"the most popular OSS data projects"を眺めてみる(1位〜10位)
元記事の話
元記事:https://petesoder.medium.com/what-are-the-most-popular-oss-data-projects-of-2021-84ef021bb5a2
データエンジニア・データサイエンティスト・研究者のイベントData Councilで、500人からアンケート(※)を取った結果の、上位20位のOSSデータ関係のプロジェクトが公開されています(全結果はこちら)。
| 順位 | 製品名 | 投票者 | ユーザー |
|---|---|---|---|
| 1 | dbt | 75 | 51 |
| 2 | Apache Airflow | 68 | 57 |
| 3 | Apache Superset | 55 | 40 |
| 4 | Dagster | 54 | 44 |
| 5 | Trino | 49 | 43 |
| 6 | Prefect | 42 | 34 |
| 7 | Great Expectations | 40 | 23 |
| 8 | Apache Spark | 37 | 29 |
| 9 | Amundsen | 37 | 21 |
| 10 | Apache Flink | 30 | 21 |
| 11 | Apache Kafka | 28 | 19 |
| 12 | Apache Pinot | 26 | 21 |
| 13 | Dask | 25 | 22 |
| 14 | Flyte | 24 | 18 |
| 15 | Apache Arrow | 23 | 20 |
| 16 | Apache Druid | 20 | 20 |
| 17 | pandas | 15 | 11 |
| 18 | RudderStack | 14 | 14 |
| 19 | Ray | 14 | 6 |
| 20 | Apache Gobblin | 13 | 12 |
※具体的なアンケートの質問は不明?
この記事
↑の上位20製品について、簡単に調べてみました。
私がよく知らない製品(Flyteとか)、みんな知っているだろう製品(Sparkとか)は記載薄めです。
なお、私の知識は
- 知っている
- Apache Airflow, Trino, Prefect, Apache Spark, Amundsen, Apache Flink, Apache Kafka,Apache Duid, pandas
- 名前だけ知っている
- dbt, Apache Pinot, Apache SuperSet, Great Expectations, Dask, Apache Arrow, Apache Gobblin
- 知らない
- Dagster, Flyte, RudderStack, Ray
な感じです。
目次
- dbt
- Apache Airflow
- Apache Superset
- Dagster
- Trino
- Prefect
- Great Expectations
- Apache Spark
- Amundsen
-
Apache Flink
--(ここから次回のページ)-- - Apache Kafka
- Apache Pinot
- Dask
- Flyte
- Apache Arrow
- Apache Druid
- pandas
- RudderStack
- Ray
- Apache Gobblin
#1 dbt
公式ページ・SaaS・サポート
概要
ELTのうちのTの部分に特化したツールです。つまり、DWH(BigQueryとか)にあるデータを、SQLで変換するためのツールで、
などをやってくれます。
スクショ

日本語資料
#2 Apache Airflow
公式ページ・SaaS・サポート
概要
ワークフローエンジン。ワークフローエンジンは多々ありますが(このランキングでもPrefectとDagster)
- プラグインの多さ
- 処理に加え、依存関係(DAG)もプログラミング言語(Python)で記載(=複雑な依存も書きやすい)
- SaaS
- プロジェクトの活発・ユーザの多さ(Apache Annual Report)
あたりが特徴だと思っています。
スクショ
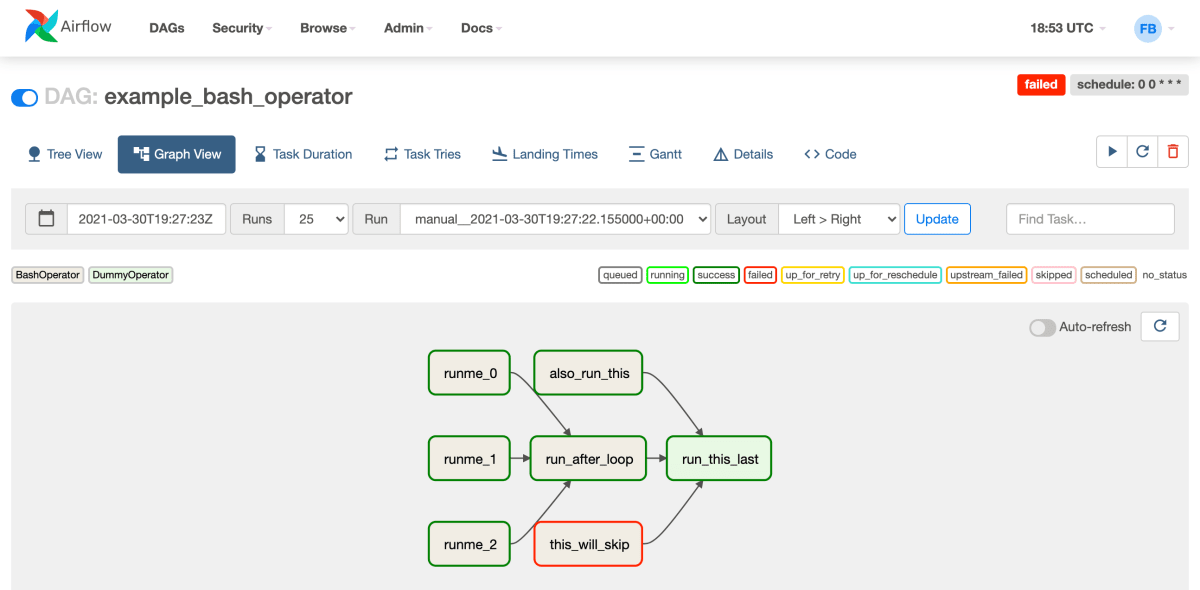
日本語資料
-
ビッグデータを支える技術
- ワークフローエンジンの例として、Airflowが紹介されています
- ちなみに、第二版の方はPrefectが紹介されています
-
Google Cloudではじめる実践データエンジニアリング入門
- Cloud Composerの話が一章あります
英語資料
- Data Pipelines with Apache Airflow
-
The Complete Hands-On Introduction to Apache Airflow
- Udemyに他にいくつかコースあります
#3 Apache Superset
公式ページ・SaaS・サポート
概要
BIツール。
- おしゃれな可視化
-
Exploration
- GUIもしくはSQLでデータ探索
-
Semantic Layer
- 指標を定義する機能
あたりが特徴だと思っています。
スクショ
日本語資料
英語資料
その他
- Apache Airflowとオリジナルの作者が同じです(Maxime Beauchemin)
#4 Dagster
公式ページ・SaaS・サポート
概要
ワークフローエンジン。
- 開発のしやすさ
- (処理でなく)データの依存関係を重視
- AirlfowのTaskFlow的な書き方
- DAGが作成したデータを管理する機構もあります
- 既存のツール・環境への対応
- 実行はSparkやCelery、Dask、Kuberernetesあたり
が特徴かなと思います。AirflowやPrefectと比べると、比較的後発(2019?)ですが綺麗にまとまっていそうです。
スクショ
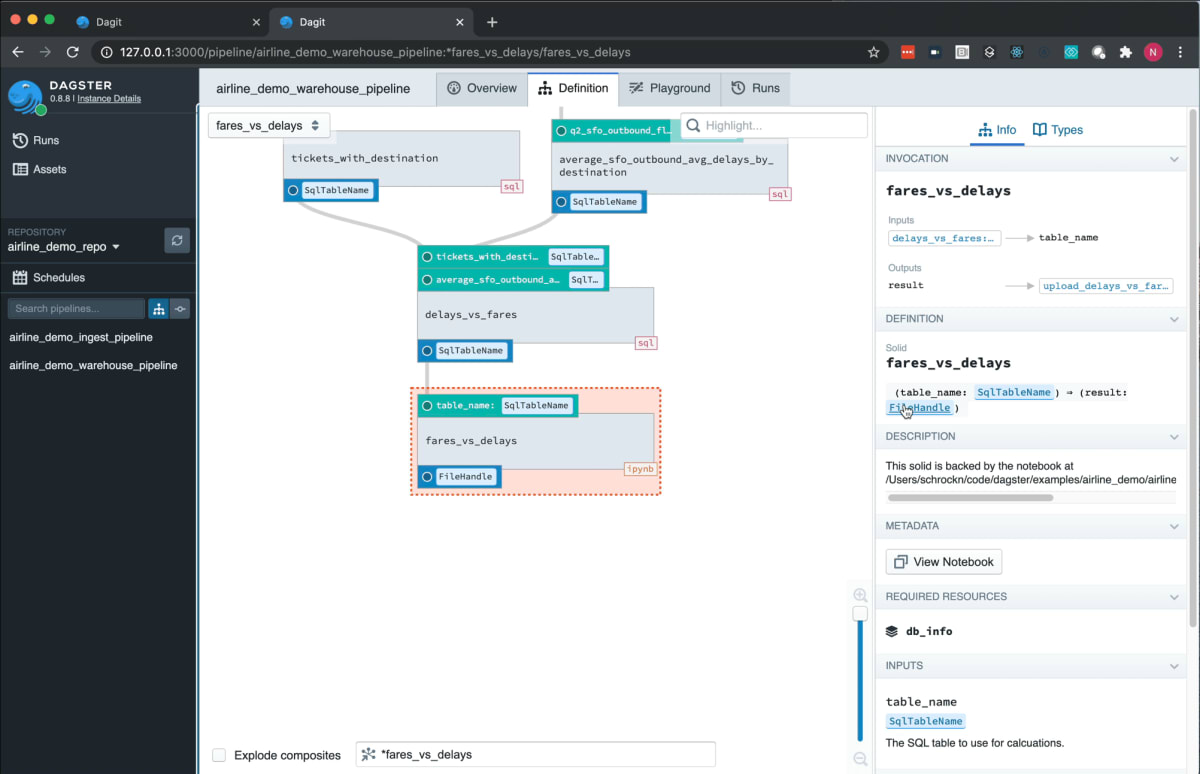
日本語資料
たぶんない
その他
- Founderの人Nick SchrockさんはGraphQLの作者でもあります
#5 Trino
公式ページ・SaaS・サポート
- 公式
- Quoble
- Amazon Athena
- Starburst
-
Treasure Data?
- TrinoのManaged Serviceに記載がないので、ちょっと違う?
概要
クエリエンジン(旧Presto)。
色々なデータソース(DB・オブジェクトストレージ等)からデータを取得し、SQLを実行します。
HDFS・S3(HiveConnector)からデータを取得してる例が多そうですが、
- DWH(BigQuery, Redshift)
- ElasticSearch
- Kafka
- RDB(MySQL, Oracle, PostgreSQL, SQL Server)
などにも対応しています。
英語資料
-
Presto: The Definitive Guide
- 「Presto」とありますがPrestoSQL(Trinoの旧名)の本です
- Starburstの人が著者です
その他
- アンケート結果がPrestoDBを含むかは不明
- Facebook等がコントリビュートしているPrestoフォーク
- PrestoからPrestoSQLにフォークし、そこから改名した
- (経緯のDiscussionがあるが、よくわからない…)
- マスコットのうさぎ(Commander Bun Bun)がカワイイ
#6 Prefect
公式ページ・SaaS・サポート
- 公式
- Prefect Core(OSS部分)
- Prefect Cloud
概要
ワークフローエンジン。基本的な機能(処理・依存をPythonで書く)などはAirflowに似ています。
- タスク間のデータの受け渡し
- スケジューラ
- Airflowだとアーキテクチャ的な制約が(バージョン1系では)あった
- DAGのバージョン管理
- Hybrid Model(データやコードと管理情報を分離)
などの点で、Airflowより優れていると主張しています
(詳しくはWhy Not Airflow)。
スクショ
((Prefect Docs)[https://docs.prefect.io/orchestration/ui/flow-run.html#schematic])より
日本語資料
-
ビッグデータを支える技術
- ワークフローエンジンの例として、Prefectが紹介されています
- ちなみに、第一版の方はAirlfowが紹介されています
- 自分のブログ
その他
- Prefect(会社の方)のCEO(https://www.linkedin.com/in/jlowin)はAirflowの元開発者(PMC Member&Committer)らしい
#7 Great Expectations
公式ページ・SaaS・サポート
概要
データの品質管理ツールです。
具体的には、
などを、DWHやPandasのデータに対して行うことができます。
AirflowやDagsterと連携もできます。
スクショ
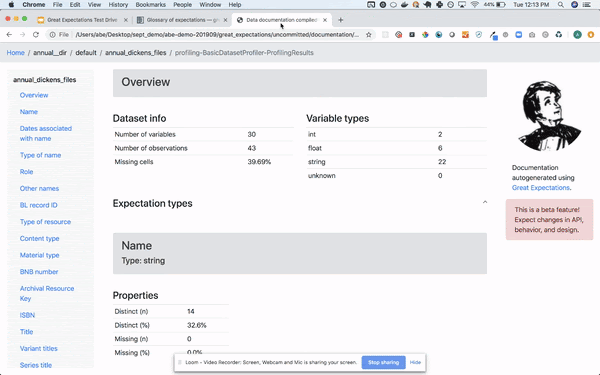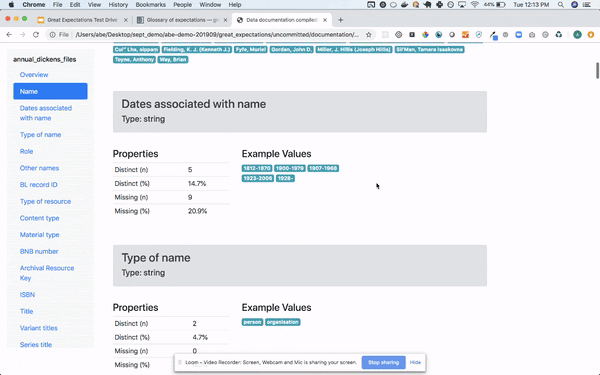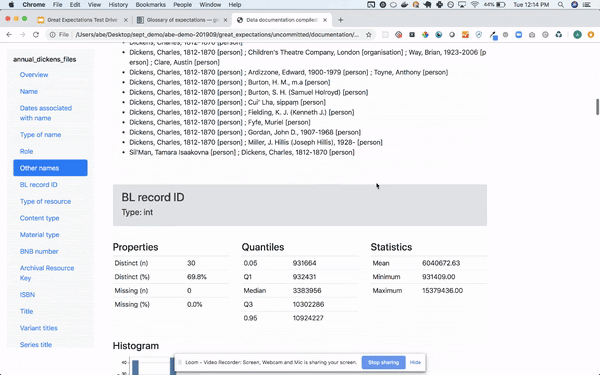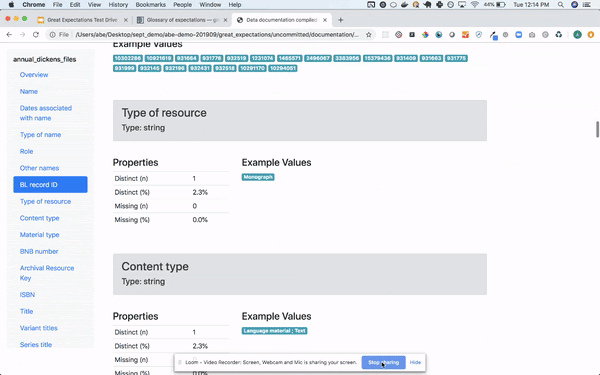
#8 Apache Spark
公式ページ・SaaS・サポート
概要
日本語資料
- アプリケーションエンジニアのためのApache Spark入門
-
増補改訂]ビッグデータを支える技術
- 日本語の本は何冊かありますが、比較的新しい本はこの二冊?
英語資料
- Learning Spark, 2nd Edition
- 英語だとちょくちょく本が出版されています
#9 Amundsen
公式ページ・SaaS・サポート
概要
メタデータ管理ツール。元々Lyftの社内ツールだったのが、Linux FoundationのLF AI&DATAでOSS化。
歴史のあるメタデータ管理ツールApache Atlasに比べると、
- Atlasの方はHadoopエコシステム色が強い
- Amundsenは管理というより、「Discovery」(メタデータの検索のニュアンス?)を押し出している
- Lineageやマスキング・認可などはAtlasの方が強い?
印象があります(なおAmundsenはバックエンドとしてAtlasを使えます)。
スクショ
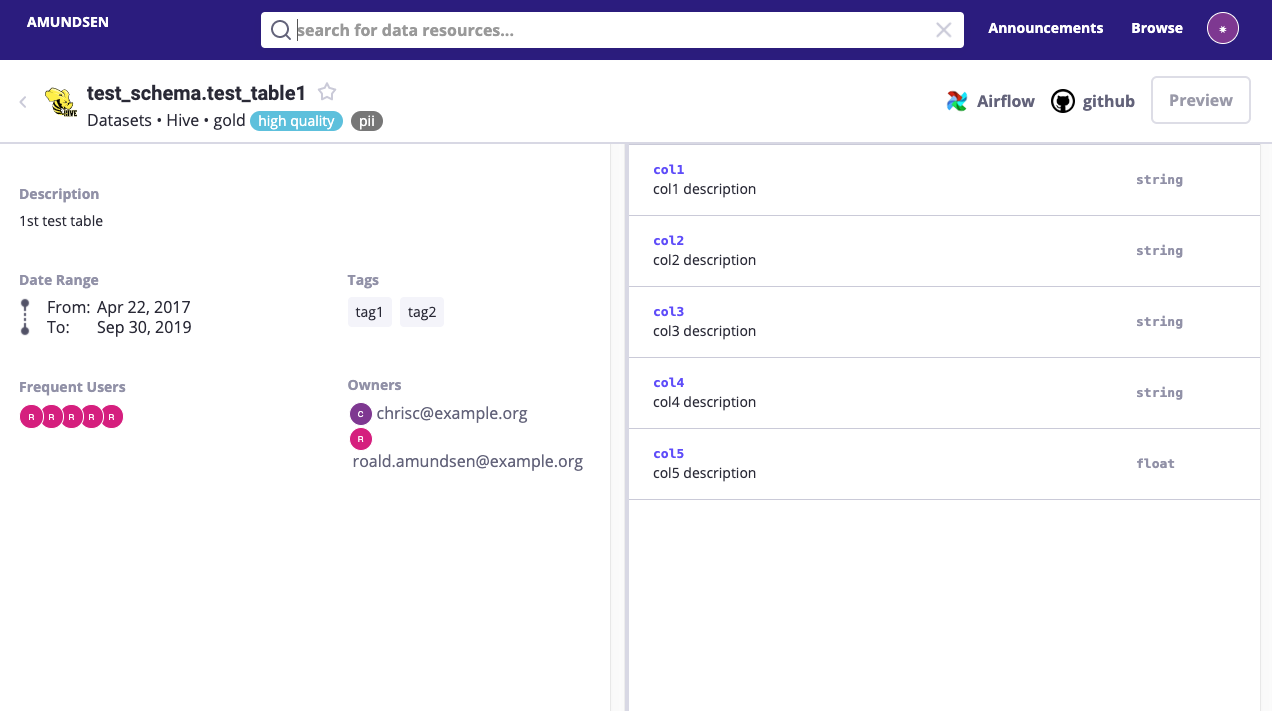
日本語資料
英語資料
#10 Apache Flink
公式ページ・SaaS・サポート
- 公式ページ
-
Ververica(旧data Artisan)
- FlinkのFounderが在籍していたFlinkのエンタープライズ版をサポートしている会社
- Alibabaの子会社
- Amazon EMR
- Amazon Kinesis Data Analytics
概要
分散処理エンジン。ストリーミング処理の文脈でよく出ますが、バッチ処理もできます。
似たジャンルの製品のApache SparkやApache Samza、Apache Stormと比べて、
- メッセージ単位の処理
- Sparkと違いMicro Batchではない
- Event Time Processing
- Exactly-Once
- Stateの管理機能の豊富さ
- バッチ処理もストリーミング処理も出来る
等を押し出しているのかなーと思っています。
なお、Apache Beamで書くと、SparkやSamzaと入れ替え可能です(ただし留保付き)。
スクショ

Discussion