概要
株式会社neoAIに所属している東京都立大学B4の板井孝樹です.
本記事では大規模言語モデル(Large Language Model: LLM)の事前学習・継続事前学習を行う際の選択肢の一つであるMegatron-DeepSpeedを用いて,GPT-2とLlama2の事前学習・継続事前学習を行う手順について解説します.
以下の東工大藤井様の記事やMegagonLabs松田様のNLP2024でのチュートリアル資料を参考に構築させていただきました.
DeepSpeedとは?
DeepSpeedはMicrosoft社が提供する大規模かつ高速な深層学習を容易することを目的としたOSSライブラリです.大規模言語モデルの学習には多くのGPU資源を必要とし,これらのリソースを効率的に活用するためには,モデルを個々のデバイスのメモリに収まるように分割し,デバイス間で効率的に並列計算を行うための複雑な最適化システムが必要となります.通常以下のような場合,GPU間のデータ転送のオーバーヘッドが大きくなり,効率的な学習効率の達成が困難となります.
- バッチサイズに対して多数のGPUで訓練するため、GPUごとのバッチサイズが小さくなり、頻繁な通信が必要になる場合
- ローエンドの計算クラスタで訓練する際、ノード間のネットワーク帯域幅が十分ではなく、通信待ち時間が長くなる場合
DeepSpeedではZeRO (Zero Redundancy Optimizer)やZeRO++により,高速化・効率化が実現されています.これにより以下のような効果が期待されます.
-
大規模モデルの事前学習・FTの高速化
- GPUあたりのバッチサイズが小さい:ZeROと比較して最大2.2倍のスループットを提供し,訓練時間とコストを削減
- 停帯域幅クラスタ:4倍の帯域幅を持つクラスタと同等のスループットを達成
-
RLHFによるChatGPTライクなモデルの訓練の高速化
- ZeRO++は訓練時の高速化を目的に設計されているが,推論のための機構であるZeRO-Inferenceでも有効
- DeepSpeed-Chatとの統合により,RLHF訓練の生成フェーズを最大2倍,訓練フェーズを最大1.3倍高速化
- ZeRO++は訓練時の高速化を目的に設計されているが,推論のための機構であるZeRO-Inferenceでも有効
DeepSpeedの詳細については,以下のMicrosoft DeepSpeed Teamの解説スライドが参考になると思われます.
Megatron-DeepSpeed
Megatoron-DeepSpeedは,NVIDIAのMegatron-LMとMicrosoftのDeepSpeedを組み合わせたライブラリです.Megatron-LMは大規模なTransformerモデルのフレームワークであり,Megatron-DeepSpeedではその効率的な分散トレーニングと推論を実現します.Megatron-DeepSpeedは、以下のような主要な機能を提供しています.
- DeepSpeed-MoE:Mixture of Experts(MoE)モデルの学習
- カリキュラム学習:モデルを徐々に難しいタスクに適応させるために、学習の進行に合わせてデータの難易度を調整する手法です。これにより、モデルの収束速度と性能が向上します。
- 3D Parallelism:モデルの重みを複数のGPUに分散する際に、テンソル並列化、パイプライン並列化、データ並列化を組み合わせる手法です。これにより、より効率的なメモリ使用と高速な学習が可能になります。
- DeepSpeedの最適化技術:上述したZeRO(Zero Redundancy Optimizer)、効率的なOptimizer、パイプライン並列化、高速なDataLoaderなど、DeepSpeedの様々な最適化技術を活用することができます。
- DeepSpeed Inference:学習済みモデルを使用して高速に推論を行うための最適化が含まれています。これにより、大規模なモデルを実用的な応答時間で利用できるようになります。
本記事ではMegatron-DeepSpeedを用いて,大規模言語モデルの独自チューニング手法について入門したいと思います.
環境構築
GCP
VMインスタンスの作成
今回はGoogle Cloud Platform(GCP)のGoogle Compute Engine(GCE)のVM上で実験を行います.
ここではGCEでのVM作成手順についてまとめます.
-
下図の左側のメニューバーからCompute Engine -> VM instances を選択後,CREATE-INSTANCEをクリックします.
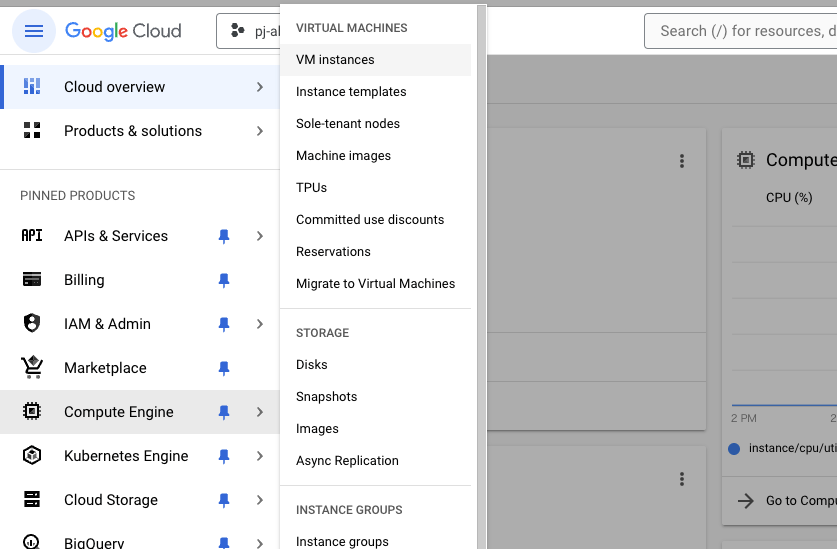
-
次にVMインスタンスの構成を設定します.
インスタンス名に適用な名前を入力し,GPU割当て済みのリージョンを選択します.ゾーンはお好きなもので問題ありませんが,分散学習環境下で複数のリージョンを跨いでいる場合,かなりの額の通信費がかかるとAbejaの担当者様がおっしゃっていたので注意してください.今回は,リージョンはasia-northeast1 (Tokyo),ゾーンはasia-northeast1-cに統一します.そしてGPU TypesでGPUの種類,Number of GPUsでGPUの個数を選択します.今回は小規模の実験用にNVIDIA A100 40GB × 2枚,Llama2-7Bの学習用にNVIDIA A100 80GB × 4枚のVMインスタンスをそれぞれ作成しました.
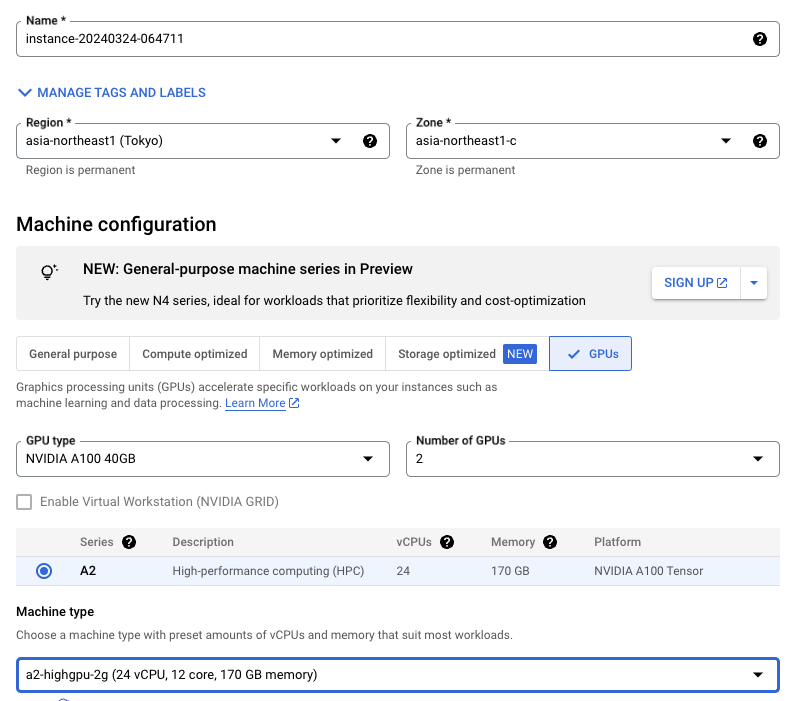
Confidential VMsサービスとコンテナ項目は今回は飛ばして構いません.
- ブートディスク項目を選択します. 下部のBoot disk -> Changeタブをクリックし,下図のようにVMのOSやバージョン、ブートディスクのサイズを選択します.OSはDeep Learning用に事前に設定されたDeep Learning on Linuxが推奨です.CUDAのインストールなどが簡単に行うことが可能です.
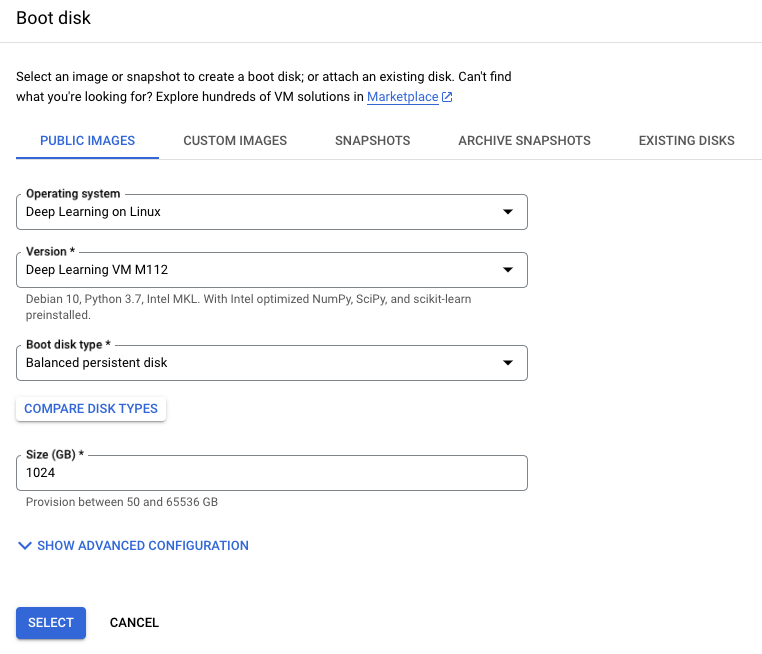
4.最後に最下部のCREATEボタンをクリックし,これでVMインスタンスの作成は完了です.
ssh接続
ssh接続によりVMインスタンスへアクセスします.
下図のConnect -> SSHタブから「View gcloud command」を選択し,接続用のコマンドを取得します.

以下のようなコマンドを取得できるかと思います.
gcloud compute ssh --zone "asia-northeast1-c" "{your instance name}" --project "{your project name}"
クライアント側で公開鍵やgcloud login等の設定を完了後,上記コマンドによりVMインスタンスに接続します.
学習環境設定
ここからはVMインスタンス下での環境設定について説明します.
CUDA
Deep Learning on Linuxを採用した場合,ssh初回起動時にCUDAのツールキットのインストールをするか確認があります.インストールが完了すれば,CUDA関連で他にセットアップすることはありません.
This VM requires Nvidia drivers to function correctly. Installation takes ~1 minute.
Would you like to install the Nvidia driver? [y/n]
pyenv
今回はpyenvによりpython環境を設定します.pyenvの設定方法についての説明は割愛しますが,以下に本環境で実行した手順を示します.
(詳細は以下の記事などが参考になるかと思います.)
sudo apt update
sudo apt install build-essential libffi-dev libssl-dev zlib1g-dev liblzma-dev libbz2-dev \
libreadline-dev libsqlite3-dev libopencv-dev tk-dev git
git clone https://github.com/pyenv/pyenv.git ~/.pyenv
echo '' >> ~/.bashrc
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init --path)"' >> ~/.bashrc
source ~/.bashrc
pyenv install 3.10.10
pyenv local 3.10.10
python -m venv .env
source .env/bin/activate
Megatron-DeepSpeed
次にMegatron-DeepSpeedを以下のコマンドでクローンします.
git clone https://github.com/microsoft/Megatron-DeepSpeed
cd Megatron-DeepSpeed
階層移動後,Megatron-DeepSpeed/requirements.txtを手動で作成します.requirements.txtには以下を追加しました.
deepspeed
ninja
numpy
packaging
pybind11
regex
six
tensorboard
torch
transformers
wandb
wheel
作成したrequirements.txtによりパッケージをインストールします.
pip install -r requirements.txt
apex
次にNDIVIA apexの設定をします.apexは混合演算(TensorCore)での処理高速化,分散学習の効率化を目的としたNVIDIAが提供するPyTorch extensionの一つです.下記の手順でapexをインストールします.
git clone https://github.com/NVIDIA/apex
cd apex
pip install -r requirements.txt
python setup.py install --cuda_ext
Flash Attention
ninjaのバージョンを確認して以下を実行し,Flash Attentionをインストールします.
$ ninja --version
1.11.1.git.kitware.jobserver-1
$ pip install "flash-attn<2.4.0" --no-build-isolation
Flash Attentionはジョブスクリプトに--use-flash-attnを追加することで使用可能です.
Llamaモデルの取得
まず以下のフォームからMetaにLlamaの利用申請を行います.
数分ほどすると登録したメールアドレス宛に認証用のURLが送付されます.
次に公式リポジトリをcloneし,ダウンロードスクリプトを実行します.download.shの実行にはwgetとmd5sumが必要なので注意してください.
git clone https://github.com/facebookresearch/llama
cd llama
bash download.sh
Enter the URL from email:と聞かれるので,先ほど取得したURLを打ち込みます.すると以下のように取得したいモデルを聞かれます.今回はLlama2-7Bを使うので7Bとだけ入力してインストールします.
Enter the list of models to download without spaces (7B,13B,70B,7B-chat,13B-chat,70B-chat), or press Enter for all: 7B
モデル取得後,llama/llama-2-7b/階層にconsolidated.00.pthが存在していることを確認し,Megatron-DeepSpeed/weights/階層を作成し,こちらにコピーします.
またllama/階層にtokenizer.modelが存在していることを確認し,Megatron-DeepSpeed/tokenizer/階層を作成し,こちらにコピーします.
学習コーパス
次に事前学習に用いるコーパスを取得します.本記事では実験データとしてarXivデータを用います.
まずは以下のコマンドで語彙データを取得します.
cd dataset
bash download_vocab.sh
cd ..
次にMegatron-DeepSpeed/階層に以下のような download_arxiv.sh を定義して,arXivデータを取得します.
pip install nltk
cd dataset
wget https://data.together.xyz/redpajama-data-1T/v1.0.0/arxiv/arxiv_024de5df-1b7f-447c-8c3a-51407d8d6732.jsonl
mv arxiv_* arxiv.jsonl
cd ..
python tools/preprocess_data.py \
--input dataset/arxiv.jsonl \
--output-prefix dataset/arxiv \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--vocab-file dataset/gpt2-vocab.json \
--merge-file dataset/gpt2-merges.txt \
--workers 64 \
--append-eod
作成したdownload_arxiv.sh を実行すると,Megatron-DeepSpeed/dataset/階層に以下の2点のファイルが作成されることを確認します.
- arxiv_text_document.bin
- arxiv_text_document.idx
学習
GPT-2 ( 1 node / 1 GPU )
まずは試験的にGPT-2(345M)に対してpre-trainingを行います.
リポジトリのコードそのままでは動作しなかったので,いくつか手動で修正します.
まず,examples/pretrain_gpt.sh を以下に書き換えます
#!/bin/bash
# Runs the "345M" parameter model
source .env/bin/activate
RANK=0
WORLD_SIZE=1
DATA_PATH=dataset/BookCorpusDataset_text_document
CHECKPOINT_PATH=checkpoints/gpt2_345m/1gpu
mkdir -p $CHECKPOINT_PATH
export LOCAL_RANK=$RANK
python pretrain_gpt.py \
--num-layers 24 \
--hidden-size 1024 \
--num-attention-heads 16 \
--micro-batch-size 4 \
--global-batch-size 8 \
--seq-length 1024 \
--max-position-embeddings 1024 \
--train-iters 500000 \
--lr-decay-iters 320000 \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
--vocab-file dataset/gpt2-vocab.json \
--merge-file dataset/gpt2-merges.txt \
--data-impl mmap \
--split 949,50,1 \
--distributed-backend nccl \
--lr 0.00015 \
--min-lr 1.0e-5 \
--lr-decay-style cosine \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--lr-warmup-fraction .01 \
--checkpoint-activations \
--log-interval 100 \
--save-interval 10000 \
--eval-interval 1000 \
--eval-iters 10 \
--fp16
--recompute-method uniform
次に環境変数をいくつか設定します.
export CUDA_DEVICE_MAX_CONNECTIONS=1
export MASTER_ADDR=localhost
export MASTER_PORT=9999
export RANK=0
export WORLD_SIZE=1
- CUDA_DEVICE_MAX_CONNECTIONS:NVIDIA GPUデバイスの最大同時接続数を設定
- MASTER_ADDR:分散処理のマスターノードのIPアドレスまたはホスト名
- MASTER_PORT:分散処理のマスターノードのポート番号
- RANK:現在のプロセスのランク(0からワールドサイズ-1までの一意の整数)
- WORLD_SIZE:分散処理に参加するプロセスの総数
環境変数の設定後, Megatron-DeepSpeed/ 階層にて以下を実行し,学習を開始します.
bash examples/pretrain_gpt.sh
Llama2 × DeepSpeed ( 1 node / 4 GPU )
本章では,いよいよLlama2の継続事前学習を行います.今回は単一ノード,複数GPUでDeepSpeedを動作させる分散学習を行います.
ランダムパラメータによるpre-training
まずはランダムパラメータのLlama2に対してpre-trainingを行います.GPT-2の場合と同様,既存のコードにいくつか修正を行います.
examples_deepspeed/pretrain_llama2_distributed.sh を以下のように修正します.
#!/bin/bash
# This example script is contributed by external user https://github.com/nrailgun
set -ex
######################################
# Change the below configurations here
BASE_PATH=./tmp
DS_CONFIG=${BASE_PATH}/deepspeed.json
< DATASET_1="./tmp/data/bookcorpus_train_1m_text_sentence"
< DATASET="1 ${DATASET_1}"
> DATASET="./dataset/arxiv_text_document"
< CHECKPOINT_PATH=./tmp
> CHECKPOINT_PATH=./checkpoints
< TOKENIZER_PATH=./tmp/tokenizer.model # offical llama tokenizer.model
> TOKENIZER_PATH=./tokenizer/tokenizer.model
> export NCCL_IB_GID_INDEX=3
> export NCCL_IB_TC=106
TP=2
PP=2
ZERO_STAGE=1
GPUS_PER_NODE=4
MASTER_ADDR=localhost
MASTER_PORT=6000
NNODES=1
NODE_RANK=0
HIDDEN_SIZE=2048 # e.g. llama-13b: 5120
FFN_HIDDEN_SIZE=5504 # e.g. llama-13b: 13824
NUM_LAYERS=24 # e.g. llama-13b: 40
NUM_HEADS=16 # e.g. llama-13b: 40
SEQ_LENGTH=2048
NUM_KV_HEADS=4 # llama2 70B uses GQA
MICRO_BATCH_SIZE=4
GLOBAL_BATCH_SIZE=32 # e.g. llama: 4M tokens
TRAIN_STEPS=250000 # e.g. llama: 1T tokens / 4M tokens_per_batch = 250000 steps
LR=3e-4
MIN_LR=3e-5
LR_WARMUP_STEPS=2000
WEIGHT_DECAY=0.1
GRAD_CLIP=1
## Activation checkpointing saves GPU memory, but reduces training speed
activation_checkpoint="true"
# Below configuration required for llama model as per llama paper
# --no-query-key-layer-scaling \
# --attention-dropout 0 \
# --hidden-dropout 0 \
# --use-rotary-position-embeddings \
# --untie-embeddings-and-output-weights \
# --swiglu \
# --normalization rmsnorm \
# --disable-bias-linear \
######################################
cat <<EOT > $DS_CONFIG
{
"train_batch_size" : $GLOBAL_BATCH_SIZE,
"train_micro_batch_size_per_gpu": $MICRO_BATCH_SIZE,
"steps_per_print": 1,
"zero_optimization": {
"stage": $ZERO_STAGE
},
"bf16": {
"enabled": true
}
}
EOT
ds_args=""
ds_args=" --deepspeed ${ds_args}"
ds_args=" --deepspeed_config=$DS_CONFIG ${ds_args}"
ds_args=" --zero-stage=$ZERO_STAGE ${ds_args}"
if [ "${activation_checkpoint}" = "true" ]; then
ds_args="--deepspeed-activation-checkpointing ${ds_args}"
## old argument for recomputing the transformer layer
# ds_args="--checkpoint-activations ${ds_args}"
## new argument for recomputing the transformer layer
ds_args="--recompute-granularity full --recompute-method uniform ${ds_args}"
## new argument for recomputing only the attention layer
# ds_args="--recompute-granularity selective ${ds_args}"
fi
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
torchrun $DISTRIBUTED_ARGS
pretrain_gpt.py \
--tensor-model-parallel-size $TP \
--pipeline-model-parallel-size $PP \
--num-layers $NUM_LAYERS \
--hidden-size $HIDDEN_SIZE \
--ffn-hidden-size $FFN_HIDDEN_SIZE \
--num-attention-heads $NUM_HEADS \
--micro-batch-size $MICRO_BATCH_SIZE \
--global-batch-size $GLOBAL_BATCH_SIZE \
--seq-length $SEQ_LENGTH \
--max-position-embeddings $SEQ_LENGTH \
--train-iters $TRAIN_STEPS \
--save $CHECKPOINT_PATH \
< --load $CHECKPOINT_PATH \
--data-path $DATASET \
--data-impl mmap \
< --tokenizer-type GPTSentencePieceTokenizer \
> --tokenizer-type SentencePieceTokenizer \
< --tokenizer-model $TOKENIZER_PATH \
> --vocab-file dataset/gpt2-vocab.json \
> --merge-file dataset/gpt2-merges.txt \
--split 949,50,1 \
--distributed-backend nccl \
--lr $LR \
--lr-decay-style cosine \
--min-lr $MIN_LR \
--weight-decay $WEIGHT_DECAY \
--clip-grad $GRAD_CLIP \
--lr-warmup-iters $LR_WARMUP_STEPS \
--optimizer adam \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--log-interval 1 \
--save-interval 10000 \
--eval-interval 1000 \
--eval-iters 10 \
--bf16 \
--no-query-key-layer-scaling \
--attention-dropout 0 \
--hidden-dropout 0 \
--use-rotary-position-embeddings \
--untie-embeddings-and-output-weights \
--swiglu \
--normalization rmsnorm \
--disable-bias-linear \
--num-key-value-heads $NUM_KV_HEADS \
> --use-flash-attn-v2 \
$ds_args
以下を実行して学習を開始します.
bash examples_deepspeed/pretrain_llama2_distributed.sh
以下のように学習が進行していることが確認できます.
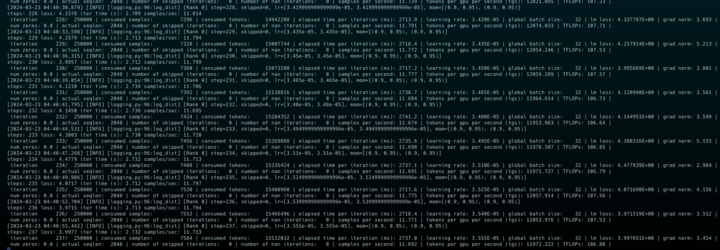
checkpointをロードして継続事前学習
最後に本題のcheckpointをロードした状態のLlama2 7Bに対して継続事前学習を行います.
学習
先ほど作成したexamples_deepspeed/pretrain_llama2_distributed.shに修正を加えます.
> LLAMA_WEIGHTS_PATH=./weights
...
< HIDDEN_SIZE=2048 # e.g. llama-13b: 5120
< FFN_HIDDEN_SIZE=5504 # e.g. llama-13b: 13824
< NUM_LAYERS=24 # e.g. llama-13b: 40
< NUM_HEADS=16 # e.g. llama-13b: 40
< SEQ_LENGTH=2048
< NUM_KV_HEADS=4 # llama2 70B uses GQA
> HIDDEN_SIZE=4096
> FFN_HIDDEN_SIZE=11008
> NUM_LAYERS=32
> NUM_HEADS=32
> SEQ_LENGTH=4096
> NUM_KV_HEADS=4 # llama2 70B uses GQA
...
DISTRIBUTED_ARGS="--nproc_per_node=2 --nnodes=$NNODES --node_rank=$NODE_RANK --master_addr=$MASTER_ADDR --master_port=$MASTER_PORT"
torchrun $DISTRIBUTED_ARGS
pretrain_gpt.py \
--tensor-model-parallel-size $TP \
--pipeline-model-parallel-size $PP \
...
> --load $LLAMA_WEIGHTS_PATH/consolidated.00.pth \
...
またWeights & Biasで学習経過をウォッチするためにdeepspeed_confingに以下の設定も加えます.プロジェクト名はお好きに設定してください.
cat <<EOT > $DS_CONFIG
{
"train_batch_size" : $GLOBAL_BATCH_SIZE,
"train_micro_batch_size_per_gpu": $MICRO_BATCH_SIZE,
"steps_per_print": 1,
"zero_optimization": {
"stage": $ZERO_STAGE
},
"bf16": {
"enabled": true
},
> "wandb": {
> "enabled": true,
> "project": $PJ_NAME
> },
}
EOT
それでは再度examples_deepspeed/pretrain_llama2_distributed.shを実行します.
実行後wandbを確認して下図のように学習が進行していれば成功です.
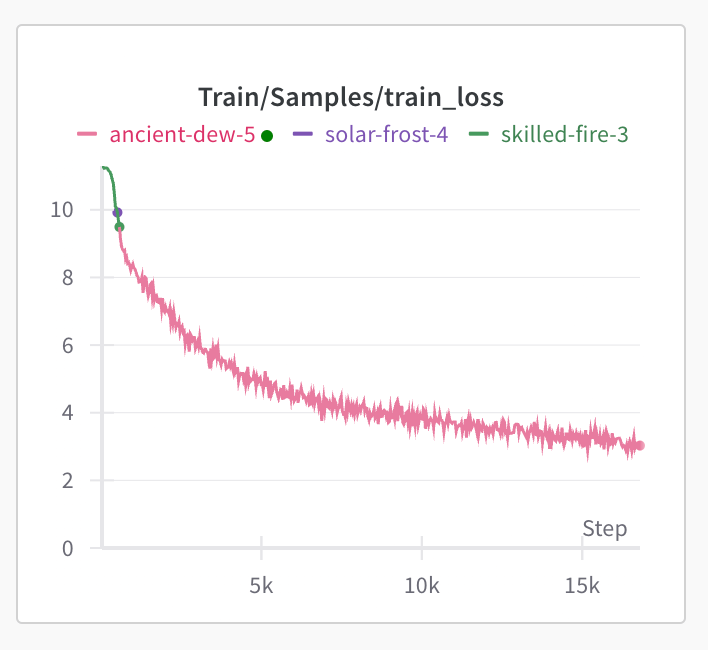
まとめ
ここまでご覧いただきありがとうございました!
本記事ではMegatron-DeepSpeedを用いてLlama2-7Bに継続事前学習を行う手順について解説しました.
今回はarxivの学習データと7BサイズのLlamaを使用しましたが,適宜データやパラメータを変更し,本手順を実行することで,目的や用途に応じたLLMの構築が可能です.
本記事が独自LLMの構築を目指している方々のハンズオン記事となれば幸いです.
今後もLLM関連の記事を投稿予定ですので,どうぞご期待ください!
【 学生/社会人 エンジニア募集中!】
neoAIでは、ともに「次の時代のAI産業を創る」プロフェッショナルな仲間を募集しています。
neoAIは「生成AI」を強みに持つ東京大学松尾研発AIスタートアップです。我々は、生成AIを、世界を大きく変える不可逆なうねりであると捉えています。
世界が大きく変わりうる中で、時代の最先端であり続け、ともに成長できる未来の仲間との出会いを楽しみにしています。

Discussion
素晴らしい記事をありがとうございます。大変参考になりました。
1つ質問させていただきたいことがございます。
をコメントアウトして、以下のようにしたのは何故でしょうか。
llamaのモデルなので、以下のようになると思っていました。
LLMの継続事前学習について詳しくないので、的外れな質問でしたら申し訳ございません。