ColPali: PaliGemma-3BとColBERTストラテジーに基づくビジュアルレトリバー
これで知った
HuggingFaceで公開されている
ColPaliは、視覚言語モデル(VLM)に基づく新しいモデルアーキテクチャと学習戦略に基づいて、視覚的特徴から効率的に文書をインデックス化するモデルである。PaliGemma-3Bの拡張で、テキストと画像のColBERTスタイルのマルチベクトル表現を生成する。論文 ColPali で紹介された: Efficient Document Retrieval with Vision Language Models で紹介され、このリポジトリで初めて公開された。
論文
GitHubレポジトリ
マルチモーダルモデルを使ったRAGはLlamaIndexのドキュメントにも色々あるけど、retrievalでColBERTを使うってのがポイントなのではなかろうか。
ちょっとRagatouille触ったところでColBERTに興味が出てきたのと、あとPaliGemma全く触ってないのもあって、少し触ってみたいところ。
どうやら近々LlamaIndexのWebinarがある様子。LlamaIndex側にはドキュメントもnotebookもまだ存在しないみたい。
少し前にByaldiというラッパーを使って試していたのだけど、
以下を試している際にColPaliのCookbookがあることを知った。
上記を試した後に、やはりネイティブなColPaliライブラリにも触れておきたいと思ったので、改めて基本的なところから試すことにする。
以下も参考にさせていただく。
Quick Start
Colaboratoryで。ランタイムはT4。
colpali-engineをインストール。インストール後に多分ランタイム再起動が求められるので再起動。
!pip install colpali-engine
!pip freeze | grep -i colpali
colpali_engine==0.3.4
検索に使用する画像はColPaliのCookbookにある画像を日本語に修正した物を使用する。
画像1

画像2
画像を処理するためのユーティリティを用意
from io import BytesIO
from PIL import Image
import requests
from typing import List
def load_image_from_url(url: str) -> Image.Image:
"""
有効なURLからPILイメージをロードする
"""
response = requests.get(url)
return Image.open(BytesIO(response.content))
def scale_image(image: Image.Image, new_height: int = 1024) -> Image.Image:
"""
アスペクト比を維持しながら画像を新しい高さにスケーリングする
"""
width, height = image.size
aspect_ratio = width / height
new_width = int(new_height * aspect_ratio)
scaled_image = image.resize((new_width, new_height))
return scaled_image
ColPaliモデルをロードして、画像・テキストのEmbeddingを生成、類似性を計算する。なお、ColPaliモデルはPaliGemmaがベースになっているが、このモデルは日本語での学習が行われていないため、Qwen2-VLをベースにしたColQwenを使用した。
import torch
from colpali_engine.models import ColQwen2, ColQwen2Processor
model_name = "vidore/colqwen2-v1.0"
model = ColQwen2.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="cuda:0", # or "mps" if on Apple Silicon
).eval()
processor = ColQwen2Processor.from_pretrained(model_name)
# 入力
images: List[Image.Image] = [
load_image_from_url(
# 2019年の燃料別平均発電量の時間帯推移に関する画像
"https://raw.githubusercontent.com/kun432/colpali-cookbooks-jp-files/refs/heads/main/data/energy_electricity_generation_ja.jpg"
),
load_image_from_url(
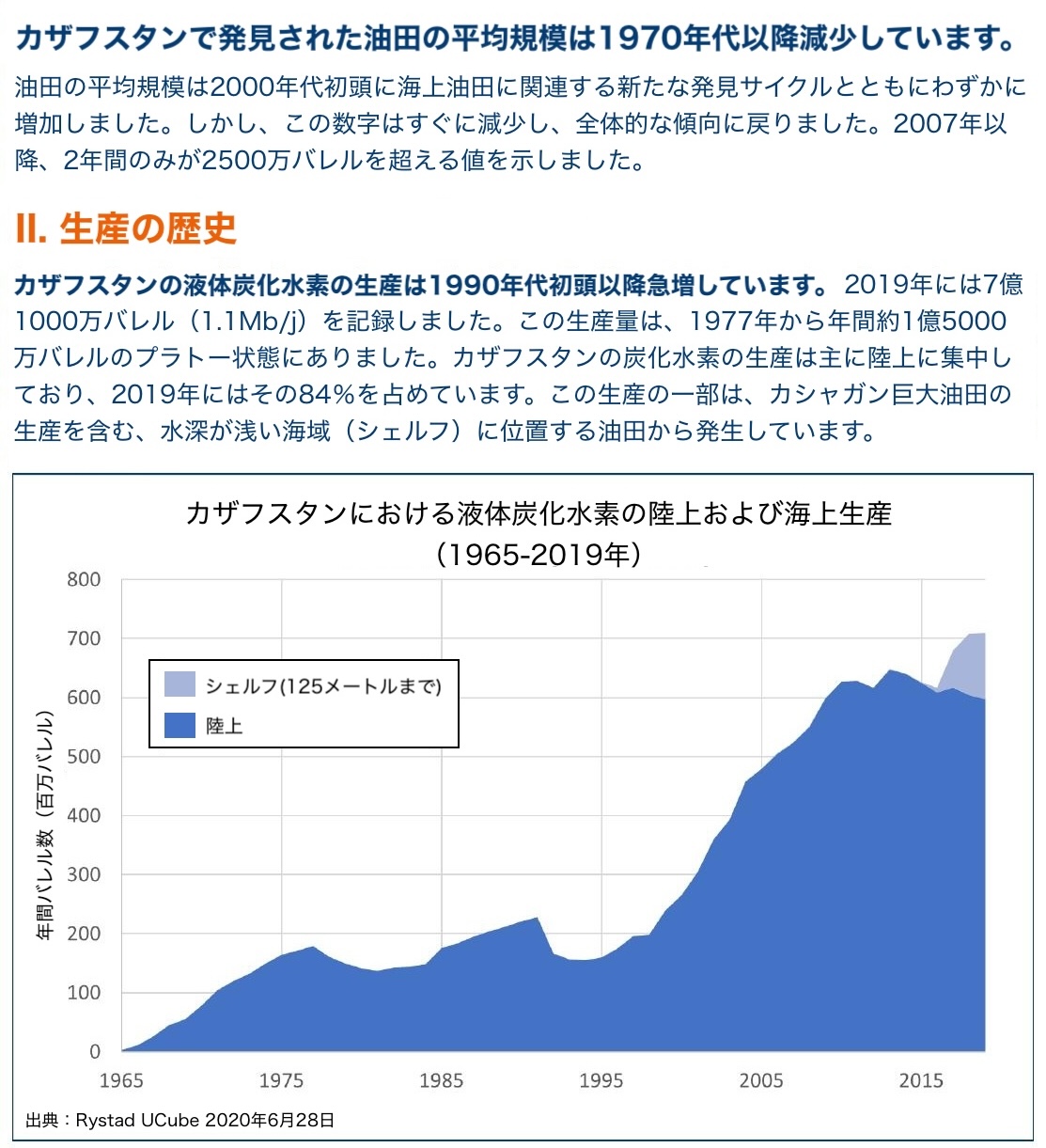
# カザフスタンの油田の生産の歴史の画像
"https://raw.githubusercontent.com/kun432/colpali-cookbooks-jp-files/refs/heads/main/data/shift_kazakhstan_ja.jpg"
),
]
images = [scale_image(image, new_height=512) for image in images]
queries = [
"カザフスタンの石油生産量のうち、海底油田の占める割合は?",
"2019年に最も多くの電力が生成された時間帯はどの時間ですか?"
]
# 入力を処理
batch_images = processor.process_images(images).to(model.device)
batch_queries = processor.process_queries(queries).to(model.device)
# フォワードパス
with torch.no_grad():
image_embeddings = model(**batch_images)
query_embeddings = model(**batch_queries)
scores = processor.score_multi_vector(query_embeddings, image_embeddings)
scores
結果
tensor([[12.1875, 21.3750],
[22.8750, 13.1875]])
クエリ順にそれぞれの画像との類似度スコアが返される。1つ目の「カザフスタンの石油生産量のうち、海底油田の占める割合は?」に対しては「カザフスタンの油田の生産の歴史の画像」、2つ目の「2019年に最も多くの電力が生成された時間帯はどの時間ですか?」に対しては「2019年の燃料別平均発電量の時間帯推移に関する画像」のほうがそれぞれスコアが高いことがわかる。
わかりやすいようにtop-1を出力してみる。
for idx, query in enumerate(queries):
retrieved_image_index = scores[idx].argmax().item()
retrieved_image = images[retrieved_image_index]
print(f"クエリ: {query}")
print("検索結果:")
display(scale_image(retrieved_image, new_height=256))
print("----")

以下を参考にさせていただいてもう少し実用的な例を試す。同じくColaboratory T4で。
神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDFを使用する。
パッケージ諸々インストール
!apt update && apt install -y poppler-utils
!pip install colpali-engine pdf2image
!pip freeze | grep -i colpali
!pip freeze | grep -i pdf2image
PDFをPILのイメージとして読み込み。
!wget https://www.city.kobe.lg.jp/documents/15123/r5_doukou.pdf
from pdf2image import convert_from_path
from PIL import Image
def scale_image(image: Image.Image, new_height: int = 1024) -> Image.Image:
"""
アスペクト比を維持しながら画像を新しい高さにスケーリングする(確認用)
"""
width, height = image.size
aspect_ratio = width / height
new_width = int(new_height * aspect_ratio)
scaled_image = image.resize((new_width, new_height))
return scaled_image
images = convert_from_path("r5_doukou.pdf")
# 確認
for idx, i in enumerate(images, start=1):
print(f"Page: {idx}")
display(scale_image(i, new_height=256))

これをEmbeddingに変換する。
from typing import List, cast
import torch
from torch.utils.data import DataLoader
from tqdm import tqdm
from colpali_engine.models import ColQwen2, ColQwen2Processor
from colpali_engine.utils.processing_utils import BaseVisualRetrieverProcessor
from colpali_engine.utils.torch_utils import get_torch_device
device = get_torch_device("auto")
print(f"Device used: {device}")
model_name = "vidore/colqwen2-v0.1"
# モデルをロード
model = ColQwen2.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map=device,
).eval()
# プロセッサをロード
processor = cast(ColQwen2Processor, ColQwen2Processor.from_pretrained(model_name))
if not isinstance(processor, BaseVisualRetrieverProcessor):
raise ValueError("Processor should be a BaseVisualRetrieverProcessor")
# ドキュメントをEmbeddingsに変換
dataloader = DataLoader(
dataset=images,
batch_size=2,
shuffle=False,
collate_fn=lambda x: processor.process_images(x),
)
embeddings_docs: List[torch.Tensor] = []
for batch_doc in tqdm(dataloader):
with torch.no_grad():
batch_doc = {k: v.to(model.device) for k, v in batch_doc.items()}
embeddings_doc = model(**batch_doc)
embeddings_docs.extend(list(torch.unbind(embeddings_doc)))
# 作成したEmbeddingsを保存
torch.save(embeddings_docs, "./embedding_docs.pt")
ではクエリ。
query = "観光客の年齢構成を教えて"
# クエリをEmbeddingに変換
processed_query = processor.process_queries([query]).to(model.device)
with torch.no_grad():
query_embedding = model(**processed_query)
scores = processor.score_multi_vector(query_embedding, embeddings_docs)[0]
scores
各ページ(画像)ごとにスコアが計算される。
tensor([13.5000, 12.5000, 12.3125, 14.0000, 11.0000, 11.1875, 11.4375, 13.8750,
12.3125, 13.3125, 12.8125, 12.5625, 11.5000, 12.8125, 13.1875, 10.7500,
11.6875, 10.4375, 13.0625, 12.1250, 12.7500])
スコアの上位5件を取得し、それぞれの画像を表示する。
k=5
scores_indices = scores.argsort().tolist()[-k:][::-1]
scores_indices
[3, 7, 0, 9, 14]
for index in scores_indices:
print(f"Page: {index+1} Score: {scores[index]}")
display(scale_image(images[index], new_height=800))
年齢構成について書かれたページが1位で取得できた。

保存したEmbeddingsを読み込んで検索する場合はこんな感じで。
from typing import List, cast
import torch
from colpali_engine.models import ColQwen2, ColQwen2Processor
from colpali_engine.utils.processing_utils import BaseVisualRetrieverProcessor
from colpali_engine.utils.torch_utils import get_torch_device
from pdf2image import convert_from_path
from PIL import Image
def scale_image(image: Image.Image, new_height: int = 1024) -> Image.Image:
"""
アスペクト比を維持しながら画像を新しい高さにスケーリングする
"""
width, height = image.size
aspect_ratio = width / height
new_width = int(new_height * aspect_ratio)
scaled_image = image.resize((new_width, new_height))
return scaled_image
images = convert_from_path("r5_doukou.pdf")
device = get_torch_device("auto")
print(f"Device used: {device}")
model_name = "vidore/colqwen2-v0.1"
# モデルをロード
model = ColQwen2.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map=device,
).eval()
# プロセッサをロード
processor = cast(ColQwen2Processor, ColQwen2Processor.from_pretrained(model_name))
if not isinstance(processor, BaseVisualRetrieverProcessor):
raise ValueError("Processor should be a BaseVisualRetrieverProcessor")
# 保存しておいたEmbeddingsをロード
embeddings_docs = torch.load("./index.pt", weights_only=True)
# クエリで検索
query = "観光客の年齢構成を教えて"
k=5
processed_query = processor.process_queries([query]).to(model.device)
with torch.no_grad():
query_embedding = model(**processed_query)
scores = processor.score_multi_vector(query_embedding, embeddings_docs)[0]
scores_indices = scores.argsort().tolist()[-k:][::-1]
# 検索結果を表示
for index in scores_indices:
print(f"Page: {index+1} Score: {scores[index]}")
display(scale_image(images[index], new_height=800))