今年の流行語といえばLLMですが、中でもローカルLLMの技術がプログラマ的には気になります。何かに使えそう!
そこでローカルLLMの代名詞である(?)llama.cppを眺めていたところ、堂々とPackage.swiftがあるのに気づきました。

ということは、自力で難しいことをしなくても、簡単にSwiftから利用できそうです。
今更感もありますが、この記事ではllama.cppをSwiftから使って色々遊んでみたいと思います。
この記事は私のインターン先であるTuringアドベントカレンダー21日目の記事です。卒が論してきているので、パッと書けそうだった趣味寄りの話で許してください😇
環境
- Mac mini
- macOS 13.5.2
- M2 Pro
- RAM 32GB
- iPhone 12 mini
- iOS 17.2
- iPad Pro
- M1 Pro
- iPadOS 17.2
- Llama.cpp
- commit
c6c4fc081c1df1c60a9bfe3e6a3fd086f1a29ec7(12月17日)
- commit
今回作ったコードはGitHubで閲覧可能です。
普通に動かす
Swiftから動かす前に、llama.cpp自体を一度動かしてみましょう。
動かす前にモデルを準備します。とりあえず130億パラメータのLLaMAを量子化したものを動かしてみましょう。
以下のリンクからllama-2-13b.Q4_0.ggufをllama.cpp/models/にDLしました。7GBあります。
まずmakeします。
$ make
そのあとは実行します。Swiftについて説明させてみます。
$ ./main -m models/llama-2-13b.Q4_0.gguf -p "Let's learn Swift Programming Language. First," -n 400 -e
First, we will learn about its basics and then move on to more advanced concepts. What is a Swift Programming Language?
Swift is a general-purpose programming language developed by Apple for iOS and macOS. It was first released in 2014 and has since become one of the most popular languages for developing apps on these platforms...
llama_print_timings: load time = 8542.04 ms
llama_print_timings: sample time = 35.58 ms / 400 runs ( 0.09 ms per token, 11241.32 tokens per second)
llama_print_timings: prompt eval time = 276.81 ms / 12 tokens ( 23.07 ms per token, 43.35 tokens per second)
llama_print_timings: eval time = 20433.67 ms / 399 runs ( 51.21 ms per token, 19.53 tokens per second)
llama_print_timings: total time = 20948.06 ms
ggml_metal_free: deallocating
Log end
めっちゃいい感じですね。生成も爆速でした。ここで動かしているモデルは量子化と呼ばれる手法で軽量化されているため、メモリ消費が小さくなっています。量子化についてはTuringアドカレ17日目の記事がわかりやすいです。
ここで動いているmainというバイナリはexamples/main/main.cppから出来ているので、細かいことを知りたくなったらまずこれを読むのが良いと思います。
SwiftUIのサンプルアプリを動かす
11月末にサンプルアプリがexampleに追加されました。これも動かしてみます。
「llama.swiftui.xcodeproj」をXcodeで開いてビルドします。クローンした直後の状態そのままでは動かないので、いくつか修正が必要です。
まず、モデルの重みへの参照が切れています。このサンプルアプリではデフォルトでllama-2-7b-chat.Q2_K.ggufが使われているので、ダウンロードして参照を修正してください。インスペクタ上のフォルダのマークのアイコンをクリックすると参照先を変更できます。
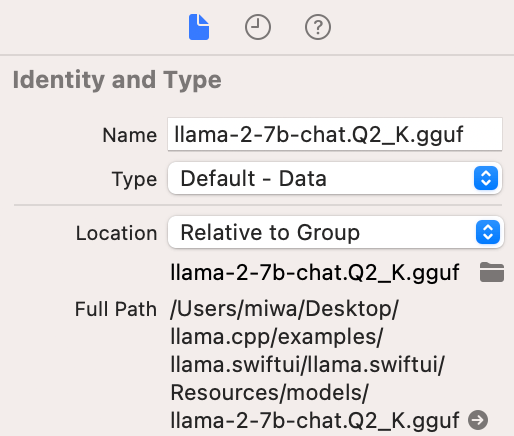
それから、モデルのURLをSwift内で指定しているのですが、これが正しくありません。ここを修正しないと実行しても「Could not load model」と言われてしまいます。Models/LlamaState.swiftのmodelURLを以下のように修正してください。
なお、異なるモデルを読み込みたい場合はここを書き換えれば良いです。
private var modelUrl: URL? {
// Bundle.main.url(forResource: "q8_0", withExtension: "gguf", subdirectory: "models")
Bundle.main.url(forResource: "llama-2-7b-chat", withExtension: "Q2_K.gguf", subdirectory: "models")
}
では実行していきましょう。
このサンプルアプリのメインのターゲットはiOS / iPadOSですが、端末によっては動かないので、まずはMac向けにRunして試してみると良いでしょう。
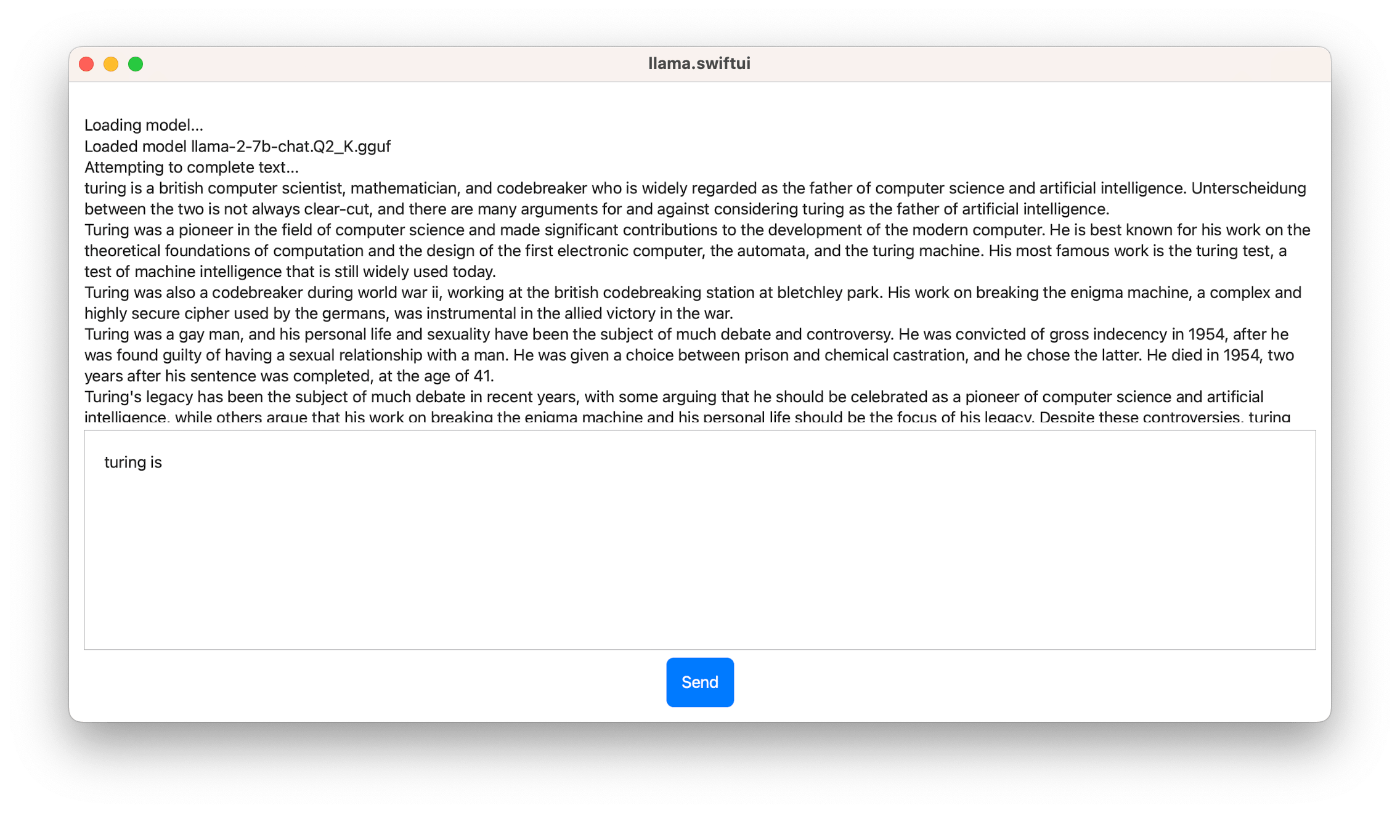
ちゃんと生成してくれました!手元のM1 iPad Pro(11インチ)でも申し分なく動作したので、お持ちの方はぜひ試してみてください。
手元のiPhone 12 miniではllama-2-7b-chat.Q2_K.ggufは動きませんでしたが、tinyllama-1.1b-intermediate-step-715k-1.5t.Q2_K.ggufなど小さめのモデルを代わりに読み込ませると、動作してくれました。生成してくれる文章はイマイチですが、調整の問題もあるのでモデルが悪いわけではありません。

llama.cppのGitHubでは端末ごとの性能比較が行われているので、必要に応じて確認すると良さそうです。
チャットする
今の状態だとモデルはただのテキスト生成を行っているだけで、チャットをしてくれるわけではありません。Swiftでチャットアプリを作りましょう。
出来上がったものはこんな感じになります。「Appleの開発環境を揃える必要がない」と、SwiftがWindowsやLinuxにも対応していることを理解したとても賢い応答をしています🙄
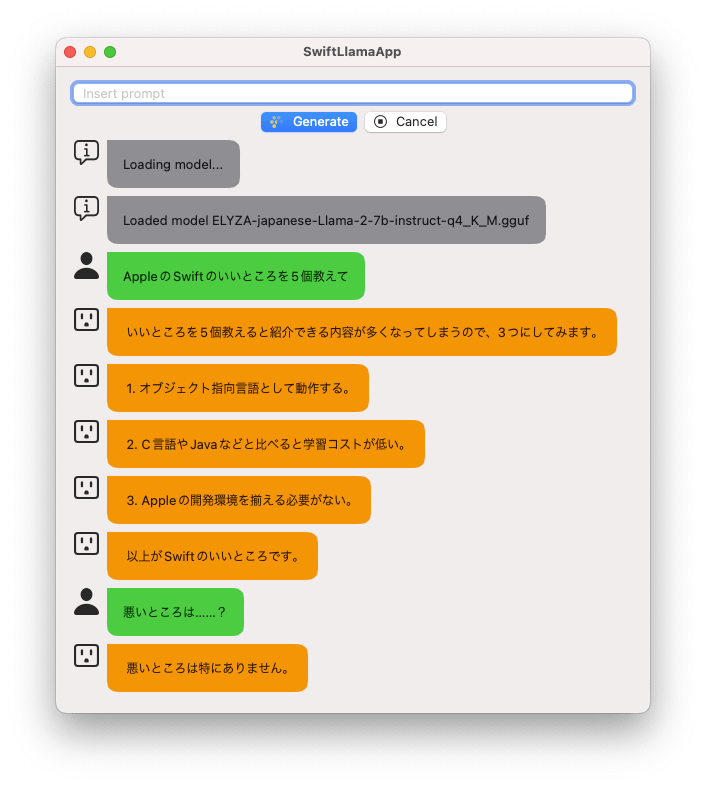
チャットの基本
チャットと言えど、本質的にはただの文章生成をGUIでそれっぽくするだけです。examples/chat.shがサンプルになっているので、これを真似して作ります。
チャットで生成される生の文章は次のようになっています。
以下はAlanというAIアシスタントとユーザの会話のログデータです
Alan:こんにちは、今日はどのようにお手伝いしましょうか?
User:あなたは誰ですか?
Alan:私はAlanです
ユーザからの入力を受けたら、これを以下のようにします。
(前略)
Alan:私はAlanです
User:大阪の観光スポットを10個教えてください
Alan:
この状態からテキスト生成を始めることで、ユーザの入力に対するAIの応答が生成されます。AIがEOSを出力するかUser:を出力したら、生成を打ち切ってユーザの入力を待ちます。
今回の工夫
せっかくなので少し工夫を入れてみました。
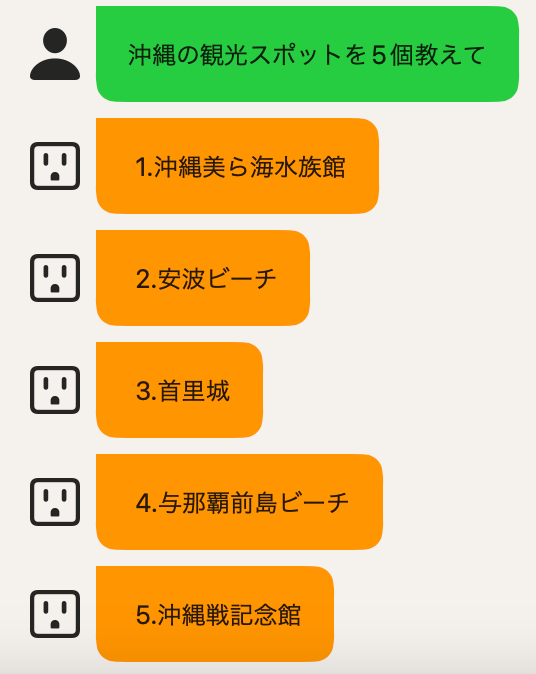
まず、あんまり長文を返してくるAIは怖いですね。「長文LINE」というのはそれひとつでアンケート記事が何本も書かれているようなcontroversialなスタイルなので、ナウなイメージのLLMと併用するのは避けたいところです。
そこで、適度に複数行に分割してもらいます。こんな感じです。
それから、本家ChatGPTのUIだと、テキストを送信すると生成が始まります。生成を途中停止することはできますが、一問一答という感じになってあまり会話らしくありません。LINEやSlack、Discordなどで行われる実際の会話では、しばしばコメントが前後したり、相手がまだ続きを送ってきそうでも割り込んで答えたりすることがあります。
そこで、AIが返信している途中で文章を送ったら、自動で生成をキャンセルし、新しい入力を加味して文章生成を再開してもらえるようにしてみました。少しわかりにくいのですが、AIの生成中に「やっぱ博多で」と割り込むと、それに応じて次の返答を始めてくれます。こういう調整はローカルLLMの方がしやすいですね。

余談ですが、AIのアイコンにはSF Symbolsからコンセントの穴のアイコンを採用しました。完全にabuseです。
実装
基本的にはSwiftUIのサンプルアプリを参考にしました。ここではLlamaContextというActorでllamaのAPIがラップされています。この中の関数を呼び出すことで、簡単に生成を実行することができます。
長くなるので細かい部分は省きますが、次のようにllamaContext.completion_initを呼んだ後にllamaContext.completion_loopを繰り返し呼んでいくことでどんどん生成されていきます。生成結果を見て、ユーザのメッセージの接頭辞が発見されたら停止、AIのメッセージの接頭辞が発見されたら新しいメッセージを追加、割り込みがあったら停止、というような振る舞いです。
func generateForChat(prompt: String, userPromptPrefix: String?, aiPromptPrefix: String?) async {
guard let llamaContext else {
return
}
await llamaContext.completion_init(text: prompt)
while await llamaContext.n_cur < llamaContext.n_len && !Task.isCancelled && !reversed {
let completion = await llamaContext.completion_loop()
var newResult = self.generatingMessage + completion.piece
// user prompt prefixが発見されたら停止する
if let userPromptPrefix, newResult.suffix(userPromptPrefix.count + 10).contains(userPromptPrefix) {
// ...
}
// ai prompt prefixが発見されたら新しいメッセージを追加する
if let aiPromptPrefix, newResult.contains(aiPromptPrefix) {
// ...
} else {
// 描画を更新する
do {
try await MainActor.run {
// 割り込みを確認するがないか確認する
// if ...
self.generatingMessage = newResult
}
} catch {
break
}
}
}
if !Task.isCancelled {
await llamaContext.clear()
self.isGenerating = false
}
}
また、サンプルアプリでは生成が貪欲法によるサンプリングでした。貪欲法は高速ですが、サンプリングを工夫すると出力がいい感じになることがあります。そこでcompletion_loop内部の実装を変更し、サンプリングをいい感じに調整しました。
この辺りは用途に応じて適宜調整するのが良いでしょう。
candidates.withUnsafeMutableBufferPointer() { buffer in
// common/sampling.hを参照すると良い
var candidates_p = llama_token_data_array(data: buffer.baseAddress, size: buffer.count, sorted: false)
// llama_sample_repetition_penalties(context, &candidates_p, tokens_list, 64, 1.0, 0.0, 0.0)
llama_sample_top_k(context, &candidates_p, 40, 2)
llama_sample_top_p(context, &candidates_p, 0.95, 2)
llama_sample_min_p(context, &candidates_p, 0.05, 2)
llama_sample_temp(context, &candidates_p, 0.8)
new_token_id = llama_sample_token(context, &candidates_p)
}
Grammarを動かす
ここまででチャットアプリができましたが、LLMは何もチャットにばかり使うものではありません。もっといろいろなことができるはずです。例えば、適当なクエリに対してJSONを生成してくれたら最高ですよね。実際、ChatGPTではFunction Callingの仕組みでこれを実現できます。
といっても、言語モデルにとってJSONは必ずしも馴染み深いフォーマットではないので、普通に「JSONを生成して」などと言って生成させるとちょくちょく正しくないJSONが出てきてしまいます。そこで使えるのがGrammarの仕組みです。
llama.cppのGrammarの仕組みでは、BNF記法(文脈自由文法を記述するフォーマット)で記述した文法をLLMの生成時に制約として与えることができます。例えばどのようなJSONを生成するかをプロンプトで説明したうえで生成させれば、LLMが自動的にJSONを吐いてくれます。最高ですね!
文法の記述
比較的シンプルな例に、japanese.gbnfがあります。日本語の文法がシンプルという意味ではなく、弱い制約だけが書かれているという意味です。正規表現++って感じですね。
文法パーサの実行
GrammarのAPI自体はllama.hに存在するので使えるのですが、実際にはBNF記法で書いた文法をC++の内部表現に置き換えるための文法パーサが欲しいです。この文法パーサはcommon/grammar-parser.cppが実装なので、Swift Packageのllamaからは使えませんでした。
そこで、common/grammar-parser.cppをそのままSwiftのプロジェクトに突っ込みました。幸い、Swift 5.9以降では実験的なC++相互運用がサポートされているので、非常に簡単に動かすことができます。
Swiftからの呼び出しを簡単にするため、次の関数を追加しました。この関数にBNFで書かれた文法を突っ込むと、llama_grammar *がもらえます。
llama_grammar * llama_grammar_init_from_content(const char * src) {
parse_state result = parse(src);
std::vector<const llama_grammar_element *> grammar_rules(result.c_rules());
return llama_grammar_init(
grammar_rules.data(),
grammar_rules.size(), result.symbol_ids.at("root"));
}
これをラップしたSwiftのclassを以下のように作ります。
final class LlamaGrammar {
var grammar: OpaquePointer
init?(_ grammar: String) {
print(grammar)
self.grammar = grammar_parser.llama_grammar_init_from_content(grammar.cString(using: .utf8))
}
deinit {
llama_grammar_free(self.grammar)
}
}
文法を加味したサンプリング
まずはjapanese.gbnfを使って生成します。チャットに組み込むには公式のものはやや表現力不足なので、次のように変更してみます。
root ::= japanese-chat+
japanese-chat ::= ai-message | user-message | "\n"
ai-message ::= "Alan:" message
user-message ::= "User:" message
message ::= jp-char+ ([ \t\n] jp-char+)*
jp-char ::= hiragana | katakana | punctuation | cjk
hiragana ::= [ぁ-ゟ]
katakana ::= [ァ-ヿ]
punctuation ::= [、-〾]
cjk ::= [一-鿿]
examples/main/main.cppから辿っていくと、文法を加味するにはllama_sample_grammarとllama_grammar_accept_tokenを呼び出せばいいようです。llama_sample_grammarは与えられた文法のパーサを使って生成され得ないトークンのlogitを負の無限大(確率0)にします。llama_grammar_accept_tokenは実際に選択したトークンに基づいてパーサの状態を更新します。
そこでサンプリングを以下のように変更します。
// func completion_loop
candidates.withUnsafeMutableBufferPointer() { buffer in
var candidates_p = llama_token_data_array(data: buffer.baseAddress, size: buffer.count, sorted: false)
// ここと
llama_sample_grammar(context, &candidates_p, grammar)
llama_sample_top_k(context, &candidates_p, 40, 2)
llama_sample_top_p(context, &candidates_p, 0.95, 2)
llama_sample_min_p(context, &candidates_p, 0.05, 2)
llama_sample_temp(context, &candidates_p, 0.8)
new_token_id = llama_sample_token(context, &candidates_p)
// ここ
llama_grammar_accept_token(context, grammar.grammar, new_token_id);
}
これを先ほどのチャットアプリで使ってみると、日本語だけを喋るAIの完成です。ローマ字も封じているので、「ウィキペディア」とカタカナで話してくれます。フレンドリー!

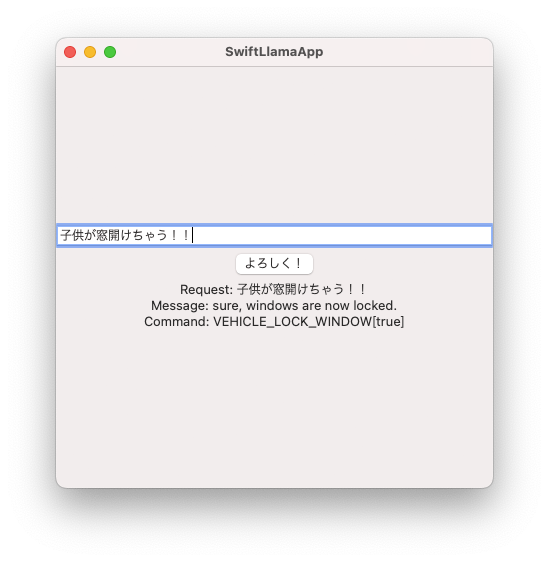
JSONもやってみましょう。簡単な例として、車のAIアシスタントとして働いてもらいます。ユーザのリクエストを入力として、その内容を適切なコマンドにマップしてもらいましょう。次のようなリクエストを与えます。
The data is request and response of in-vehicle infortainment AI assitant. AI assistant can use following commands; "AUDIO_VOLUME_SET_ABSOLUTE" (arg: 0<number<100) / "HVAC_TEMPERATURE_SET_RELATIVE" (arg: float, positive is warmer) / "VEHICLE_LOCK_WINDOW" (arg: bool, true is locked).
req: "Please lock the windows"
res: {"message": "sure, windows are now locked.", "command": {"commandName": "VEHICLE_LOCK_WINDOW", "value": true, "valueType": "bool"}}
req: "It's too hot!"
res: {"message": "I'm sorry, I'll lower the temperature soon.", "command": {"commandName": "HVAC_TEMPERATURE_SET_RELATIVE", "value": -2.0, "valueType": "float"}}
req: "寒すぎるよ"
res:
この後にJSONで制約を与えながら文章を生成させると、以下のようなものが出てきます。
{"message": "I'll increase the temperature then.", "command": {"commandName": "HVAC_TEMPERATURE_SET_RELATIVE", "value": 2.0, "valueType": "float"}}\n\n\n\n\n\n\n...
文法制約上、\nが最後は無限に出てきてしまうので、一旦"\n\n"が出てきたら生成を終了するような仕組みにしました。
func getResponse(request: String) async -> AssistantResponse? {
guard let jsonGrammar = LlamaGrammar.json else {
return nil
}
guard let result = try? await self.model.generateWithGrammar(prompt: """
// 略
req: "It's too hot!"
res: {"message": "I'm sorry, I'll lower the temperature soon.", "command": {"commandName": "HVAC_TEMPERATURE_SET_RELATIVE", "value": -2.0, "valueType": "float"}}
req: "\(request)"
res:
""", grammar: jsonGrammar) else {
return nil
}
return try? JSONDecoder().decode(AssistantResponse.self, from: result.data(using: .utf8)!)
}
通常のプロンプトの場合はJSONが出てくる保証はありませんが、今回はJSONが出てくることを保証してくれているので、とても扱いやすくなっています。SwiftのCodableとの相性もバッチリです。

今回使ったJSONの文法は公式サンプルのもので、やや過剰に表現力があります。実運用ではJSONのキーや値もある程度文法レベルで制約することで、より扱いやすくなるでしょう。
ただし、記述する文法によっては動作が極端に遅くなるケースがありました。原因は調査しきれていないのですが、文脈自由文法パーサの側が重くなっている可能性がありそうです。
iOSでも動かす
ここまではmacOSで動かしてきましたが、iPadでもちゃんと動きます。

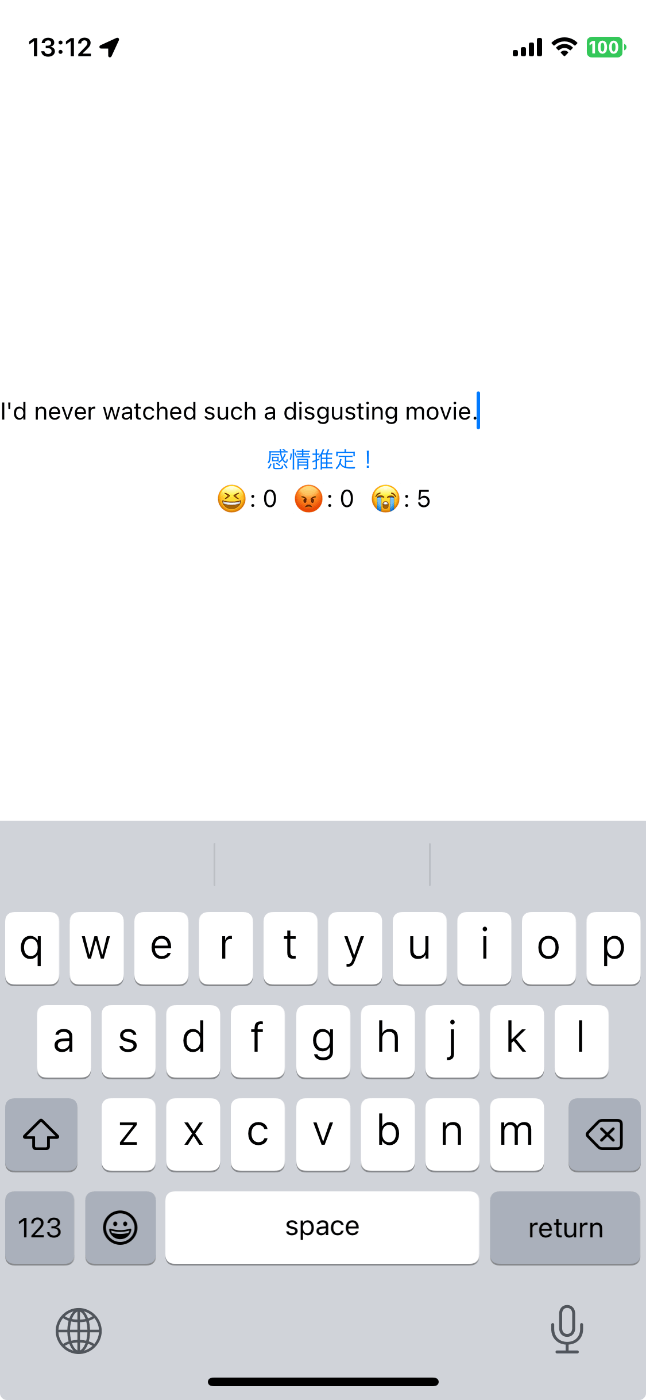
小さなモデルであればiPhoneでも問題なく動きます。小さいモデルではJSONの生成が難しい様子だったので、感情推定をやらせてみました。精度はあまり良くなかったので、モデル選択が重要になりそうです。iPhoneで動く程度の規模のモデルなら、ファインチューニングも選択肢の1つでしょう。
余談ですが、OSごとにリソースを変更できるので、やっておくとインストール時間が抑えられて便利です。

まとめ
この記事ではllama.cppをSwiftから利用してシンプルなGUIを構築し、さらにGrammarを利用した生成についても調査しました。
少し難しい部分はありますが、入門自体はかなり気軽にできる印象です。ここまでツールが揃っていれば、Swiftでも面白いことがいろいろできるのではないでしょうか。
今回作ったコードはGitHubに置いてあります。
今回作ったものよりも汎用的で高機能な実装もあります。開発の上で参考にするのはこちらのレポジトリがおすすめかもしれません。
また、最近はMLXというApple謹製機械学習ライブラリも出てきました。色々面白い感じになってきていますね!
Turingはマルチモーダルな大規模モデルを用いた完全自動運転を目標にしており、その過程ではこうしたローカルLLM的な開発も発生します。興味のある方はぜひイベント等にお越しください。

Discussion