Embeddingsの可視化
概要
ベクトル化されたデータを使ったRAGで、クエリに対して適切なデータが検索されない、ことはよくある。
- embeddingsの性能
- データの質
- クエリの質
などの理由が考えられるが、明確な根拠を出すことは難しい。結局のところ試行錯誤するしかないのだけども、もう少しヒントとなるものが欲しい。
OpenAIのcookbookを見ると、embeddingsの可視化に関するnotebookがいくつかある。可視化することで何かしらヒントになるのではないか、ということでいろいろ試してみる。
OpenAI cookbookにあるembeddingsの可視化手法
OpenAI cookbookにあるembeddings可視化のnotebookは以下の5つ。
Matplotlibを使った2D可視化
Matplotlibを使った3D可視化
W&Bを使った2D可視化
Nomic Atlasを使った可視化
Kangas Data Gridを使った2D可視化
その他の可視化手法
TensorBoard Embeddings Projector
環境
ryeでjupyter環境を作る。python-3.11.6。
$ rye init embeddings-visualization
$ cd embeddings-visualization
$ rye pin 3.11.6
$ rye add pip
$ rye add jupyterlab
$ rye add ipywidgets
$ rye add openai
$ rye sync
$ rye run jupyter-lab --ip='0.0.0.0' --NotebookApp.token=''
OpenAI cookbookのレポジトリをクローン、ただし必要なのはデータだけ。コードは自分で調べつつ書く。
$ git clone !git clone https://github.com/openai/openai-cookbook
Matplotlib/Plotlyを使った2D可視化
Amazonの商品レビューのデータセットにembeddingsを追加したものを使ってやっていく。英語。
pandasデータフレームに読み込む。
!pip install pandas
import pandas as pd
datafile_path = "openai-cookbook/examples/data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
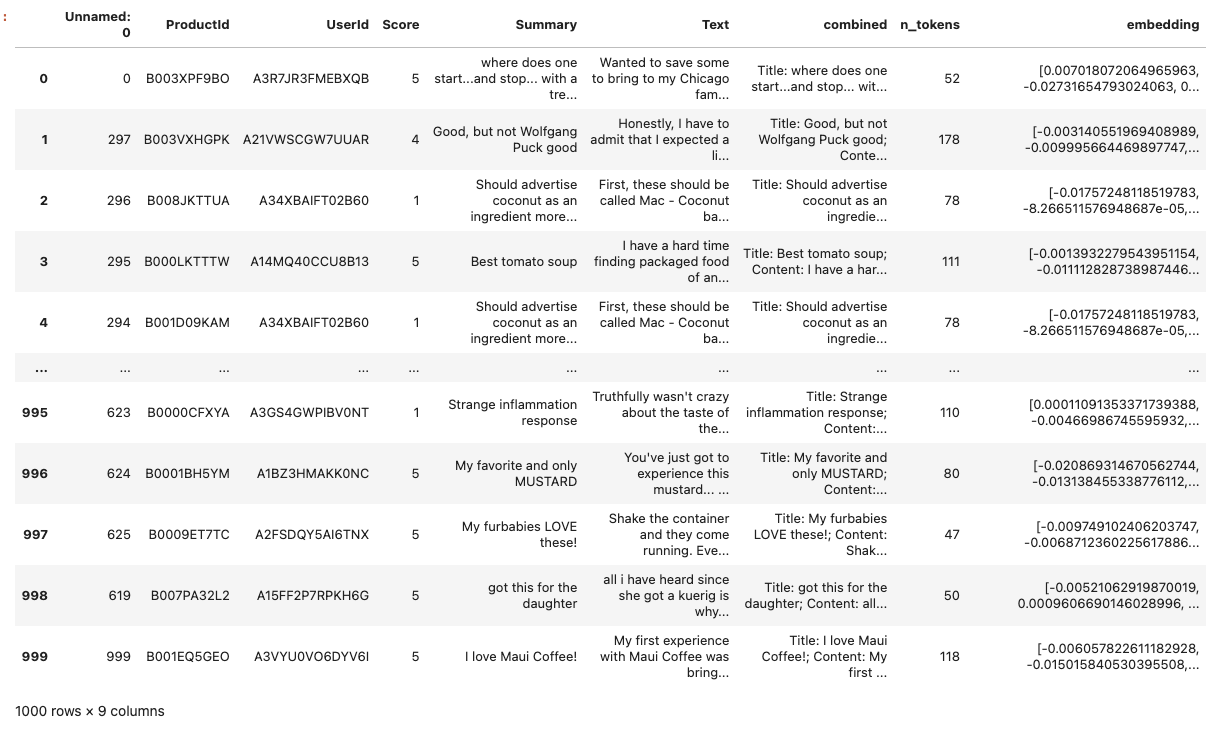
以下で構成されている。
- ProductId
- UserId
- Score
- Summary
- Text
- combined
- n_tokens
- embedding
combinedがおそらくembeddingの元となるテキストで、SummaryとTexを組み合わせたものと思われる。
df["combined"][0]
'Title: where does one start...and stop... with a treat like this; Content: Wanted to save some to bring to my Chicago family but my North Carolina family ate all 4 boxes before I could pack. These are excellent...could serve to anyone'
可視化は2次元で行うが、OpenAI のEmbeddingsは1536次元となっているため、圧縮しないと表現できない。t-SNEを使って圧縮する。
!pip install scikit-learn
from sklearn.manifold import TSNE
import numpy as np
from ast import literal_eval
matrix = np.array(df.embedding.apply(literal_eval).to_list())
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims = tsne.fit_transform(matrix)
vis_dims.shape
(1000, 2)
こんな感じで2次元のデータに圧縮される。
vis_dims
array([[ 11.486078 , 1.7048343],
[-10.225536 , -46.22204 ],
[ -8.66521 , 57.867092 ],
...,
[ 54.72112 , 17.520449 ],
[-29.86138 , -28.533998 ],
[-19.610193 , -39.09596 ]], dtype=float32)
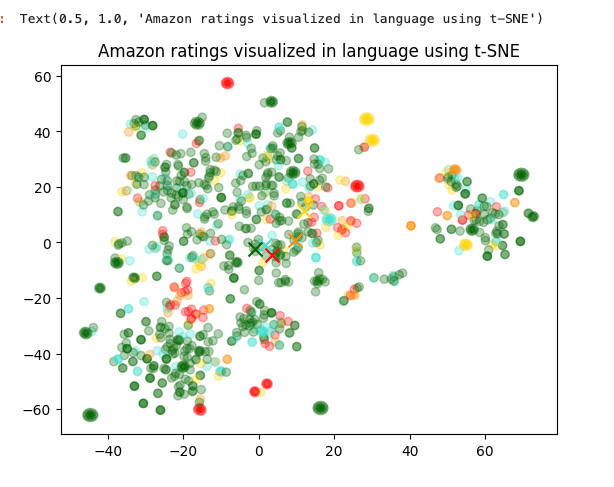
これをmatplotlibで2次元に可視化する
!pip install matplotlib
Scoreが色分けされる(赤が低くて、緑が高い)のと、各Scoreごとの平均は"X"で表示される様子。
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
colors = ["red", "darkorange", "gold", "turquoise", "darkgreen"]
x = [x for x,y in vis_dims]
y = [y for x,y in vis_dims]
color_indices = df.Score.values - 1
colormap = matplotlib.colors.ListedColormap(colors)
plt.scatter(x, y, c=color_indices, cmap=colormap, alpha=0.3)
for score in [0,1,2,3,4]:
avg_x = np.array(x)[df.Score-1==score].mean()
avg_y = np.array(y)[df.Score-1==score].mean()
color = colors[score]
plt.scatter(avg_x, avg_y, marker='x', color=color, s=100)
plt.title("Amazon ratings visualized in language using t-SNE")
Plotlyだとこんな感じ。
!pip install plotly
import plotly.graph_objects as go
import plotly.io as pio
pio.renderers.default = 'iframe'
scatter = go.Scatter(
x=x,
y=y,
mode='markers',
marker=dict(
color=[colors[i] for i in color_indices],
opacity=0.3
)
)
for score in range(5):
avg_x = np.array(x)[df.Score - 1 == score].mean()
avg_y = np.array(y)[df.Score - 1 == score].mean()
color = colors[score]
scatter_avg = go.Scatter(
x=[avg_x],
y=[avg_y],
mode='markers',
marker=dict(
color=color,
symbol='x',
size=10
)
)
layout = go.Layout(
title='Amazon ratings visualized in language using t-SNE',
xaxis=dict(title='X'),
yaxis=dict(title='Y')
)
fig = go.Figure(data=[scatter], layout=layout)
fig.show()
せっかくPlotly使ったけど、2次元に圧縮されたベクトルデータだけから作っているので、元のデータフレームの情報が活かせない。つまりインタラクティブにした意味がない。。。
ということでもう一度。ChatGPTに書いてもらった。
import pandas as pd
import numpy as np
from ast import literal_eval
from sklearn.manifold import TSNE
import plotly.graph_objects as go
import plotly.io as pio
pio.renderers.default = 'iframe'
# データの読み込み
datafile_path = "openai-cookbook/examples/data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
# t-SNEでの次元削減
matrix = np.array(df.embedding.apply(literal_eval).to_list())
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims = tsne.fit_transform(matrix)
# vis_dimsの結果をdfに追加
df['x'] = vis_dims[:, 0]
df['y'] = vis_dims[:, 1]
colors = ["red", "darkorange", "gold", "turquoise", "darkgreen"]
color_indices = df.Score.values - 1
# ホバーテキストの作成
df['hover_text'] = df.apply(lambda row: f"ProductId: {row['ProductId']}<br>"
f"UserId: {row['UserId']}<br>"
f"Score: {row['Score']}<br>"
f"Summary: {row['Summary']}<br>"
f"Text: {row['Text'][:50]}...", axis=1)
# 散布図の作成
fig = go.Figure()
# ポイントの追加
fig.add_trace(go.Scatter(
x=df['x'],
y=df['y'],
mode='markers',
marker=dict(color=color_indices, colorscale=colors, opacity=0.3),
text=df['hover_text'], # ホバー時に表示するテキスト
hoverinfo='text', # ホバー時にテキストのみ表示
))
# 平均値の追加
for score in [0,1,2,3,4]:
avg_x = df[df.Score == score + 1]['x'].mean()
avg_y = df[df.Score == score + 1]['y'].mean()
color = colors[score]
fig.add_trace(go.Scatter(x=[avg_x], y=[avg_y], mode='markers', marker=dict(color=color, symbol='x', size=10)))
# タイトルの設定
fig.update_layout(title="Amazon ratings visualized in language using t-SNE")
# グラフの表示
fig.show()
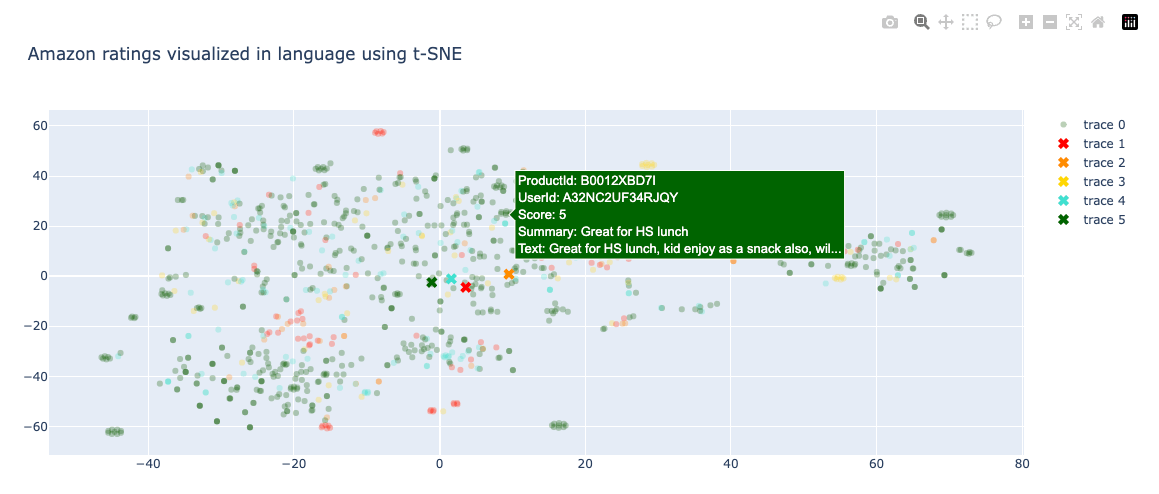
ホバーすると表示される。
Matplotlib/Plotlyを使った3D可視化
まず最初にこのノートブックでは、可視化でmatplotlib.widgetを使うので、ipymlのインストールが必要で、これはjupyterlabの起動前に行っておく必要がある様子。pandas、plotlyも後で必要になるので入れておく。
$ rye add ipyml
$ rye add pandas
$ rye add plotly
$ rye add scipy
$ rye add scikit-learn
$ rye sync
$ rye run jupyter-lab --ip='0.0.0.0' --NotebookApp.token=''
ではここから。
データセットは以下。DBPediaはWikipediaをLinked Data化したプロジェクト。ここからサンプリングしたデータセットになっている。
pandasデータフレームに読み込み。
import pandas as pd
samples = pd.read_json("openai-cookbook/examples/data/dbpedia_samples.jsonl", lines=True)
categories = sorted(samples["category"].unique())
print("Categories of DBpedia samples:", samples["category"].value_counts())
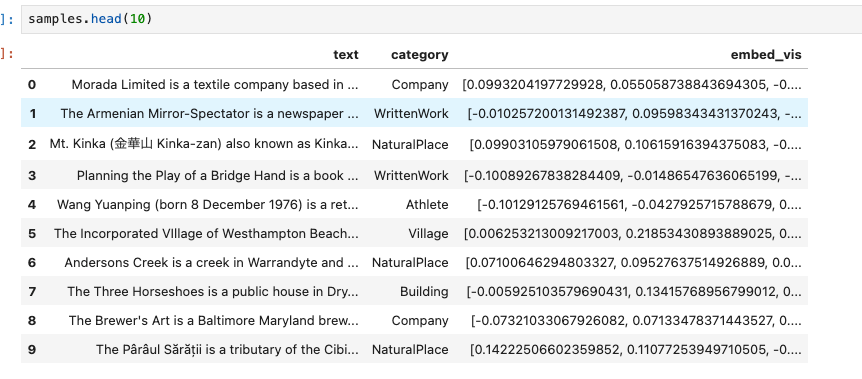
samples.head()
複数のカテゴリ付がされたテキストデータという感じ。

このデータにはembeddingsがないので、OpenAI Embeddings APIで取得する。
from openai.embeddings_utils import get_embeddings
openai_api_key = "sk-XXXXXXXXXXXXXXXXXXXXXXXX"
matrix = get_embeddings(samples["text"].to_list(), engine="text-embedding-ada-002", api_key=openai_api_key)
次元数を圧縮する。3Dなので1536->3次元。圧縮にはPCAを使う。
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
vis_dims = pca.fit_transform(matrix)
samples["embed_vis"] = vis_dims.tolist()
こんな感じで追加される。
では可視化。
%matplotlib widget
import matplotlib.pyplot as plt
import numpy as np
fig = plt.figure(figsize=(10, 5))
ax = fig.add_subplot(projection='3d')
cmap = plt.get_cmap("tab20")
for i, cat in enumerate(categories):
sub_matrix = np.array(samples[samples["category"] == cat]["embed_vis"].to_list())
x=sub_matrix[:, 0]
y=sub_matrix[:, 1]
z=sub_matrix[:, 2]
colors = [cmap(i/len(categories))] * len(sub_matrix)
ax.scatter(x, y, zs=z, zdir='z', c=colors, label=cat)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
ax.legend(bbox_to_anchor=(1.1, 1))
おお、グリグリ動く!けど、ただ各プロットの情報はわからないのだねぇ。
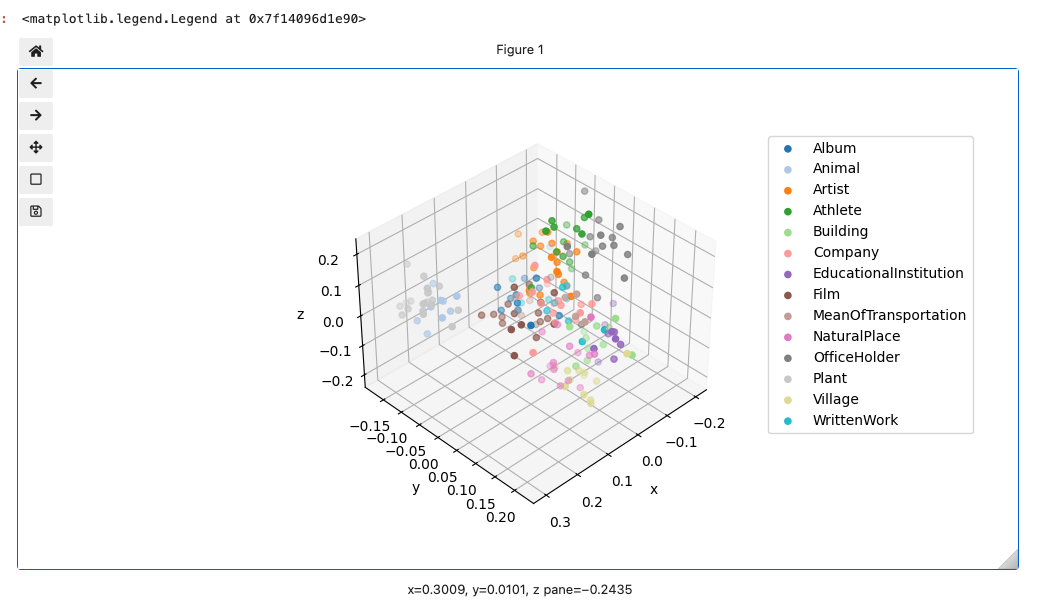
これもPlotlyに変えてみる。
import plotly.express as px
import plotly.io as pio
pio.renderers.default = 'iframe'
import textwrap
df = pd.DataFrame(vis_dims, columns=["x", "y", "z"])
df["category"] = samples["category"]
df["text"] = samples["text"].apply(lambda x: "<br>".join(textwrap.wrap(x, width=30)))
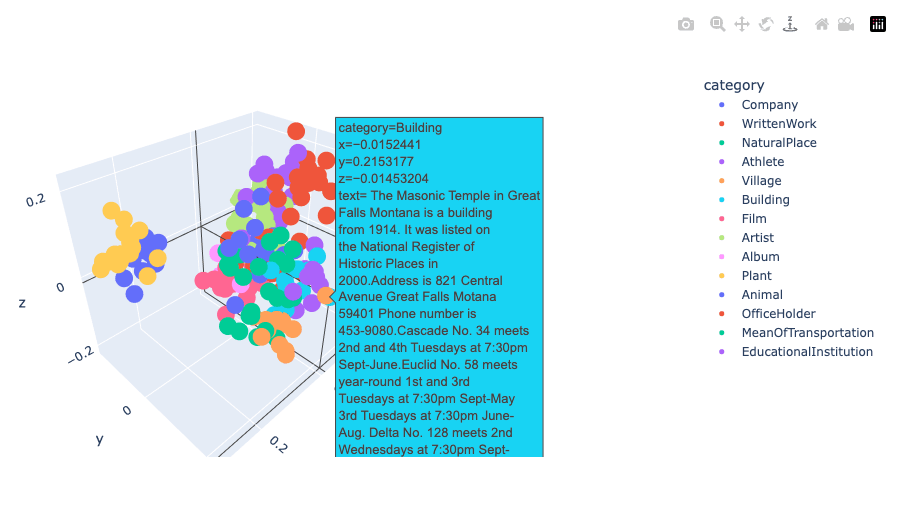
fig = px.scatter_3d(df, x="x", y="y", z="z", color="category", hover_data=["text"])
fig.update_traces(marker=dict(size=5))
fig.show()
W&Bを使った2D可視化
データセットは上の「Matplotlib/Plotlyを使った2D可視化」でも使ったAmazonの商品レビューのデータセットにembeddingsを追加したものを使ってやっていく。英語。
事前にW&Bのアカウントを作成しておくこと。
データセットを読み込んで、pandasのデータフレームを作成。embeddingsについては配列の配列にして持てておく。ここは「Matplotlib/Plotlyを使った2D可視化」と同じ。
import pandas as pd
from sklearn.manifold import TSNE
import numpy as np
from ast import literal_eval
datafile_path = "openai-cookbook/examples/data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
matrix = np.array(df.embedding.apply(literal_eval).to_list())
ではW&Bにデータを登録する。パッケージをインストール。
!pip install wandb
W&Bへのデータ登録。ざっくりこんな感じのことをしている様子
- W&Bにプロジェクトを作成
- embeddingsの次元数分の列を持ったwadb.tableオブジェクトを作成して、元のデータと分割されたembeddingsのデータを追加する。
- W&Bのプロジェクトに上記のデータを登録
import wandb
original_cols = df.columns[1:-1].tolist()
embedding_cols = ['emb_'+str(idx) for idx in range(len(matrix[0]))]
table_cols = original_cols + embedding_cols
with wandb.init(project='openai_embeddings'):
table = wandb.Table(columns=table_cols)
for i, row in enumerate(df.to_dict(orient="records")):
original_data = [row[col_name] for col_name in original_cols]
embedding_data = matrix[i].tolist()
table.add_data(*(original_data + embedding_data))
wandb.log({'openai_embedding_table': table})
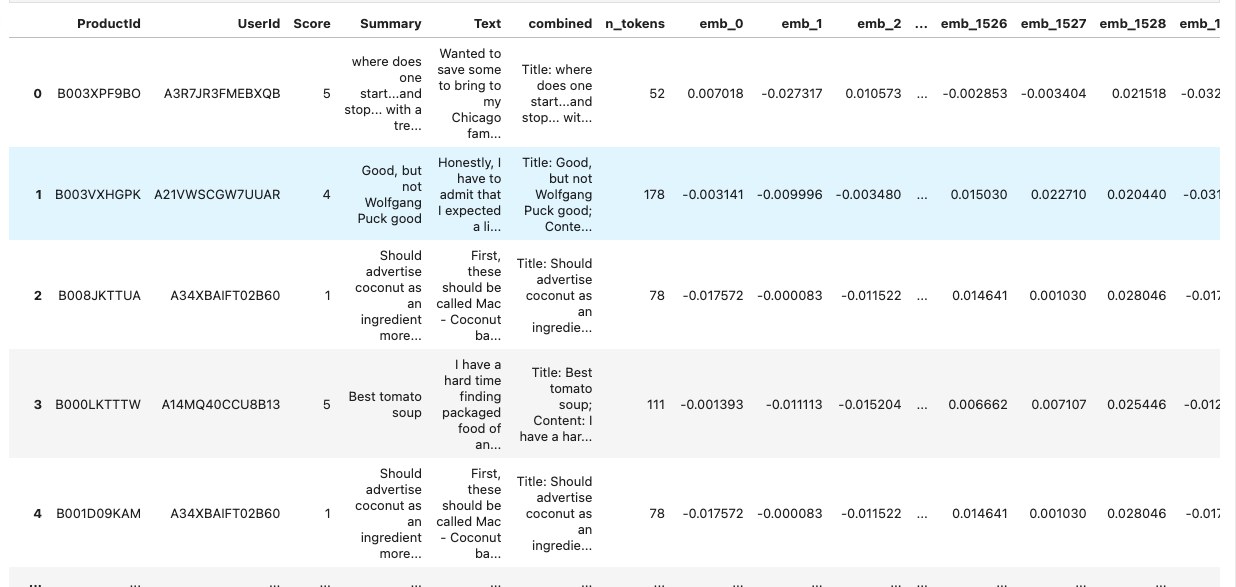
ちょっと余談だけども、wandb.tableオブジェクトはpandasのデータフレームと同じようなものらしい。
table.get_dataframe()
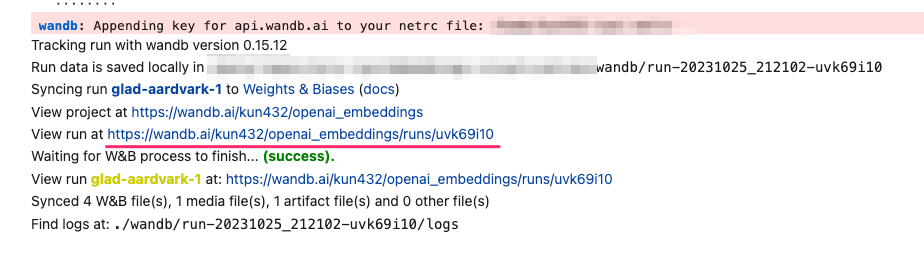
それは置いといて、上記を実行すると、コンソールにW&BのAPIキーの入力が求められる。

APIキーを入力すると上記のテーブルのデータがW&Bにアップロードされる。run at ...で始まるURLが可視化のURLになる。
URLにアクセス。多分最初はこんな感じの表になってるはず。
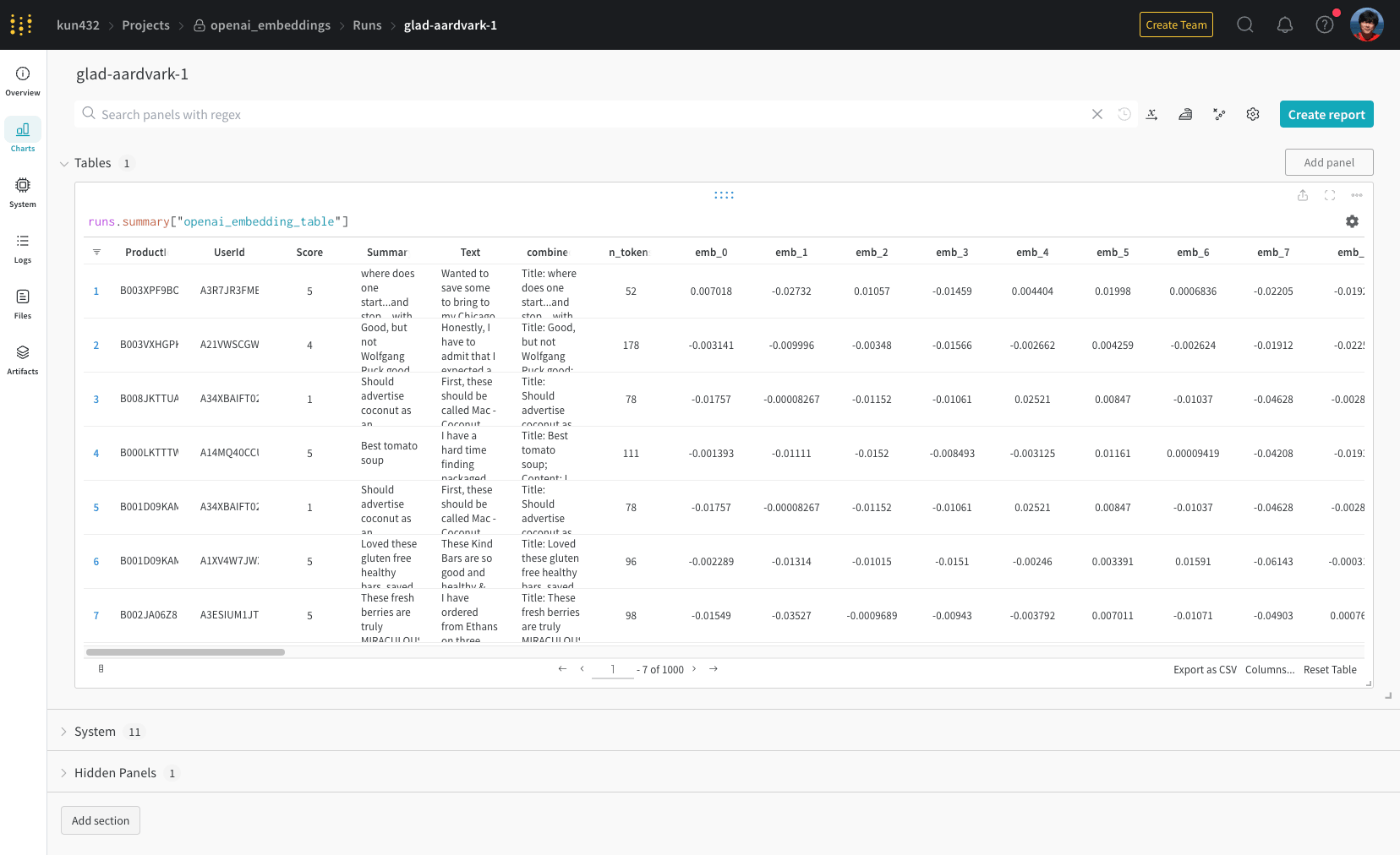
表の右上の歯車アイコン(Weave Panel Settings)をクリックして、Render asにCombined 2D Projectionを選択。
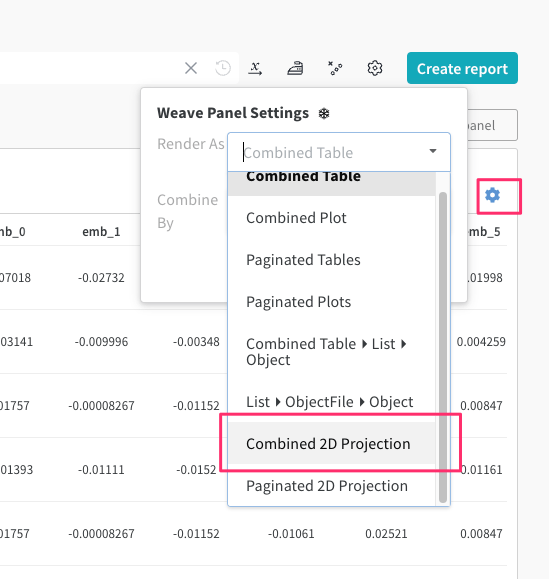
メニュー表示が変わるので以下を設定。
-
FieldsからScoreとn_tokensを削除 -
X Dim、Y Dimがそれぞれrow["projection.x"]、row["projection.y"]担っていることを確認 -
Colorにrow["source.Score"]あたりを指定、ここは目的次第 -
ToolTipにrow["source.ProductId"]あたりを指定、ここは目的次第
最後に"Apply"をクリックするとこうなる。
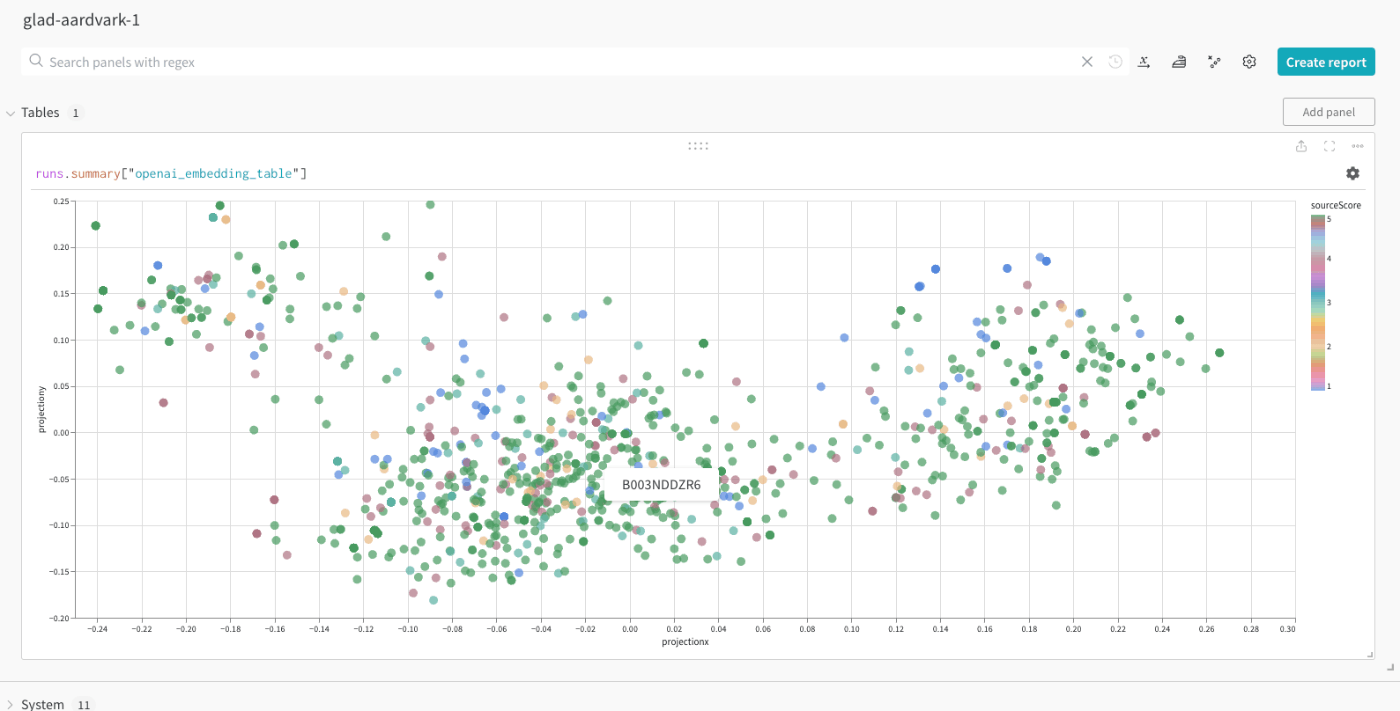
ちょっと細かいところの操作がわかってないけど、詳細はドキュメント参照。
Nomic Atlasを使った可視化
Nomic Alrasにログインして、組織名を設定、そしてアクセストークンを取得しておくこと。
アクセストークンはここから
なお、Nomic Atlasは無料でも使えるが、以下の制限がある。
- データポイントは25万、かつ、公開になる。非公開にしたい場合は、有償プランに変更する必要がある。
- 組織アカウントは自分のみ
今回はデモなので問題ないが、業務やデータの性質によっては注意が必要。
データセットは上でも使ったAmazonの商品レビューのデータセットにembeddingsを追加したものを使ってやっていく。英語。
nomicパッケージインストール
!pip install nomic
pandasデータフレームにデータセットを読み込み。embeddingsは別データにして、元のデータフレームからは消してる。
import pandas as pd
import numpy as np
from ast import literal_eval
datafile_path = "openai-cookbook/examples/data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
embeddings = np.array(df.embedding.apply(literal_eval).to_list())
df = df.drop('embedding', axis=1)
df = df.rename(columns={'Unnamed: 0': 'id'})
Nomicにログインして、データフレームのデータと先ほど分けておいたembeddigsを Nomic Atrasにアップロード。
import nomic
from nomic import atlas
nomic.login('XXXXXXXXXXXXXXXXXXXXXXXXX')
data = df.to_dict('records')
project = atlas.map_embeddings(embeddings=embeddings, data=data,
id_field='id',
colorable_fields=['Score'])
map = project.maps[0]
URLが発行されるのでアクセス。

こんな感じで表示される。
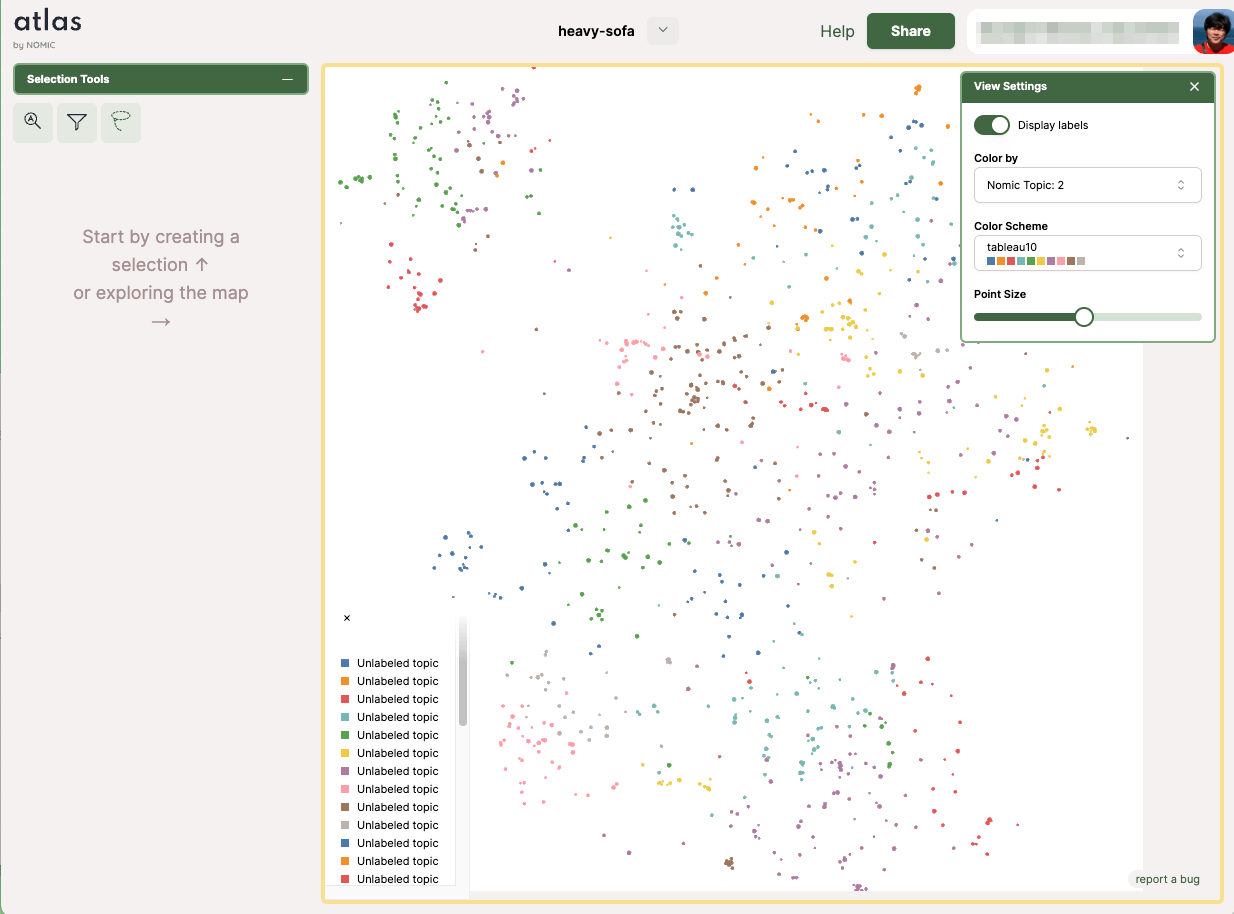
色の基準とカラースキーマ、ポイントの大きさを変えたり。

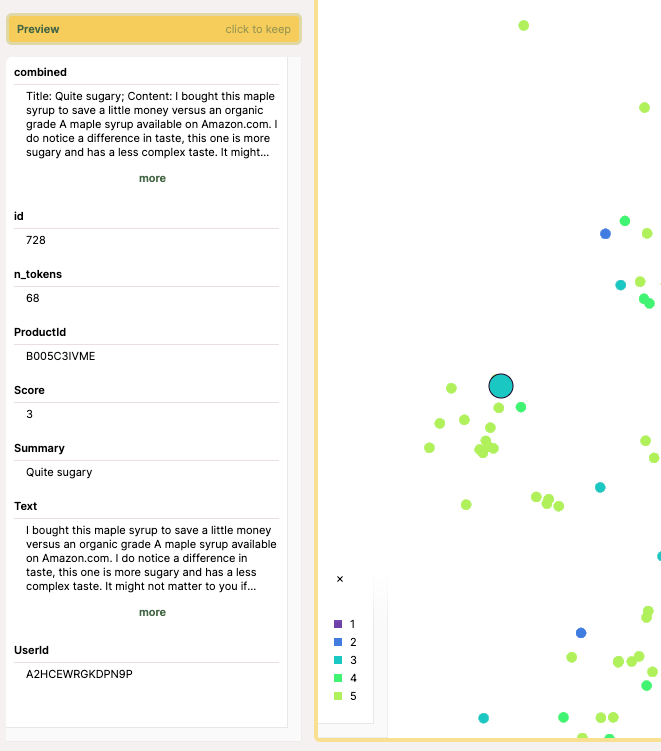
ポイントを選択して、情報を確認したり。
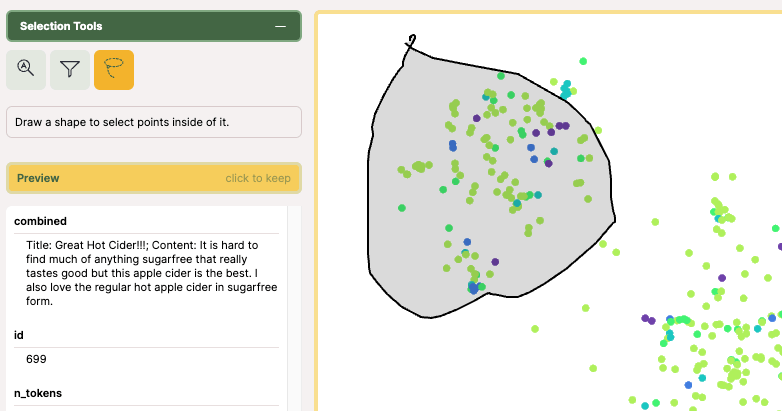
範囲選択して絞り込んだり。
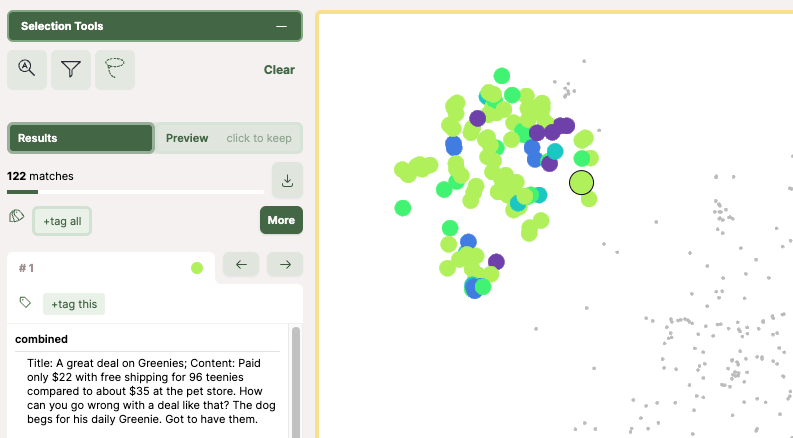
項目ごとにスライダーや文字列検索で絞り込んだり。
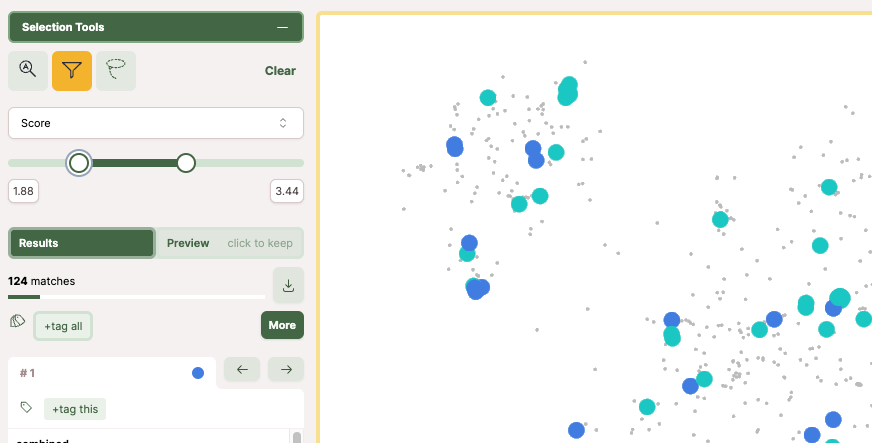
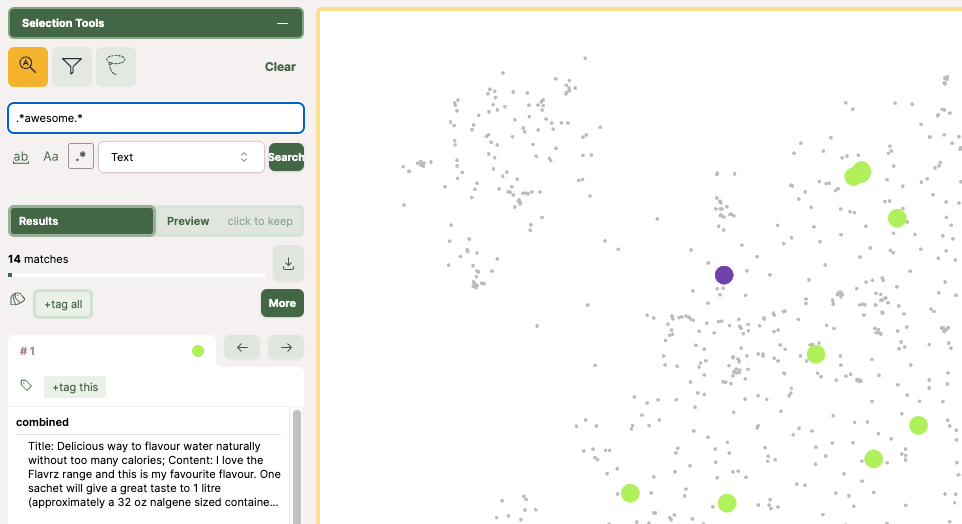
操作が直感的でとても使いやすい。
なお以下とすると、notebookの中で表示されるようなのだが、
map()
自分の環境だとこうなって表示できなかった。コンソールを見てみるとどうもhttpではダメっぽいように見える。ただ仮にこれが動いたとしても、nomicにアップロードせずにローカルで動く、というわけではない様子。

Nomic Atlasの体験が良すぎて、もうこれでいいんじゃね?になっている
が、もうちょっと続けてみる。
Kangasを使った2D可視化
Kangasはオープンソースのデータ探察ツール
Kangas is a tool for exploring, analyzing, and visualizing large-scale multimedia data. It provides a straightforward Python API for logging large tables of data, along with an intuitive visual interface for performing complex queries against your dataset.
データセットは引き続き、Amazonの商品レビューのデータセットにembeddingsを追加したものを使ってやっていく。英語。
kangasパッケージインストール
!pip install kangas
データセットを読み込み。なんかこの辺pandasっぽさがある。。。
import kangas as kg
data = kg.read_csv("openai-cookbook/examples/data/fine_food_reviews_with_embeddings_1k.csv")
読み込んだデータの情報を見てみる。何回か使ってるので中身はもう大体わかってるね。
data.info()
DataGrid (in memory)
Name : openai-cookbook/examples/data/fine_food_reviews_with_embeddings_1k
Rows : 1,000
Columns: 9
# Column Non-Null Count DataGrid Type
--- -------------------- --------------- --------------------
1 Column 1 1,000 INTEGER
2 ProductId 1,000 TEXT
3 UserId 1,000 TEXT
4 Score 1,000 INTEGER
5 Summary 1,000 TEXT
6 Text 1,000 TEXT
7 combined 1,000 TEXT
8 n_tokens 1,000 INTEGER
9 embedding 1,000 TEXT
データそのものを見てみる。
data
うん、これはpandasと同じ。
でデータフレームならぬデータグリッドを作成して、データを入れ込んでいく。
import ast
dg = kg.DataGrid(
name="openai_embeddings",
columns=data.get_columns(),
converters={"Score": str},
)
for row in data:
embedding = ast.literal_eval(row[8])
row[8] = kg.Embedding(
embedding,
name=str(row[3]),
text="%s - %.10s" % (row[3], row[4]),
projection="umap",
)
dg.append(row)
データグリッドの情報を見てみる。
dg.info()
データフレームを見たときとほぼ同じだけど、embeddingだけが違う。上のコードにもあるけどkangasにはEmbeddingを扱うためのオブジェクトがあるみたい。
DataGrid (in memory)
Name : openai_embeddings
Rows : 1,000
Columns: 9
# Column Non-Null Count DataGrid Type
--- -------------------- --------------- --------------------
1 Column 1 1,000 INTEGER
2 ProductId 1,000 TEXT
3 UserId 1,000 TEXT
4 Score 1,000 TEXT
5 Summary 1,000 TEXT
6 Text 1,000 TEXT
7 combined 1,000 TEXT
8 n_tokens 1,000 INTEGER
9 embedding 1,000 EMBEDDING-ASSET
データグリッドを保存する。
dg.save()
というところでどうやらモジュールが足りない模様。
ModuleNotFoundError: No module named 'umap'
UMAPというのはこれのことらしい。
ということでインストール。
!pip install umap-learn
再度実行。
dg.save()
datagrid形式のファイルとして保存されるらしい。
Saving settings to 'openai_embeddings.datagrid'...
では可視化する
dg.show()
が、表示されない。暫く待つとこうなる。

kangasはサーバを起動するようだが、どうも127.0.0.1にbindされてしまっているらしい。多分これローカルなら問題ないのだけど、うちの場合はリモートのjupyter labサーバなので、こういうことになっているっぽい(そういや別のやつでもあったな・・・うちの環境起因かも)
ドキュメントを見てみたところ、以下のような指定もできるみたい。
dg.show(host="192.168.XXX.XXX",port=4000)
ということで立ち上がった。
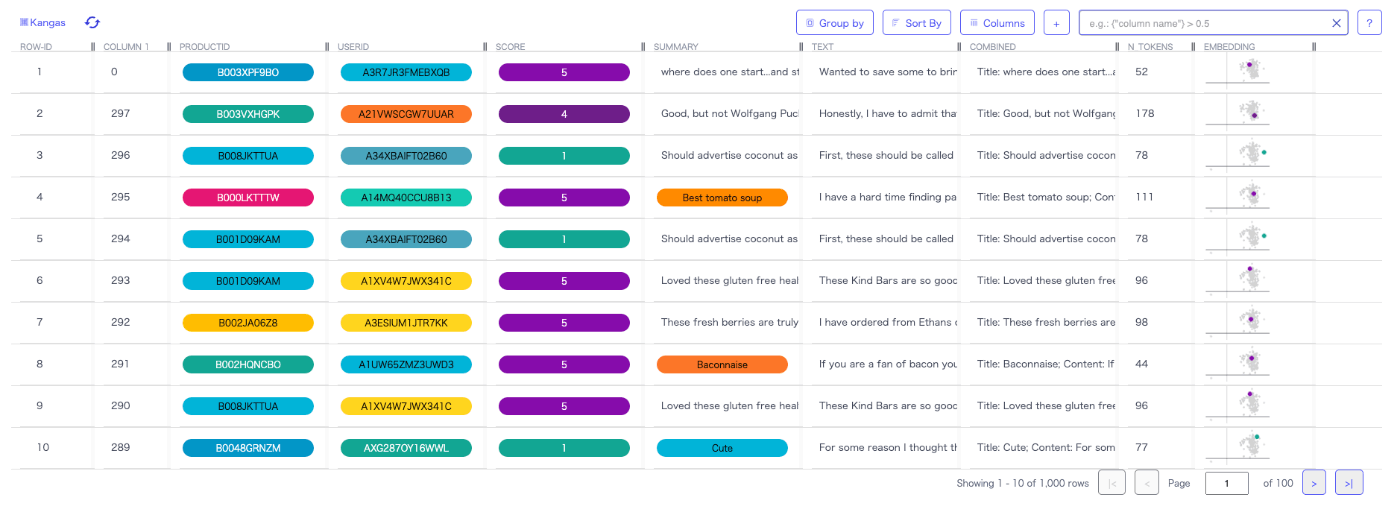
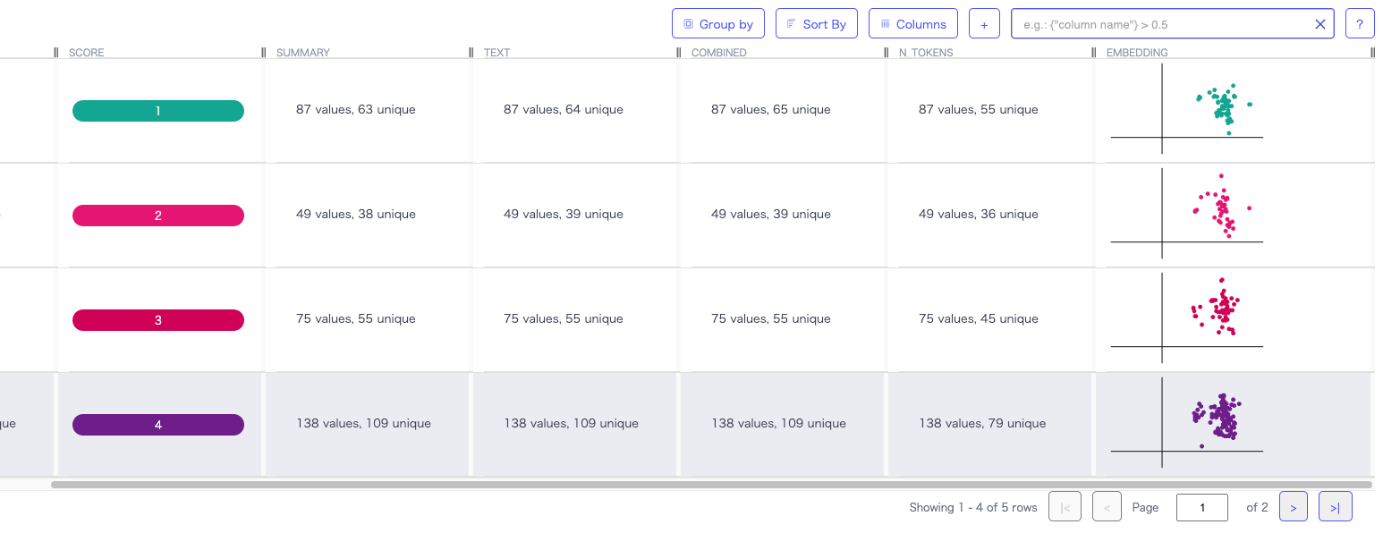
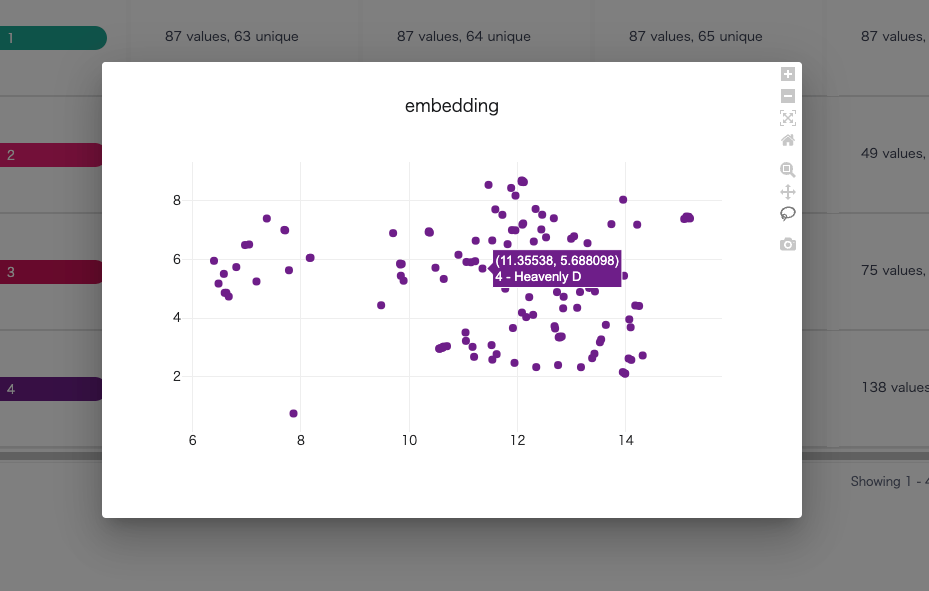
右のEmbeddingをクリックするとこんな感じで表示される。一応プロットにホバーすると多少は情報が出る。
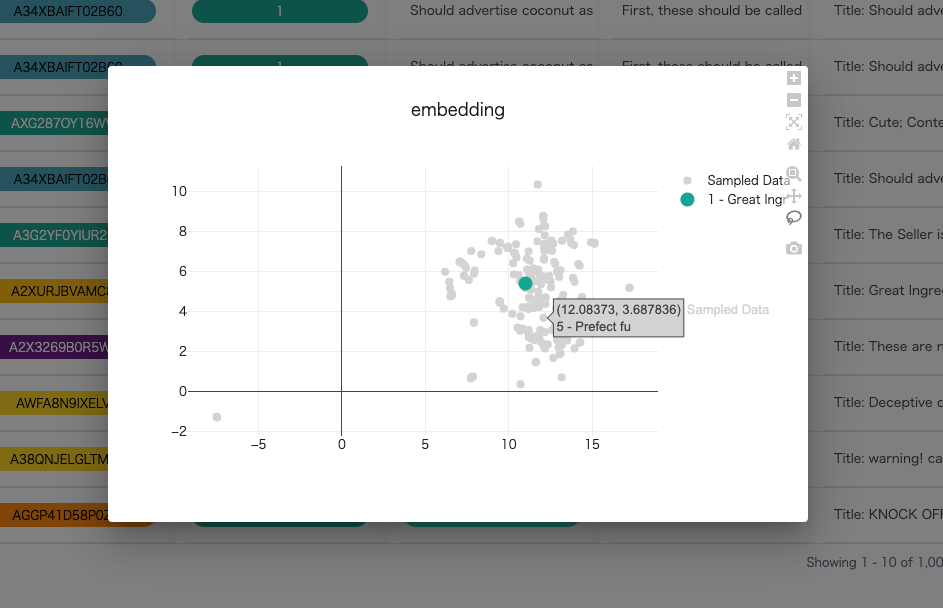
"Group by"でグルーピングすると良いかもしれない。以下はScoreでグルーピングした場合。
こんな感じでテキストでフィルタして、スコアでグルーピングしてみた。
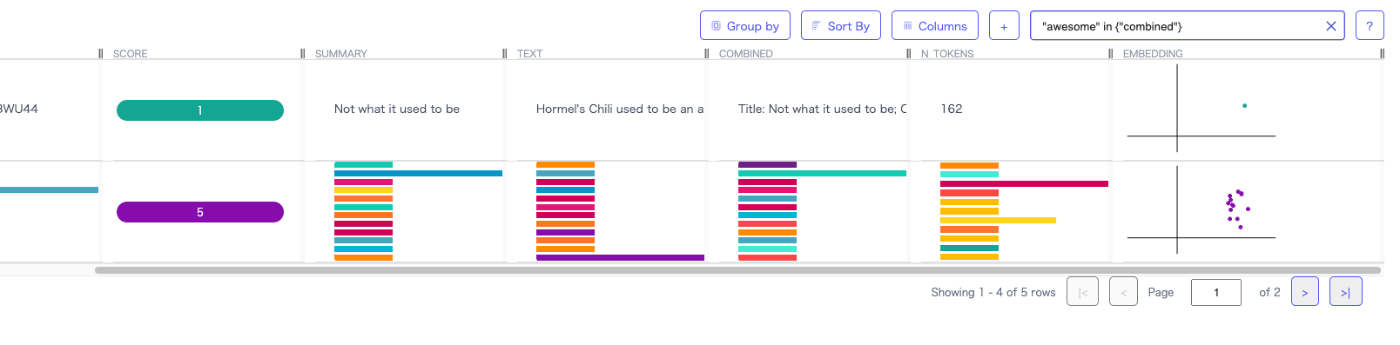
すると他の列はこんな感じにで集計されるっぽい。
ちょっとクセがある感じ。
TensorBoard Projectorによる可視化
公式のnotebookがあるのだけど、
以下にある通り、ちょっとつらい。
With that being said, it comes with minimal documentation. Google has put out an example notebook yet it is tightly coupled with TensorFlow and Keras. It is not obvious how the integration works if you already have your embeddings computed and just want to load those into the tool. To make matters even more amusing or frustrating depending on your state of mind, you can easily upload embeddings as a tsv file into the web-based version of the tool yet this option doesn’t exist if you want to integrate the Projector with the rest of your code using the TensorBoard module.
ということで、上記のサイトやnpaka大先生の記事を参考にやってみる。
データセットは引き続き、Amazonの商品レビューのデータセットにembeddingsを追加したものを使ってやっていく。英語。
ポイントは、
- メタデータ(ラベル)用TSVを作成
- embeddingsを
tf.modelのチェックポイントとして作成
することみたい。
tensorflowのインストール
!!pip install tensorflow
データセットをpandasデータフレームに読み取り。
import pandas as pd
import numpy as np
from ast import literal_eval
datafile_path = "openai-cookbook/examples/data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
embeddings_vector = np.array(df.embedding.apply(literal_eval).to_list())
df = df.drop('embedding', axis=1)
df = df.rename(columns={'Unnamed: 0': 'id'})
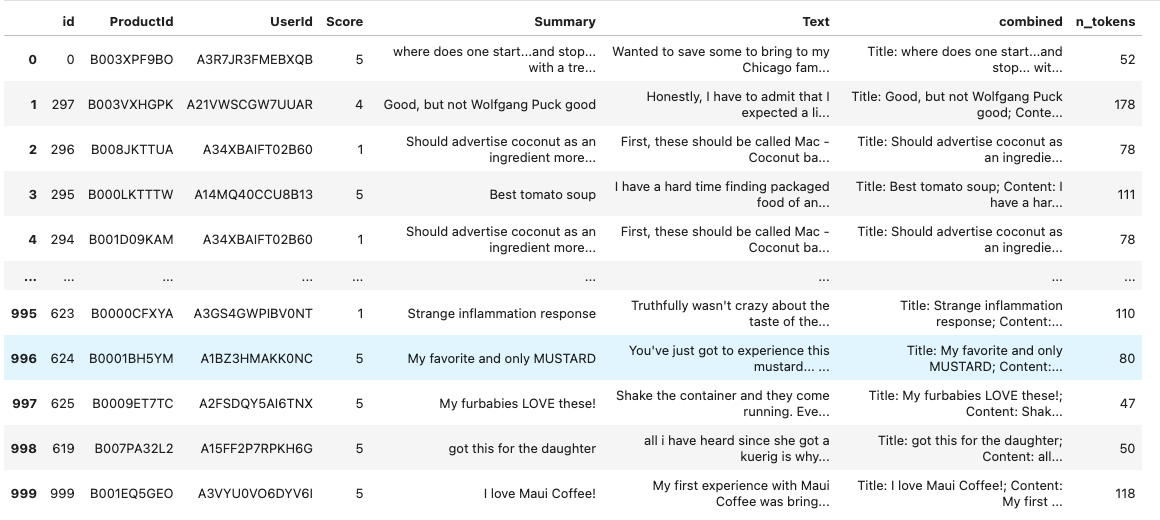
メタデータとembeddingsそれぞれが用意できた。
df
embeddings_vector
array([[ 7.01807206e-03, -2.73165479e-02, 1.05734831e-02, ...,
-7.01120170e-03, -2.18614824e-02, -3.75671238e-02],
[-3.14055197e-03, -9.99566447e-03, -3.48033849e-03, ...,
-9.74494778e-03, -2.39829952e-03, -9.20392852e-03],
[-1.75724812e-02, -8.26651158e-05, -1.15222773e-02, ...,
-1.39020244e-02, -3.90170924e-02, -2.35151257e-02],
...,
[-9.74910241e-03, -6.87123602e-03, -5.70622832e-03, ...,
-3.00459806e-02, -8.14515445e-03, -1.95114054e-02],
[-5.21062920e-03, 9.60669015e-04, 2.82862745e-02, ...,
-5.38039953e-03, -1.33138765e-02, -2.71892995e-02],
[-6.05782261e-03, -1.50158405e-02, -2.07575737e-03, ...,
-2.90671214e-02, -1.41164539e-02, -2.28756946e-02]])
tensorboardをインポート
import os
from tensorboard.plugins import projector
import tensorflow as tf
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
tensorboardが読み込むデータをおいておくディレクトリを作成する
log_dir='./logs/emb/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
データフレームをTSVにしてメタデータ用ファイルを作成する
id ProductId UserId Score Summary Text combined n_tokens
0 B003XPF9BO A3R7JR3FMEBXQB 5 where does one start...and stop... with a treat like this Wanted to save some to bring to my Chicago family but my North Carolina family ate all 4 boxes before I could pack. These are excellent...could serve to anyone Title: where does one start...and stop... with a treat like this; Content: Wanted to save some to bring to my Chicago family but my North Carolina family ate all 4 boxes before I could pack. These are excellent...could serve to anyone 52
embeddingsをチェックポイントファイル化する
emb = tf.Variable(embeddings, name='context_embeddings')
checkpoint = tf.train.Checkpoint(embedding=emb)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
Projectorの設定らしいのだけど、上記サイトにもあまり詳しいことは書いてない(謎って書いてあるw)。とりあえずそのまま進める。
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
Tensorboardの起動。うちの場合はリモートのjupyter lab上で動かしているので、--hostオプションをつけている(デフォルトだと127.0.0.1:6006で起動する)
%tensorboard --host 0.0.0.0 --logdir ./logs/emb/
画面が表示されたら、ドロップダウンから"PROJECTOR"を選択する。
表示されたー
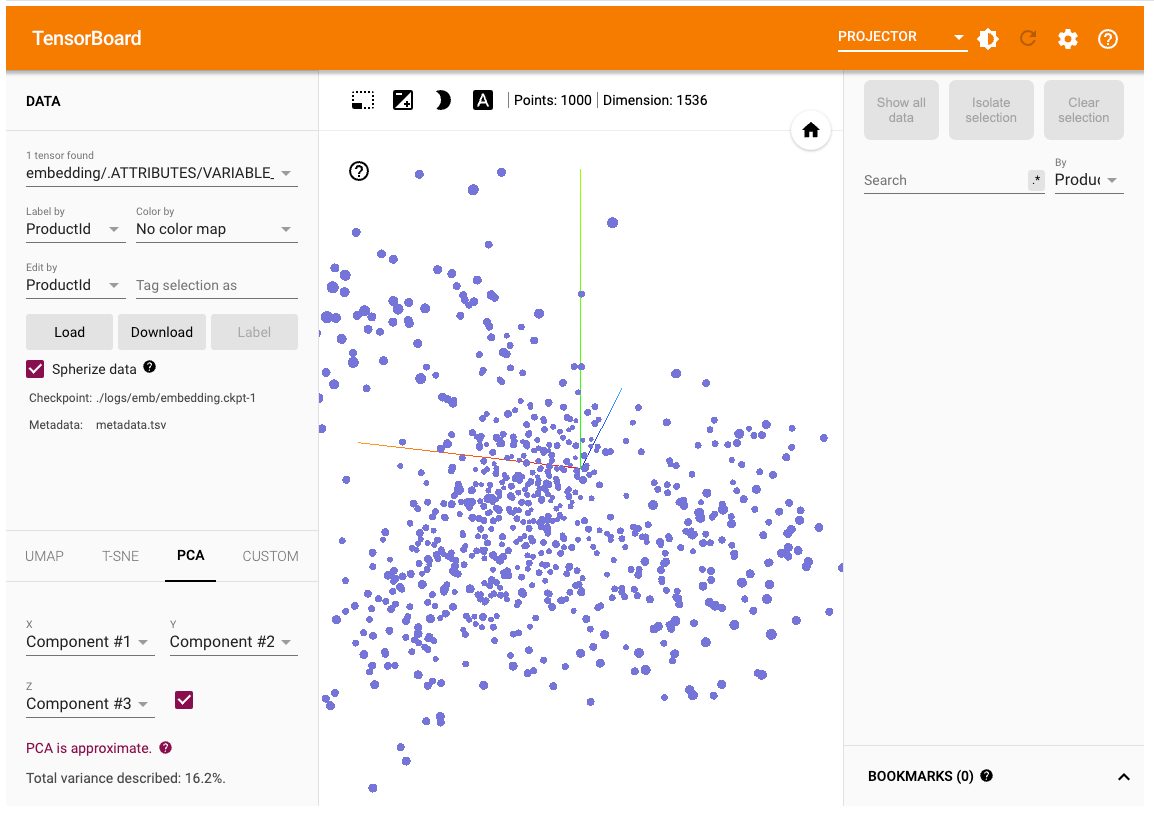
使い方は割愛。Nomic Atlasと同じような印象で使えた。Jupyuterのセル内で動かすよりもブラウザで直接開くほうが使いやすそう(http://X.X.X.X:6006/でアクセス)
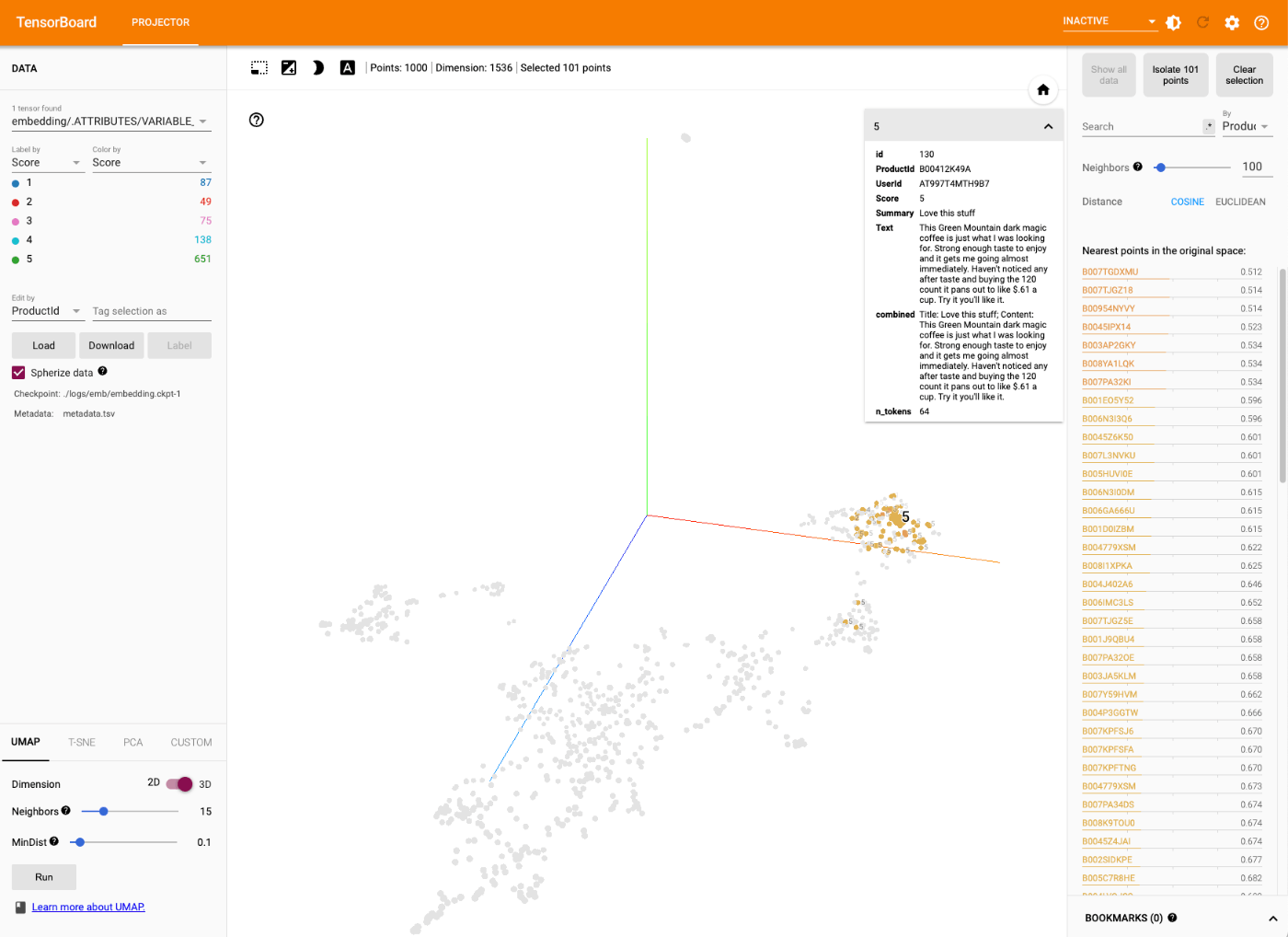
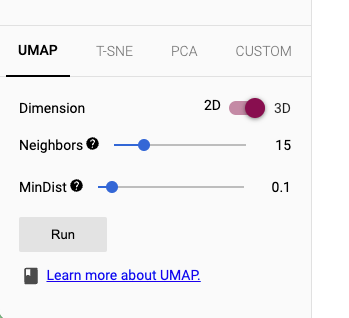
ちなみにここまでに触ってきた他のツールだと、Embeddingsの次元数の圧縮方式は1つだけだったけども、Tensorboard Projectorの場合はUI上でオンザフライで変更できる(ただ今の自分にはまだ使い分けできる気がしてないけども)
VRAMは結構食うのね・・・
Thu Oct 26 12:25:04 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 On | 00000000:01:00.0 Off | Off |
| 0% 51C P8 11W / 450W| 22683MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1127 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1350 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 3442123 C ...ings-visualization/.venv/bin/python 22658MiB |
+---------------------------------------------------------------------------------------+
個人的にはRAGで使いたくて調べてみたのだけど、RAGのクエリ・コンテキストみたいなデータの入れ方はちょっと工夫する必要があるかなぁ。
あとはいろいろ試行錯誤しながらやりたい感もあるので、結局はJupyter/Colaboratoryとかでコード書いてPlotlyで可視化しちゃいそうな気もしているw
ちょっとこれは気になってる
以下でやってみる(予定)