"the most popular OSS data projects"を眺めてみる(11位〜20位)
この記事なに
"the most popular OSS data projects"を眺めてみる(1位〜10位)の続き。
目次
- dbt
- Apache Airflow
- Apache Superset
- Dagster
- Trino
- Prefect
- Great Expectations
- Apache Spark
- Amundsen
-
Apache Flink
--(ここまで前回のページ)-- - Apache Kafka
- Apache Pinot
- Dask
- Flyte
- Apache Arrow
- Apache Druid
- pandas
- RudderStack
- Ray
- Apache Gobblin
#11 Apache Kafka
公式ページ・SaaS・サポート
概要
分散ストリーミングプラットフォームです。メッセージキューとして紹介されることも多く、その機能がメインなのも(おそらく)事実ですが、Confluent曰く「distributed event streaming platform」とのことです(Kafka StreamやSchema Registryを指している?)。
Kafka has quickly evolved from messaging queue to a full-fledged event streaming platform
日本語資料
英語資料
#12 Apache Pinot
公式ページ・SaaS・サポート
概要
OLAPデータベース。Apache Druidと同じカテゴリ。
クエリ・取り込みを高速にするために、
- 列指向
- テーブルのセグメント分割
- SQLの一部制限(JOINはできません)
- 永続化のためのストレージ(Segment Store)と、クエリ処理のサーバの分離(Realtime Server, Offline Server)(下図のアーキテクチャ)
- 水平スケールしやすい
- star-tree-indexによるpre-aggregation
などの工夫をしています。ユースケースを見ると、高速なレスポンスを活かした、ユーザーが見る画面やBI、異常検知などを想定しているようです。

スクショ
英語資料
- Druidのコミッターの方が書いた比較ブログ
- Uberでのアーキテクチャ
-
Uberでの事例
- レストラン向けのダッシュボード(Restaurant Manager)のバックエンドに使っているらしい
#13 Dask
公式ページ・SaaS・サポート
概要
分散処理フレームワーク。SparkやRayと同じカテゴリで(※)、ドキュメント等を見ると
- Pandas/Numpy/Scikit-Learnっぽいインターフェイス
- Sparkよりもlight-weight
- スケールアウト・ダウンのしやすさ
つまり、扱いやすさを押し出しているように感じます。
※ Daskのドキュメントには[Sparkとの比較](https://docs.dask.org/en/latest/spark.html)もあります
クラスタの構築は、
- CLI
- SSH経由
- Kubernetes
-
YARN
で可能です。
余談ですが、Airflow、Prefect、Dagsterの実行基盤として使うこともできます。
日本語資料
-
Simonritchieさん
- 分量すごい
英語資料
#14 Flyte
公式ページ・SaaS・サポート
概要
ワークフローエンジン。元々Lyft・SpotifyのツールだったのがLF AI&DATAでOSS化。
このランキングでワークフローエンジンは、他に
Airflow(#2)、Dagster(#4)、Prefect(#6)の3つがありますが、それらと比べると、
- Container Native
- Kubernetes前提
- それを活かしたスケール性能の高さ
- Lyftでは月に、10万Execution、100万タスク、1000万コンテナを実行
- 組織全体での利用(Lyftいわく「reproducible, and shareable」)
* マルチテナント、他のタスク・ワークフローの呼び出しの機能
あたりがアピールポイントのようです。
(詳しい情報読み取れませんでした…詳しい人いたら補足お願いします)
スクショ
日本語資料
英語資料
#15 Apache Arrow
公式ページ・SaaS・サポート
概要
大容量・高速なデータ交換を支援するためのプラットフォームで、具体的には、
を提供しています。
日本語資料
#16 Apache Druid
公式ページ・SaaS・サポート
概要
OLAPデータベース。Apache Pinotと同じカテゴリ。
アーキテクチャ(下図)や工夫もPinotと類似しています(詳しい人いたら違いを教えて欲しい…)。
利用ユーザのページ見ると、Pinotより少し豪華な気がします。

日本語資料
英語資料
#17 pandas
みんな知ってそうなので省略
#18 RudderStack
公式ページ・SaaS・サポート
概要
分類が難しいのですが、RudderStack自身は「Customer Data Pipeline」と位置づけている製品です。
公式ページに載っている概念図(下)がわかりやすく、どこかのデータソースから、どこかのデータシンクに、送る途中部分にRudderStackは位置し、ルーティングや加工を行います。

データソースは、
- マーケティング系ツール(Google Analytics等)
- DWH(BigQueryやRedshift)
- SDK(JavaScriptやRuby)
に対応しており、データシンクは、
- マーケティング系ツール(Google AnalyticsやMailchimp、Salesforce)
- キュー(RedisやCloud Pub/Sub、Kinesis)
- DHW(BigQueryやRedshift)
等に対応しています。
(OSSではない)類似した製品に、Segmentがあります(RudderStackのページにも比較があります)。
スクショ
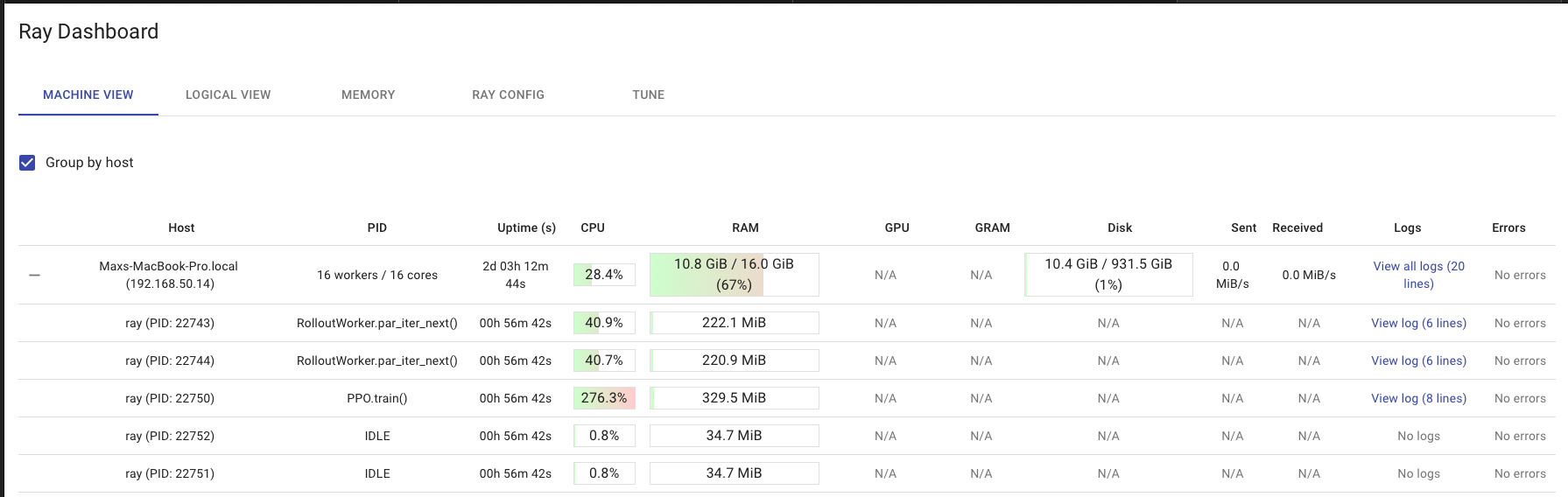
#19 Ray
公式ページ・SaaS・サポート
概要
分散処理フレームワークです。Spark・Daskと同じカテゴリで、
Kubernetes、または、パブリッククラウド(AWS/Azure/GCP)にクラスタを構築することが出来ます。
ライブラリとして、
も提供されています。
スクショ
日本語記事
#20 Apache Gobblin
公式ページ・SaaS・サポート
概要
Hadoopエコシステムへのデータの統合ツール。ETLもありますが(設定ファイルの例)、もう少しスコープが広くて、
なども提供しています。
Discussion