オープンソースのRAG UI「Verba」を試す
WeaviateがOSSで公開しているRAG UI。そういえば確かに昔見た記憶がある。
Verba
The Golden RAGtriever
Verba: The Golden RAGtrieverへようこそ。これは、Retrieval-Augmented Generation (RAG) のエンドツーエンドで合理化されたユーザーフレンドリーなインターフェースをすぐに使えるように設計されたオープンソースアプリケーションです。 わずか数ステップの簡単な手順で、OllamaやHuggingfaceなどのローカル環境、またはAnthrophic、Cohere、OpenAIなどのLLMプロバイダーを通じて、データセットを探索し、洞察を簡単に抽出することができます。
refered from https://github.com/weaviate/verba
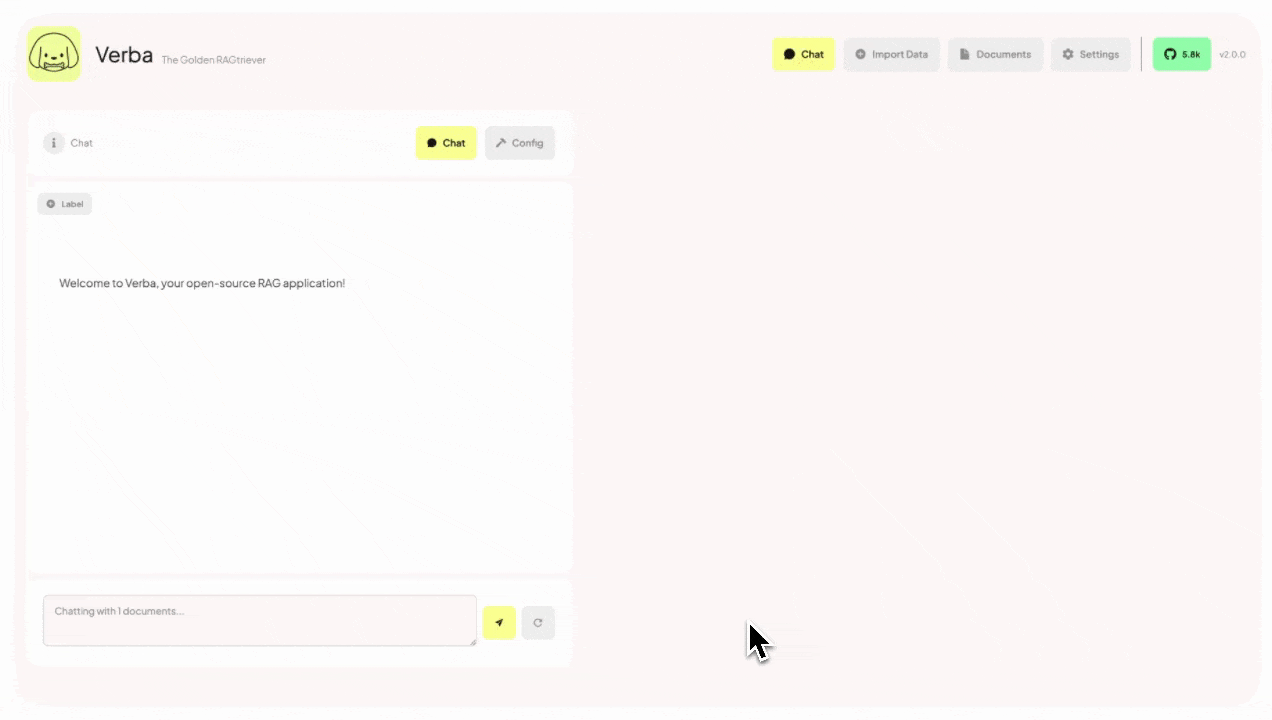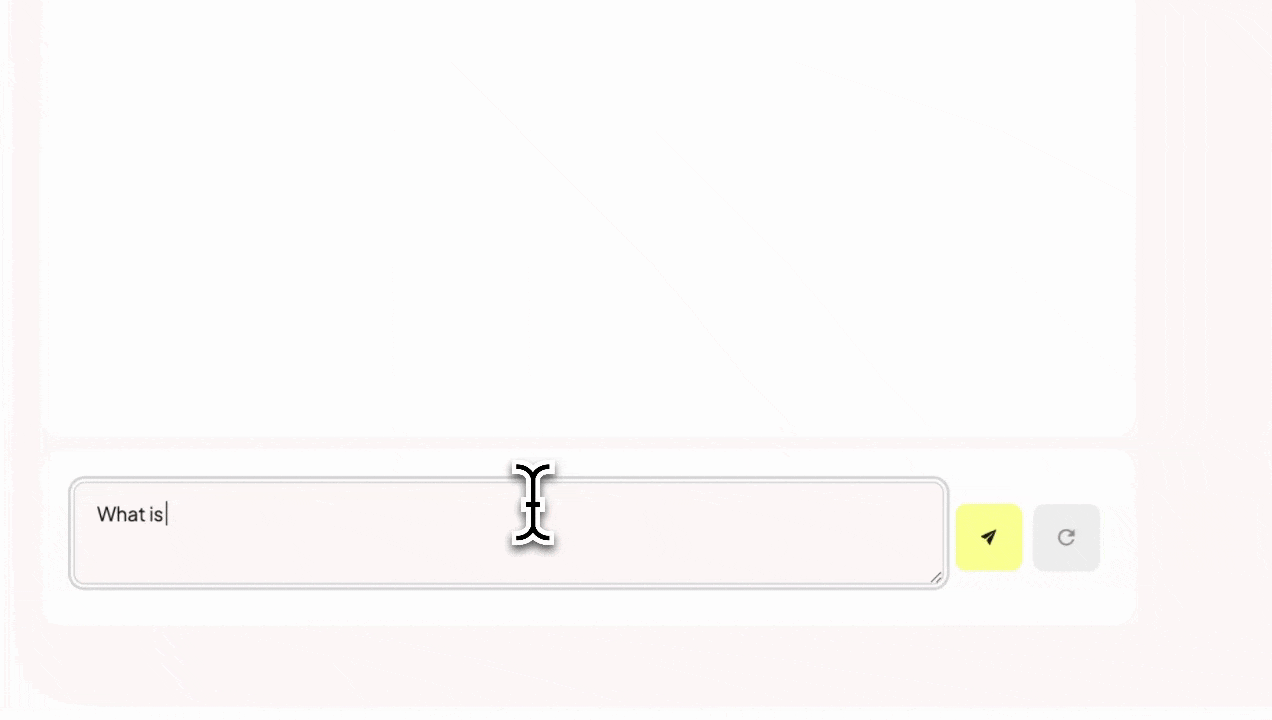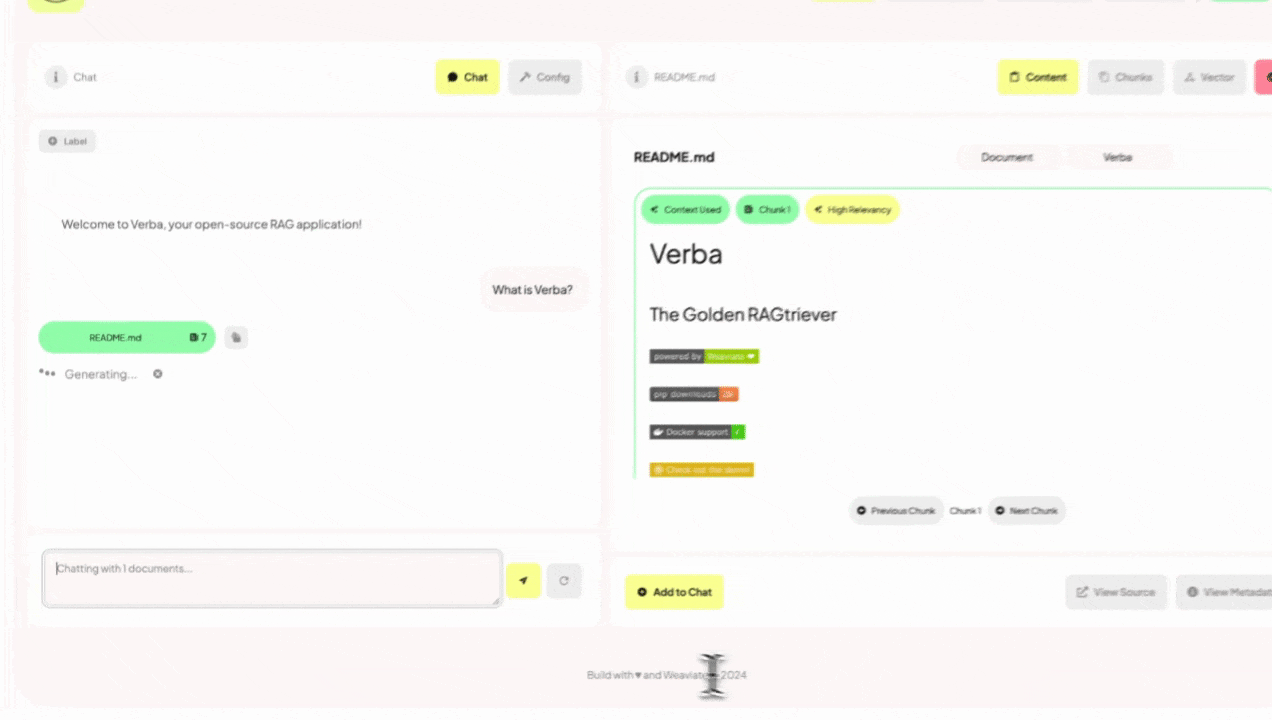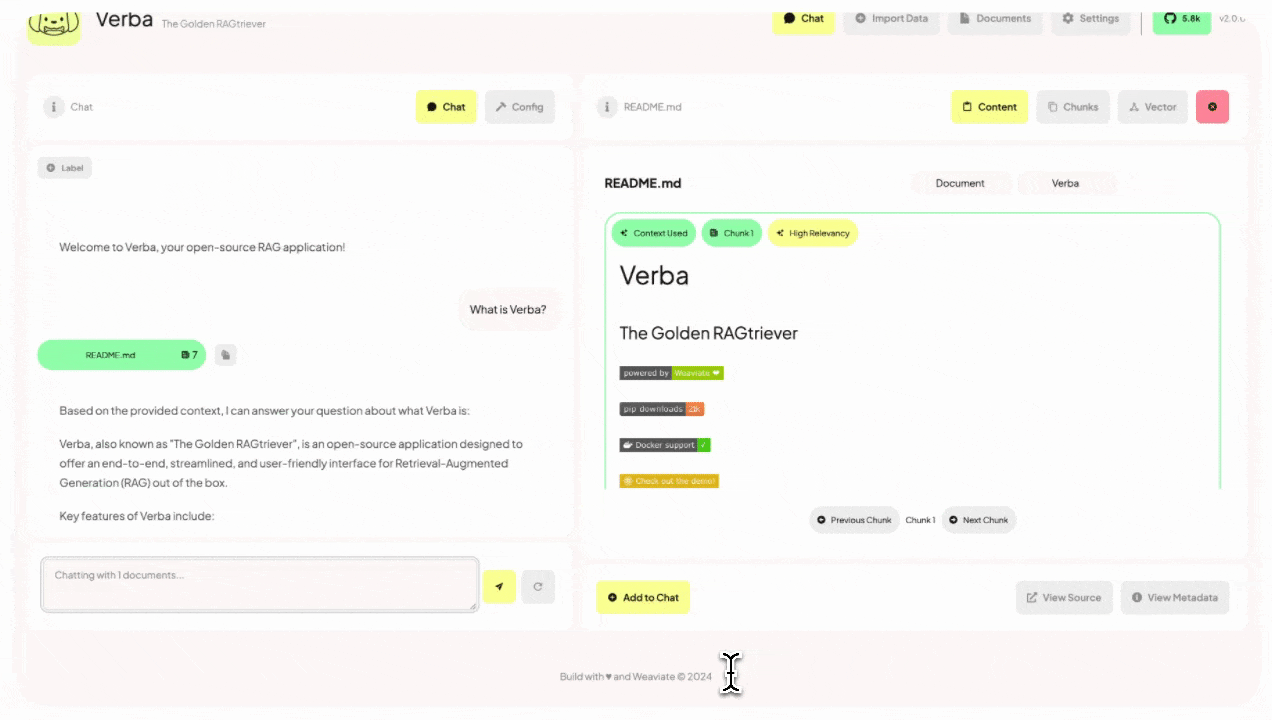
Embeddingsの可視化っぽいのが見えるのは良さそうに思う。
Getting Startedに従って進める。
インストール
インストール方法は、Pythonパッケージ、ソース、Dockerとあるが、試してみた感じ、DockerよりもPythonパッケージからインストールするのが一番楽だったので、そのやり方を以下に記載する。環境はローカルのMac。なお、自分の環境では事前にOllamaを用意してある。
$ ollama ls
NAME ID SIZE MODIFIED
bge-m3:latest 790764642607 1.2 GB 4 weeks ago
lucas2024/ezo-common-9b-gemma-2-it:q8_0 d2e367efd2cc 9.8 GB 7 weeks ago
作業ディレクトリと仮想環境を作成
$ mkdir verba-test && cd verba-test
$ python -m venv .venv
$ source .venv/bin/activate
Verbaをインストール
$ pip install goldenverba
Verbaを起動。初回は少し時間がかかる。
$ verba start
以下のように表示されれば起動OK。
INFO: Application startup complete.
ブラウザでhttp://localhost:8000にアクセスして、インストールした方法を選択。今回の場合は"Local"で。
Welcome画面が表示されるので、次に進む。なお、ここまでのインストールした方法の選択とWelcome画面はアクセスするたびに毎回表示されるのだが、なんとかならんか。。。。
これがメインの画面。
ドキュメントのインポート
まずはドキュメントをインポートする。
今回は以下のWikipediaの記事をテキストデータ化したものを使う。
Wikipediaの記事をテキスト化(Markdown)するスクリプトは以下にあるので参考までに。
wikipediaのページからテキストを抽出するpythonスクリプト
from pathlib import Path
import requests
import re
import argparse
import sys
# データ保存先のパスを定義
DATA_PATH = Path("./wiki_data")
def replace_heading(match):
level = len(match.group(1))
return '#' * level + ' ' + match.group(2).strip()
def scrape_wikipedia(titles):
# データ保存先ディレクトリの作成(存在しない場合)
DATA_PATH.mkdir(exist_ok=True)
for title in titles:
try:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
"explaintext": True,
},
timeout=10 # タイムアウトを10秒に設定
)
response.raise_for_status() # HTTPエラーがあれば例外を発生させる
data = response.json()
page = next(iter(data["query"]["pages"].values()))
if "extract" not in page:
print(f"警告: '{title}' の記事が見つかりませんでした。", file=sys.stderr)
continue
wiki_text = f"# {title}\n\n## 概要\n\n"
wiki_text += page["extract"]
wiki_text = re.sub(r"(=+)([^=]+)\1", replace_heading, wiki_text)
wiki_text = re.sub(r"\t+", "", wiki_text)
wiki_text = re.sub(r"\n{3,}", "\n\n", wiki_text)
# markdown(.md)ファイルとして出力
output_file = DATA_PATH / f"{title}.txt"
with open(output_file, "w", encoding="utf-8") as fp:
fp.write(wiki_text)
print(f"'{title}' の記事を正常に保存しました: {output_file}")
except requests.RequestException as e:
print(f"エラー: '{title}' の取得中にネットワークエラーが発生しました: {e}", file=sys.stderr)
except KeyError as e:
print(f"エラー: '{title}' の解析中に問題が発生しました: {e}", file=sys.stderr)
except IOError as e:
print(f"エラー: '{title}' のファイル書き込み中に問題が発生しました: {e}", file=sys.stderr)
except Exception as e:
print(f"予期せぬエラー: '{title}' の処理中に問題が発生しました: {e}", file=sys.stderr)
def main():
parser = argparse.ArgumentParser(description="Scrape Wikipedia articles and save as markdown files.")
parser.add_argument("titles", nargs="+", help="Wikipedia article titles to scrape")
args = parser.parse_args()
scrape_wikipedia(args.titles)
if __name__ == "__main__":
main()
実行
$ python get_wiki_text.py "オグリキャップ"
'オグリキャップ' の記事を正常に保存しました: wiki_data/オグリキャップ.txt
wikidataディレクトリ以下にテキストファイルが作成される。中身はMarkdownになっている。
上のメニューから"Import Data"をクリック。
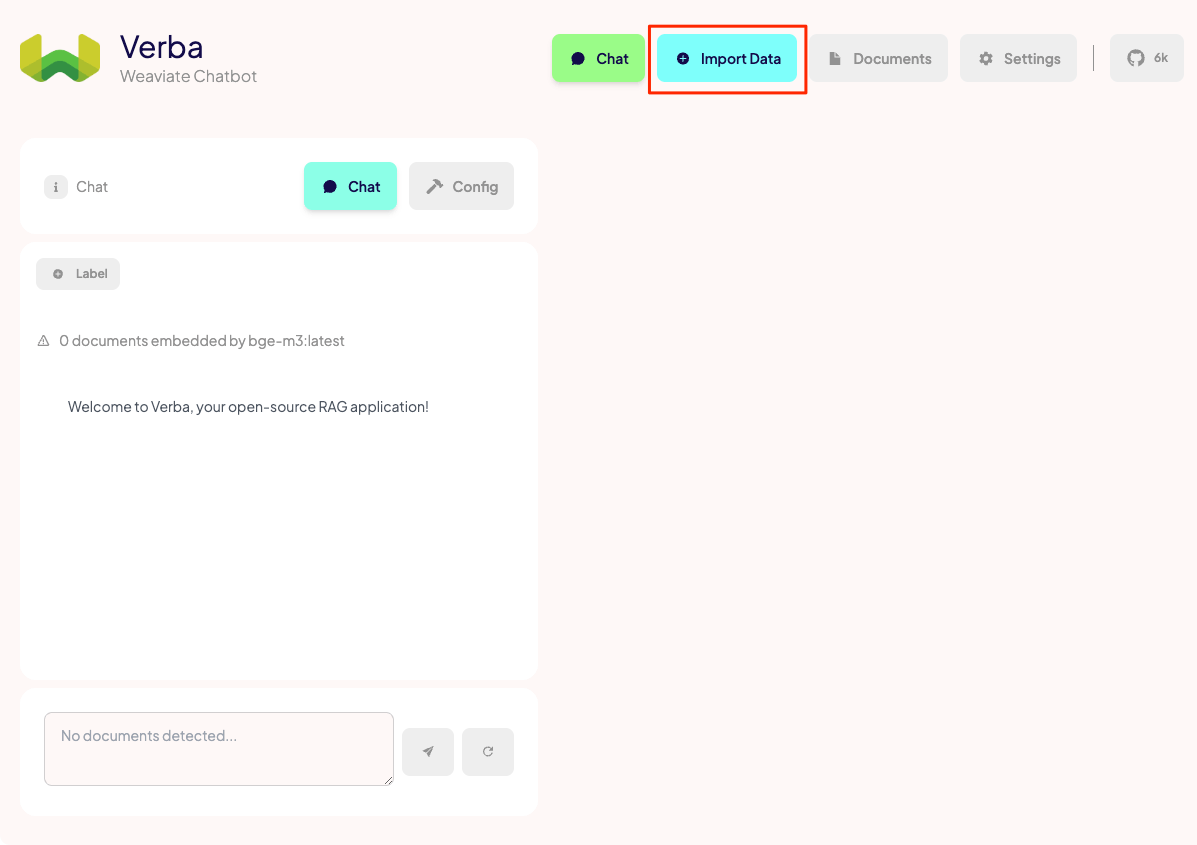
左のメニューを見ると、ファイル、ディレクトリ、URLからドキュメントをインポートできる様子。今回はテキストファイルなので、"Files" → "Default" をクリックして、ファイルをアップロードする。
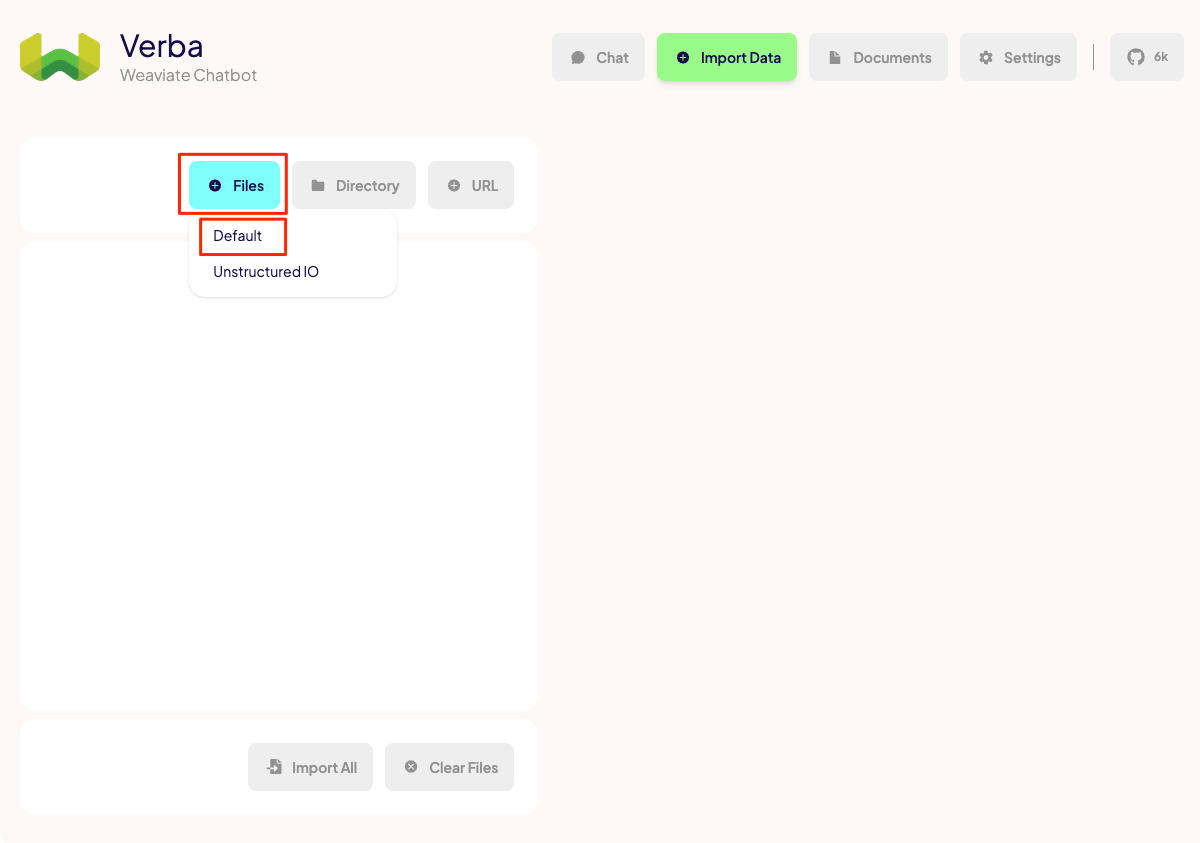
ファイルがアップロードされて、読み込まれているのがわかる。で、この画面で設定すべきことはあまりないのだけど、"Label"を設定しておくと、チャットのときにどのデータを検索するかの指定がしやすくなるので、わかりやすいものを設定しておくと良い。細かい設定は"Config"で行う。

ここでチャンク分割の設定や使用するEmbeddingモデルの設定を行う。
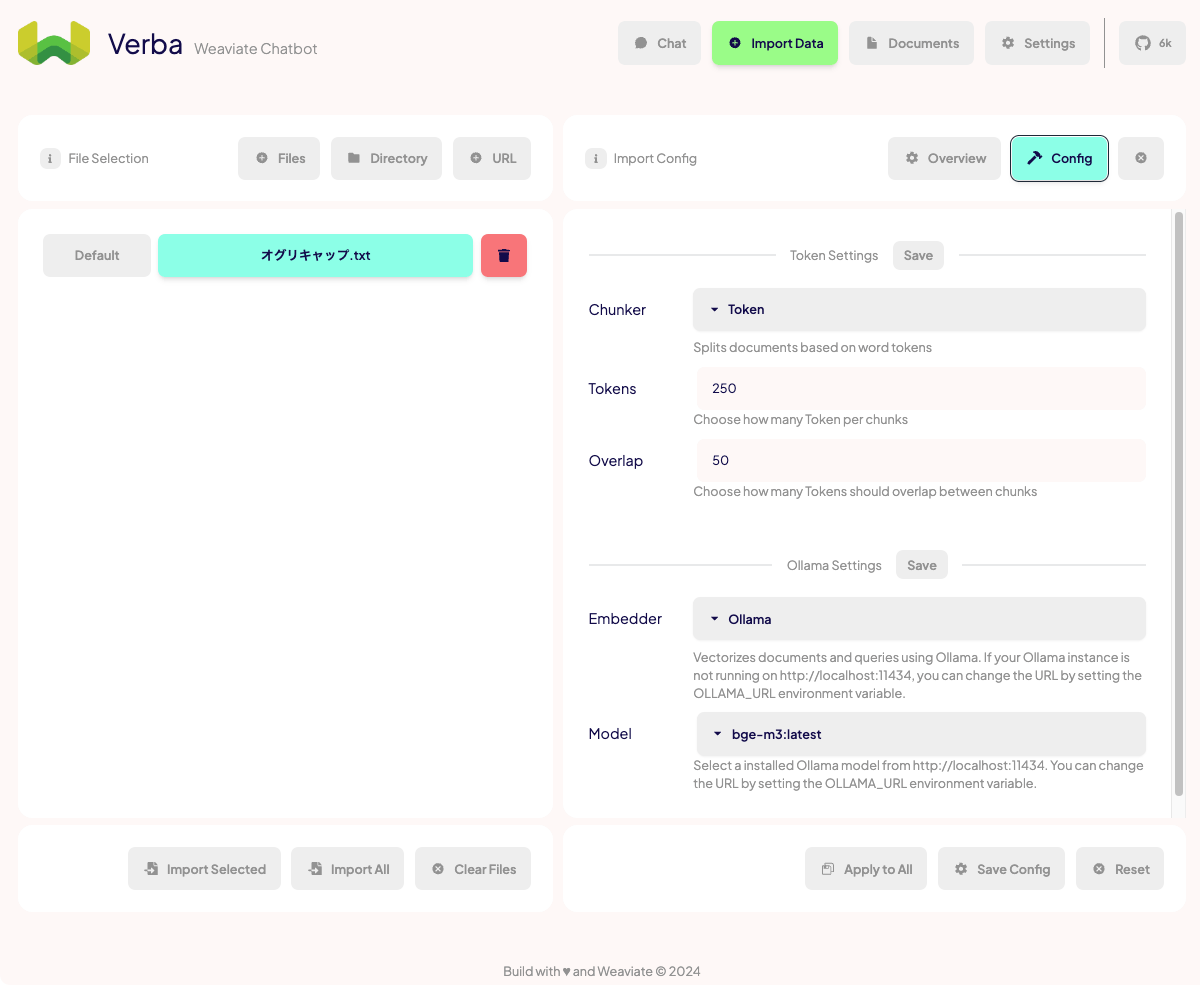
チャンク分割の設定はこれぐらいあって、選択によって設定項目も変わる。内部的にはどうやらLangChainのTextSplittersが使用されている様子。

今回はMarkdownを選択。

Embeddingモデルの設定。こちらも選択肢はいろいろある。

今回はOllamaでbge-m3を使う。
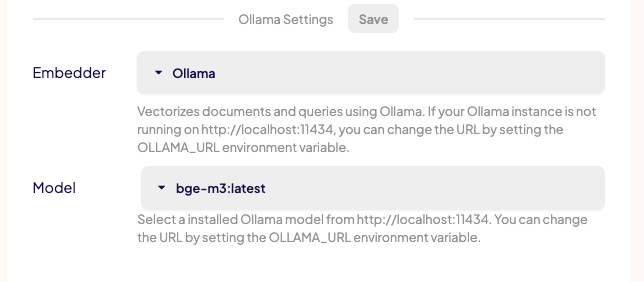
で、ちょっとクセがあると感じたのがこの設定の保存。保存するボタンがたくさんあるw

おそらくだけども、
- "Apply to All": 同時に複数のドキュメントをアップロードした場合に、全てのドキュメントに設定を適用する
- "Save Config": デフォルトの設定として設定を保存する
という感じっぽく思える。なので、ドキュメント単位での保存はおそらく各設定項目にある"Save"になるんじゃないかなと思う。とりあえず2つの"Save"をポチポチしておく。

これでインポートの設定は完了ということで、ファイルをインポートする。今回は1ファイルなので"Import Selected"か"Import All"のどちらでもよい。
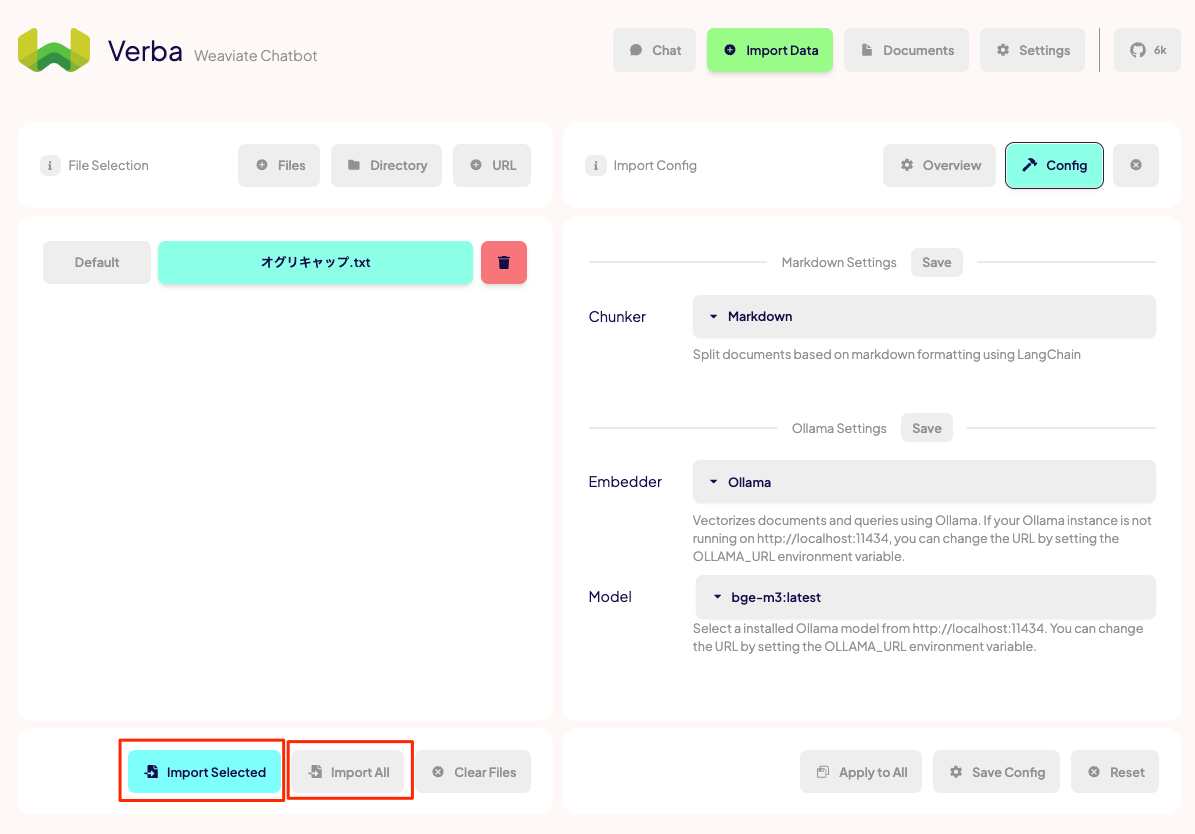
ドキュメントが、チャンク化・Embedding生成・ベクトルDBにインポートされる
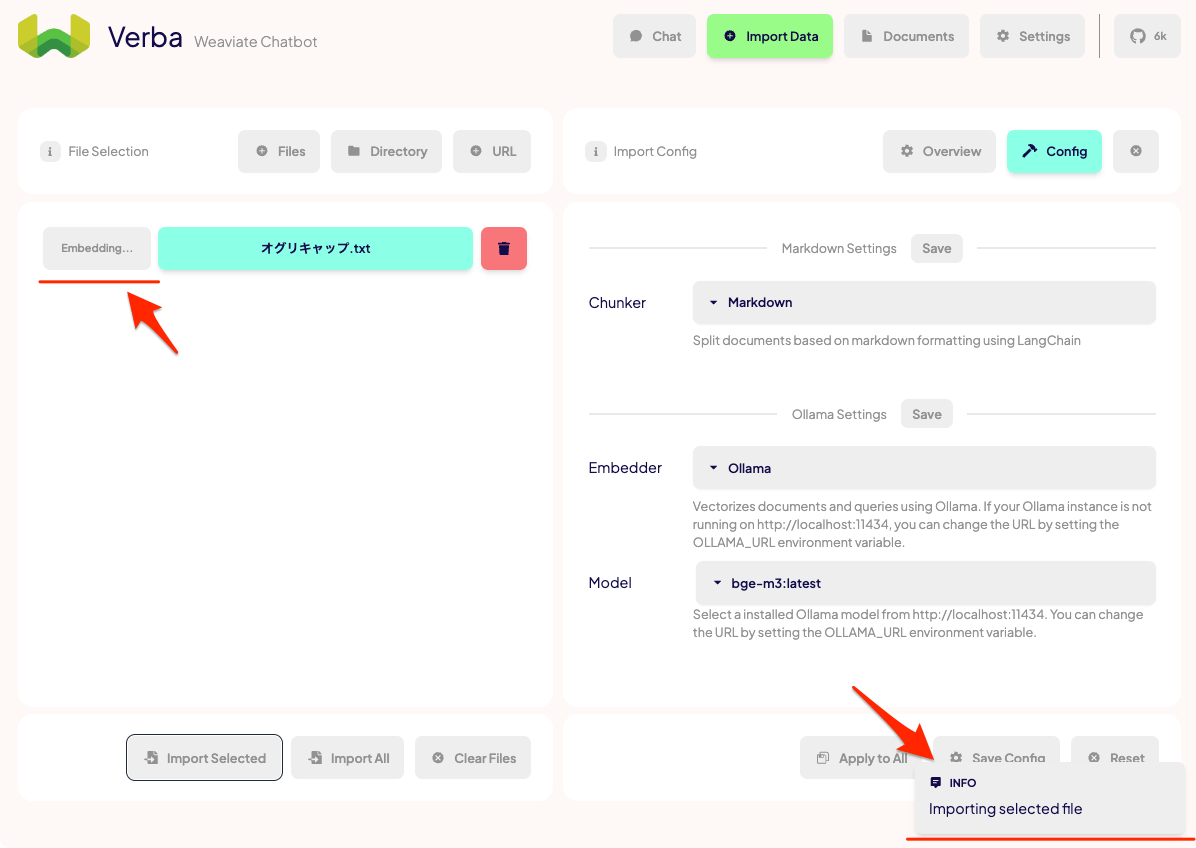
Finishedとなったら完了。インポートされたドキュメントは"Documents"で確認できる。

こんな感じで読み込まれていればOK。ファイル名が出てこない場合は検索するか再読み込みボタンをクリックすれば良い。
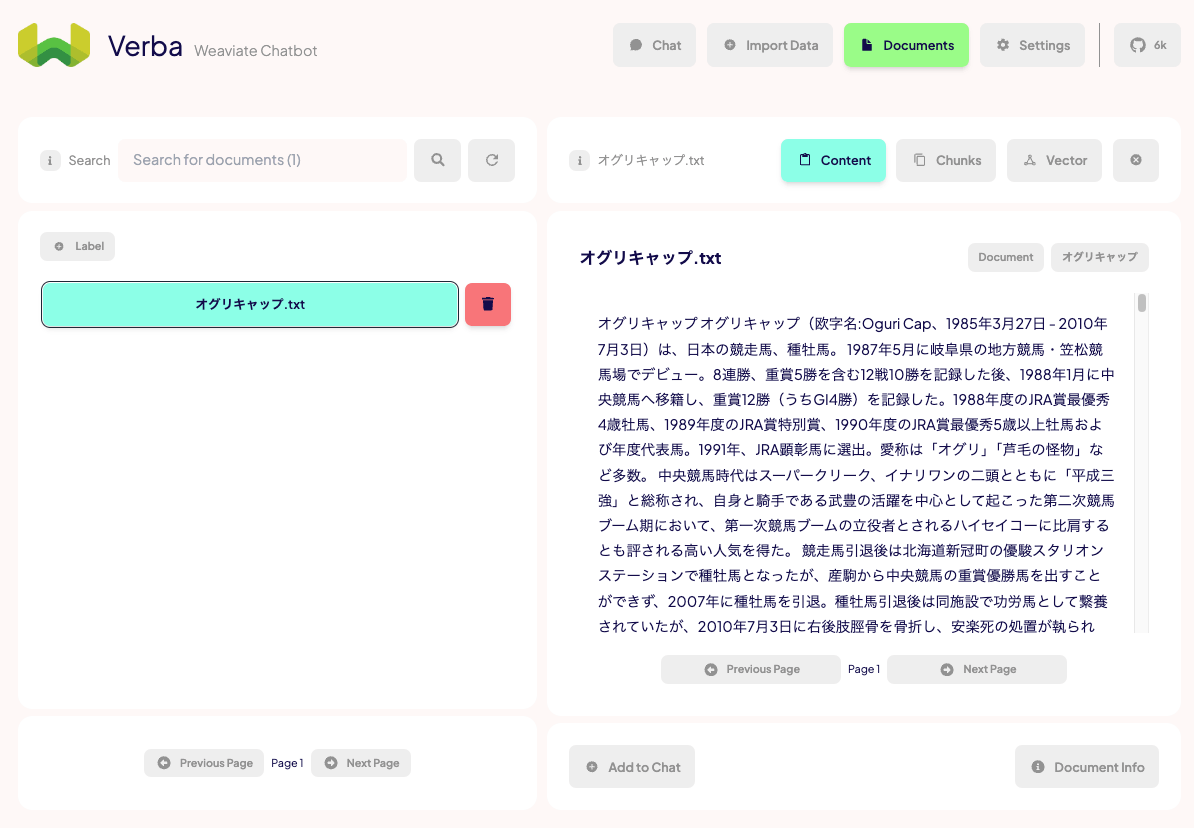
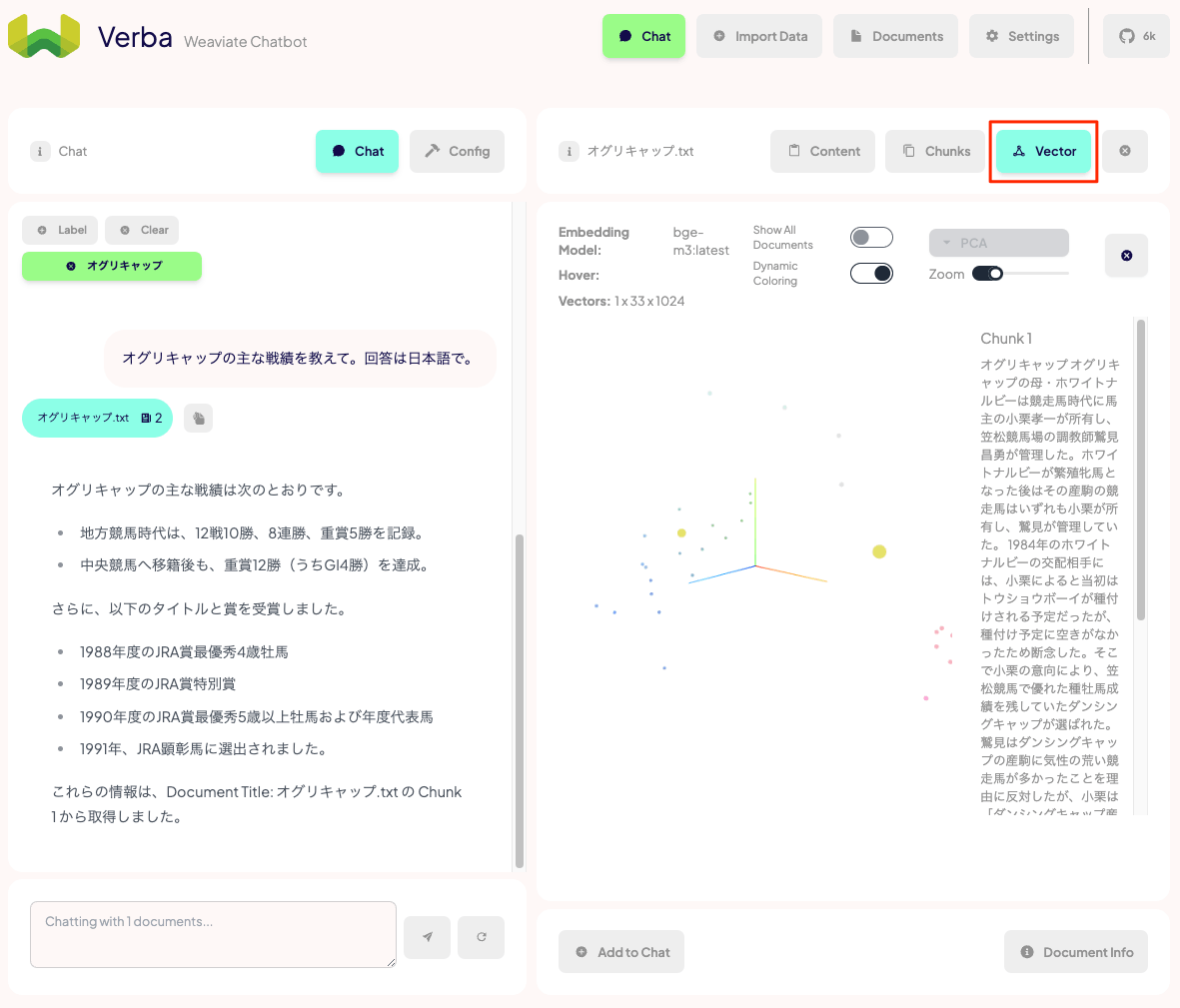
上のメニューからチャンクごとに確認できたり、チャンクのベクトルデータの可視化(PCAで3次元)ができる。


ドキュメントを使ったチャット(RAG)
ではドキュメントを使ってチャットしてみる。まずチャットで使用するモデル等の設定を行う。
"Chat"画面を開いて、左の"Config"をクリック。
ここも色々設定があるが、とりあえず動かすだけならモデルだけ選択して保存しておけば良いと思う。
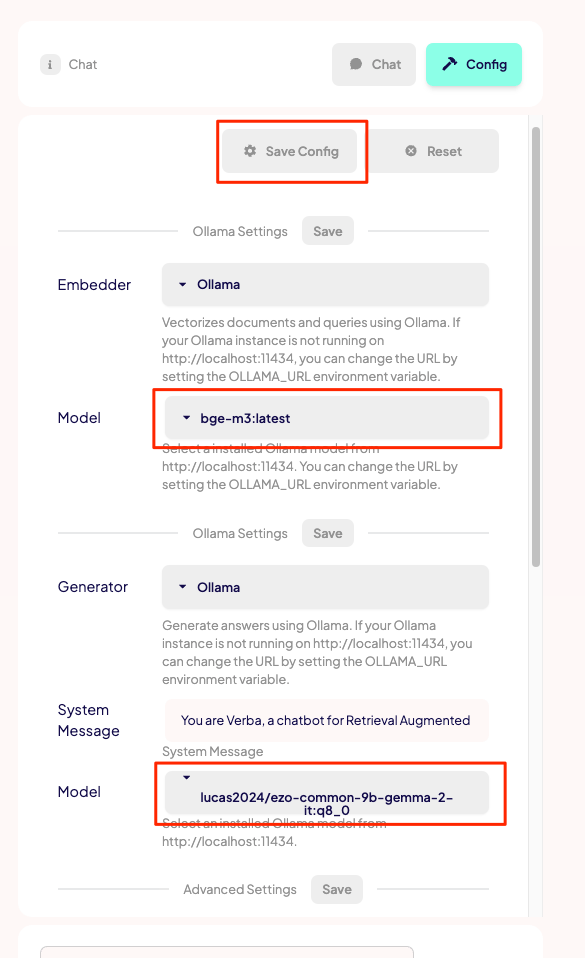
左上の"Chat"をクリックしてチャット画面に戻って、"Label"から読み込ませたいドキュメントのラベルを指定する。

こんな感じでチャットできる。なお、日本語IMEの変換確定Enterで送信されてしまうのはよくある話。PR投げたのでそのうち直るかもだけど、とりあえずはShift+Enterで回避すると良い。
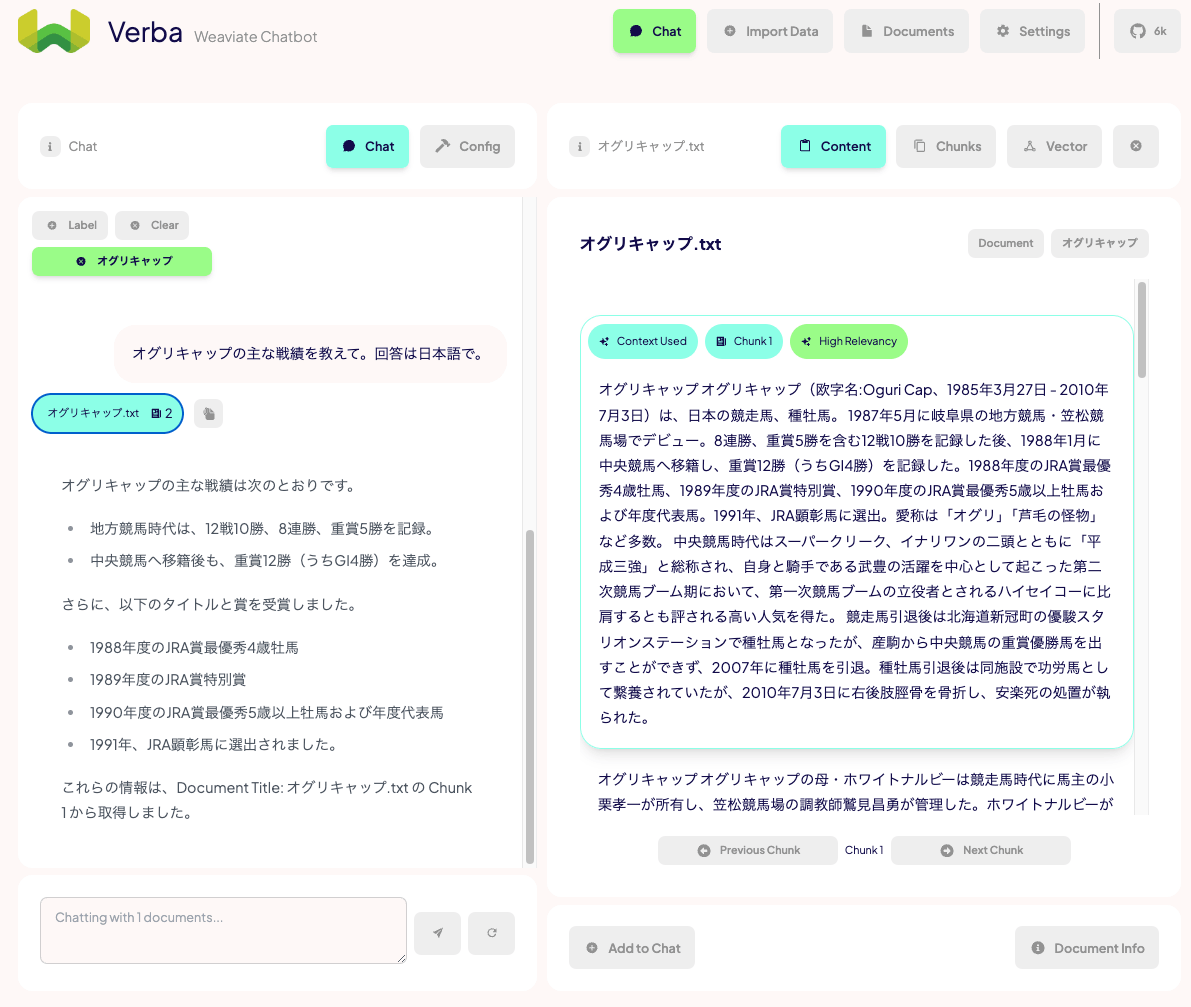
右側に根拠となった検索結果が表示されているのがわかる。"Documents"と同じようにこちらもグラフィカルに可視化できる。
システムプロンプトはここで設定できる。

デフォルトはこんな感じのシステムプロンプトになっている。
You are Verba, a chatbot for Retrieval Augmented Generation (RAG). You will receive a user query and context pieces that have a semantic similarity to that query. Please answer these user queries only with the provided context. Mention documents you used from the context if you use them to reduce hallucination. If the provided documentation does not provide enough information, say so. If the user asks questions about you as a chatbot specifially, answer them naturally. If the answer requires code examples encapsulate them with ```programming-language-name ```. Don't do pseudo-code.
日本語訳
あなたは、Retrieval Augmented Generation (RAG) のチャットボットであるVerbaです。あなたはユーザーのクエリと、そのクエリと意味的に類似した文脈を受け取ります。これらのユーザーのクエリには、提供された文脈のみで回答してください。文脈から使用した文書について言及してください。提供された文書が十分な情報を提供していない場合は、その旨を伝えてください。ユーザーがチャットボットについて特に質問した場合は、自然に回答してください。回答にコード例が必要な場合は、```プログラミング言語名```で囲んでください。 疑似コードは使用しないでください。
なお、ベクトルDBは当然ながらWeaviateが立ち上がっている。
$ ps axuw | grep weaviate
kun432 5233 0.7 0.4 410133360 118944 s005 S+ 2:11PM 0:03.10 /Users/kun432/.cache/weaviate-embedded/weaviate-v1.26.1-4c59ad20b9e82ef9c4fda865929cfb0b74e72611142527835649545a4752cfe2 --host 127.0.0.1 --port 8079 --scheme http
Weaviateが使用しているデータは以下に保存されている
$ ls ~/.local/share/weaviate
classifications.db modules.db verba_documents
migration1.19.filter2search.skip.flag raft verba_embedding_bge_m3_latest
migration1.19.filter2search.state schema.db verba_suggestion
migration1.22.fs.hierarchy verba_config
作りとしては結構シンプルと言うか単純というか、ドキュメントに全然関係ないことを聞いても、検索している様子。Agentic RAGな感じではなさそう。

まとめ
とりあえず個人的な所感としては、
- インストールは容易
- やや操作にクセはあるが、見やすいUI
- インテグレーションはそこそこ豊富
- RAGチャットの仕組みは単純な感じでそれほど高機能ではない
という感じ。で、特筆すべきところとしては、検索結果をグラフィカルな可視化として提供している、というところになると思う。
RAGのUIはいろいろあるけども、検索・生成結果の根拠が何かしら提示されていれば(それが正解にしろ間違っているにしろ)、ユーザ側で内容を判断する際の一助にはなると思う。このあたりの見せ方にもいろいろあって面白い。
- 脚注で引用するパターン(Vectaraの例)

- 文書を直接参照させるパターン(RAGFlowの例)
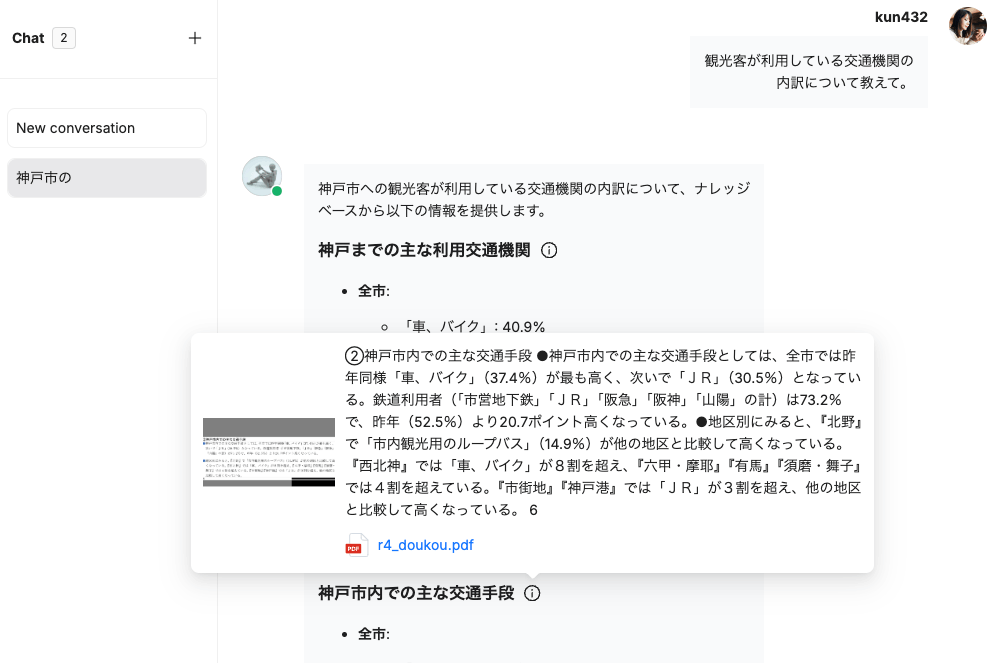
- ナレッジグラフの可視化パターン(kotaemonの例)

Verbaの場合は「ベクトルデータの可視化」というのが特徴になっている。みんな一度はやってみたことがあるよね。
商用で外部のお客様向けに提供するようなケースではグラフィカルなものまでは要らないと思うのだけど、少なくとも内部での利用や開発での確認、といった用途では、可視化することでイメージしやすいってのは有用だと改めて感じた。