JAX/Flax/OptaxでEfficientNetをやってみる
はじめに
JAX/Flax/Optaxを利用し、EfficientNetのモデルを構築する。ImageNet2012の学習データを用い、精度(Top1-Acc)が再現できるか確認する。
参照
モデル実装
いままでと同様、以下のリポジトリで実装した。
- https://github.com/NobuoTsukamoto/jax_examples
- https://github.com/NobuoTsukamoto/jax_examples/tree/main/classification
EfficientNetのモデルはEfficientNetクラスで定義し、以下を参照。
EfficientNetの各バリアントはdepth、width、resolution で決まる。EfficientNetクラスのwidth_coefficient、depth_coefficientメンバ変数、およびモデルへの入力shapeで変更可能とした。EfficientNet-B0のモデル定義は以下となる。
-
EfficientNet_B0
- depth = 1.0
- width = 1.0
- resolution = 224
学習のセットアップ
学習パラメータを以下に示す。元論文および実装を参照し、学習パラメータはTPUv2-8のリソースで実行できるよう調整した。乱数のシード値は42ですべて固定した。
学習リソース
学習はTPUv2-8で行う。
Data augmentation
元実装の"2. Using Pretrained EfficientNet Checkpoints"にあるBaseline preprocessingとする。
Optimizer
Optimizerはoptax.rmspropsを利用。MobileNet v3と同様、TF1のOptimizerを利用しているため、Initial scale、Eps in Rootの値に注意する。また、epsilonの値が大きいことにも注意する(別項にも記載するがepsilonに1e-07などの小さい値を指定すると学習が進まない)。
元実装の以下を参照した。
| Config | Params | Note |
|---|---|---|
| optimizer | RMSProp | |
| Learning rate | - | schedulerで指定(別表) |
| Decay | 0.9 | |
| Eps | 0.001 | |
| Initial scale | 1.0 | |
| Eps in sqrt | True | * |
| Eentered | False | * |
| Momentum | 0.9 | |
| Nesterov | False | * |
| Bias correction | False | * |
- *はデフォルト引数のまま
Learning scheduer
LR ScheduerはWarmup exponential decayで、optax.warmup_exponential_decay_scheduleを利用する。
以下のパラメータを指定する。learning_rate、transition_stepsはバッチサイズによる調整を行う。
| Config | Params | Note |
|---|---|---|
| Optimizer schedule | Warmup exponential decay | |
| Initial learning rate | 0.0 | |
| Learning rate | 0.128 | 0.016 * batch_size(2048) / 256 |
| Warmup epochs | 5 | |
| Exponential decay rate | 0.97 | |
| Transition steps | 1502 | 2.4 * steps_per_epoch (626) |
| LR drop staircase | True | |
| Num epochs | 350 |
Model setup
モデルの入力サイズ、Batch normalization、Dropupt、Stochastic depthに指定するパラメータは以下。
| Config | Params | Note |
|---|---|---|
| Input size | 224x224 | |
| BatchNorm momentum | 0.99 | |
| BatchNorm esp | 0.001 | |
| Dropout | 0.2 | |
| Stochastic depth | 0.2 | |
| Model dtype | bfloat16 | |
| Batch size | 2048 |
Kernel initializers
flax.linen.initializers.variance_scalingを利用し、Conv、およびDenseレイヤーを初期化を指定する。
| Config | Params | Note |
|---|---|---|
| Conv | truncated normal scale=2.0 mode=fan_out |
|
| Dense | truncated normal scale=1.0/3.0 mode=fan_out |
コメント参照 |
Loss
optax.losses.smooth_labelsを利用し、Label smoothingを指定する。
| Config | Params |
|---|---|
| Label smoothing | 0.1 |
L2 weight decay
optax.add_decayed_weightsを利用し、L2 weight decayを指定する。指定や除外するopeについては、前回(JAX/Flax/OptaxでMobileNet v2をやってみる)と同様。
| Config | Params |
|---|---|
| L2 weight decay | 0.00001 |
Model EMA
Model EMAを有効にし、以下のパラメータを指定する。前回(JAX/Flax/OptaxでMobileNet v3 smallをやってみる)と同様。
| Config | Params |
|---|---|
| EMA decay | 0.9999 |
実装でつまづいた点
以下、実装でつまづいた点を記載する。
Global average poolingでshapeを残したことにより学習でNanが発生
jax.numpy.meanでGlobal average poolingを行う際、keepdims=Trueを指定してしまった。これにより学習がまったく進まない(Nan)。
以下、誤り。
x = jnp.mean(x, axis=(1, 2), keepdims=True)
RMSPropのeplisionの指定誤りで学習が進まない
MobileNet v3と同様、RMSPropのepsilonには通常より大きい値が指定される。
元実装では、以下で指定されている(MobieNet v3より更に大きい)。
optax.rmspropのデフォルト値(1e-08)では小さすぎて学習が進まなかった。
学習1回目
コード
結果
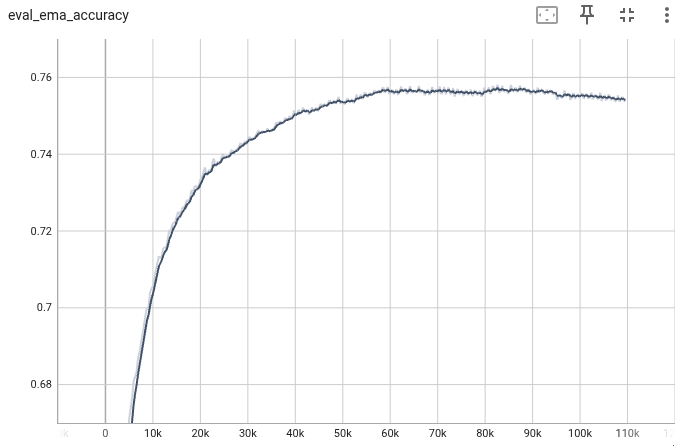
Model EMAのTop-1 , Top-5 Accuracyは、もとの実装に及ばなかった。
| Epoch | Top-1 | Top-5 |
|---|---|---|
| 350 | 75.41% | 92.48 |
実装の見直し
L2 weight decayで除外するOpeの差異
もとの実装
batch normalizationのみ除外
実装
DepthWiseとBatchNormとbiasを除外
TpuBatchNormalization(Sync Batch Normalization)
もとの実装
実装
コード
結果
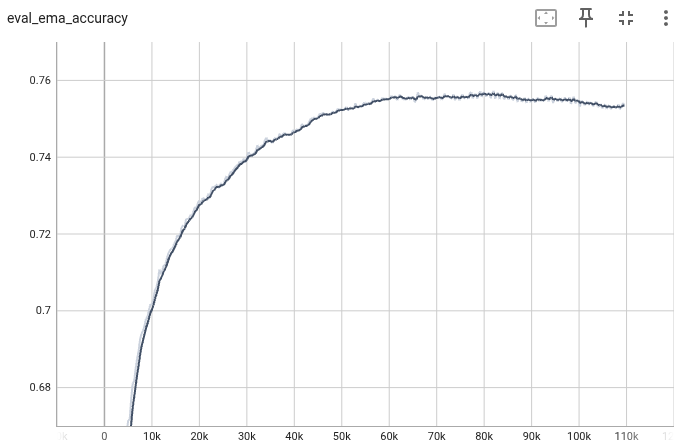
Model EMAのTop-1 , Top-5 Accuracyは、もとの実装に及ばなかった。
| Epoch | Top-1 | Top-5 |
|---|---|---|
| 350 | 75.39% | 92.33 |
3回目
学習パラメータの見直し
-
https://github.com/tensorflow/tpu/issues/546
- 実装元では、FP32で学習
-
https://github.com/tensorflow/tpu/issues/509
- 1デバイスあたりの効率的なバッチサイズは256にする
- TpuBatchNormalizationは、デバイス数が8以下の場合は有効でない?
初期値の見直し
実装元
修正
結果
- FP32(バッチサイズ=2048)で学習が一番高い精度となった。ただし、元実装の精度までは再現できなかった。
- TPUv2-8では、FP32のバッチサイズ=4096はOOMとなる。
- BF16の学習は、バッチサイズを2048, 4096で試したが、FP32(バッチサイズ=2048)に及ばなかった。
| Precision | Batch size | Epoch | Top-1 | Top-5 |
|---|---|---|---|---|
| FP32 | 2096 | 256 | 76.04 | 92.60 |
| BF16 | 2096 | 216 | 75.80 | 92.52 |
| BF16 | 4096 | 227 | 75.67 | 92.51 |