Python でデータサイエンスに入門するぜ
Data Science とは?
データを用いて新たな科学的および社会に有益な知見を引き出そうとするアプローチのことであり、その中でデータを扱う手法である情報科学、統計学、アルゴリズムなどを横断的に扱う。
データサイエンス - Wikipedia
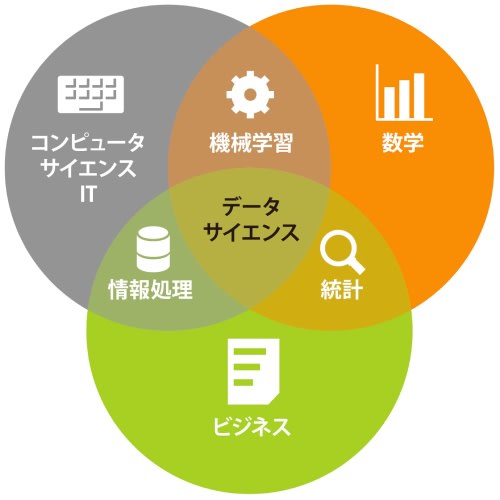
構成要素としては以下のようなものがある。
- プログラミング
- データ分析
- 視覚化
- 数学
- 統計学
- 機械学習
- ドメイン知識
ざっくり分けると CS, Mathematics, Business のスキルが必要。
前提
自身の状況をまとめる。
- プログラミング関連
- Python はまったくの未経験
- プログラミング初心者ではないため CLI とか Git とかは問題なく使える
- CS は一通り理解しているつもり
- 数学関連
- 数学・統計学・機械学習の知識は多少ある
- 開発端末
- macOS 12.4
アルゴリズムを試したり簡単な実験ができるレベルになることが目的。
Data Science の学び方を学ぶ
ざっと調べた感じ、以下の順で学ぶのがオススメらしい。
- Python を学ぶ
- 数学・統計学を学ぶ
- Python ライブラリを学ぶ
- 機械学習アルゴリズムを学ぶ
- 機械学習モデルを構築する
2, 4 は多少分かるので 1, 3, 5 がメインで学びたいところ。
調べている中で出てきたキーワードをメモっておく
- 開発環境関連
- Anaconda
- pip
- virtualenv
- pipenv
- 数値計算
- Numpy
- pandas
- Scipy
- 視覚化
- Matplotlib
- Seaborn
- Streamlit
- Dash
- Plotly
- 機械学習
- Scikit-Learn
- TensorFlow
- PyTorch
- Keras
- プラットフォーム
- Kaggle
- IDE
- JupyterLab
Python の環境について
Pythonのインストール方針: Python環境構築ガイド - python.jp
Python の環境は主に3つあるらしい。
| 環境 | 説明 |
|---|---|
| Google Colab | Google が提供するブラウザ上で Python を実行できる環境 |
| Python 公式版 | 一般的なプログラミングの学習や開発向け |
| Anaconda 版 | 機械学習や科学技術演算向け |
公式版 vs Anaconda 版
PythonとAnaconda: Python環境構築ガイド - python.jp
- 公式版
- パッケージの公開には PyPI というサービスを使用
-
pipコマンドで取得する - プロジェクトごとの仮想環境は venv で作成する
- Anaconda 版
- パッケージの公開には独自のサービスを使用
- PyPI で公開されている主要なパッケージは Anaconda にも登録されている
-
condaコマンドで取得する - プロジェクトごとの仮想環境は
condaコマンドで作成する
パッケージの二重管理にならないよう原則としてどちらかのみを使う。
今回は機械学習向けなので Anaconda 版が適しているんだろう。
Anaconda を使うなら pip や venv を使うことはほぼなさそう。
バージョン管理
複数の Python バージョンがインストールされていても python3.7 とかでバージョン付きで実行できるので問題ない。
Anaconda 環境では conda コマンドで Python のバージョンを変更できる。
Pyenv というバージョン管理ツールもあるが公式はあまり推奨しないというスタンス。
ゼロからのPython入門講座
Google Colab の説明も含む公式の入門講座があるので最初は Colab で触ってみる。
Colab はインスタントにコード書いて実行できるし主要ライブラリもインストールなしに使えて手軽。
内容はプログラミング初心者なので代入の説明とかもある。
へぇ〜となった点
- 数値
- int 型と float 型がある
- 文字列
-
"と'は一緒
-
- 数値演算
-
3 // 2のように//で floor 処理ができる
-
- 論理演算
- 論理演算子は
and,or,not
- 論理演算子は
- 変数
-
age = 20で変数を使える - 変数名などは snake_case
-
- 条件分岐
-
if 条件式:で if 文 - else if は
elif 条件式: - ブロックはインデントで表現する
-
- ループ
-
while 条件式:で while 文 -
for 変数名 in リストオブジェクト:でリストを走査できる
-
- 関数
- 関数宣言は
def 関数名(引数名1, 引数名2, ...): - キーワード引数
func(arg3="引数3", arg2="引数2", arg1="引数1")が使える
- 関数宣言は
- タプル
-
(要素1, 要素2)でタプルが使える - タプル同士で比較演算子が使える
- タプルは要素を変更できない
- タプルは固定長に制限される代わりにリストよりハイパフォーマンス
- 関数の戻り値で複数のデータをタプルで返すパターンがある
-
- コレクション
- リスト・辞書・タプル・文字列などをコレクションと呼び、共通の処理が使える
- コレクションのサイズは
len()関数で取得する - コレクションの比較は値比較
- コレクションは
var1, var2, var3 = (1, 2, 3)でアンパック代入できる
- シーケンス
- リスト・タプル・文字列などをシーケンスと予備、共通の処理が使える
Anaconda と Miniconda
Anaconda の最小構成である Miniconda というのもある。
AnacondaとMinicondaの比較、どちらで環境構築するべきか | In-Silico NoteBook
Anaconda
いろんなものが含まれている。
- プログラミング言語: Python, R
- パッケージ: numpy、pandas, Matplotlib, Scikit-learn, Tensorflow 等たくさん
- IDE: Jupyter, JupyterLab, Spyder, RStudio
- GUI: Anaconda Navigator
Miniconda
Python, conda, 最小のパッケージのみ含まれる最小構成。
どっち選べばいい?
Miniconda のドキュメント曰く「初心者は Anaconda、自分で管理したいなら Miniconda」ということらしい。
ちなみに Anaconda は大規模な商用利用は有償とのこと。
環境構築
macOS 環境での Anaconda 利用について調べると Homebrew と干渉し相性が悪いという記事がちらほら見つかる。
ローカルにいろいろ入るのは嫌なので Docker で動かすことにする。
Docker コンテナの準備
以下の記事に従い Dockerfile, docker-compose.yml を作って docker compose up するだけ。
【画像で説明】DockerでAnaconda環境をつくり、コンテナの中でVSCodeを使う - Qiita
VS Code 拡張機能
Python-Visual Studio Marketplace
たぶんこれ入れとけばいいっぽい。
ゼロから学ぶ Python
もうひとつプログラミング経験者向け Python 入門をやってみる。
公式のチュートリアルより広い範囲を扱っている。
へぇ〜となった点
基本仕様
- 変数
- 文字列の先頭に
fをつけると{}で変数などが埋め込める - リスト・タプル・文字列の添字は負数も指定できる
-
{0, 1, 2, 2}やset([1, 1, 2, 2])などで Set 型が使える -
x = Noneを使うとどの型にも属さない変数になる
- 文字列の先頭に
- 関数
-
def func(*args):で可変長引数が使える -
def sum(x: int, y: int) -> int:で引数や戻り値に型ヒントを使える - 明示的に
returnしない場合はNoneが返る
-
- 条件文
- switch 文はない(!?)
- 範囲条件は
0 <= x < 10のようにも書ける - 同一インスタンスかの判定には
isを使う - 変数に
Noneが代入されているか調べるときはx is Noneを使う
- ループ文
-
for i in range(10):で range のループが使える -
x = [i * 2 for i in range(50)]のようにリスト内にループを書くことができ、これをリスト内包表記と呼ぶ
-
- ラムダ式
-
lambda x: x * xのようにラムダ式(即時定義できる無名関数)が使える
-
クラス
- クラス
-
class Rectangle:でクラスを定義できる -
__init__がコンストラクタ - メソッドの第1引数は
selfになる
-
- スコープ
- アクセス指定子はない
- protected は
_hoge(), private は__hoge()という命名規則で区別する慣例
- protected は
- アクセス指定子はない
- プロパティ
-
@propertyというデコレータをつけることで Getter を作れる -
@foo.setterというデコレータをつけることで Setter を作れる
-
モジュールとパッケージ
- モジュール
-
__name__という変数にモジュール名が入っている
-
- パッケージ
- パッケージには
__init__.pyというファイルが必要
- パッケージには
ファイル操作
- コンテキスト
- with 文で自動的にファイルクローズするコンテキストマネージャを使える
例外
- 例外
- try-except 文で例外をキャッチできる
-
raiseで例外を投げる - エラーは
Exceptionクラスを継承して作る
ジェネレータ
- ジェネレータ
-
yieldを使うと関数を途中で抜け、再度呼ばれると抜けたところから再開することができる- このような関数をジェネレータと呼ぶ
-
テスト
- doctest
-
"""で囲った文字列を docstring と呼び docstring 内にテストコードを書ける
-
- pytest
- 単体テストのライブラリとして主流
こんなツイートを目撃。
言語機能はそれほど魅力的ではないけど周辺環境が魅力的というのはなんとなく感じる。
JupyterLab
jupyterlab/jupyterlab: JupyterLab computational environment.
Jupyter Notebook の後継機として開発されたブラウザ上で動作する対話型実行環境。
環境構築で導入済み。
Pythonではじめる数理最適化
具体的な目標なくライブラリのキャッチアップをするのはツライので、実践的な内容をやりながら雰囲気を掴みたい。
会社の人から良さげな書籍を紹介してもらったので読む。
感想文 👉 「Pythonではじめる数理最適化」を読むぜ