Langfuseを試す
Langfuseとは?
LangfuseはLLMベースのアプリケーションのためのオープンソースの観測・分析ソリューションです。主にプロダクションでの使用を想定していますが、LLMアプリケーションのローカル開発にも使用しているユーザーもいます。
LangfuseはLLMの上に構築されたアプリケーションに焦点を当てています。最近、エージェント、連鎖するプロンプト、エンベッディングベースの検索、REPL や API への LLM アクセスなど、多くの新しい抽象化と共通のベストプラクティスが進化しました。これらはアプリケーションをより強力にしますが、開発者にとっては、変更がアプリケーションの品質、コスト、全体的なレイテンシにどのような影響を与えるか完全に予測することができないため、予測不可能でもあります。Langfuseはこのようなアプリケーションの監視とデバッグを支援します。
対抗としては、
- W&B
- Arize Phoenix
- TruLens
- LangSmith
- HoneyHive
- PromptLayer
あたりになるのかな?OSSだと、Arize Phoenix、TruLens、とこのLangfuseになるのではないかと思う。
インストール
LAN内のサーバにdocker composeでセットアップしたい。公式を参考にdocker-compose.ymlを書いた。自分の環境で変更したのは以下。
- デフォルトだと3000番ポートを使うがすでに埋まっていたので、3001に変更。(
portsとNEXTAUTH_URLのところ) -
NEXTAUTH_URLはLAN内のサーバのホスト名に変更 - Langfuse用のネットワークを追加
- DBのボリュームはローカルディレクトリにマッピング
- テレメトリはオフ
version: "3.5"
services:
langfuse-server:
image: ghcr.io/langfuse/langfuse:latest
depends_on:
- db
ports:
- "3001:3000"
environment:
- NODE_ENV=production
- DATABASE_URL=postgresql://postgres:postgres@db:5432/postgres
- NEXTAUTH_SECRET=mysecret
- SALT=mysalt
- NEXTAUTH_URL=http://XXXXX.local:3001
- TELEMETRY_ENABLED=${TELEMETRY_ENABLED:-false}
- NEXT_PUBLIC_SIGN_UP_DISABLED=${NEXT_PUBLIC_SIGN_UP_DISABLED:-false}
- LANGFUSE_ENABLE_EXPERIMENTAL_FEATURES=${LANGFUSE_ENABLE_EXPERIMENTAL_FEATURES:-false}
networks:
- langfuse-network
db:
image: postgres
restart: always
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
- POSTGRES_DB=postgres
ports:
- 5432:5432
volumes:
- ./database_data:/var/lib/postgresql/data
networks:
- langfuse-network
networks:
langfuse-network:
driver: bridge
ではdocker compose upする。
$ docker compose up
ブラウザからLAN内のサーバのホスト名:3001へアクセス。
ログイン画面が表示されるので、まずアカウント作成に進む。

名前、メアド、パスワードを入れてアカウント作成。
ログインできたら、プロジェクト作成。

今回は"langfuse-test"にした。

プロジェクトが作成され、設定画面が表示される。

設定画面からAPIキーを作成する。
作成されたAPIキーを控えておく。Secret Keyはこのタイミングでしか表示されない。
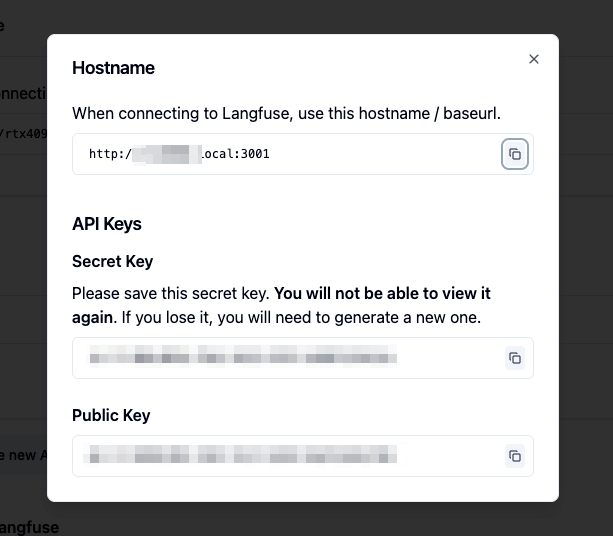
作成されたAPIキーの削除等はこちらで行える。

では実際に使ってみる。別の開発環境を用意。自分の場合はdevcontainerでpython環境を作った。
OpenAI APIを使うサンプルコードを書いてみる。
まず、.envを用意
LANGFUSE_HOST=http://XXXXX.local:3001
LANGFUSE_PUBLIC_KEY=XXXXXXXX
LANGFUSE_SECRET_KEY=XXXXXXXX
OPENAI_API_KEY=XXXXXXXX
パッケージインストール
$ pip install -U langfuse openai python-dotenv
$ pip install -U packaging
サンプルコード。LangfuseがOpenAIをラップする形になるみたい。
import os
from dotenv import load_dotenv
from langfuse.openai import openai, auth_check
load_dotenv()
auth_check()
completion = openai.chat.completions.create(
name="test-chat",
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "あなたはとても正確な計算機です。計算の結果だけを出力しなければなりません。"},
{"role": "user", "content": "2 + 5 = "}],
temperature=0,
metadata={"someMetadataKey": "someValue"},
)
print(completion.choices[0].message.content)
実行
$ python sample.py
7
ではLangfuseの管理画面を見てみる。左のメニューから"Tracing" > "Traces"と進む。

なんか1件データが入っている。IDをクリックしてみる。

なんか表示されているけど、全部"null"になってるな。。。右のところを見ると階層になっているので"GENERATION"をクリックしてみる。
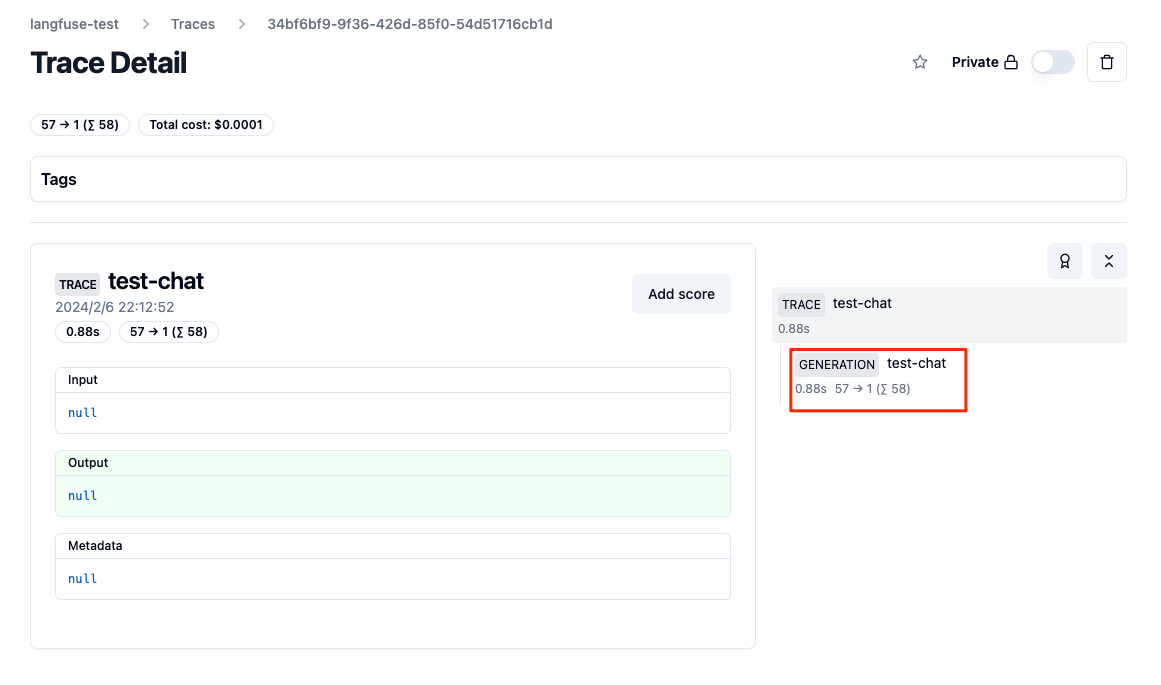
お、プロンプトやレスポンスが入っている。

んー、どうやらトレースのオブジェクトは階層構造になっているみたい。
- 各バックエンドの実行は1つの
traceで記録される。- 各traceは、実行の個々のステップを記録するために、複数の
observationsを含むことができる。
- Observationには異なるタイプがある:
Eventsは基本的なビルディングブロックである。trace内の個別のイベントを追跡するために使用される。Spans、trace内の作業単位の期間を表す。Generationsは、AIモデルの世代を記録するために使用されるspanである。このspanには、モデルやプロンプト/生成に関する追加属性が含まれる。Generationsについては、トークンの使用量とコストが自動的に計算される。- observationsは入れ子にすることができる。
んー、なんかLangChainとかだとここにChainが入るみたいで、素のOpenAIのAPI叩くような単発のAPIコールじゃなくて、抽象化されたライブラリとかを使うようなケースだとどのモジュールから呼ばれているか、みたいなのもよしなに管理できる、ってことなのかなと思う。
ちなみに、Generationsっていうメニューからだと直接generationが一覧で見える。まあこれでもいいっちゃいいのだけども。
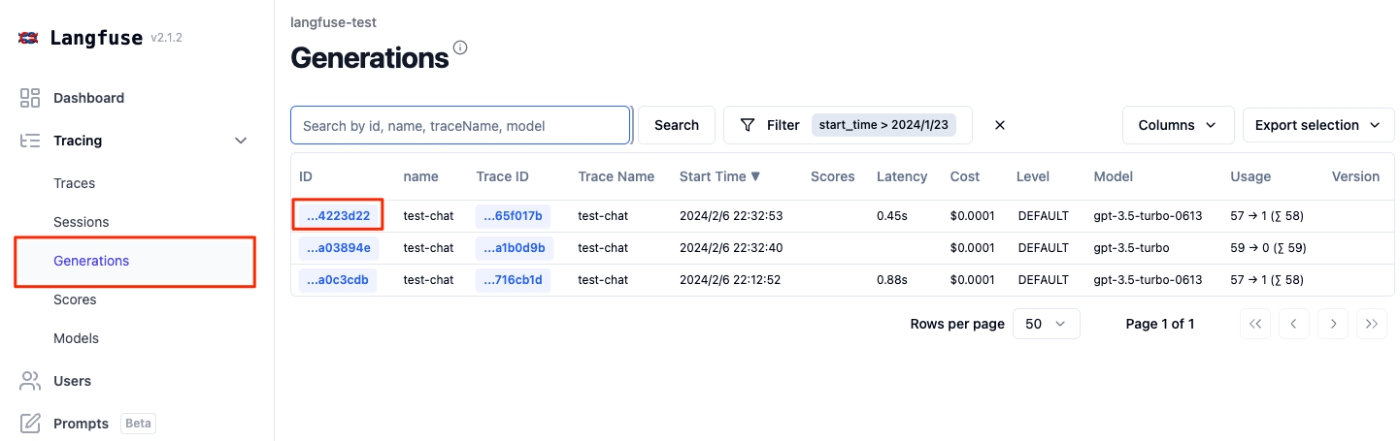

あと"Dashboard"を見ると、利用状況やコストなどがわかるようになっている。これは良さそう。

さっきはOpenAIのpythonライブラリをラップする形で使ったけど、他にも色々な使い方がある。
- LangfuseクライアントSDKからネイティブに送る。LLMとのやり取りもやってくれる。
- LangChainのコールバックハンドラを使う
- APIを直接叩く
- その他、以下のようなツールにもビルトインされている
- Flowise
- Langflow
- LiteLLM
そういえば、ragasでもLangfuseインテグレーションあったな。
LangfuseのPythonクライアントはこれ。
ざっと見てみたけども、うーん、詳細にトレースすることができるのはいいのだけども、LLMへのリクエストも完全もLangfuseクライアントSDKの書き方でアクセスするという感じに見えて、もはや書きっぷりがぜんぜん変わる。トレースはやっぱりコールバックハンドラとかで設定してコードは慣れたOpenAI SDKとかLangChainみたいなフレームワークでやりたいよね。。。トレースのツールやプラットフォームを変える場合にも全然楽だし。トレースのためにネイティブのコードまでそれに合わせるかなー?という気はする。
まあここはユースケース次第で。
LangChainのインテグレーションはあるんだけど、LlamaIndexはなくて、一応issueとかには上がってる。
この辺のインテグレーションがLlamaIndexはちょっと弱いかなぁという感はある。LangChainはこういうの強い(その分、パッケージが肥大化してたけども)
今やるとしたらLiteLLM経由にするかな。LlamaIndex → LiteLLM → Langfuseみたいな。こちらのほうが収まりは良い気がする。
Langfuseでちょっと気になってるのはこれ。
プロンプト管理ができる。似たようなやつだとPromptLayerとかがそうかな。
ということでやってみる。
左のメニュイーから"Prompts" > "+ New prompt"をクリック

プロンプト名とプロンプトを入力。プロンプトは{{変数名}}で変数を含めれば、テンプレートとして使える。Activateして作成。

プロンプトがが作成された。バージョンが発行されているのがわかる。

ではこれをコードから使う。
import os
from dotenv import load_dotenv
from langfuse.openai import openai, auth_check
from langfuse import Langfuse
load_dotenv()
auth_check()
langfuse = Langfuse()
# プロンプトテンプレートを読み込み
prompt = langfuse.get_prompt("simple-company-name-generator")
# プロンプトに値を挿入して
compiled_prompt = prompt.compile(product="カラフルなソックス")
completion = openai.chat.completions.create(
name="prompt-management-test",
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": compiled_prompt}
],
temperature=0,
metadata={"prompt_version": prompt.version}, # プロンプトバージョンをメタデータに入れてみた
)
print(completion.choices[0].message.content)
$ python sample.py
「レインボーソックス」
ではプロンプトを更新してみる。編集アイコンをクリック。
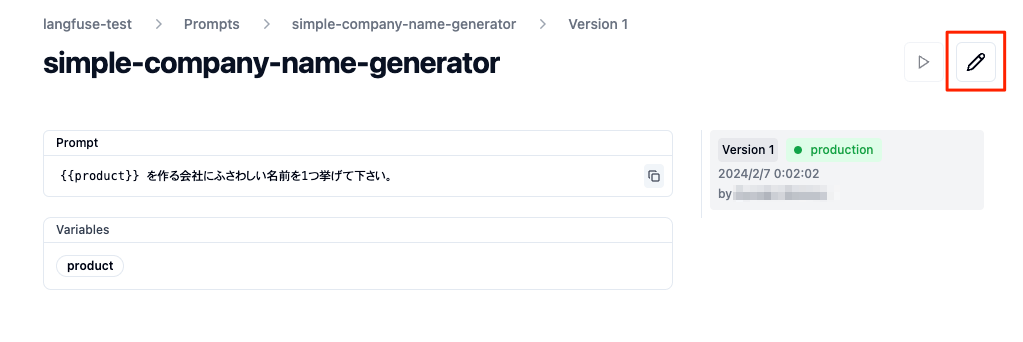
「1つ」を「5つ」に変えて更新。Activateを忘れずに。

バージョン2が生成されているのがわかる。Activateは切り替わる感じなのね。ということは切り戻しも簡単なはずだよな。

では再度スクリプトを実行。
$ python sample.py
1. カラフルソックスカンパニー
2. レインボーソックスメーカー
3. ブライトソックスプロダクション
4. カラーソックスデザイン
5. ビビッドソックスカンパニー
更新したプロンプトで動作しているのがわかる。
メタデータにバージョンを含めたので、トレースでもこんな感じで違っているのがわかる。

プロンプトはActivateしたものがコードから読み込まれるようになっている。Activateの切り替えは編集ではなく、右上の三角のアイコンで切り替える。
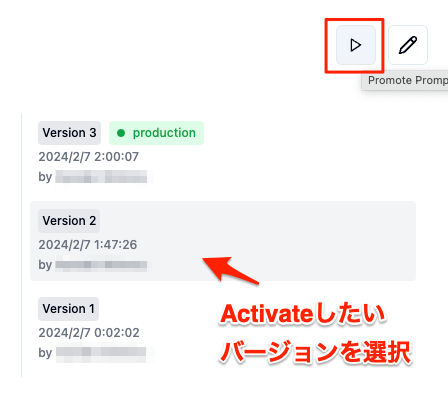


既存のバージョンを編集からActivateをクリックすると、新しいバージョンとして作成されてしまうので注意。
また、コード側からバージョンを指定することもできる。この場合はActivateに関係なくそのバージョンのプロンプトが呼ばれる。
prompt = langfuse.get_prompt("simple-company-name-generator", version=1)
あと試してないけど、キャッシュさせておく機能もあるらしい。DNSキャッシュっぽい挙動になるんじゃないかなーと推測。
prompt = langfuse.get_prompt("simple-company-name-generator", version=1, cache_ttl_secons=300)
お手軽にプロンプトを切り替えれるのは良いね。ただ、あとはこれでdiff取れたら良いのになー、ってところ。
この手のトレーシングとか解析のプラットフォームはなんか使いたいなと思って以前もTruLensとかW&Bを少し試したのだけど、
- 有償プラットフォームが多い。
- かといって自分で運用はしたくない。
- 使いこなすための学習コストも必要。
というところで本腰入れてなかった。ただ、デバッグはやっぱり便利だし、評価とか考え出すとやっぱり必要かなというのを最近感じている。
今でもできればマネージドでやりたいなという思いはあるのだけど、W&Bとか機能が豊富すぎても使いこなせる気が今のところしないので、まずはOSSでお手軽に始めるところから、でも良いのかなと思っている。テストレベルでも良いと思うしね。
あと、試してないけども、以下のような機能もちょっと面白そう。
- データセット作成
- ユーザーフィードバック
- 評価
自分の場合はしばらくはLlamaIndexを中心に使っていこうという感があるので、公式にインテグレーションしてくれたら嬉しい。
あと、試してないけども、以下のような機能もちょっと面白そう。
- データセット作成
- ユーザーフィードバック
- 評価
気になったので少しドキュメントを見てみた。
評価
基本はGUIからポチポチ手動でできるみたいなのだけど、以下のようなragasとのインテグレーションが用意されている。
- 都度のリクエストに対して、Langfuseでトレースしつつ、ragasでスコアリングしつつ、結果をLangfuseに含める。
- Langfuseから一定のトレースを取り出して、ragasでバッチ評価して、結果をLangfuseに戻す。
どっちかというと後者のほうが使いやすそう。全部やるってのは現実的ではない気がするし、前者はアプリケーションコードへの組み込みが必要になりそうで、そこは触りたくないところ。LiteLLMみたいなプロキシ挟んでそこでコールバックさせるとかのほうが良さそう、それでもやりたくはないけども。
ユーザーフィードバック
こちらは当然フロントエンドでの対応が必要なる。以下にJS/TSのSDKがある。
こういうイメージの実装になるっっぽい。トレースIDにスコアとして登録する感じかな。
PythonのSDKでもスコアを送ることはできるので、StreamlitとかChainlitでもできそう。
Streamlitだと
データセット
これはデータセットのデータを作成するんじゃなくて、データセットを用意していけば、それを読み出して簡単に実行+トレース+評価(評価部分は自分で用意する)もセットで記録しておけるって感じに読める。
どっちかというと管理に近いのかなというイメージ。
お、LlamaIndexに対応したらしい、αだけど。
We've just released the first alpha version of this integration (mostly stable but some things might still change before we add it to the documentation and the llamaindex package -> not covered by semver yet, interfaces might still change slightly).
LlamaIndexのコールバックハンドラだけで設定できてよさそう。
めちゃめちゃ参考になる。
自分が試したのももう1年前だし、v3になってるらしいので、もっかい試してみようかな。