LLMのトレーシング・評価ツール「Arize Phoenix」を試してみる
以下の記事で紹介されていた。
Phoenix provides MLOps and LLMOps insights at lightning speed with zero-config observability. Phoenix provides a notebook-first experience for monitoring your models and LLM Applications by providing:
- LLM Traces - Trace through the execution of your LLM Application to understand the internals of your LLM Application and to troubleshoot problems related to things like retrieval and tool execution.
- LLM Evals - Leverage the power of large language models to evaluate your generative model or application's relevance, toxicity, and more.
- Embedding Analysis - Explore embedding point-clouds and identify clusters of high drift and performance degradation.
- RAG Analysis - Visualize your generative application's search and retrieval process to solve improve your retrieval-augmented generation.
- Structured Data Analysis - Statistically analyze your structured data by performing A/B analysis, temporal drift analysis, and more.
環境
pyenv+pyenv-virtualenvで。python-3.10.13。
$ pyenv virtualenv 3.10.13 phoenix
$ mkdir phoenix && cd phoenix
$ pyenv local phoenix
$ pip install jupyterlab ipywidgets
$ jupyter-lab --ip='0.0.0.0' --NotebookApp.token=''
以後はjupyter labで。
前提
試すのは以下
Embedding AnalysisRAG Analysis
LLM RelavanceとTraceは余裕があればやるかもしれない。
あと、可能な限り、日本語データセットを使って試してみたいと思う。
もはやかなり時間が経ってしまったので、リセットして改めてやり直す。
以前少しだけ触ってみたArize Phoenixだが、当時はEmbeddingsを可視化したいというのが頭にあった。
あれから
- notebookでLlamaIndexを使う場合に、トレーシングでとても手軽に使えるので重宝している
- LlamaIndexとArize Phoenixが公式にトレーシングサービスを開始した
ということもあって、改めてArize Phoenixを一通り触ってみようと思う。
参考)
とりあえずざっとドキュメントを見た感じ、大きく分けると
- セットアップ
- トレーシング
- 評価
- データセット
- 検索
- 推論(+可視化)
って感じに見えるので、それぞれのQuickStartをやってみる感じで。
セットアップ
セットアップの方法は以下の通り。
- ホスティングサービスを使う
- セルフホスト
- notebook
- CLI
- Docker
という感じに見える。今回はDockerでのセルフホストを試すことにする。LAN内のUbuntu 22.04サーバにセットアップしていく。
一応作業ディレクトリ作成
$ mkdir phoenix-demo && cd phoenix-demo
Dockerコンテナを起動
$ docker run -p 6006:6006 arizephoenix/phoenix:latest
---------------------------
✅ Migrations complete.
██████╗ ██╗ ██╗ ██████╗ ███████╗███╗ ██╗██╗██╗ ██╗
██╔══██╗██║ ██║██╔═══██╗██╔════╝████╗ ██║██║╚██╗██╔╝
██████╔╝███████║██║ ██║█████╗ ██╔██╗ ██║██║ ╚███╔╝
██╔═══╝ ██╔══██║██║ ██║██╔══╝ ██║╚██╗██║██║ ██╔██╗
██║ ██║ ██║╚██████╔╝███████╗██║ ╚████║██║██╔╝ ██╗
╚═╝ ╚═╝ ╚═╝ ╚═════╝ ╚══════╝╚═╝ ╚═══╝╚═╝╚═╝ ╚═╝ v4.14.1
|
| 🌎 Join our Community 🌎
| https://join.slack.com/t/arize-ai/shared_invite/zt-1px8dcmlf-fmThhDFD_V_48oU7ALan4Q
|
| ⭐️ Leave us a Star ⭐️
| https://github.com/Arize-ai/phoenix
|
| 📚 Documentation 📚
| https://docs.arize.com/phoenix
|
| 🚀 Phoenix Server 🚀
| Phoenix UI: http:/0.0.0.0:6006
| Log traces:
| - gRPC: http://0.0.0.0:4317
| - HTTP: http:/0.0.0.0:6006/v1/traces
| Storage: sqlite:////root/.phoenix/phoenix.db
INFO: Started server process [1]
INFO: Waiting for application startup.
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1721881468.895446 1 config.cc:230] gRPC experiments enabled: call_status_override_on_cancellation, event_engine_dns, event_engine_listener, http2_stats_fix, monitoring_experiment, pick_first_new, trace_record_callops, work_serializer_clears_time_cache
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:6006 (Press CTRL+C to quit)
ブラウザで6006ポートにアクセスすると以下のような画面が表示される。ここでトレースの確認ができる。

なお、コンテナ起動時のログにも出力されるが、内部的にはデータベースで管理しているようで、Dockerコンテナで起動した場合、コンテナを落とすとトレースデータは消える。商用で使う場合にはGitHubレポジトリにあるようにdocker-compose.yamlを参考にデータベースのコンテナを分けて永続化するか、
以下のDeploymentあたりを読むと良さそう。
トレーシング
ではまずトレーシングをやってみる。以下のようなイメージで。
- ローカルのMac上にpython仮想環境+Jupyter notebook環境を用意して、コードはここで実行。
- OpenAI APIキーを記載した.envファイルも用意しておくこと。
- ローカルのMacからLAN内のPhoenixサーバにトレースを送信。
なお、QuickStartには、LlamaIndex、LangChain、OpenAI、AutoGenのサンプルコードが用意されている。普段はLlamaIndexを使うことが多いので、今回は素のOpenAIパッケージを使ってコードを書いていく。
パッケージインストール
!pip install openai python-dotenv 'arize-phoenix[evals]'
OpenAI APIキーを読み込み
from dotenv import load_dotenv
load_dotenv(verbose=True)
Phoenixサーバのエンドポイントを環境変数に設定しておく。
import os
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "http://X.X.X.X:6006"
Phoenixでは、トレースを収集するモジュールをInstrumentorと呼ぶらしい。InstrumentorはOTLP (OpenTelemetry Protocol)を使用してトレースを収集し、Phoenixサーバに送信する。
Instrumentorは、opentelemetryパッケージを使用して実装すればよいが、LlamaIndex・LangChain・OpenAI・AutoGen用にはあらかじめモジュールが用意されているので、今回はこれを使う。
from openai import OpenAI
from phoenix.trace.openai import OpenAIInstrumentor
# OpenAI用のInstrumentor
OpenAIInstrumentor().instrument()
client = OpenAI()
conversation = [
{"role": "system", "content": "あなたは親切なアシスタントです。"},
{"role": "user", "content": "日本の総理大臣は誰?"}
]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=conversation,
)
assistant_reply = response.choices[0].message.content
print(assistant_reply)
私の知識が2023年10月までのものであるため、その時点での日本の総理大臣は岸田文雄(きしだ ふみお)氏です。なお、最新の情報を確認することをお勧めします。
Phoenixの管理画面にもトレースが送信されていることが確認できる。
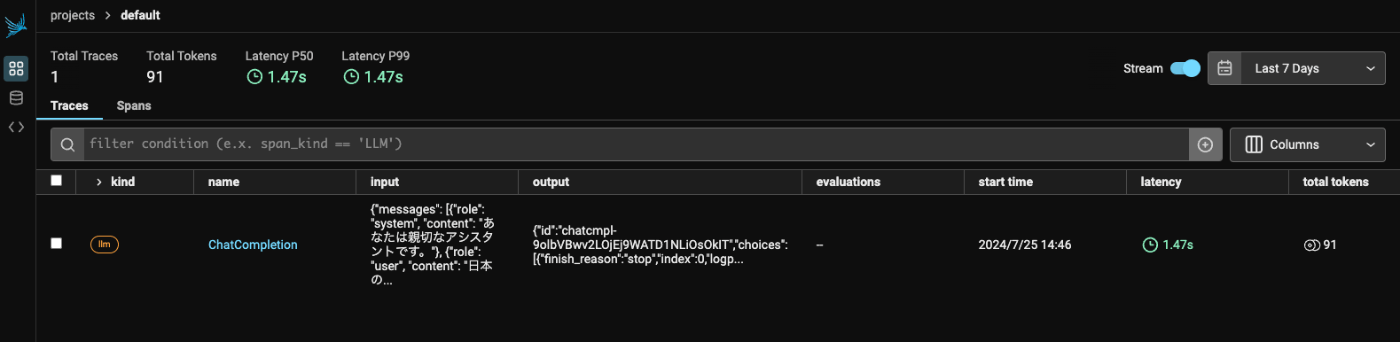
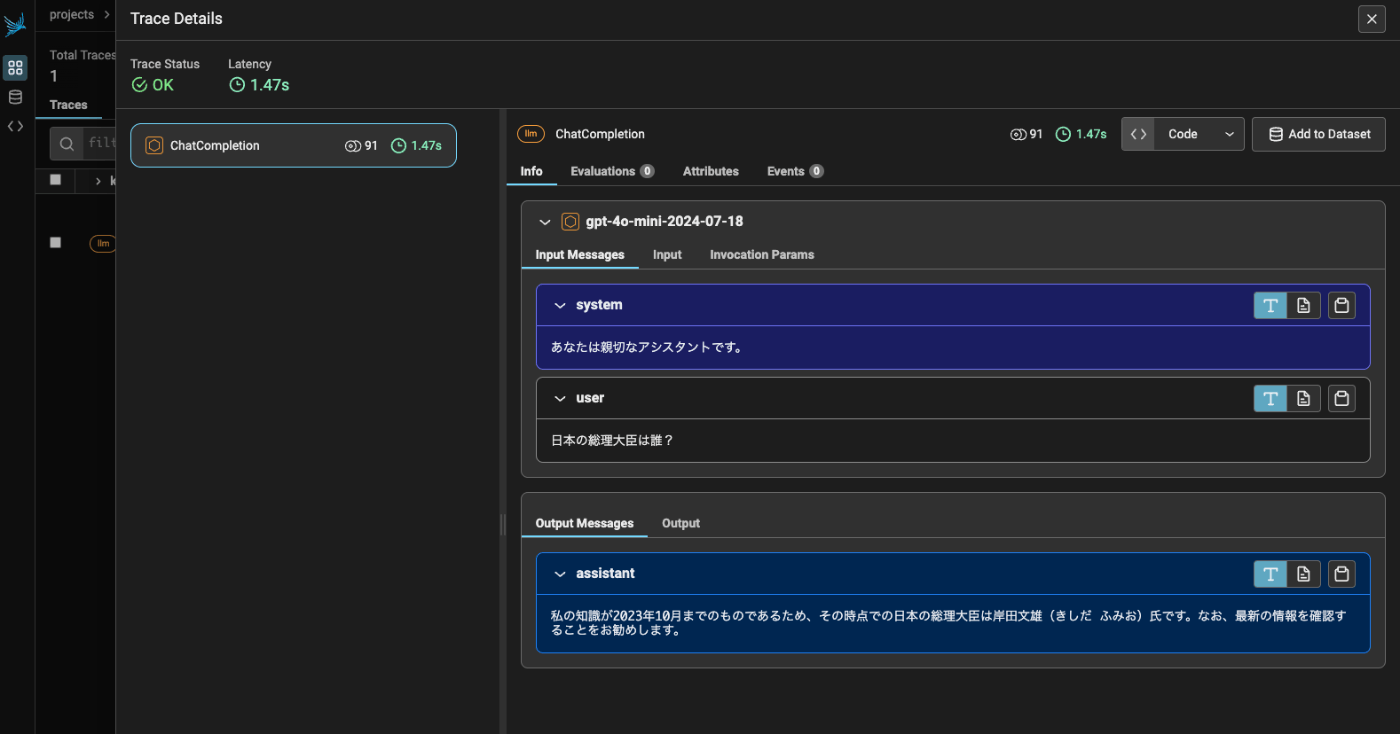
ついでにLlamaIndexでもやってみる。
LlamaIndexのOne-Click Integrationはllama-index-callbacks-arize-phoenixというインテグレーションパッケージをこれまで使ってて、LlamaTraceでも同じ。なのだけど、こちらのドキュメントではそれはLegacy扱いになっていて、必要なパッケージが違うみたい(とはいえ、llama-index-callbacks-arize-phoenixをインストールすると依存関係でほぼ似たような感じでインストールされるのだけど。)
!pip install llama-index openinference-instrumentation-llama-index opentelemetry-proto opentelemetry-exporter-otlp opentelemetry-sdk
!pip freeze | egrep -i "llama-|openinference|opentelemetry"
llama-cloud==0.0.11
llama-index==0.10.58
llama-index-agent-openai==0.2.9
llama-index-cli==0.1.13
llama-index-core==0.10.58
llama-index-embeddings-openai==0.1.11
llama-index-indices-managed-llama-cloud==0.2.6
llama-index-legacy==0.9.48
llama-index-llms-openai==0.1.27
llama-index-multi-modal-llms-openai==0.1.8
llama-index-program-openai==0.1.7
llama-index-question-gen-openai==0.1.3
llama-index-readers-file==0.1.30
llama-index-readers-llama-parse==0.1.6
llama-parse==0.4.9
openinference-instrumentation==0.1.8
openinference-instrumentation-llama-index==2.1.1
openinference-semantic-conventions==0.1.9
opentelemetry-api==1.26.0
opentelemetry-exporter-otlp==1.26.0
opentelemetry-exporter-otlp-proto-common==1.26.0
opentelemetry-exporter-otlp-proto-grpc==1.26.0
opentelemetry-exporter-otlp-proto-http==1.26.0
opentelemetry-instrumentation==0.47b0
opentelemetry-proto==1.26.0
opentelemetry-sdk==1.26.0
opentelemetry-semantic-conventions==0.47b0
インデックスからQuery Engineを作成していく。ドキュメントは以下を使う。
ドキュメントを取得
from pathlib import Path
import requests
# Wikipediaからのデータ読み込み
wiki_titles = ["イクイノックス", "ドウデュース"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = page["extract"]
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
ドキュメントからインデックス、Query Engineを作成。ここでInstrumentorを設定するのだけど、これまでのset_global_handlerを使ったOne-Click Integrationとはぜんぜん書き方が違うな・・・
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.llms.openai import OpenAI
from llama_index.core import Settings
from openinference.instrumentation.llama_index import LlamaIndexInstrumentor
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk import trace as trace_sdk
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
phoenix_endpoint = "http://X.X.X.X:6006/v1/traces"
tracer_provider = trace_sdk.TracerProvider()
tracer_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter(phoenix_endpoint)))
LlamaIndexInstrumentor().instrument(tracer_provider=tracer_provider)
Settings.llm = OpenAI(model="gpt-4o-mini")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")
Settings.node_parser = SentenceSplitter()
Settings.chunk_size = 400
Settings.chunk_overlap = 100
Settings.context_window = 4096
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents, show_progress=True)
query_engine = index.as_query_engine(similarity_top_k=5)
適当にクエリを投げてみる。
response = query_engine.query("ドウデュースの主な勝ち鞍は?")
print(response)
ドウデュースの主な勝ち鞍は、2021年の朝日杯フューチュリティステークス、2022年の東京優駿(日本ダービー)、2023年の有馬記念です。
他にも色々クエリを投げてみるとこんな感じでトレースが記録された。
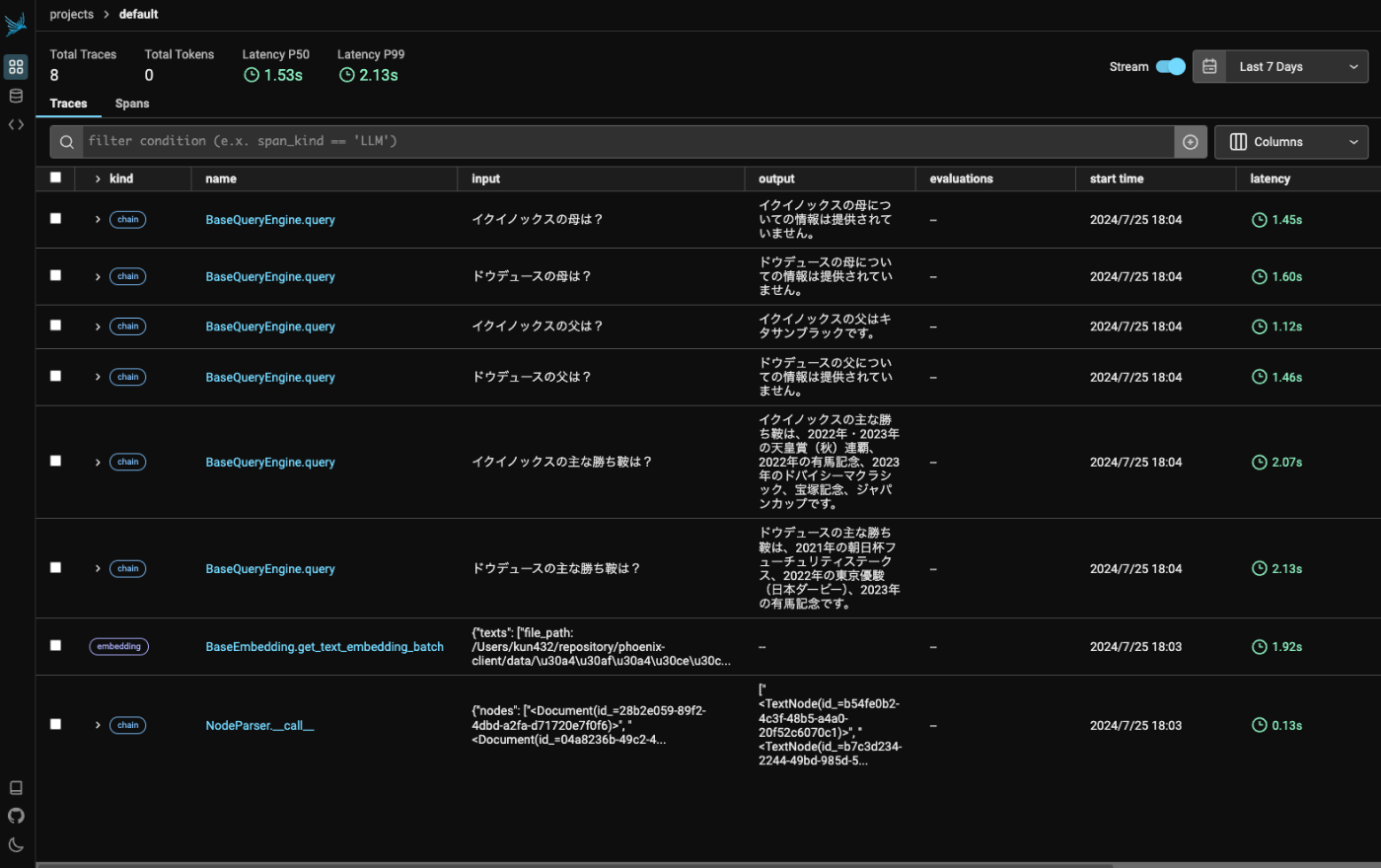

ちなみにトレースはインポート・エクスポートができる
エクスポート
import phoenix as px
import os
# トレースデータセットの出力先
directory = '/my_saved_traces'
os.makedirs(directory, exist_ok=True)
# トレースデータセットの保存
trace_id = px.Client().get_trace_dataset().save(directory=directory)
以下のように保存される
💾 Trace dataset saved to under ID: bf63b044-f45f-4b12-bb55-93f63ccf8433
📂 Trace dataset path: export_traces/trace_dataset-bf63b044-f45f-4b12-bb55-93f63ccf8433.parquet
ディレクトリを見てみるとどうやらparquet形式で保存されているらしい。
$ tree export_traces
export_traces
└── trace_dataset-bf63b044-f45f-4b12-bb55-93f63ccf8433.parquet
1 directory, 1 file
インポート
pandasのデータフレームであればトレースデータセットに変換できるようなので、インポートする場合はこんな感じで。
import pandas as pd
trace_df = pd.read_parquet("export_traces/trace_dataset-bf63b044-f45f-4b12-bb55-93f63ccf8433.parquet")
px.Client().log_traces(trace_dataset=px.TraceDataset(trace_df))
Phoenixサーバを一旦落としてトレースが全部消えた状態で上記を実行すると、先ほどのトレースが全部インポートされているのがわかる。
ドキュメントを見ていて気づいたのだけど、紹介されているサンプルコードは、notebook上でPhonixサーバを直接起動している場合について書かれているものが多い。
今回のようにリモートのPhoenixサーバとやり取りするようなケースについては、少し探しにくいかもしれない。
評価
ここはQuickStartだけではちょっと難しかった。色々試行錯誤したりコードみたりして、こんな感じのプロセスで処理されるのだろうというのを自分なりにまとめてみた。
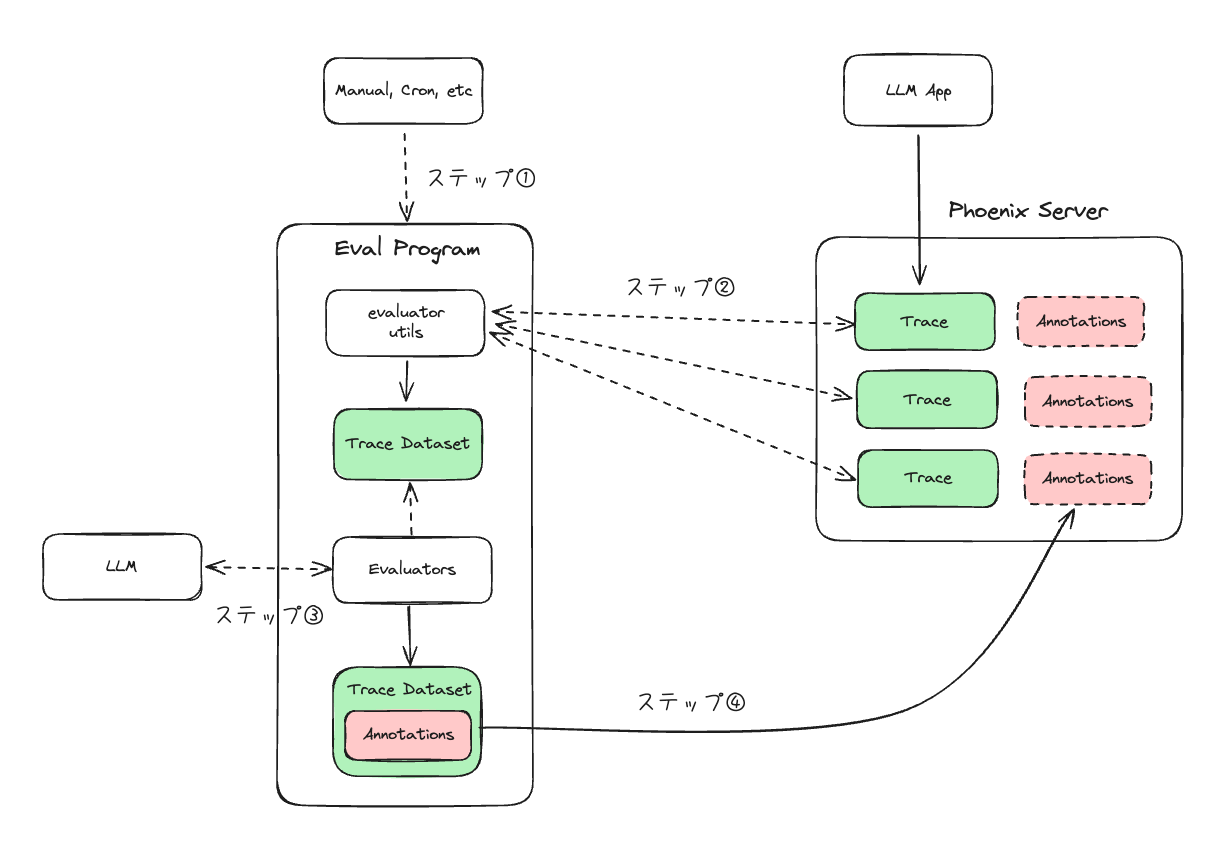
ざっくり流れをまとめるとこう。
- 手動なり自動(例えばCron等)で、評価プログラムを起動
- 評価プログラム内で、Phoenixの評価用ユーティリティを使って、Phoenixサーバからトレースデータを取得
- Phoenixの評価用モジュールを使ってトレースを評価。評価用モジュールはLLMを使って評価を行う。結果はアノテーションとしてトレースに付与される。
- 結果をPhoenixサーバに送信してアノテーションをトレースに付与する
ということで、実際にためしてみる。確認がしやすいようにPhoenixサーバは一旦再起動してトレースを全部消しておくと良い。
まずRAGを作る。RAGで使いやすいようにデータセットを用意した。
以下のデータセットがベースとなっている
最低限の評価に必要なのは「クエリ」「コンテキスト」のようなので、以下のデータから
- コンテキストがあるもの(
input) - QA形式になっているもの(
closed_qa)
でフィルタして、内容等もざっと確認、問題なさそうなものを300件サンプリングしたものとなっている。ただ細かいところまでチェックしてはいないのでRAGのQAとして望ましくないものも含まれているかもしれない。
これを使って、LlamaIndexでRAGを作っていく。データセットを取得。
!pip install datasets
from datasets import load_dataset
dataset = load_dataset("kun432/databricks-dolly-300-ja-for-rag", split="train")
df = dataset.to_pandas()
df

inputが「コンテキスト」、instructionが「クエリ」となる。outputがいわば「正解データ」なのだけど、今回は使わない(と思う)。
上記の「コンテキスト」をLlamaIndexのノードに変換してインデックスおよびQuery Engineを作成する。
from llama_index.core.schema import TextNode
nodes = []
for idx, row in df.iterrows():
id = row["index"]
text = row["input"]
node = TextNode(text=text, id_=id)
nodes.append(node)
from llama_index.core import VectorStoreIndex
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.llms.openai import OpenAI
from llama_index.core import Settings
from openinference.instrumentation.llama_index import LlamaIndexInstrumentor
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk import trace as trace_sdk
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
phoenix_endpoint = "http://X.X.X.X:6006/v1/traces"
tracer_provider = trace_sdk.TracerProvider()
tracer_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter(phoenix_endpoint)))
LlamaIndexInstrumentor().instrument(tracer_provider=tracer_provider)
Settings.llm = OpenAI(model="gpt-4o-mini")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")
Settings.chunk_size = 8192
Settings.chunk_overlap = 0
Settings.context_window = 4096
index = VectorStoreIndex(nodes, show_progress=True)
query_engine = index.as_query_engine(similarity_top_k=5)
ではトレースデータを貯めるために、データセットのクエリを順にQuery Engineに投げていく。
for idx, row in df.iterrows():
query = row["instruction"]
response = query_engine.query(query)
print(f"Q{idx + 1}: {query}")
print(f"A: {response}")
print("----")
Q1: ヴァージン・オーストラリア航空はいつから運航を開始したのですか?
A: ヴァージン・オーストラリア航空は2000年8月31日に運航を開始しました。
----
Q2: 小森田友明はいつ生まれたの?
A: 小森田友明は1981年7月10日に生まれました。
----
Q3: カイル・ヴァンジルがチーム61得点のうち36得点を挙げたとき、誰と対戦していたのですか?
A: カイル・ヴァンジルが36得点を挙げたのは、ボランドU21との対戦時です。
----
(snip)
----
Q298: ウィリアム・ギブスンの最初のコミックシリーズの名前は?
A: ウィリアム・ギブスンの最初のコミックシリーズの名前は「Archangel」です。
----
Q299: COVID-19のさまざまな名称と、最も推奨される名称はどれですか?
A: COVID-19のさまざまな名称には、「コロナウイルス」「武漢コロナウイルス」「武漢肺炎」などがあります。最も推奨される名称は「COVID-19」で、これは「コロナウイルス病2019」の略語です。
----
Q300: ブラックシーってどこ?
A: ブラックシーについての情報は提供されていません。質問の内容に関連する情報がないため、具体的な回答はできません。
こんな感じでトレースが貯まった。
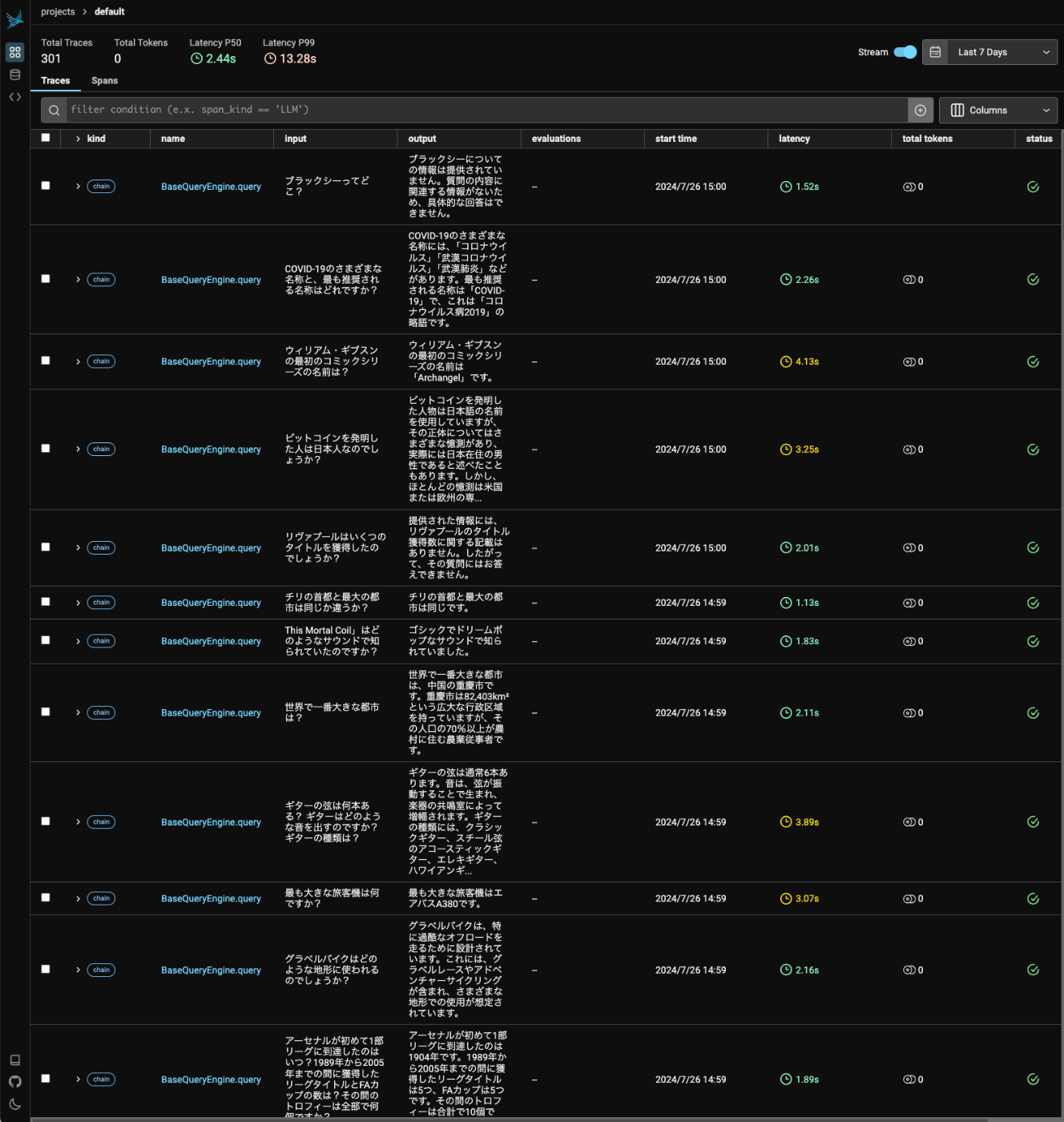
ではこのトレースを評価する。
Phoenixサーバ上に溜まったトレースを取得して、評価用データセットとしてPandasのデータフレームに変換してくれるユーティリティがあるので、これを使う。
from phoenix.session.evaluation import get_qa_with_reference, get_retrieved_documents
import phoenix as px
queries_df = get_qa_with_reference(px.Client())
retrieved_documents_df = get_retrieved_documents(px.Client())
get_qa_with_referenceはトレースの入力(クエリとコンテキスト)と出力(LLMの応答)からなるデータフレームを作成してくれる。
queries_df

get_retrieved_documentsはトレースの入力(クエリ)からretrievalで得られた結果(スコア含む)からなるデータフレームを作成してくれる。
retrieved_documents_df
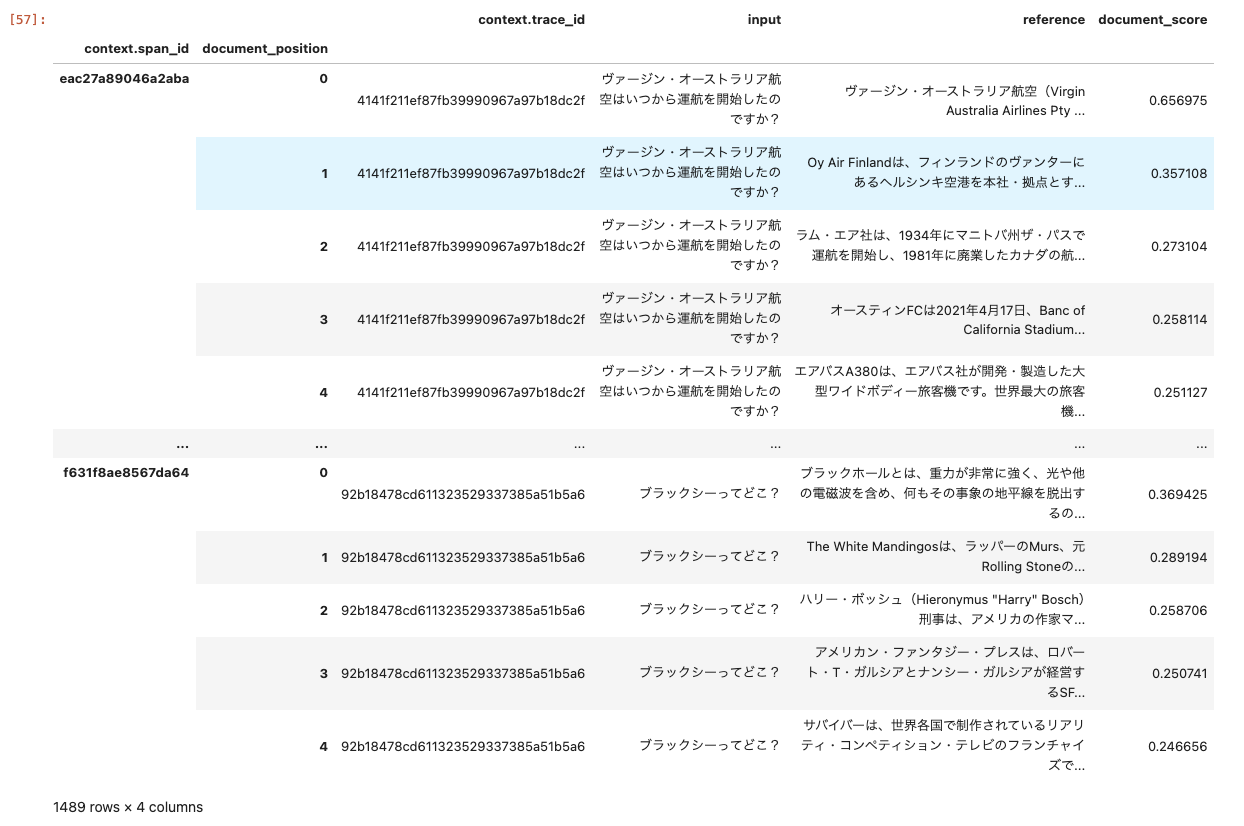
ではこれらを評価モジュールに渡して評価する。
from phoenix.evals import OpenAIModel, HallucinationEvaluator, QAEvaluator, RelevanceEvaluator
from phoenix.evals import run_evals
from phoenix.trace import SpanEvaluations, DocumentEvaluations
import nest_asyncio
# notebookなのでイベントループのネストを有効化
nest_asyncio.apply()
# 評価で使用するLLMの定義
eval_model = OpenAIModel(model="gpt-4o-mini")
# 評価モジュールの定義
hallucination_evaluator = HallucinationEvaluator(eval_model)
qa_evaluator = QAEvaluator(eval_model)
relevance_evaluator = RelevanceEvaluator(eval_model)
# 評価の実行
hallucination_eval_df, qa_eval_df = run_evals(
dataframe=queries_df,
evaluators=[hallucination_evaluator, qa_evaluator],
provide_explanation=True,
)
relevance_evals_df = run_evals(
dataframe=retrieved_documents_df,
evaluators=[relevance_evaluator],
provide_explanation=True,
)[0]
# 評価結果をPhoenixサーバに送信
px.Client().log_evaluations(
SpanEvaluations(eval_name="Hallucination", dataframe=hallucination_eval_df),
SpanEvaluations(eval_name="QA Correctness", dataframe=qa_eval_df),
DocumentEvaluations(eval_name="Relevance", dataframe=relevance_evals_df),
)
評価モジュールはいろいろあるようだが、今回は以下の3つにした。
-
HallucinationEvaluator- コンテキストデータに基づいてモデルの出力がハルシネーションかどうかを検出する。
- ある質問に対するAIの回答がハルシネーションであるかどうかを、その回答を生成するために使用された参照データに基づいて検出する。
-
QAEvaluator- 検索されたデータに基づいて、質問がシステムによって正しく回答されたかどうかを評価する。
- Q&Aシステムとして正しいのかをチェックする。検索の評価ではない。
-
RelevanceEvaluator- 検索されたチャンクがクエリに対する答えを含んでいるかどうかを評価する。
- 検索システムの評価となる
なお、ビルトインで用意されている評価モジュールは他にもあるし、自分で評価モジュールを作成することもできる。
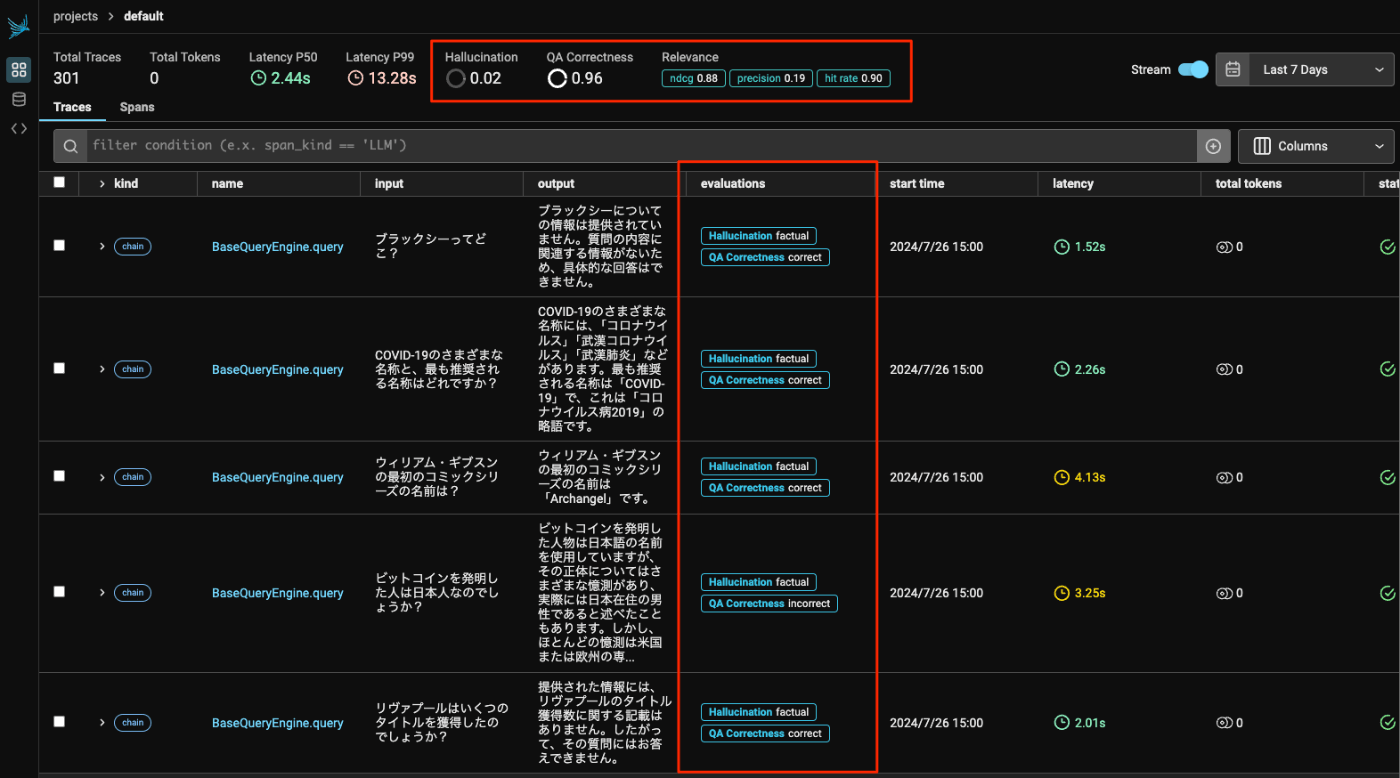
こんな感じで実行された。

PhoenixサーバのGUIをみてみると、各トレースに評価結果がアノテーションとして付与されているのがわかる。全体としての評価結果のサマリも一番上に表示されている。
なお、ここのトレースに対しても以下のように評価結果が付与される。
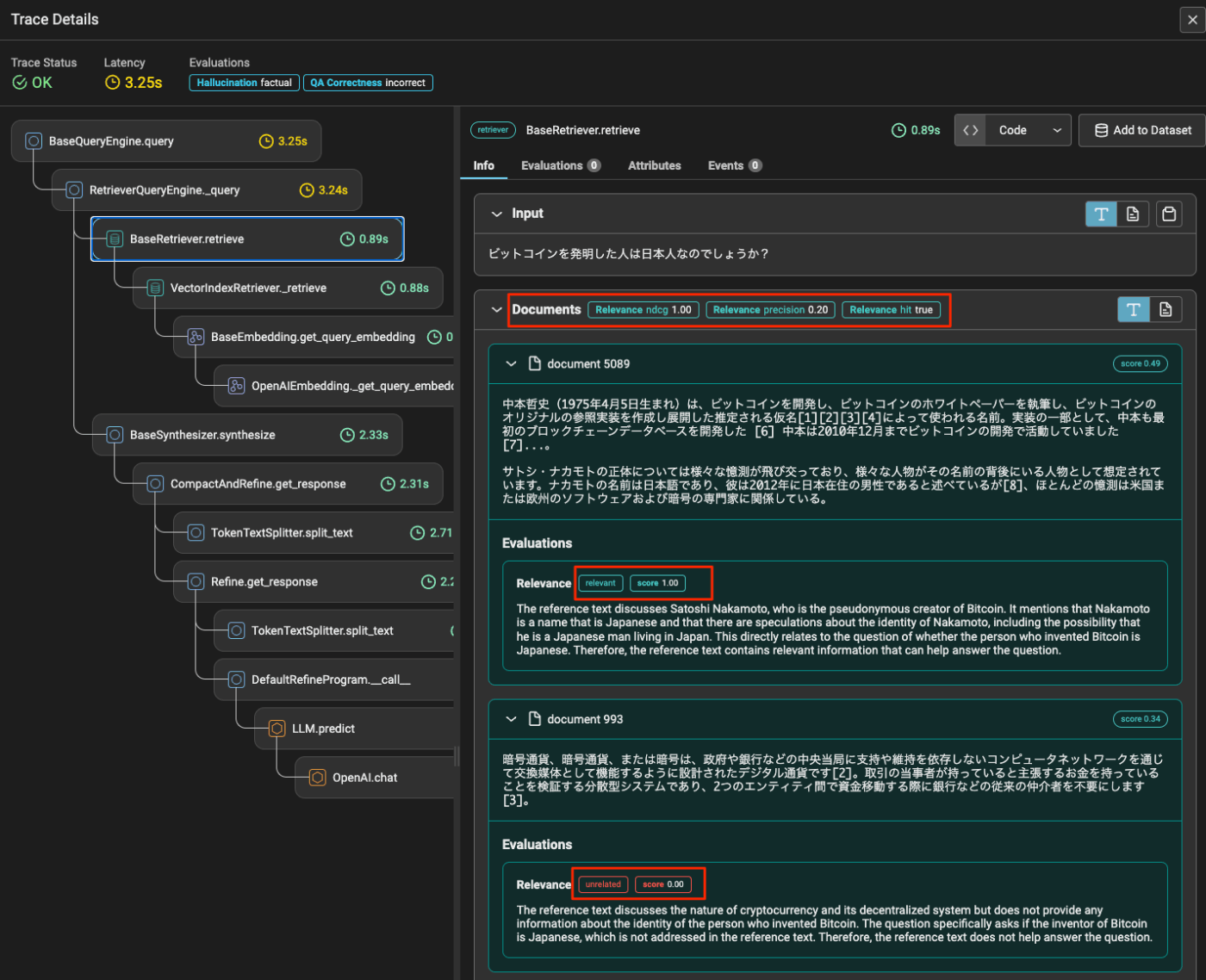
また、評価実行時にprovide_explanation=Trueをつけておくと、評価結果に関する説明も追加されたりする。

説明が英語になっているが、このあたりはプロンプトを定義できる様子。そのあたりも含めて、評価モジュールについてはドキュメントを参照。
また評価を定期的に実行したければCronで定期実行すれば良いみたい。
評価についてはある程度ドキュメントを読み込んでいかないとわからないかも。自分もQuickStartだけではさっぱりわからなかったので、ドキュメント色々見たりレポジトリの中身追いかけたりしてやっと雰囲気つかめたという感がある。
もうちょっとドキュメントの充実というか実運用を想定したnotebookがあればなーというところ。
でもまあ仕組みがわかれば、なかなか悪くないという印象ではある。
データセット
Phoenixサーバにデータセットを登録しておくと、これを使って実験ができる。評価で使用したデータセットを使ってやってみる。
from datasets import load_dataset
import pandas as pd
dataset = load_dataset("kun432/databricks-dolly-300-ja-for-rag", split="train")
df = dataset.to_pandas()
# わかりやすいようにカラム名をリネーム
df.rename(columns={"instruction":"question", "input":"context", "output":"answer"}, inplace=True)
df

このデータセットをPhoenixサーバに登録する。全件はちょっと多いので50件だけ送ることにする。
import phoenix as px
phoenix_client = px.Client()
dataset = phoenix_client.upload_dataset(
dataframe=df[:50],
dataset_name="sample-qa-dataset",
input_keys=["question","context",],
output_keys=["answer"],
metadata_keys=["index","category"],
)
📤 Uploading dataset...
💾 Examples uploaded: http://X.X.X.X:6006/datasets/RGF0YXNldDox/examples
🗄️ Dataset version ID: RGF0YXNldFZlcnNpb246MQ==
データセットがアップロードされた。ブラウザで確認するとこんな感じ。

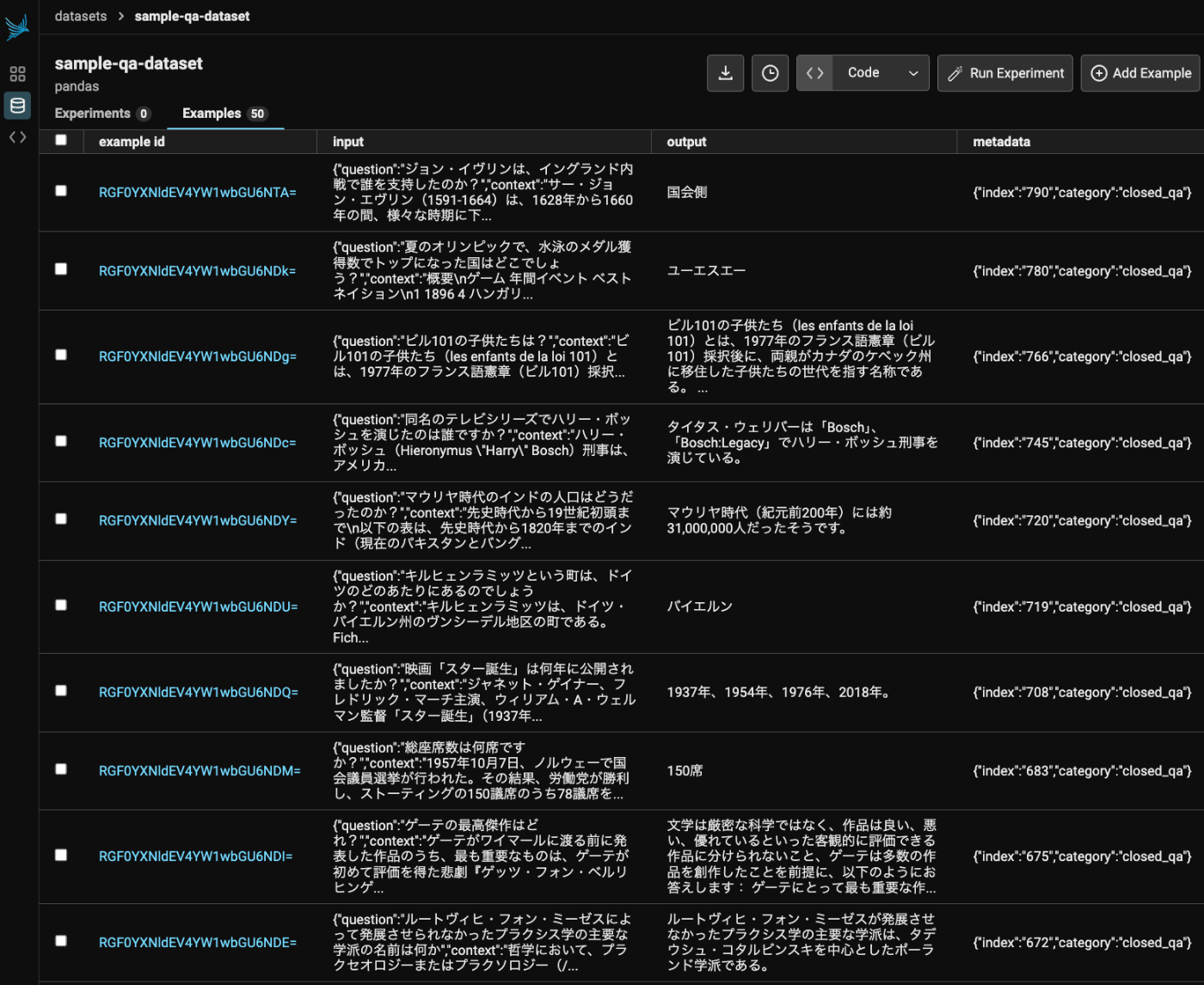
このデータセットを使って実験を行っていく。まず、LLMに対して実行されるタスクを定義。
from openai import OpenAI
from phoenix.experiments.types import Example
openai_client = OpenAI()
task_prompt_template = """\
事前知識を使わずに、以下のコンテキスト情報だけを使用して、質問に「簡潔」に答えてください。
コンテキスト情報: {context}
質問: {question}
回答: \
"""
def task(example: Example) -> str:
question = example.input["question"]
context = example.input["context"]
message_content = task_prompt_template.format(question=question, context=context)
response = openai_client.chat.completions.create(
model="gpt-4o-mini", messages=[{"role": "user", "content": message_content}]
)
return response.choices[0].message.content
タスクの実行結果を評価するための評価モジュールを定義。ビルトインで用意されている評価モジュールには、文字列が含まれているかのシンプルなチェックを行うものから、LLMを使って簡潔さ・有用度を図るようなものなどがある。また、自分でカスタムな評価モジュールを作成することも出来る。
from phoenix.experiments.evaluators import ConcisenessEvaluator
from phoenix.evals.models import OpenAIModel
from phoenix.experiments.evaluators import create_evaluator
from typing import Any, Dict
# ビルトインの評価モジュールの定義
model = OpenAIModel(model="gpt-4o-mini")
# 回答の簡潔さをLLMを使って評価するモジュール
conciseness = ConcisenessEvaluator(model=model)
# カスタムな評価の定義:
# 出力された回答と正解データの回答をLLMに比較させて正確性を判定するカスタムな評価
eval_prompt_template = """
与えられた「質問」と「参考回答」を踏まえて、「回答」の「正確性」を判定してください。
判定結果は、accurate または inaccurate のどちらか1語だけを出力してください。
質問: {question}
参考回答: {reference_answer}
回答: {answer}
正確性 (accurate / inaccurate):
"""
@create_evaluator(kind="llm") # デコレーターがないと、種類はデフォルトで "code "になる。
def accuracy(input: Dict[str, Any], output: str, expected: Dict[str, Any]) -> float:
message_content = eval_prompt_template.format(
# データセットのinputが"input"、outputが"expected"、タスクを実行して得られたレスポンスが"output"として渡される様子(ちょっとややこしい・・・)
question=input["question"], reference_answer=expected["answer"], answer=output
)
response = openai_client.chat.completions.create(
model="gpt-4o-mini", messages=[{"role": "user", "content": message_content}]
)
response_message_content = response.choices[0].message.content.lower().strip()
return 1.0 if response_message_content == "accurate" else 0.0
データセット、タスク、評価を指定して、実験を実行する
from phoenix.experiments import run_experiment
experiment = run_experiment(
dataset,
task,
experiment_name="initial-experiment",
evaluators=[conciseness, accuracy],
)
こんな感じでまずタスクが実行される。
🧪 Experiment started.
📺 View dataset experiments: http://X.X.X.X:6006/datasets/RGF0YXNldDox/experiments
🔗 View this experiment: http://X.X.X.X:6006/datasets/RGF0YXNldDox/compare?experimentId=RXhwZXJpbWVudDox
running tasks
11/50 (22.0%) | ⏳ 01:07
タスクが終わったらその結果の評価が行われる。
✅ Task runs completed.
🧠 Evaluation started.
running experiment evaluations
14/100 (14.0%) | ⏳ 00:35<03:55 | 2.74s/it
評価終了すると結果はこんな感じで表示される。
🔗 View this experiment: http://X.X.X.X:6006/datasets/RGF0YXNldDox/compare?experimentId=RXhwZXJpbWVudDox
Experiment Summary (07/26/24 07:09 PM +0900)
--------------------------------------------
evaluator n n_scores avg_score
0 Conciseness 50 50 0.86
1 accuracy 50 50 0.86
Tasks Summary (07/26/24 07:05 PM +0900)
---------------------------------------
n_examples n_runs n_errors
0 50 50 0
Phoenixサーバもブラウザで見てみると以下のように結果が記録されているのがわかる。データセットごとに実験は管理されるようなので、複数回実行した結果を横ならびで比較できるように見える。

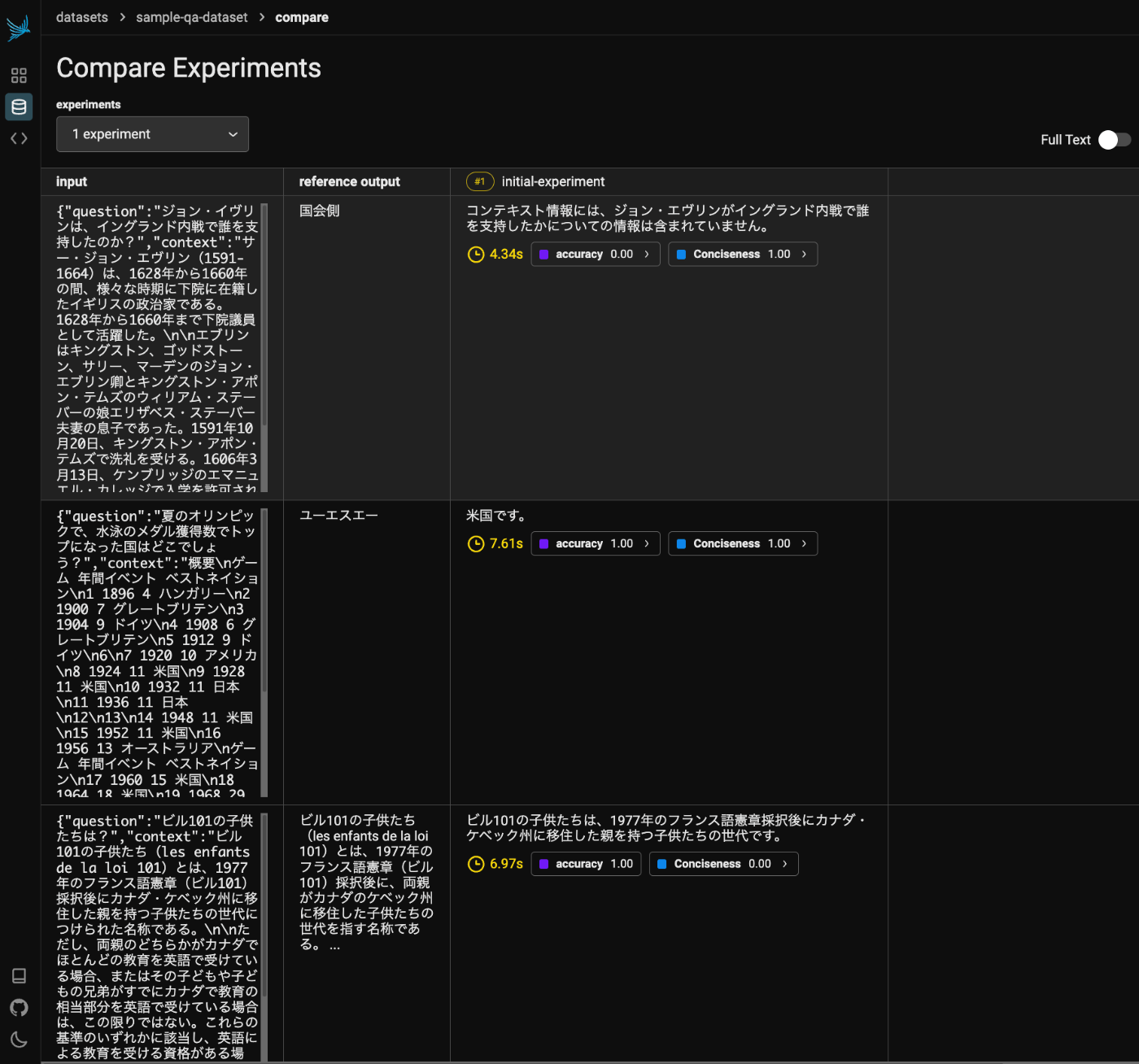
以下は少し気になったところ。
- 評価モジュールで失敗することも多少ある
- 出力結果のパースに失敗している模様。ある程度性能高めのモデルを使ったほうがいいかも。
- おそらく結果の記録時にデータベースがロックされていて失敗することもある
- デフォルトだとSQLiteのようなのでPostgreSQLとかを使ったほうがいいかもしれない
自分は、こういうデータセットを使った実験・評価みたいなものをツールで管理しつつやる、みたいなアプローチをこれまで試したことがなくて、スクラッチで作ったnotebookを使っている。なので、今回はじめてやってみたのだけど、これならかなり便利だと感じた。多分他のトレーシングツールとかでもこの手の機能はあると思うので、ちょっと積極的に使ってみようという気になった。
検索
評価のところでRAGを構築して、検索および生成の両方の評価を行ったが、こちらは検索のみに限定したものになると思う。
ということで、少しやり方は異なるようだが、ここはスキップ。
推論
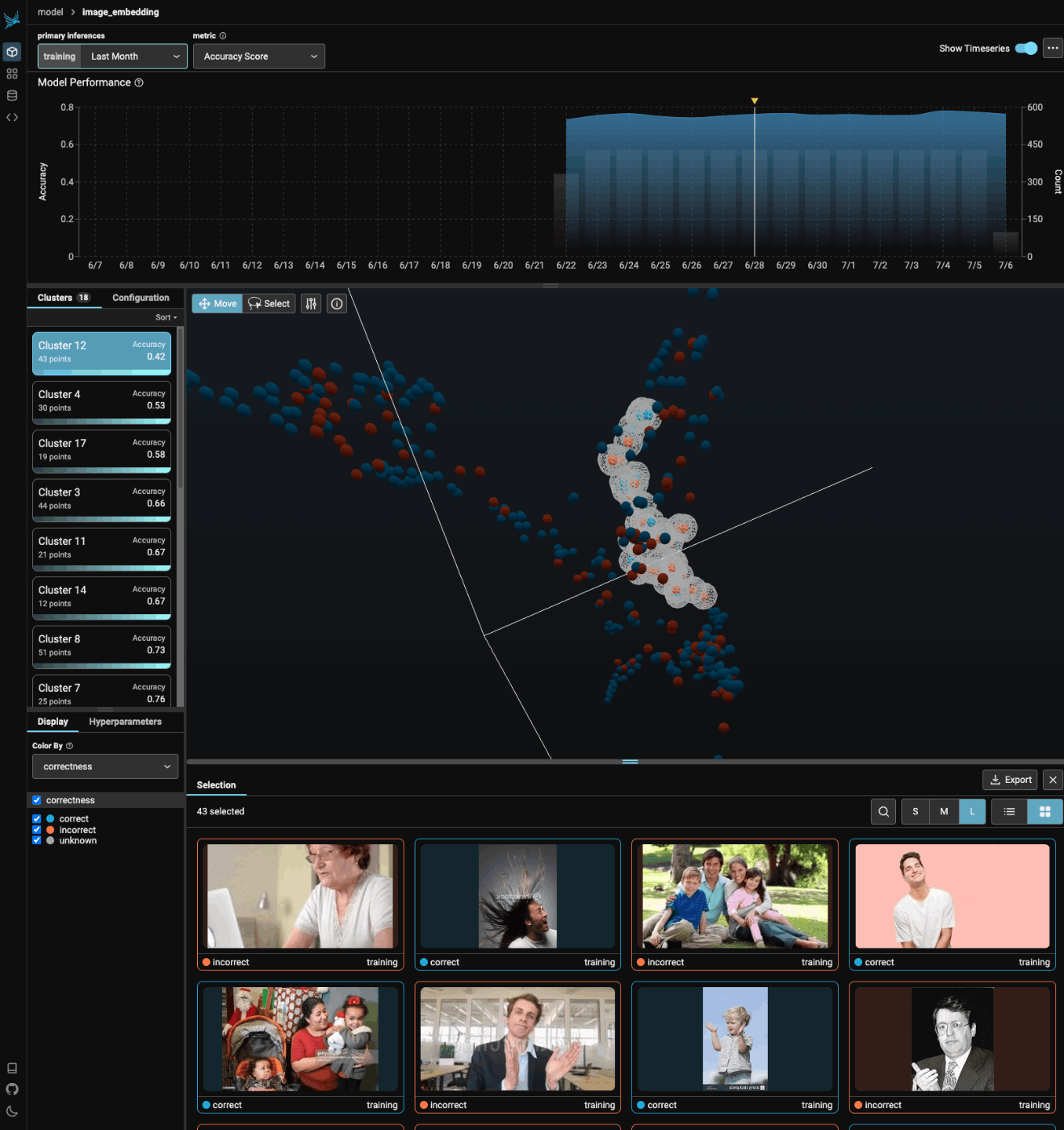
Phoenix Inferencesでは、モデルのすべての推論を1つのインタラクティブなUMAPビューで視覚化することにより、モデルのパフォーマンスを観察することができる。
この強力な可視化はEDA(Explanatory Data Analysis)中に活用でき、モデルのドリフトを理解し、性能の低いクラスタを見つけ、検索問題を発見し、再トレーニング/微調整のためにデータをエクスポートすることができる。
以前興味を持っていたのはここで、Embeddingsの可視化ができたりするみたいで、QuickStartを進めると画像データのEmbeddingsからクラスタリング・可視化ができたりする。
ただ、残念ながらこの部分はDockerでは対応していないらしく、notebook上でpx.launch_appでローカル起動して実行するしかない模様。
ArizeのSlackコミュニティのコメントを見ると、どうやらArizeはトレーシング部分に力を入れているようで、この機能については Phoenixの今後のロードマップにも入っていないらしく、どうやら将来的にはサポートされなくなるかもとのこと。残念。Arizeのクラウド版ではできるっぽいけど。
ということでここもスキップ。
まとめ
あくまでも個人の感想。
普段はnotebook上でLlamaIndexのOne Click Integration経由のトレーシングだけはかなり使っていて、めちゃめちゃお手軽で良いと感じていたのだけど、改めてがっつり触ってみると、やっぱりPhoenixは良く出来ているなーと感じた。特に評価やデータセットなどのあたりについてはこれまで触れてこなかったところなので今後もっと使っていきたいと感じた。
ただ、notebookで使う場合のお手軽さに比べると、セルフホストはいろいろ手間がかかる、というか、多分多機能さにドキュメントが追いついていないという印象を持った。今回もドキュメント見てもよくわからないのでコード読んだりnotebook見たり、してなんとかかんとかという感じ。
同じセルフホストするならLangFuseがめちゃめちゃ使いやすく感じた記憶がある。
ただLlamaIndexを使っていくとなると、LlamaTraceも踏まえてArize PhoenixとLlamaIndexの親和性は今後も高そうだし、LlamaIndexの他のトレーシングツールとのインテグレーションモジュール(LangFuse含む)が現状"Legacy"扱いになっている事も踏まえると、商用向けに自社で運用する場合でもPhoenixがいいのかなぁと思いつつ、やや不安感もある。それなら素直にLlamaTrace使っとけという気もするが、データの所在がな・・・
notebookでサクッとトレースするなら何も困らないので今後も継続的に利用するつもり。LlamaIndex使ってるならぜんぜんオススメできる。ただLlamaIndex使わないならPhoenixにこだわる必要性はないかなというところ。他のフレームワークでどうなってるのか知らんけど。
2025/04のTechnology Radar Volume 32で、Platforms に "Assess"として挙がっていた。
LLMのトレーシングツールもいろいろあって競争は激しそう。