🐧
XBRLから抽出した財務諸表をもとに自分用のExcel表をつくる 後編



好きな勘定科目を抜粋したり、指標が入った表をつくる
XBRLから抽出した財務諸表をもとに、自分の好きな勘定科目だけを抜粋する、あるいはそこに指標を混ぜるということで、GPT-4oを使ってコードを書いていきます。後編です。
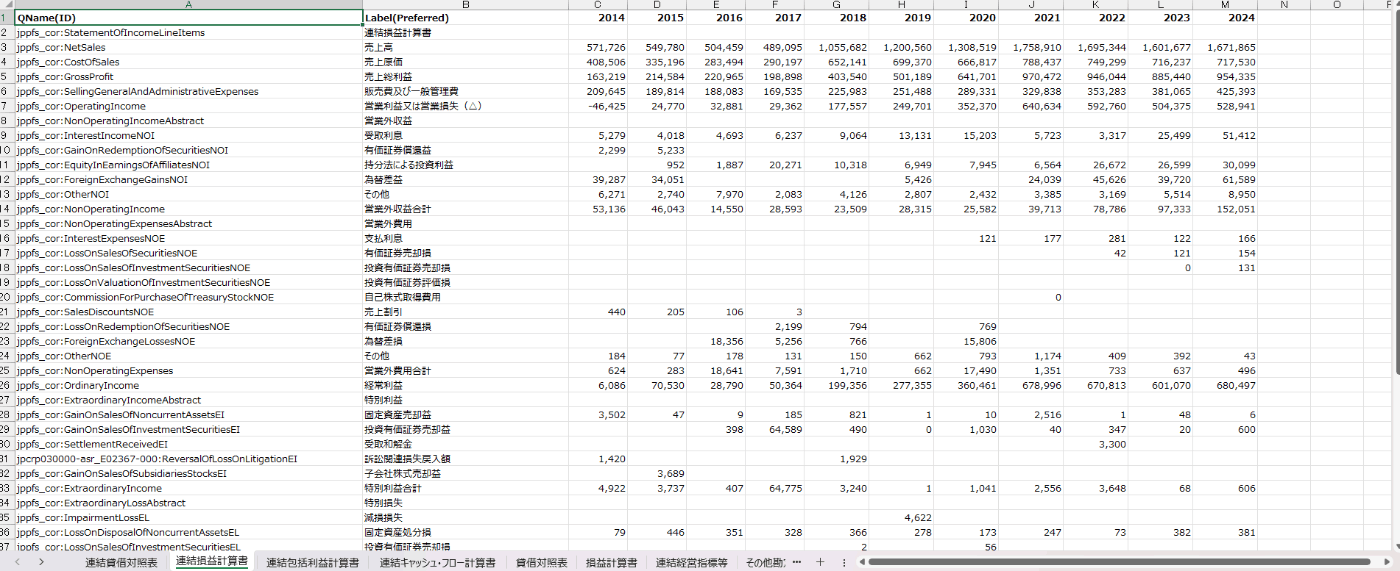
抽出した10年分の財務諸表
calculate_metrics.pyのコードを書く
前編ではdata_extraction.pyのコードを書いたので、後編では各種計算を行うためのcalculate_metrics.pyのコードを書いていきます。
ライブラリの読み込み
calculate_metrics.py
import pandas as pd
import numpy as np
from data_extraction import load_master_data, load_financial_data, get_years, extract_financial_data
pandasとnumpyは前編で使用したものと同じですが、それぞれ表や数字の計算を簡単にするためのライブラリです。
前編と異なるのはfrom data_extractionで、これはdata_extraction.pyで記載した関数を使えるようにするためのものです。
すでに計算を行ったかどうかのチェック
calculate_metrics.py
calculated_items = set()
売上高成長率や粗利益率といった計算をおこなったとき、それらの項目名をcalculated_itemsに追加します。
これにより、同じ計算を行おうとした場合に「計算済みであるためにスキップする」という判断が可能になります。
特定の項目に対してorderを決定するための関数
calculate_metrics.py
def get_order_value(output_data, master_data, item_name):
# master_dataから指定された'item_name'に対応する'order'列の値を取得
order_values = master_data[master_data['項目名'] == item_name]['order'].values
# 'order_values'に値があり、最初の値がNaN(欠損値)でない場合
if len(order_values) > 0 and pd.notna(order_values[0]):
return float(order_values[0]) # その'order'の値を返す
# それ以外の場合、'output_data'の'order'列の最大値に1を足して返す(全て欠損値であれば0を返す)
return float(output_data['order'].max() + 1 if output_data['order'].notna().any() else 0)
-
get_order_value関数は、処理をする際にデータの並び順を決めたり、新しい項目を追加する際に使用されるorderを決定するための関数です。 -
master_dataからitem_nameに該当する行のorder値を取得します。
たとえば、master_dataが売上高成長率で、orderが1となっている場合、order_valuesには[1.]が格納されます。 - if文を使用して
order_valuesのリストが空でないことと、値が欠損値(NaN)ではないことを確認します。
問題なければ、order_valuesの値をfloat型に変換して返します。 -
master_dataに対応するorderが存在しない場合、新しいorderを決定します。output_data['order'].max() + 1を使用して、既存のorderの最大値に1を追加し、新しいorderを決めます。
if文でoutput_dataに少なくとも1つの値が存在する場合に実行するようにし、すべて欠損値の場合は0を返します。
新たに計算されたデータをDataFrameに追加・更新する関数
calculate_metrics.py
# 新しい行をDataFrameに追加する共通関数
def add_calculated_row(output_data, calculated_data, item_name):
# 計算結果を元に新しい行を作成
df_new_row = pd.DataFrame([calculated_data])
# 全てがNaNの行を追加しないようにチェック
if not df_new_row.isna().all(axis=1).iloc[0]:
# 既存の項目があれば、そのインデックスを取得
idx = output_data.index[output_data['項目名'] == item_name]
# 既存の項目が存在する場合は更新
if not idx.empty:
for col in df_new_row.columns:
output_data.at[idx[0], col] = df_new_row.at[0, col]
else:
# 既存の項目が無ければ新しい行を追加
output_data = pd.concat([output_data, df_new_row], ignore_index=True)
# 更新されたDataFrameを返す
return output_data
-
pd.DataFrame([calculated_data])を使用して、新しい行のDataFrameを作成し、df_new_rowへ格納します。
たとえば{order:0, 項目名:売上高成長率, 2022:-0.036139, 2023:-0.05525, 2024:0.043822}のようなデータフレームが作成されます。 - if文を使用して、
df_new_rowのすべての列が欠損値(NaN)ではないことを確認します。
すべてがNaNであれば追加の必要がないため、この処理をスキップします。 -
output_data内にitem_nameに一致する行のインデックスを取得します。
たとえばitem_nameが売上高成長率で、その項目がすでにoutput_dataに存在する場合、その行のインデックスを取得し、idxに格納します。 -
if not idx.empty:でitem_nameに一致する行がすでに存在するかどうかを確認し、存在する場合はデータを更新する処理を行います。
forループを使用してdf_new_rowの各列に対して繰り返し処理を行います。
df_new_rowの各列をouput_dataの既存の行に代入します。
たとえば、売上高成長率がすでに存在している場合は、その各年のデータを新しい値で更新します。 - 既存の項目がなければ
pd.concatを使用して、df_new_rowをouput_dataに結合します。
このとき、ignore_index=Trueでインデックスもリセットしておきます。
たとえば、売上高成長率がouput_dataに存在しない場合は、新しい行を追加するということになります。 - 最終的に更新された
output_dataをreturnで返します。
売上高成長率を計算する関数
calculate_metrics.py
# 売上高成長率の計算
async def calculate_sales_growth_rate(output_data, years, master_data, log_function=None):
item_name = '売上高成長率'
target_item_name = '売上高'
# 既に計算済みの場合はスキップします
if item_name in calculated_items:
await log_function(f"{item_name} は既に計算済みのため、スキップします。")
return output_data
# 売上高データがあるか確認して取得します
try:
target_data = output_data[output_data['項目名'] == target_item_name].iloc[0]
except IndexError:
if log_function:
await log_function(f"{target_item_name}またはdecimalsのデータが存在しないため、{item_name}を計算できません。")
return output_data
# 'order'や'項目名'を除いた年度ごとの売上高データを取得
years_data = target_data.drop(['order', '項目名'], errors='ignore')
# 順序を取得するための関数を使用してorder値を取得
order = get_order_value(output_data, master_data, item_name)
# 計算結果を保持するための辞書を用意
growth_rates = {'order': order, '項目名': item_name}
prev_value = None # 前の年の売上高を保持する変数
# 各年度について成長率を計算する
for year in years:
current_value = years_data.get(year, None)
# 現在の年と前の年の値が存在する場合、成長率を計算する
if pd.notna(current_value) and pd.notna(prev_value) and prev_value != 0:
growth_rate = (current_value - prev_value) / abs(prev_value)
growth_rates[year] = growth_rate
else:
# 計算できない場合はNaNにする
growth_rates[year] = np.nan
# 現在の値を次のループで前の値として使う
prev_value = current_value
# 計算した成長率をoutput_dataに追加
output_data = add_calculated_row(output_data, growth_rates, item_name)
# 計算済みの項目を記録
calculated_items.add(item_name)
return output_data
-
売上高成長率をitem_nameに格納します。 - 計算する項目は
売上高であるため、こちらをtarget_item_nameに格納します。 - if文で
calculated_itemsにitem_nameがあるかどうかを調べ、既に計算済みである場合は処理をスキップし、ログにメッセージを表示します。 -
ouput_dataから売上高のデータを取得してtarget_dataに格納します。
見つからなかった場合は、ログを表示してouput_dataをreturnでそのまま返します。 -
売上高のデータであるtarget_dataから、orderや項目名を除外して年度ごとの売上高の値を取り出し、years_dataに格納します。 - データフレームに追加するため、
get_order_value関数を呼び出し、orderを取得します。 - 計算結果を保持するための辞書として
growth_ratesを作成します。最初にorderと項目名を設定しておきます。
たとえば{'order': 1.0, '項目名': '売上高成長率'}のようになります。 - 前年の売上高を記録するための変数として
prev_valueを作成し、Noneで初期化します。 - for文を使用し、年度ごとの
売上高成長率を計算します。
years_data.getで現在の年度の売上高を取得し、current_valueに格納します。 - if文で、現在の売上高と前年売上高の両方が存在していて、前年売上高が0でない場合に、成長率を計算するようにします。
-
(current_value - prev_value) / abs(prev_value)で売上高成長率を計算し、growth_rateに格納します。
成長率が計算できない場合はNaNを格納します。 -
current_valueをprev_valueに格納します。これは、現在の年度の売上高を次のループ処理で「前年度の売上高」として使用するためです。 -
add_calculated_row関数を使用し、計算結果をoutput_dataに格納します。 -
calculated_itemsに計算済みの項目としてitem_nameを格納し、重複した計算が行われないようにします。 - 最終的に更新された
output_dataをreturnで返します。
粗利益率を計算する関数
calculate_metrics.py
# 粗利益率の計算
async def calculate_gross_profit_margin(output_data, years, master_data, log_function=None):
item_name = '粗利益率'
# すでに計算済みなら処理をスキップ
if item_name in calculated_items:
return output_data
# 必要なデータが揃っているか確認
if '売上総利益' in output_data['項目名'].values and '売上高' in output_data['項目名'].values:
# '売上総利益'と'売上高'の行データを取得
gross_profit = output_data[output_data['項目名'] == '売上総利益'].iloc[0]
net_sales = output_data[output_data['項目名'] == '売上高'].iloc[0]
# 'order'や'項目名'を除いて年度ごとのデータを取得
years_gross_profit = gross_profit.drop(['order', '項目名'], errors='ignore')
years_net_sales = net_sales.drop(['order', '項目名'], errors='ignore')
# orderの取得
order = get_order_value(output_data, master_data, item_name)
# 計算結果を保存する辞書
gross_profit_margin = {'order': order, '項目名': item_name}
# 各年度について粗利益率を計算
for year in years:
gp = years_gross_profit.get(year, None)
ns = years_net_sales.get(year, None)
# 売上総利益と売上高が存在する場合、粗利益率を計算
if pd.notna(gp) and pd.notna(ns) and ns != 0:
gross_profit_margin[year] = gp / ns # 粗利益率 = 売上総利益 / 売上高
else:
gross_profit_margin[year] = np.nan
# 計算結果を既存のデータに追加
output_data = add_calculated_row(output_data, gross_profit_margin, item_name)
# 計算済みとして記録
calculated_items.add(item_name)
return output_data
-
item_nameに粗利益率を設定します。 -
calculated_itemsを確認し、すでに計算済みである場合は処理をスキップします。 - if文を使用し、
output_dataに売上総利益と売上高のデータが存在するかを確認します。 -
売上総利益をgross_profitに、売上高をnet_salesにそれぞれ格納します。 -
dropを使用してorderや項目名を取り除き、年度ごとのデータをそれぞれyears_gross_profitとyears_net_salesに格納します。 - データフレームに追加するため、
get_order_value関数を呼び出し、orderを取得します。 - 計算結果を保持するための辞書として
gross_profit_marginを作成します。最初にorderと項目名を設定しておきます。
たとえば{'order': 4.0, '項目名': '粗利益率'}のようになります。 - for文を使用し、年度ごとの
粗利益率を計算します。 - 年度ごとの
売上総利益と売上高をgpとnsに格納し、それぞれが存在する場合に粗利益率を計算します。 -
add_calculated_row関数を使用し、計算結果をoutput_dataに格納します。 -
calculated_itemsに計算済みの項目としてitem_nameを格納し、重複した計算が行われないようにします。 - 最終的に更新された
output_dataをreturnで返します。
粗利益に対する販管費比率を計算する関数
基本的には項目や計算方法が異なるだけで、粗利益率を計算する関数と処理方法はそれほど変わりません。
calculate_metrics.py
# 販管費比率の計算
async def calculate_sga_ratio(output_data, years, master_data, log_function=None):
item_name = '粗利益に対する販管費比率'
# すでに計算済みであればスキップ
if item_name in calculated_items:
return output_data
# 必要なデータが揃っているか確認
if '売上総利益' in output_data['項目名'].values and '販売費及び一般管理費' in output_data['項目名'].values:
# '売上総利益'と'販売費及び一般管理費'の行データを取得
gross_profit = output_data[output_data['項目名'] == '売上総利益'].iloc[0]
sga_expenses = output_data[output_data['項目名'] == '販売費及び一般管理費'].iloc[0]
# 'order'や'項目名'を除いた年度ごとのデータを取得
years_gross_profit = gross_profit.drop(['order', '項目名'], errors='ignore')
years_sga_expenses = sga_expenses.drop(['order', '項目名'], errors='ignore')
# orderの取得
order = get_order_value(output_data, master_data, item_name)
# 計算結果を保存する辞書を作成
sga_ratio = {'order': order, '項目名': item_name}
# 各年度について販管費比率を計算
for year in years:
gp = years_gross_profit.get(year, None)
sga = years_sga_expenses.get(year, None)
# 売上総利益と販管費が存在し、売上総利益がゼロでない場合に販管費比率を計算
if pd.notna(gp) and pd.notna(sga) and gp != 0:
sga_ratio[year] = sga / gp # 販管費比率 = 販管費 / 売上総利益
else:
sga_ratio[year] = np.nan
# 計算結果を既存のデータに追加
output_data = add_calculated_row(output_data, sga_ratio, item_name)
# 計算済みとして記録
calculated_items.add(item_name)
return output_data
-
item_nameに粗利益に対する販管費比率を設定します。 -
calculated_itemsを確認し、すでに計算済みである場合は処理をスキップします。 - if文を使用し、
output_dataに売上総利益と販売費及び一般管理費のデータが存在するかを確認します。 -
売上総利益をgross_profitに、販売費及び一般管理費をsga_expensesにそれぞれ格納します。 -
dropを使用してorderや項目名を取り除き、年度ごとのデータをそれぞれyears_gross_profitとyears_sga_expensesに格納します。 - データフレームに追加するため、
get_order_value関数を呼び出し、orderを取得します。 - 計算結果を保持するための辞書として
sga_ratioを作成します。最初にorderと項目名を設定しておきます。
たとえば{'order': 7.0, '項目名': '粗利益に対する販管費比率'}のようになります。 - for文を使用し、年度ごとの
販管費比率を計算します。 - 年度ごとの
売上総利益と販管費をgpとsgaに格納し、それぞれが存在する場合に粗利益に対する販管費比率を計算します。 -
add_calculated_row関数を使用し、計算結果をoutput_dataに格納します。 -
calculated_itemsに計算済みの項目としてitem_nameを格納し、重複した計算が行われないようにします。 - 最終的に更新された
output_dataをreturnで返します。
財務諸表にある特定の勘定科目をExcelファイルに書き出す処理
calculate_metrics.py
def main():
company_code = '7974'
# データの読み込み
master_file_path = 'Master_Analytics.xlsx'
master_data = load_master_data(master_file_path)
financial_data_sheets = load_financial_data(company_code)
years = get_years(financial_data_sheets)
# データの抽出
output_data = await extract_financial_data(master_data, financial_data_sheets, years)
# 計算項目の処理(売上高成長率、粗利益率、販管費比率を計算します)
output_data = await calculate_sales_growth_rate(output_data, years, master_data)
output_data = await calculate_gross_profit_margin(output_data, years, master_data)
output_data = await calculate_sga_ratio(output_data, years, master_data)
# 'order'列でソートしてインデックスをリセットします
output_data = output_data.sort_values('order').reset_index(drop=True)
# 'order'列を削除します(最終出力には必要ないため)
output_data = output_data.drop(columns=['order'])
# Excelファイルへの出力処理
output_file = f'{company_code}_Analytics.xlsx'
writer = pd.ExcelWriter(output_file, engine='xlsxwriter')
output_data.to_excel(writer, index=False, header=False, startrow=1, sheet_name=company_code)
# ワークブックとワークシートを取得
workbook = writer.book
worksheet = writer.sheets[company_code]
# フォーマットの定義
cell_format = workbook.add_format({'font_name': 'Meiryo', 'font_size': 10})
header_format = workbook.add_format({'font_name': 'Meiryo', 'font_size': 10, 'bold': True, 'align': 'center'})
calculated_item_format = workbook.add_format({
'font_name': 'Meiryo',
'font_size': 10,
'bg_color': '#BCE6F7', # 青の背景色
'num_format': '0.00%' # パーセンテージ表示
})
number_format = workbook.add_format({
'font_name': 'Meiryo',
'font_size': 10,
'num_format': '#,##0' # カンマ区切りの数値
})
# ヘッダー行を書き込み(フォーマット適用)
header = output_data.columns.to_list()
worksheet.write_row(0, 0, header, header_format)
# データ範囲を取得
(max_row, max_col) = output_data.shape
# '項目名'列のデータを取得
item_names = output_data['項目名'].tolist()
# 各セルのフォーマットを適用しながらデータを書き込みます
for row_idx in range(1, max_row + 1):
item_name = item_names[row_idx - 1]
is_calculated_item = any(keyword in item_name for keyword in ['成長率', '率', '比率', '割合'])
for col_idx in range(max_col):
value = output_data.iloc[row_idx - 1, col_idx]
# 項目名列(最初の列)
if col_idx == 0:
if is_calculated_item:
worksheet.write(row_idx, col_idx, value, calculated_item_format)
else:
worksheet.write(row_idx, col_idx, value, cell_format)
else:
# 数値データのセル
if pd.notna(value):
if is_calculated_item:
worksheet.write_number(row_idx, col_idx, value, calculated_item_format)
else:
worksheet.write_number(row_idx, col_idx, value, number_format)
else:
# 値がNaNの場合は空白セルにする
if is_calculated_item:
worksheet.write_blank(row_idx, col_idx, None, calculated_item_format)
else:
worksheet.write_blank(row_idx, col_idx, None, cell_format)
# 各列の幅を指定
worksheet.set_column(0, 0, 25)
worksheet.set_column(1, max_col - 1, 10)
# Excelファイルを保存
writer.close()
print(f"Excelファイル{output_file}が出力されました。")
if __name__ == "__main__":
main()
出力に向けての設定
- 4桁の証券コードを入力し、
company_codeに格納します。
-
Master_Analytics.xlsxが保存されているパスをmaster_file_pathに格納します。 -
load_master_data(master_file_path)で、Masterデータを読み込み、master_dataに格納します。 -
load_financial_data(company_code)で、指定した証券コードの財務諸表データを読み込み、financial_data_sheetsに格納します。 -
get_years(financial_data_sheets)で、読み込んだ財務諸表データから年度情報を抽出し、yearsに格納します。 -
extract_financial_data()関数を使用し、必要な勘定科目を整理して新しいデータフレームにまとめて、output_dataに格納します。 - 指標の計算処理として
売上高成長率、粗利益率、販管費比率を計算する関数を使用し、output_dataに格納します。 -
sort_values('order')を使用し、データをorder列でソートし、output_dataに格納します。 - 最終の出力結果に
order列は必要ないため、drop(columns=['order'])を使用してorder列を削除します。
Excelファイルの設定
- 任意のファイル名を設定し、
output_fileに格納します。ここでは{company_code}_Analytics.xlsxを使用していますので、証券コード4桁_Analytics.xlsxが出力されます。 -
pd.ExcelWriter()を使用して、Excelファイルを書き出すための準備を行うため、オブジェクトを作成します。 -
writerというExcelWriterのオブジェクトを使用し、output_dataをExcelファイルに書き込みます。 -
output_data.to_excelのstartrow=1は、データの書き出しを1行目から始めるように指定する設定です。
Excelシートの1行目(内部的には0行目)にはQName(ID)などのヘッダー情報を記載するため、データ自体は1行目からスタートするようにしています。
つまり、Excelファイル上ではセル2からデータが書き出されます。
ほかには、sheet_name=company_codeとすることで、証券コード4桁をシートの名前に使用しています。 -
writer.bookでワークブックを取得し、workbookに格納します。 -
writer.sheets[company_code]でワークシートを取得し、worksheetに格納します。 - フォントや背景色などのフォーマットを定義します。
cell_formatはデータが書かれているセル、header_formatはExcelシート1行目のヘッダー情報についてのフォーマットです。 - 少し特殊なフォーマットとして、財務諸表から勘定科目を引っ張ってきている項目と、指標として計算した項目をパッと見てわかるようにしたいので、指標の方は背景色を
calculated_item_formatで変更するようにしています。
他にも、売上高などの数値情報が1671865の時は少し見づらいので、number_formatで1,671,865といった形でカンマをつけるように設定しています。
データの書き込み
-
output_data.columns.to_list()を使用して、データフレームの列名リストを取得し、headerに格納します。ここには['項目名', 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023, 2024]といった形でヘッダー情報が並びます。 -
worksheet.write_rowを使用し、実際にヘッダー行へheaderを書き込みます。 - forループを二重に構成し、
output_dataの全データをExcelに書き込んでいきます。
item_namesには各行の「項目名」が入っており、row_idx - 1とすることで、適切な項目名を取得するようにしています。 -
item_nameに成長率、率、比率、割合というキーワードが含まれているかをチェックし、含まれている場合はTrue、そうでなければFalseをis_calculated_itemにセットします。
計算結果の項目は背景色を変更するため、その処理に使用しています。
- forループで、Excelの左から右にかけてデータを書き込んでいく処理を繰り返します。
col_idxは列番号を表しています。 - if文で計算項目かどうかを判定し、それぞれのフォーマットを適用します。
if is_calculated_itemは計算項目であるため、calculated_item_formatのフォーマットを適用します。
異なる場合は通常セルのフォーマットであるcell_formatを適用します。
また、数値の場合はカンマ区切りにする処理をnumber_formatで行います。
どの条件にも当てはまらない、値がNaNのときは、worksheet.write_blankを使用してセルを空白にします。 -
worksheet.set_columnを使用して、A列とB列以降のセル幅をそれぞれ250pxと100pxに設定します。 -
writer.close()でExcelファイルを保存して閉じたあと、コンソールにExcelファイルが正常に出力されたことをお知らせします。
calculate_metrics.pyのまとめ
コードをまとめると、下記のようになります。
calculate_metrics.py
import pandas as pd
import numpy as np
from data_extraction import load_master_data, load_financial_data, get_years, extract_financial_data
calculated_items = set()
def get_order_value(output_data, master_data, item_name):
# master_dataから指定された'item_name'に対応する'order'列の値を取得
order_values = master_data[master_data['項目名'] == item_name]['order'].values
# 'order_values'に値があり、最初の値がNaN(欠損値)でない場合
if len(order_values) > 0 and pd.notna(order_values[0]):
return float(order_values[0]) # その'order'の値を返す
# それ以外の場合、'output_data'の'order'列の最大値に1を足して返す(全て欠損値であれば0を返す)
return float(output_data['order'].max() + 1 if output_data['order'].notna().any() else 0)
# 新しい行をDataFrameに追加する共通関数
def add_calculated_row(output_data, calculated_data, item_name):
# 計算結果を元に新しい行を作成
df_new_row = pd.DataFrame([calculated_data])
# 全てがNaNの行を追加しないようにチェック
if not df_new_row.isna().all(axis=1).iloc[0]:
# 既存の項目があれば、そのインデックスを取得
idx = output_data.index[output_data['項目名'] == item_name]
# 既存の項目が存在する場合は更新
if not idx.empty:
for col in df_new_row.columns:
output_data.at[idx[0], col] = df_new_row.at[0, col]
else:
# 既存の項目が無ければ新しい行を追加
output_data = pd.concat([output_data, df_new_row], ignore_index=True)
# 更新されたDataFrameを返す
return output_data
# 売上高成長率の計算
async def calculate_sales_growth_rate(output_data, years, master_data, log_function=None):
item_name = '売上高成長率'
target_item_name = '売上高'
# 既に計算済みの場合はスキップします
if item_name in calculated_items:
await log_function(f"{item_name} は既に計算済みのため、スキップします。")
return output_data
# 売上高データがあるか確認して取得します
try:
target_data = output_data[output_data['項目名'] == target_item_name].iloc[0]
except IndexError:
if log_function:
await log_function(f"{target_item_name}またはdecimalsのデータが存在しないため、{item_name}を計算できません。")
return output_data
# 'order'や'項目名'を除いた年度ごとの売上高データを取得
years_data = target_data.drop(['order', '項目名'], errors='ignore')
# 順序を取得するための関数を使用してorder値を取得
order = get_order_value(output_data, master_data, item_name)
# 計算結果を保持するための辞書を用意
growth_rates = {'order': order, '項目名': item_name}
prev_value = None # 前の年の売上高を保持する変数
# 各年度について成長率を計算する
for year in years:
current_value = years_data.get(year, None)
# 現在の年と前の年の値が存在する場合、成長率を計算する
if pd.notna(current_value) and pd.notna(prev_value) and prev_value != 0:
growth_rate = (current_value - prev_value) / abs(prev_value)
growth_rates[year] = growth_rate
else:
# 計算できない場合はNaNにする
growth_rates[year] = np.nan
# 現在の値を次のループで前の値として使う
prev_value = current_value
# 計算した成長率をoutput_dataに追加
output_data = add_calculated_row(output_data, growth_rates, item_name)
# 計算済みの項目を記録
calculated_items.add(item_name)
return output_data
# 粗利益率の計算
async def calculate_gross_profit_margin(output_data, years, master_data, log_function=None):
item_name = '粗利益率'
# すでに計算済みなら処理をスキップ
if item_name in calculated_items:
return output_data
# 必要なデータが揃っているか確認
if '売上総利益' in output_data['項目名'].values and '売上高' in output_data['項目名'].values:
# '売上総利益'と'売上高'の行データを取得
gross_profit = output_data[output_data['項目名'] == '売上総利益'].iloc[0]
net_sales = output_data[output_data['項目名'] == '売上高'].iloc[0]
# 'order'や'項目名'を除いて年度ごとのデータを取得
years_gross_profit = gross_profit.drop(['order', '項目名'], errors='ignore')
years_net_sales = net_sales.drop(['order', '項目名'], errors='ignore')
# orderの取得
order = get_order_value(output_data, master_data, item_name)
# 計算結果を保存する辞書
gross_profit_margin = {'order': order, '項目名': item_name}
# 各年度について粗利益率を計算
for year in years:
gp = years_gross_profit.get(year, None)
ns = years_net_sales.get(year, None)
# 売上総利益と売上高が存在する場合、粗利益率を計算
if pd.notna(gp) and pd.notna(ns) and ns != 0:
gross_profit_margin[year] = gp / ns # 粗利益率 = 売上総利益 / 売上高
else:
gross_profit_margin[year] = np.nan
# 計算結果を既存のデータに追加
output_data = add_calculated_row(output_data, gross_profit_margin, item_name)
# 計算済みとして記録
calculated_items.add(item_name)
return output_data
# 販管費比率の計算
async def calculate_sga_ratio(output_data, years, master_data, log_function=None):
item_name = '粗利益に対する販管費比率'
# すでに計算済みであればスキップ
if item_name in calculated_items:
return output_data
# 必要なデータが揃っているか確認
if '売上総利益' in output_data['項目名'].values and '販売費及び一般管理費' in output_data['項目名'].values:
# '売上総利益'と'販売費及び一般管理費'の行データを取得
gross_profit = output_data[output_data['項目名'] == '売上総利益'].iloc[0]
sga_expenses = output_data[output_data['項目名'] == '販売費及び一般管理費'].iloc[0]
# 'order'や'項目名'を除いた年度ごとのデータを取得
years_gross_profit = gross_profit.drop(['order', '項目名'], errors='ignore')
years_sga_expenses = sga_expenses.drop(['order', '項目名'], errors='ignore')
# orderの取得
order = get_order_value(output_data, master_data, item_name)
# 計算結果を保存する辞書を作成
sga_ratio = {'order': order, '項目名': item_name}
# 各年度について販管費比率を計算
for year in years:
gp = years_gross_profit.get(year, None)
sga = years_sga_expenses.get(year, None)
# 売上総利益と販管費が存在し、売上総利益がゼロでない場合に販管費比率を計算
if pd.notna(gp) and pd.notna(sga) and gp != 0:
sga_ratio[year] = sga / gp # 販管費比率 = 販管費 / 売上総利益
else:
sga_ratio[year] = np.nan
# 計算結果を既存のデータに追加
output_data = add_calculated_row(output_data, sga_ratio, item_name)
# 計算済みとして記録
calculated_items.add(item_name)
return output_data
def main():
company_code = '7974'
# データの読み込み
master_file_path = 'Master_Analytics.xlsx'
master_data = load_master_data(master_file_path)
financial_data_sheets = load_financial_data(company_code)
years = get_years(financial_data_sheets)
# データの抽出
output_data = await extract_financial_data(master_data, financial_data_sheets, years)
# 計算項目の処理(売上高成長率、粗利益率、販管費比率を計算します)
output_data = await calculate_sales_growth_rate(output_data, years, master_data)
output_data = await calculate_gross_profit_margin(output_data, years, master_data)
output_data = await calculate_sga_ratio(output_data, years, master_data)
# 'order'列でソートしてインデックスをリセットします
output_data = output_data.sort_values('order').reset_index(drop=True)
# 'order'列を削除します(最終出力には必要ないため)
output_data = output_data.drop(columns=['order'])
# Excelファイルへの出力処理
output_file = f'{company_code}_Analytics.xlsx'
writer = pd.ExcelWriter(output_file, engine='xlsxwriter')
output_data.to_excel(writer, index=False, header=False, startrow=1, sheet_name=company_code)
# ワークブックとワークシートを取得
workbook = writer.book
worksheet = writer.sheets[company_code]
# フォーマットの定義
cell_format = workbook.add_format({'font_name': 'Meiryo', 'font_size': 10})
header_format = workbook.add_format({'font_name': 'Meiryo', 'font_size': 10, 'bold': True, 'align': 'center'})
calculated_item_format = workbook.add_format({
'font_name': 'Meiryo',
'font_size': 10,
'bg_color': '#BCE6F7', # 青の背景色
'num_format': '0.00%' # パーセンテージ表示
})
number_format = workbook.add_format({
'font_name': 'Meiryo',
'font_size': 10,
'num_format': '#,##0' # カンマ区切りの数値
})
# ヘッダー行を書き込み(フォーマット適用)
header = output_data.columns.to_list()
worksheet.write_row(0, 0, header, header_format)
# データ範囲を取得
(max_row, max_col) = output_data.shape
# '項目名'列のデータを取得
item_names = output_data['項目名'].tolist()
# 各セルのフォーマットを適用しながらデータを書き込みます
for row_idx in range(1, max_row + 1):
item_name = item_names[row_idx - 1]
is_calculated_item = any(keyword in item_name for keyword in ['成長率', '率', '比率', '割合'])
for col_idx in range(max_col):
value = output_data.iloc[row_idx - 1, col_idx]
# 項目名列(最初の列)
if col_idx == 0:
if is_calculated_item:
worksheet.write(row_idx, col_idx, value, calculated_item_format)
else:
worksheet.write(row_idx, col_idx, value, cell_format)
else:
# 数値データのセル
if pd.notna(value):
if is_calculated_item:
worksheet.write_number(row_idx, col_idx, value, calculated_item_format)
else:
worksheet.write_number(row_idx, col_idx, value, number_format)
else:
# 値がNaNの場合は空白セルにする
if is_calculated_item:
worksheet.write_blank(row_idx, col_idx, None, calculated_item_format)
else:
worksheet.write_blank(row_idx, col_idx, None, cell_format)
# 各列の幅を指定
worksheet.set_column(0, 0, 25)
worksheet.set_column(1, max_col - 1, 10)
# Excelファイルを保存
writer.close()
print(f"Excelファイル{output_file}が出力されました。")
if __name__ == "__main__":
main()
実行結果
calculate_metrics.pyを実行します。
Excelファイル7974_Analytics.xlsxが出力されました。
プロセスは終了コード 0 で終了しました
問題なく出力されたので、7974_Analytics.xlsxを開きます。
無事、自分で絞った勘定科目と、計算したい指標が出力されていることを確認できました。

Discussion