JAX/Flax/OptaxでModel EMA
はじめに
Jax/Flax/OptaxでtimmのModel EMA (Exponential Moving Average)
やtf.train.ExponentialMovingAverageのようにModel EMAを実現したい。optax.emaを利用して実現したい。
背景
Flaxを利用してModel EMAを行う場合、サンプル、チュートリアルなどには手順がない。とくに、flax.training.train_stateと組み合わせて、学習状態、パラメータ、EMAのパラメータを管理したい。
Easy JAX training loops with Flax and Optaxのブログで紹介されている方法(optax.chainで組み合わせる方法)は、学習パラメータに対して直接EMAが適用される。
Flaxの以前のサンプルでもEMAを独自に実装している。
通常はこれで十分ではあるが、optax.emaは
- ゼロ初期化
- バイアス補正
があり、timmでも議論されている。
このため、optax.emaを利用したModel EMAを実現するための実装を行う。
方針
Model EMAの学習パラメータは、flax.training.train_stateで管理する(Non EMAの学習パラメータを含め一緒に管理)。
以下の画像分類モデルの学習サンプルのコードに実装を行う。
実装
optax.emaの実装
学習状態(train_state)の管理
train_stateでEMAを適用したパラメータとEMAの変換を行う実態(optax.GradientTransformationを管理する。
flax.training.train_stateを継承し、ema_tx(EMAの変換を行う)とema_state(EMAを適用したパラメータ:optax.EmaState)を追加する。
チェックポイントとしてTrainStateを保存する際、ema_txは保存不要(関数の実態)であるため、struct.field(pytree_node=False)を明示する。
class TrainState(train_state.TrainState):
batch_stats: Any
dynamic_scale: dynamic_scale_lib.DynamicScale
ema_tx: optax.GradientTransformation = struct.field(pytree_node=False)
ema_state: optax.OptState = None
初期化
モデルを初期化した際にema_txとema_stateを初期化、TrainStateに設定する。
# モデルの定義
class SimpleModel(nn.Module):
@nn.compact
def __call__(self, x):
x = nn.Dense(features=128)(x)
x = nn.relu(x)
x = nn.Dense(features=10)(x)
return x
# モデルの初期化
model = SimpleModel()
params = model.init(jax.random.PRNGKey(0), jnp.ones((1, 28, 28)))
# Model EMAの初期化
ema_tx = optax.ema(config.model_ema_decay)
ema_state = ema_tx.init(params)
# TrainStateの生成
state = TrainStateWithoutBatchNorm.create(
apply_fn=model.apply,
params=params,
tx=tx,
ema_tx=ema_tx,
ema_state=ema_state,
)
学習でのパラメータ反映
学習ループでは、apply_gradientsで反映されたパラメータをema_txでModel EMAに反映する。ema_tx.updateでema_stateのパラメータを反映する。
def train_step(
...
):
...
grad_fn = jax.value_and_grad(loss_fn, has_aux=True)
aux, grads = grad_fn(state.params)
# Re-use same axis_name as in the call to `pmap(...train_step...)` below.
grads = lax.pmean(grads, axis_name="batch")
...
new_state = state.apply_gradients(grads=grads)
...
_, new_ema_state = state.ema_tx.update(new_state.params, state.ema_state)
new_state = new_state.replace(ema_state=new_ema_state)```
Eval時のパラメータの選択
Model EMAのパラメータはTrainStateのema_state.emaに保持される。
Checkpoint
TranStateのema_stateはpytreeとして保持されるため、そのまま何も気にせずsave、restoreが可能。
tfm.optimization.ExponentialMovingAverage を実装
MobileNet V3やEfficientnetのModelEMAはTF1ベースの実装を利用しており、TF2のModel EMA(tf.train.ExponentialMovingAverageとは動作がことなる。TF2では、tfm.optimization.ExponentialMovingAverage に実装されている。
主な動作は以下
-
dynamic_decay
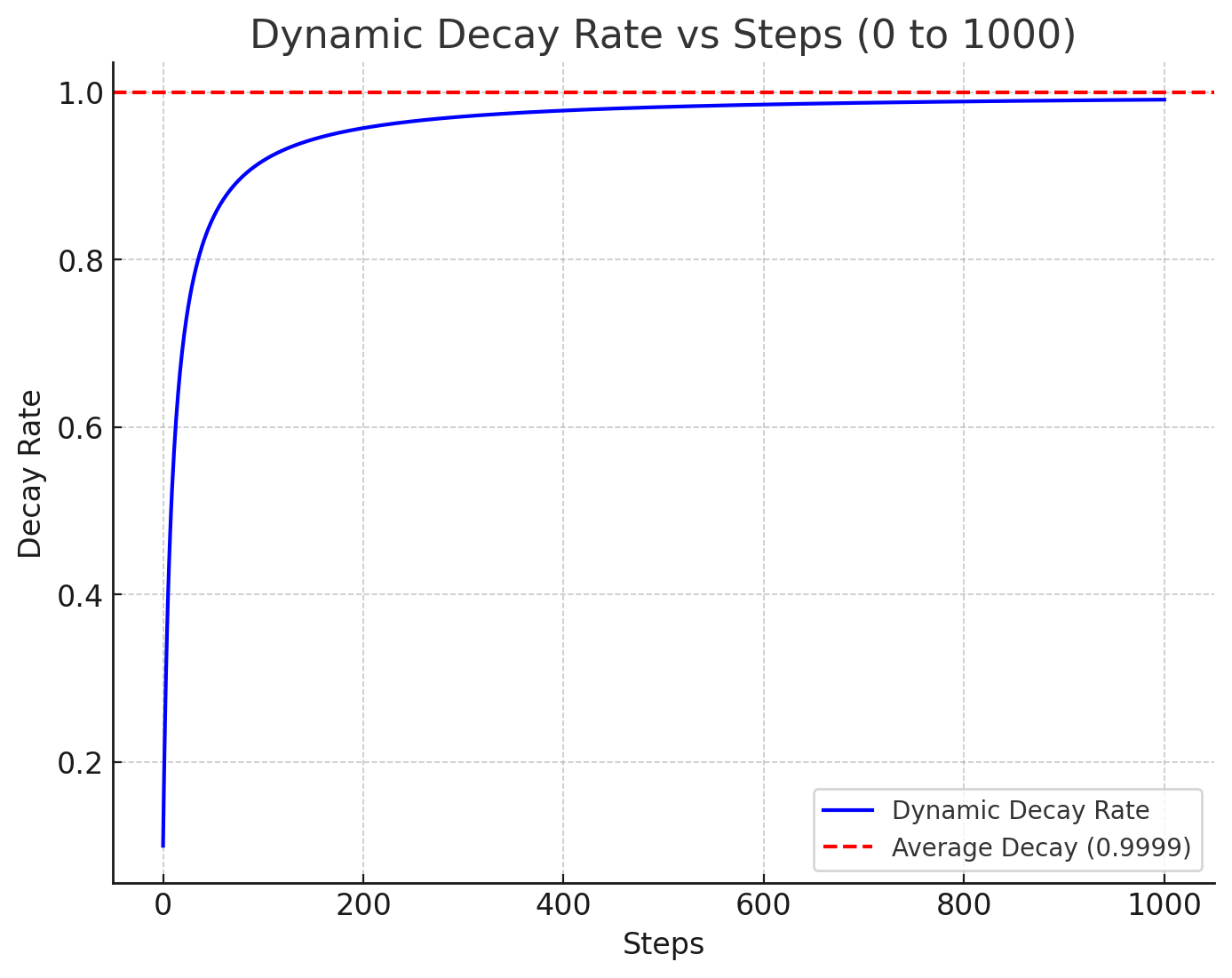
減衰率が0.1からはじまり、ステップごとに増加し、指定の減衰率に近づく。適用される減衰率 = min(指定した減衰率(最大), (1. + ステップ数) / (10. + ステップ数))初期の更新を優先する仕組みであり、たとえば、指定した減衰率が0.9999のとき、0から1000ステップまでの適用される減衰率は以下である。
-
trainable_weights_only
Model EMAを適用するパラメータに学習可能なパラメータのみかすべてのパラメータかを指定する。すべてのパラメータの場合、batch normalization 移動平均と分散も含まれる。
このtfm.optimization.ExponentialMovingAverage をJax、Flax、Optaxを利用して実装する。
Model EMAのパラメータ更新部分の実装
dynamic_decayの部分を実装する。
Optaxのemaを参考に実装する。メソッド名をema_v2としてoptax.emaと区別する。
実装する際のポイントとして、
- 減衰率の最大を
average_decayとして初期化し、保持しておく。 -
update_fnメソッドで適用する更新率new_decayを下記で更新する。
ステップ数は、optax.EmaStateで管理するcountを利用する。new_decay = jnp.minimum( average_decay, (1.0 + state.count) / (10.0 + state.count) )
実装の全体は以下。
from typing import Any, Optional
import jax.numpy as jnp
from optax import EmaState
from optax import tree_utils as otu
from optax._src import base
from optax._src import numerics
from optax._src import utils
def ema_v2(
decay: float, debias: bool = True, accumulator_dtype: Optional[Any] = None
) -> base.GradientTransformation:
"""Compute an exponential moving average of past updates.
Refference:
- https://optax.readthedocs.io/en/latest/api/transformations.html#optax.ema
- https://www.tensorflow.org/api_docs/python/tfm/optimization/ExponentialMovingAverage
"""
accumulator_dtype = utils.canonicalize_dtype(accumulator_dtype)
average_decay = decay
def init_fn(params):
return EmaState(
count=jnp.zeros([], jnp.int32),
ema=otu.tree_zeros_like(params, dtype=accumulator_dtype),
)
def update_fn(updates, state, params=None):
del params
new_decay = jnp.minimum(
average_decay, (1.0 + state.count) / (10.0 + state.count)
)
count_inc = numerics.safe_increment(state.count)
updates = new_ema = otu.tree_update_moment(
updates, state.ema, new_decay, order=1
)
if debias:
updates = otu.tree_bias_correction(new_ema, new_decay, count_inc)
state_ema = otu.tree_cast(new_ema, accumulator_dtype)
return updates, EmaState(count=count_inc, ema=state_ema)
return base.GradientTransformation(init_fn, update_fn)
学習時
trainable_weights_only=Trueの部分を含め実装する。
trainable_weights_only=True(すべてのパラメータを対象)とした場合、batch normalization 移動平均と分散も対象とする必要がある。Flaxの場合、このパラメータはbatch_statsで管理される(The batch_stats collection - Flaxを参照)。このため、batch_statsに対してModel EMAを適用し、パラメータを管理する必要がある。
パラメータの管理方法
train_stateに学習可能なパラメータに対するModel EMAema_stateに加え、normalization 移動平均と分散に対するModel EMAema_batch_statsを追加する。
class TrainStateWithBatchNorm(train_state.TrainState):
batch_stats: Any
dynamic_scale: dynamic_scale_lib.DynamicScale
ema_tx: optax.GradientTransformation = struct.field(pytree_node=False)
ema_state: optax.OptState = None
ema_batch_stats: optax.OptState = None
パラメータの初期化
ema_stateとema_batch_statsの両方を初期化する。ema_v2メソッドでoptax.GradientTransformation オブジェクトを初期化、pramsとbatch_statsのemaを管理するEmaStateを初期化、保持しておく。
def create_train_state(
rngs: Dict[str, jnp.ndarray],
config: ml_collections.ConfigDict,
model,
learning_rate_fn,
):
...
params, batch_stats = initialized(rngs, config.image_size, model)
ema_tx = None
ema_state = None
ema_batch_stats = None
ema_tx = ema_v2(config.model_ema_decay)
ema_state = ema_tx.init(params)
ema_batch_stats = ema_tx.init(batch_stats)
state = TrainStateWithBatchNorm.create(
apply_fn=model.apply,
params=params,
tx=tx,
batch_stats=batch_stats,
dynamic_scale=dynamic_scale,
ema_tx=ema_tx,
ema_state=ema_state,
ema_batch_stats=ema_batch_stats,
)
学習時
ema_stateとema_batch_statsの両方にEMAを適用する。
def train_step(...):
...
grad_fn = jax.value_and_grad(loss_fn, has_aux=True)
aux, grads = grad_fn(state.params)
# Re-use same axis_name as in the call to `pmap(...train_step...)` below.
grads = lax.pmean(grads, axis_name="batch")
new_state = state.apply_gradients(
grads=grads, batch_stats=new_model_state["batch_stats"]
)
_, new_ema_state = new_state.ema_tx.update(
new_state.params, new_state.ema_state
)
new_state = new_state.replace(ema_state=new_ema_state)
_, new_ema_batch_stats = new_state.ema_tx.update(
new_state.batch_stats, new_state.ema_batch_stats
)
new_state = new_state.replace(ema_batch_stats=new_ema_batch_stats)
...
推論時
ema_stateとema_batch_statsを使って推論
def eval_step(
...
):
params = state.ema_state.ema
batch_stats = state.ema_batch_stats.ema
variables = {"params": params, "batch_stats": batch_stats}
logits = state.apply_fn(variables, batch["image"], train=False, mutable=False)