LCEL(LangChain Expression Language)でLangChain再入門する
LCEL、いろいろな課題をクリアできそうで俄然興味がでてきたので、久々にLangChain触ってみる。再入門。
まずは公式のチュートリアルなど写経していく。
まずはシンプルな、プロンプト+モデル+出力パーサの例。
パッケージインストール
!pip install --upgrade --quiet langchain-core langchain-community langchain-openai
!pip freeze | grep -i langchain
langchain-community==0.0.32
langchain-core==0.1.41
langchain-openai==0.1.2
APIキー読み込み。
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
モデルを定義
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-3.5-turbo-0125")
プロンプトテンプレートを定義
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("{topic}についてのジョークを1つ言ってみて。")
出力パーサを定義
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
これをLCELでチェーン定義する。UNIX/Linuxのパイプ的に出力を次の入力につなげていく。
chain = prompt | model | output_parser
では、プロンプトテンプレートの変数を渡してチェーン実行。
response = chain.invoke({"topic": "アイスクリーム"})
response
アイスクリームを食べるとき、必ずしもカロリーを気にしなくていいという理論があるんだけど、それって冷たいジョークじゃない?
なるほどわかりやすい。
各コンポーネントごとに呼び出して結果を見ることもできる。
prompt_value = prompt.invoke({"topic": "アイスクリーム"})
prompt_value
ChatPromptValue(messages=[HumanMessage(content='アイスクリームについてのジョークを1つ言ってみて。')])
プロンプトをHumanMessageオブジェクトで取り出し。
prompt_value.to_messages()
[HumanMessage(content='アイスクリームについてのジョークを1つ言ってみて。')]
プロンプトを文字列で取り出し。
prompt_value.to_string()
Human: アイスクリームについてのジョークを1つ言ってみて。
モデルにプロンプトを渡すところまで。
message = model.invoke(prompt_value)
message
AIMessage(content='なぜアイスクリームはいつも元気がいいか?\nなぜなら、いつもクールなからだから!', response_metadata={'token_usage': {'completion_tokens': 37, 'prompt_tokens': 31, 'total_tokens': 68}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-58416fac-045f-4ee8-aad0-7806fac4e723-0')
completionモデルであれば文字列になるように出力は変わる。
from langchain_openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo-instruct")
message2 = llm.invoke(prompt_value)
message2
'\n\n「なぜアイスクリームはいつも冷たいの?\u3000なぜなら、冷たくなければ「アイスクリーム」じゃなくて「ミルクスープ」だからさ!」'
modelの出力をoutput_parserに渡す。output_parserはBaseOutputParserのサブクラスを指定(今回は``であり、りこれにより出力が文字列になる。
modelからのレスポンスを出力パーサで文字列に変換する。
output_parser.invoke(message)
なぜアイスクリームはいつも元気がいいか?\nなぜなら、いつもクールなからだから!
モデルの出力が違っても同じように処理される(以下の例は元々文字列なのであまり意味はないけども)
output_parser.invoke(message2)
'\n\n「なぜアイスクリームはいつも冷たいの?\u3000なぜなら、冷たくなければ「アイスクリーム」じゃなくて「ミルクスープ」だからさ!」'
見にくいので上から下にしているけど、こういう流れ。
チェーンは途中の状態で出力することもできる
input = {"topic": "アイスクリーム"}
display(prompt.invoke(input))
display((prompt | model).invoke(input))
ChatPromptValue(messages=[HumanMessage(content='アイスクリームについてのジョークを1つ言ってみて。')])
AIMessage(content='アイスクリームが怒っている理由は何でしょう?\u3000なぜなら、いつもコーンビーフがジェラートになっているから!', response_metadata={'token_usage': {'completion_tokens': 51, 'prompt_tokens': 31, 'total_tokens': 82}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-810ba337-179e-43c8-9dbc-28c74efe9c8d-0')
次にRAGの例。
少しパッケージを追加
!pip install docarray tiktoken
texts = []
texts.append("""\
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬・種牡馬。
主な勝ち鞍は、2022年・2023年の天皇賞(秋)連覇、2022年の有馬記念、2023年のドバイシーマクラシック、宝塚記念、ジャパンカップ。\
""")
texts.append("""\
オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。\
""")
texts.append("""\
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。
主な勝ち鞍は、2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。\
""")
from langchain_community.vectorstores import DocArrayInMemorySearch
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = DocArrayInMemorySearch.from_texts(
texts,
embedding=embedding,
)
retriever = vectorstore.as_retriever()
template = """\
以下のコンテキストにもとづいて、質問に答えてください:
{context}
質問: {question}
回答: \
"""
prompt = ChatPromptTemplate.from_template(template)
output_parser = StrOutputParser()
setup_and_retrieval = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
)
chain = setup_and_retrieval | prompt | model | output_parser
chain.invoke("ドウデュースの勝利したレースは何?")
主な勝ち鞍は、2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。
上記のチェーンのsetup_and_retrievalはそのためのベクトル検索を行うコンポーネントとして定義してある。まずは単体でretrieverを実行してみる。
retriever.invoke("ドウデュースの勝利したレースは何?")
[Document(page_content='ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。\n主な勝ち鞍は、2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。'),
Document(page_content='イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬・種牡馬。\n主な勝ち鞍は、2022年・2023年の天皇賞(秋)連覇、2022年の有馬記念、2023年のドバイシーマクラシック、宝塚記念、ジャパンカップ。'),
Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。')]
検索結果(といっても全件だけども)が配列でわたっている。で、これをpromptに渡すのだけど、promptは2つの引数を受け取る。
- query: 元の入力クエリ
- contexts: ベクトル検索結果
普通にチェーンでつなぐと、出力はそのまま次の入力になってしまうので、これを分けるためにRunnableParallelがある。
setup_and_retrieval = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
)
これでretrieverの結果はcontextsに入る。クエリはそのまま渡したい。RunnablePassthroughを使うと入力がそのままパススルーされて、questionに入る。
多分こんな感じ。
あとは同じ。
LCELのメリットについて書かれている。
LCELは、LLMを使って便利なアプリを構築し、関連するコンポーネントを組み合わせるプロセスを合理化するように設計されています。LCELは次のような機能を提供します:
- 統一インターフェース
- すべてのLCELオブジェクトはRunnableインターフェイスを実装し、共通の呼び出しメソッド(invoke, batch, stream, ainvoke, ...)を定義しています。これにより、LCELオブジェクトのチェーンは、それ自体がLCELオブジェクトであるため、中間ステップのバッチやストリーミングのような便利な操作を自動的にサポートすることができます。
- 合成プリミティブ
- LCELは、チェーンの構成、コンポーネントの並列化、フォールバックの追加、チェーン内部の動的構成などを容易にする、多くのプリミティブを提供します。
LCELの価値をよりよく理解するためには、LCELの動作を見て、LCELなしで同じような機能を再現する方法を考えることが役立ちます。このウォークスルーでは、スタートセクションにある基本的な例を使って、まさにそれを行います。すでに多くの機能を定義しているシンプルなプロンプト+モデルチェーンを取り上げ、そのすべてを再現するために何が必要かを見ていきます。
ということでLCELあり・なしのコードが用意されているが、LCELのコードを試していく。
パッケージインストール
!pip install --upgrade --quiet langchain-core langchain-openai langchain-anthropic
!pip freeze | grep -i langchain
langchain-anthropic==0.1.7
langchain-core==0.1.41
langchain-openai==0.1.2
APIキーを読み込み
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
os.environ['ANTHROPIC_API_KEY'] = userdata.get('ANTHROPIC_API_KEY')
Invoke
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
prompt = ChatPromptTemplate.from_template(
"{topic}についてのジョークを1つおしえて。"
)
output_parser = StrOutputParser()
model = ChatOpenAI(model="gpt-3.5-turbo")
chain = (
{"topic": RunnablePassthrough()}
| prompt
| model
| output_parser
)
response = chain.invoke("アイスクリーム")
print(response)
なぜアイスクリームはいつも元気がいいのか? なぜなら、いつもクールなからだを持っているから!
streamでストリーミング。わかりやすいように改行を入れてみた。
for chunk in chain.stream("アイスクリーム"):
print(chunk, end="\n", flush=True)
ア
イ
ス
ク
リ
ーム
は
ど
う
して
優
秀
な
従
業
員
な
ん
で
し
ょ
う
か
?
な
ぜ
な
ら
、
い
つ
も
ク
ール
で
フ
レ
ーバ
ー
が
豊
富
だ
から
!
batch。バッチ。
chain.batch(["アイスクリーム", "スパゲッティ", "餃子"])
['アイスクリームが学校に行くとき、何を着ていく?\n\nソフトクリーム!',
'スパゲッティがお皿の上で踊っていたら、なぜかみんなが手拍子をしていました。なぜなら、それはアルデンテだったから!',
'餃子が好きな人は、餃子が好きな人が好きだって!']
async。非同期。
await chain.ainvoke("アイスクリーム")
アイスクリームのためなら、どんなに寒い日でも私は"冷静"でいられるよ!
asyncのbatch。
await chain.abatch(["アイスクリーム", "スパゲッティ", "餃子"])
['なぜアイスクリームはいつも冷たいの?\u3000なぜなら、それがクールだから!',
'スパゲッティがテニスをするとき、どんなスタイルを使うか知っていますか? \n\n「スパゲッティ・スイング」です!',
'餃子ってなぜ飛べない?\nだって翼がないから!']
チャットモデルじゃないモデル
from langchain_openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo-instruct")
llm_chain = (
{"topic": RunnablePassthrough()}
| prompt
| llm
| output_parser
)
llm_chain.invoke("アイスクリーム")
\n\nQ: アイスクリームはなぜ笑っているの? \nA: なぜならば、彼はコーンに入るためにドレッシングしているから!
違うモデルプロバイダー
from langchain_anthropic import ChatAnthropic
anthropic = ChatAnthropic(model="claude-3-haiku-20240307")
anthropic_chain = (
{"topic": RunnablePassthrough()}
| prompt
| anthropic
| output_parser
)
anthropic_chain.invoke("アイスクリーム")
はい、アイスクリームのジョークを1つご紹介します。\n\nアイスクリームが冷蔵庫の中で待っていると、冷蔵庫のなかの他の食べ物たちが言いました。\n「もう少しで夏が来るから、アイス君、頑張ってね!」\nそしてアイスクリームが答えました。\n「いいえ、私はもう冷凍庫の中にいます。」\n\n冷蔵庫の中のアイスクリームが、夏が近づいているのを待っているというジョークですね。でも実際はすでに冷凍されているので、夏を待っていません。アイスクリームのユーモアを楽しんでいただけましたでしょうか。
実行時に設定を渡すのところだけど、ちょっとここの書き方が書いてあるとおりに動かない。一番下のフルコードから単体でやってみた。
from langchain_openai import OpenAI, ChatOpenAI
from langchain_anthropic import ChatAnthropic
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, ConfigurableField
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_template(
"{topic}についてのジョークを1つおしえて。"
)
chat_openai = ChatOpenAI(model="gpt-3.5-turbo")
openai = OpenAI(model="gpt-3.5-turbo-instruct")
anthropic = ChatAnthropic(model="claude-3-haiku-20240307")
model = (
chat_openai
.configurable_alternatives(
ConfigurableField(id="model"),
default_key="chat_openai",
openai=openai,
anthropic=anthropic,
)
)
chain = (
{"topic": RunnablePassthrough()}
| prompt
| model
#| StrOutputParser() # modelの出力をそのまま出す
)
chain.invoke("アイスクリーム")
AIMessage(content='なぜアイスクリームがいつも冷たいのか?\nなぜなら、冷たい方がクールだから!', response_metadata={'token_usage': {'completion_tokens': 38, 'prompt_tokens': 31, 'total_tokens': 69}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-7cab2735-4d0e-4c0c-ab5c-9fcbf8da6ea9-0')
chain.invoke("アイスクリーム", config={"model": "openai"})
AIMessage(content='なぜアイスクリームはいつも冷たいのか?\n\nなぜなら、アイスクリームはクールなやつだから!', response_metadata={'token_usage': {'completion_tokens': 43, 'prompt_tokens': 31, 'total_tokens': 74}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-0352125e-3a90-4372-911f-5a9ec4554028-0')
chain.invoke("アイスクリーム",config={"model": "anthropic"})
AIMessage(content='なぜアイスクリームはいつも笑っているのか?\nなぜなら、いつもクールなからだだから!', response_metadata={'token_usage': {'completion_tokens': 38, 'prompt_tokens': 31, 'total_tokens': 69}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-810a3784-6066-447e-b6ea-f14e6fd1f03b-0')
なんだったらこういうのも
chain.invoke("アイスクリーム", config=({"model": "hogehoge"}))
AIMessage(content='なぜアイスクリームはいつも冷たいのか?\n\nなぜなら、冷たくないと「アイス」クリームじゃなくなるから!', response_metadata={'token_usage': {'completion_tokens': 52, 'prompt_tokens': 31, 'total_tokens': 83}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-1ef57003-7e7d-431f-b05d-5cb14655f499-0')
全く機能していない・・・
で、調べてみた。
なんか書き方が違う。。。
chain.with_config(configurable={"model": "openai"}).invoke("アイスクリーム")
\n\nQ: アイスクリームが好きな人は何者でしょうか?\nA: ジェラートマニアック!
chain.with_config(configurable={"model": "anthropic"}).invoke("アイスクリーム")
AIMessage(content='はい、これはアイスクリームに関するジョークです:\n\nなぜアイスクリーマーは仕事を続けるのか分かりますか? \n\nそれは、彼らは暑い季節を通してしっかり溶けないからです。\n\nこのジョークは、アイスクリームを扱う人々がなぜ仕事を続けられるかという皮肉的なコメントです。暑い季節でもアイスクリームは溶けないため、彼らは仕事を続けられるのだと言っています。少し冗談っぽくて、アイスクリームビジネスに関する遊び心のあるジョークですね。', response_metadata={'id': 'msg_016fHk3bqzkEUfPJHMhRZd6d', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 27, 'output_tokens': 199}}, id='run-f27074ff-4249-4d6e-9c4c-daf778315170-0')
chain.with_config(configurable={"model": "hogehoge"}).invoke("アイスクリーム")
ValueError: Unknown alternative: hogehoge
ちゃんとできたっぽい。
ソースを見る限りはconfigはRunnableConfigで指定しないといけないっぽい。
from langchain_core.runnables import RunnableConfig
chain.invoke("アイスクリーム",config=RunnableConfig(configurable={"model": "anthropic"}))
AIMessage(content='アイスクリームにまつわる面白いジョークがこちらです:\n\n"アイスクリームを食べすぎたら、ぜったいにアイス・クリーミングが始まるから気をつけなきゃね。"\n\nこの冗談は、アイスクリームを食べ過ぎると胃痛になるというネタに基づいています。「アイス・クリーミング」というのは、おなかの調子が悪くなることを表現した言葉遊びです。少しグローリーかもしれませんが、アイスクリームに関するユーモアのある一例としてお楽しみください。', response_metadata={'id': 'msg_012QggXGbV6rQmKhNDGgWz81', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 27, 'output_tokens': 190}}, id='run-97111645-d93a-4759-ab8e-4206ff4f0667-0')
ドキュメントが更新されていないってことなのかしら。。。。
参考)
で最後にFallback。ここはちょっと再現ができなかったのでコードだけ。
(snip)
model = (
chat_openai
.with_fallbacks([anthropic]) # ここ
.configurable_alternatives(
ConfigurableField(id="model"),
default_key="chat_openai",
openai=openai,
anthropic=anthropic,
)
)
(snip)
すべて実装したフルのコードが公式ページの一番下にあるけど、上で少し触れたので割愛。ただ、LCELを使わない場合と比べて圧倒的にコード量も少ないし、見通しもものすごく良いのがよくわかる。
というか自分が以前触れていたのもLCELを使わない場合のコードだし、もう別物としてイチからやり直している気分だなー
LCELの各コンポーネントは、Runnableプロトコルにもとづいて統一されたインタフェースを持っている。
標準インタフェースは以下。
-
stream: レスポンスのストリームをチャンクで返す -
invoke: 入力に対してチェーンを呼び出す -
batch: 入力リストに対してチェーンを呼びだす
これらにそれぞれ非同期メソッドも用意されていて、asyncioのawaitと組み合わせて使用する
-
astream:streamの非同期 -
ainvoke:invokeの非同期 -
abatch:batchの非同期 -
astream_log: 最終的なレスポンスに加えて、中間ステップもストリームで返す。 -
astream_events: チェーンで発生したイベントをストリームで返す(ベータ。langchain-core0.1.14から)
また各コンポーネントは入力と出力のそれぞれに型を持っている。
| コンポーネント | 入力の型 | 出力の型 |
|---|---|---|
| Prompt | 辞書 | PromptValue |
| ChatModel | 単一の文字列/チャットメッセージのリスト/PromptValue | ChatMessage |
| LLM | 単一の文字列/チャットメッセージのリスト/PromptValue | 文字列 |
| OutputParser | LLM/ChatModelの出力 | パーサによって異なる |
| Retriever | 単一の文字列 | ドキュメントのリスト |
| Tool | 単一の文字列や辞書など、ツールによって異なる | ツールによって異なる |
すべてのRunnableコンポーネントは入出力をチェックするためのスキーマ、input_schema/output_schemaが用意されており、これらはコンポーネントの構造からPydanticで自動的に生成される。
シンプルなプロンプト・LLMのチェーンを作成する。
!pip install --upgrade --quiet langchain-core langchain-openai langchain-community
!pip freeze | grep -i langchain
langchain-community==0.0.32
langchain-core==0.1.41
langchain-openai==0.1.2
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
model = ChatOpenAI()
prompt = ChatPromptTemplate.from_template("{topic}についてのジョークを1つ考えて。")
chain = prompt
チェーンの入出力スキーマを確認。出力は少しインデントを整形した。
chain.input_schema.schema()
{
'title': 'PromptInput',
'type': 'object',
'properties': {
'topic': {
'title': 'Topic',
'type': 'string'
}
}
}
chain.output_schema.schema()
{
'title': 'ChatOpenAIOutput',
'anyOf': [
{
'$ref': '#/definitions/AIMessage'
},
{
'$ref': '#/definitions/HumanMessage'
},
{
'$ref': '#/definitions/ChatMessage'
},
{
'$ref': '#/definitions/SystemMessage'
},
{
'$ref': '#/definitions/FunctionMessage'
},
{
'$ref': '#/definitions/ToolMessage'
}
],
'definitions': {
'AIMessage': {
'title': 'AIMessage',
'description': 'Message from an AI.',
'type': 'object',
'properties': {
'content': {
'title': 'Content',
'anyOf': [
{
'type': 'string'
},
{
'type': 'array',
'items': {
'anyOf': [
{
'type': 'string'
},
{
'type': 'object'
}
]
}
}
]
},
'additional_kwargs': {
'title': 'Additional Kwargs',
'type': 'object'
},
'response_metadata': {
'title': 'Response Metadata',
'type': 'object'
},
'type': {
'title': 'Type',
'default': 'ai',
'enum': [
'ai'
],
'type': 'string'
},
'name': {
'title': 'Name',
'type': 'string'
},
'id': {
'title': 'Id',
'type': 'string'
},
'example': {
'title': 'Example',
'default': False,
'type': 'boolean'
}
},
'required': [
'content'
]
},
'HumanMessage': {
'title': 'HumanMessage',
'description': 'Message from a human.',
'type': 'object',
'properties': {
'content': {
'title': 'Content',
'anyOf': [
{
'type': 'string'
},
{
'type': 'array',
'items': {
'anyOf': [
{
'type': 'string'
},
{
'type': 'object'
}
]
}
}
]
},
'additional_kwargs': {
'title': 'Additional Kwargs',
'type': 'object'
},
'response_metadata': {
'title': 'Response Metadata',
'type': 'object'
},
'type': {
'title': 'Type',
'default': 'human',
'enum': [
'human'
],
'type': 'string'
},
'name': {
'title': 'Name',
'type': 'string'
},
'id': {
'title': 'Id',
'type': 'string'
},
'example': {
'title': 'Example',
'default': False,
'type': 'boolean'
}
},
'required': [
'content'
]
},
'ChatMessage': {
'title': 'ChatMessage',
'description': 'Message that can be assigned an arbitrary speaker (i.e. role).',
'type': 'object',
'properties': {
'content': {
'title': 'Content',
'anyOf': [
{
'type': 'string'
},
{
'type': 'array',
'items': {
'anyOf': [
{
'type': 'string'
},
{
'type': 'object'
}
]
}
}
]
},
'additional_kwargs': {
'title': 'Additional Kwargs',
'type': 'object'
},
'response_metadata': {
'title': 'Response Metadata',
'type': 'object'
},
'type': {
'title': 'Type',
'default': 'chat',
'enum': [
'chat'
],
'type': 'string'
},
'name': {
'title': 'Name',
'type': 'string'
},
'id': {
'title': 'Id',
'type': 'string'
},
'role': {
'title': 'Role',
'type': 'string'
}
},
'required': [
'content',
'role'
]
},
'SystemMessage': {
'title': 'SystemMessage',
'description': 'Message for priming AI behavior, usually passed in as the first of a sequence\nof input messages.',
'type': 'object',
'properties': {
'content': {
'title': 'Content',
'anyOf': [
{
'type': 'string'
},
{
'type': 'array',
'items': {
'anyOf': [
{
'type': 'string'
},
{
'type': 'object'
}
]
}
}
]
},
'additional_kwargs': {
'title': 'Additional Kwargs',
'type': 'object'
},
'response_metadata': {
'title': 'Response Metadata',
'type': 'object'
},
'type': {
'title': 'Type',
'default': 'system',
'enum': [
'system'
],
'type': 'string'
},
'name': {
'title': 'Name',
'type': 'string'
},
'id': {
'title': 'Id',
'type': 'string'
}
},
'required': [
'content'
]
},
'FunctionMessage': {
'title': 'FunctionMessage',
'description': 'Message for passing the result of executing a function back to a model.',
'type': 'object',
'properties': {
'content': {
'title': 'Content',
'anyOf': [
{
'type': 'string'
},
{
'type': 'array',
'items': {
'anyOf': [
{
'type': 'string'
},
{
'type': 'object'
}
]
}
}
]
},
'additional_kwargs': {
'title': 'Additional Kwargs',
'type': 'object'
},
'response_metadata': {
'title': 'Response Metadata',
'type': 'object'
},
'type': {
'title': 'Type',
'default': 'function',
'enum': [
'function'
],
'type': 'string'
},
'name': {
'title': 'Name',
'type': 'string'
},
'id': {
'title': 'Id',
'type': 'string'
}
},
'required': [
'content',
'name'
]
},
'ToolMessage': {
'title': 'ToolMessage',
'description': 'Message for passing the result of executing a tool back to a model.',
'type': 'object',
'properties': {
'content': {
'title': 'Content',
'anyOf': [
{
'type': 'string'
},
{
'type': 'array',
'items': {
'anyOf': [
{
'type': 'string'
},
{
'type': 'object'
}
]
}
}
]
},
'additional_kwargs': {
'title': 'Additional Kwargs',
'type': 'object'
},
'response_metadata': {
'title': 'Response Metadata',
'type': 'object'
},
'type': {
'title': 'Type',
'default': 'tool',
'enum': [
'tool'
],
'type': 'string'
},
'name': {
'title': 'Name',
'type': 'string'
},
'id': {
'title': 'Id',
'type': 'string'
},
'tool_call_id': {
'title': 'Tool Call Id',
'type': 'string'
}
},
'required': [
'content',
'tool_call_id'
]
}
}
}
各コンポーネント単位でも確認できる。以下はプロンプトの入力スキーマ。
prompt.input_schema.schema()
プロンプト→LLMのチェーンなので、当然チェーンの入力スキーマとプロンプトの入力スキーマは同じになる。
{
'title': 'PromptInput',
'type': 'object',
'properties': {
'topic': {
'title': 'Topic',
'type': 'string'
}
}
}
当然ながらチェーンの出力スキーマとLLMの出力スキーマも同じになる。
各メソッドについては前回もやっているものについては割愛。触れていないものだけ少し見ておく。
Async Stream Events (ベータ)
※ベータなので変更される可能性あり。
多分トレーシングやログで使えるものだと思う。ベータだしサラッと動かす程度で。
!pip install -q faiss-cpu
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
template = """\
以下の文脈のみに基づいて質問に回答して下さい:
{context}
質問: {question}
回答: \
"""
prompt = ChatPromptTemplate.from_template(template)
doc = """\
オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。\
"""
vectorstore = FAISS.from_texts(
[doc], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
model = ChatOpenAI()
retrieval_chain = (
{
"context": retriever.with_config(run_name="Docs"),
"question": RunnablePassthrough(),
}
| prompt
| model.with_config(run_name="my_llm")
| StrOutputParser()
)
async for event in retrieval_chain.astream_events(
"オグリキャップの主な勝ち鞍は?", version="v1", include_names=["Docs", "my_llm"]
):
kind = event["event"]
print(f"----- {kind} ----")
if kind == "on_chat_model_stream":
print(event["data"]["chunk"].content, end="\n")
elif kind in {"on_chat_model_start"}:
print("Start Streaming LLM:")
elif kind in {"on_chat_model_end"}:
print("Done streaming LLM.")
elif kind == "on_retriever_end":
print("--")
print("Retrieved the following documents:")
print(event["data"]["output"]["documents"])
elif kind == "on_tool_end":
print(f"Ended tool: {event['name']}")
else:
pass
----- on_retriever_start ----
----- on_retriever_end ----
--
Retrieved the following documents:
[Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。')]
----- on_chat_model_start ----
Start Streaming LLM:
----- on_chat_model_stream ----
----- on_chat_model_stream ----
198
----- on_chat_model_stream ----
8
----- on_chat_model_stream ----
年
----- on_chat_model_stream ----
・
----- on_chat_model_stream ----
199
----- on_chat_model_stream ----
0
----- on_chat_model_stream ----
年
----- on_chat_model_stream ----
の
----- on_chat_model_stream ----
有
----- on_chat_model_stream ----
馬
----- on_chat_model_stream ----
記
----- on_chat_model_stream ----
念
----- on_chat_model_stream ----
、
----- on_chat_model_stream ----
198
----- on_chat_model_stream ----
9
----- on_chat_model_stream ----
年
----- on_chat_model_stream ----
の
----- on_chat_model_stream ----
マ
----- on_chat_model_stream ----
イ
----- on_chat_model_stream ----
ル
----- on_chat_model_stream ----
チ
----- on_chat_model_stream ----
ャ
----- on_chat_model_stream ----
ン
----- on_chat_model_stream ----
ピ
----- on_chat_model_stream ----
オ
----- on_chat_model_stream ----
ン
----- on_chat_model_stream ----
シ
----- on_chat_model_stream ----
ッ
----- on_chat_model_stream ----
プ
----- on_chat_model_stream ----
、
----- on_chat_model_stream ----
199
----- on_chat_model_stream ----
0
----- on_chat_model_stream ----
年
----- on_chat_model_stream ----
の
----- on_chat_model_stream ----
安
----- on_chat_model_stream ----
田
----- on_chat_model_stream ----
記
----- on_chat_model_stream ----
念
----- on_chat_model_stream ----
----- on_chat_model_end ----
Done streaming LLM.
Async Stream Intermediate Steps
すべてのRunnableあh中間ステップを生成するための.astream_log()を実装している。ユーザに進行状態を示す・中間結果を表示・デバッグなどで使える。すべてのステップをストリームすることもできるし、タグ・名前・メタデータなどで含む・含まないも制御できる。
JSONPatchがストリームで流れてくるらしい。
async for chunk in retrieval_chain.astream_log(
"オグリキャップの主な勝ち鞍は?", include_names=["Docs"]
):
print("-" * 40)
print(chunk)
----------------------------------------
RunLogPatch({'op': 'replace',
'path': '',
'value': {'final_output': None,
'id': '298f2298-70ea-4993-a5a1-f059c4f8eca8',
'logs': {},
'name': 'RunnableSequence',
'streamed_output': [],
'type': 'chain'}})
----------------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/Docs',
'value': {'end_time': None,
'final_output': None,
'id': '3184e2a9-2381-471e-a2e3-b12cb8b9ab1d',
'metadata': {},
'name': 'Docs',
'start_time': '2024-04-11T18:55:03.668+00:00',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}})
----------------------------------------
RunLogPatch({'op': 'add',
'path': '/logs/Docs/final_output',
'value': {'documents': [Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。')]}},
{'op': 'add',
'path': '/logs/Docs/end_time',
'value': '2024-04-11T18:55:03.991+00:00'})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': ''},
{'op': 'replace', 'path': '/final_output', 'value': ''})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': '198'},
{'op': 'replace', 'path': '/final_output', 'value': '198'})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': '8'},
{'op': 'replace', 'path': '/final_output', 'value': '1988'})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': '年'},
{'op': 'replace', 'path': '/final_output', 'value': '1988年'})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': '・'},
{'op': 'replace', 'path': '/final_output', 'value': '1988年・'})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': '199'},
{'op': 'replace', 'path': '/final_output', 'value': '1988年・199'})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': '0'},
{'op': 'replace', 'path': '/final_output', 'value': '1988年・1990'})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': '年'},
{'op': 'replace', 'path': '/final_output', 'value': '1988年・1990年'})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': 'の'},
{'op': 'replace', 'path': '/final_output', 'value': '1988年・1990年の'})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': '有'},
{'op': 'replace', 'path': '/final_output', 'value': '1988年・1990年の有'})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': '馬'},
{'op': 'replace', 'path': '/final_output', 'value': '1988年・1990年の有馬'})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': '記'},
{'op': 'replace', 'path': '/final_output', 'value': '1988年・1990年の有馬記'})
----------------------------------------
RunLogPatch({'op': 'add', 'path': '/streamed_output/-', 'value': '念'},
{'op': 'replace', 'path': '/final_output', 'value': '1988年・1990年の有馬記念'})
(snip)
diff=Falseをつけるとインクリメンタルにストリームされる。
async for chunk in retrieval_chain.astream_log(
"オグリキャップの主な勝ち鞍は?", include_names=["Docs"], diff=False
):
print("-" * 70)
print(chunk)
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': '0f08bd20-8065-4038-81dc-75d42fb2f039',
'logs': {},
'name': 'RunnableSequence',
'streamed_output': [],
'type': 'chain'})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': '0f08bd20-8065-4038-81dc-75d42fb2f039',
'logs': {'Docs': {'end_time': None,
'final_output': None,
'id': '7f66132d-e3da-43c5-a8c6-e4dbb29d0305',
'metadata': {},
'name': 'Docs',
'start_time': '2024-04-11T18:58:33.186+00:00',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'name': 'RunnableSequence',
'streamed_output': [],
'type': 'chain'})
----------------------------------------------------------------------
RunLog({'final_output': None,
'id': '0f08bd20-8065-4038-81dc-75d42fb2f039',
'logs': {'Docs': {'end_time': '2024-04-11T18:58:33.401+00:00',
'final_output': {'documents': [Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。')]},
'id': '7f66132d-e3da-43c5-a8c6-e4dbb29d0305',
'metadata': {},
'name': 'Docs',
'start_time': '2024-04-11T18:58:33.186+00:00',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'name': 'RunnableSequence',
'streamed_output': [],
'type': 'chain'})
----------------------------------------------------------------------
RunLog({'final_output': '',
'id': '0f08bd20-8065-4038-81dc-75d42fb2f039',
'logs': {'Docs': {'end_time': '2024-04-11T18:58:33.401+00:00',
'final_output': {'documents': [Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。')]},
'id': '7f66132d-e3da-43c5-a8c6-e4dbb29d0305',
'metadata': {},
'name': 'Docs',
'start_time': '2024-04-11T18:58:33.186+00:00',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'name': 'RunnableSequence',
'streamed_output': [''],
'type': 'chain'})
----------------------------------------------------------------------
RunLog({'final_output': '198',
'id': '0f08bd20-8065-4038-81dc-75d42fb2f039',
'logs': {'Docs': {'end_time': '2024-04-11T18:58:33.401+00:00',
'final_output': {'documents': [Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。')]},
'id': '7f66132d-e3da-43c5-a8c6-e4dbb29d0305',
'metadata': {},
'name': 'Docs',
'start_time': '2024-04-11T18:58:33.186+00:00',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'name': 'RunnableSequence',
'streamed_output': ['', '198'],
'type': 'chain'})
----------------------------------------------------------------------
RunLog({'final_output': '1988',
'id': '0f08bd20-8065-4038-81dc-75d42fb2f039',
'logs': {'Docs': {'end_time': '2024-04-11T18:58:33.401+00:00',
'final_output': {'documents': [Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。')]},
'id': '7f66132d-e3da-43c5-a8c6-e4dbb29d0305',
'metadata': {},
'name': 'Docs',
'start_time': '2024-04-11T18:58:33.186+00:00',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'name': 'RunnableSequence',
'streamed_output': ['', '198', '8'],
'type': 'chain'})
----------------------------------------------------------------------
RunLog({'final_output': '1988年',
'id': '0f08bd20-8065-4038-81dc-75d42fb2f039',
'logs': {'Docs': {'end_time': '2024-04-11T18:58:33.401+00:00',
'final_output': {'documents': [Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。')]},
'id': '7f66132d-e3da-43c5-a8c6-e4dbb29d0305',
'metadata': {},
'name': 'Docs',
'start_time': '2024-04-11T18:58:33.186+00:00',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'name': 'RunnableSequence',
'streamed_output': ['', '198', '8', '年'],
'type': 'chain'})
----------------------------------------------------------------------
RunLog({'final_output': '1988年・',
'id': '0f08bd20-8065-4038-81dc-75d42fb2f039',
'logs': {'Docs': {'end_time': '2024-04-11T18:58:33.401+00:00',
'final_output': {'documents': [Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。')]},
'id': '7f66132d-e3da-43c5-a8c6-e4dbb29d0305',
'metadata': {},
'name': 'Docs',
'start_time': '2024-04-11T18:58:33.186+00:00',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'name': 'RunnableSequence',
'streamed_output': ['', '198', '8', '年', '・'],
'type': 'chain'})
----------------------------------------------------------------------
RunLog({'final_output': '1988年・199',
'id': '0f08bd20-8065-4038-81dc-75d42fb2f039',
'logs': {'Docs': {'end_time': '2024-04-11T18:58:33.401+00:00',
'final_output': {'documents': [Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。')]},
'id': '7f66132d-e3da-43c5-a8c6-e4dbb29d0305',
'metadata': {},
'name': 'Docs',
'start_time': '2024-04-11T18:58:33.186+00:00',
'streamed_output': [],
'streamed_output_str': [],
'tags': ['map:key:context', 'FAISS', 'OpenAIEmbeddings'],
'type': 'retriever'}},
'name': 'RunnableSequence',
'streamed_output': ['', '198', '8', '年', '・', '199'],
'type': 'chain'})
(snip)
Parallelism
並列リクエストはRunnableParallelを使う
from langchain_core.runnables import RunnableParallel
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
model = ChatOpenAI()
chain1 = ChatPromptTemplate.from_template("{topic}に付いてのジョークを1つ考えて") | model
chain2 = (
ChatPromptTemplate.from_template("{topic}についての短い(2行)の詩を書いて") | model
)
combined = RunnableParallel(joke=chain1, poem=chain2)
単体で実行してみる。
%%time
chain1.invoke({"topic": "アイスクリーム"})
CPU times: user 41.4 ms, sys: 813 µs, total: 42.3 ms
Wall time: 852 ms
AIMessage(content='アイスクリームは、冷たくても心は温かい!', response_metadata={'token_usage': {'completion_tokens': 22, 'prompt_tokens': 29, 'total_tokens': 51}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-f5f4f8e1-ce7a-4f01-9848-12a028050613-0')
%%time
chain2.invoke({"topic": "アイスクリーム"})
CPU times: user 23.7 ms, sys: 1.21 ms, total: 24.9 ms
Wall time: 789 ms
AIMessage(content='夏の日に\n冷たい甘味\u3000幸せ溶ける', response_metadata={'token_usage': {'completion_tokens': 22, 'prompt_tokens': 35, 'total_tokens': 57}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-663fac17-393d-4c5d-afec-7eb952cba783-0')
並列実行
%%time
combined.invoke({"topic": "アイスクリーム"})
CPU times: user 42.1 ms, sys: 7.17 ms, total: 49.3 ms
Wall time: 886 ms
{'joke': AIMessage(content='アイスクリームが嫌いな人は、クールな人とは言えないよ!', response_metadata={'token_usage': {'completion_tokens': 28, 'prompt_tokens': 29, 'total_tokens': 57}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-3b73e12b-0abb-4698-86d0-df1737eb5711-0'),
'poem': AIMessage(content='冷たい舌で溶ける\n甘い夢を追いかける', response_metadata={'token_usage': {'completion_tokens': 24, 'prompt_tokens': 35, 'total_tokens': 59}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-49d5c600-d60b-4322-8426-f67ea7cda82b-0')}
バッチで実行してみる。
%%time
chain1.batch([{"topic": "アイスクリーム"}, {"topic": "チョコレート"}])
CPU times: user 62.5 ms, sys: 11.7 ms, total: 74.2 ms
Wall time: 1.32 s
[AIMessage(content='なぜアイスクリームはいつも冷たいままなのか?なぜなら、溶けるとクリームのようになってしまうからだ!', response_metadata={'token_usage': {'completion_tokens': 51, 'prompt_tokens': 29, 'total_tokens': 80}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-088aec9b-c2a0-4071-ae1c-6e63a327894d-0'),
AIMessage(content='Why did the chocolate go to the doctor?\n\nBecause it was feeling fudged up!', response_metadata={'token_usage': {'completion_tokens': 18, 'prompt_tokens': 27, 'total_tokens': 45}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-e00fd48a-a6e7-459c-9382-aedc4def7e1b-0')]
%%time
chain2.batch([{"topic": "アイスクリーム"}, {"topic": "チョコレート"}])
CPU times: user 42 ms, sys: 5.1 ms, total: 47.1 ms
Wall time: 945 ms
[AIMessage(content='甘い氷、口の中で溶ける\n夏の日を彩る至福のひととき', response_metadata={'token_usage': {'completion_tokens': 32, 'prompt_tokens': 35, 'total_tokens': 67}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-b36a1746-4a19-4fe6-9b40-b04fb2a844f9-0'),
AIMessage(content='甘く溶ける\n口の中で幸せ満ちる', response_metadata={'token_usage': {'completion_tokens': 19, 'prompt_tokens': 33, 'total_tokens': 52}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-24975d44-0bc9-437f-8968-08e74fc28d54-0')]
%%time
combined.batch([{"topic": "アイスクリーム"}, {"topic": "チョコレート"}])
CPU times: user 79.6 ms, sys: 5.77 ms, total: 85.3 ms
Wall time: 1.13 s
[{'joke': AIMessage(content='アイスクリームがビジネスマンになったら、毎日が忙しくてバニランドに行く時間もないかもしれない!', response_metadata={'token_usage': {'completion_tokens': 49, 'prompt_tokens': 29, 'total_tokens': 78}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-7502d217-583d-49d7-ac60-968e54b5edc0-0'),
'poem': AIMessage(content='甘い冷たさ\n夏の日を涼む', response_metadata={'token_usage': {'completion_tokens': 17, 'prompt_tokens': 35, 'total_tokens': 52}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-426e420c-4d29-438f-9365-36304d85c016-0')},
{'joke': AIMessage(content="Why did the chocolate go to the therapist?\n\nBecause it just couldn't seem to break out of its shell!", response_metadata={'token_usage': {'completion_tokens': 22, 'prompt_tokens': 27, 'total_tokens': 49}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-36569f97-42e2-47fb-9c40-37fae271b29c-0'),
'poem': AIMessage(content='甘い誘惑\n口溶けの魔法', response_metadata={'token_usage': {'completion_tokens': 17, 'prompt_tokens': 33, 'total_tokens': 50}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-44b12f98-72c2-4202-8d91-c98789deb238-0')}]
短い時間で処理できていることから並列実行が効いているのがわかる
Primitives
LCELで使えるコンポーネントは以下
これ以外にもユーティリティ的なコンポーネントが用意されている。これをプリミティブという。
プリミティブを使うと以下のようなことができる。
- データの受け渡しやフォーマット
- 引数のバインド
- カスタムロジックの呼び出し
プリミティブとしてあげられているのは以下。
- Sequences: Runnableをチェーンにする
- Binding: 実行時の引数をアタッチする
- Passthrough: 入力をパススルーする
- 実行時にチェーン内の設定を変更する
- Parallel: データをフォーマットする
- Lambda: カスタム関数を実行する
- Assign: 値を状態に追加する
順に見ていく
Sequences: Runnableをチェーンにする
!pip install --upgrade --quiet langchain-core langchain-openai
!pip freeze | grep -i langchain
langchain-core==0.1.42
langchain-openai==0.1.3
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI()
prompt = ChatPromptTemplate.from_template("{topic}についてのジョークを1つ考えて。")
chain = prompt | model | StrOutputParser()
chain.invoke({"topic": "アイスクリーム"})
なぜアイスクリームはいつも冷たいのか?\n- なぜなら、"アイス"だから!
RunnableのチェーンはRunnableSequenceとなり、Runnableと同じくinvokeができる。
print(type(chain))
<class 'langchain_core.runnables.base.RunnableSequence'>
さらにチェーンを繋いでチェーンを作ることもできる。ただしRunnable同士の入出力をあわせる必要はある。
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI()
prompt = ChatPromptTemplate.from_template("{topic}についてのジョークを1つ考えて。")
chain = (
prompt
| model
| StrOutputParser()
)
analysis_prompt = ChatPromptTemplate.from_template("このジョークは笑えるどうかを説明して: {joke}")
composed_chain = (
{"joke": chain}
| analysis_prompt
| model
| StrOutputParser()
)
このジョークは、アイスクリームが冷たいという普通の理由ではなく、ジョーク自体が冷たいというユーモアが含まれています。言葉遊びを楽しむ人には笑えるかもしれません。
途中の状態も含めて見てみる。
async for event in composed_chain.astream_events(
{"topic": "アイスクリーム"}, version="v1"
):
kind = event["event"]
if kind == "on_chat_model_stream":
print(event["data"]["chunk"].content, end="")
elif kind in {"on_chat_model_start"}:
print()
print("Start LLM:")
elif kind in {"on_chat_model_end"}:
print()
print("End LLM")
print()
elif kind in {"on_prompt_start"}:
print("Start Prompt:")
print(event["data"])
print()
elif kind in {"on_prompt_end"}:
print("End prompt")
print(event["data"]["output"].to_messages())
else:
pass
Start Prompt:
{'input': {'topic': 'アイスクリーム'}}
End prompt
[HumanMessage(content='アイスクリームについてのジョークを1つ考えて。')]
Start LLM:
なぜアイスクリームはいつも冷たいのか? なぜなら、熱いと「アイス、アイス、走れ!」から始まるからだ!
End LLM
Start Prompt:
{'input': {'joke': 'なぜアイスクリームはいつも冷たいのか?\u3000なぜなら、熱いと「アイス、アイス、走れ!」から始まるからだ!'}}
End prompt
[HumanMessage(content='このジョークは笑えるどうかを説明して: なぜアイスクリームはいつも冷たいのか?\u3000なぜなら、熱いと「アイス、アイス、走れ!」から始まるからだ!')]
Start LLM:
このジョークは、アイスクリームがいつも冷たい理由を、アイスクリーム自体に対して人間の感情や行動を重ねて面白おかしく表現している点が笑いを誘う要素です。通常、アイスクリームが冷たいのはその性質によるものですが、ここではそれを熱いという感情や行動に例えて、意外性とユーモアを持って表現しています。そのため、聞いた人が予想外の展開に笑いがこみ上げるでしょう。
End LLM
関数を実行させる事もできる。ただしストリーミングとかの場合は使い方を注意しないといけない。
composed_chain_with_lambda = (
chain
| (lambda input: {"joke": input})
| analysis_prompt
| model
| StrOutputParser()
)
composed_chain_with_lambda.invoke({"topic": "アイスクリーム"})
このジョークは、アイスクリームが冷たいから元気がいいというユーモアを含んでいます。アイスクリームはクールで元気がある食べ物であるという意外な視点からのジョークであり、その意外性から笑いが生まれる要素があります。また、アイスクリームがいつも元気がいいという言い方も、人間の感情や様子を食べ物に例えているところも面白さを引き立てています。
パイプでつないでいるものは.pipe()メソッドでもつなげる。
composed_chain_with_pipe = (
chain
.pipe((lambda input: {"joke": input}))
.pipe(analysis_prompt)
.pipe(model)
.pipe(StrOutputParser())
)
composed_chain_with_pipe.invoke({"topic": "アイスクリーム"})
このジョークは、アイスクリームが自分で歩いていくことが不可能なことを前提にして、そのようなことが可能になった場合のユーモアを描写しています。また、"クリーム・パフェレーション"という造語が面白おかしいという点も笑いを生んでいます。全体的に、非現実的でありながらも想像力を掻き立てる要素があり、笑いを誘う要素が含まれています。
Parallel: データをフォーマットする
Parallelなんだけど、なんでデータのフォーマットの話なのかなと思って見てみた。
RunnableParallelプリミティブは基本的にdictで、その値はrunnable(または関数のようにrunnableに強制できるもの)です。このプリミティブはすべての値を並列に実行し、各値はRunnableParallelの全体的な入力で呼び出されます。最終的な戻り値は、各値の結果を適切なキーの下に持つdictです。
これは、操作を並列化するのに便利だが、あるRunnableの出力を操作して、シーケンスの次のRunnableの入力フォーマットと一致させるのにも役立ちます
なるほど、入出力データをフォーマットできる。
!pip install --upgrade --quiet langchain-core langchain-openai langchain_community faiss-cpu
!pip freeze | grep -i langchain
langchain-community==0.0.32
langchain-core==0.1.42
langchain-openai==0.1.3
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
texts = []
texts.append("""\
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬・種牡馬。
主な勝ち鞍は、2022年・2023年の天皇賞(秋)連覇、2022年の有馬記念、2023年のドバイシーマクラシック、宝塚記念、ジャパンカップ。\
""")
texts.append("""\
オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。\
""")
texts.append("""\
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。
主な勝ち鞍は、2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。\
""")
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
vectorstore = FAISS.from_texts(
texts, embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
template = """\
以下のコンテキストにもとづいて、質問に答えてください:
{context}
質問: {question}
回答: \
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
retrieval_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
retrieval_chain.invoke("イクイノックスの生年月日は?")
2019年3月23日
なるほど、たしかに辞書で渡していたわ。
retrieval_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
こういう書き方もできる。
retrieval_chain = (
RunnableParallel({"context": retriever, "question": RunnablePassthrough()})
| prompt
| model
| StrOutputParser()
)
retrieval_chain = (
RunnableParallel(context=retriever, question=RunnablePassthrough())
| prompt
| model
| StrOutputParser()
)
itemgetterを使ってこういう書き方もできる、というかitemgetter使ったことないわ。
なるほど。
from operator import itemgetter
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
vectorstore = FAISS.from_texts(
texts, embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
template = """\
以下のコンテキストにもとづいて、質問に答えてください:
{context}
質問: {question}
回答に使用する言語: {language}
回答: \
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{
"context": itemgetter("question") | retriever,
"question": itemgetter("question"),
"language": itemgetter("language"),
}
| prompt
| model
| StrOutputParser()
)
chain.invoke({"question": "イクイノックスの主な勝ち鞍は?", "language":"スペイン語"})
Las principales victorias de Equinox son la doble victoria en el Tenno Sho (Otoño) en 2022 y 2023, la victoria en la Copa Arima Kinen en 2022, la Dubai Sheema Classic en 2023, el Takarazuka Kinen y la Japan Cup en 2023.
questionとlanguageはパススルーされるのね
これ以降の箇所は以下と重複するのでスキップ
Binding: 実行時に引数をアタッチする
Runnableシーケンス内のRunnableを、シーケンス内の先行するRunnableの出力の一部でもなく、ユーザー入力の一部でもない定数引数で呼び出したいことがある。Runnable.bind()を使って、これらの引数を渡すことができる。
!pip install --upgrade --quiet langchain-core langchain-openai
!pip freeze | grep -i langchain
langchain-core==0.1.42
langchain-openai==0.1.3
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"代数記号を使って次の方程式を書き出しそれを解きなさい。書式は以下を使用しなさい。\n\nEQUATION:...\n\nSOLUTION:...\n\n"
),
(
"human",
"{equation_statement}"
),
]
)
model = ChatOpenAI(temperature=0)
runnable = (
{"equation_statement": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(runnable.invoke("xの3乗+7=12"))
EQUATION: ( x^3 + 7 = 12 )
SOLUTION:
( x^3 = 12 - 7 = 5 )( x = \sqrt[3]{5} )
モデル実行時にstopワードを追加する
runnable = (
{"equation_statement": RunnablePassthrough()}
| prompt
| model.bind(stop="SOLUTION")
| StrOutputParser()
)
print(runnable.invoke("xの3乗+7=12"))
EQUATION: ( x^3 + 7 = 12 )
stopワードで指定したSOLUTIONのところで出力が終了する。
Function Callingの関数をアタッチする。
function = {
"name": "solver",
"description": "方程式を立てて解く",
"parameters": {
"type": "object",
"properties": {
"equation": {
"type": "string",
"description": "方程式の代数的表現",
},
"solution": {
"type": "string",
"description": "方程式の解",
},
},
"required": ["equation", "solution"],
},
}
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"代数記号を使って次の方程式を書き出し、それを解きなさい。",
),
("human", "{equation_statement}"),
]
)
model = ChatOpenAI(model="gpt-4-turbo-2024-04-09", temperature=0).bind(
function_call={"name": "solver"}, functions=[function]
)
runnable = (
{"equation_statement": RunnablePassthrough()}
| prompt
| model
)
print(runnable.invoke("xの3乗+7=12"))
content='' additional_kwargs={'function_call': {'arguments': '{"equation":"x^3 + 7 = 12","solution":"x^3 = 5"}', 'name': 'solver'}} response_metadata={'token_usage': {'completion_tokens': 23, 'prompt_tokens': 118, 'total_tokens': 141}, 'model_name': 'gpt-4-turbo-2024-04-09', 'system_fingerprint': 'fp_6fcb0929db', 'finish_reason': 'stop', 'logprobs': None} id='run-83ccf762-c34b-4a5a-bad1-0a9ee6b9a975-0'
ということは、こういう書き方もできるはず。
model = ChatOpenAI(model="gpt-4-turbo-2024-04-09", temperature=0)
runnable = (
{"equation_statement": RunnablePassthrough()}
| prompt
| model.bind(function_call={"name": "solver"}, functions=[function])
)
print(runnable.invoke("xの3乗+7=12"))
Tool Call、つまりParallel Function Callingでもできる。
tools = [
{
"type": "function",
"function": {
"name": "get_current_temperature",
"description": "指定された都市の現在の気温を取得する",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "都市名を英語で指定。例) San Francisco, Tokyo.",
},
"unit": {
"type": "string",
"enum": ["fahrenheit", "celsius"],
"description": "気温の単位。ユーザの言語や位置情報から判断する。",
},
},
"required": ["location", "unit"],
}
}
},
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "指定された都市の現在の天気を取得する",
"input_schema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "都市名を英語で指定。例) San Francisco, Tokyo.",
},
},
"required": ["location"]
}
}
}
]
model = ChatOpenAI(model="gpt-3.5-turbo-0125").bind(tools=tools)
response = model.invoke("サンフランシスコの天気と気温を教えて")
response.additional_kwargs["tool_calls"]
[{'id': 'call_aOjTvxAyFQgDthpqmZwkKumy',
'function': {'arguments': '{}', 'name': 'get_current_weather'},
'type': 'function'},
{'id': 'call_3jNSjN9WWeAKgtJcHRBbNRKW',
'function': {'arguments': '{"location": "San Francisco", "unit": "celsius"}',
'name': 'get_current_temperature'},
'type': 'function'}]
Lambda: カスタム関数を実行する
パイプラインでは任意の関数を使用することができる。
これらの関数への入力は、すべて単一の引数である必要があることに注意してください。複数の引数を受け取る関数がある場合は、単一の入力を受け取り、それを複数の引数に展開するラッパーを書く必要があります。
RunnableLambdaを使う。
!pip install --upgrade --quiet langchain-core langchain-openai langchain-community
!pip freeze | grep -i langchain
langchain-community==0.0.32
langchain-core==0.1.42
langchain-openai==0.1.3
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
from operator import itemgetter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI
def length_function(text):
""" 単一の文字列の長さを返す """
return len(text)
def _multiple_length_function(text1, text2):
""" 2つの文字列の長さの乗を返す """
return len(text1) * len(text2)
def multiple_length_function(_dict):
""" _multiple_length_functionに渡すためのラッパー """
return _multiple_length_function(_dict["text1"], _dict["text2"])
prompt = ChatPromptTemplate.from_template("{a} + {b} は?")
model = ChatOpenAI()
chain1 = prompt | model
chain = (
{
"a": itemgetter("foo") | RunnableLambda(length_function),
"b": {"text1": itemgetter("foo"), "text2": itemgetter("bar")}
| RunnableLambda(multiple_length_function),
}
| prompt
| model
)
chain.invoke({"foo": "りんご", "bar": "パイナップル"})
AIMessage(content='3 + 18 = 21', response_metadata={'token_usage': {'completion_tokens': 7, 'prompt_tokens': 14, 'total_tokens': 21}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-fac2f053-a913-4e11-9fed-9f244a36e206-0')
んー、例がわかりにくい。。。噛み砕くとこう。
- "foo"の文字列を
RunnableLambdaで指定した関数(length_function)に渡して結果を"a"にアサイン3
- "foo"と"bar"のそれぞれの文字列を
RunnableLambdaで指定した関数(multiple_length_function)に渡して結果を"b"にアサイン-
3 * 6=18
-
- aとbをプロンプトに埋め込んでLLMに渡す(
3 + 18 は?)
なるほど、パイプの中で別のパイプを並列実行してそれぞれマッピングする的な感じか。
RunnableLambdaはオプションでRunnableConfigを受けとって、コールバック、タグ、設定などをネストされたRunnableに渡すことができる。
import json
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda, RunnableConfig
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_community.callbacks import get_openai_callback
def parse_or_fix(text: str, config: RunnableConfig):
fixing_chain = (
ChatPromptTemplate.from_template(
"以下の文章を修正して下さい:\n\n```text\n{input}\n```\nError: {error}"
"説明を入れずに、修正したデータだけを応答して下さい。"
)
| ChatOpenAI()
| StrOutputParser()
)
for _ in range(3):
try:
return json.loads(text)
except Exception as e:
text = fixing_chain.invoke({"input": text, "error": e}, config)
return "Failed to parse"
with get_openai_callback() as cb:
output = RunnableLambda(parse_or_fix).invoke(
"{foo: bar}", {"tags": ["my-tag"], "callbacks": [cb]}
)
print(output)
print(cb)
{'foo': 'bar'}
Tokens Used: 85
Prompt Tokens: 76
Completion Tokens: 9
Successful Requests: 1
Total Cost (USD): $0.000132
んー、ちょっとピンとこない。というか
with get_openai_callback() as cb:
output = RunnableLambda(parse_or_fix).invoke(
"{foo: bar}"
)
print(output)
print(cb)
指定がない場合でも同じ出力になる。
{'foo': 'bar'}
Tokens Used: 85
Prompt Tokens: 76
Completion Tokens: 9
Successful Requests: 1
Total Cost (USD): $0.000132
一応まあこうやると
def parse_or_fix(text: str, config: RunnableConfig):
fixing_chain = (
ChatPromptTemplate.from_template(
"以下の文章を修正して下さい:\n\n```text\n{input}\n```\nError: {error}"
"説明を入れずに、修正したデータだけを応答して下さい。"
)
| ChatOpenAI()
| StrOutputParser()
)
for _ in range(3):
try:
return json.loads(text)
except Exception as e:
print("DEBUG: ", config) # ここ
text = fixing_chain.invoke({"input": text, "error": e}, config)
return "Failed to parse"
普通にわたっているので何かしらコールバックとか使えそうではあるんだけども。
DEBUG: {'tags': ['my-tag'], 'metadata': {}, 'callbacks': <langchain_core.callbacks.manager.CallbackManager object at 0x7e353636a650>, 'recursion_limit': 25}
なんか上の方でもあったけどRunnableConfigがドキュメントのとおりに書いても動いてない気がするなぁ。。。とりあえずスルーする。
ジェネレーターを使った関数をパイプラインで使うこともできる。
まず普通に動物名をリストアップするチェーンを作る
from typing import Iterator, List
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_template(
"Write a comma-separated list of 5 animals similar to: {animal}. Do not include numbers"
"{animal} に似た動物を5つ、カンマ区切りで書いてください。数字は含めないでください。"
)
model = ChatOpenAI(temperature=0.0)
str_chain = prompt | model | StrOutputParser()
stream。わかりやすいように"|"を含めている。
for chunk in str_chain.stream({"animal": "クマ"}):
print(chunk, end="|", flush=True)
|ク|マ|,| パ|ン|ダ|,| シ|ロ|ク|マ|,| ヒ|グ|マ|,| コ|ア|ラ||
invoke
str_chain.invoke({"animal": "クマ"})
クマ, パンダ, シロクマ, コアラ, クマネズミ
これにカンマでsplitするような関数を出力パーサとして追加する。このときの入出力はIterator[Input] -> Iterator[Output]でなけれなばらない。
# LLMトークンのイテレータをカンマで区切られた文字列のリストに
# 分割するカスタムパーサ
def split_into_list(input: Iterator[str]) -> Iterator[List[str]]:
# コンマが入るまで保持
buffer = ""
for chunk in input:
# 現在のチャンクをバッファに追加
buffer += chunk
# バッファにカンマがある間
while "," in buffer:
# コンマでバッファを分割
comma_index = buffer.index(",")
# コンマより前はすべてyieldで返す
yield [buffer[:comma_index].strip()]
# 次回のイテレーションのための残りを保持
buffer = buffer[comma_index + 1 :]
# 最後のチャンクをyieldで返す
yield [buffer.strip()]
list_chain = str_chain | split_into_list
for chunk in list_chain.stream({"animal": "クマ"}):
print(chunk, end="|", flush=True)
['クマ']|['パンダ']|['シロクマ']|['ヒグマ']|['コアラ']|
list_chain.invoke({"animal": "クマ"})
['クマ', 'パンダ', 'シロクマ', 'ヒグマ', 'コアラ']
これの非同期バージョン。非同期の場合はAsyncIterator[Input] -> AsyncIterator[Output]でなければならない。
stream。
async for chunk in list_chain.astream({"animal": "クマ"}):
print(chunk, end="|", flush=True)
['クマ']|['パンダ']|['シロクマ']|['コアラ']|['クマネズミ']|
invoke
await list_chain.ainvoke({"animal": "クマ"})
['クマ', 'パンダ', 'シロクマ', 'ヒグマ', 'コアラ']
Passthrough: 入力をパススルーする
RunnablePassthroughは入力をそのままパススルーする。RunnableParallelで後続のRunnableに新しい変数としてマップする場合に使われることが多い。
!pip install --upgrade --quiet langchain-core langchain-openai langchain-community
!pip freeze | grep -i langchain
langchain-community==0.0.32
langchain-core==0.1.42
langchain-openai==0.1.3
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
runnable = RunnableParallel(
passed=RunnablePassthrough(),
modified=lambda x: x["num"] + 1,
)
runnable.invoke({"num": 1})
{'passed': {'num': 1}, 'modified': 2}
retrievalの例は重複するので割愛。
Assign: 値を状態に追加する
RunnablePassthrough.assign(...)静的メソッドは、入力値を受け取り、assign関数に渡された追加引数を追加します。
これは、LCELの一般的なパターンである、後のステップの入力として使用する辞書を追加的に作成する場合に便利です。
!pip install --upgrade --quiet langchain-core langchain-openai langchain-community faiss-cpu
!pip freeze | grep -i langchain
langchain-community==0.0.32
langchain-core==0.1.42
langchain-openai==0.1.3
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
一つ上のコードのRunnablePassthroughに.assign()メソッドで関数を追加している。
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
runnable = RunnableParallel(
extra=RunnablePassthrough().assign(multi=lambda x: x["num"] * 3),
modified=lambda x: x["num"] + 1,
)
runnable.invoke({"num": 1})
{'extra': {'num': 1, 'multi': 3}, 'modified': 2}
RunnablePassthrough.assign()を使うと、値が利用可能になったらすぐに使えること、らしい。
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
texts = []
texts.append("""\
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬・種牡馬。
主な勝ち鞍は、2022年・2023年の天皇賞(秋)連覇、2022年の有馬記念、2023年のドバイシーマクラシック、宝塚記念、ジャパンカップ。\
""")
texts.append("""\
オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。\
""")
texts.append("""\
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。
主な勝ち鞍は、2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。\
""")
vectorstore = FAISS.from_texts(
texts, embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
template = """\
以下のコンテキストにもとづいて、質問に答えてください:
{context}
質問: {question}
回答: \
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
generation_chain = prompt | model | StrOutputParser()
retrieval_chain = {
"context": retriever,
"question": RunnablePassthrough(),
} | RunnablePassthrough.assign(output=generation_chain)
stream = retrieval_chain.stream("オグリキャップの主な勝ち鞍は?")
for chunk in stream:
print(chunk)
retrievalのドキュメントが一番最初に出力されている。
{'question': 'オグリキャップの主な勝ち鞍は?'}
{'context': [Document(page_content='オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。\n主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。'), Document(page_content='イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬・種牡馬。\n主な勝ち鞍は、2022年・2023年の天皇賞(秋)連覇、2022年の有馬記念、2023年のドバイシーマクラシック、宝塚記念、ジャパンカップ。'), Document(page_content='ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。\n主な勝ち鞍は、2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。')]}
{'output': ''}
{'output': '198'}
{'output': '8'}
{'output': '年'}
{'output': '・'}
{'output': '199'}
{'output': '0'}
{'output': '年'}
{'output': 'の'}
{'output': '有'}
{'output': '馬'}
{'output': '記'}
{'output': '念'}
{'output': '、'}
{'output': '198'}
{'output': '9'}
{'output': '年'}
{'output': 'の'}
{'output': 'マ'}
{'output': 'イ'}
{'output': 'ル'}
{'output': 'チ'}
{'output': 'ャ'}
{'output': 'ン'}
{'output': 'ピ'}
{'output': 'オ'}
{'output': 'ン'}
{'output': 'シ'}
{'output': 'ッ'}
{'output': 'プ'}
{'output': '、'}
{'output': '199'}
{'output': '0'}
{'output': '年'}
{'output': 'の'}
{'output': '安'}
{'output': '田'}
{'output': '記'}
{'output': '念'}
{'output': ''}
なんかユースケースありそうだけど思いつかないな。
追記:以下をやってみてわかった。RunnablePassthroughと組み合わせると出力パラメータを追加するのに使える。
実行時にチェーン内の設定を変更する
-
configurable_fieldsはRunnableの特定のフィールドを設定変更できる。 -
configurable_alternativesは実行時に設定ができるRunnableランナブルのオプションを用意する。
configurable_fields
!pip install --upgrade --quiet langchain-core langchain-openai langchain-anthropic
!pip freeze | grep -i langchain
langchain-anthropic==0.1.8
langchain-core==0.1.42
langchain-openai==0.1.3
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
os.environ['ANTHROPIC_API_KEY'] = userdata.get('ANTHROPIC_API_KEY')
ConfigurableFieldでモデルのtemperatureを設定可能にする。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import ConfigurableField
from langchain_openai import ChatOpenAI
model = ChatOpenAI(temperature=0).configurable_fields(
temperature=ConfigurableField(
id="llm_temperature",
name="LLM Temperature",
description="The temperature of the LLM",
)
)
普通に実行
model.invoke("ランダムな数字を1つ選んで。")
AIMessage(content='9', response_metadata={'token_usage': {'completion_tokens': 1, 'prompt_tokens': 20, 'total_tokens': 21}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-8c9402c8-498a-44f8-bca2-20c4076c9c04-0')
実行時に変更する
model.with_config(configurable={"llm_temperature": 0.9}).invoke("ランダムな数字を1つ選んで。")
AIMessage(content='8', response_metadata={'token_usage': {'completion_tokens': 1, 'prompt_tokens': 20, 'total_tokens': 21}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-599e1b9f-05fc-4a3b-8037-2d149a8295af-0')
チェインに対して設定することでも反映される。
prompt = ChatPromptTemplate.from_template("{x}以上のランダムな数字を1つ選んで。")
chain = prompt | model
chain.with_config(configurable={"llm_temperature": 0.9}).invoke({"x": 10})
AIMessage(content='27', response_metadata={'token_usage': {'completion_tokens': 1, 'prompt_tokens': 23, 'total_tokens': 24}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-9f555d73-61a1-4c0e-8e61-6747ef9743cf-0')
LangChain Hubのプロンプト切り替えとかにはHubRunnablesが使える。
ちょっとパッケージがよくわからないけど、以下が追加で必要。
!pip install --upgrade --quiet langchain langchainhub
from langchain.runnables.hub import HubRunnable
from langchain_core.runnables import ConfigurableField
prompt = HubRunnable("rlm/rag-prompt").configurable_fields(
owner_repo_commit=ConfigurableField(
id="hub_commit",
name="Hub Commit",
description="The Hub commit to pull from",
)
)
prompt.invoke({"question": "foo", "context": "bar"})
ChatPromptValue(messages=[HumanMessage(content="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: foo \nContext: bar \nAnswer:")])
prompt.with_config(configurable={"hub_commit": "rlm/rag-prompt-llama"}).invoke(
{"question": "foo", "context": "bar"}
)
ChatPromptValue(messages=[HumanMessage(content="[INST]<<SYS>> You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.<</SYS>> \nQuestion: foo \nContext: bar \nAnswer: [/INST]")])
configurable_alternatives
ちょっとインポートのところは変更している。
from langchain_core.prompts import ChatPromptTemplate
from langchain_anthropic import ChatAnthropic
from langchain_core.runnables import ConfigurableField
from langchain_openai import ChatOpenAI
llm = ChatAnthropic(model="claude-3-haiku-20240307", temperature=0).configurable_alternatives(
# これはこのフィールドにidを与える。
# 一番最後のRunnableを設定するとき、このidを使ってこのフィールドを設定することができる
ConfigurableField(id="llm"),
# これはデフォルトキーをセットする
# このキーを指定すると、デフォルトのLLM(上で初期化されたChatAnthropic)が使われる
default_key="anthropic",
# これは新しいオプションを追加する。`openai`という名前で`ChatOpenAI()`になる
openai=ChatOpenAI(),
# これは新しいオプションを追加する。`gpt`という名前で`ChatOpenAI(model="gpt-4")`になる
gpt4=ChatOpenAI(model="gpt-4"),
# 更にオプションを追加できる
)
prompt = ChatPromptTemplate.from_template("{topic}についてのジョークを1つ考えて。")
chain = prompt | llm
何も指定しなければデフォルト(claude-3-haiku)
chain.invoke({"topic": "クマ"})
AIMessage(content='はい、クマについてのジョークを考えてみました。\n\nクマが森の中を歩いていると、ウサギに出会いました。\nクマは尋ねました。「ウサギさん、この森の中で一番面白いジョークを教えてください。」\nウサギは答えました。「クマさん、あなたがちょうど今立っているところが一番面白いジョークです!」\n\nクマは少し困惑しながらも、ウサギのジョークを面白いと感じたそうです。クマはウサギの機知に富んだユーモアに感心したのでした。', response_metadata={'id': 'msg_018i1czJUTmny3qgZjX3tysr', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 23, 'output_tokens': 183}}, id='run-2d7ddb9c-9629-4e91-b966-3c096352d161-0')
"openai" = ChatOpenAI()
chain.with_config(configurable={"llm": "openai"}).invoke({"topic": "クマ"})
AIMessage(content='クマがお風呂に入るとどうなるか知ってる?\u3000クマだらけのお湯風呂になるんだよ!', response_metadata={'token_usage': {'completion_tokens': 42, 'prompt_tokens': 25, 'total_tokens': 67}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-e5918663-3f0c-4079-bba6-94fb5fdbec88-0')
"gpt4" = ChatOpenAI(model="gpt-4")
chain.with_config(configurable={"llm": "gpt4"}).invoke({"topic": "クマ"})
AIMessage(content='どうしてクマはコンピューターが苦手なの?\n\nキーボードを押すと、いつも"ベア"が出てしまうからだよ!(Bearは英語でクマの意味)', response_metadata={'token_usage': {'completion_tokens': 62, 'prompt_tokens': 25, 'total_tokens': 87}, 'model_name': 'gpt-4', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-8a60c2ac-7c9b-46d8-ba0a-72ad4400acb5-0')
同じようにプロンプトでもやってみる。
llm = ChatAnthropic(model="claude-3-haiku-20240307", temperature=0)
prompt = ChatPromptTemplate.from_template(
"{topic}についてのジョークを1つ考えて。"
).configurable_alternatives(
ConfigurableField(id="prompt"),
default_key="joke",
poem=ChatPromptTemplate.from_template("{topic}についての短い詩を1つ考えて。"),
)
chain = prompt | llm
chain.invoke({"topic": "クマ"})
AIMessage(content='はい、クマについてのジョークを考えてみました。\n\nクマが森の中を歩いていると、ウサギに出会いました。\nクマは尋ねました。「ウサギさん、この森の中で一番面白いジョークを教えてください。」\nウサギは答えました。「はい、分かりました。クマさん、クマさんはなぜ木の上に登るのですか?」\nクマは考えて言いました。「それは、木の上から落ちるのが怖いからですよ。」\nウサギは笑いながら言いました。「違います。クマさんは木の上に登るのが怖いからですよ!」\n\nクマは少し恥ずかしそうでしたが、ウサギのジョークを面白いと思いました。\nクマとウサギは森の中で楽しく過ごしたのでした。', response_metadata={'id': 'msg_01MW8cgK1kHv9CKwaw9E9D4E', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 23, 'output_tokens': 263}}, id='run-d7e5d86b-687f-415d-a9ad-72b2bd3855f3-0')
chain.with_config(configurable={"prompt": "poem"}).invoke({"topic": "クマ"})
AIMessage(content='クマの詩\n\n大きな体に優しい瞳\n森の中で静かに歩む\n木の実を探し食べては\n冬眠の準備をする\n\n力強く、でも穏やかな\n自然の一部であるクマ\n人間に脅かされながらも\n大切な生き物なのだ', response_metadata={'id': 'msg_01Y3iLQSzzqpQZWXxKVpxpet', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 23, 'output_tokens': 96}}, id='run-84c97b70-b22f-4add-b43b-5109e7e79e2f-0')
両方組み合わせる
from langchain_core.prompts import ChatPromptTemplate
from langchain_anthropic import ChatAnthropic
from langchain_core.runnables import ConfigurableField
from langchain_openai import ChatOpenAI
llm = ChatAnthropic(model="claude-3-haiku-20240307", temperature=0).configurable_alternatives(
ConfigurableField(id="llm"),
default_key="anthropic",
openai=ChatOpenAI(),
gpt4=ChatOpenAI(model="gpt-4"),
)
prompt = ChatPromptTemplate.from_template(
"{topic}についてのジョークを1つ考えて。"
).configurable_alternatives(
ConfigurableField(id="prompt"),
default_key="joke",
poem=ChatPromptTemplate.from_template("{topic}についての短い詩を1つ考えて。"),
)
chain = prompt | llm
chain.invoke({"topic": "クマ"})
AIMessage(content='はい、クマについてのジョークを考えてみました。\n\nクマが森の中を歩いていると、ウサギに出会いました。\nクマは尋ねました。「ウサギさん、この森の中で一番速いのは誰ですか?」\nウサギは答えました。「もちろんわたしですよ!」\nすると、クマは言いました。「じゃあ、一緒に走ってみましょう!」\nウサギは喜んで走り出しましたが、すぐにクマに追いつかれてしまいました。\nクマは満足そうに言いました。「やっぱり、クマが一番速いんだね。」\n\nいかがでしょうか。クマの特徴を活かしたジョークになっていると思います。クマの力強さと、ウサギの速さのギャップが面白いポイントになっています。', response_metadata={'id': 'msg_011rUxXsGRxXc5MoTPNogKgY', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 23, 'output_tokens': 264}}, id='run-34b57172-a4d8-40a9-af4e-4c764d8c86a9-0')
chain.with_config(configurable={"llm": "openai", "prompt": "poem"}).invoke({"topic": "クマ"})
AIMessage(content='森の中に\nふわふわと歩く\nやさしいクマ', response_metadata={'token_usage': {'completion_tokens': 23, 'prompt_tokens': 27, 'total_tokens': 50}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-251d0ea2-c684-449d-8488-07cb8a69fc32-0')
オブジェクトとして設定付きで保持できる。
openai_poem = chain.with_config(configurable={"llm": "openai", "prompt": "poem"})
openai_poem.invoke({"topic": "クマ"})
AIMessage(content=' 森の中に\u3000クマが住む\u3000大きな力\u3000心温かく', response_metadata={'token_usage': {'completion_tokens': 25, 'prompt_tokens': 27, 'total_tokens': 52}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None}, id='run-a9d25e18-3d9d-4777-a7e2-be29cc673efd-0')
Streaming
ここはこれまで繰り返してきた内容がカバーされてそうなので、とりまスキップ。
Adding message history(memory)
ここざっと見てみたのだけど、ちょっとむずい。というか、まずLangChainの旧来のメモリの扱い方を先にやったほうがいい気がしてきた。
ということで、一旦LCELから離れて、これまでのやり方を少し確認してから戻ることにする
メモリについては以下の前提がまず重要と感じる。
LangChainは、システムにメモリを追加するための多くのユーティリティを提供しています。 これらのユーティリティは、単独で使用することも、チェーンにシームレスに組み込むこともできます。
LangChainのメモリ関連機能のほとんどはベータ版としてマークされています。これには2つの理由があります:
- ほとんどの機能(例外あり、詳細は以下)は、本番環境での利用には準備が整っていない。
- ほとんどの機能(例外あり、詳細は以下)は、新しいLCEL構文ではなく、"レガシー"なチェーンで動作する。
主な例外は
ChatMessageHistory機能です。この機能は、本番環境での利用が可能で、LCELと統合されています。
- LCEL Runnables:LCEL runnables で
ChatMessageHistoryを使用する方法の概要についてはこのドキュメントを参照してください。- インテグレーション:ChatMessageHistoryの様々なインテグレーションについてはこのドキュメントを参照してください。
ということで、LCELで使うならば、基本的にはChatMessageHistoryだけを見ておけば良さそうではあるものの、一応レガシーなメモリ関連モジュールにあってLCEL対応のChatMessageHistoryにはないもの、を抑えておく意味で、非LCELでサラッと流してみる。
基本的な仕組み

- ユーザの入力を受けて、メモリから過去の会話履歴を読み込んで、セットでプロンプトに渡してから、LLMに渡す
- LLMの出力結果を受けて、メモリに今回の会話ターン(ユーザクエリ+LLMの回答)を記録する
よって、メモリに最低限必要な機能は以下の2つだけとなる。
- メモリの読み出し
- メモリへの書き込み
これらがメモリ機能の基本的なインタフェースになる。
その他に関連するところで、
- メモリストレージのインテグレーション
- 揮発的なオンメモリか、永続ストレージか
- ストレージはいろいろ
- メモリのデータ構造とアルゴリズム
- 最もシンプルなのは、会話のやり取りを延々と保存していくものだけど、考慮すべき点は色々でてくる
- 履歴は長くなる一方。多すぎると入力トークンに収まらない・履歴はどんどん増える
- 入力トークン制限に収めるための工夫が必要になる。削る/絞る/圧縮する等
- 会話以外に保持したいものはある?
- 例えばretrievalの情報とか。メタデータ的に保持させるとかエンティティ抽出とか。
- 履歴は長くなる一方。多すぎると入力トークンに収まらない・履歴はどんどん増える
- 最もシンプルなのは、会話のやり取りを延々と保存していくものだけど、考慮すべき点は色々でてくる
など。このあたりを抽象化したモジュールが多数ある。
Get Started
まずはLangChainで最もシンプルなConversationBufferMemoryを使う。
!pip install --upgrade --quiet langchain langchain-core langchain-openai
!pip freeze | grep -i langchain
langchain==0.1.16
langchain-community==0.0.32
langchain-core==0.1.42
langchain-openai==0.1.3
langchain-text-splitters==0.0.1
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
ConversationBufferMemoryを初期化して、これにユーザからの入力+LLMからの応答を追加する。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("こんにちは!")
memory.chat_memory.add_ai_message("やあ、元気かい?")
メモリを参照する。空の辞書を渡しているけど、ここはメモリモジュールによって変わってくるらしい。
memory.load_memory_variables({})
{'history': 'Human: こんにちは!\nAI: やあ、元気かい?'}
デフォルトだとhistoryというキーに会話履歴が含まれている。これを明示的に指定するにはmemory_keyで指定する。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history")
memory.chat_memory.add_user_message("こんにちは!")
memory.chat_memory.add_ai_message("やあ、元気かい?")
memory.load_memory_variables({})
{'chat_history': 'Human: こんにちは!\nAI: やあ、元気かい?'}
上記では会話履歴は文字列で出力されているが、実際にはリストとして取得できる。return_messages=Trueを付与する。
memory = ConversationBufferMemory(return_messages=True)
memory.chat_memory.add_user_message("こんにちは!")
memory.chat_memory.add_ai_message("やあ、元気かい?")
memory.load_memory_variables({})
{'history': [HumanMessage(content='こんにちは!'), AIMessage(content='やあ、元気かい?')]}
ではプロンプト、LLMと組み合わせてみる。completionモデルの例。
from langchain_openai import OpenAI
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0) # gpt-3.5-turbo-instrct
template = """\
あなたは人間と会話をするチャットボットです。
これまでの会話:
{chat_history}
新しい人間の入力: {human_input}
回答: \
"""
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
なるほど、LLMChainでメモリを指定していれば、そのメモリのキーをプロンプトから参照できると。
print(conversation.predict(human_input="こんにちは。私の趣味は競馬です。"))
> Entering new LLMChain chain...
Prompt after formatting:
あなたは人間と会話をするチャットボットです。
これまでの会話:
新しい人間の入力: こんにちは。私の趣味は競馬です。
回答:
> Finished chain.
それは面白そうですね。競馬に詳しいですか?
print(conversation.predict(human_input="あれ、私の趣味ってなんでしたっけ?"))
> Entering new LLMChain chain...
Prompt after formatting:
あなたは人間と会話をするチャットボットです。
これまでの会話:
Human: こんにちは。私の趣味は競馬です。
AI: それは面白そうですね。競馬に詳しいですか?
新しい人間の入力: あれ、私の趣味ってなんでしたっけ?
回答:
> Finished chain.
あなたの趣味は競馬ですね。私はあなたの趣味を覚えています。
ちゃんと前回から会話がつながっているのがわかる。メモリを直接見てみる。
print(memory.load_memory_variables({}))
{'chat_history': 'Human: こんにちは。私の趣味は競馬です。\nAI: それは面白そうですね。競馬に詳しいですか?\nHuman: あれ、私の趣味ってなんでしたっけ?\nAI: あなたの趣味は競馬ですね。私はあなたの趣味を覚えています。'}
これまでのやりとりがメモリに記録されているのもわかる。
Chatモデルを使った場合。
from langchain_openai import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI() # gpt-3.5-turbo
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"あなたは人間と会話をするチャットボットです。"
),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
chatモデルの場合、MessagesPlaceholderでメモリーが割り当てられているインスタンスのキーをそのまま変数で指定すれば埋め込めるみたい。
conversation({"question":"こんにちは。私の趣味は競馬です。"})
> Entering new LLMChain chain...
Prompt after formatting:
System: あなたは人間と会話をするチャットボットです。
Human: こんにちは。私の趣味は競馬です。
> Finished chain.
{'question': 'こんにちは。私の趣味は競馬です。',
'chat_history': [HumanMessage(content='こんにちは。私の趣味は競馬です。'),
AIMessage(content='こんにちは!競馬は面白い趣味ですね。競馬で好きな競走馬やレースはありますか?')],
'text': 'こんにちは!競馬は面白い趣味ですね。競馬で好きな競走馬やレースはありますか?'}
conversation({"question":"あれ、私の趣味って何でしたっけ?"})
> Entering new LLMChain chain...
Prompt after formatting:
System: あなたは人間と会話をするチャットボットです。
Human: こんにちは。私の趣味は競馬です。
AI: こんにちは!競馬は面白い趣味ですね。競馬で好きな競走馬やレースはありますか?
Human: あれ、私の趣味って何でしたっけ?
> Finished chain.
{'question': 'あれ、私の趣味って何でしたっけ?',
'chat_history': [HumanMessage(content='こんにちは。私の趣味は競馬です。'),
AIMessage(content='こんにちは!競馬は面白い趣味ですね。競馬で好きな競走馬やレースはありますか?'),
HumanMessage(content='あれ、私の趣味って何でしたっけ?'),
AIMessage(content='あなたの趣味は競馬だとおっしゃいましたよ。競馬についてお話しするのはいかがですか?')],
'text': 'あなたの趣味は競馬だとおっしゃいましたよ。競馬についてお話しするのはいかがですか?'}
ChatMessageHistory
先ほど上にも書いてあったけど、LCELに商用レベルで対応しているモジュールらしい。
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("こんにちはー")
history.add_ai_message("やあ、元気かい?")
history.add_user_message("また競馬で負けちゃったよ・・・")
history.add_ai_message("あー、それは残念だね。そういう日もあるさ。")
history.messages
[HumanMessage(content='こんにちはー'),
AIMessage(content='やあ、元気かい?'),
HumanMessage(content='また競馬で負けちゃったよ・・・'),
AIMessage(content='あー、それは残念だね。そういう日もあるさ。')]
LLMChain
LCELよりも前のレガシーな使い方。ここはGet Startedと同じなのでスキップ。
Memory in the Multi-Input Chain
ここまでの例では、メモリに入っていたの個々のやりとり、例えば、ユーザの入力だったり、LLMのレスポンスだったり、すなわち、1つのオブジェクトだけを受け取る形になっていた。
複数の入力を受け取る場合、例えばRAGのように、ユーザのクエリ・クエリから検索したドキュメント、のような複数の入力があった場合の例。
まずドキュメントを用意。
from pathlib import Path
import requests
import re
def replace_heading(match):
level = len(match.group(1))
return '#' * level + ' ' + match.group(2).strip()
wiki_titles = ["オグリキャップ"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
#wiki_text = f"# {title}\n\n## 概要\n\n"
wiki_text = ""
wiki_text += page["extract"]
wiki_text = re.sub(r"(=+)([^=]+)\1", replace_heading, wiki_text)
wiki_text = re.sub(r"\t+", "", wiki_text)
wiki_text = re.sub(r"\n{3,}", "\n\n", wiki_text)
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
ベクトルDBにはChromaを使う。
!pip install --upgrade --quiet langchain langchain-core langchain-openai langchain-chroma chromadb
!pip freeze | grep -i langchain
langchain==0.1.16
langchain-chroma==0.1.0
langchain-community==0.0.32
langchain-core==0.1.42
langchain-openai==0.1.3
langchain-text-splitters==0.0.1
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
ベクトルDBへドキュメントを登録して検索できるところまで。
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
with open("data/オグリキャップ.txt") as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=400, chunk_overlap=100)
texts = text_splitter.split_text(state_of_the_union)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(
texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))]
)
query = "オグリキャップの血統について教えて。"
docs = docsearch.similarity_search(query)
docs[0]
Document(page_content='オグリキャップが人気を得た要因についてライターの市丸博司は、「地方出身の三流血統馬が中央のエリートたちをナデ斬りにし、トラブルや過酷なローテーションの中で名勝負を数々演じ、二度の挫折を克服」したことにあるとし、オグリキャップは「ファンの記憶の中でだけ、本当の姿で生き続けている」「競馬ファンにもたらした感動は、恐らく同時代を過ごした者にしか理解できないものだろう」と述べ、山河拓也も市丸と同趣旨の見解を示している。斎藤修は、日本人が好む「田舎から裸一貫で出てきて都会で名をあげる」という立身出世物語に当てはまったことに加え、クラシックに出走することができないという挫折や、タマモクロス、イナリワン、スーパークリークというライバルとの対決がファンの共感を得たのだと分析している。お笑い芸人の明石家さんまは雑誌『サラブレッドグランプリ』のインタビューにおいて、オグリキャップについて「マル地馬で血統も良', metadata={'source': 111})
今回はload_qa_chainを使う。
from langchain.chains.question_answering import load_qa_chain
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI
template = """
あなたは人間と会話するチャットボットです。
与えられた長い文書の一部抜粋と質問だけを踏まえて、最終的な回答を作成してください。
与えられた文書に根拠が記載されてない場合、架空の回答を作成せずに、わからないと答えて下さい。
{context}
{chat_history}
Human: {human_input}
Chatbot:"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input", "context"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain(
OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt
)
クエリを投げる。
query = "オグリキャップの血統について教えて。"
chain({"input_documents": docs, "human_input": query}, return_only_outputs=True)
{'output_text': ' オグリキャップの父はダンシングキャップで、母はホワイトナルビーです。ダンシングキャップは種牡馬としてはあまり優れていませんでしたが、ネイティヴダンサー系の種牡馬は時々大物を出すことがあり、オグリキャップもそのような血統を受け継いでいると言われています。また、オグリキャップの母の一族には重賞勝ち馬が多く、血統的にも優れていると言えるでしょう。'}
print(memory.load_memory_variables({}))
{'chat_history': 'Human: オグリキャップの血統について教えて。\nAI: オグリキャップの父はダンシングキャップで、種牡馬としてはあまり優れていませんでした。そのため、オグリキャップは「突然変異で生まれた」または「ネイティヴダンサーの隔世遺伝で生まれた競走馬」と主張されています。しかし、血統評論家の山野浩一氏はダンシングキャップを「一発ある血統」と評価し、ネイティヴダンサー系の種牡馬は時々大物を出すことがあるため、オグリキャップに関してもそういう可能性があると分析しています。また、母のホワイトナルビーは現役時代に4勝を挙げ、産'}
Memory in Agent
Agentは今の自分のスコープにはないのでパス。
Message Memory in Agent backed by a database
Agentは今の自分のスコープにはないのでパス。
Customizing Conversational Memory
メモリを文字列化してみると以下のようになっていたと思う。
{'chat_history': 'Human: こんにちは。私の趣味は競馬です。\nAI: それは面白そうですね。競馬に詳しいですか?\nHuman: あれ、私の趣味ってなんでしたっけ?\nAI: あなたの趣味は競馬ですね。私はあなたの趣味を覚えています。'}
ユーザの入力にはHuman、LLMの出力にはAIというプレフィクスがついている。これを変更することができる。
!pip install --upgrade --quiet langchain langchain-core langchain-openai
!pip freeze | grep -i langchain
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain_openai import OpenAI
llm = OpenAI(temperature=0)
conversation = ConversationChain(
llm=llm, verbose=True, memory=ConversationBufferMemory()
)
conversation.predict(input="こんにちは!")
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: こんにちは!
AI:
> Finished chain.
こんにちは!私はAIです。私は人間のように話すことができますが、私は人間ではありません。私はコンピュータープログラムです。どのようにお手伝いしましょうか?
これを変更するにはConversationBufferMemoryにai_prefix/human_prefixというパラメータを付与する
from langchain.prompts.prompt import PromptTemplate
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain_openai import OpenAI
llm = OpenAI(temperature=0)
template = """\
以下は人間とAIのフレンドリーな会話です。AIは、饒舌で、文脈から具体的な詳細をたくさん話します。
AIは、質問の答えを知らない場合、正直に「知らない」と答えます。
人間からの入力に対して回答を生成して下さい。
現在の会話:
{history}
人間: {input}
AIアシスタント: """
PROMPT = PromptTemplate(input_variables=["history", "input"], template=template)
memory = ConversationBufferMemory(ai_prefix="AIアシスタント", human_prefix="人間")
conversation = ConversationChain(
prompt=PROMPT,
llm=llm,
verbose=True,
memory=memory,
)
conversation.predict(input="こんにちは!")
> Entering new ConversationChain chain...
Prompt after formatting:
以下は人間とAIのフレンドリーな会話です。AIは、饒舌で、文脈から具体的な詳細をたくさん話します。
AIは、質問の答えを知らない場合、正直に「知らない」と答えます。
人間からの入力に対して回答を生成して下さい。
現在の会話:
人間: こんにちは!
AIアシスタント:
> Finished chain.
こんにちは!私はAIアシスタントです。どのようにお手伝いしましょうか?
メモリを見てみる。
print(memory.load_memory_variables({}))
{'history': '人間: こんにちは!\nAIアシスタント: こんにちは!私はAIアシスタントです。どのようにお手伝いしましょうか?'}
ただしまるっと置き換わっているわけではなくて、
memory
ConversationBufferMemory(chat_memory=ChatMessageHistory(messages=[HumanMessage(content='こんにちは!'), AIMessage(content='こんにちは!私はAIアシスタントです。どのようにお手伝いしましょうか?')]), human_prefix='人間', ai_prefix='AIアシスタント')
基本的にはHumanMessage/AIMessageオブジェクトはそのままで、出力時のエイリアス的なものが持たされているという感じぽい。
何が嬉しいのかなーと思ったけど、おそらくプロンプトに会話履歴を文字列で埋め込む場合に使うのだろうと思う。completionモデルだと使うことがある、か、も、しれないけど、chatモデルだとあんまり意味がなさそうな気がしている。
Custom Memory
自分でメモリを作成することもできる。ここはちょっとやってみたけど、metaclass conflictエラーが出る。どうやらLangChainのBaseModelがpydantic v2に対応していない?ということっぽい。一応回避策はできたのだけど、単純日本語化すればいいというものでもないのかな、spaCy全然わかってない。
ということでスキップする。
Multiple Memory classes
複数のメモリクラスを同じチェーンで使う。複数のメモリクラスを1つにまとめるCombinedMemoryを使って、これまで使ってきたConversationBufferMemoryと、要約を行うConversationSummaryMemoryを1つにまとめる。
!pip install --upgrade --quiet langchain langchain-core langchain-openai
!pip freeze | grep -i langchain
langchain==0.1.16
langchain-community==0.0.32
langchain-core==0.1.42
langchain-openai==0.1.3
langchain-text-splitters==0.0.1
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
from langchain.chains import ConversationChain
from langchain.memory import (
CombinedMemory,
ConversationBufferMemory,
ConversationSummaryMemory,
)
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI
conversation_memory = ConversationBufferMemory(
memory_key="chat_history_lines", input_key="input"
)
summary_memory = ConversationSummaryMemory(llm=OpenAI(), input_key="input")
# conversation_memoryとsummary_memoryを結合
memory = CombinedMemory(memories=[conversation_memory, summary_memory])
_DEFAULT_TEMPLATE = """\
以下は人間とAIのフレンドリーな会話です。AIは、饒舌で、文脈から具体的な詳細をたくさん話します。
AIは、質問の答えを知らない場合、正直に「知らない」と答えます。
人間からの入力に対して回答を生成して下さい。
会話の要約:
{history}
原罪の会話:
{chat_history_lines}
Human: {input}
AI:"""
PROMPT = PromptTemplate(
input_variables=["history", "input", "chat_history_lines"],
template=_DEFAULT_TEMPLATE,
)
llm = OpenAI(temperature=0)
conversation = ConversationChain(llm=llm, verbose=True, memory=memory, prompt=PROMPT)
ではクエリ
conversation.run("こんにちは!")
> Entering new ConversationChain chain...
Prompt after formatting:
以下は人間とAIのフレンドリーな会話です。AIは、饒舌で、文脈から具体的な詳細をたくさん話します。
AIは、質問の答えを知らない場合、正直に「知らない」と答えます。
人間からの入力に対して回答を生成して下さい。
会話の要約:
原罪の会話:
Human: こんにちは!
AI:
> Finished chain.
こんにちは!元気ですか?私はAIです。どんなお話がしたいですか?
conversation.run("そういえば昨日は、競馬で皐月賞が行われたんですよ。")
> Entering new ConversationChain chain...
Prompt after formatting:
以下は人間とAIのフレンドリーな会話です。AIは、饒舌で、文脈から具体的な詳細をたくさん話します。
AIは、質問の答えを知らない場合、正直に「知らない」と答えます。
人間からの入力に対して回答を生成して下さい。
会話の要約:
The human greets the AI in Japanese and the AI responds with a greeting in Japanese. The AI introduces itself as an AI and asks what the human would like to talk about.
原罪の会話:
Human: こんにちは!
AI: こんにちは!元気ですか?私はAIです。どんなお話がしたいですか?
Human: そういえば昨日は、競馬で皐月賞が行われたんですよ。
AI:
> Finished chain.
本当ですか?私は競馬については詳しくありませんが、皐月賞というのはどのようなレースなのでしょうか?
プロンプトの中に会話履歴が2つ記載されているのがわかる。
conversation.run("皐月賞は3歳牡馬のクラシックレースの第1冠ですね。")
> Entering new ConversationChain chain...
Prompt after formatting:
以下は人間とAIのフレンドリーな会話です。AIは、饒舌で、文脈から具体的な詳細をたくさん話します。
AIは、質問の答えを知らない場合、正直に「知らない」と答えます。
人間からの入力に対して回答を生成して下さい。
会話の要約:
The human greets the AI in Japanese and the AI responds with a greeting in Japanese. The AI introduces itself as an AI and asks what the human would like to talk about. The human mentions the recent horse race, "Satsuki Sho", and the AI expresses interest in learning more about it.
原罪の会話:
Human: こんにちは!
AI: こんにちは!元気ですか?私はAIです。どんなお話がしたいですか?
Human: そういえば昨日は、競馬で皐月賞が行われたんですよ。
AI: 本当ですか?私は競馬については詳しくありませんが、皐月賞というのはどのようなレースなのでしょうか?
Human: 皐月賞は3歳牡馬のクラシックレースの第1冠ですね。
AI:
> Finished chain.
なるほど、興味深いですね。3歳牡馬のレースということですね。どのような馬が優勝したのでしょうか?
Types
メモリクラスはいくつかの種類がある。紹介されているものは以下。
- Conversation Buffer
- Conversation Buffer Window
- Entity
- Conversation Knowledge Graph
- Conversation Summary
- Conversation Summary Buffer
- Conversation Token Buffer
- Backed by a Vector Store
さらっと順に見ていく。
Conversation Buffer
これはここまでいろいろ触れてきたのでスキップ
Conversation Buffer Window
ConversationBufferWindowMemoryは直近k件の会話履歴だけを保持するというもの。入力コンテキストサイズの制限等がある場合に有用。
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k=2)
memory.save_context(
{"input": "こんにちは!"},
{"output": "こんにちは!元気ですか?私はAIです。どんなお話がしたいですか?"}
)
memory.save_context(
{"input": "そういえば昨日は、競馬で皐月賞が行われたんですよ。"},
{"output": "本当ですか?私は競馬については詳しくありませんが、皐月賞というのはどのようなレースなのでしょうか?"}
)
memory.save_context(
{"input": "皐月賞は3歳牡馬のクラシックレースの第1冠ですね。"},
{"output": "なるほど、興味深いですね。3歳牡馬のレースということですね。どのような馬が優勝したのでしょうか?"}
)
memory.save_context(
{"input": "優勝したのはジャスティンミラノですね。ハイペース追走経験がないので危険な人気馬かと思ってましたが、強かったです。"},
{"output": "ジャスティンミラノですね。興味深いです。ハイペース追走経験がないのに勝ったということですね。どのような特徴を持っているのでしょうか?"}
)
memory.load_memory_variables({})
{'history': 'Human: 皐月賞は3歳牡馬のクラシックレースの第1冠ですね。\nAI: なるほど、興味深いですね。3歳牡馬のレースということですね。どのような馬が優勝したのでしょうか?\nHuman: 優勝したのはジャスティンミラノですね。ハイペース追走経験がないので危険な人気馬かと思ってましたが、強かったです。\nAI: ジャスティンミラノですね。興味深いです。ハイペース追走経験がないのに勝ったということですね。どのような特徴を持っているのでしょうか?'}
最後の2件だけが保持されている。
Entity
ConversationEntityMemoryは会話中の特定のエンティティをLLMを使って抽出し記憶する。
from langchain_openai import OpenAI
from langchain.memory import ConversationEntityMemory
llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm)
_input = {"input": "先日の皐月賞はジャスティンミラノが1着でした。2着はコスモキュランダでした。"}
memory.load_memory_variables(_input)
エンティティが抽出されるのがわかる。ただしこの状態ではまだ保存されていないのだと思う。
{'history': '', 'entities': {'皐月賞': '', 'ジャスティンミラノ': '', 'コスモキュランダ': ''}}
入出力を含めて保存する。
memory.save_context(
_input,
{"output": "素晴らしいレースでしたね!ジャスティンミラノはどんな勝ち方でしたか?"}
)
再度メモリ経由で聞いてみる。
memory.load_memory_variables({"input": 'ジャスティンミラノとは?'})
{'history': 'Human: 先日の皐月賞はジャスティンミラノが1着でした。2着はコスモキュランダでした。\nAI: 素晴らしいレースでしたね!ジャスティンミラノはどんな勝ち方でしたか?',
'entities': {'ジャスティンミラノ': 'ジャスティンミラノは先日の皐月賞で1着になりました。'}}
Conversation Knowledge Graph
ナレッジグラフを使ったメモリ
from langchain.memory import ConversationKGMemory
from langchain_openai import OpenAI
llm = OpenAI(temperature=0)
memory = ConversationKGMemory(llm=llm)
memory.save_context({"input": "昨日は、競馬で皐月賞が行われたんですよ。"}, {"output": "私は競馬については詳しくありませんが、皐月賞というのはどのようなレースなのでしょうか?"})
memory.save_context({"input": "皐月賞は3歳牡馬のクラシックレースの第1冠ですね。"}, {"output": "興味深いですね。3歳牡馬のレースということですね。どのような馬が優勝したのでしょうか?"})
memory.save_context({"input": "優勝したのはジャスティンミラノですね。"}, {"output": "ジャスティンミラノですね。興味深いです。2着はどの馬だったのでしょうか?"})
memory.save_context({"input": "コスモキュランダは2着ですね。惜しかったです。"}, {"output": "そうなんですね。コスモキュランダは残念でしたね。"})
memory.load_memory_variables({"input": "皐月賞とは?"})
{'history': 'On 皐月賞: 皐月賞 is the first crown of 3歳牡馬のクラシックレース.'}
memory.load_memory_variables({"input": "ジャスティンミラノの着順は?"})
{'history': 'On ジャスティンミラノ: ジャスティンミラノ is the winner of 皐月賞.'}
文章のどこがエンティティになっているかを確認
memory.get_current_entities("ジャスティンミラノの着順は?")
['ジャスティンミラノ']
memory.get_knowledge_triplets("ジャスティンミラノの皐月賞の結果は?")
[KnowledgeTriple(subject='ジャスティンミラノ', predicate='is the winner of', object_='皐月賞'),
KnowledgeTriple(subject='コスモキュランダ', predicate='is the runner-up of', object_='皐月賞')]
Conversation Summary
上で少し出てきたけど、ConversationSummaryMemoryは会話履歴から要約を生成する
from langchain.memory import ConversationSummaryMemory, ChatMessageHistory
from langchain_openai import OpenAI
llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context(
{"input": "こんにちは!"},
{"output": "こんにちは!元気ですか?私はAIです。どんなお話がしたいですか?"}
)
memory.load_memory_variables({})
{'history': '\nThe human greets the AI in Japanese and the AI responds in kind, asking what the human would like to talk about.'}
from langchain.memory import ConversationSummaryMemory, ChatMessageHistory
from langchain_openai import OpenAI
llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context(
{"input": "こんにちは!"},
{"output": "こんにちは!元気ですか?私はAIです。どんなお話がしたいですか?"}
)
memory.save_context(
{"input": "そういえば昨日は、競馬で皐月賞が行われたんですよ。"},
{"output": "本当ですか?私は競馬については詳しくありませんが、皐月賞というのはどのようなレースなのでしょうか?"}
)
memory.save_context(
{"input": "皐月賞は3歳牡馬のクラシックレースの第1冠ですね。"},
{"output": "なるほど、興味深いですね。3歳牡馬のレースということですね。どのような馬が優勝したのでしょうか?"}
)
memory.save_context(
{"input": "優勝したのはジャスティンミラノですね。ハイペース追走経験がないので危険な人気馬かと思ってましたが、強かったです。"},
{"output": "ジャスティンミラノですね。興味深いです。ハイペース追走経験がないのに勝ったということですね。どのような特徴を持っているのでしょうか?"}
)
memory.load_memory_variables({})
{'history': '\nThe human greets the AI in Japanese and the AI responds in kind, asking what the human would like to talk about. The human mentions the recent horse race, the "Satsuki Sho," and the AI admits to not being knowledgeable about horse racing and asks for more information about the race. The human explains that the Satsuki Sho is the first crown of the classic race for 3-year-old male horses. The AI finds it interesting and asks about the winning horse, Justin Milano, and its unique characteristics that allowed it to win despite not having experience with high-paced races.'}
completionモデルのプロンプトならいいんだろうけど、chatモデルだとどうするのがいいかなー、Userメッセージでも別にいいんだろうけど、なんとなくSystemの一番最後に付与するのが良さそうな気がする。
Conversation Summary Buffer
ConversationSummaryMemoryと同じく、会話履歴から要約を生成するのだけど、古いものから一定のトークンで要約するというもの。一番使いやすそう。
from langchain.memory import ConversationSummaryBufferMemory
from langchain_openai import OpenAI
llm = OpenAI()
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=200)
memory.save_context(
{"input": "こんにちは!"},
{"output": "こんにちは!元気ですか?私はAIです。どんなお話がしたいですか?"}
)
memory.save_context(
{"input": "そういえば昨日は、競馬で皐月賞が行われたんですよ。"},
{"output": "本当ですか?私は競馬については詳しくありませんが、皐月賞というのはどのようなレースなのでしょうか?"}
)
memory.save_context(
{"input": "皐月賞は3歳牡馬のクラシックレースの第1冠ですね。"},
{"output": "なるほど、興味深いですね。3歳牡馬のレースということですね。どのような馬が優勝したのでしょうか?"}
)
memory.save_context(
{"input": "優勝したのはジャスティンミラノですね。ハイペース追走経験がないので危険な人気馬かと思ってましたが、強かったです。"},
{"output": "ジャスティンミラノですね。興味深いです。ハイペース追走経験がないのに勝ったということですね。どのような特徴を持っているのでしょうか?"}
)
memory.load_memory_variables({})
{'history': "System: \nThe human greets the AI in Japanese and the AI responds in Japanese, asking how the human is and introducing itself as an AI. The AI also asks what the human would like to talk about. The human brings up yesterday's horse race, the Sakurazaka Sho, and explains that it is the first crown in the Triple Crown for 3-year-old colts. The AI expresses interest and asks for more information about the winning horse.\nHuman: 優勝したのはジャスティンミラノですね。ハイペース追走経験がないので危険な人気馬かと思ってましたが、強かったです。\nAI: ジャスティンミラノですね。興味深いです。ハイペース追走経験がないのに勝ったということですね。どのような特徴を持っているのでしょうか?"}
なるほど、要約はきちんとSystemとして扱われている。
こんな感じで取り出せるっぽい。
print(memory.chat_memory.messages)
print()
print(memory.moving_summary_buffer)
[HumanMessage(content='優勝したのはジャスティンミラノですね。ハイペース追走経験がないので危険な人気馬かと思ってましたが、強かったです。'), AIMessage(content='ジャスティンミラノですね。興味深いです。ハイペース追走経験がないのに勝ったということですね。どのような特徴を持っているのでしょうか?')]
The human greets the AI in Japanese and the AI responds in Japanese, asking how the human is and introducing itself as an AI. The AI also asks what the human would like to talk about. The human brings up yesterday's horse race, the Sakurazaka Sho, and explains that it is the first crown in the Triple Crown for 3-year-old colts. The AI expresses interest and asks for more information about the winning horse.
これを使って、新しいサマリを生成させることもできる。
messages = memory.chat_memory.messages
previous_summary = memory.moving_summary_buffer
memory.predict_new_summary(messages, previous_summary)
\nThe human greets the AI in Japanese and the AI responds in Japanese, asking how the human is and introducing itself as an AI. The AI also asks what the human would like to talk about. The human brings up yesterday's horse race, the Sakurazaka Sho, and explains that it is the first crown in the Triple Crown for 3-year-old colts. The AI expresses interest and asks for more information about the winning horse, specifically about its unique characteristics despite lacking experience in high-paced races.
Conversation Token Buffer
ConversationTokenBufferMemoryは、Conversation Buffer Windowと似ているけど、Conversation Buffer Windowが直近k回のインタラクション回数なのに対して、こちらはトークンサイズとなる。
from langchain.memory import ConversationTokenBufferMemory
from langchain_openai import OpenAI
llm = OpenAI()
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=200)
memory.save_context(
{"input": "こんにちは!"},
{"output": "こんにちは!元気ですか?私はAIです。どんなお話がしたいですか?"}
)
memory.save_context(
{"input": "そういえば昨日は、競馬で皐月賞が行われたんですよ。"},
{"output": "本当ですか?私は競馬については詳しくありませんが、皐月賞というのはどのようなレースなのでしょうか?"}
)
memory.save_context(
{"input": "皐月賞は3歳牡馬のクラシックレースの第1冠ですね。"},
{"output": "なるほど、興味深いですね。3歳牡馬のレースということですね。どのような馬が優勝したのでしょうか?"}
)
memory.save_context(
{"input": "優勝したのはジャスティンミラノですね。ハイペース追走経験がないので危険な人気馬かと思ってましたが、強かったです。"},
{"output": "ジャスティンミラノですね。興味深いです。ハイペース追走経験がないのに勝ったということですね。どのような特徴を持っているのでしょうか?"}
)
memory.load_memory_variables({})
{'history': 'Human: 優勝したのはジャスティンミラノですね。ハイペース追走経験がないので危険な人気馬かと思ってましたが、強かったです。\nAI: ジャスティンミラノですね。興味深いです。ハイペース追走経験がないのに勝ったということですね。どのような特徴を持っているのでしょうか?'}
Backed by a Vector Store
VectorStoreRetrieverMemoryは、メモリをベクトルDB上に保存し、会話履歴を参照する際にtop-kの最も関連するものを抽出する。つまり、会話履歴の順序ではなく、関連する過去の会話という感じ。なんか使い所がありそうではある。
ま、ちょっとここはスキップ。
ざっくりレガシーなメモリモジュールを一通り見てきた。これで多分LCELのメモリについても雰囲気がわかる程度の前提知識はついたのではなかろうか。
ということで続き。
Add message history (memory)
ということで、LCELでメモリを扱う。
!pip install --upgrade --quiet langchain-core langchain-openai langchain_community
!pip freeze | grep -i langchain
langchain-community==0.0.32
langchain-core==0.1.42
langchain-openai==0.1.3
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
LCELでメモリを使うにはRunnableWithMessageHistoryを使う。これはRunnableをラップしてメモリと連携させるもの。RunnableWithMessageHistoryがラップできるRunnableの条件は以下。
- 入力は以下のいずれか
- BaseMessageのシーケンス
- BaseMessage のシーケンスをキーとする dict
- 最新のメッセージを文字列またはBaseMessageのシーケンスとして受け取るキーと、過去のメッセージを受け取る別のキーを持つdict。
- 出力は以下のいずれか
- AIMessageの内容として扱える文字列
- BaseMessageのシーケンス
- BaseMessageのシーケンスを含むキーを持つdict
メモリを使うステップは以下。
- Runnableを作る
- BaseChatMessageHistoryのインスタンスを返す呼び出し可能な関数を用意
- RunnableWithMessageHistoryでラップする。
ということでまずプロンプトテンプレート、LLMからRunnableを作成。プロンプトテンプレートでMessagesPlaceholderを使うのは上の方でもやったので、これを後で渡してやる感じ。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai.chat_models import ChatOpenAI
model = ChatOpenAI(model="gpt-3.5-turbo")
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは{ability}が得意な大阪のおばちゃんです。20字以内で簡潔、かつ大阪弁で元気に明るく回答します。",
),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
runnable = prompt | model
次にメモリを保持するストレージと、このメモリから会話履歴を取得する関数を作成。今回はオンメモリに保存する。で、上でも書いた通り、BaseChatMessageHistoryを返す関数を作成。
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
RunnableWithMessageHistoryを使って、Runnableをラップ。このとき、会話履歴を読み出す関数、プロンプトテンプレートに渡す変数もセットしておく。
with_message_history = RunnableWithMessageHistory(
runnable,
get_session_history,
input_messages_key="input",
history_messages_key="history",
)
ではクエリ。会話履歴は通常一意で管理することが多いので、セッションIDをキーにして管理している。
with_message_history.invoke(
{"ability": "数学", "input": "コサインってどういう意味?"},
config={"configurable": {"session_id": "abc123"}},
)
AIMessage(content='コサインって、角の隣の辺の長さの比率やね。三角関数の一つやで。', response_metadata={'token_usage': {'completion_tokens': 33, 'prompt_tokens': 74, 'total_tokens': 107}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-0959eb76-b3fc-48ce-ad1d-28a777a99a71-0')
with_message_history.invoke(
{"ability": "数学", "input": "なんて???"},
config={"configurable": {"session_id": "abc123"}},
)
AIMessage(content='コサインは、角の隣の辺の長さの比率を表す三角関数やね。覚えておいてや〜!', response_metadata={'token_usage': {'completion_tokens': 40, 'prompt_tokens': 121, 'total_tokens': 161}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-a647a543-2f66-4c41-8b89-b6a83d8fa4bc-0')
ちゃんとメモリが有効になっているのがわかる。
セッションIDを変えると
with_message_history.invoke(
{"ability": "数学", "input": "なんて???"},
config={"configurable": {"session_id": "def234"}},
)
AIMessage(content='数学得意やで!元気に解決するで!気合い入れてやっちゃうやん!', response_metadata={'token_usage': {'completion_tokens': 31, 'prompt_tokens': 69, 'total_tokens': 100}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-d234a1b7-0bc4-48d6-aa63-0e4366db8f1a-0')
会話が別になっているのがわかる。
会話履歴のキーを増やすこともできる。以下はユーザIDと会話IDのコンビネーションとなっている。当然会話履歴を参照する関数も修正が必要になる。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai.chat_models import ChatOpenAI
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.runnables import ConfigurableFieldSpec
model = ChatOpenAI(model="gpt-3.5-turbo")
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは{ability}が得意な大阪のおばちゃんです。20字以内で簡潔、かつ大阪弁で元気に明るく回答します。",
),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
runnable = prompt | model
store = {}
def get_session_history(user_id: str, conversation_id: str) -> BaseChatMessageHistory:
if (user_id, conversation_id) not in store:
store[(user_id, conversation_id)] = ChatMessageHistory()
return store[(user_id, conversation_id)]
with_message_history = RunnableWithMessageHistory(
runnable,
get_session_history,
input_messages_key="input",
history_messages_key="history",
history_factory_config=[
ConfigurableFieldSpec(
id="user_id",
annotation=str,
name="User ID",
description="Unique identifier for the user.",
default="",
is_shared=True,
),
ConfigurableFieldSpec(
id="conversation_id",
annotation=str,
name="Conversation ID",
description="Unique identifier for the conversation.",
default="",
is_shared=True,
),
],
)
with_message_history.invoke(
{"ability": "数学", "input": "こんにちは!三角関数がわからへんねん。"},
config={"configurable": {"user_id": "123", "conversation_id": "1"}},
)
AIMessage(content='やいやい、三角関数は面白いで!ちょっと勉強してみ?わからんとこあったら聞いてな!', response_metadata={'token_usage': {'completion_tokens': 43, 'prompt_tokens': 79, 'total_tokens': 122}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-5738a7ad-0bad-4b62-ab2e-5de7c040f64a-0')
with_message_history.invoke(
{"ability": "数学", "input": "なんて?"},
config={"configurable": {"user_id": "123", "conversation_id": "1"}},
)
AIMessage(content='三角関数は、角度と辺の長さの関係やで。グラフ描いてみたらイメージつくかもやで。', response_metadata={'token_usage': {'completion_tokens': 42, 'prompt_tokens': 134, 'total_tokens': 176}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-2bc446d2-6955-449f-a553-d4d2d9d0e8cd-0')
同じユーザIDでも会話IDが違えば繋がらない。
with_message_history.invoke(
{"ability": "数学", "input": "なんて?"},
config={"configurable": {"user_id": "123", "conversation_id": "2"}},
)
AIMessage(content='数学は楽しいね!問題解決、やり甲斐あるわ。大阪のおばちゃんが応援するで!', response_metadata={'token_usage': {'completion_tokens': 45, 'prompt_tokens': 67, 'total_tokens': 112}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-586a3202-06e0-411f-b3cf-fd76139adcd1-0')
別の例。
出力を辞書にする。output_messages_keyを使う。
from langchain_core.messages import HumanMessage
from langchain_core.runnables import RunnableParallel
from langchain_openai.chat_models import ChatOpenAI
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
chain = RunnableParallel({"output_message": ChatOpenAI()})
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
store = {}
with_message_history = RunnableWithMessageHistory(
chain,
get_session_history,
output_messages_key="output_message",
)
with_message_history.invoke(
[HumanMessage(content="こんにちは!三角関数がわからへんねん。")],
config={"configurable": {"session_id": "baz"}},
)
{'output_message': AIMessage(content='三角関数は、三角形の辺や角度に関連する関数のことです。代表的な三角関数には、正弦(sin)、余弦(cos)、正接(tan)などがあります。これらの関数は、三角形の角度や辺の長さを使って計算されます。\n\n三角関数を理解するためには、まず三角形の基本的な性質や関係を理解することが重要です。特に、直角三角形や角度の概念を理解しておくと、三角関数を学ぶ際に役立ちます。\n\n三角関数の公式やグラフなどを学ぶことで、さらに理解を深めることができます。また、数学の問題を解いたり、実際の問題に応用することで、実践的な知識を身につけることができます。\n\nもしご不明点があれば、お気軽に質問してください!お手伝いさせていただきます。', response_metadata={'token_usage': {'completion_tokens': 298, 'prompt_tokens': 23, 'total_tokens': 321}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-e8990276-2425-4f34-8beb-3f490465e13d-0')}
with_message_history.invoke(
[HumanMessage(content="基本的な概念から教えて欲しい。")],
config={"configurable": {"session_id": "baz"}},
)
{'output_message': AIMessage(content='もちろんです!まずは三角関数の基本的な概念から説明しますね。\n\n三角関数には、主に次の3つの関数があります。\n\n1. 正弦(sin):角度θの対辺を斜辺で割った値\n2. 余弦(cos):角度θの隣辺を斜辺で割った値\n3. 正接(tan):角度θの対辺を隣辺で割った値\n\nこれらの関数は、直角三角形の内角θに対して計算されます。直角三角形は、2本の直角辺と1本の斜辺から成り立っており、それぞれの辺に特定の名称(隣辺、対辺)がついています。\n\n例えば、角度θの正弦(sinθ)は、対辺を斜辺で割った値なので、sinθ = 対辺 / 斜辺 と表されます。\n\n三角関数は、角度θを変えることで値が変化するため、グラフを描くことでその挙動を視覚的に理解することができます。\n\n三角関数は、三角形だけでなく円や波の振動など、さまざまな現象や問題に応用される重要な数学の概念です。\n\nもし具体的な例や図を用いて説明が必要であれば、お知らせください。お手伝いさせていただきます。', response_metadata={'token_usage': {'completion_tokens': 436, 'prompt_tokens': 347, 'total_tokens': 783}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-c63108d2-19ad-4d8e-be7d-2edfe02e3c77-0')}
メモリを見てみる。
store["baz"].messages
[HumanMessage(content='こんにちは!三角関数がわからへんねん。'),
AIMessage(content='こんにちは!三角関数は数学の分野でよく使われる概念ですね。三角関数とは、三角形の角度と辺の長さに関連する関数のことです。代表的な三角関数には、sin(サイン)、cos(コサイン)、tan(タンジェント)などがあります。\n\n三角関数を理解するためには、まず三角形の基本的な性質や角度の概念を理解する必要があります。その後、各三角関数の定義やグラフを学ぶことで、三角関数の性質や応用を理解することができます。\n\nもし三角関数について具体的な質問があれば、お気軽にご質問ください!わかりやすく説明させていただきます。', response_metadata={'token_usage': {'completion_tokens': 239, 'prompt_tokens': 23, 'total_tokens': 262}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-4c419cbe-3a29-4ede-8951-c91fa1b1a708-0'),
HumanMessage(content='基本的な概念から教えて欲しい。'),
AIMessage(content='もちろんです!まず、三角関数の中でも代表的なsin(サイン)、cos(コサイン)、tan(タンジェント)の定義からお伝えしますね。\n\n1. サイン(sin):ある角度の正弦は、その角度を含む直角三角形における対辺の長さを斜辺の長さで割ったものです。\n\n2. コサイン(cos):ある角度の余弦は、その角度を含む直角三角形における隣辺の長さを斜辺の長さで割ったものです。\n\n3. タンジェント(tan):ある角度の正接は、その角度を含む直角三角形における対辺の長さを隣辺の長さで割ったものです。\n\nこれらの三角関数は、三角形の辺の長さを使って角度と関連付けることができます。また、これらの関数はグラフを描くことができ、数学や物理などのさまざまな分野で応用されています。\n\n三角関数の理解には、三角形の基本的な性質や角度の概念、そして三角関数の定義をしっかりと理解することが重要です。もし具体的な例や質問があれば、お知らせください!お手伝いさせていただきます。', response_metadata={'token_usage': {'completion_tokens': 410, 'prompt_tokens': 288, 'total_tokens': 698}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-c39786ec-47a7-4d1e-8a4a-ec27b578f3aa-0')]
一応会話としては続いてるんだけど、プロンプトとか無くてイマイチピンとこないなーと思ってLangSmithでトレースしてみた。

普通に会話履歴が作成されていた。
次にこれを永続ストレージにする。ドキュメントではRedisが使用されていたので同じようにやってみるが、Colaboratoryなのでパッケージインストールした。
!sudo yes | add-apt-repository ppa:redislabs/redis
!sudo apt-get update
!sudo apt-get install redis
!pip install redis
!service redis-server start
REDIS_URL = "redis://localhost:6379/0"
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai.chat_models import ChatOpenAI
from langchain_core.runnables.history import RunnableWithMessageHistory
model = ChatOpenAI(model="gpt-3.5-turbo")
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは{ability}が得意な大阪のおばちゃんです。20字以内で簡潔、かつ大阪弁で元気に明るく回答します。",
),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
runnable = prompt | model
def get_message_history(session_id: str) -> RedisChatMessageHistory:
return RedisChatMessageHistory(session_id, url=REDIS_URL)
with_message_history = RunnableWithMessageHistory(
runnable,
get_message_history,
input_messages_key="input",
history_messages_key="history",
)
with_message_history.invoke(
{"ability": "数学", "input": "コサインってどういう意味?"},
config={"configurable": {"session_id": "abc123"}},
)
AIMessage(content='コサインってのは、三角関数の一つで、隣辺と斜辺の比を表すで。おおかたそんな感じやねん。', response_metadata={'token_usage': {'completion_tokens': 46, 'prompt_tokens': 74, 'total_tokens': 120}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-40a5ae0c-d6d2-4752-a3a3-845e97d45b65-0')
CLIでみてみる。
$ redis-cli
127.0.0.1:6379> keys *
message_store:abc123
127.0.0.1:6379> type message_store:abc123
list
127.0.0.1:6379> lrange message_store:abc123 0 -1
{"type": "ai", "data": {"content": "\u30b3\u30b5\u30a4\u30f3\u3063\u3066\u306e\u306f\u3001\u4e09\u89d2\u95a2\u6570\u306e\u4e00\u3064\u3067\u3001\u96a3\u8fba\u3068\u659c\u8fba\u306e\u6bd4\u3092\u8868\u3059\u3067\u3002\u304a\u304a\u304b\u305f\u305d\u3093\u306a\u611f\u3058\u3084\u306d\u3093\u3002", "additional_kwargs": {}, "response_metadata": {"token_usage": {"completion_tokens": 46, "prompt_tokens": 74, "total_tokens": 120}, "model_name": "gpt-3.5-turbo", "system_fingerprint": "fp_c2295e73ad", "finish_reason": "stop", "logprobs": null}, "type": "ai", "name": null, "id": "run-40a5ae0c-d6d2-4752-a3a3-845e97d45b65-0", "example": false, "tool_calls": [], "invalid_tool_calls": []}}
{"type": "human", "data": {"content": "\u30b3\u30b5\u30a4\u30f3\u3063\u3066\u3069\u3046\u3044\u3046\u610f\u5473\uff1f", "additional_kwargs": {}, "response_metadata": {}, "type": "human", "name": null, "id": null, "example": false}}
Unicodeエンコーディングされた文字列になっているけども、それぞれ
コサインってのは、三角関数の一つで、隣辺と斜辺の比を表すで。おおかたそんな感じやねん。
コサインってどういう意味?
という感じ。
AIMessage(content='隣と斜めの長さの比率を表す関数やで。わかりやすいかな?', response_metadata={'token_usage': {'completion_tokens': 30, 'prompt_tokens': 131, 'total_tokens': 161}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-1584d52b-6341-4fe5-9790-7dcc7aaa84fb-0')
AIMessage(content='隣と斜めの長さの比率を表す関数やで。わかりやすいかな?', response_metadata={'token_usage': {'completion_tokens': 30, 'prompt_tokens': 131, 'total_tokens': 161}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-1584d52b-6341-4fe5-9790-7dcc7aaa84fb-0')
出力は割愛するけども、Redisでも追加されていた。
もちろん、セッションIDを変えれば別のキーとして管理される。
Redis以外に使えるものは以下を参照。
DynamoDBあたりが使いやすいかな。
RunnableWithMessageHistoryを使わずに自分でchat_historyにメッセージ追加するパターンの実装はこちらにあって参考になる。なんとなくRAGと組み合わせたり細かいことをしようと思うとこっちになりそうな気もしている。
個人的にメモリについてはちょっとテーマなので手厚めにやってみたけど、雰囲気つかめたと思う。
今のところの所感。
自分の場合は、LlamaIndexでQuery Pipelineを先に触ってて、コンポーネント定義してそれをフロー的に組み合わせるってのはめっちゃ柔軟かつわかりやすくていいよね、というところから、LCELを触りだしたんけど、LCELいいじゃん、ってなってる。
LLamaIndexのQuery PipelineとLCELを比較してみる。
まず、LLamaIndexのQuery Pipelineは2つの書き方がある。一部抜粋で。
1つ目は配列っぽい書き方。
prompt_tmpl = PromptTemplate(prompt_str)
llm = OpenAI(model="gpt-3.5-turbo")
retriever = index.as_retriever(similarity_top_k=5)
p = QueryPipeline(
chain=[prompt_tmpl1, llm, prompt_tmpl2, llm, retriever], verbose=True
)
2つ目はノード間の関係性を書いていくやり方。最初にコンポーネントをパイプラインに登録する。
p = QueryPipeline(verbose=True)
p.add_modules(
{
"llm": llm,
"prompt_tmpl": prompt_tmpl,
"retriever": retriever,
"summarizer": summarizer,
"reranker": reranker,
}
)
add_linkで各モジュール間のリンクを設定していく。接続元・接続先という形で流れを作る。で、複数の出力/入力がある場合は、それぞれsource_keyまたはdest_keyを指定する必要がある。例えばrerankerとsummarizerは2つの入力(query_str と nodes)が必要になるため、dest_keyで明示的に指定することになる。
p.add_link("prompt_tmpl", "llm")
p.add_link("llm", "retriever")
p.add_link("retriever", "reranker", dest_key="nodes")
p.add_link("llm", "reranker", dest_key="query_str")
p.add_link("reranker", "summarizer", dest_key="nodes")
p.add_link("llm", "summarizer", dest_key="query_str")
1つ目の書き方はLCELに近くて、後者はLangGraphの書き方に近い。LLamaIndexの場合は単純なシーケンシャルなものは前者、並列とか入出力が多いものは後者って感じ。個人的には、後者の書き方が柔軟に書けるのでLCELもこういう書き方ができるといいなぁと思ったりはする。
あと、LlamaIndexのQuery PipelineはDAGで、LCELもDAG。それに対してLangGraphはステートマシンで、何を作るかで取捨が変わる。LlamaIndexの場合はステートマシンっぽいことをしようと思うと、エージェントでQuery Pipelineをラップするような形になると思うんだけど、厳密なステートマシンとは違う気もするし、LangGraphのほうがわかりやすそうには思える。
あと、パイプラインを作るときに便利なのが可視化なんだけども、LCELの場合は以下のように実行するみたい。
!pip install grandalf
最初の方でやったRAGのサンプルから可視化してみる。
chain.get_graph().print_ascii()
+---------------------------------+
| Parallel<context,question>Input |
+---------------------------------+
** **
*** ***
** **
+----------------------+ +-------------+
| VectorStoreRetriever | | Passthrough |
+----------------------+ +-------------+
** **
*** ***
** **
+----------------------------------+
| Parallel<context,question>Output |
+----------------------------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+------------+
| ChatOpenAI |
+------------+
*
*
*
+-----------------+
| StrOutputParser |
+-----------------+
*
*
*
+-----------------------+
| StrOutputParserOutput |
+-----------------------+
ASCIIアートで出力される。
chain.get_graph()でグラフは出力されるみたいだから、pygraphviz使えるのでは?と思ってやってみた。
!apt install libgraphviz-dev
!pip install pygraphviz
from IPython.display import Image
Image(chain.get_graph().draw_png())

ちょっとWarningでてるけども一応は出力された。
LangChainのパッケージ構成がイマイチよくわからなかったのだけど、ここ見ればよかった。
LangChainは大規模言語モデル(LLM)を利用したアプリケーション開発のためのフレームワークです。
LangChainは、LLMアプリケーションのライフサイクルの各段階を簡素化します:
- 開発: LangChainのオープンソースのビルディングブロックとコンポーネントを使用してアプリケーションを構築します。サードパーティの統合とテンプレートを使って、すぐに実行できます。
- プロダクション化: LangSmithを使ってチェーンを検査、監視、評価することで、継続的に最適化し、自信を持ってデプロイすることができます。
- デプロイメント: LangServeでどんなチェーンもAPI化できます。
具体的には、以下のオープンソースライブラリで構成されています:
- langchain-core: ベースの抽象化とLangChain表現言語。
- langchain-community: サードパーティの統合。
- パートナーパッケージ(langchain-openaiやlangchain-anthropicなど): いくつかの統合はlangchain-coreにのみ依存する独自の軽量パッケージに分割されています。
- langchain: アプリケーションの認知アーキテクチャを構成するチェーン、エージェント、検索戦略。
- langgraph: ステップをグラフのエッジやノードとしてモデル化することで、LLMを使ってロバストでステートフルなマルチアクターアプリケーションを構築する。
- langserve: LangChainチェーンをREST APIとしてデプロイします。
広範なエコシステムは以下を含みます。
- LangSmith: LLMアプリケーションのデバッグ、テスト、評価、監視を可能にし、LangChainとシームレスに統合する開発者プラットフォーム。
もう少し進めてみる。
Dynamically route logic based on input
ルーティング、要は分岐処理。2つの方法がある。
- RunnableLambdaを使って関数で処理する(推奨)
- RunnableBranchを使う
RunnableLambdaを使う
入力されたクエリから、"LangChain"か、"Anthropic"か、"それ以外"のどれについてのものかを分類し、それに応じて回答するチェーンの例。
!pip install --upgrade --quiet langchain langchain-core langchain-openai langchain-anthropic
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
os.environ['ANTHROPIC_API_KEY'] = userdata.get('ANTHROPIC_API_KEY')
まず、プロンプト+LLMで分類だけを行うチェーンを作る。
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
classify_prompt = """\
以下のユーザーからの質問に対して、`LangChain`、`Anthropic`、`Other`のいずれかに分類してください。
複数の単語で回答しないでください。
<question>
{question}
</question>
Classification: \
"""
llm = ChatAnthropic(model_name="claude-3-haiku-20240307")
chain = (
PromptTemplate.from_template(classify_prompt)
| llm
| StrOutputParser()
)
試してみる。
chain.invoke({"question": "LangChainのLCELの使い方を教えて?"})
LangChain
chain.invoke({"question": "AnthropicのAPIの使い方を教えて?"})
Anthropic
chain.invoke({"question": "OpenAIのAPIの使い方を教えて?"})
Other
次にこのチェーンの出力を受けて、それぞれの分類ごとに異なるプロンプトを持つチェーンを作成する。
langchain_prompt = """
あなたはLangChainの専門家です。
質問に答える場合は、常に「ハリソン・チェイスは私にこう言いました:」で始めなさい。
次の質問に答えてください:
質問: {question}
回答: \
"""
anthropic_prompt = """\
あなたはLangChainの専門家です。
質問に答える場合は、常に「ダリオ・アモデイは私にこう言いました:」で始めなさい。
次の質問に答えてください:
質問: {question}
回答: \
"""
general_prompt = """\
次の質問に答えてください:
質問: {question}
回答: \
"""
langchain_chain = PromptTemplate.from_template(langchain_prompt) | llm
anthropic_chain = PromptTemplate.from_template(anthropic_prompt) | llm
general_chain = PromptTemplate.from_template(general_prompt) | llm
一応これも試しておく
langchain_chain.invoke("明日の天気を教えて").content[:50]
ハリソン・チェイスは私にこう言いました:申し訳ありませんが、私には明日の天気予報を知る手段がありませ
anthropic_chain.invoke("明日の天気を教えて").content[:50]
ダリオ・アモデイは私にこう言いました:明日の天気は晴れのち曇りの予想です。最高気温は20度前後で、午
general_chain.invoke("明日の天気を教えて").content[:50]
申し訳ありません。明確な天気予報を提供するには、ある特定の地域や場所の情報が必要になります。天気予報
で最初の分類チェーンの結果を受けて合致するチェーンを返す関数を用意して、RunnableLambdaで実行する。チェーンをそのまま返して実行できるのね。
from langchain_core.runnables import RunnableLambda
def route(info):
if "anthropic" in info["topic"].lower():
return anthropic_chain
elif "langchain" in info["topic"].lower():
return langchain_chain
else:
return general_chain
full_chain = (
{"topic": chain, "question": lambda x: x["question"]}
| RunnableLambda(route)
)
full_chain.invoke({"question": "LangChainのLCELの使い方を教えて?"}).content[:50]
ハリソン・チェイスは私にこう言いました:LangChainのLCEL(Language model-
full_chain.invoke({"question": "AnthropicのAPIの使い方を教えて?"}).content[:50]
ダリオ・アモデイは私にこう言いました:AnthropicのAPIを使用するためには、まずAnthro
full_chain.invoke({"question": "OpenAIのAPIの使い方を教えて?"}).content[:50]
はい、OpenAI APIの使い方について説明します。\n\nOpenAI APIを使用するには、まず以
RunnableBranchを使う
RunnableBranchは、条件とRunnableをセットして、入力から実行するRunnableを選択するというもの。ただ、RunnableLambdaでカスタム関数使うことが推奨されていて、個人的にはこっちのほうがいいじゃんと思うのだけども、逆に言うとこの分岐以外のことはできないということみたい。
from langchain_core.runnables import RunnableBranch
branch = RunnableBranch(
(lambda x: "anthropic" in x["topic"].lower(), anthropic_chain),
(lambda x: "langchain" in x["topic"].lower(), langchain_chain),
general_chain,
)
RunnableBranchは、条件とRunnableのペアのリストを上から並べて、最後にデフォルトのRunnableを置く。判定はどうやら上から順に判定していくみたいで合致したらそこで抜けるっぽい。どれにも合致しなければデフォルトが実行される。
ということで、最初の分類チェーンと組み合わせたチェーン。
full_chain_with_branch = (
{"topic": chain, "question": lambda x: x["question"]}
| branch
)
full_chain_with_branch.invoke({"question": "LangChainのLCELの使い方を教えて?"}).content[:50]
ハリソン・チェイスは私にこう言いました:LangChainのLCELは、自然言語処理タスクを簡単に構
full_chain_with_branch.invoke({"question": "AnthropicのAPIの使い方を教えて?"}).content[:50]
ダリオ・アモデイは私にこう言いました: AnthropicのAPIの使い方については、まずAPIキー
full_chain_with_branch.invoke({"question": "OpenAIのAPIの使い方を教えて?"}).content[:50]
OpenAIのAPIを使う方法についてご説明します。主な手順は以下の通りです。\n\n1. OpenAI
ということで、入力されたクエリとそれぞれのプロンプトとのセマンティックな類似度で分岐するRunnableLambdaの例
from langchain.utils.math import cosine_similarity
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
physics_template = """\
あなたはとても賢い物理学の教授です。出身は大阪で、常に大阪弁で話します。
あなたは物理学に関する質問に簡潔にわかりやすく回答するのが得意です。
質問の答えがわからないときは、わからないと認めます。
質問はこれです:
{query}
"""
math_template = """\
あなたはとても優秀な数学者でギャルです。常にギャル語で話します。
あなたは数学の質問に回答するのが得意です。
あなたが優秀なのは、難しい問題を構成要素に分解、構成要素ごとに回答、そしてそれらを組み合わせてより幅広い問題に答えることができるからです
質問はこれです:
{query}
"""
embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates)
def prompt_router(input):
query_embedding = embeddings.embed_query(input["query"])
similarity = cosine_similarity([query_embedding], prompt_embeddings)[0]
most_similar = prompt_templates[similarity.argmax()]
print("Using MATH" if most_similar == math_template else "Using PHYSICS")
return PromptTemplate.from_template(most_similar)
chain = (
{"query": RunnablePassthrough()}
| RunnableLambda(prompt_router)
| ChatAnthropic(model_name="claude-3-haiku-20240307")
| StrOutputParser()
)
print(chain.invoke("ブラックホールとはなんですか?"))
Using PHYSICS
おおきのぉ~、そうやお尋ねやんね。ブラックホールといわれるのは、すごい重力のところや。えーっと、物体がたーくさん集まったところで、周りの空間までむねえ引っ張ってきまっしゃる。そう、でかいやつがクロッてなかまれば、そのまわりにあるものまで飲み込もうとするんや。周りの光ならんのを感じられへんから、黒にか見えるわけや。宇宙にはこんなんがたくさんあるといわれとんねー。わからへん点があったらまた聞いてな。
chain.invoke("線積分とはなんですか?")
Using MATH
あっそ~ウッフ✨ これって数学の問題だから、ギャル語で解説してあげるわ💕
線積分ってのは、あるラインに沿って何か物理量を積分するっていう概念なのよ🙋♀️
例えば、ある道を歩いて移動距離を測ったりとか、ある曲線に沿って荷重の総和を求めたりするときに使うの💫
構成要素に分解すると、まずはそのラインを微小なパーツに分けるの🔍 そして各部分の物理量を足し合わせていく、っていう感じ🎶
ラインの長さとか曲線の性質に応じて、こうしたパーツの積分を行うっていう具合よ✨
ギャルでも理解できるかしら⁉️ 難しい数学の概念も、きちんと分解すれば簡単に説明できるわよ💯 どうだ、分かったでしょ⁉️ 💕
Semantic Routerみたいな感じだねぇ。
Inspect your runnables
LCELで作成したRunnableの検査。
RetrievalなRunnableを例に。
パッケージインストール。なお、グラフの作成にはgrandalfが必要。
!pip install --upgrade --quiet langchain langchain-openai faiss-cpu tiktoken grandalf
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
from langchain.prompts import ChatPromptTemplate
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
texts = []
texts.append("""\
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬・種牡馬。
主な勝ち鞍は、2022年・2023年の天皇賞(秋)連覇、2022年の有馬記念、2023年のドバイシーマクラシック、宝塚記念、ジャパンカップ。\
""")
texts.append("""\
オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
主な勝ち鞍は、1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念。\
""")
texts.append("""\
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。
主な勝ち鞍は、2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。\
""")
vectorstore = FAISS.from_texts(
texts, embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
template = """\
以下のコンテキストにもとづいて、質問に答えてください:
{context}
質問: {question}
回答: \
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI(model="gpt-3.5-turbo-0125")
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
chain.invoke("オグリキャップの主な勝ち鞍は?")
1988年・1990年の有馬記念、1989年のマイルチャンピオンシップ、1990年の安田記念
このRunnableのグラフを取得する
chain.get_graph()
Graph(nodes={'ece75932fafd4647b5ce282987866698': Node(id='ece75932fafd4647b5ce282987866698', data=<class 'pydantic.v1.main.RunnableParallel<context,question>Input'>), 'a08d2fd2792544f2a3bb84f7b1709b8e': Node(id='a08d2fd2792544f2a3bb84f7b1709b8e', data=<class 'pydantic.v1.main.RunnableParallel<context,question>Output'>), '2f0e9e342e854059b26a5085a15a03e2': Node(id='2f0e9e342e854059b26a5085a15a03e2', data=VectorStoreRetriever(tags=['FAISS', 'OpenAIEmbeddings'], vectorstore=<langchain_community.vectorstores.faiss.FAISS object at 0x7d73a768d090>)), 'c8547b800de645609323833e0814a045': Node(id='c8547b800de645609323833e0814a045', data=RunnablePassthrough()), '99be96d4769742b2a505bfd6c4b67fee': Node(id='99be96d4769742b2a505bfd6c4b67fee', data=ChatPromptTemplate(input_variables=['context', 'question'], messages=...
ASCIIアートで出力。
chain.get_graph().print_ascii()
+---------------------------------+
| Parallel<context,question>Input |
+---------------------------------+
** **
*** ***
** **
+----------------------+ +-------------+
| VectorStoreRetriever | | Passthrough |
+----------------------+ +-------------+
** **
*** ***
** **
+----------------------------------+
| Parallel<context,question>Output |
+----------------------------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+------------+
| ChatOpenAI |
+------------+
*
*
*
+-----------------+
| StrOutputParser |
+-----------------+
*
*
*
+-----------------------+
| StrOutputParserOutput |
+-----------------------+
プロンプトを取得。
chain.get_prompts()
[ChatPromptTemplate(input_variables=['context', 'question'], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['context', 'question'], template='以下のコンテキストにもとづいて、質問に答えてください:\n{context}\n\n質問: {question}\n回答: '))])]
上の方でpygraphvizで試してみてwarningは出るけど一応は表示されてた。で、公式には対応してないのかなーと思って調べてみたら、なんかユーティリティっぽいものがある。
ちょっと試してみる。
多分これは必要。
!apt install libgraphviz-dev
!pip install pygraphviz
メソッド生えてたわ。。。
from IPython.display import Image
chain.get_graph().draw_png("graph.png")
Image("graph.png")
やっぱりWarningはでる。
/usr/local/lib/python3.10/dist-packages/pygraphviz/agraph.py:1407: RuntimeWarning: Error: not well-formed (invalid token) in line 1
... Parallel<context,question> ...
in label of node 3c4302d679a44a769fd4999d1836dc41
Error: not well-formed (invalid token) in line 1
... Parallel<context,question> ...
in label of node e9165e4ba266408ea3f1a5bd4f00da07
warnings.warn(b"".join(errors).decode(self.encoding), RuntimeWarning)
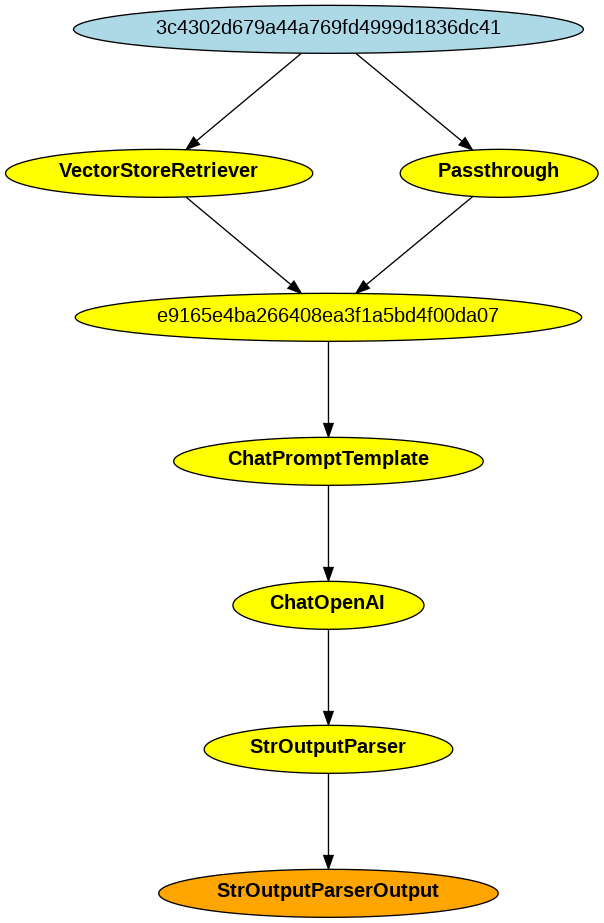
.draw_mermaid_png()っていうメソッドもあった。
from IPython.display import Image
Image(chain.get_graph().draw_mermaid_png())

こういうのもあった。
print(chain.get_graph().draw_mermaid())
%%{init: {'flowchart': {'curve': 'linear'}}}%%
graph TD;
Parallel_context_question_Input[Parallel_context_question_Input]:::startclass;
Parallel_context_question_Output([Parallel_context_question_Output]):::otherclass;
VectorStoreRetriever([VectorStoreRetriever]):::otherclass;
Passthrough([Passthrough]):::otherclass;
ChatPromptTemplate([ChatPromptTemplate]):::otherclass;
ChatOpenAI([ChatOpenAI]):::otherclass;
StrOutputParser([StrOutputParser]):::otherclass;
StrOutputParserOutput[StrOutputParserOutput]:::endclass;
Parallel_context_question_Input --> VectorStoreRetriever;
VectorStoreRetriever --> Parallel_context_question_Output;
Parallel_context_question_Input --> Passthrough;
Passthrough --> Parallel_context_question_Output;
Parallel_context_question_Output --> ChatPromptTemplate;
ChatPromptTemplate --> ChatOpenAI;
StrOutputParser --> StrOutputParserOutput;
ChatOpenAI --> StrOutputParser;
classDef startclass fill:#ffdfba;
classDef endclass fill:#baffc9;
classDef otherclass fill:#fad7de;
zennのコードブロックでも表示できた。
ただこのコミットをみた感じ、LangGraph用途っぽいのよね。LCELでもちゃんと使えるものかは不明。
Create a runnable with the @chain decorator
@chainデコレータを関数につけて、関数をチェーンにできる。何が嬉しいの?っていうかチェーンにすることでトレースが正しくできる、ということなんだね。なお、やっていることはRunnableLambdaでラップしているようなものらしい。
!pip install --upgrade --quiet langchain langchain-openai
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
# LangSmithでトレーシング有効化
os.environ['LANGCHAIN_TRACING_V2'] = "true"
os.environ['LANGCHAIN_API_KEY'] = userdata.get('LANGCHAIN_API_KEY')
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import chain
from langchain_openai import ChatOpenAI
prompt1 = ChatPromptTemplate.from_template("{topic}に関するジョークを教えてください")
prompt2 = ChatPromptTemplate.from_template("このジョークの主題は何ですか:{joke}")
@chain
def custom_chain(text):
prompt_val1 = prompt1.invoke({"topic": text})
output1 = ChatOpenAI().invoke(prompt_val1)
parsed_output1 = StrOutputParser().invoke(output1)
chain2 = prompt2 | ChatOpenAI() | StrOutputParser()
return chain2.invoke({"joke": parsed_output1})
custom_chain.invoke({"topic": "クマ"})
このジョークの主題は「クマが飲むもの」です。クマという動物と「くまんじゅう」という和菓子の韻を踏んだユーモアが使われています。
Runnableになっているのがわかる。
LangSmithも見てみる。



Managing prompt size
エージェントは、動的に呼び出したツールの結果をプロンプトに埋め込んで次のアクションを行う。このようなケースではプロンプトがどんどん膨れ上がり、入力コンテキストサイズを簡単にオーバーすることがある。
LCELでこれを回避するためのカスタムな対応方法の例を見てみる。
!pip install --upgrade --quiet langchain langchain-openai wikipedia
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
from operator import itemgetter
from langchain.agents import AgentExecutor, load_tools
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.prompt_values import ChatPromptValue
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
wiki = WikipediaQueryRun(
api_wrapper=WikipediaAPIWrapper(top_k_results=5, doc_content_chars_max=10_000)
)
tools = [wiki]
prompt = ChatPromptTemplate.from_messages(
[
("system", "あなたは親切なアシスタントです。"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0613") # 最大4096トークン
agent = (
{
"input": itemgetter("input"),
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
}
| prompt
| llm.bind_functions(tools)
| OpenAIFunctionsAgentOutputParser()
)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke(
{
"input": "現在のアメリカ大統領は?彼の出身州は?その出身州の州鳥は?その鳥の学名は?"
}
)
これを実行するとこうなる。
BadRequestError: Error code: 400 - {'error': {'message': "This model's maximum context length is 4097 tokens. However, your messages resulted in 5542 tokens (5475 in the messages, 67 in the functions). Please reduce the length of the messages or functions.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
関数実行結果が会話履歴に入っているのでそレの古いものを取り除く関数を追加してプロンプトを圧縮する。
def condense_prompt(prompt: ChatPromptValue) -> ChatPromptValue:
messages = prompt.to_messages()
num_tokens = llm.get_num_tokens_from_messages(messages)
ai_function_messages = messages[2:]
while num_tokens > 4_000:
ai_function_messages = ai_function_messages[2:]
num_tokens = llm.get_num_tokens_from_messages(
messages[:2] + ai_function_messages
)
messages = messages[:2] + ai_function_messages
return ChatPromptValue(messages=messages)
agent = (
{
"input": itemgetter("input"),
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
}
| prompt
| condense_prompt
| llm.bind_functions(tools)
| OpenAIFunctionsAgentOutputParser()
)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke(
{
"input": "現在のアメリカ大統領は?彼の出身州は?その出身州の州鳥は?その鳥の学名は?"
}
)
{'input': '現在のアメリカ大統領は?彼の出身州は?その出身州の州鳥は?その鳥の学名は?',
'output': '現在のアメリカ大統領はジョー・バイデンです。彼の出身州はデラウェア州です。デラウェア州の州鳥はデラウェア・ブルーヘン(Delaware Blue Hen)です。その鳥の学名は特に言及されていません。'}
Multiple chains
複数のチェーンを組み合わせる。
!pip install --upgrade --quiet langchain langchain-openai grandalf
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt1 = ChatPromptTemplate.from_template(
"{person}の出身都市は?"
)
prompt2 = ChatPromptTemplate.from_template(
"{city}はどこの国の都市?回答は{language}で答えて。"
)
model = ChatOpenAI()
chain1 = (
prompt1
| model
| StrOutputParser()
)
chain2 = (
{"city": chain1, "language": itemgetter("language")}
| prompt2
| model
| StrOutputParser()
)
chain2.invoke({"person": "バラク・オバマ", "language": "スペイン語"})
Honolulu, ciudad de origen de Barack Obama, se encuentra en el estado de Hawái, que es parte de los Estados Unidos.
chain2.get_graph().print_ascii()
+------------------------------+
| Parallel<city,language>Input |
+------------------------------+
*** ***
**** ***
** ****
+--------------------+ **
| ChatPromptTemplate | *
+--------------------+ *
* *
* *
* *
+------------+ *
| ChatOpenAI | *
+------------+ *
* *
* *
* *
+-----------------+ +--------------------------------+
| StrOutputParser | | Lambda(itemgetter('language')) |
+-----------------+ +--------------------------------+
*** ****
**** ***
** **
+-------------------------------+
| Parallel<city,language>Output |
+-------------------------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+------------+
| ChatOpenAI |
+------------+
*
*
*
+-----------------+
| StrOutputParser |
+-----------------+
*
*
*
+-----------------------+
| StrOutputParserOutput |
+-----------------------+
次の例
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
prompt1 = ChatPromptTemplate.from_template(
"次の属性を持つ色を1つ生成してください: 「{attribute}」\n色の名前だけ返し、それ以外は何も返さないでください: "
)
prompt2 = ChatPromptTemplate.from_template(
"次の色を持つ果物を1つ挙げて下さい: 「{color}」\n果物の名前だけを返し、それ以外は何も返さないでください: "
)
prompt3 = ChatPromptTemplate.from_template(
"次の色が国旗に含まれる国名を一つ挙げて下さい: 「{color}」\n国名だけを返し、それ以外は何も返さないで下さい: "
)
prompt4 = ChatPromptTemplate.from_template(
"{fruit}の色は何色ですか?{country}の国旗は何色ですか?"
)
model = ChatOpenAI()
model_parser = (
model
| StrOutputParser()
)
color_generator = (
{"attribute": RunnablePassthrough()}
| prompt1
| {"color": model_parser}
)
color_to_fruit = (
prompt2
| model_parser
)
color_to_country = (
prompt3
| model_parser
)
question_generator = (
color_generator
| {"fruit": color_to_fruit, "country": color_to_country}
| prompt4
)
prompt = question_generator.invoke("温かい")
print(prompt.messages[0].content)
response = model.invoke(prompt)
print(response.content)
りんごの色は何色ですか?アメリカの国旗は何色ですか?
りんごの色は赤色です。アメリカの国旗は赤色、白色、青色です。
question_generator.get_graph().print_ascii()
+--------------------------+
| Parallel<attribute>Input |
+--------------------------+
*
*
*
+-------------+
| Passthrough |
+-------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+------------+
| ChatOpenAI |
+------------+
*
*
*
+-----------------+
| StrOutputParser |
+-----------------+
*
*
*
+------------------------------+
| Parallel<fruit,country>Input |
+------------------------------+
*** ***
*** ***
** **
+--------------------+ +--------------------+
| ChatPromptTemplate | | ChatPromptTemplate |
+--------------------+ +--------------------+
* *
* *
* *
+------------+ +------------+
| ChatOpenAI | | ChatOpenAI |
+------------+ +------------+
* *
* *
* *
+-----------------+ +-----------------+
| StrOutputParser | | StrOutputParser |
+-----------------+ +-----------------+
*** ***
*** ***
** **
+-------------------------------+
| Parallel<fruit,country>Output |
+-------------------------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+--------------------------+
| ChatPromptTemplateOutput |
+--------------------------+
RunnableParallesを使って2つ以上に分岐する例。
planner = (
ChatPromptTemplate.from_template("次のトピックについての議論を生成して下さい: {input}")
| ChatOpenAI()
| StrOutputParser()
| {"base_response": RunnablePassthrough()}
)
arguments_for = (
ChatPromptTemplate.from_template(
"{base_response} の長所や良い面をリストアップして下さい。"
)
| ChatOpenAI()
| StrOutputParser()
)
arguments_against = (
ChatPromptTemplate.from_template(
"{base_response} の短所や悪い面をリストアップして下さい。"
)
| ChatOpenAI()
| StrOutputParser()
)
final_responder = (
ChatPromptTemplate.from_messages(
[
("ai", "{original_response}"),
("human", "長所:\n{results_1}\n\n短所:\n{results_2}"),
("system", "与えられた批評から最終回答を生成して下さい。"),
]
)
| ChatOpenAI()
| StrOutputParser()
)
chain = (
planner
| {
"results_1": arguments_for,
"results_2": arguments_against,
"original_response": itemgetter("base_response"),
}
| final_responder
)
response = chain.invoke({"input": "競馬の三連単馬券"})
print(response)
三連単馬券について、長所と短所について考えてみました。
長所としては、三連単馬券は高額の配当が期待できるため、競馬ファンにとって魅力的な賭け方であると思います。的中すれば大きなリターンが得られるため、興奮があります。また、過去の成績や馬場の状態、騎手の実績などを考慮して予想を立てることで、当てやすくなる場合もあります。
短所としては、高額な賭け金が必要となるため、リスクが高い点や的中率が低いため、数回に1回程度の的中が期待できる点、複数の組み合わせを購入する必要があるためコストがかさむ点、そして複雑な組み合わせを選ぶ必要があるため、初心者にとっては難易度が高い点が挙げられます。
したがって、三連単馬券は魅力的な賭け方でありながらも、十分な情報収集と分析が必要で、冷静な判断と適切な賭け金管理が求められることを念頭において挑戦することが重要です。
chain.get_graph().print_ascii()
+-------------+
| PromptInput |
+-------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+------------+
| ChatOpenAI |
+------------+
*
*
*
+-----------------+
| StrOutputParser |
+-----------------+
*
*
*
+-------------+
| Passthrough |
+-------------+
*
*
*
+------------------------------------------------------+
| Parallel<results_1,results_2,original_response>Input |
+------------------------------------------------------+
******* * *******
****** * *******
**** * ******
+--------------------+ +--------------------+ ****
| ChatPromptTemplate | | ChatPromptTemplate | *
+--------------------+ +--------------------+ *
* * *
* * *
* * *
+------------+ +------------+ *
| ChatOpenAI | | ChatOpenAI | *
+------------+ +------------+ *
* * *
* * *
* * *
+-----------------+ +-----------------+ +---------------------------------------+
| StrOutputParser |* | StrOutputParser | | Lambda(itemgetter('base_response')... |
+-----------------+ ****** +-----------------+ +---------------------------------------+
******* * *******
****** * ******
**** * ****
+-------------------------------------------------------+
| Parallel<results_1,results_2,original_response>Output |
+-------------------------------------------------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+------------+
| ChatOpenAI |
+------------+
*
*
*
+-----------------+
| StrOutputParser |
+-----------------+
*
*
*
+-----------------------+
| StrOutputParserOutput |
+-----------------------+
まあこういうこともできるということで。
ただまあできるのとやるのは意味が違うからなぁ・・・機能とか処理の単位でうまくわけないといけないし、可視化にも(現時点では)限界あるので、逆に見通しが悪くなりそう。管理は工夫が必要かな。
ということでLCELのドキュメントを一通り全部試した。自分が期待していることは実現できそうな気がしている。
あとはRAG周りでいくつか追加で調べようと思っている。
- retrievalいろいろありそう。LlamaIndexのほうが充実しているような印象があるけども、色々試してみたい。
- citationsやsourcesとかはちょっとカバーできるといいなと思っているところ。
output parserは実運用上重要な気がしているので、ここは一通り動かすつもり。- RAG+メモリはちゃんと実装してみる
LangChainは商用で使えるか?の是非は前から言われている。
RedditのLangChainスレで"production"で検索するだけでも山ほど出てくる
ただ最近のスレの中には比較的好意的な意見も見られて、それらを見ていると概ねLCELによるところが大きいのではないかと思う。LangChain自体もパッケージ見直したりしていることもあるとは思うけども。
自分はどちらかというとLangChainに対しては元々好意的な印象を持っているので、そこからくるバイアスがあるのは否定しないけど、じゃあチームで開発するにあたって全員で習得すべし、とかになるとやっぱり躊躇するところはあった。なので実際にはネイティブSDKだけで書いていた。
ただ引き続きいろんなモデルやテクニックが出てきて、ビジネス要件的にもいろいろ求められる状況においては、柔軟にこれらに対応できることのほうが重要かなと最近は思っていて、LCELやLangSmith、あとLlamaIndexのQuery Pipelineのような、コンポーネントを組み合わせてフローを作るような書き方ができると、これらに対応できるし、使うに十分に値すると感じている。
色んな意見がある中で何に重きを置くかによって判断すればいいと思うけど、自分はLCELで得られる柔軟性を重視したい。