BigQuery ML で多変数のデータを時系列モデリング(ARIMA_PLUS_XREG)
BigQuery ML の ARIMA_PLUS_XREG を用いて、外部変数を含む多変数時系列モデリングをおこなってみた。
実験対象としては、「コマンダー&クープマン、状態空間時系列分析入門(シーエーピー出版、2008)」のサンプルデータを用いる。
データ: http://www.ssfpack.com/CKbook.html (現在リンク切れ)
なお、上掲書では ARIMA ではなく状態空間モデルを用いている。
状態空間モデルと ARIMA モデルの比較の議論は、上掲書の第10章を参照のこと。
また、上掲書に沿った R, Python によるモデリングは以下を参照:
データの用意
上掲書では、主に3種類のデータが用いられている:
- イギリスにおける自動車事故死傷者数
- イギリスにおけるインフレ率
- ノルウェイとフィンランドにおける自動車事故数
今回は、これらのうちひとつ目の「イギリスにおける自動車事故死傷者数」を主に用いる。
データ加工
データを上述のサポートページ(現在リンク切れ)からデータをダウンロードした。
イギリスにおける自動車事故死傷者数のほかに、それに関連する変数として
- 石油価格
- 英国シートベルト法の導入(ダミー変数)
がある。
これらを一つの DataFrame にまとめて、csv ファイルとして保存する。
# 死傷者数(対数をとる)
df_ukdrivers = pd.read_csv('../data/ckbook/UKdriversKSI.txt', skiprows=[0], header=None)
df_ukdrivers.columns = ['drivers']
df_ukdrivers['log_drivers'] = np.log(df_ukdrivers['drivers'])
df_ukdrivers.index = pd.date_range(start='1969-01', periods=df_ukdrivers.shape[0], freq='M')
# 石油価格
df_ukpetrol = pd.read_csv('../data/ckbook/logUKpetrolprice.txt')
df_ukpetrol.columns = ['log_petrol_price']
df_ukpetrol.index = pd.date_range(start='1969-01', periods=df_ukpetrol.shape[0], freq='M')
# シートベルト法
dummy_var_seatbelt = pd.Series(df_ukdrivers.index >= datetime.datetime(1983, 2,1), index=df_ukdrivers.index).astype(int)
# 上記を統合する
df_uk_all = df_ukdrivers[['log_drivers']].copy()
df_uk_all['log_petrol_price'] = df_ukpetrol['log_petrol_price']
df_uk_all['seatbelt'] = dummy_var_seatbelt
df_uk_all.index.name="date"
# 保存
df_uk_all.to_csv("../data/ckbook/UKdrivers_with_petrolprice_seatbelt.csv")
BigQuery へのアップロード
上記の csv ファイルを、コンソールから手動でアップロードした。
補足: データ内容
時系列プロット
log_drivers: 自動車事故死傷者数(対数)

log_petrol_price: 石油価格(対数)

seatbelt: シートベルト法の導入(ダミー変数)

傾向として、以下が見える:
- 石油価格が上昇すると、自動車事故死傷者数が減っている
- シートベルト法の導入と同時に、自動車事故死傷者数が減っている
状態空間モデルによる結果
コマンダー&クープマン(2008)では、以下の成分を含んだモデリングをおこなっている:
- 外部変数
log_petrol_price,seatbeltによる寄与(回帰係数は時間変化なし) - 確率的に変動する1年周期成分
- 確率的に変動するトレンド成分
log_drivers
log_petrol_price
seatbelt
where


1変数の ARIMA_PLUS モデルを作成
まずは、通常の ARIMA_PLUS で1変数でのモデリングを行なってみる。
モデル作成クエリ
CREATE MODEL
`ckbook.uk_drivers_first_trial` OPTIONS(MODEL_TYPE='ARIMA_PLUS',
time_series_timestamp_col='date',
time_series_data_col='log_drivers',
AUTO_ARIMA=TRUE, -- ARIMA(p,r,q)の次数p,r,qを自動で選択(AICを用いる)
HORIZON=10, --何手ステップまで予測するか
SEASONALITIES=["AUTO"], -- 季節性は自動で設定
DECOMPOSE_TIME_SERIES=TRUE -- EXPLAIN_FORECAST を利用するためには必須
) AS
SELECT
date,
log_drivers
FROM
`ckbook.uk_drivers_ksi`
作成したモデルの確認
モデル設定・パラメータの確認
SELECT
*
FROM
ML.ARIMA_EVALUATE(MODEL `ckbook.uk_drivers_first_trial`,
STRUCT(FALSE AS show_all_candidate_models))

ARIMA(p,d,q) 次数で d=1 なので、ドリフト項が入っている。
また、年単位の周期性もある。
一方で、step_changes はないと判断された。
係数
SELECT
*
FROM
ML.ARIMA_COEFFICIENTS(MODEL `ckbook.uk_drivers_first_trial`)

結果の取得と可視化
予測・推測結果
SELECT
*
FROM
ML.EXPLAIN_FORECAST(MODEL `ckbook.uk_drivers_first_trial`)

観測値と平滑化推定値

成分分解
トレンド成分

季節性分

考察
1983年2月付近でトレンド成分が急激に減少している。
Commandeur&Koopman2007 ではこれはシートベルト法の導入によるものとしてモデリングが行われていたが、BigQuery ML では step_changes ではなくトレンドの変化に吸収されていることがわかる。
ただし、観測値と平滑化推定値を比較すると同時期に大きな差が生じているので、
外部変数としてシートベルト法導入有無のダミー変数を指定することでより当てはまりの良いモデリングを行える可能性がある。
ARIMA_PLUS_XREG は何ができる?
外部変数を用いた多変数時系列モデルを作成できる。

上記の公式ドキュメント掲載の図を見ると、予測対象の変数に対して covatiates (共変量)を用いて回帰を行うらしい。
詳しくはわからないので筆者の解釈になるが、おそらくは回帰後の残差に対して ARIMA_PLUS と同様のモデル作成プロセスが走るのではないか。
多変数時系列モデルでは VAR (Vector Auto-Regression)モデルもよく知られるが、VARモデルと異なり予測対象の変数は1つだけである。
ARIMA_PLUS_XREG を用いてモデルを作成してみる(2変数)
https://zenn.dev/link/comments/aa2b0da9021f51 と同様にモデリングを行うが、今度は ARIMA_PLUS_REG を利用してシートベルト法導入有無を示すダミー変数 seatbelt をモデルに含めてみる。
モデル作成
CREATE MODEL
`ckbook.uk_drivers_xreg_seatbelt` OPTIONS(MODEL_TYPE='ARIMA_PLUS_XREG',
time_series_timestamp_col='date',
time_series_data_col='log_drivers',
AUTO_ARIMA=TRUE, -- ARIMA(p,r,q)の次数p,r,qを自動で選択(AICを用いる)
HORIZON=10, --何手ステップまで予測するか
SEASONALITIES=["AUTO"] -- 季節性は自動で設定
--DECOMPOSE_TIME_SERIES=TRUE -- XREGでは使用不可
) AS
SELECT
date,
log_drivers,
seatbelt
FROM
`ckbook.uk_drivers_ksi`
基本的には一変数のとき(ARIMA_PLUS)と同様に行うが、SELECT 分で選択したカラムのうち time_series_timestamp_col, time_series_data_col で選択しなかったものが外部変数としてモデルに組み込まれる。
なお、ARIMA_PLUS では DECOMPOSE_TIME_SERIES=TRUEを指定することでML.EXPLAIN_FORECASTによりトレンド成分・季節成分やフィルタリング値も取得できたが、ARIMA_PLUS_REG では DECOMPOSE_TIME_SERIES オプションがサポートされていない(2023/06/26時点)。
作成したモデルの確認
モデル設定・パラメータの確認
SELECT
*
FROM
ML.ARIMA_EVALUATE(MODEL `.ckbook.uk_drivers_xreg_seatbelt`,
STRUCT(FALSE AS show_all_candidate_models))

ARIMA_PLUS と同様にして取得可能。
なお、AIC は -550.188であり、ARIMA_PLUS で作成した一変数モデルにおける-529.793より小さくなっている。
係数
SELECT
*
FROM
ML.ARIMA_COEFFICIENTS(MODEL `ckbook.uk_drivers_xreg_seatbelt`)
ARIMA_PLUS のときと同様、ML.ARIMA_COEFFICEINTS で次数・係数を取得可能。

外部変数で回帰を行った際の係数もこちら確認することができる。
今回で言うと、ダミー変数 seatbelt の係数の値は -0.179 とある。
シートベルト法の導入により交通事故による死傷者数が
この係数についての分散が分かれば seatbelt の効果が統計的に有意か判断できそうだが、そこまではわからないらしい。
結果の取得
冒頭で述べたとおり、2023/06/27現在 ARIMA_PLUS_REG では DECOMPOSE_TIME_SERIES オプションを指定できず、ML.EXPLAIN_FORECAST を実行できない。
したがって、平滑化推定値や成分分解の可視化を行うことはできない。
-- 実行不可
SELECT
*
FROM
ML.EXPLAIN_FORECAST(MODEL `ckbook.uk_drivers_xreg_seatbelt`)

ARIMA_PLUS_XREG による予測(ML.FORECAST)
SELECT
*
FROM
ML.FORECAST(MODEL `ckbook.uk_drivers_xreg_seatbelt`,
STRUCT(10 AS horizon),
(
SELECT
date,
s.seatbelt
FROM
UNNEST( GENERATE_DATE_ARRAY(DATE('1985-01-28'), DATE('1985-10-28'), INTERVAL 1 MONTH) ) AS date,
(
SELECT
1 AS seatbelt) AS s ))
ARIMA_PLUSの時と異なり、予測時にもデータを与える必要がある。
上記のように MODEL, STRUCT() に続く三番目の引数にクエリを記述して予測対象期間のタイムスタンプと外部変数を与える。
なお、予測パラメータ(horizon, confidence_level)を指定する必要がない場合でも、MODELに続く二番目の引数に空のSTRUCT() を記述しておく必要がある。
予測結果

補足: 外部変数で回帰した際の係数・切片は、線形回帰した際の回帰係数・切片と一致するか?
A. しない。
線形回帰
ダミー変数seatbelt で死傷者数の単回帰モデルを作成してみた。
CREATE MODEL
`ckbook.uk_drivers_linear_reg` OPTIONS ( MODEL_TYPE='LINEAR_REG',
DATA_SPLIT_METHOD="NO_SPLIT",
ENABLE_GLOBAL_EXPLAIN=TRUE,
CALCULATE_P_VALUES=TRUE,
FIT_INTERCEPT=TRUE,
CATEGORY_ENCODING_METHOD="DUMMY_ENCODING" ) AS
SELECT
log_drivers AS label,
seatbelt
FROM
`ckbook.uk_drivers_ksi`
結果:[1]
SELECT
*
FROM
ML.ADVANCED_WEIGHTS(MODEL `ckbook.uk_drivers_linear_reg`)

回帰係数: -0.261
切片: 7.44
ARIMA_PLUS_XREG との比較
ARIMA_PLUS_REG で 外部変数としてseatbeltを用いた際の係数・切片は以下であった:
係数: -0.179
切片: 7.09
これは、上記の(通常の)線形回帰における結果と異なっている。
したがって、ARIMA_PLUS_XREG では通常の線形回帰とは異なる方法で係数と切片を算出しているらしい。
なお、回帰後の残差を比べると以下のようになる:
線形回帰

ARIMA_PLUS_XREG

ARIMA_PLUS_XREG における回帰では、残差が正の値をとるようになっている。
(どのようなロジックで係数・切片を決定しているのだろうか?)
参考
BQMLにおける線形回帰は以下を参照:
-
念の為 Python の statsmodels を用いて実行した結果(Deterministic Level and Intervention Variable)と比較したところ、係数・切片共に一致していた。 ↩︎
ARIMA_PLUS_XREG で成分分解をしてみる
以下で述べたように、ARIMA_PLUS_XREG では ML.EXPLAIN_FORECAST を用いて分解成分ごとの推定値を取得することができない。
しかし、以下で見たように、外部変数による回帰を行なった後は通常の ARIMA_PLUS と同じ手順でモデル作成を行なっているので、外部変数による寄与をあらかじめ差っ引いてから ARIMA_PLUS を適用すれば ML.EXPLAIN_FORECAST を利用して成分分解を取得できるのではと考え、試してみた。
モデル作成
以前 ARIMA_PLUS_XREG でモデル作成した際に得られた回帰係数・切片の値を用いて、ダミー変数 seatbelt の寄与をあらかじめ除去した。
そのうえで残った成分にたいして ARIMA_PLUS でモデルを作成した。
CREATE OR REPLACE MODEL
`ckbook.uk_drivers_reg_resid` OPTIONS(MODEL_TYPE='ARIMA_PLUS',
time_series_timestamp_col='date',
time_series_data_col='log_drivers_reg_resid',
AUTO_ARIMA=TRUE, -- ARIMA(p,r,q)の次数p,r,qを自動で選択(AICを用いる)
HORIZON=10, --何手ステップまで予測するか
SEASONALITIES=["AUTO"], -- 季節性は自動で設定
DECOMPOSE_TIME_SERIES=TRUE -- EXPLAIN_FORECAST を利用するためには必須
) AS
SELECT
date,
-- seatbelt による寄与を差し引いて残った成分を目的変数としてモデリングを行う
log_drivers + 0.1786694455089741 * seatbelt - 7.0878200984565707 AS log_drivers_reg_resid,
FROM
`ckbook.uk_drivers_ksi`
作成したモデルの確認
次数や係数が下記にて ARIMA_PLUS_XREG で作成した時のものと一致していることを確認した。
次数・AIC
SELECT
*
FROM
ML.ARIMA_EVALUATE(MODEL `.ckbook.uk_drivers_reg_resid`,
STRUCT(FALSE AS show_all_candidate_models))

係数
SELECT
*
FROM
ML.ARIMA_COEFFICIENTS(MODEL `ckbook.uk_drivers_reg_resid`)

成分分解
ML.EXPLAIN_FORECAST で平滑化推定値、周期成分、トレンド成分などを取得した。
ただし、ここで表示されるのは観測値(と予測値)は外部変数の寄与を差し引いた後のものなので、
差し引く前の値と外部変数の値を得るために元データを結合した。
SELECT
*
FROM
ML.EXPLAIN_FORECAST(MODEL `ckbook.uk_drivers_reg_resid`) exp
LEFT JOIN
`ckbook.uk_drivers_ksi` ksi
ON
DATE_TRUNC(DATE(exp.time_series_timestamp), MONTH) = DATE_TRUNC(ksi.date, MONTH)
観測値と平滑化推定値
time_series_adjusted_data で得られる値は、外部変数による寄与を差し引いた残差に対しての平滑化推定値である。
そのため、観測値と比較するために平滑化推定値に外部変数による寄与(-0.179 * seatbelt + 7.09)を加えた。

トレンド成分と周期成分と残差
トレンド成分

トレンド成分 + 外部変数の寄与

周期成分
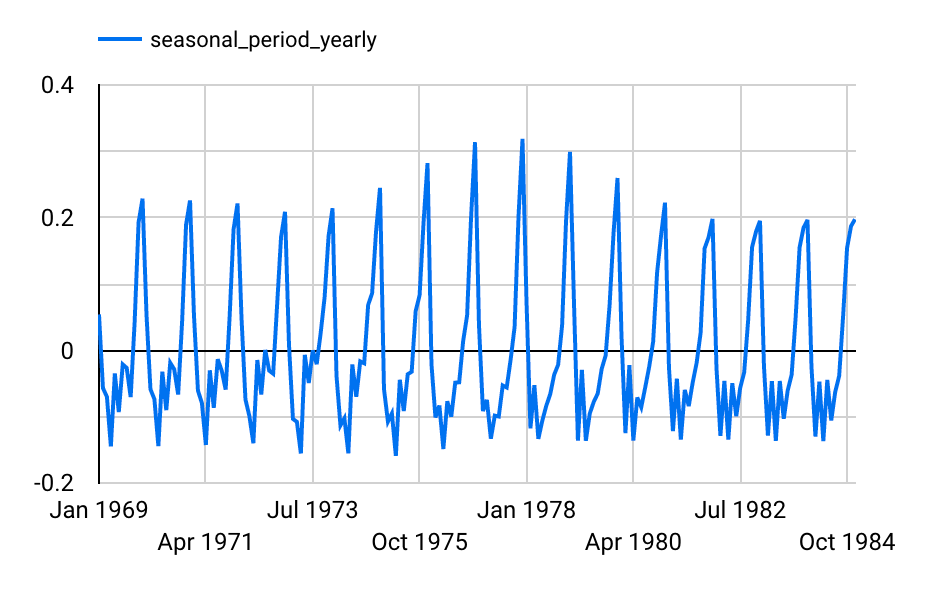
残差

まとめ
やや面倒だが ARIMA_PLUS_XREG でモデル作成後に再度 ARIMA_PLUS でモデル作成を行うことで、外部変数を用いたモデリングでも成分分解を(半ば無理やり)取得できることがわかった。
同様にして、異常検知(ML.DETECT_ANOMALIES)も実行できるはずである。
面倒とはいえそこまでそこまで複雑な処理が必要なわけでもないので、遠からずのうちに ARIMA_PLUS_XREG でも ML.EXPLAIN_FORECAST が実行できるようになることを期待する。
※2023/07/21追記
ARIMA_PLUS_XREG が GA になると同時に、ML.EXPLAIN_FORECAST もできるようになったみたいです。
近日中に試して再度紹介します。
補足: 外部変数を2つ使った時系列モデリング
これまでは目的変数として死傷者数、外部変数としてシートベルト法の実施(ダミー変数)を用いた2変数の時系列モデリングをおこなってきた。
同様にして外部変数を増やしてモデルを構築することができる。
手順等はこれまでと同じなので、簡単に試した結果を紹介する。
モデル作成
以前作成したモデル からの変更点は、
外部変数として seatbelt に加えて log_petrol_price(石油価格に対数をとったもの)を加えたことである。
CREATE MODEL
`ckbook.uk_drivers_xreg_seatbelt_and_petrolprice` OPTIONS(MODEL_TYPE='ARIMA_PLUS_XREG',
time_series_timestamp_col='date',
time_series_data_col='log_drivers',
AUTO_ARIMA=TRUE, -- ARIMA(p,r,q)の次数p,r,qを自動で選択(AICを用いる)
HORIZON=10, --何手ステップまで予測するか
SEASONALITIES=["AUTO"] -- 季節性は自動で設定
--DECOMPOSE_TIME_SERIES=TRUE -- XREGでは使用不可
) AS
SELECT
date,
log_drivers,
log_petrol_price, -- 石油価格に対数をとったもの
seatbelt,
FROM
`ckbook.uk_drivers_ksi`
作成したモデルの確認
次数・AICほか
SELECT
*
FROM
ML.ARIMA_EVALUATE(MODEL `.ckbook.uk_drivers_xreg_seatbelt_and_petrolprice`,
STRUCT(FALSE AS show_all_candidate_models))

(疑問: non_seasonal_d=1 にもかかわらず has_drift=False と出ている。なぜだろうか?)
係数
SELECT
*
FROM
ML.ARIMA_COEFFICIENTS(MODEL `ckbook.uk_drivers_xreg_seatbelt_and_petrolprice`)
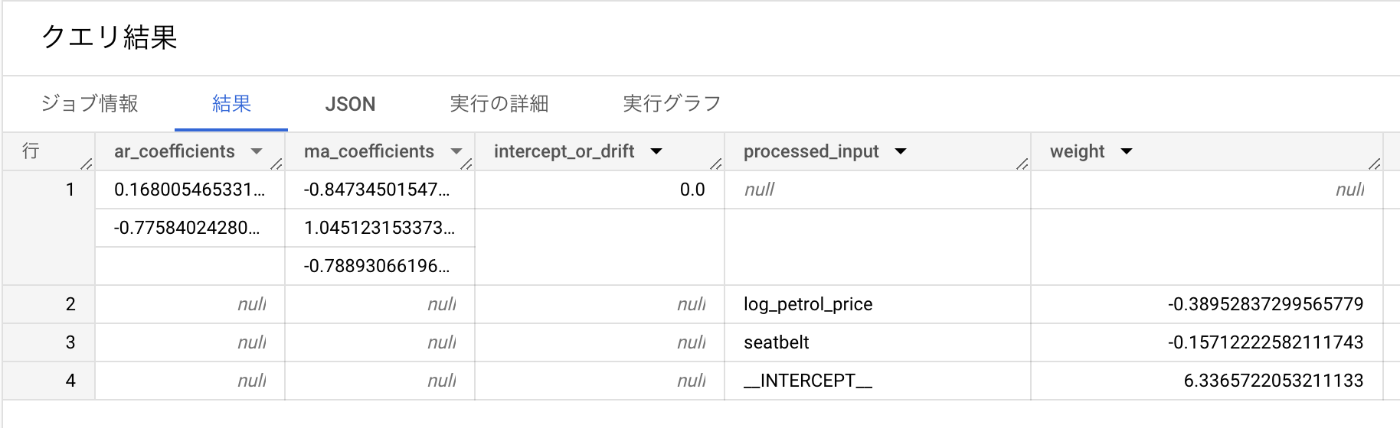
外部変数による寄与は
-0.390 * log_petrol_price - 0.157 * seatbelt + 6.34
と表されることがわかる。
(疑問:intercept_or_drift=0と出ている。だったらなぜ``non_seasonal_d=0`にしなかったのだろう?)
成分分解
以前紹介したように、 ARIMA_PLUS で外部変数の寄与を差し引いたモデルを作り直した:
CREATE OR REPLACE MODEL
`ckbook.uk_drivers_xreg_resid_seatbelt_and_petrolprice` OPTIONS(MODEL_TYPE='ARIMA_PLUS',
time_series_timestamp_col='date',
time_series_data_col='log_drivers_reg_resid',
AUTO_ARIMA=TRUE,
-- ARIMA(p,r,q)の次数p,r,qを自動で選択(AICを用いる)
HORIZON=10,
--何手ステップまで予測するか
SEASONALITIES=["AUTO"],
-- 季節性は自動で設定
DECOMPOSE_TIME_SERIES=TRUE -- EXPLAIN_FORECAST を利用するためには必須
) AS
SELECT
date,
log_drivers + 0.38952837299565779 * log_petrol_price + 0.15712222582111743 * seatbelt - 6.3365722053211133 AS log_drivers_reg_resid,
FROM
`ckbook.uk_drivers_ksi`
そのうえで、平滑化推定値と分解成分を取得した:
SELECT
*
FROM
ML.EXPLAIN_FORECAST(MODEL `ckbook.uk_drivers_xreg_resid_seatbelt_and_petrolprice`) exp
LEFT JOIN
`ckbook.uk_drivers_ksi` ksi
ON
DATE_TRUNC(DATE(exp.time_series_timestamp), MONTH) = DATE_TRUNC(ksi.date, MONTH)
観測値と平滑化推定値

成分分解(トレンド成分、周期成分、残差)
トレンド成分

トレンド成分+外部変数の寄与

周期成分

残差

GA になった ARIMA_PLUS_XREG で ML.EXPLAIN_FORECAST を実行してみる
2023/07/21に ARIMA_PLUS_XREG が GA(Generally Available)となり、同時に今まで使えなかった ML.EXPLAIN_FORECAST() によるモデル説明にも対応した。
そこで、早速試してみる。
モデル作成
これまでと同様にモデル作成を行う:
CREATE MODEL
`ckbook.uk_drivers_xreg_seatbelt_ga` OPTIONS(MODEL_TYPE='ARIMA_PLUS_XREG',
time_series_timestamp_col='date',
time_series_data_col='log_drivers',
AUTO_ARIMA=TRUE, -- ARIMA(p,r,q)の次数p,r,qを自動で選択(AICを用いる)
HORIZON=10, --何手ステップまで予測するか
SEASONALITIES=["AUTO"] -- 季節性は自動で設定
-- DECOMPOSE_TIME_SERIES=TRUE -- XREGでは指定不要
) AS
SELECT
date,
log_drivers,
seatbelt
FROM
`ckbook.uk_drivers_ksi`
ARIMA_PLUS では ML.EXPLAIN_FORECAST() の実行に必須だったオプション DECOMPOSE_TIME_SERIES は依然と指定できない。
しかし、指定なしでも default で ML.EXPLAIN_FORECAST() を実行できるようになっていた。
作成したモデルの確認
ML.ARIMA_EVALUATE() による次数と評価指標の表示と、ML.ARIMA_COEFFICIENTS() による係数の表示。
モデル次数・パラメータの確認
これまでと同様に実行できる。
細かいところではあるが、 log likelihood や AIC などの数値が微妙に以前と異なっている。
SELECT
*
FROM
ML.ARIMA_EVALUATE(MODEL `.ckbook.uk_drivers_xreg_seatbelt_ga`,
STRUCT(FALSE AS show_all_candidate_models))

係数
SELECT
*
FROM
ML.ARIMA_COEFFICIENTS(MODEL `ckbook.uk_drivers_xreg_seatbelt_ga`)

こちらもこれまでと同様に実行できる。
前述の ML.ARIMA_EVALUATE() と同様に数値に僅かな差があることに加えて、
出力のレイアウトも少し異なっている。
以前は外部変数の回帰係数・切片の方が ARIMA 係数より先の行に来ていたが、現在では ARIMA 係数の方が先に来ている。
モデル説明(成分分解表示)
以下に示すよう、ML.FORECAST() 実行時と同様に外部変数の予測期間における値を与える必要がある:
SELECT
*
FROM
ML.EXPLAIN_FORECAST(MODEL `ckbook.uk_drivers_xreg_seatbelt_ga`,
STRUCT(10 AS horizon),
(
SELECT
date,
s.seatbelt
FROM
UNNEST( GENERATE_DATE_ARRAY(DATE('1985-01-28'), DATE('1985-10-28'), INTERVAL 1 MONTH) ) AS date,
(
SELECT
1 AS seatbelt) AS s ))
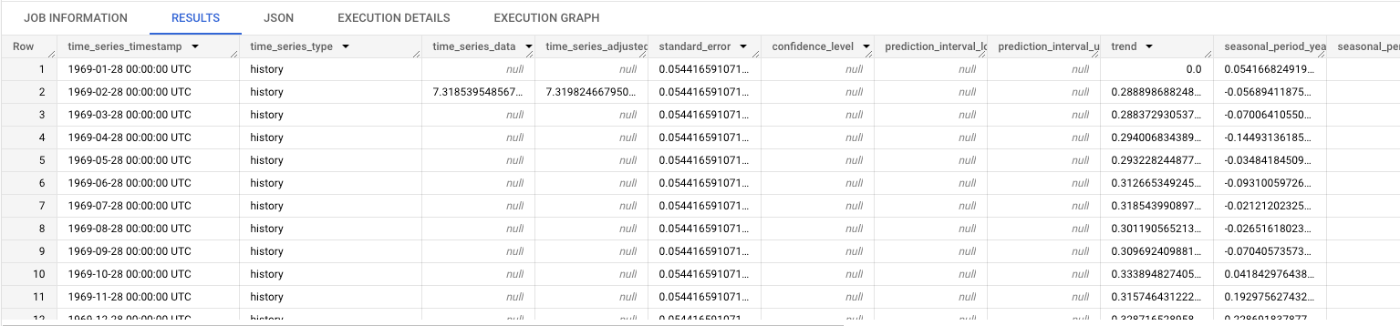
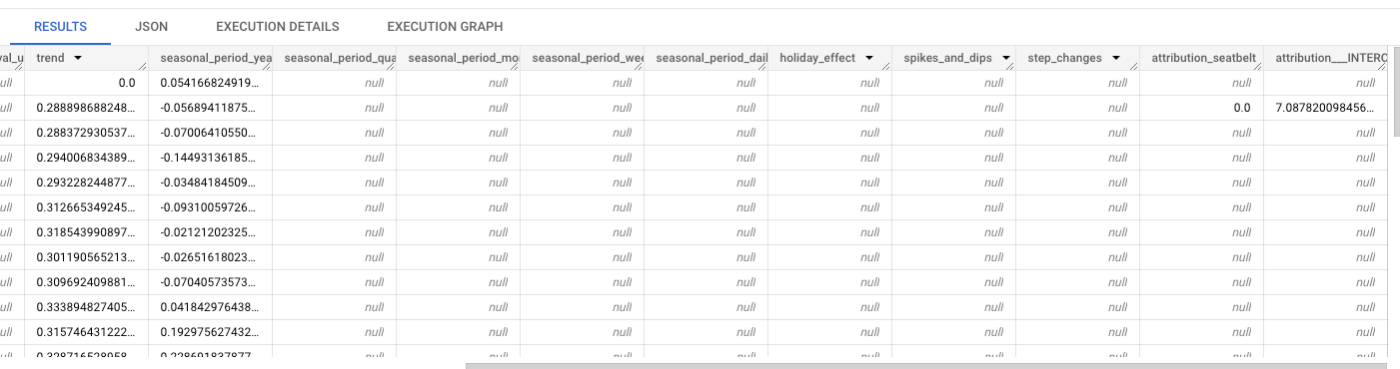
ARIMA_PLUS_XREG では、外部変数による寄与も表示されるようになったのが嬉しい。
意外なことに、観測値(入力データ)が入っているはずの time_series_data カラムの大半が NULL になっている。
これはおそらく、モデルを作る過程でタイムスタンプの間隔が揃えられたことで、
実データが存在する日付しかデータが表示されなくなったためだろう。
実際、元々の 'date' カラムには月末の日付(1969-01-31, 1969-02-28, 1969-03-31, 1969-04-30, ...) が入っていたが、予測では全て28日に揃えられている。
このため、閏年でない2月のデータ以外は time_series_data が表示され無くなったと考えられる。
これまでの ARIMA_PLUS の ML.EXPLAIN_FORECAST 時には、タイムスタンプの間隔に入力データから変更があってもそのまま元の入力データの値が表示されていたので、やや不便に感じる:
SELECT
*
FROM
ML.EXPLAIN_FORECAST(MODEL `ckbook.uk_drivers_xreg_resid_seatbelt_and_petrolprice`) exp
LEFT JOIN
`ckbook.uk_drivers_ksi` ksi
ON
DATE_TRUNC(DATE(exp.time_series_timestamp), MONTH) = DATE_TRUNC(ksi.date, MONTH)

補足: GA以前に作成したモデルで ML.EXPLAIN_FORECAST() を試してみる。
実行できなかった。再学習しろとのこと。
# ERROR につき実行不可能
SELECT
*
FROM
ML.EXPLAIN_FORECAST(MODEL `ckbook.uk_drivers_xreg_seatbelt`,
STRUCT(10 AS horizon),
(
SELECT
date,
s.seatbelt
FROM
UNNEST( GENERATE_DATE_ARRAY(DATE('1985-01-28'), DATE('1985-10-28'), INTERVAL 1 MONTH) ) AS date,
(
SELECT
1 AS seatbelt) AS s ))
Invalid table-valued function ML.EXPLAIN_FORECAST Model
does not have feature contribution information.
To use ML.EXPLAIN_FORECAST, please re-train the model. at [4:3]