BigQuery ML による時系列解析(ARIMA_PLUS)
TODO:
- x: EVALUATE
-
ML.ARIMA_EVALUATEとは別。 - https://cloud.google.com/bigquery/docs/reference/standard-sql/bigqueryml-syntax-evaluate
-
- x: DECOMPOSE
- x: EXPLAIN_FORECAST
- x: パラメータ(特に次数)の取得方法
- x: 学習期間についてフィルタリング値を取得できるか?
- 異常検知に使えるか?
- x: 実データ + 予測値を並べる
- x: 祝日効果を陽に指定してみる
- → 無理。それらしきオプションはなかった。祝日効果の有無は自動で判断させるしかないらしい。
- [ ]: 別データで、
step_changesなども見てみる - [ ]: 数式との対応づけ
- ARIMA については https://zenn.dev/tatamiya/scraps/d9628437dd93ee も参照
- [ ]: 成分分解アルゴリズムについて調べる
- x:
ARIMA_PLUS_XREGを試してみる - x: 料金
モデル作成方法
CREATE(基本形)
-
OPTIONSでMODEL_TYPE='ARIMA_PLUS'を指定する -
TIME_SERIES_TIMESTAMP_COLで時刻・日付などのカラム名を指定する -
TIME_SERIES_DATA_COLで予測したい値のカラム名を指定する
CREATE MODEL `project_id.mydataset.mymodel`
OPTIONS(MODEL_TYPE='ARIMA_PLUS',
time_series_timestamp_col='date',
time_series_data_col='transaction') AS
SELECT
date,
transaction
FROM
`mydataset.mytable`
予測ステップ数
HORIZONで指定する。
次数の選択と指定
ARIMA(p,d,q) モデルの次数(p,d,q)は、自動で選択することも手動で指定することもできる。
自動で選択する
AUTO_ARIMA=TRUE を指定すればよい。
モデル選択は AIC をもとに行う。
なお、次数p,qについては最大値を AUTO_ARIMA_MAX_ORDER で指定できる。
手動で指定する
NON_SEASONAL_ORDER=(p,d,q) のように指定する。
季節性
SEASONALITIESで文字列リストにより指定する。
選択肢は、NO_SEASONALITY, AUTO, DAILY, WEEKLY など
祝日の扱い
HOLIDAY_REGION で地域を指定する。
日本なら、
HOLIDAY_REGION="JP"
リストによって複数指定することも可能。
予測値の取得(FORECAST)
SELECT
*
FROM
ML.FORECAST(MODEL `<project-id>.<dataset>.<model-mane>`,
STRUCT(30 AS horizon, 0.95 AS confidence_interval))
オプション
-
horizon: 何ステップ先まで予測するかを指定する。-
CREATE MODELの同名オプションで指定した値が上限となる(モデル構築時点で予測まで行われているため)。
-
-
confidence_interval: 信頼区間の指定(default では 95%)
出力値(抜粋)
-
forecast_timestamp: タイムスタンプ -
forecast_value: 予測値 -
prediction_interval_lower_bound: 予測の信頼区間下限-
confidence_interval_lower_boundは同内容だが、deprecated
-
-
prediction_interval_upper_bound: 予測の信頼区間上限-
confidence_interval_upper_boundは同内容だが、deprecated
-

予測例

(なお、上記の入力データは count データなので本来は負の値になることはない。この点を考慮するには一般化線形問題に拡張してポアソン分布などを仮定する必要があるが、現状のBQMLではそこまでのことはできない認識。)
EXPLAIN_FORECAST(成分分解)
時系列の成分分解や、訓練期間のデータ(観測値)のフィルタリング値を取得できる。
それ以外の内容については、FORECAST で出力したものと同一。
モデル作成時にオプションで DECOMPOSE_TIME_SERIES=TRUE を指定した場合のみ利用可能。
SELECT
*
FROM
ML.EXPLAIN_FORECAST(MODEL `mydataset.mymodel`,
STRUCT(30 AS horizon, 0.95 AS confidence_level))
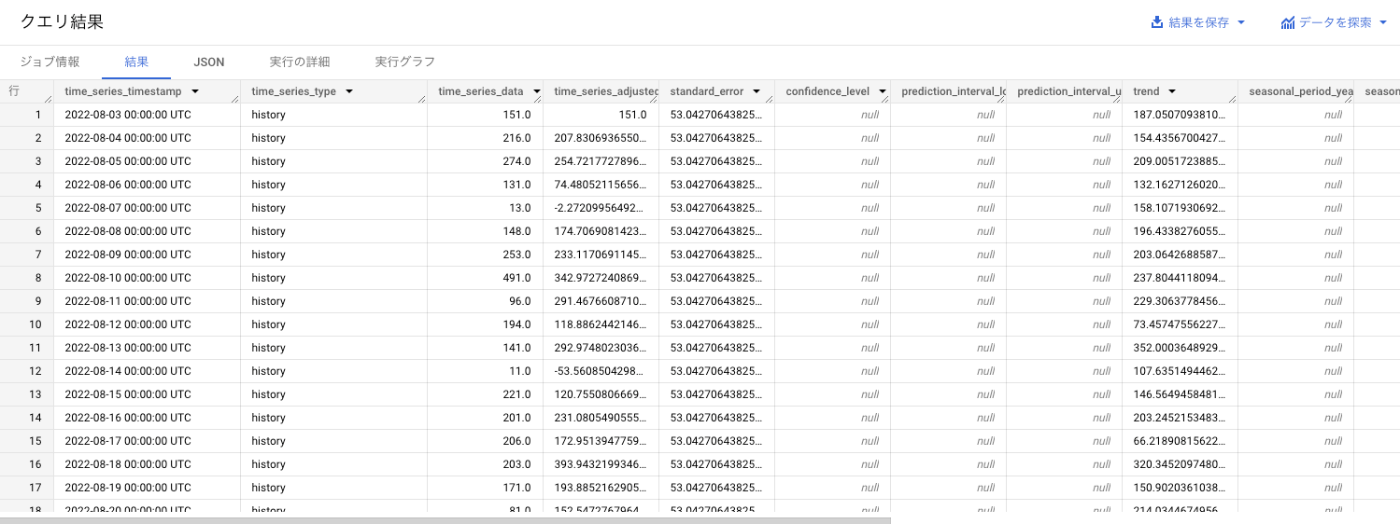
出力値(抜粋)
基本
-
time_series_timestamp: タイムスタンプ列 -
time_series_type: history(観測値) ・ forecast(予測値)の種別
データ数値・標準誤差
time_series_type が history が forecast によって、入っている値が異なる場合がある。
| カラム名 | 概要 | history | forecast |
|---|---|---|---|
time_series_data |
データ数値列 | 観測値(入力データ) | 予測値 |
time_series_adjusted_data |
分解成分の和 |
time_series_dataから残差を差し引いた値 |
time_series_dataと同一の値 |
standard_error |
標準誤差 | (おそらく)フィルタリング標準誤差 | 予測標準誤差 |
prediction_interval_{lower / upper}_bound |
予測値信頼区間の下限・上限 | NULL | 下限値・上限値 |
分解成分
時系列を成分分解した結果が入るカラム。
どの成分に値が入るかは、モデルの設定による。
(CREATE時にSEASONALITIES="AUTO"とした場合は、BQ側で自動的に検出してくれるという理解。)
-
trend: トレンド成分 -
seasonal_period_{yearly / quarterly / monthly / weekly / daily}: 周期成分 -
holiday_effect: 祝日効果
そのほかに、以下のような内容も含まれることがある(未調査):
-
spikes_and_dips: step_changes
成分分解の例
観測値(or 予測値) = トレンド (trend) + 週単位の周期成分 (seasonal_period_weekly) + 残差
に分解される場合は、以下のようになる:
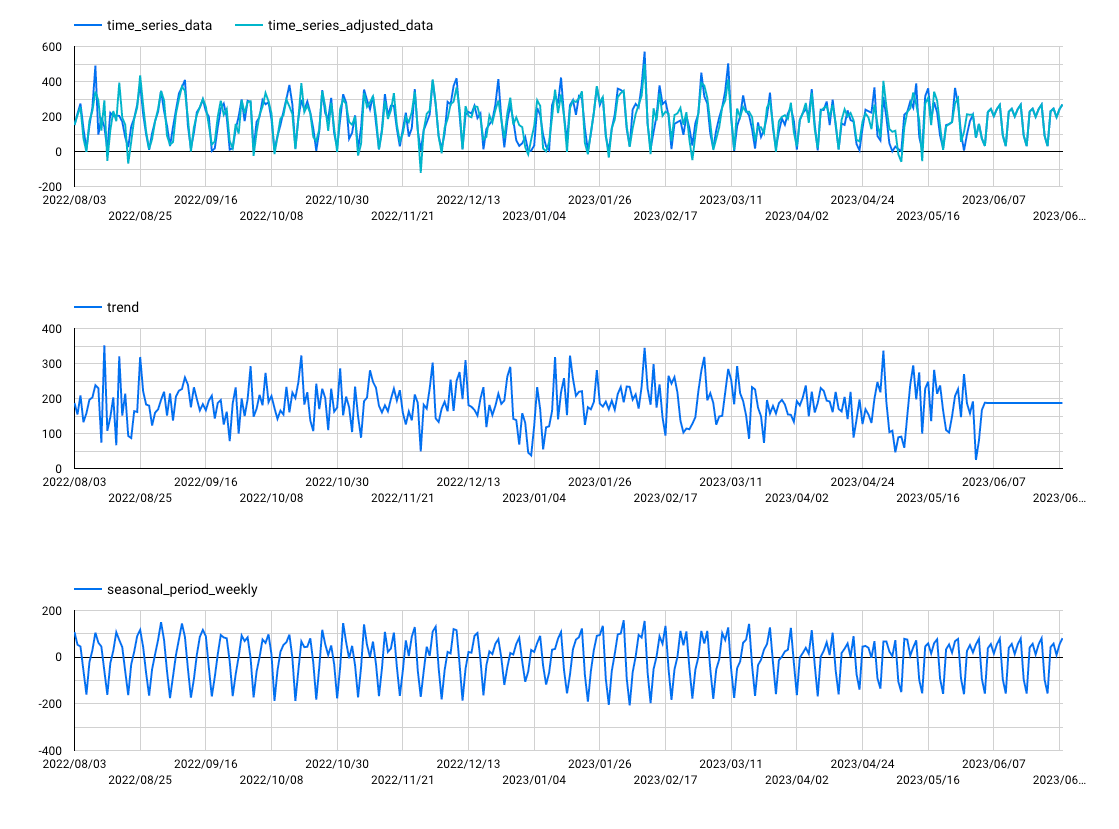
なお、この場合、
time_series_adjusted_data = trend + seasonal_period_weekly
に一致する。
残差分析
残差(residual)はカラムとしては存在しないが、
residual = time_series_data - time_series_adjusted_data
として取得することができる。
さらに、標準誤差(standard_error)をもとに信頼区間を表示したものが以下:

upper bound, lower bound は、以下のように算出した:
upper bound = standard_error *
lower bound = -standard_error *
ここで、
この内容をもとに異常検知のようなこともできそうだが、もしかしたら spikes_and_dips を用いた方が良いかもしれない。
異常検知(ML.DETECT_ANOMALIES)
https://zenn.dev/link/comments/8ecb9c45c4de02 の「残差分析」の項で述べた異常検知と同様のことをBQの関数を用いて簡易に実行できる。
特に、観測値(EXPLAIN_FORECASTのときでいうtime_series_type="history")に対して判定を行う場合は、入力データを指定することなく実行できる。
(ただし、EXPLAIN_FORECASTと同様 CREATE 時にDECOMPOSE_TIME_SERIES=TRUEオプションは必要。)
SELECT
*
FROM
ML.DETECT_ANOMALIES(MODEL `mydataset.my_arima_plus_model`,
STRUCT(0.95 AS anomaly_prob_threshold) -- 閾値。DEFAULT は 0.95
)
出力内容
- (
time_series_timestamp): タイムスタンプ。入力データのカラム名が用いられる。 - (
time_series_data): データ数値。入力データのカラム名が用いられる。 -
lower_bound: 信頼区間の下限。- 信頼係数は実行時の引数
anomaly_prob_thresholdによって決まる。
- 信頼係数は実行時の引数
-
upper_bound: 同上限。 -
anomaly_probability: 異常値である確率。- 観測値がフィルタリング値から離れるほど大きくな値を取る。
-
is_anomaly: 異常値かどうかを TRUE / FALSE で表したもの。- 実行時に
0.95 AS anomaly_prob_thresholdとしていた場合、anomaly_probability>0.95なら TRUE となる。
- 実行時に
実行例
異常値を赤ドットで表示した(異常値以外については値0に赤ドットが表示されてしまっている)。
観測値が upper_bound / lower_bound から外れた部分は異常値として判定されていることがわかる。

異常値率。0.95を超えたら異常値と見做される。

係数の取得(ML.ARIMA_COEFFICIENTS)
ARIMA の係数を取得できる。
SELECT
*
FROM
ML.ARIMA_COEFFICIENTS(MODEL `mydataset.mymodel`)
実行例

備考
モデル設定によっては weight, category_weights というカラムも出力されるらしい。
(どう言う条件?どういう用途?)
次数含むモデル学習情報の取得(ML.ARIMA_EVALUATE)
ML.ARIMA_EVALUATE を用いれば、モデル学習情報(次数、尤度、AIC、分散など)を取得できる。
(XGBoost等の機械学習モデルにおける ML.EVALUATE と異なり、データを入力して精度評価を行うことはできない。)
SELECT
*
FROM
ML.ARIMA_EVALUATE(MODEL `mydataset.mymodel`, STRUCT(FALSE AS show_all_candidate_models))
実行時に FALSE AS show_all_candidate_models を指定すれば、パラメータチューニングで選択された最良モデルのみが表示される。
したがって、次数を知りたい場合はこれを用いる。
Default では TRUE AS show_all_candidate_modelsで、この場合 AUTO_ARIMA でチューニングを行った際の試行結果が全て表示される。
この場合、コンソール上で表示される内容と異なり、エラーにより学習できなかったものも表示してくれる。
実行結果例
FALSE AS show_all_candidate_models
今回の場合、最良モデル ARIMA(p,r,q) の指数は、p=1, r=0, q=4 であることがわかる。

TRUE AS show_all_candidate_models

予測誤差の評価 (ML.EVALUATE)
ML.EVALUATE を用いれば、予測値と実際の値の誤差評価を行うことができる。
SELECT
*
FROM
ML.EVALUATE(MODEL `mydataset.my_arima_model`,
(
SELECT
timeseries_date,
timeseries_metric
FROM
`mydataset.mytable`),
STRUCT(TRUE AS perform_aggregation, 30 AS horizon))
perform_aggregation を TRUE に指定すると、予測期間全体での誤差評価がなされる。
perform_aggregation を FALSE の場合、予測期間各タイムスタンプごとに評価値が出力される。
なお、学習時に入力した期間のデータ(time_series_type="history" に対応)については、評価に用いられない。
予測期間のみが評価対象となる。
実行例
FALSE AS perform_aggregation
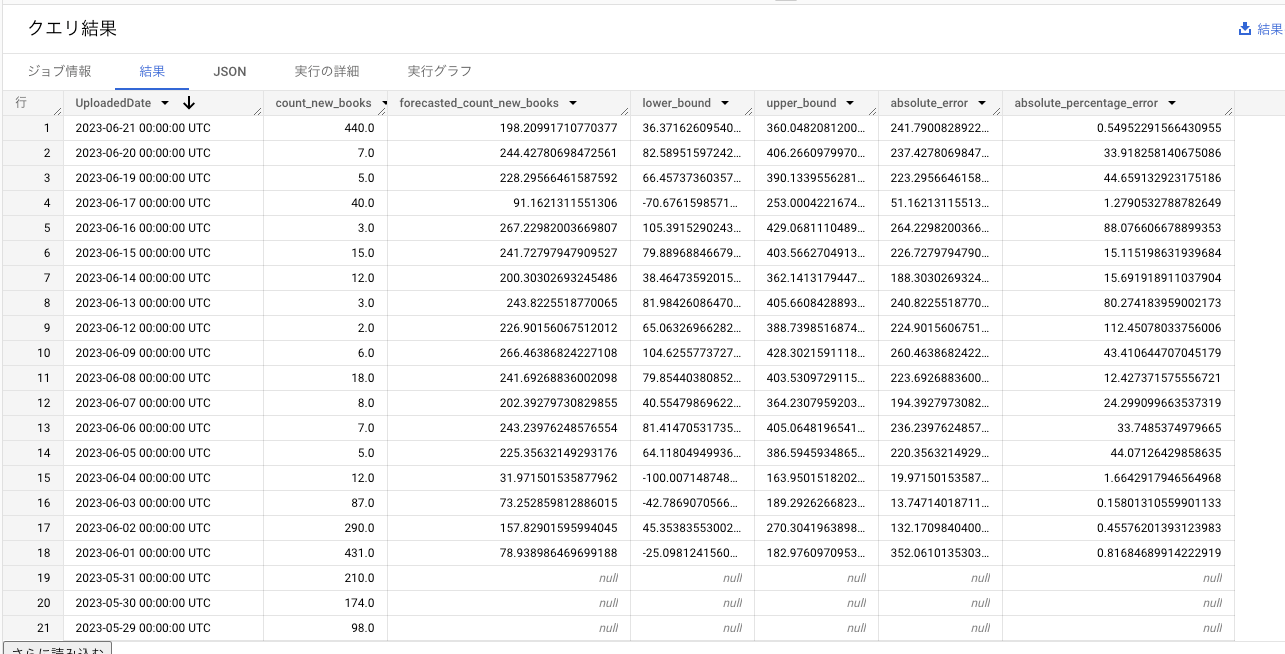
-
time_series_timestamp_col: タイムスタンプ列 -
time_series_data_col: 実データ -
forecasted_time_series_data_col: 予測値 -
lower_bound: 信頼区間下端 -
upper_bound: 信頼区間上端 -
absolute_error: 絶対誤差- |
time_series_data_col-forecasted_time_series_data_col|
- |
-
absolute_percentage_error: 絶対パーセント誤差- |
time_series_data_col-forecasted_time_series_data_col| / |time_series_data_col|
- |
TRUE AS perform_aggregation

-
mean_absolute_error: 平均絶対誤差 -
mean_squared_error: 平均二乗誤差 -
root_mean_squared_error: 二乗平均平方根誤差 -
mean_absolute_percentage_error: 平均絶対パーセント誤差 -
symmetric_mean_absolute_percentage_error: 対称平均絶対パーセント誤差- 定義はこちらを参照
それぞれ、FALSE AS perform_aggregation の場合と以下のように対応する
SELECT
AVG(absolute_error) AS mean_absolute_error,
AVG(absolute_error * absolute_error) AS mean_squared_error,
SQRT(AVG(absolute_error * absolute_error)) AS root_mean_squared_error,
AVG(absolute_percentage_error) * 100 AS mean_absolute_percentage_error,
AVG(2 * absolute_error / (ABS(timeseries_metric) + ABS(forecasted_timeseries_metric))) * 100 AS symmetric_mean_absolute_percentage_error
FROM
ML.EVALUATE(MODEL `mydataset.my_arima_model`,
(
SELECT
timeseries_date,
timeseries_metric
FROM
`mydataset.mytable`),
STRUCT(FALSE AS perform_aggregation))
補足
入力データを与えずに実行した場合、モデルの学習情報が表示される。
要するに、ML.ARIMA_EVALUATE で TRUE AS show_all_candidate_models とするのと同じ。
(こちらの使い方は Deprecated とのことなので、学習情報の取得は ML.ARIMA_EVALUATE の方を使うべき。)
BQML の ARIMA_PLUS はどのようにモデルを作っているか?
詳細な記述は見つからなかったが、公式ドキュメントの以下のパイプライン図が参考になりそう:

この図をもとに解釈すると、以下のように順次処理を行なっていると読める:
- 前処理
- 祝日効果の調整
- スパイクやdipといった急激な変化や異常値の除去(クリーニング)
- 季節変動・トレンドの分解(STL)
- 季節変動のみ差し引く
- ステップ状変化の調整
- ARIMA によるトレンドのモデル化
trend 成分の内容
上記で気になったのは、ML.EXPLAIN_FORECAST で取得できる trend 成分がどのように算出されたものなのか、ということ。
途中で STL により「季節変動 + トレンド + 残差」に成分分解されているものの、上記の図をみる限り、ここで出てきたトレンド成分は以降のモデリングでは使用していない模様。
代わりに、季節変動とステップ変化諸々を差し引いて残った成分を「トレンド + 残差」と見做し、これをもとに作成した ARIMA モデルから算出したフィルタリング値を最終的な trend として出力していそうである。
料金体系
データ処理量に応じて課金される。

1TBごとに$250、ただし月10GBまでのCREATEは無料。
なお、AUTO_ARIMA=TRUEオプションで次数を自動選択した場合は、データ処理量×候補モデル数が課金判定の対象になる。