選定 → 推論という段階的な手続きを踏襲しつつ、精度向上を目指して新たな検出手法「Warden」も導入されました[28]。AirAlert では、各コンポーネントで発生したアラート数で相関を見ていたのに対し、Warden はオンコールエンジニアの対応状況なども加味して大幅な性能向上を達成します。
AirAlert や Warden のようなシステムでアウテージが特定された後は、エンジニアが調査するフェーズに移行しますが、ここでも Microsoft は調査を補助するツールを導入しました。それが 2023 年に発表された「Oasis」です[29]。
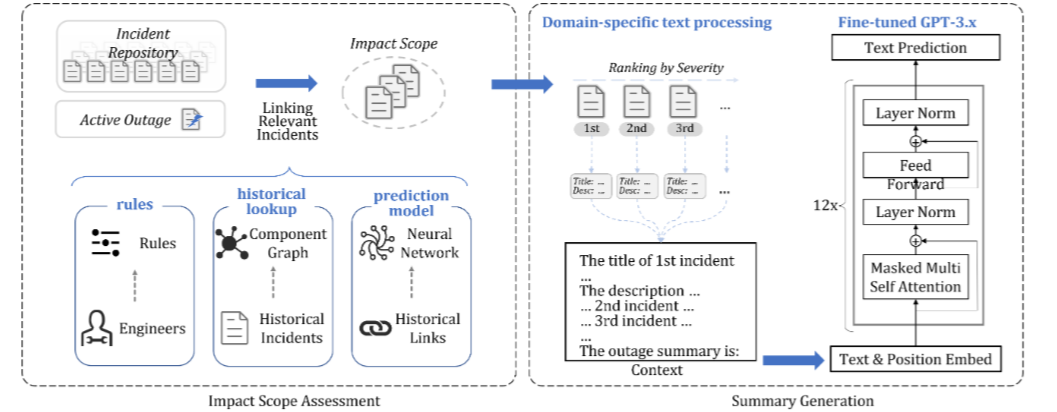
Oasis がアウテージをスコーピングして要約を生成する流れ
Oasis は、アウテージに該当するインシデントの抽出(インシデント関連付け)によって影響範囲を特定し、さらに LLM でアウテージの要約を生成するシステムです。インシデントの関連付けは AirAlert や Warden でも可能ですが、より精度を高めるために 3 つの異なる方法を総合的に活用しています。
- ルールによる関連付け: エンジニアのドメイン知識を活用
- コンポーネント依存関係による関連付け: 過去のアウテージで関連付けられたコンポーネント同士には、サービスやトポロジー的な依存関係があることを活用
- 機械学習モデルによる関連付け: LiDAR[30] や LinkCM[31] のような、インシデントの関連付けを目的とした機械学習モデルを活用
最後に、Oasis で生成された要約のサンプルを紹介します。アウテージの内容、影響しているサービス、重大さを手軽に把握するのに十分な情報量だと思います。
Outage Summary by Oasis: The API failed with HTTP 5xx errors (over 𝛼_1 fall failures) because of bad gateway errors to the endpoint_1. Due to this issue, commercial customers could not sign-up for System-Cloud or SystemProductivity via endpoint_2 or endpoint_3, and perform management related actions on endpoint_4. Additionally, System-Cloud users were not able to access their billing accounts and invoices on System-Cloud portal. Approximately 𝛼_2 unique users were impacted.
(筆者翻訳)
オアシスによる障害概要 : 当該 API は、エンドポイント1へのバッドゲートウェイエラーが原因で HTTP 5xx エラー(X個以上の障害)を起こしました。この問題により、商用顧客はエンドポイント2またはエンドポイント3を通じてシステム A やシステム B にサインアップできず、エンドポイント4での管理関連の操作ができませんでした。また、システム A ユーザーは、システム B ポータルで自分の請求アカウントや請求書にアクセスできませんでした。約Y人のユニークユーザーに影響がありました。
トリアージの効率化
Azure のインシデント トリアージの歴史を振り返ると、Azure の誕生前のオンラインサービス(例: Office 365、Skype)にさかのぼります。
その当時は、インシデントが作成されると、システムが複数のオンコールエンジニアに架電する仕組みになっていました。エンジニアが完全にマニュアルで優先度の判断や対応チームの割り当てを実施していたのです[32]。この方法ではエンジニアの工数も多く消費するため、自動トリアージのシステムが求められました。
まず試みられたのは、ソフトウェアのバグ報告を Software Engineer に自動アサインする既存手法の転用です[32:1]。結果、ある程度の応用可能性は認められたものの、バグ報告とオンラインサービスのインシデントは多くの側面で異なるため、オンラインサービスに適した手法が必要だと結論づけられました。以後、以下のような手法が試されてきました。
- 2019 年: 継続的なインシデント トリアージ システム「DeepCT」が提案されました[33]。インシデントの割り当て(再割り当て)が調査進展につれて複数回発生し得ることを考慮して、DeepCT はエンジニアのディスカッションから知識を学習し、トリアージ結果を逐次更新します。
- 2020 年: DeepCT を改善したシステム「DeepTriage」を本番環境に導入しました[34]。ニューラルネットワークに頼っていた DeepCT に対して、DeepTriage は LightGBM[35] を始めとする複数モデルのアンサンブルによって精度を高めています。
- 2020 年: 本来対応する必要のないアラート(偽検知)を見分けて、優先度を調整する手法「DeepIP」が提案されました[36]。この研究では、実際に 30% 異常が偽検知に相当していることを予備研究で明らかにした上で、ディープラーニング基づく優先度振り分けを実現しています。
- 2021 年: インシデント緩和に要する時間(TTM)を予測することで、適切な人員配置などを可能にする予測手法「TTMPred」が提案されました[37]。テキスト情報とエンジニアのディスカッションの推移をとらえるために、再帰型ニューラルネットワーク(RNN)が使用されました。
そして、最新の取り組みとして、2024 年に LLM を活用した新たなインシデント トリアージ システム「COMET」が提案されます[38]。
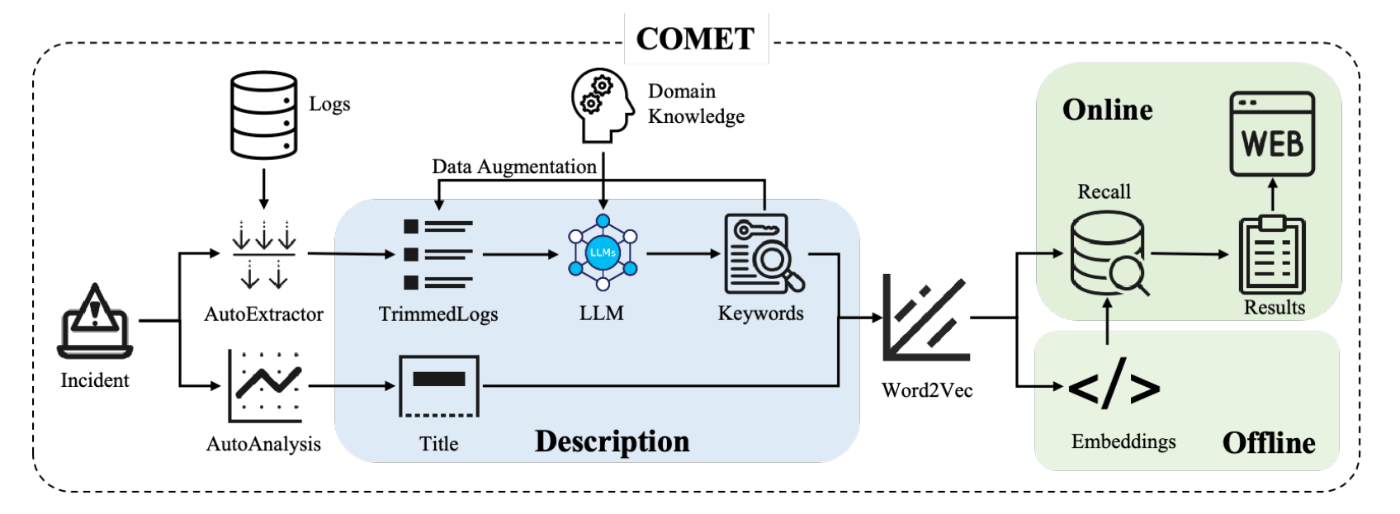
COMET のアーキテクチャ(図は論文から抜粋)
COMET の特徴一つは、ログを上手く取り扱ってトリアージを実行することです。インシデントが発生したコンポーネントのログにはトリアージに必要な情報が含まれていますが、それを機械学習モデルで取り扱うには、ログ特有の問題に対処する必要があります。例えば、冗長なログのトリミング、重要なキーワードの抽出、データ不均衡などです。COMET では、これを LLM (とプロンプトエンジニアリング) を活用することでクリアしています。
また、インシデントのトリアージと共に、分析結果をレポートする機能も有します。実際のインシデント管理システムでは、次のような形で COMET による分析結果が提示されます。
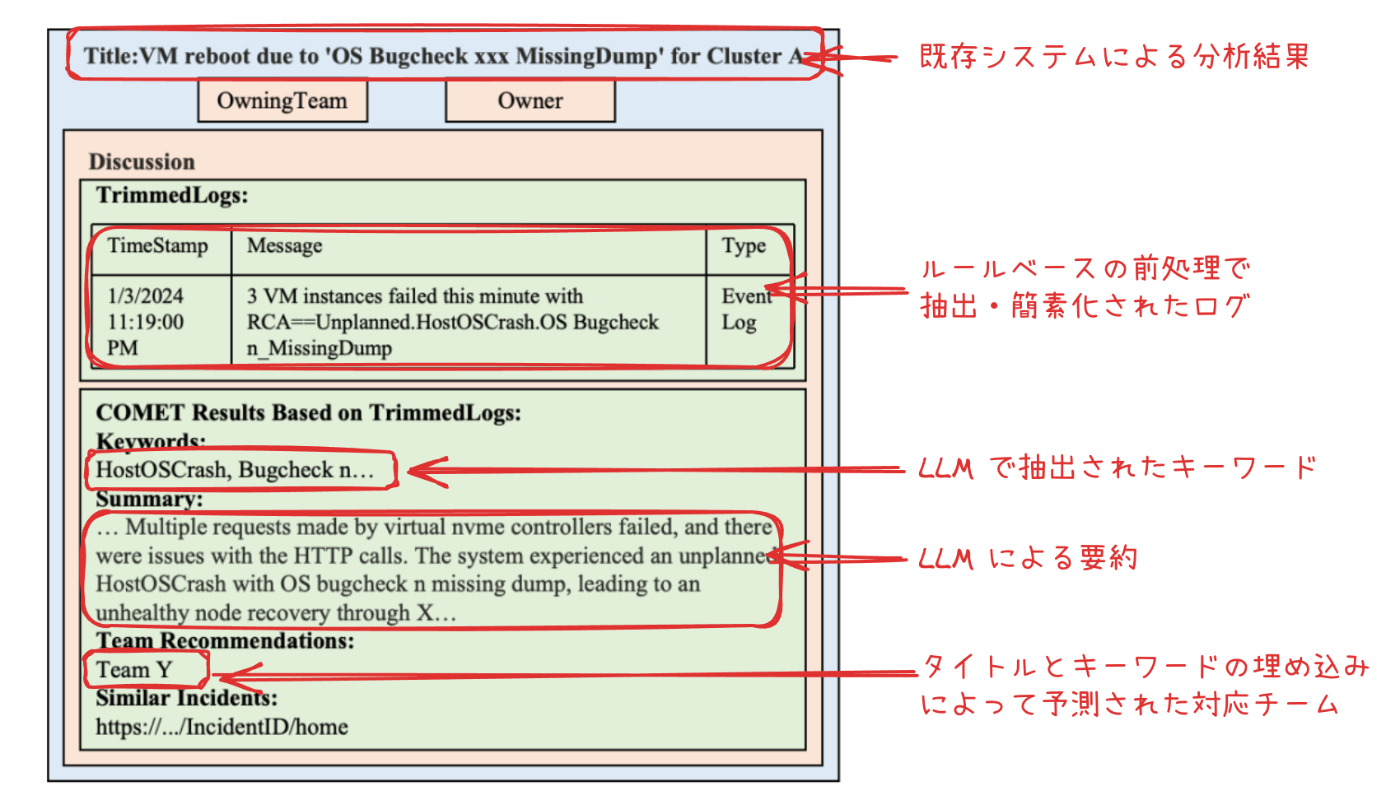
オンコールエンジニアに提示される情報
この報告書は、COMET が単なるトリアージ システムに留まらず、重要なインサイトを提供する能力を備えていることをよく表しています。性能評価でも、トリアージ精度が 30% 向上しただけでなく、TTM (Time-To-Mitigate) が最大 35% 削減できたことが示されています。COMET は、現在、仮想マシンを提供する内部サービスで実運用されています。
類似インシデントの関連付け
類似するインシデントの特定(関連付け)は、インシデント対応の様々な場面で有益です。例えば以下のような理由です。
- サービス同士の依存関係により、インシデントは連鎖的に、コンポーネントを超えて発生することがあります[39]。
- 同じ事象に対して、複数のアラートが発砲されたり、複数の顧客から報告が上がることがあります。
- 関連する過去のインシデントは、調査で重要なヒントを与えてくれます。
Microsoft では、様々なインシデント関連付け手法を考案、導入してきました。
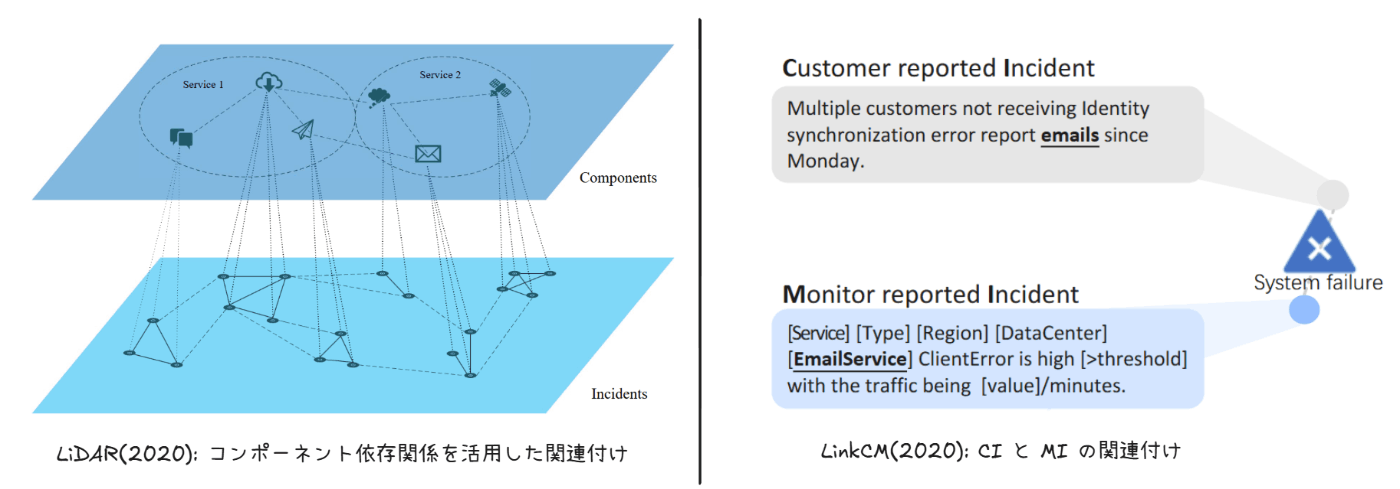
まず、2020 年に、ソフトウェアのバグレポート重複を発見する手法に着想を得た、オンラインサービスのインシデント関連付けシステム「LiDAR」を発表しています[30:1]。LiDAR はインシデントのテキスト情報とコンポーネント依存関係の両方を考慮できることが特徴的です。どちらの情報もニューラルネットワークベースの手法で特徴を抽出し、インシデント間の類似度を計算します。
同年には、顧客報告のインシデント(CI)と監視システムによって自動起票されたインシデント(MI)の関連付けを行う手法「LinkCM」を提案しています[31:1]。というのも、77% の CI では、それに対応する MI が事前に起票されているのにも関わらず、調査の初期段階で正しく関連付けられたケースが約 2 割しか無かったためです。LinkCM では、自然言語で書かれた CI の説明文を解釈して、ディープラーニングベースの手法で MI と紐づけます。
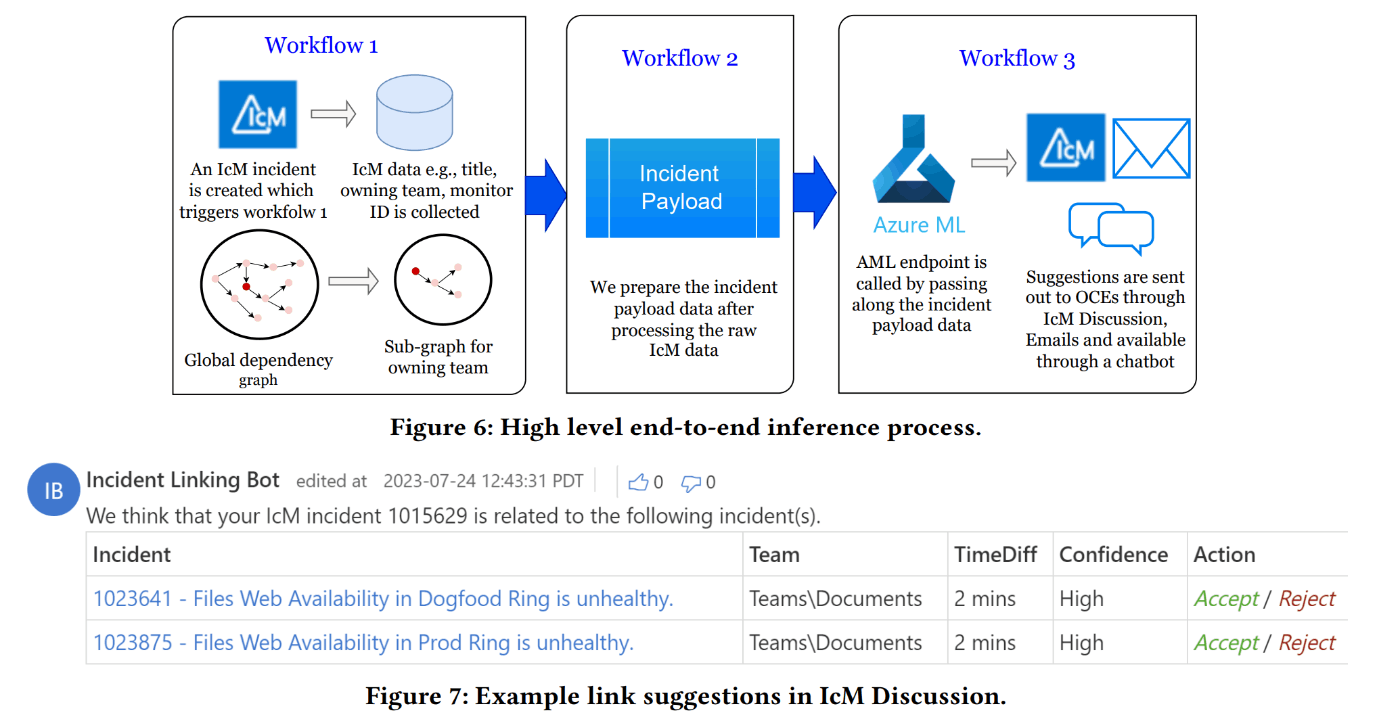
そして、2024 年には、LiDAR を進化させたインシデント関連付けシステム「DiLink」が提案されています[30:2]。LiDAR と DiLink はどちらも、テキスト情報とコンポーネント間の依存関係を特徴量に活用する手法を採用していますが、既存手法の LiDAR では2つの特徴量を個別のモデルで学習していました。DiLink では、テキスト情報と依存グラフ情報を単一のニューラルネットワークで取りあつかうことで、より精度の高い、マルチモーダルなインシデント関連付けを実現します。
KQL クエリの自動生成
Microsoft の監視システムでは、Kusto Query Language (KQL) と呼ばれるドメイン固有言語 (DSL) を使って、クエリを発行する機会が多いです。
しかし、KQL を使った調査は簡単なタスクではありません。KQL のシンタックスを学習[40]したり、検索対象のデータスキーマに精通する必要があるためです。トラブルシューティングガイドがあっても、更新されず腐ってしまっていたり、そもそも未知の事象では役に立つとは限らないです。オンコール エンジニアが KQL クエリを書く場面は、想像以上に多く存在します。
そこで、KQL クエリを自動生成するシステム「Xpert」が開発されました[41]。インシデント管理システムに組み込まれた Xpert は、インシデントが登録されると自動的に類似インシデントの情報を収集し、過去対応時のクエリを基に新たな KQL クエリを生成します。生成には、LLM のコンテキスト内学習(Few-shot Learning)が活用されています。
また、生成される KQL クエリは、「Xcore」と呼ばれる独自指標を最大化するように設計されています。Xcore は、任意の DSL に対して適用できるクエリ(コード)品質の評価指標です。構文・意味論的な正確さ、トークンとオペレーションの正確さ、調査に必要な情報の網羅性といった複数の観点で、クエリの良さを評価します。

Xpert のアーキテクチャ(図は論文から抜粋)
Xpert は一般的な RAG に近いアーキテクチャを採用していますが、事後検証のプロセスがある点が特徴です。事後処理では、LLM の生成結果が KQL のシンタックスに従っていることを構文解析によって確認します。もし不完全なクエリが生成された場合は、再度 LLM に問い合わせることで修正が試みられます。また、インシデント情報や過去のクエリを溜め込むデータベースは逐次更新されるため、時間経過により精度向上が期待できるほか、データドリフトの問題にも対応できます。
トラブルシューティングの自動化
Microsoft のハイブリッド クラウド製品のあるチームは、トラブル シューティング ガイド (TSG) に関する課題を抱えていました。それは、TSG の文章が長いことです(中央値 815 語、最大 5000 語!)。
TSG の自動化も検討されていましたが、自動化コードやスクリプトは TSG の更新のたびにメンテナンスが必要です。このチームでは、平均して 19 日毎という高い頻度で TSG が更新されるため、中々自動化に踏み切れずにいました。
そこで、TSG を LLM で解釈し、実行するためのシステム「LLexus」が開発されました[42]。LLexus は、自然言語で書かれた TSG をマシンコードにコンパイラするような働きをします。

LLexus のアーキテクチャ(図は論文から抜粋)
LLexus の興味深い点は、Planner と Executor がそれぞれ独立している点です。Planner が TSG の更新を検知すると、Executor で実行可能なプランに変換します。この際の自然言語の解釈には LLM が使用され、精度向上のテクニックとして Chain of Thought が導入されています。そして、インシデントが発生し当該の TSG が適合する場合、Executor によってプランが実行されます(その後は、緩和措置が採られて実行が終了するか、エンジニアへエスカレーションされる)。
この分離の仕組みは、プランへの変換が高コストかつ不安定であるという事実をうまく活かしています。つまり、インシデントごとに毎回 LLM を使用する実行モデルと比べると、LLM の呼び出し回数を大きく削減することができます。さらに、LLM の出力は信頼性に欠けるため、実用的には何らかの形で Human-in-the-Loop を確立する必要があります。LLexus では、TSG が更新された際にプランを作成し、エンジニアに即時フィードバックすることでこの課題に対応します。また、プラニングに成功しない TSG の作成が制限される副産物として、理解しづらい不完全な TSG が減少することから、エンジニアにとってもメリットがもたらされます。
AI エージェントによる根本原因分析
緩和策の考案と根本原因分析は、全く難易度が異なるタスクです。例えば、仮想マシンをホストするノードに異常が発生した時、緩和策の一つは仮想マシンの再デプロイです。異なるノードにデプロイされれば、復旧できるためです。しかし、根本原因の分析はノードのログを調べ、ソフトウェアのロジックを調査する作業が含まれます。時には、根本原因が全く別のコンポーネントにあることもあります。
ある Microsoft のメール配信サービスチームでは、毎日 1,500 億通のメッセージを配信しており、度々発生するインシデントの根本原因分析のフローを最適化する必要がありました。効率化のため、サービスで1年のうちに発生した全インシデントを分析した結果、次の洞察が得られました。
- 洞察1: 単一のデータソースでは根本原因にまでたどり着くことは難しい。
- 洞察2: 同じあるいは類似の根本原因から派生するインシデントは、時間的な相関がある(再発するなら短期間のうちに再発する)。
- 洞察3: 新しい根本原因から派生するインシデントの数は多く、インシデントの約 25% が未知の事象である。
特に、洞察3が重要で、25% のインシデントでは既存のトラブルシューティングガイド (TSG) があまり有効でないことを意味します。
そこで、根本原因分析を AI でアシストするシステム「RCACopilot」が開発されました[43]。名前に Copilot が入ってるからには、処理のほとんどは LLM に投げて終わりかな?と思いきや、実態はかなりしっかり作り込まれたオートメーション システムで、LLM は最後に少し登場する程度です。
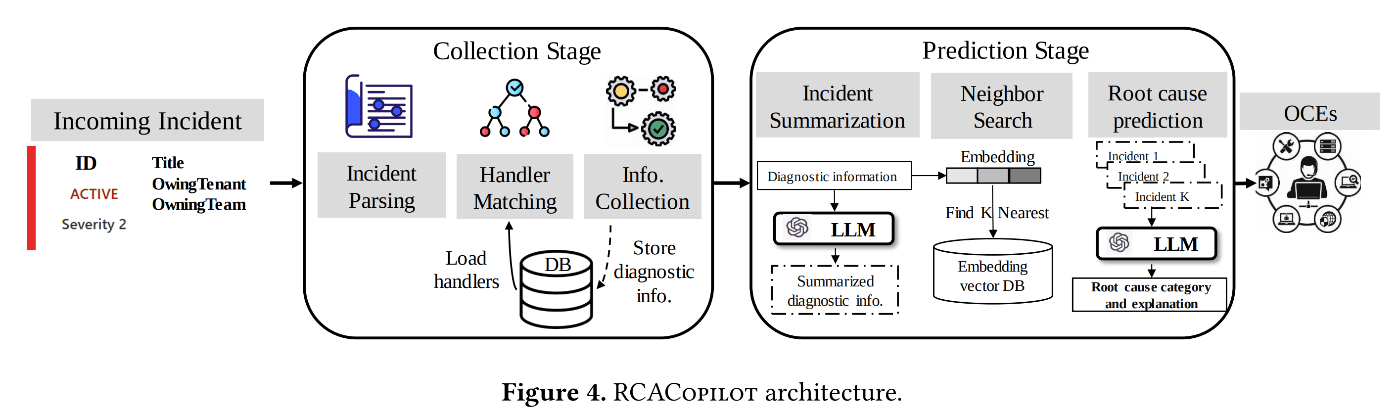
RCACopilot のアーキテクチャ(図は論文から抜粋)
- RCACopilot がインシデントを認識すると、まずは情報収集ステージを開始します。ここでは、洞察1に習い、なるべく多くのデータソースから情報を取得します。前もって有向非巡回グラフのようなロジックフローを登録しておき、そのフローに従って取得されます(例: このログを取ってから、次はこのコマンドを実行して、さらに条件分岐して…)。フローはいつでもエンジニアが修正可能です。
- 情報収集が終わると、根本原因予測のステージに移行します。このステージでは、似ている数個の過去インシデントを検索します。インシデント間の類似度を計算するため、FastText を使って得た埋め込み表現と、インシデントの発生間隔が使用されます(洞察2に基づく考慮)。
- ここで、ようやく LLM の登場です。過去インシデントについては根本原因がわかっているため、これらの情報をプロンプトで LLM に渡しながら「当該事象のログと、類似事象のログ・根本原因を提示します。当該事象がどの根本原因に相当するか、または何れにも当てはまらないか、理由と共に教えてください」と質問します。そうして得られた回答が、最終的な根本原因分析として出力されます。
特にファインチューニングをしていない事前学習済みの LLM であっても有効性があるようで、単に FastText で埋め込みをして最近傍を得る方法よりかなり精度が改善されることが示されています。これは、個人的に面白い LLM の使い方だなと感じました。
RCACopilot は、2024 年の時点で、30 を超えるサービスチームで 4 年以上運用されているようです。また、情報収集フローの定義は比較的面倒くさい作業であるにも関わらず、現場のオンコールエンジニア (OCE) からアンケートで「RCACopilot に満足」の評価が多く得られている理由として、情報収集ロジックを保存したり、再利用すできることが挙げられていました。
ログやトレースの有効活用
最後に、ログの有効活用についてのアプローチを紹介します。AIOps でログを取り扱う際は、次のような課題に対処する必要があります。
- データ量が多い: 監視システムが生成するログの量は、1日あたり何百 TB にも登ることがあります。インシデント対応にニアリアルタイムでログを活用するためには、インジェストと同じスループットを持つデータ処理アルゴリズムとパイプライン基盤が必要です。
- ログのパースが難しい: ログのパースとは、ログメッセージを、ログ生成に使用したテンプレートとパラメータに分解することです。簡単に言えば、メッセージを出力したコードを予測することと同義です。ログのパースには、適切なログクラスタリングの手法を必要とします。
- データの偏りが激しい: 障害予測モデルの学習データは、「正常」時と「異常」時のデータをバランスよく含む必要があります。しかし、実際には異常データは極端に少ないため、このアンバランスさを解消するための工夫(例: サンプリング)が不可欠です。
データ量を削減するという観点では、2015 年に発表された Log2 が興味深いです[44]。Log2 では、ある処理の実行時間を図るための API (Begin と End) をライブラリで提供します。この API で時間を計測すると、過去の計測結果から見て逸脱したものだと判断された場合にのみ、データが記録されるようになっています。そもそもデータを記録しないようにするというアプローチです。
また、2016 年には、ログのクラスター化(クラスタリング)に基づいて類似インシデントの検索を実現する手法「LogCluster」が発表されました[45]。膨大な数のログ シーケンスが与えられた場合でも、実際は限定された数のクラスターから抽出されていると仮定すれば、ログをクラスターの代表値に集約できます。LogCluster は、このようにしてログを効率的に扱う仕組みを実現しました。
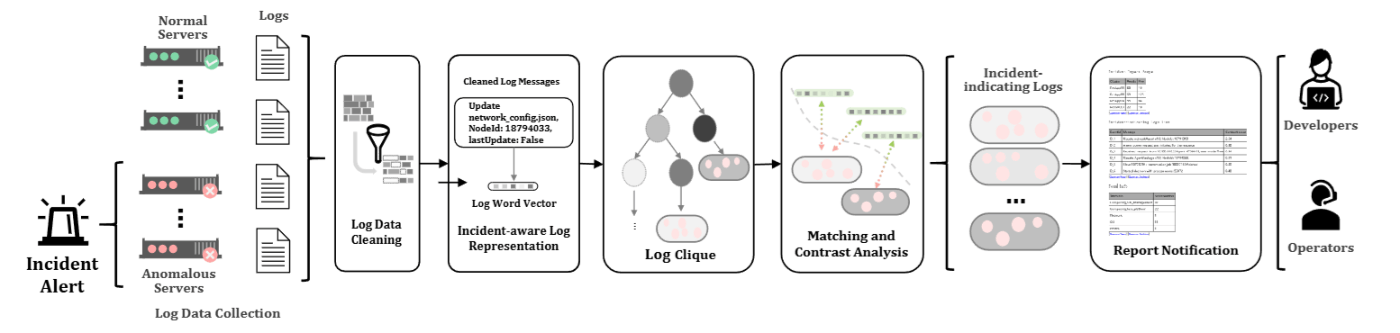
Onion (2021) のアーキテクチャ
このログをクラスター化するというアイディアは、他の手法でも多々見られます。たとえば、2018 年の Log3C[46] や 2021 年の Onion[47] では、ログのクラスター(クリーク)を抽出した後に、相関分析や対称分析などの手法を適用して、障害検知や障害に関係のあるログデータの抽出を実現しています。
また、2022 年には、ログ パーシングに関連する二つの手法が提案されています。
- UniParser: ディープニューラルネットワークを使ったログパーシング手法です[48]。LSTM を使った Token Encoder でログの埋め込みを学習しながら、さらに似たログと似てないログを使った対照損失を組み合わせます。これにより、各トークンの意味を考慮した埋め込みの獲得と、高速な推論を可能にします。
- SPINE: 分散計算機環境で並列実行することを前提に設計されたログパーシング手法です[49]。ジョブを実行するワーカーに均等な負荷(ログの集合)がいきわたるよう、貪欲法に基づくビンパッキング アルゴリズム「BestFit」を使っています。また、昨今の CI/CD の活用でログの多様化が進んでいることを指摘し、それを考慮したモデルの再学習ループ(フィードバックループ)のデザインもおこなっています。
最後に、ログだけでなくトレースを有効活用した手法も紹介します。トレースとは、複数のコンポーネントに渡って処理されたイベントに対して、流れを後から追跡できるように取られたログです。2021 年の TraceLingo は、そんなトレースがコールツリー(木構造)で表現出来ることを活用し、異常が発生した箇所(スパン)を特定するディープニューラルネットワークのモデルです[50]。
紹介しきれなかったものたち
本番導入されていることが明記されていない、重要度が低い、自分が読み切れてない、などの様々な理由で、本記事で紹介できていないアプローチがまだまだたくさんあります。おそらく一部ではありますが、できるだけ下記に記載したので、もし興味があればチェックしてみてください。
| 発表年 | プロジェクト名 | 説明 |
|---|---|---|
| 2012 | (リンクのみ) | データマイニングの手法によってオンラインサービスのパフォーマンス問題を検出するシステム |
| 2012 | NetPilot | データセンターのネットワーク障害を検知して、安全に自動緩和するシステム |
| 2014 | HMRF | メトリックからパフォーマンス問題を検出する手法 |
| 2017 | CorrOpt | データセンターネットワークのパケット破損を検出する監視システム |
| 2017 | GraphWeaver | Microsoft Defender XDR に実装されているインシデント関連付け手法 |
| 2018 | Panorama | グレー障害や Limplock のような、検出が難しい部分故障やパフォーマンス劣化を検出する監視システム |
| 2019 | ATAD | 学習データが乏しいテレメトリに対する異常検知を実現する、異常検知モデルの転移学習 |
| 2019 | BlameIt | WAN のレイテンシ問題と原因箇所(ISP or WAN)を特定する監視システム |
| 2019 | NetBouncer | データセンターネットワーク内のリンク障害(デバイス障害)を検出する監視システム |
| 2019 | SR-CNN | Azure AI Service の Anomaly Detector に導入された異常検知手法 |
| 2019 | dShark | データセンター ネットワーク内を横断してパケット トレースを取得する診断ツール |
| 2020 | BRAIN | AIOps を中心とするインシデント管理のプラットフォーム |
| 2020 | Decaf | Microsoft 365 の障害トリアージと初期診断を助けるためのシステム |
| 2020 | Gandalf | Azure プラットフォームへの fix や update のデプロイメントで発生する問題を早期発見し、影響の拡大を防ぐ監視システム |
| 2020 | Lumos | 既存の異常検知システムの誤検知を削減し、根本原因の特定を補助するライブラリ |
| 2020 | MTAD-GAT | Azure AI Service の Anomaly Detector に導入された、Graph NN による多変量時系列データの異常検知 |
| 2021 | CARE | Microsoft 365 のサービスで使用されている自動 RCA システム |
| 2022 | MTHC | Microsoft 365 のディスク障害予測システムに使われている、故障原因の分類手法 |
| 2022 | NENYA | データベースに対する予測的緩和と強化学習によるポリシー調整を実現する Microsoft 365 の監視システム |
| 2022 | T-SMOTE | Azure と Microsoft 365 に導入された、遠い未来の障害を早めに予測することを目的とする時系列モデルの学習フレームワーク |
| 2023 | Diffusion+ | Microsoft 365 のディスク障害予測のための欠損データ補完手法 |
| 2023 | EDITS | Azure と Microsoft 365 のサービスに導入された、カリキュラム学習による障害予測モデルの学習方法 |
| 2023 | HRLHF | Microsoft 365 の Exchange サービスに導入された自動 RCA システム |
| 2023 | Hyrax | 部分故障したサーバーを継続稼働させるための fail-in-place パラダイム |
| 2023 | STEAM | グラフ対照学習を使った分散トレースのテールサンプリング手法 |
| 2023 | TraceDiag | Microsoft 365 の Exchange サービスに導入された自動 RCA システム |
| 2023 | iPACK | アラート情報に基づき、同じ障害のサポートチケットを集約する手法 |
| 2024 | AIOpsLab | 障害対応を効率化するエージェント型 AIOps プラットフォームのプロトタイプ実装 |
| 2024 | Automated Root Causing | コンテキスト内学習 (ICL) を活用した LLM による自動 RCA システム |
| 2024 | Early Bird | 遠い未来の障害を早めに予測することを目的とした、時系列モデルの学習フレームワーク |
| 2024 | FCVAE | VAE によるネットワーク障害の検知 |
| 2024 | FLASH | ステップごとに推論を重ねながらトラブルシューティングを実行する、AI エージェント型のインシデント管理システム |
| 2024 | ImDiffusion | Microsoft のメール配信サービス向けの、時系列補完と拡散モデルを用いた多変量時系列データの異常検知システム |
| 2024 | NetVigil | グラフニューラルネットワークの対照学習を使用した、データセンターの東西トラフィックに対する異常検知システム |
| 2024 | ReAct | LLM ベースの AI エージェントによる RCA 診断システムの試作 |
| 2024 | SWARM | 接続品質 (CLP) に基づき、DCN 障害の緩和対策をランク付けするシステム |
参考文献
- Cloud Intelligence/AIOps – Infusing AI into Cloud Computing Systems - Microsoft Research
- Building toward more autonomous and proactive cloud technologies with AI - Microsoft Research
- Automatic post-deployment management of cloud applications - Microsoft Research
- Using AI for tiered cloud platform operation - Microsoft Research
-
Predicting Node Failure in Cloud Service Systems - Microsoft Research ↩︎
-
Can We Trust Auto-Mitigation? Improving Cloud Failure Prediction with Uncertain Positive Learning - Microsoft Research ↩︎
-
Improving Service Availability of Cloud Systems by Predicting Disk Error - Microsoft Research ↩︎
-
NTAM: Neighborhood-Temporal Attention Model for Disk Failure Prediction in Cloud Platforms - Microsoft Research ↩︎
-
Neural Feature Search: A Neural Architecture for Automated Feature Engineering | IEEE Conference Publication | IEEE Xplore ↩︎
-
PULNS: Positive-Unlabeled Learning with Effective Negative Sample Selector | Proceedings of the AAAI Conference on Artificial Intelligence ↩︎
-
Improving Azure Virtual Machine resiliency with predictive ML and live migration | Microsoft Azure Blog ↩︎
-
Narya: Predictive and Adaptive Failure Mitigation to Avert Production Cloud VM Interruptions - Microsoft Research ↩︎
-
Advancing failure prediction and mitigation—introducing Narya | Azure Blog | Microsoft Azure ↩︎
-
F3: Fault Forecasting Framework for Cloud Systems - Microsoft Research ↩︎
-
Inside Azure innovations with Mark Russinovich | BRK290HFS ↩︎
-
Inside Microsoft AI innovation with Mark Russinovich | BRK256 ↩︎
-
Exploring the Inner Workings of Azures Advanced AI Infrastructure Presented by Microsoft ↩︎
-
Accelerating industry-wide innovations in datacenter infrastructure and security | Microsoft Azure Blog ↩︎
-
Microsoft to invest US$2.9 billion in AI and cloud infrastructure in Japan while boosting the nation’s skills, research and cybersecurity - Microsoft Stories Asia ↩︎
-
いわゆる ”デグレ" のことですが、英語の degradation は(ハードウェア故障などの原因で)性能劣化・縮退した状態を指す用語なので、混同しないようにリグレッションを使いたい派です。 ↩︎
-
row-remapping は、Ampere アーキテクチャから導入された NVIDIA GPU メモリ (HBM) の冗長機構で、劣化したメモリセルを予備用のものと置き換えます。参考: https://docs.nvidia.com/deploy/a100-gpu-mem-error-mgmt/index.html#row-remapping ↩︎
-
SuperBench: Improving Cloud AI Infrastructure Reliability with Proactive Validation - Microsoft Research ↩︎
-
Detection Is Better Than Cure: A Cloud Incidents Perspective - Microsoft Research ↩︎
-
[2308.00393] A Survey of Time Series Anomaly Detection Methods in the AIOps Domain ↩︎
-
MonitorAssistant: Simplifying Cloud Service Monitoring via Large Language Models - Microsoft Research ↩︎
-
iDice: Problem Identification for Emerging Issues - Microsoft Research ↩︎
-
Efficient incident identification from multi-dimensional issue reports via meta-heuristic search - Microsoft Research ↩︎
-
Advancing anomaly detection with AIOps—introducing AiDice | Microsoft Azure Blog ↩︎
-
HALO: Hierarchy-aware Fault Localization for Cloud Systems - Microsoft Research ↩︎
-
Outage Prediction and Diagnosis for Cloud Service Systems - Microsoft Research ↩︎
-
Fighting the Fog of War: Automated Incident Detection for Cloud Systems - Microsoft Research ↩︎
-
Assess and Summarize: Improve Outage Understanding with Large Language Models - Microsoft Research ↩︎
-
Identifying linked incidents in large-scale online service systems - Microsoft Research ↩︎ ↩︎ ↩︎
-
Efficient customer incident triage via linking with system incidents | Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering ↩︎ ↩︎
-
An Empirical Investigation of Incident Triage for Online Service Systems - Microsoft Research ↩︎ ↩︎
-
Continuous incident triage for large-scale online service systems | Proceedings of the 34th IEEE/ACM International Conference on Automated Software Engineering ↩︎
-
DeepTriage | Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining ↩︎
-
Welcome to LightGBM’s documentation! — LightGBM 4.5.0 documentation ↩︎
-
How incidental are the incidents? | Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering ↩︎
-
How Long Will it Take to Mitigate this Incident for Online Service Systems? - Microsoft Research ↩︎
-
https://www.microsoft.com/en-us/research/publication/large-language-models-can-provide-accurate-and-interpretable-incident-triage/ ↩︎
-
このような現象を「カスケード故障(cascading failure)」と呼びます。参考: https://en.wikipedia.org/wiki/Cascading_failure ↩︎
-
KQL の書き方を勉強したければ「Kusto 100 本ノック」がおすすめです。参考: https://azure.github.io/fta-kusto100knocks/ja/ ↩︎
-
Xpert: Empowering Incident Management with Query Recommendations via Large Language Models - Microsoft Research ↩︎
-
LLexus: an AI agent system for incident management - Microsoft Research ↩︎
-
Automatic Root Cause Analysis via Large Language Models for Cloud Incidents - Microsoft Research ↩︎
-
Log2: A Cost-Aware Logging Mechanism for Performance Diagnosis - Microsoft Research ↩︎
-
Log Clustering based Problem Identification for Online Service Systems - Microsoft Research ↩︎
-
Identifying Impactful Service System Problems via Log Analysis - Microsoft Research ↩︎
-
Onion: Identifying Incident-indicating Logs for Cloud Systems - Microsoft Research ↩︎
-
UniParser: A Unified Log Parser for Heterogeneous Log Data - Microsoft Research ↩︎
-
SPINE: A Scalable Log Parser with Feedback Guidance - Microsoft Research ↩︎
-
TraceLingo: Trace representation and learning for performance issue diagnosis in cloud services | IEEE Conference Publication | IEEE Xplore ↩︎
Discussion