LangChainのOutput Parserを試す
Quick start
出力パーサは以下のメソッドを持つ。
-
get_format_instructions: 言語モデルの出力がどのようにフォーマットされるべきかの命令を含む文字列を返すメソッド。 -
parse: 文字列(言語モデルからのレスポンスを想定)を受け取り、それを何らかの構造にパースするメソッド。 -
parse_with_prompt: [オプション] 文字列(言語モデルからのレスポンスを想定)とプロンプト(そのレスポンスを生成したプロンプトを想定)を取り込み、それを何らかの構造に解析するメソッド。プロンプトは、OutputParserが何らかの方法で出力を再試行または修正したい場合に、そのためにプロンプトからの情報を必要とする場合に提供される。
以下はPydandicOutputParserの例
!pip install --upgrade --quiet langchain langchain-core langchain-openai
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
この例では、LCELででてきたようなOutputParserの使い方とは少し違って、プロンプトにOutputParserの指示プロンプトを埋め込むような使い方になっている。
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0.3)
# 必要なデータ構造を定義
class Joke(BaseModel):
setup: str = Field(description="ジョークを生成するための質問")
punchline: str = Field(description="ジョークを成り立たせるための回答")
# Pydanticを使ってカスタムな検証ロジックを簡単に追加することが可能
@validator("setup")
def question_ends_with_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("Badly formed question!")
return field
# パーサをセットアップし、プロンプトテンプレートに指示を注入
parser = PydanticOutputParser(pydantic_object=Joke)
prompt = ChatPromptTemplate(
messages=[
HumanMessagePromptTemplate.from_template(
"ユーザからの質問に回答して下さい。回答は日本語で。\n{format_instructions}\n{query}\n"
),
],
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 言語モデルにデータ構造を入力させるためのクエリ
prompt_and_model = prompt | model
チェーンにクエリを送る。なるほど、ここで生成した出力をparserに通しているのか。
output = prompt_and_model.invoke({"query": "ジョークを言ってみて。"})
parser.invoke(output)
Joke(setup='なぜライオンはサーカスでジャグリングができないの?', punchline='なぜなら、彼らにはすでにたくさんのマネージャーがいるから!')
実質的にはこれは上と同じ。
prompt_and_model_parser = prompt | model | parser
prompt_and_model_parser.invoke({"query": "ジョークを言ってみて。"})
Joke(setup='なぜサルは木の上でバナナを食べるの?', punchline='なぜなら、下で食べると落ちるから!')
すべてのparserはストリーミングインタフェースをサポートしているが、オブジェクトを部分的にパースしてストリーミングできるかはparserによって異なる。
例えばSimpleJsonOutputParserはストリーミング出力が可能
from langchain.output_parsers.json import SimpleJsonOutputParser
json_prompt = ChatPromptTemplate.from_template(
"次の質問に答える`answer`キーを持つJSONオブジェクトを返してください: {question}"
)
json_parser = SimpleJsonOutputParser()
json_chain = json_prompt | model | json_parser
list(json_chain.stream({"question": "顕微鏡を発明したのは誰?"}))
[{},
{'answer': ''},
{'answer': 'ア'},
{'answer': 'アント'},
{'answer': 'アントニ'},
{'answer': 'アントニ・'},
{'answer': 'アントニ・ファ'},
{'answer': 'アントニ・ファン'},
{'answer': 'アントニ・ファン・'},
{'answer': 'アントニ・ファン・レ'},
{'answer': 'アントニ・ファン・レーウ'},
{'answer': 'アントニ・ファン・レーウェ'},
{'answer': 'アントニ・ファン・レーウェン'},
{'answer': 'アントニ・ファン・レーウェンフ'},
{'answer': 'アントニ・ファン・レーウェンフック'}]
上で使用したPydanticOutputParserはストリーミング不可。
list(prompt_and_model_parser.stream({"query": "ジョークを言ってみて。"}))
OutputParserException: Invalid json output:
ビルトインのOutputParser
ドキュメントには13個(バリエーションを含めると18個かな)紹介されている。
- CSV parser(
CommaSeparatedListOutputParser) - Datetime parser(
DatetimeOutputParser) - Datetime parser(
EnumOutputParser) - JSON parser(
JsonOutputParser) - OpenAI Functions(
JsonOutputFunctionsParser/JsonKeyOutputFunctionsParser/PydanticOutputFunctionsParser/PydanticAttrOutputFunctionsParser) - OpenAI Tools(
JsonOutputToolsParser/JsonOutputKeyToolsParser/PydanticToolsParser) - Output fixing parser(
OutputFixingParser) - Pandas Dataframe parser(
PandasDataFrameOutputParser) - Pydantic parser(
PydanticOutputParser) - Retry parser(
RetryOutputParser) - Structured output parser(
StructuredOutputParser) - XML parser(
XMLOutputParser) - YAML parser(
YamlOutputParser)
順に軽く触っていく。
CSV parser
CSV出力を行うパーサ。CommaSeparatedListOutputParserを使う。
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | ◯ |
| 指示プロンプト | ◯ |
| LLM使用 | - |
| 入力の型 |
str / Message
|
| 出力の型 | List[str] |
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
output_parser = CommaSeparatedListOutputParser()
format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate(
template="{subject}を5つリストアップして下さい。回答は日本語で。\n{format_instructions}",
input_variables=["subject"],
partial_variables={"format_instructions": format_instructions},
)
model = ChatOpenAI(temperature=0)
chain = prompt | model | output_parser
chain.invoke({"subject": "JRAの歴代GI馬"})
['ディープインパクト', 'オルフェーヴル', 'ゴールドシップ', 'ウオッカ', 'ウイニングチケット']
for s in chain.stream({"subject": "JRAの歴代GI馬"}):
print(s)
['ディープインパクト']
['オルフェーヴル']
['ゴールドシップ']
['ウオッカ']
['ウイニングチケット']
format_instructions
Your response should be a list of comma separated values, eg: `foo, bar, baz`
ふと思ったんだけども、この指示プロンプト、カスタマイズできないのかな?コード見てみたけどそういうメソッドも属性も見当たらないように思える。
issueにあった。
うーん、サブクラス作ってやるか、上のコードみたいに、この指示プロンプトはそのままで「日本語で」みたいなのを入れるかしかないのかな・・・・
Datetime parser
datetimeフォーマットで出力するパーサ。DatetimeOutputParserを使う。
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | - |
| 指示プロンプト | ◯ |
| LLM使用 | - |
| 入力の型 |
str / Message
|
| 出力の型 | datetime.datetime |
from langchain.output_parsers import DatetimeOutputParser
from langchain.prompts import PromptTemplate
from langchain_openai import OpenAI
output_parser = DatetimeOutputParser()
format_instructions = output_parser.get_format_instructions()
template = """\
ユーザの質問に回答して下さい:
{question}
{format_instructions}\
"""
prompt = PromptTemplate.from_template(
template,
partial_variables={"format_instructions": format_instructions},
)
model = ChatOpenAI(temperature=0)
chain = prompt | model | output_parser
chain.invoke({"question": "when was bitcoin founded?"})
datetime.datetime(2009, 1, 3, 18, 15, 5)
print(chain.invoke({"question": "ビットコインが創設されたのはいつ?"}))
2009-01-03 18:15:05
print(format_instructions)
Write a datetime string that matches the following pattern: '%Y-%m-%dT%H:%M:%S.%fZ'.
Examples: 1208-06-22T17:38:12.461296Z, 1864-12-18T07:46:47.435745Z, 189-07-09T23:23:32.257865Z
Return ONLY this string, no other words!
Enum parser
Enumで出力するパーサ。EnumOutputParserを使う。
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | - |
| 指示プロンプト | ◯ |
| LLM使用 | - |
| 入力の型 |
str / Message
|
| 出力の型 | Enum |
from langchain.output_parsers.enum import EnumOutputParser
from enum import Enum
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
class Colors(Enum):
RED = "赤"
GREEN = "緑"
BLUE = "青"
parser = EnumOutputParser(enum=Colors)
format_instructions = parser.get_format_instructions()
template = """\
この人物の目の色は?
人物: {person}
指示: {format_instructions}\
"""
prompt = PromptTemplate.from_template(
template,
partial_variables={"format_instructions": format_instructions},
)
model = ChatOpenAI(temperature=0)
chain = prompt | model | parser
chain.invoke({"person": "ドラキュラ"})
<Colors.RED: '赤'>
chain.invoke({"person": "ドラキュラ"}).value
赤
print(format_instructions)
Select one of the following options: 赤, 緑, 青
JSON parser
JSONオブジェクトで出力するパーサ。JsonOutputParserを使う。
Pydanticでデータモデルを定義することもできるし、Pydanticなし・スキーマ指定なしでLLMに任せることもできる。ただしLLMに任せた場合、当然JSONのスキーマはブレる可能性があるし、モデル性能が十分でないと正しいフォーマットで出力できない可能性もある。
なおFunction Callを使わない。
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | ◯ |
| 指示プロンプト | ◯ |
| LLM使用 | - |
| 入力の型 |
str / Message
|
| 出力の型 | JSONオブジェクト |
from typing import List
from langchain_core.output_parsers import JsonOutputParser
from langchain.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
class Joke(BaseModel):
setup: str = Field(description="ジョークを生成するための質問")
punchline: str = Field(description="ジョークを成り立たせるための回答")
parser = JsonOutputParser(pydantic_object=Joke)
format_instructions = parser.get_format_instructions()
template = "ユーザからの質問に回答して下さい。回答は日本語で。\n{format_instructions}\n{query}\n"
prompt = PromptTemplate.from_template(
template,
partial_variables={"format_instructions": format_instructions},
)
model = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
chain = prompt | model | parser
chain.invoke({"query": "なにかジョークを言ってみて"})
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜならば、水が好きだから!'}
print(format_instructions)
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.Here is the output schema:
```
{"properties": {"setup": {"title": "Setup", "description": "\u30b8\u30e7\u30fc\u30af\u3092\u751f\u6210\u3059\u308b\u305f\u3081\u306e\u8cea\u554f", "type": "string"}, "punchline": {"title": "Punchline", "description": "\u30b8\u30e7\u30fc\u30af\u3092\u6210\u308a\u7acb\u305f\u305b\u308b\u305f\u3081\u306e\u56de\u7b54", "type": "string"}}, "required": ["setup", "punchline"]}
```
Unicodeエンコードされちゃってるけど、少し試してみた感じ、LLMは普通に読めるっぽいので大丈夫なのかも。気になるなら英語のほうが無難かも。
ストリーミングに対応している
for s in chain.stream({"query": "なにかジョークを言ってみて"}):
print(s)
{}
{'setup': ''}
{'setup': 'な'}
{'setup': 'なぜ'}
{'setup': 'なぜ魚'}
{'setup': 'なぜ魚は'}
{'setup': 'なぜ魚は泳'}
{'setup': 'なぜ魚は泳げ'}
{'setup': 'なぜ魚は泳げる'}
{'setup': 'なぜ魚は泳げるの'}
{'setup': 'なぜ魚は泳げるのか'}
{'setup': 'なぜ魚は泳げるのか?'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': ''}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'な'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜ'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜな'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜなら'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜならば'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜならば、'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜならば、水'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜならば、水が'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜならば、水が好'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜならば、水が好き'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜならば、水が好きだ'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜならば、水が好きだから'}
{'setup': 'なぜ魚は泳げるのか?', 'punchline': 'なぜならば、水が好きだから!'}
Pydanticなしの場合。
parser = JsonOutputParser()
format_instructions = parser.get_format_instructions()
template = "ユーザからの質問に回答して下さい。回答は日本語で。\n{format_instructions}\n{query}\n"
prompt = PromptTemplate.from_template(
template,
partial_variables={"format_instructions": format_instructions},
)
model = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
chain_without_pydantic = prompt | model | parser
print(format_instructions)
Return a JSON object.
chain_without_pydantic.invoke({"query": "なにかジョークを言ってみて。"})
OutputParserException: Invalid json output: 申し訳ありませんが、私はジョークを言うことができません。他に質問があればお答えしますので、どうぞお尋ねください。
これだけだとちょっと安定しない。format_instructionsの内容がこれぐらいなら、いっそプロンプトに書いたほうがマシ。
(snip)
template = "ユーザからの質問に回答して下さい。回答は日本語で、正しいJSON形式で。\n{query}\n"
(snip)
chain_without_pydantic.invoke({"query": "なにかジョークを言ってみて。"})
{'回答': 'なぜサルは木の上でバナナを食べるのか?\u3000なぜなら、地面で食べると地面に落ちるから!'}
まあPydanticでモデル定義するのが吉。
XML Parser
XMLで出力するパーサ。XMLOutputParserを使う。
XMLが得意なモデル、例えばAnthropicとかが推奨されている。JSONと同じで、モデル性能が十分でないと正しいフォーマットで出力できない可能性あり。
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | ◯ |
| 指示プロンプト | ◯ |
| LLM使用 | - |
| 入力の型 |
str / Message
|
| 出力の型 | dict |
まずはXMLOutputParserを使わずにプロンプトだけでやる。モデルはOpusで。
from langchain.prompts import PromptTemplate
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-3-opus-20240229", temperature=0)
actor_query = "トム・ハンクスの簡易なフィルモグラフィーを作成してください。"
xml_query = "映画名を<movie></movie>タグで囲んで下さい。"
output = model.invoke(
actor_query + "\n" + xml_query
)
print(output.content)
<movie>スプラッシュ</movie> (1984年)
<movie>ビッグ</movie> (1988年)
<movie>眠れぬ夜の恋人たち</movie> (1993年)
<movie>フォレスト・ガンプ/一期一会</movie> (1994年)
<movie>アポロ13</movie> (1995年)
<movie>プライベート・ライアン</movie> (1998年)
<movie>キャスト・アウェイ</movie> (2000年)
<movie>ロード・トゥ・パーディション</movie> (2002年)
<movie>ターミナル</movie> (2004年)
<movie>ダ・ヴィンチ・コード</movie> (2006年)
<movie>天使と悪魔</movie> (2009年)
<movie>キャプテン・フィリップス</movie> (2013年)
<movie>ブリッジ・オブ・スパイ</movie> (2015年)
<movie>ザ・サークル</movie> (2017年)
<movie>グレイテスト・ショーマン</movie> (2017年)
<movie>ニュースの真相</movie> (2017年)
<movie>トイ・ストーリー4</movie> (2019年)
<movie>グレイハウンド</movie> (2020年)
ではXMLOutputParserを使ってみる。Opus使ってみる。
from langchain.output_parsers import XMLOutputParser
from langchain.prompts import PromptTemplate
from langchain_anthropic import ChatAnthropic
parser = XMLOutputParser()
format_instructions = parser.get_format_instructions()
prompt = PromptTemplate.from_template(
"{query}\n{format_instructions}",
partial_variables={"format_instructions": format_instructions},
)
model = ChatAnthropic(model="claude-3-opus-20240229", temperature=0.1)
chain = prompt | model | parser
output = chain.invoke({"query": "トム・ハンクスの簡易なフィルモグラフィーを作成してください。"})
print(output)
{'filmography': [{'actor': [{'name': 'トム・ハンクス'}, {'films': [{'film': [{'title': 'スプラッシュ'}, {'year': '1984'}]}, {'film': [{'title': 'ビッグ'}, {'year': '1988'}]}, {'film': [{'title': 'フィラデルフィア'}, {'year': '1993'}]}, {'film': [{'title': 'フォレスト・ガンプ/一期一会'}, {'year': '1994'}]}, {'film': [{'title': 'アポロ13'}, {'year': '1995'}]}, {'film': [{'title': 'プライベート・ライアン'}, {'year': '1998'}]}, {'film': [{'title': 'キャスト・アウェイ'}, {'year': '2000'}]}, {'film': [{'title': 'ロード・トゥ・パーディション'}, {'year': '2002'}]}, {'film': [{'title': 'ターミナル'}, {'year': '2004'}]}, {'film': [{'title': 'ダ・ヴィンチ・コード'}, {'year': '2006'}]}]}]}]}
んー、正しくはLLMがXMLで出力したのをそのまま扱えるようにdictで出力するパーサ、ってところだね。XMLで出力されるのかと思ってしまうな。
print(format_instructions)
The output should be formatted as a XML file.
- Output should conform to the tags below.
- If tags are not given, make them on your own.
- Remember to always open and close all the tags.
As an example, for the tags ["foo", "bar", "baz"]:
- String "<foo>
<bar>
<baz></baz>
</bar>
</foo>" is a well-formatted instance of the schema.- String "<foo>
<bar>
</foo>" is a badly-formatted instance.- String "<foo>
<tag>
</tag>
</foo>" is a badly-formatted instance.Here are the output tags:
```
None
````
出力タグを指定することもできる。
(snip)
parser = XMLOutputParser(parser="xml", tags=["movies", "actor", "film", "name", "genre"])
(snip)
print(format_instructions)
The output should be formatted as a XML file.
- Output should conform to the tags below.
- If tags are not given, make them on your own.
- Remember to always open and close all the tags.
As an example, for the tags ["foo", "bar", "baz"]:
- String "<foo>
<bar>
<baz></baz>
</bar>
</foo>" is a well-formatted instance of the schema.- String "<foo>
<bar>
</foo>" is a badly-formatted instance.- String "<foo>
<tag>
</tag>
</foo>" is a badly-formatted instance.Here are the output tags:
```
['movies', 'actor', 'film', 'name', 'genre']
```
最後にタグが指定されているのがわかる。
ではクエリ。
output = chain.invoke({"query": "トム・ハンクスの簡易なフィルモグラフィーを作成してください。"})
output
OutputParserException: Failed to parse XML format from completion Here is the XML output for a simplified filmography of Tom Hanks:
<movies>
<actor>
<name>Tom Hanks</name>
<film>
<name>Forrest Gump</name>
<genre>Drama</genre>
</film>
<film>
<name>Cast Away</name>
<genre>Drama</genre>
</film>
<film>
<name>Saving Private Ryan</name>
<genre>War</genre>
</film>
<film>
<name>Apollo 13</name>
<genre>Historical drama</genre>
</film>
<film>
<name>Toy Story</name>
<genre>Animated comedy</genre>
</film>
</actor>
</movies>. Got: syntax error: line 1, column 0
あー、余計な出力があるからかー。なんというかClaudeは喋り過ぎなんだよな・・・ただここでもLLMがXMLで出力してるのがわかるね。
ちょっとプロンプトで。
output = chain.invoke({"query": "トム・ハンクスの簡易なフィルモグラフィーを作成してください。日本語で。フィルモグラフィー以外の説明は一切不要です。"})
output
{'movies': [{'actor': 'トム・ハンクス'},
{'film': [{'name': 'ビッグ'}, {'genre': 'コメディ'}]},
{'film': [{'name': 'フィラデルフィア'}, {'genre': 'ドラマ'}]},
{'film': [{'name': 'フォレスト・ガンプ/一期一会'}, {'genre': 'ドラマ'}]},
{'film': [{'name': 'アポロ13'}, {'genre': 'ドラマ'}]},
{'film': [{'name': 'プライベート・ライアン'}, {'genre': '戦争'}]},
{'film': [{'name': 'キャスト・アウェイ'}, {'genre': 'ドラマ'}]},
{'film': [{'name': 'ロード・トゥ・パーディション'}, {'genre': '犯罪'}]},
{'film': [{'name': 'ターミナル'}, {'genre': 'コメディ・ドラマ'}]},
{'film': [{'name': 'ダ・ヴィンチ・コード'}, {'genre': 'ミステリー・スリラー'}]},
{'film': [{'name': 'ブリッジ・オブ・スパイ'}, {'genre': 'スリラー'}]},
{'film': [{'name': 'ザ・ポスト'}, {'genre': 'ドラマ'}]},
{'film': [{'name': 'グレイハウンド'}, {'genre': '戦争'}]}]}
ストリーミングが可能。
output = chain.stream({"query": "トム・ハンクスの簡易なフィルモグラフィーを作成してください。日本語で。フィルモグラフィー以外の説明は一切不要です。"})
for s in output:
print(s)
{'movies': [{'actor': 'トム・ハンクス'}]}
{'movies': [{'film': [{'name': 'ビッグ'}]}]}
{'movies': [{'film': [{'genre': 'コメディ'}]}]}
{'movies': [{'film': [{'name': 'フィラデルフィア'}]}]}
{'movies': [{'film': [{'genre': 'ドラマ'}]}]}
{'movies': [{'film': [{'name': 'フォレスト・ガンプ/一期一会'}]}]}
{'movies': [{'film': [{'genre': 'ドラマ'}]}]}
{'movies': [{'film': [{'name': 'アポロ13'}]}]}
{'movies': [{'film': [{'genre': 'ドラマ'}]}]}
{'movies': [{'film': [{'name': 'プライベート・ライアン'}]}]}
{'movies': [{'film': [{'genre': '戦争'}]}]}
{'movies': [{'film': [{'name': 'キャスト・アウェイ'}]}]}
{'movies': [{'film': [{'genre': 'ドラマ'}]}]}
{'movies': [{'film': [{'name': 'ロード・トゥ・パーディション'}]}]}
{'movies': [{'film': [{'genre': '犯罪'}]}]}
{'movies': [{'film': [{'name': 'ターミナル'}]}]}
{'movies': [{'film': [{'genre': 'コメディドラマ'}]}]}
{'movies': [{'film': [{'name': 'ダ・ヴィンチ・コード'}]}]}
{'movies': [{'film': [{'genre': 'ミステリー'}]}]}
{'movies': [{'film': [{'name': '天使と悪魔'}]}]}
{'movies': [{'film': [{'genre': 'ミステリー'}]}]}
{'movies': [{'film': [{'name': 'ブリッジ・オブ・スパイ'}]}]}
{'movies': [{'film': [{'genre': 'スリラー'}]}]}
{'movies': [{'film': [{'name': 'ザ・ポスト'}]}]}
{'movies': [{'film': [{'genre': 'ドラマ'}]}]}
{'movies': [{'film': [{'name': 'グレイハウンド'}]}]}
{'movies': [{'film': [{'genre': '戦争'}]}]}
{'movies': [{'film': [{'name': 'ニュース・オブ・ザ・ワールド'}]}]}
{'movies': [{'film': [{'genre': '西部劇'}]}]}
あと、XMLでそのまま出力させるならば、format_instructionsだけ使って、チェーンの最後はStrOutputParserにすれば良さそう。
from langchain.output_parsers import XMLOutputParser
from langchain.prompts import PromptTemplate
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import StrOutputParser
parser = XMLOutputParser(parser="xml", tags=["movies", "actor", "film", "name", "genre"])
format_instructions = parser.get_format_instructions()
prompt = PromptTemplate.from_template(
"{query}\n{format_instructions}",
partial_variables={"format_instructions": format_instructions},
)
model = ChatAnthropic(model="claude-3-opus-20240229", temperature=0.1)
chain = prompt | model | StrOutputParser()
output = chain.invoke({"query": "トム・ハンクスの簡易なフィルモグラフィーを作成してください。日本語で。フィルモグラフィー以外の説明は一切不要です。"})
print(output)
<?xml version="1.0" encoding="UTF-8"?>
<movies>
<actor>トム・ハンクス</actor>
<film>
<name>ビッグ</name>
<genre>コメディ</genre>
</film>
<film>
<name>フィラデルフィア</name>
<genre>ドラマ</genre>
</film>
<film>
<name>フォレスト・ガンプ/一期一会</name>
<genre>ドラマ</genre>
</film>
<film>
<name>アポロ13</name>
<genre>ドラマ</genre>
</film>
<film>
<name>プライベート・ライアン</name>
<genre>戦争</genre>
</film>
<film>
<name>キャスト・アウェイ</name>
<genre>ドラマ</genre>
</film>
<film>
<name>ロード・トゥ・パーディション</name>
<genre>犯罪</genre>
</film>
<film>
<name>ターミナル</name>
<genre>コメディドラマ</genre>
</film>
<film>
<name>ダ・ヴィンチ・コード</name>
<genre>ミステリー</genre>
</film>
<film>
<name>天使と悪魔</name>
<genre>ミステリー</genre>
</film>
<film>
<name>ブリッジ・オブ・スパイ</name>
<genre>スリラー</genre>
</film>
<film>
<name>ザ・ポスト</name>
<genre>ドラマ</genre>
</film>
<film>
<name>グレイハウンド</name>
<genre>戦争</genre>
</film>
<film>
<name>ニュース・オブ・ザ・ワールド</name>
<genre>西部劇</genre>
</film>
</movies>
んー、なんだろうな、format_instructionsいじれないの結構面倒だな。。。
YAML parser
ということで次はYAML。JSONやXMLと注意点は同じで、モデル性能がある程度必要というところ。
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | - |
| 指示プロンプト | ◯ |
| LLM使用 | - |
| 入力の型 |
str / Message
|
| 出力の型 | pydantic.BaseModel |
from langchain.output_parsers import YamlOutputParser
from langchain.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
class Joke(BaseModel):
setup: str = Field(description="ジョークを生成するための質問")
punchline: str = Field(description="ジョークを成り立たせるための回答")
parser = YamlOutputParser(pydantic_object=Joke)
format_instructions = parser.get_format_instructions()
template = "ユーザからの質問に回答して下さい。回答は日本語で。\n{format_instructions}\n{query}\n"
prompt = PromptTemplate.from_template(
template,
partial_variables={"format_instructions": format_instructions},
)
model = ChatOpenAI(temperature=0)
chain = prompt | model | parser
chain.invoke({"query": "ジョークを言ってみて。"})
Joke(setup='なぜ恐竜はプレゼントをあげられないの?', punchline='ラップができないから!')
print(format_instructions)
The output should be formatted as a YAML instance that conforms to the given JSON schema below.
# Examples
## Schema{"title": "Players", "description": "A list of players", "type": "array", "items": {"$ref": "#/definitions/Player"}, "definitions": {"Player": {"title": "Player", "type": "object", "properties": {"name": {"title": "Name", "description": "Player name", "type": "string"}, "avg": {"title": "Avg", "description": "Batting average", "type": "number"}}, "required": ["name", "avg"]}}}## Well formatted instance
- name: John Doe avg: 0.3 - name: Jane Maxfield avg: 1.4## Schema
```
{"properties": {"habit": { "description": "A common daily habit", "type": "string" }, "sustainable_alternative": { "description": "An environmentally friendly alternative to the habit", "type": "string"}}, "required": ["habit", "sustainable_alternative"]}
```
## Well formatted instance
```
habit: Using disposable water bottles for daily hydration.
sustainable_alternative: Switch to a reusable water bottle to reduce plastic waste and decrease your environmental footprint.
```Please follow the standard YAML formatting conventions with an indent of 2 spaces and make sure that the data types adhere strictly to the following JSON schema:
```
{"properties": {"setup": {"title": "Setup", "description": "\u30b8\u30e7\u30fc\u30af\u3092\u751f\u6210\u3059\u308b\u305f\u3081\u306e\u8cea\u554f", "type": "string"}, "punchline": {"title": "Punchline", "description": "\u30b8\u30e7\u30fc\u30af\u3092\u6210\u308a\u7acb\u305f\u305b\u308b\u305f\u3081\u306e\u56de\u7b54", "type": "string"}}, "required": ["setup", "punchline"]}
```Make sure to always enclose the YAML output in triple backticks (```). Please do not add anything other than valid YAML output!
Pandas Dataframe parser
指定のPandasのデータフレームから辞書で取り出すパーサ。これも一定のモデル性能が必要。
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | - |
| 指示プロンプト | ◯ |
| LLM使用 | - |
| 入力の型 |
str / Message
|
| 出力の型 | dict |
import pandas as pd
from langchain.output_parsers import PandasDataFrameOutputParser
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
model = ChatOpenAI(temperature=0)
df = pd.DataFrame(
{
"num_legs": [2, 4, 8, 0],
"num_wings": [2, 0, 0, 0],
"num_specimen_seen": [10, 2, 1, 8],
}
)
parser = PandasDataFrameOutputParser(dataframe=df)
format_instructions = parser.get_format_instructions()
template = "ユーザからの質問に回答して下さい。回答は日本語で。\n{format_instructions}\n{query}\n"
prompt = PromptTemplate.from_template(
template,
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
データフレームはこう。

print(format_instructions)
The output should be formatted as a string as the operation, followed by a colon, followed by the column or row to be queried on, followed by optional array parameters.
- The column names are limited to the possible columns below.
- Arrays must either be a comma-separated list of numbers formatted as [1,3,5], or it must be in range of numbers formatted as [0..4].
- Remember that arrays are optional and not necessarily required.
- If the column is not in the possible columns or the operation is not a valid Pandas DataFrame operation, return why it is invalid as a sentence starting with either "Invalid column" or "Invalid operation".
As an example, for the formats:
- String "column:num_legs" is a well-formatted instance which gets the column num_legs, where num_legs is a possible column.
- String "row:1" is a well-formatted instance which gets row 1.
- String "column:num_legs[1,2]" is a well-formatted instance which gets the column num_legs for rows 1 and 2, where num_legs is a possible column.
- String "row:1[num_legs]" is a well-formatted instance which gets row 1, but for just column num_legs, where num_legs is a possible column.
- String "mean:num_legs[1..3]" is a well-formatted instance which takes the mean of num_legs from rows 1 to 3, where num_legs is a possible column and mean is a valid Pandas DataFrame operation.
- String "do_something:num_legs" is a badly-formatted instance, where do_something is not a valid Pandas DataFrame operation.
- String "mean:invalid_col" is a badly-formatted instance, where invalid_col is not a possible column.
Here are the possible columns:
```
num_legs, num_wings, num_specimen_seen
```
ではクエリいろいろ。
import pprint
from typing import Any, Dict
# 出力用
def format_parser_output(parser_output: Dict[str, Any]) -> None:
for key in parser_output.keys():
parser_output[key] = parser_output[key].to_dict()
return pprint.PrettyPrinter(width=4, compact=True).pprint(parser_output)
parser_output = chain.invoke({"query": "num_wings列を取得して下さい"})
format_parser_output(parser_output)
{'num_wings': {0: 2,
1: 0,
2: 0,
3: 0}}
parser_output = chain.invoke({"query": "最初の行を取得して下さい。"})
format_parser_output(parser_output)
{'0': {'num_legs': 2,
'num_specimen_seen': 10,
'num_wings': 2}}
parser_output = chain.invoke({"query": "num_legs列の1〜3行目の平均を出して下さい。"})
print(parser_output)
{'mean': 4.0}
存在しない列を指定するダメな例
parser_output = chain.invoke({"query": "num_fingers列の平均を出して下さい。"})
print(parser_output)
OutputParserException: Invalid column: num_fingers. Please check the format instructions.
Pydantic parser
Pydanticでモデル定義して、そのスキーマに従ってLLMに出力させる。
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | - |
| 指示プロンプト | ◯ |
| LLM使用 | - |
| 入力の型 |
str / Message
|
| 出力の型 | pydantic.BaseModel |
Quickstartでやっているのでスキップ。ただし、format_instructionsは見てなかったので、それだけ。
from langchain.output_parsers import PydanticOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field, validator
class Joke(BaseModel):
setup: str = Field(description="ジョークを生成するための質問")
punchline: str = Field(description="ジョークを成り立たせるための回答")
@validator("setup")
def question_ends_with_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("Badly formed question!")
return field
print(PydanticOutputParser(pydantic_object=Joke).get_format_instructions())
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.Here is the output schema:
```
{"properties": {"setup": {"title": "Setup", "description": "\u30b8\u30e7\u30fc\u30af\u3092\u751f\u6210\u3059\u308b\u305f\u3081\u306e\u8cea\u554f", "type": "string"}, "punchline": {"title": "Punchline", "description": "\u30b8\u30e7\u30fc\u30af\u3092\u6210\u308a\u7acb\u305f\u305b\u308b\u305f\u3081\u306e\u56de\u7b54", "type": "string"}}, "required": ["setup", "punchline"]}
```
Structured output parser
構造化出力パーサ、って少しざっくりしてるな。 Pydantic/JSONパーサはモデル性能が必要だけど、これはモデル性能が低くても使えるらしい。
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | - |
| 指示プロンプト | ◯ |
| LLM使用 | - |
| 入力の型 |
str / Message
|
| 出力の型 | Dict[str, str] |
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
response_schemas = [
ResponseSchema(
name="answer",
description="ユーザの質問に対する回答。"
),
ResponseSchema(
name="source",
description="ユーザーの質問に答えるために使用されるソース、例えば、ウェブサイト等。",
),
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
template = "ユーザからの質問に回答して下さい。回答は日本語で。\n{format_instructions}\n{question}\n"
prompt = PromptTemplate.from_template(
template,
partial_variables={"format_instructions": format_instructions},
)
model = ChatOpenAI(temperature=0)
chain = prompt | model | output_parser
Pydanticとかを使わない代わりに、ResponseSchemaってのでスキーマを定義するみたい。
print(format_instructions)
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
```json
{
"answer": string // ユーザの質問に対する回答。
"source": string // ユーザーの質問に答えるために使用されるソース、例えば、ウェブサイト等。
}
```
なるほどね。
ではクエリ。
chain.invoke({"question": "フランスの首都は?"})
{'answer': 'パリ',
'source': 'https://ja.wikipedia.org/wiki/フランス'}
なんとなくあまり複雑なものは厳しそうな気はする、ネストしているとか。
ストリームの例がドキュメントにはあるけど、対応していないはず、ということでやってみた。
for s in chain.stream({"question": "フランスの首都は?"}):
print(s, end="|", flush=True)
{'answer': 'パリ', 'source': 'https://ja.wikipedia.org/wiki/パリ'}|
対応していない。
OpenAI Functions
OpenAI function callingを使った出力パーサ。当然 Function Callingをサポートしているモデルのみ。4つのバリエーションが有る。
-
JsonOutputFunctionsParser: Function CallingのargumentsをJSONで返す -
PydanticOutputFunctionsParser: Function CallingのargumentsをPydanticモデルで返す -
JsonKeyOutputFunctionsParser: Function Callingの特定のキーの値をJSONで返す -
PydanticAttrOutputFunctionsParser: Function Callingの特定のキーの値をPydanticモデルで返す
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | ◯ |
| 指示プロンプト | (functionsをモデルに渡す) |
| LLM使用 | - |
| 入力の型 |
Message(とfunction_call) |
| 出力の型 | JSONオブジェクト |
ただし現在のFunction Callingはtoolsを使うのが最新なので、functionsはもうレガシー。
JsonOutputFunctionsParser
from langchain_community.utils.openai_functions import (
convert_pydantic_to_openai_function,
)
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_openai import ChatOpenAI
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
class Joke(BaseModel):
"""ユーザにジョークを言う"""
setup: str = Field(description="ジョークを生成するための質問")
punchline: str = Field(description="ジョークを成り立たせるための回答")
openai_functions = [convert_pydantic_to_openai_function(Joke)]
model = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは親切なアシスタントです。常に日本語で回答します。"
),
(
"user",
"{input}"
)
]
)
parser = JsonOutputFunctionsParser()
chain = prompt | model.bind(functions=openai_functions) | parser
chain.invoke({"input": "ジョークを1つ言ってみて。"})
{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}
for s in chain.stream({"input": "ジョークを1つ言ってみて。"}):
print(s)
{}
{'setup': ''}
{'setup': 'な'}
{'setup': 'なぜ'}
{'setup': 'なぜサ'}
{'setup': 'なぜサル'}
{'setup': 'なぜサルは'}
{'setup': 'なぜサルは木'}
{'setup': 'なぜサルは木の'}
{'setup': 'なぜサルは木の上'}
{'setup': 'なぜサルは木の上で'}
{'setup': 'なぜサルは木の上でバ'}
{'setup': 'なぜサルは木の上でバナ'}
{'setup': 'なぜサルは木の上でバナナ'}
{'setup': 'なぜサルは木の上でバナナを'}
{'setup': 'なぜサルは木の上でバナナを食'}
{'setup': 'なぜサルは木の上でバナナを食べ'}
{'setup': 'なぜサルは木の上でバナナを食べる'}
{'setup': 'なぜサルは木の上でバナナを食べるの'}
{'setup': 'なぜサルは木の上でバナナを食べるの?'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': ''}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'な'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜ'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜな'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、下'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、下で'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、下で皮'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、下で皮を'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、下で皮を滑'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、下で皮を滑ら'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、下で皮を滑らせ'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、下で皮を滑らせる'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、下で皮を滑らせるから'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、下で皮を滑らせるからだ'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、下で皮を滑らせるからだよ'}
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'なぜなら、下で皮を滑らせるからだよ!'}
JsonKeyOutputFunctionsParser
イマイチ違いがぴんときてないのだけども、リストを受け取りたい場合に便利らしい。たしかにリストのキーを指定している。
from typing import List
from langchain_community.utils.openai_functions import (
convert_pydantic_to_openai_function,
)
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser
class Joke(BaseModel):
"""ユーザにジョークを言う"""
setup: str = Field(description="ジョークを生成するための質問")
punchline: str = Field(description="ジョークを成り立たせるための回答")
class Jokes(BaseModel):
"""Jokes to tell user."""
joke: List[Joke]
funniness_level: int
parser = JsonKeyOutputFunctionsParser(key_name="joke")
openai_functions = [convert_pydantic_to_openai_function(Jokes)]
model = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは親切なアシスタントです。常に日本語で回答します。"
),
(
"user",
"{input}"
)
]
)
chain = prompt | model.bind(functions=openai_functions) | parser
chain.invoke({"input": "ジョークを2つ言ってみて。"})
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'},
{'setup': 'おなかがすいた時に何を食べるといい?', 'punchline': '食べ物!'}]
for s in chain.stream({"input": "ジョークを2つ言ってみて。"}):
print(s)
[{}]
[{'setup': ''}]
[{'setup': 'な'}]
[{'setup': 'なぜ'}]
[{'setup': 'なぜサ'}]
[{'setup': 'なぜサル'}]
[{'setup': 'なぜサルは'}]
[{'setup': 'なぜサルは木'}]
[{'setup': 'なぜサルは木に'}]
[{'setup': 'なぜサルは木に登'}]
[{'setup': 'なぜサルは木に登る'}]
[{'setup': 'なぜサルは木に登るの'}]
[{'setup': 'なぜサルは木に登るの?'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': ''}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'な'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜ'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜな'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜなら'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそ'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこ'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこに'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバ'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナ'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナ'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナが'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあ'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがある'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': ''}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'お'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おな'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなか'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかが'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがす'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすい'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を食'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を食べ'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を食べる'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を食べると'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を食べるとい'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を食べるといい'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を食べるといい?'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を食べるといい?', 'punchline': ''}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を食べるといい?', 'punchline': '食'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を食べるといい?', 'punchline': '食べ'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を食べるといい?', 'punchline': '食べ物'}]
[{'setup': 'なぜサルは木に登るの?', 'punchline': 'なぜならそこにバナナがあるから!'}, {'setup': 'おなかがすいた時に何を食べるといい?', 'punchline': '食べ物!'}]
PydanticOutputFunctionsParser
JsonOutputFunctionsParserがベースになっていて、その結果をPydanticモデルに渡すらしい。ある意味バリデーション2回やってるような感じかな。
from langchain_community.utils.openai_functions import (
convert_pydantic_to_openai_function,
)
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_openai import ChatOpenAI
from langchain.output_parsers.openai_functions import PydanticOutputFunctionsParser
class Joke(BaseModel):
"""ユーザにジョークを言う"""
setup: str = Field(description="ジョークを生成するための質問")
punchline: str = Field(description="ジョークを成り立たせるための回答")
@validator("setup")
def question_ends_with_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("Badly formed question!")
return field
parser = PydanticOutputFunctionsParser(pydantic_schema=Joke)
openai_functions = [convert_pydantic_to_openai_function(Joke)]
model = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは親切なアシスタントです。常に日本語で回答します。"
),
(
"user",
"{input}"
)
]
)
chain = prompt | model.bind(functions=openai_functions) | parser
chain.invoke({"input": "ジョークを1つ言ってみて。"})
Joke(setup='なぜサルは木の上でバナナを食べるの?', punchline='なぜなら、下で食べると落ちるからだよ!')
for s in chain.stream({"input": "ジョークを1つ言ってみて。"}):
print(s)
おっと、Pydantic使っているためか、こっちはストリーミングが効かないっぽい。
setup='なぜパンは元気がいいのか?' punchline='いつもホカホカだからです!'
PydanticAttrOutputFunctionsParser
これはサンプルがないのよね。ChatGPTに聞きながら作ってみた。
from typing import List, Union
from langchain_community.utils.openai_functions import (
convert_pydantic_to_openai_function,
)
from langchain_core.pydantic_v1 import BaseModel
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers.openai_functions import PydanticAttrOutputFunctionsParser
class Joke(BaseModel):
"""ユーザにジョークを言う"""
setup: str = Field(description="ジョークを生成するための質問")
punchline: str = Field(description="ジョークを成り立たせるための回答")
class Jokes(BaseModel):
"""ユーザに複数のジョークを言う"""
joke: List[Joke]
funniness_level: int
@validator('joke', each_item=True)
def ensure_setup_ends_with_question_mark(cls, joke):
"""各jokeのsetupが疑問符「?」で終わることを確認するバリデータ"""
if not joke.setup.strip().endswith('?'):
raise ValueError(f"Badly formed question: {joke.setup}")
return joke
parser = PydanticAttrOutputFunctionsParser(attr_name="joke", pydantic_schema=Jokes)
openai_functions = [convert_pydantic_to_openai_function(Jokes)]
model = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは親切なアシスタントです。常に日本語で回答します。"
),
(
"user",
"{input}"
)
]
)
chain = prompt | model.bind(functions=openai_functions) | parser
chain.invoke({"input": "ジョークを2つ言ってみて。"})
[Joke(setup='なぜサッカーピッチは草で覆われているの?', punchline='サッカーピッチが芝生で覆われているのは、選手たちがハーフタイムにお茶を飲むためです!'),
Joke(setup='なぜバナナはバナナのパーティーに招待されなかったの?', punchline='バナナは皮が剥けてしまうからです!')]
うまくいかないというかバリデーションが効いている場合の例。
chain.invoke({"input": "ジョークを2つ言ってみて。"})
ValidationError: 2 validation errors for Jokes
joke -> 0
Badly formed question: What do you call a fake noodle? (type=value_error)
joke -> 1
Badly formed question: Why couldn't the bicycle stand up by itself? (type=value_error)
これでいいのかな?ちょっと自信ないけども。
OpenAI Tools
OpenAI function callingを使った出力パーサ。当然 Function Callingをサポートしているモデルのみ。3つのバリエーションがある。先ほどとは違って、現在のFunction Callingの最新であるtoolsを使うやり方。
-
JsonOutputToolsParser: Function CallingのargumentsをJSONで返す -
JsonOutputKeyToolsParser: Function Callingの特定のキーの値をJSONで返す -
PydanticToolsParser: Function CallingのargumentsをPydanticモデルで返す
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | - |
| 指示プロンプト | (toolsをモデルに渡す) |
| LLM使用 | - |
| 入力の型 |
Message(とtool_choice) |
| 出力の型 | JSONオブジェクト |
JsonOutputToolsParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_openai import ChatOpenAI
from langchain.output_parsers.openai_tools import JsonOutputToolsParser
class Joke(BaseModel):
"""ユーザにジョークを言う"""
setup: str = Field(description="ジョークを生成するための質問")
punchline: str = Field(description="ジョークを成り立たせるための回答")
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0).bind_tools([Joke])
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは親切なアシスタントです。常に日本語で回答します。"
),
(
"user",
"{input}"
)
]
)
Function Callingのツール定義を確認。
model.kwargs["tools"]
[{'type': 'function',
'function': {'name': 'Joke',
'description': 'ユーザにジョークを言う',
'parameters': {'type': 'object',
'properties': {'setup': {'description': 'ジョークを生成するための質問',
'type': 'string'},
'punchline': {'description': 'ジョークを成り立たせるための回答', 'type': 'string'}},
'required': ['setup', 'punchline']}}}]
chain = prompt | model | JsonOutputToolsParser()
chain.invoke({"input": "ジョークを1つ言ってみて。"})
[{'args': {'setup': 'なぜパンはおしゃべりができないのか?', 'punchline': 'パンだから。'},
'type': 'Joke'}]
return_id=Trueでtool call idが取得できる
chain = prompt | model | JsonOutputToolsParser(return_id=True)
chain.invoke({"input": "ジョークを1つ言ってみて。"})
[{'args': {'setup': 'なぜパンはおしゃべりができないのか?', 'punchline': 'パンだから。'},
'id': 'call_QLd2yzoU3RBmiPRsKI1db24S',
'type': 'Joke'}]
JsonOutputKeyToolsParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_openai import ChatOpenAI
from langchain.output_parsers.openai_tools import JsonOutputKeyToolsParser
class Joke(BaseModel):
"""ユーザにジョークを言う"""
setup: str = Field(description="ジョークを生成するための質問")
punchline: str = Field(description="ジョークを成り立たせるための回答")
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0).bind_tools([Joke])
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは親切なアシスタントです。常に日本語で回答します。"
),
(
"user",
"{input}"
)
]
)
chain = prompt | model | JsonOutputKeyToolsParser(key_name="Joke")
chain.invoke({"input": "ジョークを1つ言ってみて。"})
[{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': '下に落とすと皿が割れるからです。'}]
tool callでは複数ツールが返される場合があるため、上記のように配列で返ってくる。first_tool_only=Trueを指定すると最初のtoolのみが返されるみたい。
chain = prompt | model | JsonOutputKeyToolsParser(key_name="Joke", first_tool_only=True)
chain.invoke({"input": "ジョークを1つ言ってみて。"})
{'setup': 'なぜサルは木の上でバナナを食べるの?', 'punchline': 'だって、落とすと皮がむけるからだよ!'}
PydanticToolsParser
JsonOutputToolsParserをベースに、その結果をPydanticモデルに渡してバリデーションする。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_openai import ChatOpenAI
from langchain.output_parsers.openai_tools import PydanticToolsParser
class Joke(BaseModel):
"""ユーザにジョークを言う"""
setup: str = Field(description="ジョークを生成するための質問")
punchline: str = Field(description="ジョークを成り立たせるための回答")
@validator("setup")
def question_ends_with_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("Badly formed question!")
return field
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0).bind_tools([Joke])
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは親切なアシスタントです。常に日本語で回答します。"
),
(
"user",
"{input}"
)
]
)
chain = prompt | model | PydanticToolsParser(tools=[Joke])
chain.invoke({"input": "ジョークを1つ言ってみて。"})
[Joke(setup='なぜサルは木の上でバナナを食べるの?', punchline='だって、落とすと皮が剥けるからだよ!')]
Output-fixing parser
OutputFixingParserは他のoutput parserをラップして使うパーサ。元のoutput parserで失敗した場合にLLMを呼び出してエラーを修正するというような使い方ができる。
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | - |
| 指示プロンプト | - |
| LLM使用 | ◯ |
| 入力の型 |
Message(とtool_choice) |
| 出力の型 | - |
まずはPydanticOutputParserを使う。
from typing import List
from langchain.output_parsers import PydanticOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
class Actor(BaseModel):
name: str = Field(description="俳優の名前")
film_names: List[str] = Field(description="出演した映画名のリスト")
parser = PydanticOutputParser(pydantic_object=Actor)
LLMから正しくない出力が返ってきたという想定で、パーサに渡す。
parser.parse("{'name': 'トム・ハンクス', 'film_names': ['フォレスト・ガンプ']}")
JSONDecodeError: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
OutputParserException: Invalid json output: {'name': 'トム・ハンクス', 'film_names': ['フォレスト・ガンプ']}
シングルクォートで囲んでいるのでエラーになっている。正しくはこう。
parser.parse('{"name": "トム・ハンクス", "film_names": ["フォレスト・ガンプ"]}')
Actor(name='トム・ハンクス', film_names=['フォレスト・ガンプ'])
OutputFixingParserを使ってエラーを修正する。OutputFixingParserでPydanticOutputParserとLLMをラップする。
from langchain.output_parsers import OutputFixingParser
new_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())
このパーサに先ほどのNGな出力を渡す。
new_parser.parse("{'name': 'トム・ハンクス', 'film_names': ['フォレスト・ガンプ']}")
Actor(name='トム・ハンクス', film_names=['フォレスト・ガンプ'])
問題なくパースされた。
これどうやってんのかなとLangSmithをみてみた。
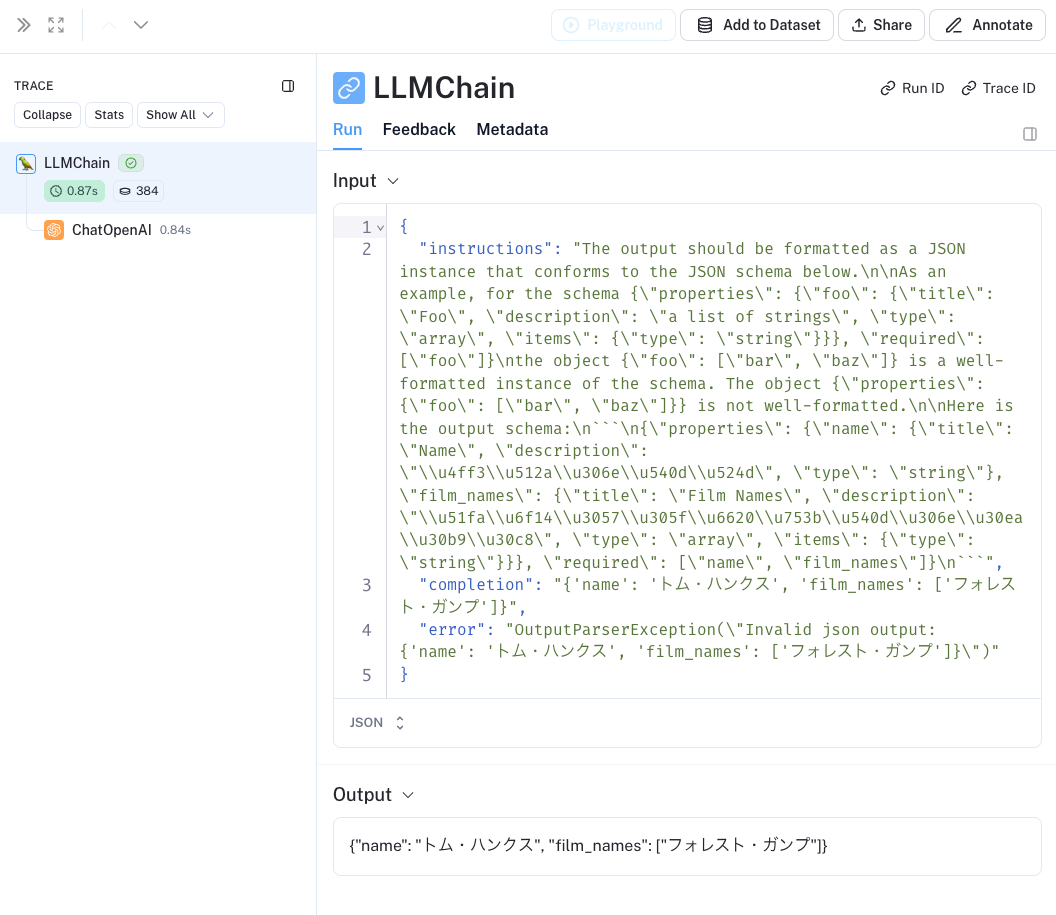
"instructions"にあるプロンプトは元のPydanticOutputParsersのものだけど、そこに、実行結果とエラーを付与して渡してるのね、なるほどね。
Retry parser
RetryOutputParserも、OutputFixingParser同様に、他のoutput parserをラップして使うパーサ。元のoutput parserで失敗した場合にLLMを呼び出してエラーを修正するというような使い方ができるのは同じで、違いは元のプロンプトを渡せることらしい。
| サポートする項目 | サポート内容/有無 |
|---|---|
| ストリーミング対応 | - |
| 指示プロンプト | - |
| LLM使用 | ◯ |
| 入力の型 |
Message(とtool_choice) |
| 出力の型 | - |
・・・なんだけども、なんかこのnotebookおかしい・・・
template = """Based on the user question, provide an Action and Action Input for what step should be taken.
{format_instructions}
Question: {query}
Response:"""
このtemplateはどこにも使われていない。流れからして以下のtemplateを上記で書き換えるのが正しいのではないだろうか?
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
正しいかどうかは置いといて、一旦それで進めることとする。
ユーザのクエリをPydanticOutputParserでバリデーションする。
from langchain.output_parsers import (
OutputFixingParser,
PydanticOutputParser,
)
from langchain.prompts import (
PromptTemplate,
)
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI, OpenAI
class Action(BaseModel):
action: str = Field(description="取るべきアクション ex: search")
action_input: str = Field(description="アクションへの入力")
parser = PydanticOutputParser(pydantic_object=Action)
format_instructions = parser.get_format_instructions()
template = """\
ユーザーの質問に基づいて、どのようなステップを取るべきかのアクションとアクション入力を提示してください。
{format_instructions}
質問: {query}
応答: \
"""
prompt = PromptTemplate.from_template(
template,
partial_variables={"format_instructions": format_instructions},
)
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = prompt | llm | parser
chain.invoke({"query": "レオナルド・ディカプリオの恋人は誰?"}).json(ensure_ascii=False)
{"action": "search", "action_input": "レオナルド・ディカプリオの恋人"}
これが本来欲しい結果。
で、例えば、LLMから以下のようなレスポンスが返ってきたと仮に想定する。
'{"action": "search"}'
これをparserでパースすると、
parser.parse('{"action": "search"}')
OutputParserException: Failed to parse Action from completion {"action": "search"}. Got: 1 validation error for Action
action_input
field required (type=value_error.missing)
当然ながらバリデーションでエラーになる、これは正しい。
ただできればエラーを修正して欲しい。ということでOutputFixingParserを使ってみる。
fix_parser = OutputFixingParser.from_llm(parser=parser, llm=llm)
fix_parser.parse('{"action": "search"}').json()
{"action": "search", "action_input": "keyword"}
OutputFixingParserは前回の壊れたレスポンスとエラー理由しか渡さないので、JSONバリデーションはできてるんだけども、本来取りたいaction_inputを取れていない。なぜなら元のクエリを知らないから。
RetryOutputParserを使ってみる。RetryOutputParserのparse_with_promptメソッドで元のクエリのプロンプトを渡してやる。
from langchain.output_parsers import RetryOutputParser
retry_parser = RetryOutputParser.from_llm(parser=parser, llm=llm)
retry_parser.parse_with_prompt('{"action": "search"}', prompt.format_prompt(query="レオナルド・ディカプリオの恋人は誰?"))
{"action": "search", "action_input": "レオナルド・ディカプリオの恋人"}
想定通りの結果となる。
これをチェーンでまとめるとこうなる。
from langchain_core.runnables import RunnableLambda, RunnableParallel
completion_chain = prompt | OpenAI(temperature=0)
retry_chain = (
RunnableParallel(
completion=completion_chain,
prompt_value=prompt
)
| RunnableLambda(lambda x: retry_parser.parse_with_prompt(**x))
)
retry_chain.invoke({"query": "レオナルド・ディカプリオの恋人は誰?"})
Action(action='search', action_input='レオナルド・ディカプリオの恋人')
エラーが出れば確認できるんだけど、試してみた限りはでなかったので、ここは実際に確認はできていない。
一通りざっと流した。出力フォーマットを揃えたいは常にあるので、積極的に使うべし。