XBRLから抽出した財務諸表をもとに自分用のExcel表をつくる 前編



好きな勘定科目を抜粋したり、指標が入った表をつくる
XBRLから抽出した財務諸表をもとに、自分の好きな勘定科目だけを抜粋する、あるいはそこに指標を混ぜるということで、GPT-4oを使ってコードを書いていきます。前編です。
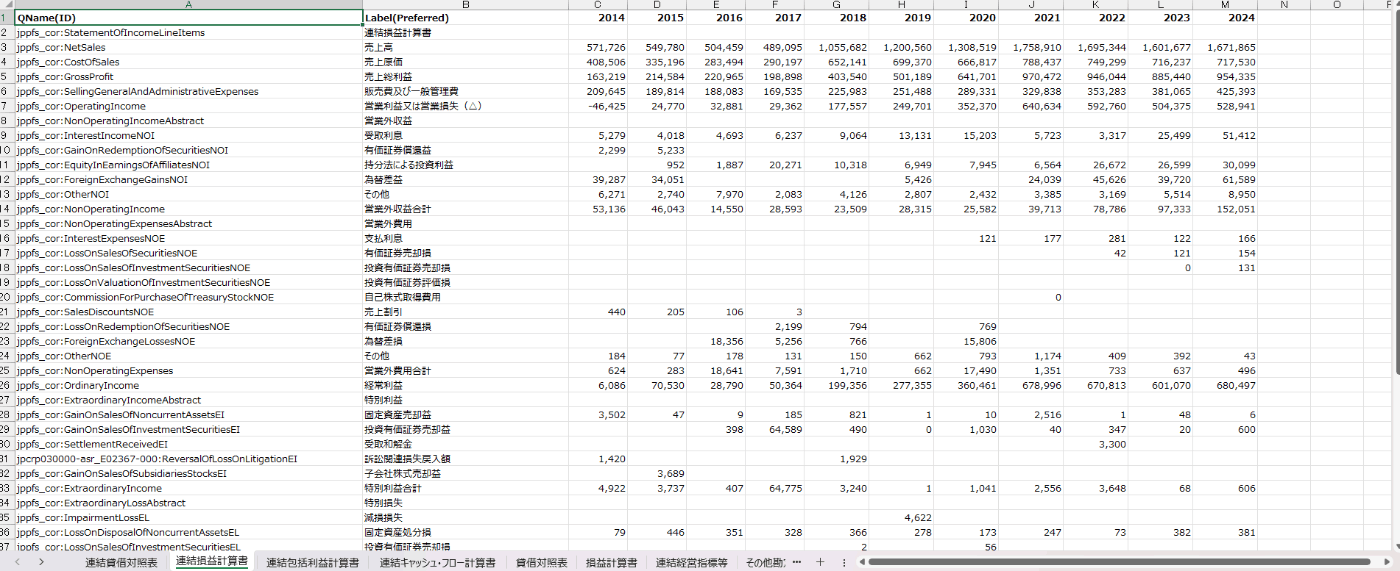
抽出した10年分の財務諸表
MasterファイルをExcelで作成する
好みの表を作るためのリストとして「Master_Analytics.xlsx」というExcelファイルを作成します。(名前は何でも構いません)
そのあと、別途XBRLから抽出した財務諸表の勘定科目が出力されたExcelファイルを開き、お好みで勘定科目を見繕っていきます。
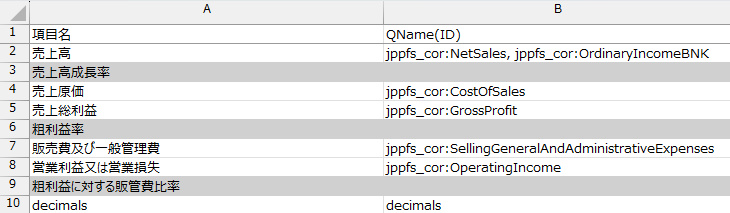
- Master_Analytics.xlsxのA1に「項目名」、B1に「QName(ID)」と入力します。

- Sheetの名前を「Master」としておきます。

- A列のA2以降に、項目として自分が確認したい勘定科目や、確認したい指標を入れていきます。
ここでは例として、A2から順番に「売上高」「売上高成長率」「売上原価」「売上総利益」「粗利益率」「販売費及び一般管理費」「営業利益又は営業損失」「粗利益に対する販管費比率」「decimals」を入力します。
例えば売上高は財務諸表の項目ですが、売上高成長率や粗利益率といったものは財務諸表に掲載されていないため、計算を行って出力します。
decimalsは数値の精度です。XBRLでは主に-6(百万円)か-3(千円)辺りが使用されています。(項目によって2とかもありますが。)
詳細は省きますが、その年度で最も多く使用されているdecimalsの単位を出力するようにしています。
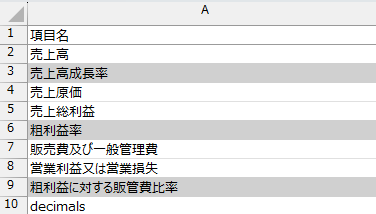 計算が必要なものはセルの色をグレーにしています
計算が必要なものはセルの色をグレーにしています
4. B列には、XBRLで使用している要素名を入力していきます。例えば、売上高であれば「jppfs_cor:NetSales」です。ただ、業種によって、例えば銀行であればこの売上高は「経常収益」と記載されていて、要素名も「jppfs_cor:OrdinaryIncomeBNK」だったりします。
こういったパターンに対応できるようにもしたいので、「jppfs_cor:NetSales, jppfs_cor:OrdinaryIncomeBNK」という風に区切り、複数の要素名を受け付けるようにします。

5. 「売上高成長率」のように計算を行うセルの場合、B列には何も入力しません。
6. 「decimals」については、要素名ではなく計算も行わないです。抽出した財務諸表から情報を取得する形になるので「decimals」と入力しておきます。
Pythonファイルを2つ作成する
data_extraction.pyとcalculate_metrics.pyを準備します。
data_extraction.pyではデータの読み込みや整理を、calculate_metrics.pyで各種計算を行います。
まずはdata_extraction.pyからコードを書いていきます。
ここでは、Excelファイルから財務諸表のデータを読み取り、整理し、出力用のデータを作っていきます。
ライブラリの読み込み
import pandas as pd
import numpy as np
pandasとnumpyというライブラリを使います。pandasは表(データフレーム)を扱えて便利です。numpyは数字の計算を簡単にするためのライブラリとなっています。
QName(ID)を使用して、Excelのシートからデータを探し出す関数
invalid_strings = ['o', '△']
async def extract_xbrl_data_from_excel(qnames_param, financial_sheets_param, log_function=None):
# 各シートを順に処理
for sheet_name, sheet_data in financial_sheets_param.items():
# 'QName(ID)'列の存在確認
if 'QName(ID)' not in sheet_data.columns:
if log_function:
await log_function(f"[ERROR] 'QName(ID)' column not found in sheet: {sheet_name}")
continue
# 'QName(ID)'列がqnames_paramに含まれる行を取得
data_row = sheet_data[sheet_data['QName(ID)'].isin(qnames_param)]
# データが見つかった場合、その行の3列目以降を返す
if not data_row.empty:
return data_row.iloc[0, 2:] # 年度ごとのデータを取得('QName(ID)', 'Label(Preferred)'を除く)
# 見つからなかった場合のエラーログ
if log_function:
await log_function("[ERROR] No matching data found in any sheet.")
return None
-
invalid_strings = ['o', '△']というリストを作成し、使用したくないデータを指定します。ここではoと△がデータの中にあった場合、無効として扱います。 -
extract_xbrl_data_from_excel関数を作成します。関数にはasyncをつけて非同期関数とします。この関数は、指定されたQName(ID)を使用して、Excelのシートからデータを探し出す関数です。該当するデータが見つかった場合、そのデータを返します。
qnames_paramはQName(ID)のリストです。financial_sheets_paramは財務情報が入ったExcelシートのデータとなっていて、シートごとに辞書の形で情報が入っています。
たとえば、qnames_paramが['jppfs_cor:NetSales', 'jppfs_cor:OrdinaryIncomeBNK']だった場合、Excelの中からjppfs_cor:NetSalesやjppfs_cor:OrdinaryIncomeBNKがある行を探すということです。
log_function=Noneは、ログ用の関数を受け取れるようにするものです。 - forループを使用して、すべてのシートを順番に見ていきます。
financial_sheets_param.items()でシートの名前であるsheet_nameと、そのシートに含まれるデータsheet_dataをペアとして取り出していきます。
sheet_nameは「連結損益計算書」などが入り、sheet_dataにjppfs_cor:NetSalesが116192.0などの情報が入っています。 - if文を使用して、各シートに
QName(ID)という列が存在するか確認します。
存在しない場合、log_functionを使用してエラーメッセージを出力します。 -
sheet_dataから、qnames_paramに含まれるQName(ID)に一致する行だけを抽出し、data_rowに格納します。
.isin(qnames_param)は、QName(ID)のリストであるqnames_paramの中にあるIDと一致するかをチェックするためのものです。
たとえばqnames_paramが['jppfs_cor:NetSales', 'jppfs_cor:OrdinaryIncomeBNK']となっていた場合、この行はQName(ID)列にjppfs_cor:NetSalesまたはjppfs_cor:OrdinaryIncomeBNKが含まれている行を取り出します。
もし、sheet_dataの中に以下のようなデータがあった場合、
| QName(ID) | Label(Preferred) | 2022 | 2023 | 2024 |
|---|---|---|---|---|
| jppfs_cor:NetSales | 売上高 | 1,695,344 | 1,601,677 | 1,671,865 |
| jppfs_cor:CostOfSales | 売上原価 | 749,299 | 716,237 | 717,530 |
結果は次のようにjppfs_cor:NetSalesの行のみ取り出します。
| QName(ID) | Label(Preferred) | 2022 | 2023 | 2024 |
|---|---|---|---|---|
| jppfs_cor:NetSales | 売上高 | 1,695,344 | 1,601,677 | 1,671,865 |
-
if not data_row.empty:で、data_rowが空っぽかどうかをチェックします。 -
data_row.iloc[0, 2:]をreturnで返します。これは、data_rowの最初の行から、3列目以降のデータを取得するものです。[0, 2:]とすることで、最初の行から2番目以降のすべての列を選ぶことになります。
次のようにjppfs_cor:NetSalesが取り出されたとき、
| QName(ID) | Label(Preferred) | 2022 | 2023 | 2024 |
|---|---|---|---|---|
| jppfs_cor:NetSales | 売上高 | 1,695,344 | 1,601,677 | 1,671,865 |
data_row.iloc[0, 2:]は[1,695,344, 1,601,677, 1,671,865]といった形で、年度のデータだけを取り出します。
7. 最後に、もしデータが見つからなかった場合はlog_functionを使用してエラーメッセージを出力します。
また、return NoneでNoneを返すようにします。
データを使用する際の順序を整理する関数
def load_master_data(master_file_path):
# ExcelファイルからMasterシートを読み込む
master_data = pd.read_excel(master_file_path, sheet_name='Master')
# データのインデックスをリセットして、新しい'order'列として使う
master_data = master_data.reset_index().rename(columns={'index': 'order'})
# '項目名'列の前後に余分な空白があれば削除する
master_data['項目名'] = master_data['項目名'].astype(str).str.strip()
# 'order'列をfloat型に変換する(番号を整数として扱えるように)
master_data['order'] = master_data['order'].astype(float)
# 加工したデータを返す
return master_data
-
pd.read_excelでExcelファイルの'Master'シートを読み込んで、データをmaster_dataとして格納します。
たとえばmaster_file_pathがMaster_Analytics.xlsxであれば、そのファイルの中にあるMasterシートの内容を読み込みます。 -
master_data.reset_index()を使用してデータ上のインデックス(自動生成された行番号)をリセットし、renameでorderという列にリネームします。
この列は、各項目に順番を付けるのに使います。
0が売上高、1が売上高成長率、2が売上原価…といった行番号になります。 -
master_data['項目名'].astype(str).str.strip()を使用して、項目名の列に余分な空白、たとえば名前前後のスペースなどが含まれている場合、それを削除し、master_data['項目名']に格納します。
これによりデータの比較や検索が正確に行えます。 -
master_data['order'].astype(float)を使用して、order列のデータ型をfloat(小数)に変換します。この列はソートに使用することがあるため、番号を整数値や小数として扱いやすくします。
例えば、orderが整数の1, 2, 3の場合、これを1.0, 2.0, 3.0といったように変換しています。 - 最終的な
master_dataをreturnで返します。
証券コードが指定された財務諸表のエクセルを読み込む関数
def load_financial_data(company_code):
# 証券コードを使って財務データファイルのパスを作成
financial_file_path = f'data/{company_code}/{company_code}_consolidated_financial_statements.xlsx'
# 指定したファイルのすべてのシートを読み込み、辞書として返す
return pd.read_excel(financial_file_path, sheet_name=None)
-
company_codeを使用して財務データファイルのパスを作成し、financial_file_pathに格納します。
-
pd.read_excelを使用して、financial_file_pathに入っているExcelファイルの中のすべてのシートを読み込みます。
sheet_name=Noneと指定することで、ファイル内の全てのシートを読み込み、それを「辞書」として返しています。
この「辞書」はシート名をキー(連結貸借対照表, 連結損益計算書など)として、そのシートのデータをデータフレーム形式で持つ構造になっています。
たとえば7974_consolidated_financial_statements.xlsxの連結貸借対照表や連結損益計算書シートにあるデータを辞書として返します。
財務諸表のエクセルにある最初のシートから、年度に関する列名を取得する関数
def get_years(financial_data_sheets):
# 財務データの辞書から最初のシートを取得
first_sheet = next(iter(financial_data_sheets.values()))
# 最初のシートの3列目以降の列名(年度)をリストとして取得して返す
return first_sheet.columns[2:].tolist()
-
financial_data_sheets.value()を使用して、Excelファイル内の各シートにある辞書形式の値を返し、first_sheetに格納します。
iterやnextは少しややこしいのですが、ものすごくざっくり説明すると「辞書に入っているシートの中から最初のシートを取り出す」ということです。
例えばfinancial_data_sheetsが[連結貸借対照表, 連結損益計算書, 連結包括利益計算書]となっている場合、その最初のシートである「連結貸借対照表」のデータを取り出します。 -
first_sheet.columnsを使用して、最初のシートのすべての列の名前(QName(ID), Label(Preferred), 2014, 2015,……)を返します。
[2:]を使用することで最初の2列を除いて、年度の列だけを選択するようにします。
.tolist()を使って、その列名をリストとして返します。
たとえばfirst_sheetが['QName(ID)', 'Label(Preferred)', '2022', '2023', '2024']となっていた場合、first_sheet.columns[2:]は['2022', '2023', '2024']となります。
必要な勘定科目を整理し、新しいデータフレームにまとめる関数
async def extract_financial_data(master_data, financial_data_sheets, years, log_function=None):
# データフレームの列データ型を指定
dtype_dict = {'order': float, '項目名': str, **{year: float for year in years}}
output_data = pd.DataFrame(columns=['order', '項目名'] + years).astype(dtype_dict)
for _, master_row in master_data.iterrows():
item_name = master_row['項目名']
qname_ids = master_row.get('QName(ID)', None)
order = master_row['order']
# 項目名が無効でないことを確認
if pd.notna(item_name) and item_name not in invalid_strings:
item_name = item_name.strip()
# QName(ID)がある場合
if pd.notna(qname_ids) and str(qname_ids).strip():
data = await extract_xbrl_data_from_excel(str(qname_ids).split(','), financial_data_sheets)
new_row = {'order': order, '項目名': item_name}
for year in years:
new_row[year] = data.get(year, np.nan) if data is not None else np.nan
output_data = pd.concat([output_data, pd.DataFrame([new_row], columns=output_data.columns)], ignore_index=True)
else:
# QName(ID)が無い場合のプレースホルダー作成
new_row = {'order': order, '項目名': item_name, **{year: np.nan for year in years}}
output_data = pd.concat([output_data, pd.DataFrame([new_row], columns=output_data.columns)], ignore_index=True)
# 項目名の空白を削除
output_data['項目名'] = output_data['項目名'].astype(str).str.strip()
output_data.reset_index(drop=True, inplace=True)
return output_data
-
dtype_dictという名前の辞書を作成し、order列をfloatに、項目名列をstrに、yearの列をfloatに指定します。
このようにデータ型(数値や文字列など)を指定することで、データが正確に取り扱いできるようにします。 -
pd.DataFrameで空のデータフレームを作成します。列はorder,項目名,yearsになります。 - forループを使用してデータフレームの各行に対して繰り返し処理を行います。
_にはインデックス番号が入ります。ただ、インデックス番号は使わないので_としています。
master_rowにはデータフレームのデータが入ります。.iterrows():を使用することで、master_dataの各行を順番に取り出して使えるようになります。
たとえば、master_rowには{'order': 0.0, '項目名': '売上高', 'QName(ID)': 'jppfs_cor:NetSales, jppfs_cor:OrdinaryIncomeBNK'}のようなデータが入ります。 - 取得したデータを、それぞれの変数に格納します。
item_nameには項目名を、qname_idsにはQName(ID)を、orderにはorderを格納します。 -
pd.nonta(item_name)を使用して、項目名にinvalid_stringsとして指定した['o', '△']が入っていないかを確認します。
問題なければitem_name.strip()で空白を削除してitem_nameに格納します。 - if文を使用して
pd.notna(qname_ids)とstr(qname_ids).strip():でqname_idsが欠損していないことを確認し、前後の空白を削除します。 -
extract_xbrl_data_from_excel()関数を呼び出し、財務諸表のデータからQName(ID)に沿った各年度のデータを抽出し、dataに格納します。たとえば2014は571726.0といった情報です。 -
new_rowで新しくデータ行を作成する準備を行います。ここではorderと項目名を適用し、new_rowに格納します。 - forループを使用して年度ごとに繰り返し処理を行い、各年度に対してのデータを取得します。もし取得したデータが存在すれば
new_rowに値を格納し、存在しない場合は空のデータであるNaNを格納します。 -
pd.concatを使用して、新しいデータであるnew_rowを既存のデータフレームであるoutput_dataに追加します。
また、データを追加したときにインデックス(行番号)が重複しないようにignore_index=Trueで新しいデータフレームのインデックスをリセットします。 -
売上高成長率などのQName(ID)が無い場合にも行は同じように準備する必要があるので、仮の行としてouput_dataを作成します。
計算自体は、あとから行います。 -
str.strip()を使用して、項目名の空白を削除します。 -
output_dataのインデックスをリセットします。 -
output_dataをreturnで返します。
data_extraction.pyのまとめ
コードをまとめると、下記のようになります。
import pandas as pd
import numpy as np
invalid_strings = ['o', '△']
async def extract_xbrl_data_from_excel(qnames_param, financial_sheets_param, log_function=None):
# 各シートを順に処理
for sheet_name, sheet_data in financial_sheets_param.items():
# 'QName(ID)'列の存在確認
if 'QName(ID)' not in sheet_data.columns:
if log_function:
await log_function(f"[ERROR] 'QName(ID)' column not found in sheet: {sheet_name}")
continue
# 'QName(ID)'列がqnames_paramに含まれる行を取得
data_row = sheet_data[sheet_data['QName(ID)'].isin(qnames_param)]
# データが見つかった場合、その行の3列目以降を返す
if not data_row.empty:
return data_row.iloc[0, 2:] # 年度ごとのデータを取得('QName(ID)', 'Label(Preferred)'を除く)
# 見つからなかった場合のエラーログ
if log_function:
await log_function("[ERROR] No matching data found in any sheet.")
return None
def load_master_data(master_file_path):
# ExcelファイルからMasterシートを読み込む
master_data = pd.read_excel(master_file_path, sheet_name='Master')
# データのインデックスをリセットして、新しい'order'列として使う
master_data = master_data.reset_index().rename(columns={'index': 'order'})
# '項目名'列の前後に余分な空白があれば削除する
master_data['項目名'] = master_data['項目名'].astype(str).str.strip()
# 'order'列をfloat型に変換する(番号を整数として扱えるように)
master_data['order'] = master_data['order'].astype(float)
# 加工したデータを返す
return master_data
def load_financial_data(company_code):
# 証券コードを使って財務データファイルのパスを作成
financial_file_path = f'data/{company_code}/{company_code}_consolidated_financial_statements.xlsx'
# 指定したファイルのすべてのシートを読み込み、辞書として返す
return pd.read_excel(financial_file_path, sheet_name=None)
def get_years(financial_data_sheets):
# 財務データの辞書から最初のシートを取得
first_sheet = next(iter(financial_data_sheets.values()))
# 最初のシートの3列目以降の列名(年度)をリストとして取得して返す
return first_sheet.columns[2:].tolist()
async def extract_financial_data(master_data, financial_data_sheets, years, log_function=None):
# データフレームの列データ型を指定
dtype_dict = {'order': float, '項目名': str, **{year: float for year in years}}
output_data = pd.DataFrame(columns=['order', '項目名'] + years).astype(dtype_dict)
for _, master_row in master_data.iterrows():
item_name = master_row['項目名']
qname_ids = master_row.get('QName(ID)', None)
order = master_row['order']
# 項目名が無効でないことを確認
if pd.notna(item_name) and item_name not in invalid_strings:
item_name = item_name.strip()
# QName(ID)がある場合
if pd.notna(qname_ids) and str(qname_ids).strip():
data = await extract_xbrl_data_from_excel(str(qname_ids).split(','), financial_data_sheets, log_function)
new_row = {'order': order, '項目名': item_name}
for year in years:
new_row[year] = data.get(year, np.nan) if data is not None else np.nan
output_data = pd.concat([output_data, pd.DataFrame([new_row], columns=output_data.columns)], ignore_index=True)
else:
# QName(ID)が無い場合のプレースホルダー作成
new_row = {'order': order, '項目名': item_name, **{year: np.nan for year in years}}
output_data = pd.concat([output_data, pd.DataFrame([new_row], columns=output_data.columns)], ignore_index=True)
# 項目名の空白を削除
output_data['項目名'] = output_data['項目名'].astype(str).str.strip()
output_data.reset_index(drop=True, inplace=True)
return output_data
後編へ続きます。
Discussion