LangChain LCELでRAGのいろんな機能やテクニックを実装してみる
LCELを契機にLangChain再入門中。
ということで、以下を参考にいろいろRAGのテクニック的なところの実装を試してみる。
とりあえずベースとなるRAGをまず構築。Colaboratoryで。
セットアップ
パッケージインストール
!pip install --upgrade --quiet langchain langchain-core langchain-openai langchain-chroma langchain-text-splitters grandalf
APIキー
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
LangSmithも一応有効化
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = userdata.get('LANGCHAIN_API_KEY')
ドキュメントの準備
RAGのドキュメントは以下を使う。
from pathlib import Path
import requests
import re
def replace_heading(match):
level = len(match.group(1))
return '#' * level + ' ' + match.group(2).strip()
# Wikipediaからのデータ読み込み
wiki_titles = ["オグリキャップ"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = f"# {title}\n\n## 概要\n\n"
wiki_text += page["extract"]
wiki_text = re.sub(r"(=+)([^=]+)\1", replace_heading, wiki_text)
wiki_text = re.sub(r"\t+", "", wiki_text)
wiki_text = re.sub(r"\n{3,}", "\n\n", wiki_text)
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
# markdown(.md)ファイルとして出力
with open(data_path / f"{title}.md", "w") as fp:
fp.write(wiki_text)
Markdownをセクションごとのチャンクにする。LangChainのMarkdown用document loadersには自分に合うものがなかったので、MarkdownHeaderTextSplitterを使って、メタデータやチャンクサイズなどをいじっている。
import glob
import os
from langchain_text_splitters import MarkdownHeaderTextSplitter
from langchain_core.documents import Document
def text_split(text, max_length=400):
"""
"""
chunks = re.split(r'(?<=[。!?\n])', text)
chunks = [s for s in chunks if s.strip()]
temp_chunk = ""
final_chunks = []
for chunk in chunks:
if len(temp_chunk + chunk) <= max_length:
temp_chunk += chunk
else:
final_chunks.append(temp_chunk)
temp_chunk = chunk
if temp_chunk:
final_chunks.append(temp_chunk)
return final_chunks
sections_for_delete = ["競走成績", "外部リンク", "参考文献"]
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
("####", "Header 4"),
("#####", "Header 5"),
("######", "Header 6"),
]
files = glob.glob('data/*.md')
splits = []
for file in files:
with open(file) as f:
md = f.read()
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_split = markdown_splitter.split_text(md)
docs_for_delete = []
for idx, d in enumerate(docs_split):
metadatas = []
header_keys = []
d.metadata["source"] = file
for m in d.metadata:
if m.startswith("Header"):
metadatas.append(d.metadata[m])
header_keys.append(m)
# 削除対象のセクションを含むドキュメントを後で削除するためにそのインデックス登録しておく
if d.metadata[m] in sections_for_delete:
docs_for_delete.append(idx)
# セクションの階層を結合、パンくずリストとしてセクション情報に追加
if len(metadatas) > 0:
d.metadata["section"] = metadata_str = " > ".join(metadatas)
for k in header_keys:
if k.startswith("Header"):
del d.metadata[k]
# 削除対象セクションの削除
docs = [item for i, item in enumerate(docs_split) if i not in docs_for_delete]
# セクション内のテキストが一定量を超えていればさらにチャンク分割
for d in docs:
chunks = text_split(d.page_content, 500)
if len(chunks) == 1:
splits.append(d)
else:
for idx, chunk in enumerate(chunks, start=1):
metadata = d.metadata.copy()
metadata["section"] += f"({idx})"
splits.append(Document(page_content=chunk, metadata=metadata))
こういう感じのチャンクができる。
for s in splits[:5]:
print(s.metadata)
print(s.page_content[:60] + "...")
print("====")
{'source': 'data/オグリキャップ.md', 'section': 'オグリキャップ > 概要'}
オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
1...
====
{'source': 'data/オグリキャップ.md', 'section': 'オグリキャップ > デビューまで > 誕生に至る経緯'}
オグリキャップの母・ホワイトナルビーは競走馬時代に馬主の小栗孝一が所有し、笠松競馬場の調教師鷲見昌勇が管理した。ホワイト...
====
{'source': 'data/オグリキャップ.md', 'section': 'オグリキャップ > デビューまで > 誕生・生い立ち > 稲葉牧場時代'}
オグリキャップは1985年3月27日の深夜に誕生した。誕生時には右前脚が大きく外向しており、出生直後はなかなか自力で立ち...
====
{'source': 'data/オグリキャップ.md', 'section': 'オグリキャップ > デビューまで > 誕生・生い立ち > 美山育成牧場時代'}
1986年の10月、ハツラツは岐阜県山県郡美山町(現:山県市)にあった美山育成牧場に移り、3か月間馴致を施された。当時の...
====
{'source': 'data/オグリキャップ.md', 'section': 'オグリキャップ > 競走馬時代 > 笠松競馬時代 > 競走内容(1)'}
1987年1月28日に笠松競馬場の鷲見昌勇厩舎に入厩。登録馬名は「オグリキヤツプ」。ダート800mで行われた能力試験を5...
====
インデックスの作成
ドキュメントからベクトルインデックスを作成する。
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_documents(documents=splits, embedding=embedding)
retrieverの作成
ベクトルインデックスを検索するretrieverを作成。
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
検索してみる。
search_result = retriever.invoke("オグリキャップの血統は?")
for r in search_result:
print(r.metadata)
print(r.page_content[:60] + "...")
print("====")
{'section': 'オグリキャップ > 概要', 'source': 'data/オグリキャップ.md'}
オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
1...
====
{'section': 'オグリキャップ > 特徴・評価 > 競走馬名および愛称・呼称', 'source': 'data/オグリキャップ.md'}
競走馬名「オグリキャップ」の由来は、馬主の小栗が使用していた冠名「オグリ」に父ダンシングキャップの馬名の一部「キャップ」...
====
{'section': 'オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(2)', 'source': 'data/オグリキャップ.md'}
オグリキャップは肢のキック力が強く、瞬発力の強さは一回の蹴りで前肢を目いっぱいに延ばし、浮くように跳びながら走るため、こ...
====
{'section': 'オグリキャップ > 特徴・評価 > 身体面に関する特徴・評価(2)', 'source': 'data/オグリキャップ.md'}
オグリキャップの体力面について、競馬関係者からは故障しにくい点や故障から立ち直るタフさを評価する声が挙がっている。輸送時...
====
{'section': 'オグリキャップ > 人気 > 概要(2)', 'source': 'data/オグリキャップ.md'}
お笑い芸人の明石家さんまは雑誌『サラブレッドグランプリ』のインタビューにおいて、オグリキャップについて「マル地馬で血統も...
====
RAGのチェーンの作成
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
template = """\
あなたは質問応答タスクのアシスタントです。
検索された以下のコンテキストの一部を使って質問に丁寧に答えてください。
答えがわからなければ、わからないと答えてください。
最大で3つの文章を使い、簡潔な回答を心がけてください。
質問: {question}
文脈:
====
{context}
====
回答:
"""
prompt = ChatPromptTemplate.from_template(template)
# プロンプトに含まれるコンテキストの整形
def format_docs(docs):
return "\n----\n".join("metadata: {}\ncontent: {}".format(doc.metadata, doc.page_content) for doc in docs)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("オグリキャップの主な勝ち鞍は?")
オグリキャップの主な勝ち鞍は、中央競馬での重賞12勝のうちGI4勝が含まれます。また、競走馬として活躍した際には、JRA賞最優秀4歳牡馬やJRA顕彰馬にも選出されました。オグリキャップは多くのファンに愛され、高い人気を誇りました。
全体はこういうフローになる。
rag_chain.get_graph().print_ascii()
+---------------------------------+
| Parallel<context,question>Input |
+---------------------------------+
**** ****
*** ***
** ***
+----------------------+ **
| VectorStoreRetriever | *
+----------------------+ *
* *
* *
* *
+---------------------+ +-------------+
| Lambda(format_docs) | | Passthrough |
+---------------------+ +-------------+
**** ***
*** ***
** **
+----------------------------------+
| Parallel<context,question>Output |
+----------------------------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+------------+
| ChatOpenAI |
+------------+
*
*
*
+-----------------+
| StrOutputParser |
+-----------------+
*
*
*
+-----------------------+
| StrOutputParserOutput |
+-----------------------+
プロンプト部分だけ少し見ておく。
retrival_prompt_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
)
print(retrival_prompt_chain.invoke("オグリキャップの主な勝ち鞍は?").messages[0].content)
あなたは質問応答タスクのアシスタントです。
検索された以下のコンテキストの一部を使って質問に丁寧に答えてください。
答えがわからなければ、わからないと答えてください。
最大で3つの文章を使い、簡潔な回答を心がけてください。
質問: オグリキャップの主な勝ち鞍は?
文脈:
====
metadata: {'section': 'オグリキャップ > 特徴・評価 > 競走馬名および愛称・呼称', 'source': 'data/オグリキャップ.md'}
content: 競走馬名「オグリキャップ」の由来は、馬主の小栗が使用していた冠名「オグリ」に父ダンシングキャップの馬名の一部「キャップ」を加えたものである。
同馬の愛称としては「オグリ」が一般的だが、女性ファンの中には「オグリちゃん」、「オグリン」と呼ぶファンも存在し、その他「怪物」「新怪物」「白い怪物」「芦毛の怪物」と呼ばれた。またオグリキャップは前述のように生来食欲が旺盛で、「食べる競走馬」とも呼ばれた。
----
metadata: {'section': 'オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(2)', 'source': 'data/オグリキャップ.md'}
content: オグリキャップは肢のキック力が強く、瞬発力の強さは一回の蹴りで前肢を目いっぱいに延ばし、浮くように跳びながら走るため、この走法によって普通の馬よりも20から30センチ前に出ることができた。一方で入厩当初は右前脚に骨膜炎を発症しており「馬場に出ると怖くてよう乗れん」という声もあった。オグリキャップは首を良く使う走法で、沈むように首を下げ、前後にバランスを取りながら地面と平行に馬体を運んでいく走りから、笠松時代から「地を這う馬」と形容されることがあった。安藤勝己は秋風ジュニアのレース後、「重心が低く、前への推進力がケタ違い。あんな走り方をする馬に巡り会ったのは、初めて」と思ったという。瀬戸口勉もオグリキャップの走り方の特徴について、重心と首の位置が低いことを挙げている。河内洋はオグリキャップのレースぶりについて、スピードタイプとは対照的な「グイッグイッと伸びる力タイプ」と評し、騎乗した当初からオグリキャップは「勝負所になると自ら上がっていくような感じで、もうオグリキャップ自身が競馬を知っていた」と述べている。
----
metadata: {'section': 'オグリキャップ > 概要', 'source': 'data/オグリキャップ.md'}
content: オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
1987年5月に岐阜県の地方競馬・笠松競馬場でデビュー。8連勝、重賞5勝を含む12戦10勝を記録した後、1988年1月に中央競馬へ移籍し、重賞12勝(うちGI4勝)を記録した。1988年度のJRA賞最優秀4歳牡馬、1989年度のJRA賞特別賞、1990年度のJRA賞最優秀5歳以上牡馬および年度代表馬。1991年、JRA顕彰馬に選出。愛称は「オグリ」「芦毛の怪物」など多数。
中央競馬時代はスーパークリーク、イナリワンの二頭とともに「平成三強」と総称され、自身と騎手である武豊の活躍を中心として起こった第二次競馬ブーム期において、第一次競馬ブームの立役者とされるハイセイコーに比肩するとも評される高い人気を得た。
競走馬引退後は北海道新冠町の優駿スタリオンステーションで種牡馬となったが、産駒から中央競馬の重賞優勝馬を出すことができず、2007年に種牡馬を引退。種牡馬引退後は同施設で功労馬として繋養されていたが、2010年7月3日に右後肢脛骨を骨折し、安楽死の処置が執られた。
----
metadata: {'section': 'オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(3)', 'source': 'data/オグリキャップ.md'}
content: また「一生懸命さがヒシヒシ伝わってくる馬」、「伸びきったかな、と思って追うと、そこからまた伸びてきよる」、「底力がある」とする一方、走る気を出し過ぎるところもあったとしている。一方でGIクラスを相手にした時のオグリキャップは抜け出すまでにモタつく面があるため多頭数のレースだとかなり不安が残る馬と分析し、「直線の入り口でスーッと行ける脚が欲しい」と要望していた。河内の次に主戦騎手を務めた南井克巳は、オグリキャップを「力そのもの、パワーそのものを感じさせる馬」「どんなレースでもできる馬」「レースを知っている」と評し、1989年の毎日王冠のレース後には「この馬の勝負根性には本当に頭が下がる」と語った。同じく主戦騎手を務めたタマモクロスとの比較については「馬の強さではタマモクロスのほうが上だったんじゃないか」と語った一方で、「オグリキャップのほうが素直で非常に乗りやすい」と述べている。
----
metadata: {'section': 'オグリキャップ > 競走馬時代 > 中央競馬時代 > 4歳(1988年) > 競走内容(1)', 'source': 'data/オグリキャップ.md'}
content: オグリキャップの中央移籍後の初戦にはペガサスステークスが選ばれ、鞍上は佐橋の希望により河内洋に決まった。地方での快進撃は知られていたものの、当日の単勝オッズは2番人気であった。レースでは序盤は後方に控え、第3コーナーから馬群の外を通って前方へ進出を開始。第4コーナーを過ぎてからスパートをかけて他馬を追い抜き、優勝した。出走前の時点では陣営の期待は必ずしも高いものではなく、優勝は予想を上回る結果だった。レースで実況を担当した杉本清は最後の直線で「これは噂にたがわない強さだ」と実況した。なお、この日中京競馬場で行われた中日新聞杯では佐橋が所有するトキノオリエントが優勝し、佐橋は中央競馬史上初となる同一馬主による地方出身馬の同日開催重賞制覇を達成している。移籍2戦目には毎日杯が選ばれた。このレースでは馬場状態が追い込み馬に不利とされる重馬場と発表され、オグリキャップが馬場状態に対応できるかどうかに注目が集まった。オグリキャップは第3コーナーで最後方の位置から馬群の外を通って前方へ進出を開始し、ゴール直前で先頭に立って優勝した。
====
回答:
ここまでを基本としてこれにいろいろ追加して試してみようと思う。
HyDE
RePhraseQueryRetrieverを使う。
from langchain.retrievers import RePhraseQueryRetriever
rephrase_retriever = RePhraseQueryRetriever.from_llm(
retriever=retriever, llm=llm
)
実際に試してみる。
search_result = rephrase_retriever.invoke("オグリキャップの主な勝ち鞍は?")
for r in search_result:
print(r.metadata)
print(r.page_content[:60] + "...")
print("====")
{'section': 'オグリキャップ > 競走馬時代 > 中央競馬時代 > 4歳(1988年) > 競走内容(1)', 'source': 'data/オグリキャップ.md'}
オグリキャップの中央移籍後の初戦にはペガサスステークスが選ばれ、鞍上は佐橋の希望により河内洋に決まった。地方での快進撃は...
====
{'section': 'オグリキャップ > 人気 > 馬券売り上げ・入場者数の増加(1)', 'source': 'data/オグリキャップ.md'}
オグリキャップが中央競馬移籍後に出走したレースにおける馬券の売上額は、20レース中17レースで前年よりも増加し、単勝式の...
====
{'section': 'オグリキャップ > 競走馬時代 > 近藤俊典への売却', 'source': 'data/オグリキャップ.md'}
1988年9月、オグリキャップの2代目の馬主であった佐橋五十雄に脱税容疑がかかり、将来馬主登録を抹消される可能性が浮上し...
====
{'section': 'オグリキャップ > 特徴・評価 > 投票における評価(2)', 'source': 'data/オグリキャップ.md'}
2004年に『優駿』が行った「THE GREATEST 記憶に残る名馬たち」という特集の「年度別代表馬BEST10」にお...
====
{'section': 'オグリキャップ > 競走馬時代 > 中央競馬時代 > 4歳(1988年) > 競走内容(3)', 'source': 'data/オグリキャップ.md'}
このレースでのオグリキャップの走破タイムは同レースのレースレコードを記録し、このタイムは前月に同じ東京芝1600mで行わ...
====
デフォルトのプロンプトは以下のようなものが入っている。
日本語訳
あなたは、ユーザーから自然言語によるクエリを受け取り、それをベクトルストアのクエリに変換することを任されたアシスタントです。
この過程で、あなたは検索タスクに関係のない情報を取り除きます。ユーザークエリはこれです: {question}
HyDEのプロンプトに変更してみる。
from langchain.retrievers import RePhraseQueryRetriever
from langchain_core.prompts import ChatPromptTemplate
hyde_prompt_template = """\
以下の質問に答える文章を書いてください。
質問: {question}
文章: \
"""
hyde_prompt = ChatPromptTemplate.from_template(hyde_prompt_template)
hyde_retriever = RePhraseQueryRetriever.from_llm(
retriever=retriever, llm=llm, prompt=hyde_prompt
)
search_result = hyde_retriever.invoke("オグリキャップの主な勝ち鞍は?")
for r in search_result:
print(r.metadata)
print(r.page_content[:60] + "...")
print("====")
{'section': 'オグリキャップ > 競走馬時代 > 中央競馬時代 > 4歳(1988年) > 競走内容(3)', 'source': 'data/オグリキャップ.md'}
このレースでのオグリキャップの走破タイムは同レースのレースレコードを記録し、このタイムは前月に同じ東京芝1600mで行わ...
====
{'section': 'オグリキャップ > 競走馬時代 > 中央競馬時代 > 4歳(1988年) > 競走内容(2)', 'source': 'data/オグリキャップ.md'}
オグリキャップは初代馬主の小栗孝一が中央で走らせるつもりがなかったことでクラシック登録をしていなかったため、前哨戦である...
====
{'section': 'オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(3)', 'source': 'data/オグリキャップ.md'}
また「一生懸命さがヒシヒシ伝わってくる馬」、「伸びきったかな、と思って追うと、そこからまた伸びてきよる」、「底力がある」...
====
{'section': 'オグリキャップ > 特徴・評価 > 知能・精神面に関する特徴・評価', 'source': 'data/オグリキャップ.md'}
ダンシングキャップ産駒の多くは気性が荒いことで知られていたが、オグリキャップは現3歳時に調教のために騎乗した河内洋と岡部...
====
{'section': 'オグリキャップ > 概要', 'source': 'data/オグリキャップ.md'}
オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
1...
ではこれをRAGのチェーンに組み込む。
rag_chain_with_hyde = (
{"context": hyde_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_hyde.invoke("オグリキャップの主な勝ち鞍は?")
オグリキャップの主な勝ち鞍は、ニュージーランドトロフィー4歳ステークスや高松宮杯などです。具体的なレース名は複数あります。
実際にはこんな感じのクエリが生成されて検索に使われていた。


フロー
rag_chain_with_hyde.get_graph().print_ascii()
+---------------------------------+
| Parallel<context,question>Input |
+---------------------------------+
**** ***
*** ***
** ****
+------------------------+ **
| RePhraseQueryRetriever | *
+------------------------+ *
* *
* *
* *
+---------------------+ +-------------+
| Lambda(format_docs) | | Passthrough |
+---------------------+ +-------------+
**** ****
*** ***
** **
+----------------------------------+
| Parallel<context,question>Output |
+----------------------------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+------------+
| ChatOpenAI |
+------------+
*
*
*
+-----------------+
| StrOutputParser |
+-----------------+
*
*
*
+-----------------------+
| StrOutputParserOutput |
+-----------------------+
RePhraseQueryRetrieverの裏ではプロンプト・LLM・VectorStoreRetrieverが動いてるんだけどね、そこは出力されない。
うーん、これLCELで置き換えれるんじゃないかなー。こんな感じ?
hyde_chain = hyde_prompt | llm | StrOutputParser() | retriever | format_docs
rag_chain_with_hyde_lcel = (
{
"context": hyde_chain,
"question": RunnablePassthrough()
}
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_hyde_lcel.invoke("オグリキャップの主な勝ち鞍は?")
オグリキャップの主な勝ち鞍は、毎日王冠での史上初の連覇や高松宮杯でのコースレコード達成などが挙げられます。また、有馬記念でのファン投票では1位に支持されました。
rag_chain_with_hyde_lcel.get_graph().print_ascii()
+---------------------------------+
| Parallel<context,question>Input |
+---------------------------------+
*** ***
*** ***
** ***
+--------------------+ **
| ChatPromptTemplate | *
+--------------------+ *
* *
* *
* *
+------------+ *
| ChatOpenAI | *
+------------+ *
* *
* *
* *
+-----------------+ *
| StrOutputParser | *
+-----------------+ *
* *
* *
* *
+----------------------+ *
| VectorStoreRetriever | *
+----------------------+ *
* *
* *
* *
+---------------------+ +-------------+
| Lambda(format_docs) | | Passthrough |
+---------------------+ +-------------+
*** ***
*** ***
** **
+----------------------------------+
| Parallel<context,question>Output |
+----------------------------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+------------+
| ChatOpenAI |
+------------+
*
*
*
+-----------------+
| StrOutputParser |
+-----------------+
*
*
*
+-----------------------+
| StrOutputParserOutput |
+-----------------------+
Rerank
retrieverの結果をリランクしてみる。rerankerはCohereを使う。
!pip install langchain_cohere
import os
from google.colab import userdata
os.environ["COHERE_API_KEY"] = userdata.get('CO_API_KEY')
ContextualCompressionRetrieverを使って、retrieverをラップする。"compress(圧縮)"っていうのがイマイチピンとこなかったのだけど、LangChainのドキュメントによれば、
- コンテキストの圧縮
- 検索されたドキュメントをそのまますぐに返してしまうのではなく、指定されたクエリのコンテキストを使って圧縮し、関連する情報だけを返すようにする
- 「圧縮」が指すのは以下の2つ
- 個々のドキュメントの内容を圧縮する
- キュメント全体をフィルタリングする
ということらしいので、リランキングも圧縮という概念になるらしい。
ということで、元のretrieverの検索結果を10件にして、リランク後に上位5件を取得するようにしてみた。
from langchain_cohere import CohereRerank
from langchain.retrievers import ContextualCompressionRetriever
reranker = CohereRerank(model="rerank-multilingual-v2.0", top_n=5) # 上位5件
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 10}) # 上位10件
rerank_retriever = ContextualCompressionRetriever(
base_compressor=reranker, base_retriever=retriever
)
違いを見てみる。
query = "オグリキャップの主な勝ち鞍は?"
base_search_result = base_retriever.invoke(query)
reranked_search_result = rerank_retriever.invoke(query)
print("==== base ====")
print("\n----\n".join(
"Rank {}\n{}\n{}".format(idx, r.metadata, r.page_content)
for idx, r in enumerate(base_search_result, start=1)
))
print()
print("==== reranked ====")
print("\n----\n".join(
"Rank {}\n{}\n{}".format(idx, r.metadata, r.page_content)
for idx, r in enumerate(reranked_search_result, start=1)
))
==== base ====
Rank 1
{'section': 'オグリキャップ > 特徴・評価 > 競走馬名および愛称・呼称', 'source': 'data/オグリキャップ.md'}
競走馬名「オグリキャップ」の由来は、馬主の小栗が使用していた冠名「オグリ」に父ダンシングキャップの馬名の一部「キャップ」を加えたものである。
同馬の愛称としては「オグリ」が一般的だが、女性ファンの中には「オグリちゃん」、「オグリン」と呼ぶファンも存在し、その他「怪物」「新怪物」「白い怪物」「芦毛の怪物」と呼ばれた。またオグリキャップは前述のように生来食欲が旺盛で、「食べる競走馬」とも呼ばれた。
----
Rank 2
{'section': 'オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(2)', 'source': 'data/オグリキャップ.md'}
オグリキャップは肢のキック力が強く、瞬発力の強さは一回の蹴りで前肢を目いっぱいに延ばし、浮くように跳びながら走るため、この走法によって普通の馬よりも20から30センチ前に出ることができた。一方で入厩当初は右前脚に骨膜炎を発症しており「馬場に出ると怖くてよう乗れん」という声もあった。オグリキャップは首を良く使う走法で、沈むように首を下げ、前後にバランスを取りながら地面と平行に馬体を運んでいく走りから、笠松時代から「地を這う馬」と形容されることがあった。安藤勝己は秋風ジュニアのレース後、「重心が低く、前への推進力がケタ違い。あんな走り方をする馬に巡り会ったのは、初めて」と思ったという。瀬戸口勉もオグリキャップの走り方の特徴について、重心と首の位置が低いことを挙げている。河内洋はオグリキャップのレースぶりについて、スピードタイプとは対照的な「グイッグイッと伸びる力タイプ」と評し、騎乗した当初からオグリキャップは「勝負所になると自ら上がっていくような感じで、もうオグリキャップ自身が競馬を知っていた」と述べている。
----
Rank 3
{'section': 'オグリキャップ > 概要', 'source': 'data/オグリキャップ.md'}
オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
1987年5月に岐阜県の地方競馬・笠松競馬場でデビュー。8連勝、重賞5勝を含む12戦10勝を記録した後、1988年1月に中央競馬へ移籍し、重賞12勝(うちGI4勝)を記録した。1988年度のJRA賞最優秀4歳牡馬、1989年度のJRA賞特別賞、1990年度のJRA賞最優秀5歳以上牡馬および年度代表馬。1991年、JRA顕彰馬に選出。愛称は「オグリ」「芦毛の怪物」など多数。
中央競馬時代はスーパークリーク、イナリワンの二頭とともに「平成三強」と総称され、自身と騎手である武豊の活躍を中心として起こった第二次競馬ブーム期において、第一次競馬ブームの立役者とされるハイセイコーに比肩するとも評される高い人気を得た。
競走馬引退後は北海道新冠町の優駿スタリオンステーションで種牡馬となったが、産駒から中央競馬の重賞優勝馬を出すことができず、2007年に種牡馬を引退。種牡馬引退後は同施設で功労馬として繋養されていたが、2010年7月3日に右後肢脛骨を骨折し、安楽死の処置が執られた。
----
Rank 4
{'section': 'オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(3)', 'source': 'data/オグリキャップ.md'}
また「一生懸命さがヒシヒシ伝わってくる馬」、「伸びきったかな、と思って追うと、そこからまた伸びてきよる」、「底力がある」とする一方、走る気を出し過ぎるところもあったとしている。一方でGIクラスを相手にした時のオグリキャップは抜け出すまでにモタつく面があるため多頭数のレースだとかなり不安が残る馬と分析し、「直線の入り口でスーッと行ける脚が欲しい」と要望していた。河内の次に主戦騎手を務めた南井克巳は、オグリキャップを「力そのもの、パワーそのものを感じさせる馬」「どんなレースでもできる馬」「レースを知っている」と評し、1989年の毎日王冠のレース後には「この馬の勝負根性には本当に頭が下がる」と語った。同じく主戦騎手を務めたタマモクロスとの比較については「馬の強さではタマモクロスのほうが上だったんじゃないか」と語った一方で、「オグリキャップのほうが素直で非常に乗りやすい」と述べている。
----
Rank 5
{'section': 'オグリキャップ > 競走馬時代 > 中央競馬時代 > 4歳(1988年) > 競走内容(1)', 'source': 'data/オグリキャップ.md'}
オグリキャップの中央移籍後の初戦にはペガサスステークスが選ばれ、鞍上は佐橋の希望により河内洋に決まった。地方での快進撃は知られていたものの、当日の単勝オッズは2番人気であった。レースでは序盤は後方に控え、第3コーナーから馬群の外を通って前方へ進出を開始。第4コーナーを過ぎてからスパートをかけて他馬を追い抜き、優勝した。出走前の時点では陣営の期待は必ずしも高いものではなく、優勝は予想を上回る結果だった。レースで実況を担当した杉本清は最後の直線で「これは噂にたがわない強さだ」と実況した。なお、この日中京競馬場で行われた中日新聞杯では佐橋が所有するトキノオリエントが優勝し、佐橋は中央競馬史上初となる同一馬主による地方出身馬の同日開催重賞制覇を達成している。移籍2戦目には毎日杯が選ばれた。このレースでは馬場状態が追い込み馬に不利とされる重馬場と発表され、オグリキャップが馬場状態に対応できるかどうかに注目が集まった。オグリキャップは第3コーナーで最後方の位置から馬群の外を通って前方へ進出を開始し、ゴール直前で先頭に立って優勝した。
----
Rank 6
{'section': 'オグリキャップ > 特徴・評価 > 知能・精神面に関する特徴・評価', 'source': 'data/オグリキャップ.md'}
ダンシングキャップ産駒の多くは気性が荒いことで知られていたが、オグリキャップは現3歳時に調教のために騎乗した河内洋と岡部幸雄が共に古馬のように落ち着いていると評するなど、落ち着いた性格の持ち主であった。オグリキャップの落ち着きは競馬場でも発揮され、パドックで観客の歓声を浴びても動じることがなく、ゲートでは落ち着き過ぎてスタートが遅れることがあるほどであった。岡部幸雄は1988年の有馬記念のレース後に「素晴らしい精神力だね。この馬は耳を立てて走るんだ。レースを楽しんでいるのかもしれない」と語り、1990年の有馬記念でスローペースの中で忍耐強く折り合いを保ち続けて勝利したことについて、「類稀なる精神力が生んだ勝利だ」と評したが、オグリキャップと対戦した競走馬の関係者からもオグリキャップの精神面を評価する声が多く挙がっている。オグリキャップに携わった者からは学習能力の高さなど、賢さ・利口さを指摘する声も多い。
----
Rank 7
{'section': 'オグリキャップ > 人気 > 概要(2)', 'source': 'data/オグリキャップ.md'}
お笑い芸人の明石家さんまは雑誌『サラブレッドグランプリ』のインタビューにおいて、オグリキャップについて「マル地馬で血統も良くない。それが中央に来て勝ち続ける。エリートが歩むクラシック路線から外されてね。ボクらみたいにイナカから出てきて東京で働いているもんにとっては希望の星ですよ」と述べている。須田鷹雄は中央移籍3戦目のNZT4歳Sを7馬身差で圧勝して大きな衝撃を与えたことでオグリキャップは競馬人気の旗手を担うこととなったとし、その後有馬記念を優勝したことで競馬ブームの代名詞的存在となったと述べている。江面弘也は、5歳初戦のオールカマーでオグリキャップがパドックに姿を現しただけで拍手が沸き起こったことを振り返り、「後になって思えば、あれが『オグリキャップ・ブーム』の始まりだった」と回顧している。阿部珠樹は「オグリキャップのように、人の気持ちをグイグイ引っ張り、新しい場所に連れて行ってくれた馬はもう出ないのではないだろうか」と述べている。
----
Rank 8
{'section': 'オグリキャップ > 人気 > 概要(1)', 'source': 'data/オグリキャップ.md'}
競走馬時代のオグリキャップの人気の高さについて、ライターの関口隆哉は「シンボリルドルフを軽く凌駕し」、「ハイセイコーとも肩を並べるほど」と評している。また岡部幸雄は「ハイセイコーを超えるほど」であったとしている(ハイセイコー#人気(ハイセイコーブーム)も参照)。オグリキャップが人気を得た要因についてライターの市丸博司は、「地方出身の三流血統馬が中央のエリートたちをナデ斬りにし、トラブルや過酷なローテーションの中で名勝負を数々演じ、二度の挫折を克服」したことにあるとし、オグリキャップは「ファンの記憶の中でだけ、本当の姿で生き続けている」「競馬ファンにもたらした感動は、恐らく同時代を過ごした者にしか理解できないものだろう」と述べ、山河拓也も市丸と同趣旨の見解を示している。斎藤修は、日本人が好む「田舎から裸一貫で出てきて都会で名をあげる」という立身出世物語に当てはまったことに加え、クラシックに出走することができないという挫折や、タマモクロス、イナリワン、スーパークリークというライバルとの対決がファンの共感を得たのだと分析している。
----
Rank 9
{'section': 'オグリキャップ > 人気 > 馬券売り上げ・入場者数の増加(1)', 'source': 'data/オグリキャップ.md'}
オグリキャップが中央競馬移籍後に出走したレースにおける馬券の売上額は、20レース中17レースで前年よりも増加し、単勝式の売上額は全てのレースで増加した。また、オグリキャップが出走した当日の競馬場への入場者数は、16レース中15レースで前年よりも増加した。中央競馬全体の年間の馬券売上額をみると、オグリキャップが笠松から移籍した1988年に2兆円に、引退した1990年に3兆円に、それぞれ初めて到達している。なお、1988年の高松宮杯では馬券全体の売り上げは減少したものの、オグリキャップとランドヒリュウの枠連は中京競馬場の電光掲示板に売上票数が表示できないほどの売上額を記録した。第35回有馬記念では同年の東京優駿の売上額の397億3151万3500円を上回ってJRAレコードとなる480億3126万2100円を記録した。オグリキャップ自身は出走した32レースのうち27レースで単勝式馬券の1番人気に支持された。なお、中央競馬時代には12回単枠指定制度の適用を受けている。
----
Rank 10
{'section': 'オグリキャップ > 特徴・評価 > 身体面に関する特徴・評価(2)', 'source': 'data/オグリキャップ.md'}
オグリキャップの体力面について、競馬関係者からは故障しにくい点や故障から立ち直るタフさを評価する声が挙がっている。輸送時に体重が減りにくい体質でもあり、通常の競走馬が二時間程度の輸送で6キロから8キロ体重が減少するのに対し、1988年の有馬記念の前に美浦トレーニングセンターと中山競馬場を往復した上に同競馬場で調教を行った際に2キロしか体重が減少しなかった。オグリキャップは心臓や消化器官をはじめとする内臓も強く、普通の馬であればエンバクが未消化のまま糞として排出されることが多いものの、オグリキャップはエンバクの殻まで隈なく消化されていた。安藤勝己は、オグリキャップのタフさは心臓の強さからくるものだと述べている。獣医師の吉村秀之は、オグリキャップは中央競馬へ移籍してきた当初からスポーツ心臓を持っていたと証言している。
==== reranked ====
Rank 1
{'section': 'オグリキャップ > 概要', 'source': 'data/オグリキャップ.md', 'relevance_score': 0.89858866}
オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
1987年5月に岐阜県の地方競馬・笠松競馬場でデビュー。8連勝、重賞5勝を含む12戦10勝を記録した後、1988年1月に中央競馬へ移籍し、重賞12勝(うちGI4勝)を記録した。1988年度のJRA賞最優秀4歳牡馬、1989年度のJRA賞特別賞、1990年度のJRA賞最優秀5歳以上牡馬および年度代表馬。1991年、JRA顕彰馬に選出。愛称は「オグリ」「芦毛の怪物」など多数。
中央競馬時代はスーパークリーク、イナリワンの二頭とともに「平成三強」と総称され、自身と騎手である武豊の活躍を中心として起こった第二次競馬ブーム期において、第一次競馬ブームの立役者とされるハイセイコーに比肩するとも評される高い人気を得た。
競走馬引退後は北海道新冠町の優駿スタリオンステーションで種牡馬となったが、産駒から中央競馬の重賞優勝馬を出すことができず、2007年に種牡馬を引退。種牡馬引退後は同施設で功労馬として繋養されていたが、2010年7月3日に右後肢脛骨を骨折し、安楽死の処置が執られた。
----
Rank 2
{'section': 'オグリキャップ > 人気 > 概要(2)', 'source': 'data/オグリキャップ.md', 'relevance_score': 0.15431227}
お笑い芸人の明石家さんまは雑誌『サラブレッドグランプリ』のインタビューにおいて、オグリキャップについて「マル地馬で血統も良くない。それが中央に来て勝ち続ける。エリートが歩むクラシック路線から外されてね。ボクらみたいにイナカから出てきて東京で働いているもんにとっては希望の星ですよ」と述べている。須田鷹雄は中央移籍3戦目のNZT4歳Sを7馬身差で圧勝して大きな衝撃を与えたことでオグリキャップは競馬人気の旗手を担うこととなったとし、その後有馬記念を優勝したことで競馬ブームの代名詞的存在となったと述べている。江面弘也は、5歳初戦のオールカマーでオグリキャップがパドックに姿を現しただけで拍手が沸き起こったことを振り返り、「後になって思えば、あれが『オグリキャップ・ブーム』の始まりだった」と回顧している。阿部珠樹は「オグリキャップのように、人の気持ちをグイグイ引っ張り、新しい場所に連れて行ってくれた馬はもう出ないのではないだろうか」と述べている。
----
Rank 3
{'section': 'オグリキャップ > 競走馬時代 > 中央競馬時代 > 4歳(1988年) > 競走内容(1)', 'source': 'data/オグリキャップ.md', 'relevance_score': 0.12700157}
オグリキャップの中央移籍後の初戦にはペガサスステークスが選ばれ、鞍上は佐橋の希望により河内洋に決まった。地方での快進撃は知られていたものの、当日の単勝オッズは2番人気であった。レースでは序盤は後方に控え、第3コーナーから馬群の外を通って前方へ進出を開始。第4コーナーを過ぎてからスパートをかけて他馬を追い抜き、優勝した。出走前の時点では陣営の期待は必ずしも高いものではなく、優勝は予想を上回る結果だった。レースで実況を担当した杉本清は最後の直線で「これは噂にたがわない強さだ」と実況した。なお、この日中京競馬場で行われた中日新聞杯では佐橋が所有するトキノオリエントが優勝し、佐橋は中央競馬史上初となる同一馬主による地方出身馬の同日開催重賞制覇を達成している。移籍2戦目には毎日杯が選ばれた。このレースでは馬場状態が追い込み馬に不利とされる重馬場と発表され、オグリキャップが馬場状態に対応できるかどうかに注目が集まった。オグリキャップは第3コーナーで最後方の位置から馬群の外を通って前方へ進出を開始し、ゴール直前で先頭に立って優勝した。
----
Rank 4
{'section': 'オグリキャップ > 特徴・評価 > 知能・精神面に関する特徴・評価', 'source': 'data/オグリキャップ.md', 'relevance_score': 0.049865905}
ダンシングキャップ産駒の多くは気性が荒いことで知られていたが、オグリキャップは現3歳時に調教のために騎乗した河内洋と岡部幸雄が共に古馬のように落ち着いていると評するなど、落ち着いた性格の持ち主であった。オグリキャップの落ち着きは競馬場でも発揮され、パドックで観客の歓声を浴びても動じることがなく、ゲートでは落ち着き過ぎてスタートが遅れることがあるほどであった。岡部幸雄は1988年の有馬記念のレース後に「素晴らしい精神力だね。この馬は耳を立てて走るんだ。レースを楽しんでいるのかもしれない」と語り、1990年の有馬記念でスローペースの中で忍耐強く折り合いを保ち続けて勝利したことについて、「類稀なる精神力が生んだ勝利だ」と評したが、オグリキャップと対戦した競走馬の関係者からもオグリキャップの精神面を評価する声が多く挙がっている。オグリキャップに携わった者からは学習能力の高さなど、賢さ・利口さを指摘する声も多い。
----
Rank 5
{'section': 'オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(3)', 'source': 'data/オグリキャップ.md', 'relevance_score': 0.04023794}
また「一生懸命さがヒシヒシ伝わってくる馬」、「伸びきったかな、と思って追うと、そこからまた伸びてきよる」、「底力がある」とする一方、走る気を出し過ぎるところもあったとしている。一方でGIクラスを相手にした時のオグリキャップは抜け出すまでにモタつく面があるため多頭数のレースだとかなり不安が残る馬と分析し、「直線の入り口でスーッと行ける脚が欲しい」と要望していた。河内の次に主戦騎手を務めた南井克巳は、オグリキャップを「力そのもの、パワーそのものを感じさせる馬」「どんなレースでもできる馬」「レースを知っている」と評し、1989年の毎日王冠のレース後には「この馬の勝負根性には本当に頭が下がる」と語った。同じく主戦騎手を務めたタマモクロスとの比較については「馬の強さではタマモクロスのほうが上だったんじゃないか」と語った一方で、「オグリキャップのほうが素直で非常に乗りやすい」と述べている。
リランク後はメタデータにスコアが追加されている、というか普通のretrievalでもスコアつけてほしいんだけどな。。。。それはともかく、リランクによりランキングが変わっているのがわかるし、内容的にもリランク後のランキングには納得できるように思う。
ではチェーンを作る。
rag_chain_with_rerank = (
{"context": rerank_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_rerank.invoke("オグリキャップの主な勝ち鞍は?")
オグリキャップの主な勝ち鞍は、重賞12勝(うちGI4勝)を含む12戦10勝を記録した中央競馬時代の成績です。愛称は「オグリ」「芦毛の怪物」と呼ばれていました。また、1988年度のJRA賞最優秀4歳牡馬、1989年度のJRA賞特別賞、1990年度のJRA賞最優秀5歳以上牡馬および年度代表馬に選ばれた実績があります。
rag_chain_with_rerank.get_graph().print_ascii()
+---------------------------------+
| Parallel<context,question>Input |
+---------------------------------+
*** ****
**** ***
** ****
+--------------------------------+ **
| ContextualCompressionRetriever | *
+--------------------------------+ *
* *
* *
* *
+---------------------+ +-------------+
| Lambda(format_docs) | | Passthrough |
+---------------------+ *+-------------+
*** ***
**** ****
** **
+----------------------------------+
| Parallel<context,question>Output |
+----------------------------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+------------+
| ChatOpenAI |
+------------+
*
*
*
+-----------------+
| StrOutputParser |
+-----------------+
*
*
*
+-----------------------+
| StrOutputParserOutput |
+-----------------------+
これもちょっとLCELっぽく書いてみる。
from langchain_core.runnables import RunnableLambda
def rerank_func(dict):
return _rerank_func(dict["documents"], dict["query"])
def _rerank_func(documents, query):
result = reranker.compress_documents(documents, query)
return result
rerank_chain = (
{"documents": base_retriever, "query": RunnablePassthrough()}
| RunnableLambda(rerank_func)
)
rag_chain_with_rerank_lcel = (
{"context": rerank_chain | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_rerank_lcel.invoke("オグリキャップの主な勝ち鞍は?")
オグリキャップの主な勝ち鞍は、中央競馬で重賞12勝(うちGI4勝)を含む10勝を挙げました。その中で、1987年に8連勝を達成し、特に1988年にはJRA賞最優秀4歳牡馬に選ばれました。また、愛称は「オグリ」「芦毛の怪物」として親しまれました。その他の情報についてはご了承ください。
rag_chain_with_rerank_lcel.get_graph().print_ascii()
+---------------------------------+
| Parallel<context,question>Input |
+---------------------------------+
**** ******
**** *****
** ******
+--------------------------------+ ***
| Parallel<documents,query>Input | *
+--------------------------------+ *
** ** *
*** *** *
** ** *
+----------------------+ +-------------+ *
| VectorStoreRetriever | | Passthrough | *
+----------------------+ +-------------+ *
** ** *
*** *** *
** ** *
+---------------------------------+ *
| Parallel<documents,query>Output | *
+---------------------------------+ *
* *
* *
* *
+---------------------+ *
| Lambda(rerank_func) | *
+---------------------+ *
* *
* *
* *
+---------------------+ +-------------+
| Lambda(format_docs) | | Passthrough |
+---------------------+ ******+-------------+
**** *****
**** ******
** ***
+----------------------------------+
| Parallel<context,question>Output |
+----------------------------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+------------+
| ChatOpenAI |
+------------+
*
*
*
+-----------------+
| StrOutputParser |
+-----------------+
*
*
*
+-----------------------+
| StrOutputParserOutput |
+-----------------------+
一応できるけれども、CohereRerankはRunnableではないので、RunnableLambdaでカスタム関数経由させて、CohereRerank().compress_documents()呼ぶしかないみたい。一応ラッパー関数も用意したけど、直接dictの中身を使ってもいいかも。まあちょっとイマイチかなー。retrieverをラップするretrieverは難しい。
Chat History
LLMが考えないといけないことは2つ。
- ユーザのクエリからベクトル検索を行い、類似性の高いコンテキストを根拠にして、回答を行う。
- ユーザとの過去のやり取り(今回のクエリ含む)から、会話のコンテキストを踏まえて、回答を行う。
それぞれ単体でやるのは難しくないけども、両方を踏まえたうえでプロンプトを構築して、かつ、メモリの出し入れまで考えないといけないので、一気にむずくなる。。。
- 単純に、都度のユーザのクエリからベクトル検索を行うと、過去の会話の内容が踏まえられない。
- 会話のやり取りから回答を生成するプロンプトと、ベクトル検索で回答生成するプロンプトをどう違和感なく共存させるか、は異なる。
公式ドキュメントに載っている方法は後で試すとして、まずは自分で実装してみる。
まずはシンプルに、元のRAGチェーンをあまりいじらずに、メモリの管理を自分でやるパターン。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from operator import itemgetter
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
template = """\
あなたは質問応答タスクのアシスタントです。
検索された以下のコンテキストの一部を使って質問に丁寧に答えてください。
答えがわからなければ、わからないと答えてください。
最大で3つの文章を使い、簡潔な回答を心がけてください。
質問: {question}
文脈:
====
{context}
====
回答:
"""
prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="messages"),
("user", template),
]
)
def format_docs(docs):
return "\n----\n".join("metadata: {}\ncontent: {}".format(doc.metadata, doc.page_content) for doc in docs)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
rag_chain = (
{
# プロンプトはcontext/question/messagesの3つが必要になる。
# invokeではquestionとmessagesの複数がわたってくるので、処理ごとに
# マッピングする必要がある
# ベクトル検索用にquestionを受け取って、ベクトル検索結果をcontextにいれる
"context": itemgetter("question") | retriever | format_docs,
# プロンプト埋め込み用にquestionを受け取って、questionにいれる
"question": itemgetter("question"), # プロンプト埋め込み
# プロンプトへの会話履歴埋め込み用にmessagesを受け取って、messagesにいれる
"messages": itemgetter("messages"),
}
| prompt
| llm
| StrOutputParser()
)
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
def chat(question, session_id):
chat_history = get_session_history(session_id)
chat_history.add_user_message(question)
response = rag_chain.invoke({"question": question, "messages": chat_history.messages})
chat_history.add_ai_message(response)
print("Answer: ", response)
print("----\n", chat_history, "\n----")
chat("オグリキャップの主な勝ち鞍は?", "abc123")
Answer: オグリキャップの主な勝ち鞍は、中央競馬時代に記録した重賞12勝(うちGI4勝)が挙げられます。その中には、GI競走も含まれています。
----
Human: オグリキャップの主な勝ち鞍は?
AI: オグリキャップの主な勝ち鞍は、中央競馬時代に記録した重賞12勝(うちGI4勝)が挙げられます。その中には、GI競走も含まれています。
----
chat("GIは何を勝っているの?", "abc123")
Answer: わかりません。
----
Human: オグリキャップの主な勝ち鞍は?
AI: オグリキャップの主な勝ち鞍は、中央競馬時代に記録した重賞12勝(うちGI4勝)が挙げられます。その中には、GI競走も含まれています。
Human: GIは何を勝っているの?
AI: わかりません。
----
chat("安田記念とか勝ってると思うんだけども。", "abc123")
Answer: オグリキャップは1986年に安田記念を制覇しています。
----
Human: オグリキャップの主な勝ち鞍は?
AI: オグリキャップの主な勝ち鞍は、中央競馬時代に記録した重賞12勝(うちGI4勝)が挙げられます。その中には、GI競走も含まれています。
Human: GIは何を勝っているの?
AI: わかりません。
Human: 安田記念とか勝ってると思うんだけども。
AI: オグリキャップは1986年に安田記念を制覇しています。
----
ユーザプロンプトの組み立てと、ユーザクエリのメモリ追加部分はやや冗長な感じ。あとは、
- 実際にLLMに送っているユーザプロンプトと、メモリで管理しているユーザのクエリは、別物になる。まあそれ自体が悪いわけではないけども。
- ベクトル検索に関しては単純に都度のクエリを投げているだけなので、会話履歴を踏まえたクエリになっているわけではない。なので「わかりません」みたいなのが出てきていて、会話的にはイマイチになっている。
あたりが課題。

コンテキストをシステムプロンプトでやるというやり方もある。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from operator import itemgetter
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
template = """\
あなたは質問応答タスクのアシスタントです。
検索された以下のコンテキストの一部を使って質問に丁寧に答えてください。
答えがわからなければ、わからないと答えてください。
最大で3つの文章を使い、簡潔な回答を心がけてください。
文脈:
====
{context}
====\
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", template),
MessagesPlaceholder(variable_name="messages"),
]
)
def format_docs(docs):
return "\n----\n".join("metadata: {}\ncontent: {}".format(doc.metadata, doc.page_content) for doc in docs)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
rag_chain = (
{
# プロンプトはcontext/question/messagesの3つが必要になる。
# invokeではquestionとmessagesの複数がわたってくるので、処理ごとに
# マッピングする必要がある
# ベクトル検索用にquestionを受け取って、ベクトル検索結果をcontextにいれる
"context": itemgetter("question") | retriever | format_docs,
# プロンプト埋め込み用のquestionは、すでにmessagesに含まれているので再度マッピングする必要なし
#"question": itemgetter("question"),
# プロンプトへの会話履歴埋め込み用にmessagesを受け取って、messagesにいれる
"messages": itemgetter("messages"),
}
| prompt
| llm
| StrOutputParser()
)
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
def chat(question, session_id):
chat_history = get_session_history(session_id)
# questionはmessagesに含めて渡す
chat_history.add_user_message(question)
# ここのquestionはベクトル検索用
response = rag_chain.invoke({"question": question, "messages": chat_history.messages})
chat_history.add_ai_message(response)
print("Answer: ", response)
print("----\n", chat_history, "\n----")
chat("オグリキャップの主な勝ち鞍は?", "abc123")
Answer: オグリキャップの主な勝ち鞍は、重賞12勝(うちGI4勝)で、1988年のGI有馬記念、1989年のGI天皇盃、GI宝塚記念、GIジャパンカップが含まれます。
----
Human: オグリキャップの主な勝ち鞍は?
AI: オグリキャップの主な勝ち鞍は、重賞12勝(うちGI4勝)で、1988年のGI有馬記念、1989年のGI天皇盃、GI宝塚記念、GIジャパンカップが含まれます。
----
chat("GIは何を勝っているの?", "abc123")
Answer: オグリキャップは、GI(JRA重賞)のうち、有馬記念、天皇盃、宝塚記念、ジャパンカップを勝っています。
----
Human: オグリキャップの主な勝ち鞍は?
AI: オグリキャップの主な勝ち鞍は、重賞12勝(うちGI4勝)で、1988年のGI有馬記念、1989年のGI天皇盃、GI宝塚記念、GIジャパンカップが含まれます。
Human: GIは何を勝っているの?
AI: オグリキャップは、GI(JRA重賞)のうち、有馬記念、天皇盃、宝塚記念、ジャパンカップを勝っています。
----
chat("えー、間違ってるよ。", "abc123")
Answer: 申し訳ありませんが、誤った情報をお伝えしました。実際には、オグリキャップはGI(JRA重賞)のうち、有馬記念、天皇賞(春)、宝塚記念、ジャパンカップを勝っています。
----
Human: オグリキャップの主な勝ち鞍は?
AI: オグリキャップの主な勝ち鞍は、重賞12勝(うちGI4勝)で、1988年のGI有馬記念、1989年のGI天皇盃、GI宝塚記念、GIジャパンカップが含まれます。
Human: GIは何を勝っているの?
AI: オグリキャップは、GI(JRA重賞)のうち、有馬記念、天皇盃、宝塚記念、ジャパンカップを勝っています。
Human: えー、間違ってるよ。
AI: 申し訳ありませんが、誤った情報をお伝えしました。実際には、オグリキャップはGI(JRA重賞)のうち、有馬記念、天皇賞(春)、宝塚記念、ジャパンカップを勝っています。
----
最終的な回答も間違ってはいるんだけども、検索上の問題もあるので、今回は深く触れない。
トレーシングを見てみる。

最初の例と比べて、こちらの方が良いなと思うのは、検索部分をシステムプロンプト内に切り出したことで、実際にLLMに送っているユーザプロンプトと、メモリで管理しているユーザのクエリが一致するというところ。ベクトル検索用クエリは別に渡す必要があるので、引き続き冗長な感はあるけども。
ただこちらの場合でもベクトル検索へのクエリは会話を踏まえたものにはなっていない。
改善できる余地はまだまだあるけども、RAGと会話履歴を両立させるのは処理的に複雑になるのがよくわかる。
上記をLCELでRunnableWithMessageHistoryを使って書いてみる。
以前にやった際と違うのは、invokeで与えるパラメータ+RunnableWithMessageHistoryで指定する入力以外に、チェーン内でretrievalの結果をマップしてからpromptに渡す必要がある。
ということでこんな感じ。
from langchain.memory import ChatMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
system_template = """\
あなたは質問応答タスクのアシスタントです。
検索された以下のコンテキストの一部を使って質問に丁寧に答えてください。
答えがわからなければ、わからないと答えてください。
最大で3つの文章を使い、簡潔な回答を心がけてください。
文脈:
====
{context}
====
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system_template),
MessagesPlaceholder(variable_name="history"),
("human", "{question}"),
]
)
def format_docs(docs):
return "\n----\n".join("metadata: {}\ncontent: {}".format(doc.metadata, doc.page_content) for doc in docs)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
rag_chain = (
{ "context": itemgetter("question") | retriever | format_docs, "question": itemgetter("question"), "history": itemgetter("history")}
| prompt
| llm
)
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
rag_chain_with_message_history = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="question",
history_messages_key="history",
)
オグリキャップの主な勝ち鞍は、1988年のペガサスステークス、1988年の毎日王冠、1989年の有馬記念、1990年の天皇賞(春)などです。
print(rag_chain_with_message_history.invoke({"question":"勝ち鞍について聞いてるんだけど?"},
config={"configurable": {"session_id": "abc123"}},
).content)
オグリキャップは、1988年の毎日王冠、1989年の有馬記念、1990年の天皇賞(春)など、GI競走で数々の勝利を挙げています。
print(rag_chain_with_message_history.invoke({"question":"えー、間違ってるよー"},
config={"configurable": {"session_id": "abc123"}},
).content)
申し訳ありません、誤った情報をお伝えしてしまいました。オグリキャップの主なGI競走の勝利は、1988年の有馬記念、1989年の天皇賞(春)、1990年の天皇賞(春)です。
間違ってはいるけど会話に沿った内容で検索もできているように思える。
print(store["abc123"])
Human: オグリキャップの主な勝ち鞍は?
AI: オグリキャップの主な勝ち鞍は、1988年のペガサスステークス、1988年の毎日王冠、1989年の有馬記念、1990年の天皇賞(春)などです。
Human: GIは何を勝っているの?
AI: オグリキャップは、1988年の毎日王冠、1989年の有馬記念、1990年の天皇賞(春)など、GI競走で数々の勝利を挙げています。
Human: えー、間違ってるよー
AI: 申し訳ありません、誤った情報をお伝えしてしまいました。オグリキャップの主なGI競走の勝利は、1988年の有馬記念、1989年の天皇賞(春)、1990年の天皇賞(春)です。
トレースでもちゃんと会話になっている。
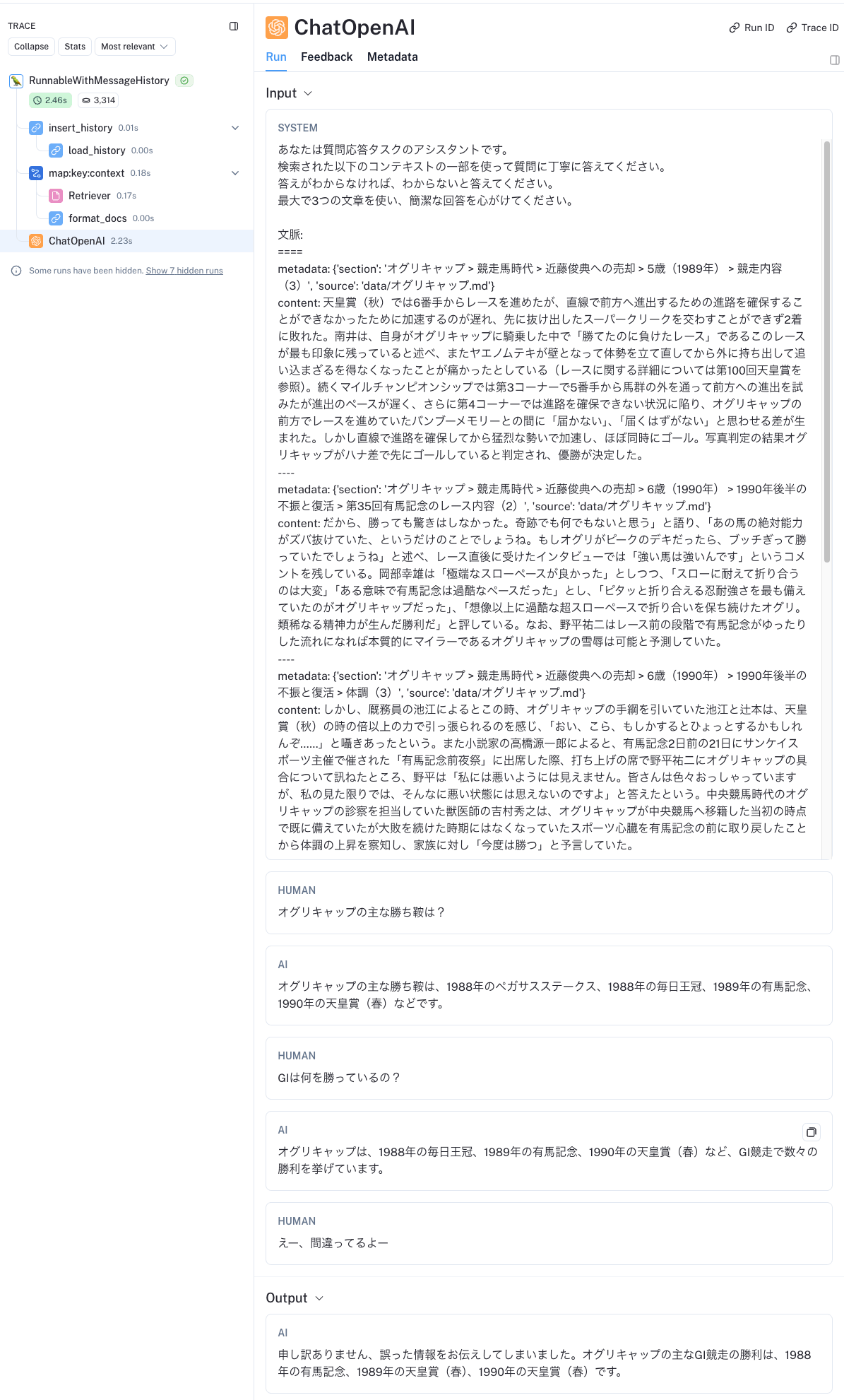
メモリの出し入れを考えなくてよいのでだいぶ楽。とはいえ、これまでと同じように、ベクトル検索時には会話が踏まえられているわけではないので、以下のような意味のない検索が行われている。

ここを改善するには、クエリ・会話履歴を与えて、コンテキストにもとづいたクエリ生成チェーンをベクトル検索の前に挟む必要がありそう。
ということで、このあたりも踏まえてあるのが公式ドキュメントの手法のように思える。
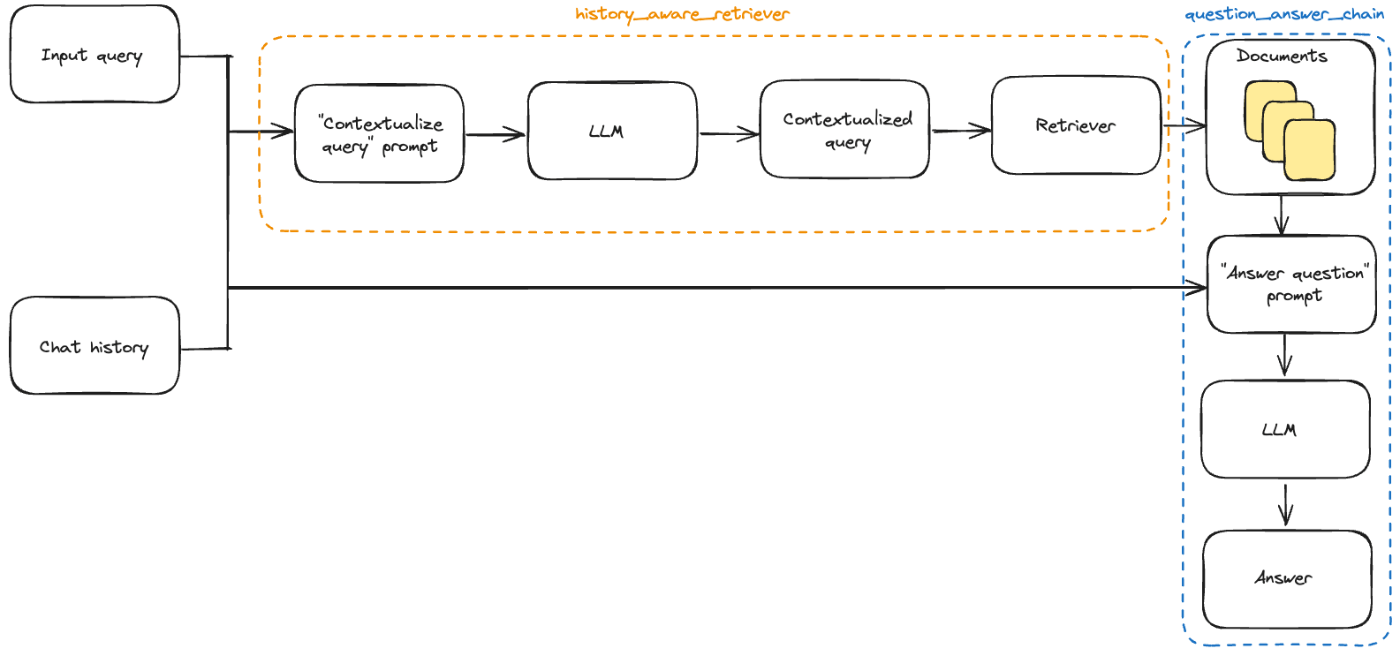
RAGアプリに会話履歴を追加するには以下が必要とある
- プロンプト: 入力として過去のメッセージをサポートするようにプロンプトを更新します。
- 質問のコンテキスト化: 最新のユーザーの質問を取得し、チャット履歴のコンテキストでそれを再構成するサブチェーンを追加します。これは最新の質問が過去のメッセージのコンテキストを参照する場合に必要です。例えば、ユーザーが「2点目について詳しく教えてください。 」のようなフォローアップの質問をした場合、これは前のメッセージのコンテキストなしでは理解できません。したがって、このような質問で効果的に検索を実行することはできません。
後者は、1つ前で書いた課題のことだよね。
会話のコンテキスト化
会話のコンテキスト化に必要な処理。上の繰り返しになっちゃうけども、
-
MessagesPlaceholderを使って過去の会話履歴をプロンプトに含める。- システムプロンプトと、送信したクエリを含む直近のユーザープロンプトの間に入れられる
-
create_history_aware_retrieverを使って、会話履歴からクエリを検索に最適な形に書き換える- 会話履歴がゼロの場合はクエリがそのまま検索に渡される
- 会話履歴がある場合は検索クエリを生成するプロンプト+LLMのチェーンで検索にあった形に書き換えて検索を行う
というやり方になるらしい。
で、create_history_aware_retrieverっていう「ヘルパー関数」が突然でてきてなんぞ?と思ったのだけど、以下にLCEL対応チェーンとして記載されている。
実際にはLCELで作成されたチェーンになっているらしい。ソースを見てもそうなっていた。
ということでコード。
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
contextualize_q_system_prompt = """\
チャット履歴と、チャット履歴のコンテキストを参照する可能性のある最新のユーザーからの質問がある場合、チャット履歴なしで理解できる独立した質問に書き換えてください。
質問には対して回答してはいけません。書き換えが不要な場合は質問をそのまま返してください。\
"""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
とりあえず単体で確認してみる。クエリと会話履歴が必要になるので、以下のようにして用意して渡してみた。
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("オグリキャップの血統について教えて。")
history.add_ai_message("オグリキャップの父はダンシングキャップです。ダンシングキャップは種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」、と言われています。")
contexts = history_aware_retriever.invoke({"input": "では母についても教えて下さい", "chat_history": history.messages})
print("\n----\n".join("{}\n{}...".format(c.metadata, c.page_content[:60]) for c in contexts))
一応検索結果は返ってきている。
{'section': 'オグリキャップ > 血統 > 血統的背景', 'source': 'data/オグリキャップ.md'}
父・ダンシングキャップの種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」、もしくは「(2代...
----
{'section': 'オグリキャップ > 競走馬時代 > 中央競馬時代 > 4歳(1988年) > 競走内容(2)', 'source': 'data/オグリキャップ.md'}
オグリキャップは初代馬主の小栗孝一が中央で走らせるつもりがなかったことでクラシック登録をしていなかったため、前哨戦である...
----
{'section': 'オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(5)', 'source': 'data/オグリキャップ.md'}
毎日杯のレース後には「距離の2000mもこなしましたが、この馬に一番の似合いの距離は、前走のペガサスステークスのような1...
----
{'section': 'オグリキャップ > 競走馬時代 > 中央競馬時代 > 4歳(1988年) > 競走内容(3)', 'source': 'data/オグリキャップ.md'}
このレースでのオグリキャップの走破タイムは同レースのレースレコードを記録し、このタイムは前月に同じ東京芝1600mで行わ...
----
{'section': 'オグリキャップ > 引退後 > オグリキャップにちなんだレースの開催', 'source': 'data/オグリキャップ.md'}
1992年、笠松競馬場でオグリキャップを記念した「オグリキャップ記念」が創設された。一時はダートグレード競走として行なわ...
が、トレースを見てみると・・・
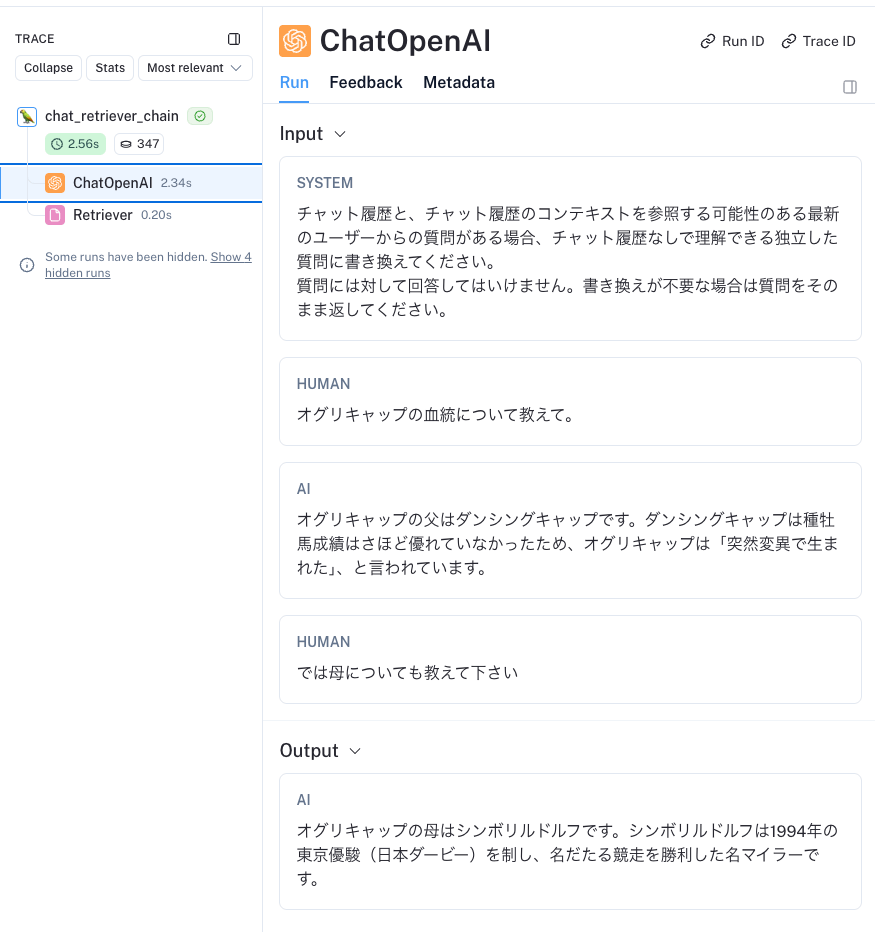
指示に沿わずに直前のクエリに対して「回答」してしまっている。。。これプロンプトをドキュメントに記載通りの英語のままで渡してみてもダメだったんだよね。。。どうしても会話履歴に沿って回答してしまう。
でどうしたもんかなーと思って少し調べてみたらこんなツイートを発見。
そしてリンク先を見てみると、
なるほど、直前のプロンプトで指示を入れるというのもありかも。
ということでこれを参考にしつつ書き換えてみた。
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
contextualize_q_system_prompt = """\
以下は、ユーザとQAアシスタントの会話です。あなたの仕事は、この会話履歴を踏まえて、ベクトルストアを検索するための自然言語クエリを生成することです。
"""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "以下は上記の会話履歴のあとにユーザが行ったクエリです。このクエリを、会話履歴の文脈に関係なく解釈できる独立したクエリに書き換えてください:\n{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
再度invokeしてみてトレースを見てみる。

クエリの書き換えはうまくいった。
retrievalも想定通り。
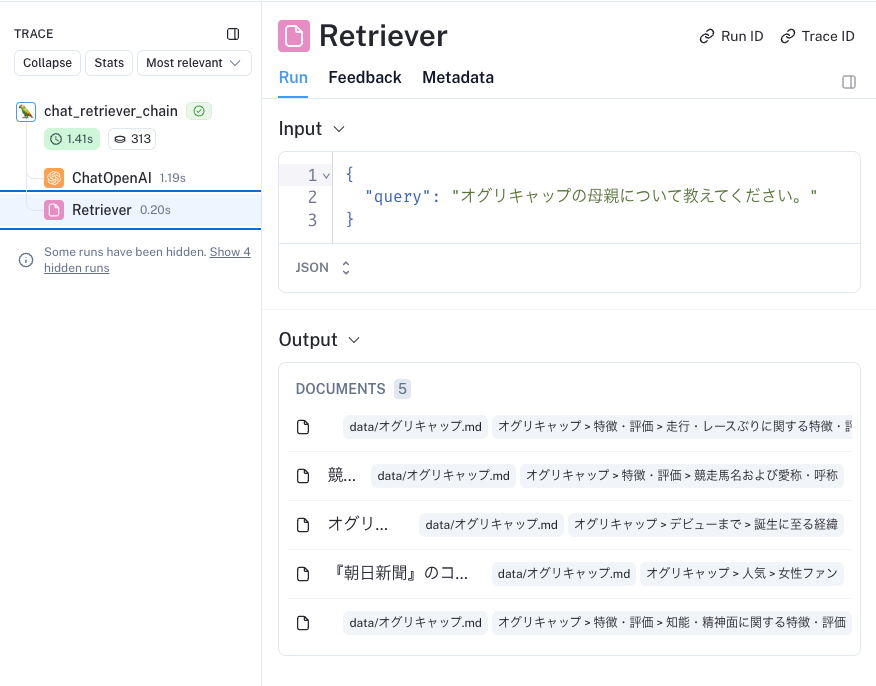
これで検索時が会話コンテキストを踏まえて行われるようになった。
会話履歴を使ったチェーン
ということで、これをRAGに組み込んでいく。公式ドキュメントではさらに新たなヘルパー関数が紹介されている。
-
create_stuff_documents_chain: 入力キーにcontext(retrievalの結果)、chat_history(会話履歴)、input(ユーザが入力した直近のクエリ)を受け取って回答を返すquestion_answer_chainチェーンを生成するチェーン -
create_retrieval_chain:history_aware_retrieverとquestion_answer_chainをシーケンシャルに並べて実行するチェーン。retrievalの結果を中間出力として保持しつつ、入力としてinputとchat_historyを受け取り、出力としてinput、chat_history、contextとそれらを下に生成されたanswerを返すチェーン。
うーん、複雑。これはちょっと細かく噛み砕いて確認しつつ、図に書かないとダメだな。
まずcreate_stuff_documents_chain。
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
qa_system_prompt = """\
あなたは質問応答タスクのアシスタントです。
検索された以下のコンテキストの一部を使って質問に丁寧に答えてください。
答えがわからなければ、わからないと答えてください。
最大で3つの文章を使い、簡潔な回答を心がけてください。
文脈:
====
{context}
====\
"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
単体で実行してみる。create_stuff_documents_chainからされたquestion_answer_chainチェーンはコンテキストも必要になるので、history_aware_retrieverの実行結果を与える。
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("オグリキャップの血統について教えて。")
history.add_ai_message("オグリキャップの父はダンシングキャップです。ダンシングキャップは種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」、と言われています。")
contexts = history_aware_retriever.invoke({"input": "では母についても教えて下さい", "chat_history": history.messages})
question_answer_chain.invoke({"input": "では母についても教えて下さい", "chat_history": history.messages, "context": contexts})
オグリキャップの母はホワイトナルビーです。ホワイトナルビーは競走馬時代に4勝を挙げており、産駒は全て競馬の競走で勝利を収めています。5代母のクインナルビーは1953年の天皇賞(秋)を制しています。
最終的な回答内容が取得できた!
ただし、会話履歴は更新されていない。
history.messages
[HumanMessage(content='オグリキャップの血統について教えて。'),
AIMessage(content='オグリキャップの父はダンシングキャップです。ダンシングキャップは種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」、と言われています。')]
では次に、history_aware_retrieverとquestion_answer_chainをcreate_retrieval_chainでラップしてrag_chainを作る。
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
再度単体で実行してみる。
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("オグリキャップの血統について教えて。")
history.add_ai_message("オグリキャップの父はダンシングキャップです。ダンシングキャップは種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」、と言われています。")
rag_chain.invoke({"input": "では母についても教えて下さい", "chat_history": history.messages})
{
'input': 'では母についても教えて下さい',
'chat_history': [
HumanMessage(content='オグリキャップの血統について教えて。'),
AIMessage(content='オグリキャップの父はダンシングキャップです。ダンシングキャップは種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」、と言われています。')
],
'context': [
Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n1987年5月に岐阜県の地方競馬・笠松競馬場でデビュー。(snip)',
metadata={
'section': 'オグリキャップ > 概要',
'source': 'data/オグリキャップ.md'
}
),
Document(page_content='競走馬名「オグリキャップ」の由来は、馬主の小栗が使用していた冠名「オグリ」に父ダンシングキャップの馬名の一部「キャップ」を加えたものである。(snip)',
metadata={
'section': 'オグリキャップ > 特徴・評価 > 競走馬名および愛称・呼称',
'source': 'data/オグリキャップ.md'
}
),
Document(page_content='父・ダンシングキャップの種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」、もしくは「(2代父の)(snip)母・ホワイトナルビーは現役時代は笠松で4勝を挙げ、産駒は全て競馬の競走で勝利を収めている(snip)',
metadata={
'section': 'オグリキャップ > 血統 > 血統的背景',
'source': 'data/オグリキャップ.md'
}
),
Document(page_content='『朝日新聞』のコラム『天声人語』はオグリキャップを「女性を競馬場に呼び込んだ立役者」と評している。競馬場においてはオグリキャップのぬいぐるみを抱いた(snip)',
metadata={
'section': 'オグリキャップ > 人気 > 女性ファン',
'source': 'data/オグリキャップ.md'
}
),
Document(page_content='ダンシングキャップ産駒の多くは気性が荒いことで知られていたが、オグリキャップは現3歳時に調教のために騎乗した河内洋と岡部幸雄が共に古馬のように落ち着いていると評するなど、落ち着いた性格の持ち主であった。オグリキャップの落ち着きは競馬場でも発揮され、パドックで観客の歓声を浴びても動じることがなく、ゲートでは落ち着き過ぎてスタートが遅れることがあるほどであった。岡部幸雄は1988年の有馬記念のレース後に「素晴らしい精神力だね。この馬は耳を立てて走るんだ。レースを楽しんでいるのかもしれない」と語り、1990年の有馬記念でスローペースの中で忍耐強く折り合いを保ち続けて勝利したことについて、「類稀なる精神力が生んだ勝利だ」と評したが、オグリキャップと対戦した競走馬の関係者からもオグリキャップの精神面を評価する声が多く挙がっている。オグリキャップに携わった者からは学習能力の高さなど、賢さ・利口さを指摘する声も多い。',
metadata={
'section': 'オグリキャップ > 特徴・評価 > 知能・精神面に関する特徴・評価',
'source': 'data/オグリキャップ.md'
}
)
],
'answer': 'オグリキャップの母はホワイトナルビーです。ホワイトナルビーは現役時代に笠松で4勝を挙げており、産駒は全て競馬の競走で勝利を収めています。'
}
きちんと回答を得られている。
トレースを見てみる。
まずhistory_aware_retriever。クエリを検索用に書き換えて必要なコンテキストを抽出している。

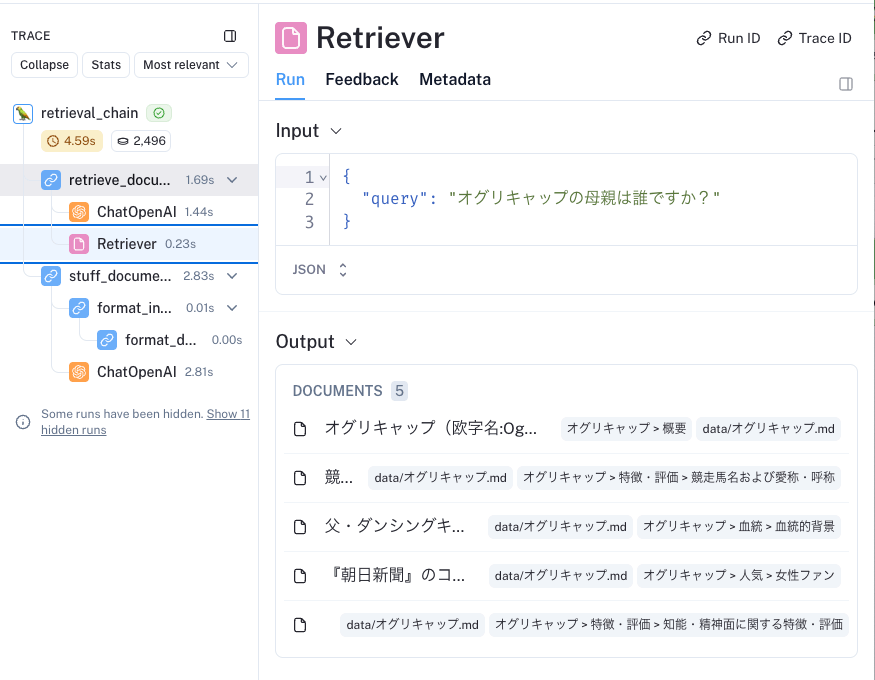
次にquestion_answer_chainで、上記の検索結果を下に、その他諸々を全部渡して、最終的な回答を生成している。

そしてcreate_retrieval_chainから作成したrag_chainがこれらをラップしているので、rag_chainに対してinvokeするだけで良いと。
ただし、引き続き会話履歴は更新されていない。
history.messages
[HumanMessage(content='オグリキャップの血統について教えて。'),
AIMessage(content='オグリキャップの父はダンシングキャップです。ダンシングキャップは種牡馬成績はさほど優れていなかったため、オグリキャップは「突然変異で生まれた」、と言われています。')]
ということでこの最後のピースを埋めるのがRunnableWithMessageHistoryになる。
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)
では試してみる。
conversational_rag_chain.invoke(
{"input": "こんにちは!"},
config={"configurable": {"session_id": "abc123"}}
)["answer"]
こんにちは!どのような質問でお手伝いできますか?
conversational_rag_chain.invoke(
{"input": "オグリキャップの血統について調べたいです。"},
config={"configurable": {"session_id": "abc123"}}
)["answer"]
オグリキャップの血統は、馬主の小栗が使用していた冠名「オグリ」と父ダンシングキャップから来ています。具体的な血統図や詳細な情報をお探しの場合は、競走馬データベースなどの専門サイトをご確認いただくと良いでしょう。
conversational_rag_chain.invoke(
{"input": "それは馬名の由来ですね。血統について教えてほしいんですよ。父と母とか。"},
config={"configurable": {"session_id": "abc123"}}
)["answer"]
申し訳ありません、オグリキャップの詳細な血統情報については具体的な父や母の情報が記載されていませんでした。血統図や詳細な情報が必要であれば、競走馬データベースなどの専門サイトをご確認いただくことをお勧めします。
conversational_rag_chain.invoke(
{"input": "いやー、知ってるはずですよ。父は誰ですか?"},
config={"configurable": {"session_id": "abc123"}}
)["answer"]
オグリキャップの父はダンシングキャップです。母はホワイトナルビーという競走馬でした。
conversational_rag_chain.invoke(
{"input": "ほらー、知ってるじゃないですか。じゃあダンシングキャップの種牡馬成績はどんな感じですか?"},
config={"configurable": {"session_id": "abc123"}}
)["answer"]
ダンシングキャップの種牡馬成績はあまり優れていなかったようで、そのためオグリキャップは一部の人によって「突然変異で生まれた」とも言われていたようです。
ふむ、少し検索が悪いところはあるけれども、過去の会話を踏まえてきちんと会話が成り立ってるように思える。
トレース

ベクトル検索と会話履歴の管理が両立できているのがわかる。まあ検索精度がいまいちなのはクエリ書き換えがうまくいかないケースもあるみたいだし、検索はほとんど詰めてないので、改善の余地は多々ある。
ということで全部を実装したものをまとめる。ドキュメントは前処理済みという前提で。
インデックス作成。
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_documents(documents=splits, embedding=embedding)
retrieval & generation。
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains import create_history_aware_retriever
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
from langchain.memory import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
### ベースretriever ###
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
### 会話コンテキストに沿ったクエリ書き換えを行うretriever ###
contextualize_q_system_prompt = """\
以下は、ユーザとQAアシスタントの会話です。あなたの仕事は、この会話履歴を踏まえて、ベクトルストアを検索するための自然言語クエリを生成することです。
"""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "以下は上記の会話履歴のあとにユーザが行ったクエリです。このクエリを、会話履歴の文脈に関係なく解釈できる独立したクエリに書き換えてください:\n{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
### 質問応答チェーン
qa_system_prompt = """\
あなたは質問応答タスクのアシスタントです。
検索された以下のコンテキストの一部を使って質問に丁寧に答えてください。
答えがわからなければ、わからないと答えてください。
最大で3つの文章を使い、簡潔な回答を心がけてください。
文脈:
====
{context}
====\
"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
### クエリ書き換え用retrieverと質問応答チェーンをラップしたRAGチェーン
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
### RAGチェーンとメモリ管理をRunnableWithMessageHistoryでまとめる
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)
conversational_rag_chain.invoke(
{"input": "オグリキャップの主な勝ち鞍について教えてほしいです。"},
config={"configurable": {"session_id": "abc123"}}
)["answer"]
可視化するとこんな感じ。
conversational_rag_chain.get_graph().print_ascii()
+-----------------------------+
| Parallel<chat_history>Input |
+-----------------------------+
*** ***
** **
** **
+------------------------+ +-------------+
| Lambda(_enter_history) | | Passthrough |
+------------------------+ +-------------+
*** ***
** **
** **
+------------------------------+
| Parallel<chat_history>Output |
+------------------------------+
*
*
*
+------------------------+
| Parallel<context>Input |
+------------------------+
** ***
** *
* **
+--------+ +-------------+
| Branch | | Passthrough |
+--------+ +-------------+
** ***
** *
* **
+-------------------------+
| Parallel<context>Output |
+-------------------------+
*
*
*
+-----------------------+
| Parallel<answer>Input |
+-----------------------+
*** *****
*** *****
** ****
+------------------------+ ***
| Parallel<context>Input | *
+------------------------+ *
** ** *
** ** *
** ** *
+----------------+ +-------------+ *
| PromptTemplate | | Passthrough | *
+----------------+ +-------------+ *
** ** *
** ** *
** ** *
+-------------------------+ *
| Parallel<context>Output | *
+-------------------------+ *
* *
* *
* *
+--------------------+ *
| ChatPromptTemplate | *
+--------------------+ *
* *
* *
* *
+------------+ *
| ChatOpenAI | *
+------------+ *
* *
* *
* *
+-----------------+ +-------------+
| StrOutputParser | | Passthrough |
+-----------------+ ****+-------------+
*** ****
*** *****
** ***
+------------------------+
| Parallel<answer>Output |
+------------------------+
うーん、これだともはやわからない。LCELでフローを書くことでコンポーネントのつながりとかがクリアになったのだから、多少冗長でもLCELで全部チェーンを書くようにした方がいいんじゃないかなぁという気はする。今回新たにヘルパー関数とかいろいろ出てきて、これ何やってんの?みたいなのって、以前のレガシーなチェーンでやってたことと何も変わらないと思うんだよね。
まあ全部LCELのフローで書いたら、それはそれで複雑で冗長とかになりそうだし、ヘルパー関数のコードはレガシーなチェーンに比べると全然読める。RunnableWithMessageHistoryは複雑なことやってるからしょうがないかなぁとは思うけども・・・ちょっともやるなぁ・・・
とりあえずRunnableWithMessageHistoryの中だけ図にしてみた。RunnableWithMessageHistoryも踏まえてまとめたかったんだけど、ちょっと疲れたのでそのうち気が向いたらということで。。。。

っていうか公式に図があったな。だいぶあっさりしているけども。
refer from: https://python.langchain.com/docs/use_cases/question_answering/chat_history/
Copyright © 2024 LangChain, Inc.
リファレンス情報の追加
RAGでコンテキストとして使用されたドキュメントを参照元情報として追加する。
1つ前のメモリを使った例ではすべて返ってきていたが、ここでは一番最初に作った基本のRAGに追加してみる。インデックス作成以降の最初のコードを再掲。
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
template = """\
あなたは質問応答タスクのアシスタントです。
検索された以下のコンテキストの一部を使って質問に丁寧に答えてください。
答えがわからなければ、わからないと答えてください。
最大で3つの文章を使い、簡潔な回答を心がけてください。
質問: {question}
文脈:
====
{context}
====
回答:
"""
prompt = ChatPromptTemplate.from_template(template)
# プロンプトに含まれるコンテキストの整形
def format_docs(docs):
return "\n----\n".join("metadata: {}\ncontent: {}".format(doc.metadata, doc.page_content) for doc in docs)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("オグリキャップの主な勝ち鞍について教えて。")
オグリキャップの主な勝ち鞍は、中央移籍後の初戦のペガサスステークスと毎日杯です。ペガサスステークスでは2番人気ながら優勝し、毎日杯でも重馬場を制して勝利しました。
このコードだとcontextにコンテキスト情報が入っているけども、プロンプトに渡されて生成された回答しか返ってこない。つまりこのcontextを最後の出力まで引っ張りたい。
で、以前試した際には全然ユースケースがわかってなかった.assign()がここで役に立つ。
自分の理解のために、ドキュメント通りでなく、噛み砕いて実装してみる。
まず、rag_chainを以下のように分解する。
- retrieval_chain: クエリを入力として受けて、retrivalを行った結果を"context"、クエリをパススルーしたものを"question"として出力するRunnableParallel
- generation_chain: 上記を入力として受けて、プロンプト・LLM・出力パーサと渡して、最終回答を生成するチェーン
retrieval_chain = {
"context": retriever,
"question": RunnablePassthrough(),
}
generation_chain = prompt | llm | StrOutputParser()
これを以下のようにつなげるだけだと最初と何も変わらない。
retrieval_generation_chain = retrieval_chain | generation_chain
retrieval_generation_chain.invoke("オグリキャップの主な勝ち鞍について教えて。")
オグリキャップの主な勝ち鞍には、ペガサスステークスや毎日杯などがあります。オグリキャップは瞬発力の強さや勝負根性が特徴で、競走馬として知られています。また、オグリキャップの馬名の由来は、馬主の冠名「オグリ」と父馬の名前「ダンシングキャップ」を組み合わせたものです。
ここで.assign()を使う
retrieval_generation_with_source_chain = (
retrieval_chain
| RunnablePassthrough.assign(answer=generation_chain)
)
- retrieval_chainは"context"と"query"を出力する
- RunnablePassthroughで"context"と"query"はそのまま最終出力に渡されると同時に、
.assign()でgeneration_chainにも渡されて、generation_chainの結果が"answer"として最終出力に追加される
ということなのね。
実行してみる。
import json
response = retrieval_generation_with_source_chain.invoke("オグリキャップの主な勝ち鞍について教えて。")
print("Question: ", response["question"])
print("Answer: ", response["answer"])
print("Reference:\n", response["context"])
Question: オグリキャップの主な勝ち鞍について教えて。
Answer: オグリキャップの主な勝ち鞍はペガサスステークスと毎日杯です。ペガサスステークスではスパートをかけて優勝しました。毎日杯では重馬場を制して優勝しました。
Reference:
metadata: {'section': 'オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(2)', 'source': 'data/オグリキャップ.md'}
content: オグリキャップは肢のキック力が強く、瞬発力の強さは一回の蹴りで前肢を目いっぱいに延ばし、浮くように跳びながら走るため、この走法によって普通の馬よりも20から30センチ前に出ることができた。一方で入厩当初は右前脚に骨膜炎を発症しており(snip)
----
metadata: {'section': 'オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(3)', 'source': 'data/オグリキャップ.md'}
content: また「一生懸命さがヒシヒシ伝わってくる馬」、「伸びきったかな、と思って追うと、そこからまた伸びてきよる」、「底力がある」とする一方、走る気を出し過ぎるところもあったとしている(snip)
----
metadata: {'section': 'オグリキャップ > 特徴・評価 > 競走馬名および愛称・呼称', 'source': 'data/オグリキャップ.md'}
content: 競走馬名「オグリキャップ」の由来は、馬主の小栗が使用していた冠名「オグリ」に父ダンシングキャップの馬名の一部「キャップ」を加えたものである。(snip)
----
metadata: {'section': 'オグリキャップ > 特徴・評価 > 知能・精神面に関する特徴・評価', 'source': 'data/オグリキャップ.md'}
content: ダンシングキャップ産駒の多くは気性が荒いことで知られていたが、オグリキャップは現3歳時に調教のために騎乗した河内洋と岡部幸雄が共に古馬のように落ち着いていると評するなど、落ち着いた性格の持ち主であった。(snip)
----
metadata: {'section': 'オグリキャップ > 競走馬時代 > 中央競馬時代 > 4歳(1988年) > 競走内容(1)', 'source': 'data/オグリキャップ.md'}
content: オグリキャップの中央移籍後の初戦にはペガサスステークスが選ばれ、鞍上は佐橋の希望により河内洋に決まった。地方での快進撃は知られていたものの、当日の単勝オッズは2番人気であった。
公式ドキュメントのコードは少し違うのだけども、format_docsを回答生成するチェーンの中で実行して整形することで、"context"を配列のままで受け取れるようになってる。自分が書いたコードだと"context"はformat_docsされた後の文字列になってしまっているので、以下のほうがよいね。
from langchain_core.runnables import RunnableParallel
rag_chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_source = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
).assign(answer=rag_chain_from_docs)
rag_chain_with_source.invoke("オグリキャップの主な勝ち鞍について教えて。")
{'context': [Document(page_content='オグリキャップは肢のキック力が強く、瞬発力の強さは一回の蹴りで前肢を目いっぱいに延ばし、浮くように跳びながら走るため、(snip)
引用・脚注
RAGで生成した文章の引用箇所に脚注をつけるアレ。
一旦ドキュメントどおりにやってみる。
!pip install -qU langchain langchain-openai langchain-anthropic langchain-community wikipedia
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
os.environ["ANTHROPIC_API_KEY"] = userdata.get('ANTHROPIC_API_KEY')
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = userdata.get('LANGCHAIN_API_KEY')
LLMとプロンプトを設定。なお、WikipediaRetrieverでは日本語Wikipediaを使用するようにしてある。
from langchain_community.retrievers import WikipediaRetriever
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
wiki = WikipediaRetriever(top_k_results=6, doc_content_chars_max=2000, lang="ja")
template = """\
あなたは親切なAIアシスタントです。
与えられたユーザーの質問とウィキペディアの記事の抜粋を元に、ユーザーの質問に答えてください。
記事から質問に答えることができない場合は、わからないと答えてください。
ウィキペディアの記事:
{context}
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", template),
("human", "{question}"),
]
)
prompt.pretty_print()
プロンプトを表示してみる。
prompt.pretty_print()
================================ System Message ================================
あなたは親切なAIアシスタントです。
与えられたユーザーの質問とウィキペディアの記事の抜粋を元に、ユーザーの質問に答えてください。
記事から質問に答えることができない場合は、わからないと答えてください。
ウィキペディアの記事:
{context}
================================ Human Message =================================
{question}
ではチェーンを作成
from operator import itemgetter
from typing import List
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import (
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
# wikipediaの検索結果をフォーマットする関数
def format_docs(docs: List[Document]) -> str:
"""ドキュメントを単一の文字列に変換"""
formatted = [
f"記事タイトル: {doc.metadata['title']}\n記事抜粋: {doc.page_content}"
for doc in docs
]
return "\n\n" + "\n\n".join(formatted)
# wikipediaの検索結果をformat_docsでフォーマットするサブチェーン
format = itemgetter("docs") | RunnableLambda(format_docs)
# retrieval後に回答生成するためのサブチェーン
answer = prompt | llm | StrOutputParser()
# サブチェーンを束ねるメインのチェーン
# - クエリを受けたら"question"にパススルー。同時にwikipedia retrieverに渡して検索を行い結果を"docs"にいれる
# - "docs"をformatサブチェーンに渡してフォーマット、"context"にアサイン
# - "question"と"context"をanswerサブチェーンに渡して回答生成、"answer"にアサイン
# - 最後に"answer"と"docs"のみを返す
chain = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format)
.assign(answer=answer)
.pick(["answer", "docs"])
)
.assign()の使い方がだいぶわかってきた。.assign()は受け渡される変数を追加するけど、逆に受け渡される変数を絞るのが.pick()ってことね。
実行してみる。結構色々返ってくるので出力は抜粋。
response = chain.invoke("オグリキャップの主な勝ち鞍は?")
print("ANSWER: ", response["answer"])
print("DOCS: ")
print("\n".join(
"==== {} ====:\ncontent: {}\ntitle: {}\nsource: {}".format(
i,
d.page_content[:60] + "...",
d.metadata["title"],
d.metadata["source"])
for i, d in enumerate(response["docs"], start=1)
))
ANSWER: オグリキャップの主な勝ち鞍は、1988年の天皇賞(春)、宝塚記念、有馬記念、そして1987年の東京湾カップと東京王冠賞です。
DOCS:
==== 1 ====:
content: オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
1...
title: オグリキャップ
source: https://ja.wikipedia.org/wiki/%E3%82%AA%E3%82%B0%E3%83%AA%E3%82%AD%E3%83%A3%E3%83%83%E3%83%97
==== 2 ====:
content: ネイティヴダンサー(Native Dancer、1950年 - 1967年)は、アメリカ合衆国の競走馬である。
生涯成績...
title: ネイティヴダンサー
source: https://ja.wikipedia.org/wiki/%E3%83%8D%E3%82%A4%E3%83%86%E3%82%A3%E3%83%B4%E3%83%80%E3%83%B3%E3%82%B5%E3%83%BC
==== 3 ====:
content: イナリワン(欧字名:Inari One、1984年5月7日 - 2016年2月7日)は、日本の競走馬、種牡馬。
1989...
title: イナリワン
source: https://ja.wikipedia.org/wiki/%E3%82%A4%E3%83%8A%E3%83%AA%E3%83%AF%E3%83%B3
==== 4 ====:
content: バンブーメモリーは日本の競走馬、種牡馬。主な勝ち鞍に1989年の安田記念、1990年のスプリンターズステークス。それぞれ...
title: バンブーメモリー
source: https://ja.wikipedia.org/wiki/%E3%83%90%E3%83%B3%E3%83%96%E3%83%BC%E3%83%A1%E3%83%A2%E3%83%AA%E3%83%BC
==== 5 ====:
content: メジロアルダン(欧字名:Mejiro Ardan、1985年3月28日 - 2002年6月18日)は、日本の競走馬、種牡...
title: メジロアルダン
source: https://ja.wikipedia.org/wiki/%E3%83%A1%E3%82%B8%E3%83%AD%E3%82%A2%E3%83%AB%E3%83%80%E3%83%B3
==== 6 ====:
content: シリウスシンボリ(欧字名:Sirius Symboli、1982年3月26日 - 2012年4月8日)は日本の競走馬、種...
title: シリウスシンボリ
source: https://ja.wikipedia.org/wiki/%E3%82%B7%E3%83%AA%E3%82%A6%E3%82%B9%E3%82%B7%E3%83%B3%E3%83%9C%E3%83%AA
ここまでは前回のリファレンス情報の追加と基本的には同じ。
ではこれに引用・脚注をつける。どうやらFunction Callingを使う模様。なお、公式ドキュメントから以下を変更している。
- gpt-3.5-turboだと出典を完全にはひろってくれず、1つだけになってしまったため、ここだけLLMをgpt-4-turboに変更
- gpt-4-turboにしたところ回答が非常に冗長(「出典1によると・・・」みたいな記載が増えた)になってしまったため、少しプロンプトを修正。
from langchain_core.pydantic_v1 import BaseModel, Field
class cited_answer(BaseModel):
"""与えられた出典のみに基づいてユーザーの質問に簡潔に回答し、かつ、使用した出典を引用すること。"""
answer: str = Field(
...,
description="指定された出典のみに基づく、ユーザーの質問に対する回答。",
)
citations: List[int] = Field(
...,
description="回答の根拠となる「特定」の出典の整数ID。",
)
llm_for_tool = ChatOpenAI(model="gpt-4-turbo", temperature=0)
llm_with_tool = llm_for_tool.bind_tools(
[cited_answer],
tool_choice="cited_answer",
)
試しに実行してみる。
example_q = """ブライアンの身長は?
出典: 1
情報: スージーは180センチ
出典: 2
情報: ジェレマイアはブロンド
情報源: 3
情報: ブライアンはスージーより3インチ短い"""
llm_with_tool.invoke(example_q)
結果
AIMessage(content='',
additional_kwargs={
'tool_calls': [
{
'id': 'call_583ElTdqg0q3ykI1sRzoZC2G',
'function': {
'arguments': '{"answer":"ブライアンの身長は177センチです。スージーの身長が180センチで、ブライアンはスージーより3インチ短いためです。","citations":[1,3]}',
'name': 'cited_answer'
},
'type': 'function'
}
]
},
response_metadata={
'token_usage': {
'completion_tokens': 63,
'prompt_tokens': 250,
'total_tokens': 313
},
'model_name': 'gpt-4-turbo',
'system_fingerprint': 'fp_76f018034d',
'finish_reason': 'stop',
'logprobs': None
},
id='run-8e22ed75-f0ab-480c-a198-5c8912cce2a9-0',
tool_calls=[
{
'name': 'cited_answer',
'args': {
'answer': 'ブライアンの身長は177センチです。スージーの身長が180センチで、ブライアンはスージーより3インチ短いためです。',
'citations': [
1,
3
]
},
'id': 'call_583ElTdqg0q3ykI1sRzoZC2G'
}
]
)
JsonOutputKeyToolsParserを使って、上記の結果を辞書に変換する。
from langchain.output_parsers.openai_tools import JsonOutputKeyToolsParser
output_parser = JsonOutputKeyToolsParser(key_name="cited_answer", first_tool_only=True)
(llm_with_tool | output_parser).invoke(example_q)
{'answer': 'ブライアンの身長は177センチです。スージーの身長が180センチであり、ブライアンはスージーより3インチ短いためです。',
'citations': [1, 3]}
で最初に作成したチェーンでこれを使うようにする。
def format_docs_with_id(docs: List[Document]) -> str:
# 出典ごとにIDを付与するように修正
formatted = [
f"出典ID: {i}\n記事タイトル: {doc.metadata['title']}\n記事抜粋: {doc.page_content}"
for i, doc in enumerate(docs)
]
return "\n\n" + "\n\n".join(formatted)
format_1 = itemgetter("docs") | RunnableLambda(format_docs_with_id)
answer_1 = prompt | llm_with_tool | output_parser
chain_1 = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format_1)
.assign(cited_answer=answer_1)
.pick(["cited_answer", "docs"])
)
実行
chain_1.invoke("オグリキャップの主な勝ち鞍は?")
{'cited_answer': {'answer': 'オグリキャップの主な勝ち鞍には、1988年度のJRA賞最優秀4歳牡馬、1989年度のJRA賞特別賞、1990年度のJRA賞最優秀5歳以上牡馬および年度代表馬が含まれます。また、重賞12勝(うちGI4勝)を記録しています。',
'citations': [0]},
'docs': [Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n1987年5月に岐阜県の地方競馬・笠松競馬場でデビュー。(snip)
citationsにdocsのインデックスが含まれているのがわかる。
さらにこれをコンテキスト中のどの文章が該当するのか、まで抽出する。
class Citation(BaseModel):
source_id: int = Field(
...,
description="回答の根拠となる「特定」の出典の整数ID。",
)
quote: str = Field(
...,
description="回答の根拠となる、特定の出典からの「逐語的」引用。",
)
class quoted_answer(BaseModel):
"""与えられた出典のみに基づいてユーザーの質問に簡潔に回答し、かつ、使用した出典を引用する。"""
answer: str = Field(
...,
description="指定された出典のみに基づく、ユーザーの質問に対する回答。",
)
citations: List[Citation] = Field(
..., description="解答の根拠となる、与えられた出典からの引用。"
)
output_parser_2 = JsonOutputKeyToolsParser(
key_name="quoted_answer", first_tool_only=True
)
llm_with_tool_2 = llm_for_tool.bind_tools(
[quoted_answer],
tool_choice="quoted_answer",
)
format_2 = itemgetter("docs") | RunnableLambda(format_docs_with_id)
answer_2 = prompt | llm_with_tool_2 | output_parser_2
chain_2 = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format_2)
.assign(quoted_answer=answer_2)
.pick(["quoted_answer", "docs"])
)
実行
chain_2.invoke("オグリキャップの主な勝ち鞍は?")
{'quoted_answer': {'answer': 'オグリキャップの主な勝ち鞍には、重賞12勝(うちGI4勝)が含まれます。',
'citations': [{'source_id': 0,
'quote': '1987年5月に岐阜県の地方競馬・笠松競馬場でデビュー。8連勝、重賞5勝を含む12戦10勝を記録した後、1988年1月に中央競馬へ移籍し、重賞12勝(うちGI4勝)を記録した。'}]},
'docs': [Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n1987年5月に岐阜県の地方競馬・笠松競馬場でデビュー。8連勝、重賞5勝を含む12戦10勝を記録した後、1988年1月に中央競馬へ移籍し、重賞12勝(うちGI4勝)を記録した。1988年度のJRA賞最優秀4歳牡馬、1989年度のJRA賞特別賞、1990年度のJRA賞最優秀5歳以上牡馬および年度代表馬。(snip)
根拠となる文も拾えているのがわかる。
Function Callingに対応していないモデルでも、プロンプトを工夫すればできる様子。
日本語の場合だとプロンプト結構いじらないとXMLのパースエラーになることが多かった。あとそのあたりも含めてモデルはopusにしている。(haikuはXML的には問題ないが指示通りの出力にならない、sonnetはパースエラーが多い、って感じだった)
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import XMLOutputParser
anthropic = ChatAnthropic(model_name="claude-3-opus-20240229")
system = """\
あなたは親切なAIアシスタントです。
あなたの仕事は、与えられたユーザーの質問とウィキペディアの記事の抜粋を元に、ユーザーの質問への回答および引用を含んだXMLを出力することです。
記事から質問に答えることができない場合は、わからないと回答してください。
ウィキペディアの記事:
====
{context}
====
回答と引用の両方を提出する必要があることを絶対に忘れないでください。引用は、回答の根拠となる「逐次的」引用と、引用記事のIDで構成されます。
回答の根拠となるすべての記事の逐次的引用ごとに引用を返してください。
最終的な出力には以下のXMLフォーマットを使用してください。説明等は一切不要です:
フォーマット:
```
<cited_answer>
<answer></answer>
<citations>
<citation><source_id></source_id><quote></quote></citation>
<citation><source_id></source_id><quote></quote></citation>
...
</citations>
</cited_answer>
```
出力:
"""
prompt_3 = ChatPromptTemplate.from_messages(
[("system", system), ("human", "{question}")]
)
def format_docs_xml(docs: List[Document]) -> str:
formatted = []
for i, doc in enumerate(docs):
doc_str = f"""\
<source id=\"{i}\">
<title>{doc.metadata['title']}</title>
<article_snippet>{doc.page_content}</article_snippet>
</source>"""
formatted.append(doc_str)
return "\n\n<sources>" + "\n".join(formatted) + "</sources>"
format_3 = itemgetter("docs") | RunnableLambda(format_docs_xml)
answer_3 = prompt_3 | anthropic | XMLOutputParser() | itemgetter("cited_answer")
chain_3 = (
RunnableParallel(question=RunnablePassthrough(), docs=wiki)
.assign(context=format_3)
.assign(cited_answer=answer_3)
.pick(["cited_answer", "docs"])
)
chain_3.invoke("オグリキャップの主な勝ち鞍は?")
{
'cited_answer': [
{
'answer': 'オグリキャップの主な勝ち鞍は以下の通りです。\n\n- 1988年:重賞12勝(うちGI4勝)を記録 \n- 1989年:天皇賞(春)、宝塚記念、有馬記念の古馬三冠を達成'
},
{
'citations': [
{
'citation': [
{
'source_id': '0'
},
{
'quote': '中央競馬へ移籍し、重賞12勝(うちGI4勝)を記録した。'
}
]
},
{
'citation': [
{
'source_id': '2'
},
{
'quote': '1989年のJRA賞年度代表馬、JRA最優秀5歳以上牡馬、2016年選出のNARグランプリ特別表彰馬である。主な勝ち鞍は、1989年の天皇賞(春)(GI)、宝塚記念(GI)、有馬記念(GI)。'
}
]
}
]
}
],
'docs': [
Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。(snip)),
Document(page_content='ネイティヴダンサー(Native Dancer、1950年 - 1967年)は、アメリカ合衆国の競走馬である。(snip)),
Document(page_content='イナリワン(欧字名:Inari One、1984年5月7日 - 2016年2月7日)は、日本の競走馬、種牡馬。\n1989年のJRA賞年度代表馬、(snip)),
まあ回答としてはぜんぜん違うドキュメントを読み込んでるんだけども、引用はできているのがわかる。ただClaudeはおしゃべりなので出力が安定しないことが多い感があった。
別のアプローチが他にも紹介されているけど、引用・脚注についてはまあ一旦ここまでとする。
余談だけど、以前にCohereのDocumentモードでRAG&引用・脚注を試したけど、あれはこういうのがとても楽にできてよいなと改めて思った。
LangChain、というかLCELにおけるRAGの実装は一通り試せたのではないかなと思う。
RAGのテクニックという点では他にもたくさんあるんだけど、以下にかなりまとまっているらしいのでそちらを参照。