JAX/Flax/OptaxでMobileNet v3 smallをやってみる
はじめに
JAX/Flax/Optaxを利用し、MobileNet v3 smallのモデルを構築する。ImageNet2012の学習データを用い、精度(Top1-Acc)が再現できるか確認する。
参照
モデル実装
前回(JAX/Flax/OptaxでMobileNet v2をやってみる)と同様、以下のリポジトリで実装した。
MobileNet v3のモデルは以下で定義した。
- classification/implements/mobilenet_v3.py
- small/largeで共通となっており、レイヤーの定義で切り分ける
Small
Model EMAの実装
MobileNet v3は学習時、Model EMA(Exponential Moving Average)を使用している。Optaxにはoptax.emaがあるが、Model EMAへの利用方法がよくわからない(optax.chainと組み合わせると、学習時のパラメータと別にEMAのパラメータを保持できない)ため、flax.training.train_stateを継承したクラスに独自にEMAを行うメソッドとパラメータを用意することとした。これにより、1つのtrain_stateでEMAを行う前のパラメータや状態、EMAのパラメータを管理できることにした。
class TrainStateWithBatchNorm(train_state.TrainState):
batch_stats: Any
dynamic_scale: dynamic_scale_lib.DynamicScale
ema_decay: float = 0.0
ema_params: Any = None
def apply_ema(self):
return jax.tree_util.tree_map(
lambda ema, param: (ema * self.ema_decay + param * (1.0 - self.ema_decay)),
self.ema_params,
self.params,
)
モデルの初期化時にema_paramsを初期化、
state = TrainStateWithoutBatchNorm.create(
apply_fn=model.apply,
params=params,
tx=tx,
dynamic_scale=dynamic_scale,
ema_params=params,
ema_decay=config.model_ema_decay,
)
学習時、apply_emaメソッドを実行することで更新したパラメータをもとにEMAのパラメータを得る(実装では、Gradient accumulationを考慮してapply_emaメソッドを呼び出すステップを調整)。
new_state = jax.lax.cond(
step % gradient_accumulation_steps == 0,
lambda _: new_state.replace(ema_params=new_state.apply_ema()),
lambda _: new_state,
None,
)
MobileNet v3 smallの学習のセットアップ
MobileNet v3 smallの学習を行う。
学習パラメータを以下に示す。学習パラメータはTPUv2-8のリソースで実行できるようにTensorFlow-Slimの実装を参照し、バッチサイズを1536(192 par chip)とした。乱数のシード値は42ですべて固定した。
学習リソース
学習はTPUv2-8で行う。
Data augmentation
前回(JAX/Flax/OptaxでMobileNet v2をやってみる)と同様。
Optimizer
Optimizerはoptax.rmspropsを利用。
| Config | Params | Note |
|---|---|---|
| optimizer | RMSProp | |
| Learning rate | - | schedulerで指定(別表) |
| Decay | 0.9 | |
| Eps | 0.002 | |
| Initial scale | 1.0 | |
| Eps in sqrt | True | * |
| Eentered | False | * |
| Momentum | 0.9 | |
| Nesterov | False | * |
| Bias correction | False | * |
- *はデフォルト引数のまま
Learning scheduer
LR ScheduerはWarmup exponential decayで、optax.warmup_exponential_decay_scheduleを利用する。
以下のパラメータを指定する。learning_rate、transition_stepsはバッチサイズによる調整を行う。
| Config | Params | Note |
|---|---|---|
| Optimizer schedule | Warmup exponential decay | |
| Initial learning rate | 0.0 | |
| Learning rate | 0.16 | 0.02 * (batch_size(1536) / 192) |
| Warmup epochs | 5 | |
| Exponential decay rate | 0.99 | |
| Transition steps | 2505 | 3.0 * steps_per_epoch (835) |
| LR drop staircase | True | |
| Num epochs | 1000 |
Model setup
モデルの入力サイズ、Batch normalization、Dropuptに指定するパラメータは以下。
| Config | Params | Note |
|---|---|---|
| Input size | 224x224 | |
| BatchNorm momentum | 0.997 | |
| BatchNorm esp | 0.001 | |
| Dropout | 0.2 | |
| Stochastic depth | 0.0 | |
| Initializer | truncated normal scale=1.0 |
別途記載 |
| Model dtype | bfloat16 | |
| Batch size | 1536 |
Kernel initializers
flax.linen.initializers.variance_scalingで指定する。
kernel_initializer = jax.nn.initializers.variance_scaling(
scale=1.0, mode="fan_in", distribution="truncated_normal"
)
conv = partial(
nn.Conv, use_bias=False, kernel_init=kernel_initializer, dtype=self.dtype
)
Loss
optax.losses.smooth_labelsにてLabel smoothingを指定する。
| Config | Params |
|---|---|
| Label smoothing | 0.1 |
L2 weight decay
optax.add_decayed_weightsにて、L2 weight decayを指定する。指定や除外するopeについては、前回(JAX/Flax/OptaxでMobileNet v2をやってみる)と同様。
| Config | Params |
|---|---|
| L2 weight decay | 0.00001 |
Model EMA
Model EMAを有効にし、以下のパラメータを指定する。
| Config | Params |
|---|---|
| EMA decay | 0.9999 |
モデル学習の結果
1回目
終了時点から3epoch以内(checkpointの保存数)でもっともよいTop-1 Accuracyと参考にBest Top-1 Accuarcyも確認。
元論文はTop-1 Accuracyは67.5%で、今回の結果は許容できる誤差でなかった。
slimの実装でも8 GPU(バッチサイズ1536)での結果は若干の精度が低下があるが、その範囲を超えている。
Non-EMA Model
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 999 | 64.77 | |
| 992 | 65.29 | best |

EMA Model
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 999 | 64.62 | |
| 909 | 65.44 | best |

学習2回目
バッチサイズを大きくした場合、精度が1回目より向上するか確認する。バッチサイズを4096とし、LR scheduerを下記の表のとおりとする。
Learning scheduer
| Config | Params | Note |
|---|---|---|
| Learning rate | 0.426 | 0.02 * (batch_size(4096) / 192) |
| Transition steps | 936 | 3.0 * steps_per_epoch (312) |
Model setup
| Config | Params | Note |
|---|---|---|
| Batch size | 4096 | Gradient accumulation batch size=1024, every k schedule=4 |
学習の結果
期待できる精度を達成できなかった。また、Model EMAは1回目と比べ、十分に上がりきらない。
Non Model EMA
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 998 | 64.39 | |
| 983 | 64.65 | best |

Model EMA
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 1000 | 55.64 | |
| 946 | 60.04 | best |

学習3回目
実装の見直し
期待した精度を大幅に下回ったため、モデルの実装を中心に見直しを行った。結果、アクティベーションの指定に誤りがあった。元実装ではreluのところをrelu6としていた。
アクティベーションの指定を修正する。
学習の結果
2回目と同様のパラメータで学習を行う。精度は多少向上したが、元実装の精度67.5%を実現できなかった。
Non Model EMA
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 1000 | 65.20 | |
| 980 | 65.53 | best |

Model EMA
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 1000 | 61.44 | best |

学習4回目
Model EMAの見直し
TF-Vision Model Garden(TFM)の実装を再確認。TFMではModel EMAにtfm.optimization.ExponentialMovingAverageを利用している。tf.train.ExponentialMovingAverageと動作が異なる。
-
trainable_weights_onlyフラグ
Falseの場合、全パラメータ(batch normalization 移動平均(mean)と分散(var))を対象とする。 -
dynamic_decayフラグ
Trueの場合、decay rateが0.1からはじまり、minimum(decay_rate, (1. + decay) / (10. + decay))で計算されたdecay rateが設定される。
tfm.optimization.ExponentialMovingAverageにあわせるように、Model EMAの実装を見直した。
学習の結果
期待した精度(Top-1、Top-5)を達成した。
設定したEpoch数(1000)に到達する前に、論文の精度まで到達したため、中止。
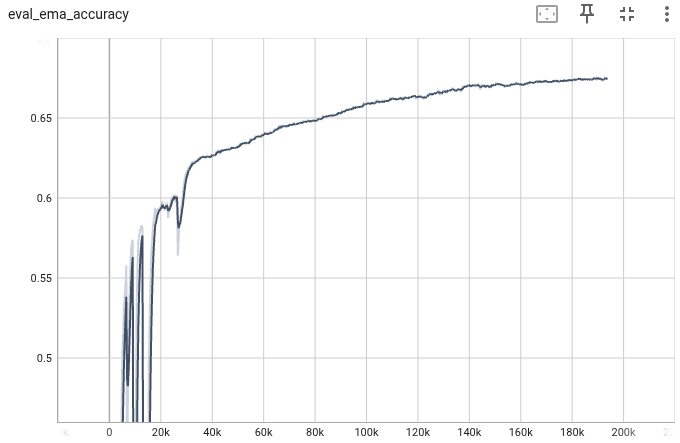
| Epoch | Top-1 accuracy | Top-5 accuracy |
|---|---|---|
| 619 | 67.52% | 87.60% |