iOSアプリでllama.cppを使ってGGUF形式の言語モデルを呼び出す方法
はじめに
LLMをmacOSやiOSのアプリに組み込みたい場合は、llama.cppを使ってGGUFファイル形式のモデルを読み込む方法がよく知られています。GGUFは、llama.cppでモデルファイルを読み込む際のデフォルト形式の一つです。
新しいオープンな言語モデルが発表されると、Hugging Face上に公式または有志によってGGUF形式の量子化版モデルが公開されることが多く、誰でも簡単にダウンロードできます。
最近、Sakana AIと東京科学大学のSwallowチームが共同開発した日本語対応の言語モデル「TinySwallow-1.5B」は、1.5Bというパラメータ数にもかかわらず高い応答性能を発揮しており、デバイスへの組み込みも十分現実的だと感じました。実際、TinySwallow-1.5Bのモデルサイズは約1.6GBほどです(参考までに、Llama-3-ELYZA-JP-8Bは約5GB弱)。このように比較的コンパクトなSLMをiPhoneなどのアプリ内でオフライン動作させることで、AI機能の強化が期待できます。
たとえば、私自身は日本語翻訳や要約などのタスクをアプリ内でオフライン処理したいと考えています。エディタ上での校正機能を強化することもできるでしょう。
そこでGGUF形式のモデルをiOSアプリから呼び出すための方法を検証しました。3パターン紹介しますがそれぞれが行なっていることは共通しています。
- llama.cppをSwiftPMで自分のアプリにビルド対象として組み込む
- SwiftからC APIを呼び出すラッパーを書く
- SwiftUIから使う
1. 正攻法:examples/llama.swiftui
llama.cppのリポジトリにはSwiftUIアプリのサンプルがあります。
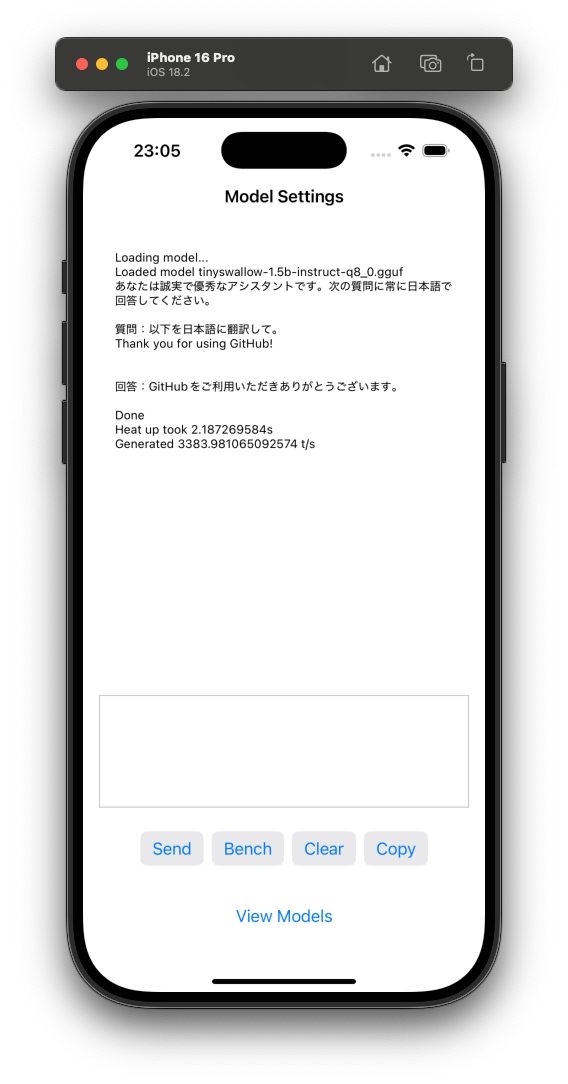
任意のモデルをmodelsディレクトリコピーしてBundleから読み込む名前を変更すれば実機で動作します。
private var defaultModelUrl: URL? {
Bundle.main.url(forResource: "tinyswallow-1.5b-instruct-q8_0", withExtension: "gguf", subdirectory: "models")
// Bundle.main.url(forResource: "llama-2-7b-chat", withExtension: "Q2_K.gguf", subdirectory: "models")
}
しかし現在のHEADcfd74c86dbaa95ed30aa6b30e14d8801eb975d63ではビルドが失敗します。
タイミングとしては2025/01/06の#11110 以降です。
/Library/Developer/Xcode/DerivedData/llama.swiftui-ckrcdzqhkwhfhnbyreolkfyeszfk/SourcePackages/checkouts/llama.cpp/Sources/llama/llama.h:3:10 'llama.h' file not found with <angled> include; use "quotes" instead
簡単な回避策は依存するllama.cppのパッケージをビルドが成功する時点のバージョンまで戻して、古いAPIを呼び出すよう一部書き換えます。
まずXcodeのSwiftPackage設定からローカルパスの参照を削除します
その後、リポジトリのURLとコミットID6dfcfef0787e9902df29f510b63621f60a09a50bを指定して設定します

#11110で追加された新APIの呼び出しをrevertします。これは3箇所なので手で行えます。
diff --git a/examples/llama.swiftui/llama.cpp.swift/LibLlama.swift b/examples/llama.swiftui/llama.cpp.swift/LibLlama.swift
index 998c673d5d31f..477c3e6f2e95b 100644
--- a/examples/llama.swiftui/llama.cpp.swift/LibLlama.swift
+++ b/examples/llama.swiftui/llama.cpp.swift/LibLlama.swift
@@ -52,8 +52,8 @@ actor LlamaContext {
deinit {
llama_sampler_free(sampling)
llama_batch_free(batch)
+ llama_model_free(model)
llama_free(context)
- llama_free_model(model)
llama_backend_free()
}
@@ -65,7 +65,7 @@ actor LlamaContext {
model_params.n_gpu_layers = 0
print("Running on simulator, force use n_gpu_layers = 0")
#endif
- let model = llama_load_model_from_file(path, model_params)
+ let model = llama_model_load_from_file(path, model_params)
guard let model else {
print("Could not load model at \(path)")
throw LlamaError.couldNotInitializeContext
@@ -151,7 +151,7 @@ actor LlamaContext {
new_token_id = llama_sampler_sample(sampling, context, batch.n_tokens - 1)
- if llama_token_is_eog(model, new_token_id) || n_cur == n_len {
+ if llama_vocab_is_eog(model, new_token_id) || n_cur == n_len {
print("\n")
is_done = true
let new_token_str = String(cString: temporary_invalid_cchars + [0])
このようにllama.cppの開発は常にエッジバージョンで進行しているため優先度の低いiOS向けのビルドは壊れがちです。
動作するバージョンの見つけ方として参考になるのは以下です
- cmakeディレクトの変更履歴
- examples/llama.swiftuiの変更履歴
またCIでxcodebuildのビルドも含めて実行されているので .github/workflows/build.ymlの監視も有効です
2. スターターキット:MiniAIChatアプリ
giginetさんが公開しているMiniAIChatアプリは2024年11月時点のllama.cppをSwiftPMで組み込んであり、おそらくみなさんの環境でもそのまま動作するはずです。
Configurations.swiftにあるLlama-3-ELYZA-JP-8B-q4_k_mを任意のGGUFファイルに置き換え、models/ディレクトリにコピーして実機に転送することでフレンドリーなチャットアプリが実行できます。
Swiftラッパークラスは公式のllama.swiftuiアプリはllama-cpp-swiftというライブラリのコードを流用しているのですが、MiniAIChat版のがllama.cppの細かい設定やAsyncSequenceを使ったSwiftらしい実装になっているので、チャットアプリのベースとして最適でしょう。
iOSシミュレータで起動するには
iOSシミュレータはMetalサポートがないので明示的にオフにします。
convenience init(modelPath: URL, params: Parameters) throws {
var modelParams = llama_model_default_params()
#if targetEnvironment(simulator)
modelParams.n_gpu_layers = 0
print("Running on simulator, force use n_gpu_layers = 0")
#endif
3. リファレンス用:LLMFarm_core.swift
LLMFarm_core.swiftは前述のTinySwallow-1.5Bのデモでも使用されていたLLMFarmというアプリのコアライブラリです。
このライブラリはSwiftPMでインストールして使うことができます。デモプロジェクトがついています。
しかし内部で呼び出すllama.cppは独自にフォークされたものです。
guinmoon/llama.cpp
このプロジェクトはいきなりベースとして組み込むというより、実際の本番環境で動いているアプリの実装を参考にするときに使います。
参考文献
Discussion