JAX/Flax/OptaxでMobileNet v2をやってみる
はじめに
JAX/Flax/Optaxを利用し、MobileNet v2のモデルを構築する。ImageNet2012の学習データを用い、精度(Top1-Acc)が再現できるか確認する。
学習のセットアップ
学習パラメータを以下に示す。学習パラメータはTF-Vision Model GardenのMobileNet v2を参照にした。ただし、学習リソース(TPUv2-8)よりバッチサイズを1024とし、パラメータを調整した。乱数のシード値は42ですべて固定した。
学習リソース
学習はTPUv2-8で行う。
Data augmentation
学習データのハンドリングは、参考元のFlaxのImageNet classificationのサンプル(ResNet50)をベースに、
- TensorFlow
- TensorFlow Datasets
- TensorFlow Models Vision Libraries.
を利用している。
以下のパラメータを指定する。
| Config | Params |
|---|---|
| Random crop | (0.08, 1.0) |
| Center crops | 0.875 |
Optimizer
Optimizerはoptax.rmspropsを利用。
Everything you need to know about TorchVision’s MobileNetV3 implementationによると、TensorFlowとPyTorchではRMSPropsのepsilonの取り扱いに実装の差異がある。Optaxではeps_in_sqrtで指定ができる。デフォルトはeps_in_sqrt=TrueでTensorFlowと同様の実装である。今回の目的は再現のため、デフォルトの指定とする。
| Config | Params | Note |
|---|---|---|
| optimizer | RMSProp | |
| Learning rate | - | schedulerで指定(別表) |
| Decay | 0.9 | |
| Eps | 0.002 | |
| Initial scale | 0.0 | * |
| Eps in sqrt | True | * |
| Eentered | False | * |
| Momentum | 0.9 | |
| Nesterov | False | * |
| Bias correction | False | * |
- *はデフォルト引数のまま
Learning scheduer
LR ScheduerはWarmup exponential decayで、optax.warmup_exponential_decay_scheduleを利用する。
以下のパラメータを指定する。learning_rate、transition_stepsはバッチサイズによる調整を行う。
| Config | Params | Note |
|---|---|---|
| Optimizer schedule | Warmup exponential decay | |
| Initial learning rate | 0.0 | |
| Learning rate | 0.064 | 0.008 * batch_size(1024) / 128 |
| Warmup epochs | 5 | |
| Exponential decay rate | 0.94 | |
| Transition steps | 3127 | 2.5 * steps_per_epoch (1251) |
| LR drop staircase | True | |
| Num epochs | 500 |
Model setup
モデルの入力サイズ、Batch normalization、Dropuptに指定するパラメータは以下。
| Config | Params |
|---|---|
| Input size | 224x224 |
| BatchNorm momentum | 0.999 |
| BatchNorm esp | 0.001 |
| Dropout | 0.2 |
| Stochastic depth | 0.0 |
| Model dtype | bfloat16 |
Loss
optax.losses.smooth_labelsにてLabel smoothingを指定する。
| Config | Params |
|---|---|
| Label smoothing | 0.1 |
L2 weight decay
optax.add_decayed_weightsにて、L2 weight decayを指定する。なお、MobileNet v1よりDepthwise ConvやBatch normalizationは対象外している。optax.add_decayed_weightsの引数maskにて除外するopeを一括で指定している。
| Config | Params |
|---|---|
| L2 weight decay | 0.00001 |
optax.chainを利用し、L2 weight decayとOptimizerの組み合わせを行う。
組み合わせの順は
- add_decayed_weights
- optimizezr(rmsprop)
である。
モデル学習の結果
1回目
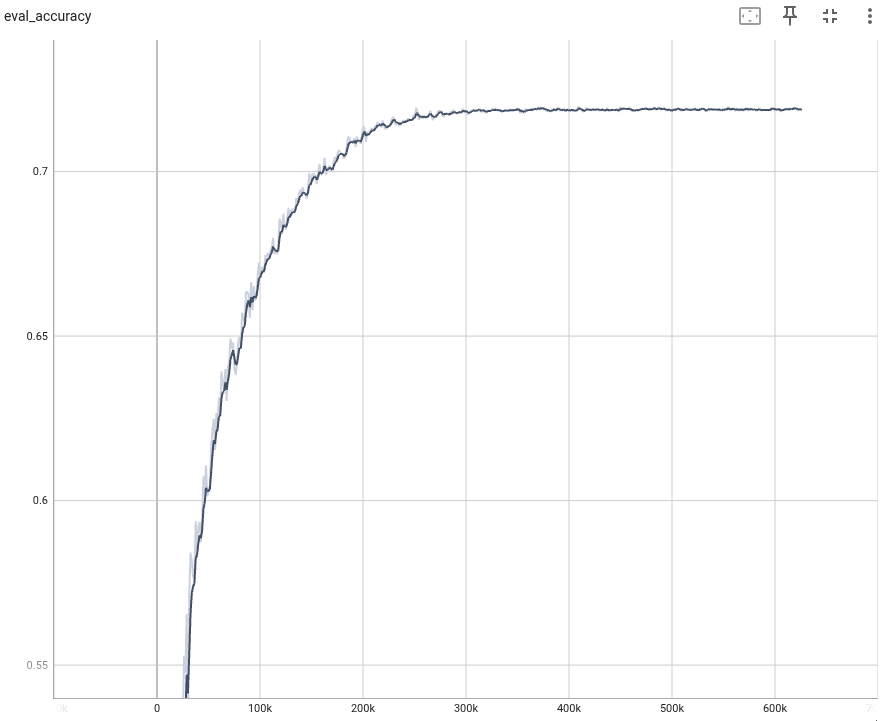
終了時点から3epoch以内(checkpointの保存数)でもっともよいTop-1 Accuracyと参考にBest Top-1 Accuarcyも確認。
元論文では、Top-1 Accuracyは72.0%で若干(0.18%程度)低いが許容できる精度となった。
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 499 | 71.82 | |
| 457 | 71.86 | best |

2回目
optax.rmspropsの関連を調査したところ、esp_in_sqrt以外にもTensorFlowとPyTorchで実装が異なる点の議論をGitHub上で確認した。
initial_scaleはTF1とそれ以外のFrameworkで実装が異なる模様。MobileNet v2はTF1のころからの実装であるため、実装を合わせるため、initial_scale = 1.0で再度学習を行う。
Learning scheduer
| Config | Params |
|---|---|
| Initial scale | 1.0 |
若干だが、精度は向上した。誤差の範囲かは不明
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 499 | 71.90 | |
| 327 | 71.97 | best |
3回目
TF-Vision Model GardenのMobileNet v2の学習パラメータによると、72.72% top-1 and 91.05% top-5 accuracy.とある。同じパラメータで達成できるかを確認する。ただし、バッチサイズは4096で学習リソースTPUv2-8では難しいため、Gradient accumulationでバッチサイズを確保する。バッチサイズは1024で、every_k_schedule=4とした。
Gradient accumulationは、optax.MultiStepsで実装する。以下のサンプルで、Flaxと組み合わせての実装を確認した。
Learning scheduer
| Config | Params |
|---|---|
| Learning rate | 0.256 |
| Transition steps | 780 |
Gradient accumulation
| Config | Params |
|---|---|
| every k schedule | 4 |
1回目と同様の精度となり、72.0%以上の精度を実現はできなかった(他のモデルでも、Gradient accumulationでは精度が1.0%程度低くなってしまうことがある)。
Result
| Epoch | Top-1 Accuracy | Note |
|---|---|---|
| 499 | 71.84 | |
| 430 | 71.87 | best |
