Azure の運用を支える AIOps #1【イントロ編】
クラウドサービスが成長するとともに、サービスの運用(Ops)チームは多くの負担を負うようになりました。負担を生んでいる要素には、複雑化していく内部システム、高いレベルの信頼性を要求するミッション クリティカルなワークロード、データセンター運用費に対する最適化要請などがあげられます。
これは、Microsoft が抱える課題でもあります。全世界で 60 以上存在する Azure リージョンには、300 を超えるデータセンターと数百万台に及ぶサーバーが展開され、数多のサービスが提供されています。このような規模でサービスを運用していきながら、複雑なシステムに対応し、サービスの信頼性を高め、運用コストを削減することが求められているのです。
このような背景から、Microsoft では人工知能(AI)技術を活用した運用の最適化に取り組んでいます。これは AIOps と呼ばれるアプローチです。AIOps で取り扱う運用タスクは千差万別ですが、多くが次の二つの運用オペレーションに関連するものです。
- インシデント管理: 障害の早期発見、原因個所や解決策を提案することで、サービスの信頼性を向上させる。
- リソース管理: サーバー、ネットワーク、ストレージなどのリソースを効率的に利用し、コストを削減する。
そこで、Microsoft が AIOps を使ってどのようにインシデント管理とリソース管理の課題に取り組んでいるか、ご紹介したいと思います。ですが、記事のボリュームが大きくなってしまった為、今回は AIOps の説明にフォーカスして、次回以降の記事でインシデント管理とリソース管理の具体的な事例を取り扱います。
AIOps とは
改めて、AIOps (Artificial Intelligence for IT Operations) とは、機械学習アルゴリズムを代表とする人工知能の技術を使用して、運用オペレーションを改善するプラクティスを指します。人工知能(Artificial Intelligence; AI)と運用(Operations; Ops)を組み合わせた造語です。
AIOps の目的は、システムの可用性やパフォーマンスを最大化しながら、(金銭的、人的、時間的な)運用コストを最小化することです。この目的を達成するため、AIOps では次のような観点で運用を改善します。
- 自動化された運用: 適切に学習された機械学習モデルは、人間が直感的に理解しやすい単純なルールやポリシーだけでなく、より複雑なパターンを示す事象にも対応できます。また、ヒューマンエラーに起因する問題(障害、作業の遅延など)やナレッジの属人化を減らすこともできます。
- プロアクティブな運用: 機械学習を活用すれば、過去のデータをもとに将来の障害を予測し、事前に対策を講じることができます。これにより、障害の発生を未然に防ぐことができます。
- 解釈しやすい運用: データの可視化や分析にも、数理モデルが活用できます。例えば、マイクロサービス システムのコンポーネント間の振る舞いはグラフで表現でき、グラフ上のアルゴリズムや機械学習モデルによって分析できます。整理されたデータを通じて、運用の状況を把握しやすくし、適切な意思決定が迅速に行えるようになります。
Ops の道のり
AIOps という用語は、2016 年に出版された Gartner のレポートで初めて使用されました[1]。2016 年というと、DeepMind の AlphaGo が世界最強の棋士と知られたイ・セドル氏に勝利した[2]年でもあり、AI 技術、特に深層ニューラルネットワークの有効性が実証され、社会実装が進んでいく転換期にあったといえます。
その一方で、2010 年代後半は DevOps [3]の浸透が(主に欧米企業において)進んだ時代です。以下の図は、Gartner のハイプ・サイクルで DevOps がどのような軌跡を辿ったか表しています[4]。AIOps の概念が誕生した 2016 年には、既に過度な期待の峠を過ぎ、地道に実装を推し進めるフェーズに入っていたと言えるでしょう。
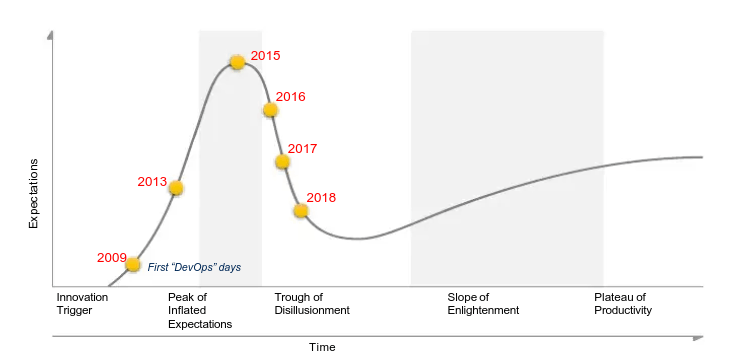
ハイプ・サイクル上の DevOps の遷移 (2009 年 - 2018 年)
また、当時は SRE (Site Reliability Engineering) の注目が高まりつつあった時代でもあります。SRE は、信頼性の高い本番環境システムを実行するためのアプローチやプラクティスで、Google が 2003 年から始めたイニシアチブに発端するものです。たとえば、2014 年には SRE に関する USENIX の国際会議 (SREcon) が初めて開催され[5]、Microsoft も SREcon 2016 から度々発表をしています。
したがって、DevOps や SRE もまた(少なくとも部分的に)運用を改善することを目的としていることを考えると、AIOps はこの延長線上にあると言えます。つまり、DevOps や SRE によって醸造されたオートメーションや継続的フィードバックといった流れを、AI 技術により (スコープ、精度、自動化度合いなどの観点で) 強化するものとして AIOps を捉えることが出来ます。裏を返せば、AIOps は、DevOps や SRE に足りなかったピースを AI 技術で補完するものとも言えます。
この視点から得られる重要な洞察は、AIOps が既存の IT 運用のやり方を全てを刷新する劇的なパラダイムでもなければ、全ての悩みを解決する銀の弾丸でもないということです。DevOps や SRE を基盤にして成り立つものだと考え、段階的に導入を行うことが重要です。
AI x Ops の再発見
もう一つ明確にしておきたい点があります。それは、AI 技術を使った運用の改善は今に始まったことではないという事実です。
これまでにも、エキスパートシステムをはじめとした知識ベースモデルや、さまざまな機械学習モデルに基づいた手法が数多く提案されてきました。たとえば、深層ニューラルネットワーク(DNN)以前に一世を風靡した AI 技術 にサポートベクトルマシン (SVM) がありますが、SVM による障害検出(異常検知)やその応用可能性を調べた研究は 2006 年頃から存在していたようです[6]。
では、過去の取り組みと AIOps の違いは何でしょうか。
ちなみに、概念の再発見というのは普遍的に見られる現象です。たとえば、日本の小学校で習う「国語」もそうです。国語に相当するもの(言語や文化)自体は存在はしていたものの、近代化を目指す明治維新期の指導層が、全国民を統一する(日本という国を象徴する)目的で概念化したのが「国語」であり「日本語」です[7]。「国語」を習う事で、日本人としてのアイデンティティを持ち、国民の結束を強めることができると考えられました。
このように、同じ概念であっても、時代や背景に応じて異なる役割を求められることがあります。AIOps も同様です。過去の取り組みと比べて、AIOps に多く見られる特徴があります。たとえば、次のようなものです。
- 大規模環境/ビッグデータへの適応: 時代とともに IT システムの複雑度は増していくばかりです。そのため、運用自動化の文脈でも、複雑なモデリングが必要な事象を対象としたり、大規模なデータを取り扱ったりすることが多くなりました。Gartner が AIOps を「ビッグデータと機械学習の組み合わせ」と定義している[1:1]ように、この点は過去のものと一線を画すものと言えます。AIOps には、こうした大規模環境における運用改善のニーズに対応することが求められています。
- 深層ニューラル ネットワークの活用: 深層ニューラルネットワーク(DNN)や大規模言語モデル (LLM) の登場によって、人工知能の世界では多くのパラダイムシフトが発生しました。AIOps の名の下で発表されている研究・成果の多くはこうした最新の手法を取り込む傾向があり、よもやすると "DNN/LLM for IT Operations" のほうが名前として相応しいんじゃないかという節すらあります。AIOps には、こうした最新の AI 技術の応用可能性を試験しているという側面も感じられます。
- ユーザビリティの設計: LLM の登場により、機械と人間のコミュニケーション方法に新たなツール(自然言語)が加わりました。そのうえ、ハルシネーションへの対応として Human-in-the-Loop を組み込んだデザインが良いプラクティスとされています。つまり、従来以上にシステムと人間との間のインタラクションが意識されるようになったということです。そのため、AIOps ではヒューマン コンピューター インタラクション(HCI)の要素がシステムデザインの一部として考慮されることが多いです。
Microsoft と AIOps
Microsoft は、学術界と産業界の両面で AIOps 業界をリードする組織の一つで、"AIOps" が誕生する前からも機械学習に基づく運用改善に取り組んでいました。たとえば、次のようなものがあります。
- 2005 年: 単純ベイズ分類器で WEB アプリケーションの障害を検出し、発生個所を特定する手法[8]
- 2010 年: P2P オンライン ストレージ システムの故障を確率的に分類することで、システム全体でのネットワーク スループットを削減する手法[9]
- 2012 年: Windows Error Reporting (WER) のクラッシュレポートに含まれるコールスタックを基に、階層的クラスタリングでクラッシュ種別をジャンル分けする手法[10]
この系譜を受け継ぎ、Azure でもサービスチームと Microsoft Research (MSR) が共同で先進的な取り組みを行い、その結果を学術界で共有しています。個人的に調べられたものだけでも、AI によるクラウドサービスの運用改善に関する MSR の論文は、40 本を超えていました(もっと多いはず)。また掲載されてるジャーナルも ICSE、FSE、ASE、SOSP、OSDI、NSDI と錚々たる顔ぶれです。
Microsoft が自社サービスの中でどのように AIOps を位置づけ、何に対してアプローチしているかは以下の情報が参考になります。
- Cloud Intelligence/AIOps – Infusing AI into Cloud Computing Systems - Microsoft Research
- Advancing Azure service quality with artificial intelligence: AIOps - Azure のブログ - Microsoft Azure
- Research talk: Cloud Intelligence/AIOps – Infusing AI into cloud computing - YouTube
- AIOps: Real-World Challenges and Research Innovations - Microsoft Research
- AIOps - Microsoft Research

Microsoft の AIOps が取り組むシナリオ(Research talk: Cloud Intelligence/AIOps より抜粋)
かいつまんで要約すると、付加価値のあるインテリジェントな(データドリブン/自律的/包括的/予防的な)クラウド サービスを実現するために、AI システムを備えたプラットフォームが不可欠と考え、サービス/DevOps/カスタマーという3つの領域を設定してアプローチしています。
Azure ユーザーの AIOps
この記事の焦点は Azure を運用する側の AIOps なので趣旨とずれますが、Azure をプラットフォームとしてサービスを構築するユーザーも AIOps を体験できるという点を補足しておきます。
たとえば、障害検知の文脈であれば、Azure Monitor に備わるマネージドの AIOps 機能を使うか、基本的な Azure Monitor のサービス(例: Log Analytics ワークスペース)を Azure ML と組み合わせて独自の AIOps パイプラインを構築するという 2 種類の方法が取れます。
マネージドの方法に関しては、動的なしきい値によるアラートや Application Insights のスマート検出が手っ取り早く簡単に試せる機能です。また、最近、仮想マシンの VM watch と呼ばれる機能が Public Preview で登場しました。これは、VM 内の状況をシステムメトリックから適応的に判断して、正常性を判断してくれる監視ツールです。
また、リソース管理の文脈であれば、Azure Advisor のコスト最適化が不要なリソースを推奨してくれます。ただし、現時点では、Advisor が適応的にサブスクリプションの環境を学習して推奨するような感じではなく、ルールベース(Microsoft のドメイン知識がルールとして表現されたエキスパート システム)の推奨に近いものです。AI の定義、イメージ次第では AIOps にジャンル分けさなさそうな感じの微妙なエリアですね。
論文を読んだ感想
最後に、AIOps の文献を読み漁ってみた感想を少しシェアしたいと思います。お題がないととりとめもない小学生の読書感想文みたいになってしまいそうなので、「Microsoft の AIOps に共通する特徴」という点で書き出してみます。
既存の IT 資産が活かされている
AIOps を実現するには、監視システム、観測データの処理パイプライン(データ基盤)、機械学習モデルを学習・推論する基盤、インシデント管理システムなどを整備する必要があります。また、それらシームレスに統合する枠組みも不可欠です。Microsoft は、長年にわたるサービスとデータセンター運用で培った IT 資産を活かして、AIOps の導入をうまく進めている印象を受けます。
予備研究に余念がない
『計測せよ。計測するまで速度調整をしてはいけない(筆者抄訳)』[11]とは有名なパフォーマンス チューニングの格言ですが、おおよそどの分野でも同様のことが言えるのではないでしょうか。AIOps でも、最適化対象を理解した上で、最も効果が高く実行しやすいものから攻めることが重要です。
Microsoft は、この点をよく理解しているように思えます。その証拠に、以下のような実証研究を通して、運用チームが感じている障害を把握することに労力を割いています。
- Characterizing Cloud Computing Hardware Reliability - Microsoft Research
- Understanding Network Failures in Data Centers: Measurement, Analysis, and Implications - Microsoft Research
- Gray Failure: The Achilles' Heel of Cloud-Scale Systems - Microsoft Research
- Resource Central: Understanding and Predicting Workloads for Improved Resource Management in Large Cloud Platforms - Microsoft Research
- What bugs cause production cloud incidents? - Microsoft Research
- An Empirical Investigation of Incident Triage for Online Service Systems - Microsoft Research
- How to Fight Production Incidents? An Empirical Study on a Large-scale Cloud Service - Microsoft Research
- An Empirical Study of Log Analysis at Microsoft - Microsoft Research
- Detection Is Better Than Cure: A Cloud Incidents Perspective - Microsoft Research
- Towards Cloud Efficiency with Large-scale Workload Characterization - Microsoft Research
問題設計が適切
自分が大学生の時、研究指導の先生から教わった印象的な言葉があります。それは、「問題を上手に解くのも偉いけど、問題を作った奴のほうがもっと偉い」というものです(もっと物腰の柔らかい表現をしてたと思います)。問題設計は、解決策の設計に先立つ重要なステップであり、問題の設定が不適切であれば、どんなに優れた技術を使っても解決策は見つからないことがあります。
たとえば、体型を評価する指標の一つに BMI がありますよね。BMI は肥満度との相関関係があり医学的に有益ですが、BMI の数値だけに依存して筋トレを行うボディービルダーは存在しません。体組成(脂肪率や水分含有量)が体重に与える影響を BMI が捉えられないからです。BMI を改善することに専念しても、あの Chris Bumstead[12] にはなれません。もっと違うやり方が必要です。
つまり何が言いたいのかと言うと、改善する指標の設定を間違うと期待した結果は得られないということです。Microsoft はこの点を非常に意識していて、問題のフレーミングや KPI(指標)の設計を丁寧に行っています。
その姿勢を象徴するものの一つに Annual Interruption Rate (AIR) があります。これは、Azure VM の信頼性を高める取り組みの中で生まれた指標で、「100 台の仮想マシンを 1 年間運用した時の平均ダウン回数」で定義されます[13]。
わざわざこの指標を作ったのは、ミッションクリティカルなシステムをホストする Azure の特性が理由です。一般的に普及している MTTF、MTTD、MTTR などの時間ベースの指標では、すぐに復旧される瞬間的な障害の影響が矮小化されてしまい、一瞬のダウンでも影響が大きいアプリケーション(例: 整合性検査等で復旧に時間を要するデータベース)には向きません。
このように、Microsoft は AIOps の取り組みにおいて、問題設計に注意を払い、適切な指標を設定することで、効果的な改善を実現していると感じます。
まとめ
今回は、AIOps とは何ぞやという所にフォーカスして概観をお伝えしました。ギュっとすると、この記事で持ち帰ってもらいたいものはこの2点だけです。
- AIOps は、DevOps や SRE のような既存のアプローチの延長線上にある、AI 技術による運用改善プラクティス
- Microsoft は AIOps の分野で頑張っている
次回以降は、インシデント管理とリソース管理というジャンルで Microsoft / Azure が取り組んでいる具体事例を取り上げます。良ければそちらもご一読いただければ幸いです。
-
Definition of AIOps (Artificial Intelligence for IT Operations) - IT Glossary | Gartner ↩︎ ↩︎
-
Fuqing, Yuan. "Failure diagnostics using support vector machine ↩︎
-
Combining Visualization and Statistical Analysis to Improve Operator Confidence and Efficiency for Failure Detection and Localization - Microsoft Research ↩︎
-
Protector: A Probabilistic Failure Detector for Cost-effective Peer-to-peer Storage - Microsoft Research ↩︎
-
ReBucket - A Method for Clustering Duplicate Crash Reports based on Call Stack Similarity - Microsoft Research ↩︎
-
[1910.12200] Annual Interruption Rate as a KPI, its measurement and comparison ↩︎ ↩︎
Discussion