JAX/Flax/OptaxでMobileNet v3 largeをやってみる
はじめに
JAX/Flax/Optaxを利用し、MobileNet v3 largeのモデルを構築する。ImageNet2012の学習データを用い、精度(Top1-Acc)が再現できるか確認する。
参照
モデル実装
前回(JAX/Flax/OptaxでMobileNet v3 smallをやってみる)と同様、以下のリポジトリで実装した。
MobileNet v3のモデルは以下で定義した。
- classification/implements/mobilenet_v3.py
- small/largeで共通となっており、レイヤーの定義で切り分ける
Large
MobileNet v3 largeの学習のセットアップ
MobileNet v3 largeの学習を行う。
学習パラメータは、TF-Vision Model GardenのMobileNet v3 largeの学習パラメータを参考にした。論文実装とパラメータが異なり、Adamw、AutoAugにより ~75.7% top-1.とある。
今回このパラメータで学習を行う。乱数のシード値は42ですべて固定した。
学習リソース
学習はTPUv2-8で行う。
Data augmentation
TF-Vision Model GardenのMobileNet v3の学習パラメータでは、AutoAugを指定している。
tfm.vision.augment.AutoAugmentを用い、以下のパラメータを指定した。
| Config | Params | Note |
|---|---|---|
| Augmentation name | v0 | |
| Policies | None | * |
| Cutout const | 100 | |
| Translate const | 250 |
Optimizer
Optimizerはoptax.adamwを利用。
| Config | Params | Note |
|---|---|---|
| Optimizer | AdamW | |
| Learning rate | - | schedulerで指定(別表) |
| b1 | 0.9 | * |
| b2 | 0.999 | * |
| Eps | 1e-08 | *(元は1e-07を指定だが影響少ないと判断し、デフォルトのまま) |
| Eps root | 0.0 | * |
| Mu dtype | None | * |
| Weight decay | 0.1 | |
| Mask | - | 指定(別表) |
| Nesterov | False | * |
- *はデフォルト引数のまま
Learning scheduer
LR Scheduerはcosine decayで、optax.cosine_decay_scheduleを利用する。
以下のパラメータを指定する。
| Config | Params | Note |
|---|---|---|
| Optimizer schedule | Cosine decay | |
| Init value | 0.004 | |
| Decay steps | 219100 | 700 * 313 |
| Alpha | 0.0 | * |
| Exponent | 1.0 | * |
| Num epochs | 700 |
Model setup
モデルの入力サイズ、Batch normalization、Dropuptに指定するパラメータは以下。TPUv2-8ではバッチサイズに4096を確保できないため、Gradient accumulation(every k schedule=4)、バッチサイズを1024とする。
| Config | Params | Note |
|---|---|---|
| Input size | 224x224 | |
| BatchNorm momentum | 0.997 | |
| BatchNorm esp | 0.001 | |
| Dropout | 0.2 | |
| Stochastic depth | 0.0 | |
| Model dtype | bfloat16 | |
| Batch size | 4096 | Batch size=1024, Gradient accumulation=4) |
Loss
optax.losses.smooth_labelsにてLabel smoothingを指定する。
| Config | Params |
|---|---|
| Label smoothing | 0.1 |
Weight decay
optax.adamwのweight_decay、およびmaskに指定する。maskに指定する除外opeについては、前回(JAX/Flax/OptaxでMobileNet v2をやってみる)と同様。
Model EMA
TF-Vision Model GardenのMobileNet v3 largeの学習パラメータでは、Model EMAは行わない。今回、パラメータのミスでModel EMAを指定したのでこちらも結果に記載する。
| Config | Params |
|---|---|
| EMA decay | 0.9999 |
学習の結果
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 698 | 74.09 | |
| 677 | 74.14 | best |
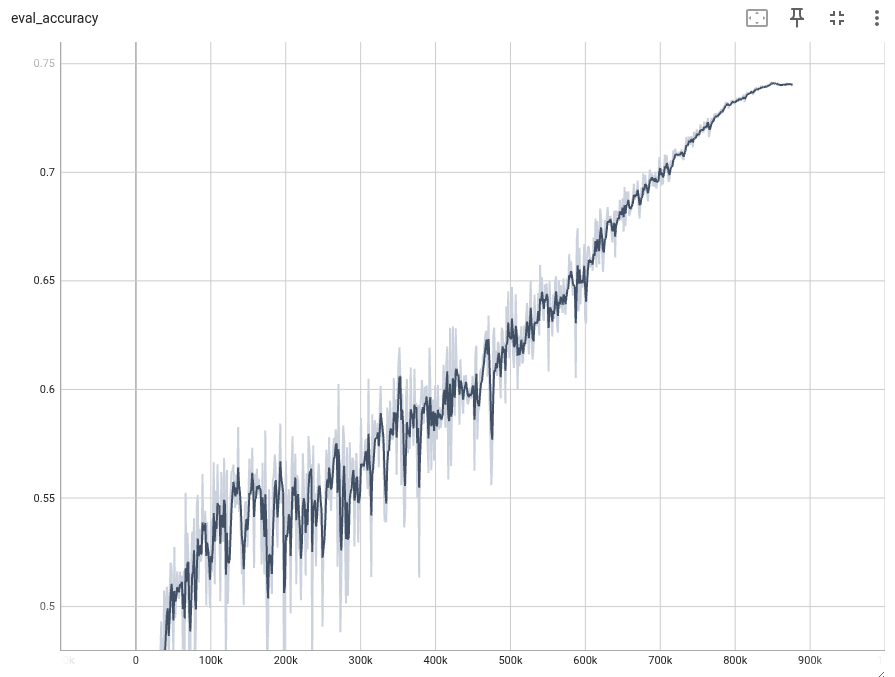
Model EMAの結果
Model EMAの場合、よい精度は得られなかった。ステップ数が不足か他の要因と推測。
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 700 | 61.52 | best |

2回目
以下を変更して再度学習。
- Relu6ではなく、Reluを指定(単純に指定誤り)。
- 学習パラメータをTF-Vision Model GardenのMobileNet v3 largeの学習パラメータにあわせる。
Optimizer
| Config | Params | Note |
|---|---|---|
| Optimizer | AdamW | |
| Eps | 1e-07 | |
| Mask | - | 指定(別表) |
Model setup
| Config | Params | Note |
|---|---|---|
| Batch size | 4096 |
Model EMA
なし
学習の結果
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 695 | 74.42 | best |

3回目
TF-Vision Model GardenのMobileNet v3 largeの学習パラメータでは、AdamWのexclude_from_weight_decay(Weight decayで除外するレイヤー)にbatch_normalizationのみを指定しているため、これにあわせる
(いままでは、BatchNormalization、DepthWiseConv、biasを除外)。
加えてkernel initializerにFlaxのデフォルト(flax.linen.initializers.lecun_normal)にした。
学習の結果
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 700 | 73.97 | best |

4回目
MobileNet V4のConv-Mと同じTraining setupで学習してみる。
-
https://arxiv.org/pdf/2404.10518
C Training setup for ImageNet-1k classification
Table 10: Training hyper-parameters for ImageNet-1k classification.
学習パラメータ
下記実装を参考にパラメータを設定
RandAugment
| Args | Value |
|---|---|
| num_layers | 2 |
| magnitude | 15 |
| cutout_const | 20 |
| translate_const | 10 |
| magnitude_std | 0.0 |
| prob_to_apply | 0.7 |
| exclude_ops | Cutout |
Optimizer
AdamW
| Args | Value |
|---|---|
| weight_decay | 0.01 |
| epsilon | 1e-7 |
β1, β2はoptaxのデフォルト
LR scheduler config
warmup cosine decay
| Args | Value |
|---|---|
| warmup epochs | 5 |
| peek learning rate | 004 |
実装
結果
| Epoch | Top-1 | Top-5 |
|---|---|---|
| 500 | 73.31% | 91.13% |

5回目
元論文と同じ学習パラメータで学習する。
MobileNet v3 smallと同じパラメータ。
実装
結果
| Epoch | Top-1 | Top-5 |
|---|---|---|
| 607 | 74.91% | 92.12% |
