AIアプリ向けプロファイルベースの長期メモリ「Memobase」を試す①
たまたま見つけた
Memobase
AIアプリケーション向けプロファイルベースの長期記憶システム
Memobaseは、あなたの生成AI(GenAI)アプリケーションに長期的なユーザーメモリをもたらすために設計されたユーザープロファイルベースのメモリシステムです。仮想コンパニオン、教育ツール、またはパーソナライズされたアシスタントを構築している場合でも、MemobaseはあなたのAIがユーザーを記憶し、理解し、共に進化することを可能にします。Memobaseはユーザーの構造化されたプロファイルを提供することができます。900ターンの実際のチャットから得られた結果(mem0と比較)をご覧ください。
プロファイル出力の一部
{ "basic_info": { "language_spoken": ["English", "Korean"], "name": "오*영" }, "demographics": { "marital_status": "married" }, "education": { "notes": "Had an English teacher who emphasized capitalization rules during school days", "major": "국어국문학과 (Korean Language and Literature)" }, "interest": { "games": 'User is interested in Cyberpunk 2077 and wants to create a game better than it', 'youtube_channels': "Kurzgesagt", ... }, "psychological": {...}, 'work': {'working_industry': ..., 'title': ..., }, ... }特徴
- 🎯 エージェントではなくユーザーのためのメモリ: AIが取得するユーザー情報を正確に定義および制御します。
- ➡️ 時間認識メモリ: Memobaseはプロファイルに特定の日付を保存し、古い情報があなたのAIに影響を与えることを防ぎます。また、Memobaseイベントで連続的なイベント(エピソード記憶)を確認してください。
- 🖼️ 制御可能なメモリ: すべてのタイプのメモリの中で、一部だけが製品体験を向上させる可能性があります。Memobaseはプロファイルを設計するための柔軟な構成を提供します。
- 🔌 簡単な統合: API、Python / Node / Go SDKを使用して既存のLLMスタックと統合するための最小限のコード変更。
- ⚡️ バッファによる挿入: メモリシステムは追加のコストがかかりますが、Memobaseは会話後にチャットをバッチ処理するためのバッファを各ユーザーに提供します。高速で低コスト。
- 🚀 プロダクション対応: MemobaseはFastAPI、Postgres、Redisで構築されており、リクエストキャッシング、認証、テレメトリをサポートしています...完全にDockerize済み。
Memobaseがどのように動くか?
referred from https://github.com/memodb-io/memobase and translated into Japanese by kun432
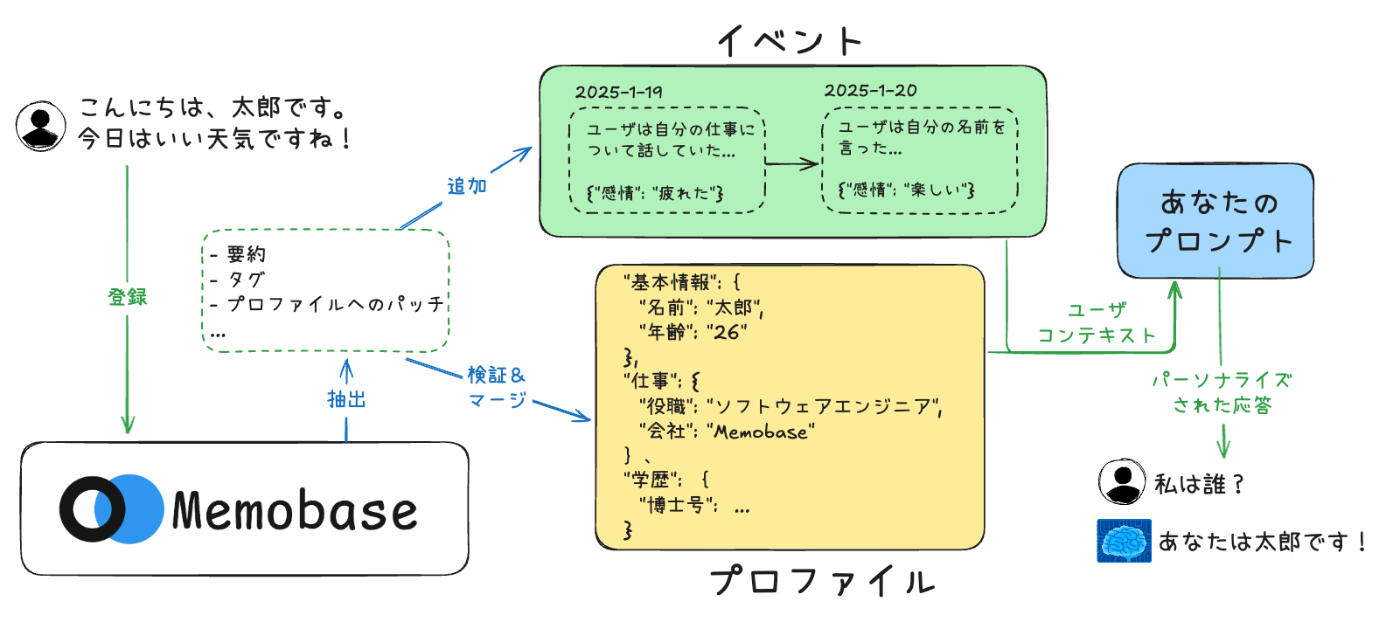
なぜ/どこでMemobaseを使用すべきか?
ユーザーを記憶
プロファイルをAIに配置する(例: システムプロンプト)。
ユーザー分析とトラッキング
ユーザーとAIの間の会話には多くの情報が隠されているため、ユーザーの好みや行動を記録するための新しいデータトラッキング方法が必要です。
顧客に何かを販売する
誰もがGrammarlyを探しているわけではなく、ユーザーが望む可能性のあるものを販売することは常に良いことです。
ドキュメント
詳細な使用方法については、ドキュメントをご覧ください。
ライセンスはApache-2.0
あと、クラウドサービスもやっている
Memobaseのインストール(Docker)
Memobaseの利用方法は、クラウドとセルフホスト(Docker)がある。今回はローカルのMacでDockerで建ててみる。LLMはOpenAIを使う。
レポジトリクローン
git clone https://github.com/memodb-io/memobase && cd memobase
サーバのソースディレクトリに移動
cd src/server
設定ファイルなどを雛形から作成
cp .env.example .env
cp ./api/config.yaml.example ./api/config.yaml
まず.env。こちらは API_HOSTS だけデフォルトから入れ替えた。
DATABASE_NAME="memobase"
DATABASE_USER="memobase"
DATABASE_PASSWORD="helloworld"
DATABASE_LOCATION="./db/data"
REDIS_PASSWORD="helloworld"
REDIS_LOCATION="./db/redis/data"
DATABASE_EXPORT_PORT="15432"
REDIS_EXPORT_PORT="16379"
API_EXPORT_PORT="8019"
# Swagger をローカル Docker で使用したい場合は、API_HOSTS を次のように設定してください:
API_HOSTS="http://0.0.0.0:8019,http://localhost:8019,https://api.memobase.dev,https://api.memobase.cn"
#API_HOSTS="https://api.memobase.dev,https://api.memobase.cn"
# Swagger フロントエンドで CORS に関連する問題が発生した場合は、この設定を true に変更してみてください
USE_CORS=false
PROJECT_ID="memobase_dev"
ACCESS_TOKEN="secret"
./api/config.yaml。こちらにOpenAIのAPIキーをセットする。この書き方だとOpenAI互換APIならどれでも使えそう。
llm_api_key: XXXXXXXXXX
llm_base_url: https://api.openai.com/v1/
docker-compose.ymlはこんな感じになっていて、Memobase以外にRedisとPostgreSQLも必要になる様子。
services:
memobase-server-db:
image: pgvector/pgvector:pg17
restart: unless-stopped
container_name: memobase-server-db
environment:
- POSTGRES_USER=${DATABASE_USER}
- POSTGRES_PASSWORD=${DATABASE_PASSWORD}
- POSTGRES_DB=${DATABASE_NAME}
ports:
- '${DATABASE_EXPORT_PORT}:5432'
volumes:
- ${DATABASE_LOCATION}:/var/lib/postgresql/data
# - ./db/init.sql:/docker-entrypoint-initdb.d/create_tables.sql
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${DATABASE_USER} -d ${DATABASE_NAME}"]
interval: 5s
timeout: 5s
retries: 5
memobase-server-redis:
image: redis:7.4
restart: unless-stopped
container_name: memobase-server-redis
ports:
- "${REDIS_EXPORT_PORT}:6379"
volumes:
- ${REDIS_LOCATION}:/data
command: ["redis-server", "--requirepass", "${REDIS_PASSWORD}"]
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 5s
retries: 5
memobase-server-api:
platform: linux/amd64
container_name: memobase-server-api
environment:
- DATABASE_URL=postgresql://${DATABASE_USER}:${DATABASE_PASSWORD}@memobase-server-db:5432/${DATABASE_NAME}
- REDIS_URL=redis://:${REDIS_PASSWORD}@memobase-server-redis:6379/0
- ACCESS_TOKEN=${ACCESS_TOKEN}
- PROJECT_ID=${PROJECT_ID}
- API_HOSTS=${API_HOSTS}
- USE_CORS=${USE_CORS}
extra_hosts:
- "host.docker.internal:host-gateway"
depends_on:
memobase-server-db:
condition: service_healthy
memobase-server-redis:
condition: service_healthy
ports:
- '${API_EXPORT_PORT}:8000'
build:
context: ./api
volumes:
- ./api/config.yaml:/app/config.yaml
volumes:
memobase-server-db:
driver: local
memobase-server-redis:
driver: local
memobase-server-api:
driver: local
docker composeでビルドして起動。
docker-compose build && docker-compose up
8019番ポートで立ち上がる。/docsにアクセスするとAPIドキュメントが見れる。
Quickstarts
公式ドキュメントにQuickstartがあるので、まずはこれに従う。
uvでプロジェクトを作成する。
uv init -p 3.12.9 memobase-work && cd memobase-work
パッケージ追加
uv add memobase
(snip)
+ memobase==0.0.16
(snip)
Memobaseへの接続
まずは簡単にMemobaseに接続のテスト。接続には、プロジェクトURLとAPIキーが必要になるが、これはapi/config.yamlの一番下に書いてある。プロジェクトURLがちょっとよくわからなかったのだけど、レポジトリのコードを見る限り http://localhost:8019 で良さそう。PROJECT_IDは何に使ってるんだろう?
(snip)
PROJECT_ID="memobase_dev"
ACCESS_TOKEN="secret"
ということで接続テストを行うコード
from memobase import MemoBaseClient
client = MemoBaseClient(
project_url="http://localhost:8019",
api_key="secret",
)
assert client.ping()
実行
uv run connect_test.py
何も出力されなければ接続できた様子。
ユーザの管理
次にユーザを作成する。適当な辞書を与えてユーザを作成すると、ユーザIDが返ってくる。
from memobase import MemoBaseClient
client = MemoBaseClient(
project_url="http://localhost:8019",
api_key="secret",
)
uid = client.add_user({"any_key": "any_value"})
print("UID:", uid)
以下のユーザIDでユーザが作成された。
UID: 8ae8c728-fb1f-4665-98b6-d1a00d66eb26
ユーザを参照する。
from memobase import MemoBaseClient
client = MemoBaseClient(
project_url="http://localhost:8019",
api_key="secret",
)
uid = "8ae8c728-fb1f-4665-98b6-d1a00d66eb26"
u = client.get_user(uid)
print(u)
以下のような情報が返ってくる。実際には1行で返ってくるけど、構造がわかりやすいように改行している。与えた辞書の情報が含まれているのがわかる。
User(
user_id='8ae8c728-fb1f-4665-98b6-d1a00d66eb26',
project_client=MemoBaseClient(api_key='secret', api_version='api/v1', project_url='http://localhost:8019'),
fields={
'data': {'any_key': 'any_value'},
'id': None,
'created_at': '2025-04-24T15:47:03.148391Z',
'updated_at': '2025-04-24T15:47:03.148391Z'
}
)
次に更新。
from memobase import MemoBaseClient
client = MemoBaseClient(
project_url="http://localhost:8019",
api_key="secret",
)
uid = "8ae8c728-fb1f-4665-98b6-d1a00d66eb26"
client.update_user(uid, {"any_key": "any_data2"})
u = client.get_user(uid)
print(u)
なんかデータの階層構造が変わってしまっているような・・・?これは想定された挙動なのかな?
User(
user_id='8ae8c728-fb1f-4665-98b6-d1a00d66eb26',
project_client=MemoBaseClient(api_key='secret', api_version='api/v1', project_url='http://localhost:8019'),
fields={
'data': {'data': {'any_key': 'any_data2'}},
'id': None,
'created_at': '2025-04-24T15:47:03.148391Z',
'updated_at': '2025-04-24T15:51:57.163917Z'
}
)
ユーザの削除
from memobase import MemoBaseClient
client = MemoBaseClient(
project_url="http://localhost:8019",
api_key="secret",
)
uid = "8ae8c728-fb1f-4665-98b6-d1a00d66eb26"
client.delete_user(uid)
ちょっと気になるところもあるけど、現時点では上記の辞書のデータをどう使うのかもわからないし、他にもidみたいなフィールドもあるので、一旦置いておくことにする。
ユーザデータの管理
ユーザを追加したら、ユーザデータを登録することができる。
まず、一つ上で使用したユーザ作成スクリプトでユーザを作成。
uv run user_create.py
UID: a5313661-5c07-425d-855f-1ab66b4c8933
このユーザにデータを登録する。データは以下のようにチャットのメッセージ形式を ChatBlob デラップして渡す。
from memobase import MemoBaseClient
from memobase import ChatBlob
client = MemoBaseClient(
project_url="http://localhost:8019",
api_key="secret",
)
uid = "a5313661-5c07-425d-855f-1ab66b4c8933"
b = ChatBlob(messages=[
{
"role": "user",
"content": "はじめまして。私は太郎といいます。普段はエンジニアをやっています。よろしくお願いします。"
},
{
"role": "assistant",
"content": "太郎さん、はじめまして。こちらこそよろしくお願いします。今日はどんなご用ですか?"
}
])
u = client.get_user(uid)
bid = u.insert(b)
print("BID:", bid)
bidってのはおそらく BLOB ID ということだろう。
BID: 9e4830a3-48b7-445b-9e1b-22792d660dfc
この bid を参照してみる。
from memobase import MemoBaseClient
from memobase import ChatBlob
client = MemoBaseClient(
project_url="http://localhost:8019",
api_key="secret",
)
uid = "a5313661-5c07-425d-855f-1ab66b4c8933"
bid = "9e4830a3-48b7-445b-9e1b-22792d660dfc"
u = client.get_user(uid)
b = u.get(bid)
print(b.model_dump())
ちょっと見やすいように改行を入れているが、先ほど登録したメッセージが含まれていて、日付などが付与されているのがわかる。
{
'type': <BlobType.chat: 'chat'>,
'fields': None,
'created_at': datetime.datetime(2025, 4, 24, 16, 27, 32, 550955, tzinfo=TzInfo(UTC)),
'messages': [
{'role': 'user', 'content': 'はじめまして。私は太郎といいます。普段はエンジニアをやっています。よろしくお願いします。', 'alias': None, 'created_at': None},
{'role': 'assistant', 'content': '太郎さん、はじめまして。こちらこそよろしくお願いします。今日はどんなご用ですか?', 'alias': None, 'created_at': None}
]
}
削除は以下のような感じで行えるが、このまま続けるので、一旦削除せずに置いておく。
u.delete(bid)
メモリの操作
ここまででMemobaseにユーザの会話データが登録されたが、どうやらここまではあくまでも「バッファ」に登録されたような状態になる様子。実際に使うには「抽出」を行う。
from memobase import MemoBaseClient
from memobase import ChatBlob
client = MemoBaseClient(
project_url="http://localhost:8019",
api_key="secret",
)
uid = "a5313661-5c07-425d-855f-1ab66b4c8933"
u = client.get_user(uid)
# バッファをフラッシュして、メモリの抽出を行う
u.flush()
# ユーザのメモリプロファイルを取得する
print(u.profile())
以下のような感じで、名前と職業が記録されているのがわかる。
[
UserProfile(
id=UUID('aaf0557f-da30-4165-b83d-bccb4dea2af0'),
created_at=datetime.datetime(2025, 4, 24, 16, 28, 27, 624399, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 24, 16, 28, 27, 624399, tzinfo=TzInfo(UTC)),
topic='work',
sub_topic='title', content='エンジニア'
),
UserProfile(
id=UUID('b8a6db56-60a8-4a37-bc58-820fa2dd6c9e'),
created_at=datetime.datetime(2025, 4, 24, 16, 28, 27, 624399, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 24, 16, 28, 27, 624399, tzinfo=TzInfo(UTC)),
topic='basic_info',
sub_topic='name',
content='太郎'
)
]改めて見ると、ユーザ作成時の辞書データはおそらくメタデータに近いもので、実際のメモリとなるのはユーザデータから情報を抽出するということなのだろうと思う。ただ、メタデータだったとしても、データ構造が変わるってのは変だよなぁ。バグっぽく思えるけど、あまりそこは使われていないのかもね。
ユーザプロファイル
冒頭で記載した通り、Memobaseは「プロファイルベース」のメモリとなっている。こんな感じ。
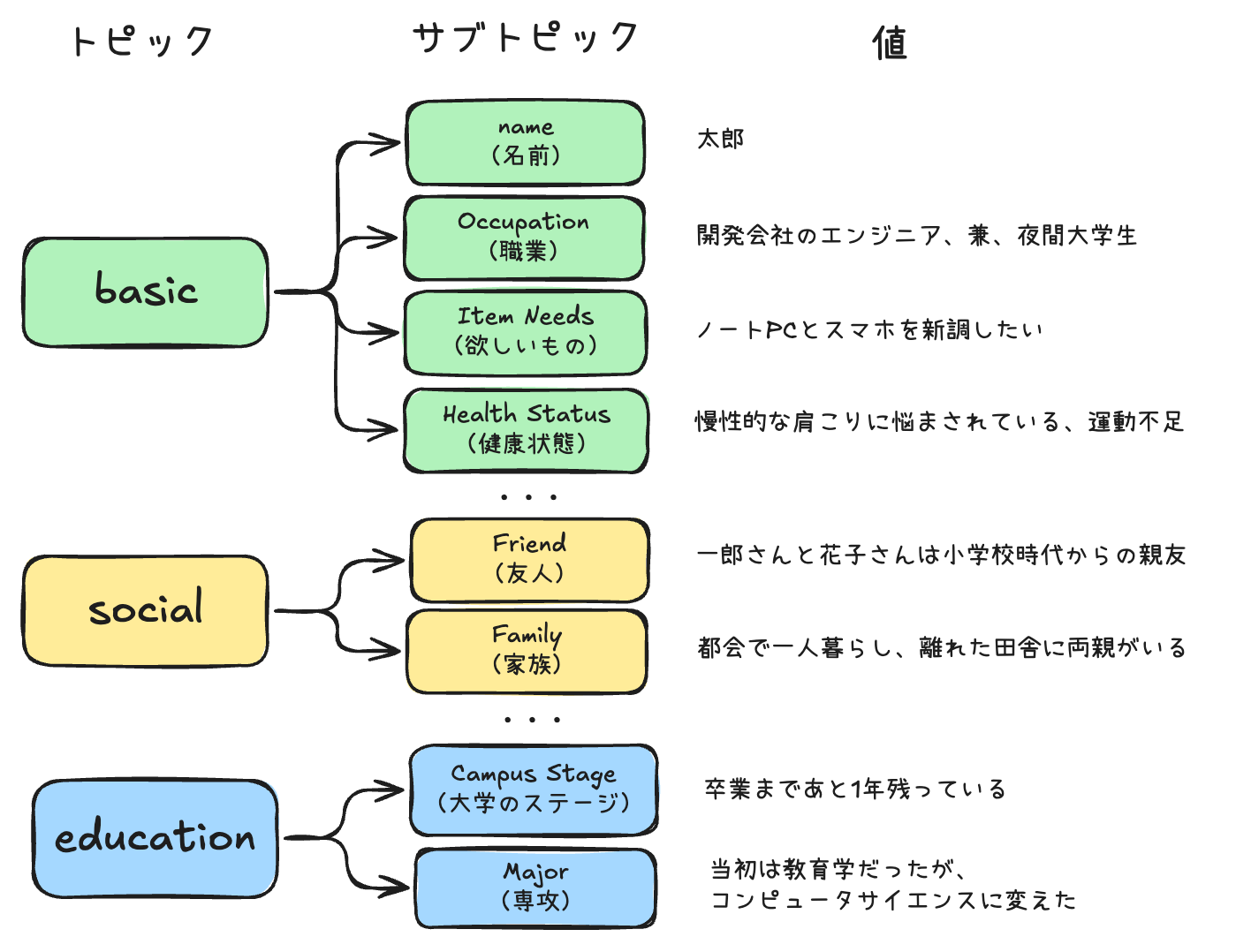
referred from https://docs.memobase.io/features/profile/profile and translated/rewritten by kun432
このプロファイルの項目は、大抵のユースケースに合うようにあらかじめビルトインで定義されている。多分このあたり。
でapi/config.yamlでこれをカスタマイズできる。方法は2つ。
-
additional_user_profilesで、ビルトインの定義に追加 -
overwrite_user_profilesで、ビルトインの定義を上書きして全部自分で作る。
YAMLの定義については以下。
基本的には、「トピック」・「サブトピック」・「スロット(項目)」という基本的な形は決まっているみたい。descriptionを追加すると、データのフォーマットや更新方法などを記載できる。つまりプロンプトなのだと思う。
overwrite_user_profiles:
- topic: "work"
sub_topics:
- "company"
- "position"
- "department"
- "start_date"
- "achievements"
- name: "start_date"
description: "The start date of new job, in format YYYY-MM-DD"
プロファイルは基本的に検証されていて、LLMが正しく抽出できなかった場合(「ユーザは仕事について話しませんでした」とか)は登録されないらしい。あと、プロファイルで定義されたスロットはあらかじめ決めたもの以外に追加されることもあるらしく、これを定義に厳密にさせる(定義されたもの以外は追加しない)、みたいなこともできるみたい。
ユーザイベント
イベントはその名の通り、ユーザの「イベント」を記録する。以下のようなデータが保存される。
- イベントの概要: (オプション)ユーザーの最近の体験の簡潔な要約。
-
イベントのタグ: (オプション)イベントの意味的なタグ(例:
感情::幸せ、`目標::家を購入``)。デフォルトは空。独自のイベントタグを設計することも可能。 - 部分的プロファイル: (必須)このイベントで抽出されたプロファイルスロット。
- 作成時間: (必須)
イベント的な内容を含む対話をユーザデータとして登録してみる。
from memobase import MemoBaseClient
from memobase import ChatBlob
client = MemoBaseClient(
project_url="http://localhost:8019",
api_key="secret",
)
uid = "a5313661-5c07-425d-855f-1ab66b4c8933"
b = ChatBlob(messages=[
{
"role": "user",
"content": "明日は、競馬観戦に行く予定なんだよね。楽しみ〜。お天気はどうかな?"
},
{
"role": "assistant",
"content": "太郎さん、すごく楽しそうですね!明日の阪神競馬場の天気は晴れで、最高の観戦日和になると思いますよ!"
}
])
u = client.get_user(uid)
bid = u.insert(b)
print("BID:", bid)
BID: d2440841-ecd2-4c17-b188-008af403f0ad
バッファをフラッシュして会話の内容からプロファイルやイベントを抽出する。イベントの参照は.event()メソッドで取得できる。
from memobase import MemoBaseClient
from memobase import ChatBlob
client = MemoBaseClient(
project_url="http://localhost:8019",
api_key="secret",
)
uid = "a5313661-5c07-425d-855f-1ab66b4c8933"
u = client.get_user(uid)
# バッファをフラッシュして、メモリの抽出を行う
u.flush()
# ユーザのメモリプロファイルを取得する
print("=== プロファイル ===")
print(u.profile())
# ユーザのイベントを取得する
print("=== イベント ===")
print(u.event())
プロファイルとイベント
=== プロファイル ===
[
UserProfile(
id=UUID('49afdfcb-34c0-49ae-9f1c-3ce21f6ef768'),
created_at=datetime.datetime(2025, 4, 25, 3, 44, 21, 810928, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 25, 3, 44, 21, 810928, tzinfo=TzInfo(UTC)),
topic='interest',
sub_topic='sports',
content='User is planning to go to horse racing on 2025/04/26'
),
UserProfile(
id=UUID('62219b29-9b1c-4046-a866-64d6d038324d'),
created_at=datetime.datetime(2025, 4, 25, 3, 44, 21, 810928, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 25, 3, 44, 21, 810928, tzinfo=TzInfo(UTC)),
topic='interest',
sub_topic='sports_event',
content='User is going to Hanshin Racecourse for horse racing'
),
UserProfile(
id=UUID('aaf0557f-da30-4165-b83d-bccb4dea2af0'),
created_at=datetime.datetime(2025, 4, 24, 16, 28, 27, 624399, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 24, 16, 28, 27, 624399, tzinfo=TzInfo(UTC)),
topic='work',
sub_topic='title',
content='エンジニア'
),
UserProfile(
id=UUID('b8a6db56-60a8-4a37-bc58-820fa2dd6c9e'),
created_at=datetime.datetime(2025, 4, 24, 16, 28, 27, 624399, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 24, 16, 28, 27, 624399, tzinfo=TzInfo(UTC)),
topic='basic_info',
sub_topic='name',
content='太郎'
)
]
=== イベント ===
[
UserEventData(
id=UUID('7ca64035-767a-49c3-a03d-c93919a74665'),
event_data=EventData(
profile_delta=[
ProfileDelta(
content='user is planning to go to horse racing on 2025/04/26',
attributes={'topic': 'interest', 'sub_topic': 'sports'}
),
ProfileDelta(
content='user is going to Hanshin Racecourse for horse racing',
attributes={'topic': 'interest', 'sub_topic': 'sports_event'}
)
],
event_tip=None,
event_tags=None
),
created_at=datetime.datetime(2025, 4, 25, 3, 44, 21, 802302, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 25, 3, 44, 21, 802302, tzinfo=TzInfo(UTC))
),
UserEventData(
id=UUID('8a48d5f9-e615-4012-aad1-d25c7506c20d'),
event_data=EventData(
profile_delta=[
ProfileDelta(
content='太郎',
attributes={'topic': 'basic_info', 'sub_topic': 'name'}
),
ProfileDelta(
content='エンジニア',
attributes={'topic': 'work', 'sub_topic': 'title'}
)
],
event_tip=None,
event_tags=None
),
created_at=datetime.datetime(2025, 4, 24, 16, 28, 27, 612834, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 24, 16, 28, 27, 612834, tzinfo=TzInfo(UTC))
)
]
イベント不要でプロファイルだけで良い場合はイベントの要約を無効にしたり、
イベントのタグをどのようにつけるか?を定義することもできる。
パーソナライズされたコンテキスト
取得したプロファイルやイベントを、パーソナライズされたコンテキストとして取り出すことができる。
ここまでの流れをひとまとめにしたものが以下。ドキュメントにあるサンプルコードだと上手くいかなかったので、u.flush()を追加したりしてる。
from memobase import MemoBaseClient, ChatBlob
client = MemoBaseClient(
project_url="http://localhost:8019",
api_key="secret",
)
uid = client.add_user()
print("UID:", uid)
print()
u = client.get_user(uid)
u.insert(
ChatBlob(
messages=[
{
"role": "user",
"content": "はじめまして。私は太郎といいます。普段はエンジニアをやっています。よろしくお願いします。",
},
{
"role": "assistant",
"content": "太郎さん、はじめまして。こちらこそよろしくお願いします。ご機嫌いかがですか?"
},
{
"role": "user",
"content": "明日は、競馬観戦に行く予定なんだよね。楽しみ〜。お天気はどうかな?"
},
{
"role": "assistant",
"content": "すごく楽しそうですね!明日の阪神競馬場の天気は晴れで、最高の観戦日和になると思いますよ!"
}
]
)
)
# これを実行しないと出力されなかった
u.flush()
# ユーザのメモリプロファイルを取得する
print("=== プロファイル ===")
print(u.profile())
print()
# ユーザのイベントを取得する
print("=== イベント ===")
print(u.event())
print()
# ユーザのコンテキストを取得する
print("=== コンテキスト ===")
print(u.context())
print()
UID: cf955930-7f30-439f-bafa-0d4ea9419f81
=== プロファイル ===
[
UserProfile(
id=UUID('1d23b6b5-22d9-4da0-98ab-67c97ff12b37'),
created_at=datetime.datetime(2025, 4, 25, 13, 52, 23, 805199, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 25, 13, 52, 23, 805199, tzinfo=TzInfo(UTC)),
topic='work',
sub_topic='title',
content='エンジニア'
),
UserProfile(
id=UUID('61974e77-b22e-4bfc-b1d7-cc705ef58d09'),
created_at=datetime.datetime(2025, 4, 25, 13, 52, 23, 805199, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 25, 13, 52, 23, 805199, tzinfo=TzInfo(UTC)),
topic='interest',
sub_topic='sports',
content='競馬観戦が好き'
),
UserProfile(
id=UUID('d1504c51-c6f9-488f-a718-ad58b1dbf9ea'),
created_at=datetime.datetime(2025, 4, 25, 13, 52, 23, 805199, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 25, 13, 52, 23, 805199, tzinfo=TzInfo(UTC)),
topic='basic_info',
sub_topic='name',
content='太郎'
),
UserProfile(
id=UUID('ef5dafe5-13f6-4169-9263-3b01528aecfc'),
created_at=datetime.datetime(2025, 4, 25, 13, 52, 23, 805199, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 25, 13, 52, 23, 805199, tzinfo=TzInfo(UTC)),
topic='interest',
sub_topic='event',
content='明日、競馬観戦に行く予定'
)
]
=== イベント ===
[
UserEventData(
id=UUID('a60fed33-eca4-4704-adf7-159a47c08adb'),
event_data=EventData(
profile_delta=[
ProfileDelta(
content='太郎',
attributes={'topic': 'basic_info', 'sub_topic': 'name'}
),
ProfileDelta(
content='エンジニア',
attributes={'topic': 'work', 'sub_topic': 'title'}
),
ProfileDelta(
content='競馬観戦が好き',
attributes={'topic': 'interest', 'sub_topic': 'sports'}
),
ProfileDelta(
content='明日、競馬観戦に行く予定',
attributes={'topic': 'interest', 'sub_topic': 'event'}
)
],
event_tip=None,
event_tags=None
),
created_at=datetime.datetime(2025, 4, 25, 13, 52, 23, 798977, tzinfo=TzInfo(UTC)),
updated_at=datetime.datetime(2025, 4, 25, 13, 52, 23, 798977, tzinfo=TzInfo(UTC))
)
]
=== コンテキスト ===
<memory>
# Below is the user profile:
- work::title: エンジニア
- interest::sports: 競馬観戦が好き
- basic_info::name: 太郎
- interest::event: 明日、競馬観戦に行く予定
# Below is the latest events of the user:
2025/04/25:
- basic_info::name: 太郎
- work::title: エンジニア
- interest::sports: 競馬観戦が好き
- interest::event: 明日、競馬観戦に行く予定
</memory>
Please provide your answer using the information within the <memory> tag at the appropriate time.
この最後の部分をプロンプトに入れ込めばよいということになる。
あと、ユーザ追加時に渡す辞書はオプションみたい。上の方で書いたような更新時にデータ構造がおかしくなるっていうの、案外気づかれていないだけでは?という気がしてきた。
uid = client.add_user()
ドキュメントにあるサンプルコードだと上手くいかなかったので、u.flush()を追加したりしてる。
このflushを行うべきタイミングだけども、Quickstartには以下とあった。
flush: ユーザーデータは、バッファが容量いっぱいになるか、アイドル状態が一定時間続いた場合にバッファから削除されます。バッファをフラッシュして、メモリの抽出を手動で実行することができます。
まあLLMに処理させるので、会話の中でやるよりは別のタイミングでやりたいような気はするが、手動でやらないのいけないのかな?
というところがTIPSに書いてあった
Memobase はメモリをすぐに更新しません。以下の条件のいずれかが満たされた場合にのみ更新されます:
- バッファが肥大化: Memobase はユーザー未処理のメッセージのサイズを追跡し、制限を超えた場合、バッファをデータベースにフラッシュします。
- バッファが長時間アイドル状態: Memobase は、一定時間のアイドル状態が続いた後、バッファをデータベースにフラッシュします。
flushAPI を手動で呼び出した場合通常は、チャット セッションが閉じられた直後に
flushAPI を呼び出すべきです。
なるほど、最初の文章だと「抽出されずに消えてしまう」のかな?と思ったがそういうわけではなさそう。とはいえ、何らかのタイミングでデータベースに反映するのは必要そう。
上記以外にもTIPSがあるので、目を通しておくと良さそう。
OpenAI APIと組み合わせる
MemobaseはOpenAI Python SDKのクライアントをラップするような関数が用意されている(Memobaseではこれを「パッチ」と言っている)。これを使えば、OpenAI SDKの書き方を維持しつつ、Memobaseをインテグレーションできるようになっている。
from openai import OpenAI
from memobase import MemoBaseClient
from memobase.patch.openai import openai_memory
# OpenAIのクライアントを作成
client = OpenAI()
# MemoBaseのクライアントを作成
mb_client = MemoBaseClient(
project_url="http://localhost:8019",
api_key="secret",
)
# openai_memoryで、OpenAIのクライアントとMemoBaseのクライアントをラップして統合
client = openai_memory(client, mb_client)
# ユニークなユーザIDを設定
user_id = "test001"
messages = []
while True:
input_text = input("ユーザー: ")
if input_text in ["quit", "exit", "終了"]:
# 発話内容からプロファイルを抽出してMemobaseにフラッシュ
client.flush(user_id)
print("チャットを終了します・・・")
break
messages.append({"role": "user", "content": input_text})
# 普通にOpenAIのAPIを呼び出すだけで使える
response = client.chat.completions.create(
messages=messages,
model="gpt-4o-mini",
user_id=user_id, # ユーザIDを指定することでメモリをトリガーできる
store=True, # トレースのため
)
output_text = response.choices[0].message.content
print("AI:", output_text)
messages.append({"role": "assistant", "content": output_text})
ユーザIDを指定することで、メモリがそれに紐づくようになり、プロンプトにプロファイルが埋め込まれるようになるらしい。あと、会話履歴はセッション内では保持しているが、起動時に初期化しているので、セッション間は跨がれないようにしている。で、終了時に会話情報からメモリを抽出してデータベースにフラッシュするという流れ。
なお、store=Trueは、OpenAIのダッシュボード上でログを残して後で見るため。
実行。
uv run openai_patch.py
とりあえずこんな感じで会話セッションを終了。
ユーザー: はじめまして。私は太郎といいます。
AI: はじめまして、太郎さん!どうぞよろしくお願いします。何かお手伝いできることがありますか?
ユーザー: 私の趣味は競馬なんですよ。
AI: 競馬が趣味なんですね!競馬のどの部分が特に好きですか?レース観戦や予想すること、馬の特徴を学ぶことなど、いろいろ楽しめるポイントがありますよね。
ユーザー: そうそう、一番は予想ですかね。
AI: 予想するのが一番の楽しみなんですね!競馬の予想には、馬の成績や騎手、厩舎の情報を分析するのが重要ですよね。最近のレースで注目している馬や騎手はいますか?
ユーザー: モレイラ騎手に注目しています。大活躍してますからね。
AI: モレイラ騎手は本当に素晴らしいですよね!彼のレース運びやテクニックは多くのファンに支持されています。最近のレースでも活躍しているようですが、特に印象に残ったレースはありますか?
ユーザー: 皐月賞の彼の騎乗は素晴らしかったですね。
AI: 皐月賞でのモレイラ騎手の騎乗は本当に素晴らしかったですね!彼の巧みなレース運びが目立っていました。レースの展開をどのように見ましたか?特に印象に残ったポイントなどあれば教えてください。
ユーザー: 終了
チャットを終了します・・・
では再度実行
uv run openai_patch.py
ユーザー: おはよう!
AI: おはようございます、太郎さん!今日はどんなことを考えていますか?
ユーザー: 今日も競馬のことを考えています。
AI: 競馬の予想を楽しんでいるんですね!最近のレースや注目している馬についてお話ししたいことはありますか?モレイラ騎手についても何か気になることがあれば教えてください。
ユーザー: 私について知ってることをリストアップして。
AI: もちろんです、太郎さんについての情報をリストアップしますね。
- 趣味: 競馬
- 競馬の予想をすることが一番の楽しみ
- 注目している人物: モレイラ騎手
- 最近評価した競馬のイベント: 皐月賞でのモレイラ騎手の騎乗が素晴らしかったと感じている
何か他に知りたいことがあれば教えてください!
ユーザー: 終了
チャットを終了します・・・
前回の会話の内容から作成したユーザのプロファイル情報を使って会話ができているのがわかる。
OpenAIのダッシュボードで見てみる。実際には他にも色々出ているのだけども、チャットの最後の部分。

システムプロンプトに初回の会話から抽出された情報が含まれているのがわかる。
なお、Memobaseによって設定されるシステムプロンプトは、既存のシステムプロンプトがあった場合にはその末尾に追加される。例えば上のコードで、システムプロンプトを以下のように設定していた場合だとこうなる。
(snip)
messages = [{"role": "system", "content": "あなたは親切な日本語のチャットボットです。"}]
(snip)

ドキュメントにはより進んだ使い方として
- メモリプロンプトのサイズ
- 追加されるメモリプロンプトのカスタマイズ
- 実際に追加されるメモリプロンプトの確認方法
なども記載されている。
まとめ
メモリ関連のフレームワークやライブラリは過去に以下を試している。
最近はナレッジグラフを使ってメモリを構築するものが増えているような感がある。ナレッジグラフのほうがより複雑な情報の関係性を構築しやすいということなのだろうと思う。自分もナレッジグラフはRAGよりもメモリのほうが扱いやすいと感じている。
ただ、それでもナレッジグラフの運用は正直大変かなというところもあって、あらかじめ定義できるプロファイルベースのもののほうが管理はしやすそうに感じる。プロファイルの項目の定義は、汎用にしようと思うと広すぎて細かいものが拾えなさそう・もしくは膨大になりそう、と思うので、ある程度ユースケースが絞られてれば、データベーススキーマの延長線ぐらいで考えれそうな気がする。
ナレッジグラフベースのものを使う前に、こういうので一度やってみるのはいいかもね。
API的にはもう少し管理用のエンドポイント、例えばユーザ一覧、とかのエンドポイントは欲しいかも。まあ別のデータベースでユーザ管理して紐づけることにはなりそうではあるけど。
なお、対mem0比較が以下に記載されている。
どちらを選んだとしてもメリデメはあるかなと思う
もう少し細かいところを追ってみる。続き。