LoRAアダプターのホットスワッピングを使ったColQwen2単体でのRAGを試す
ここで知った。これちょっと気になる。
🚀 新しいクックブックのご紹介:アダプターのホットスワッピングを活用し、単一のColQwen2モデルでRAGパイプライン全体を実装する方法を解説。無料のColab T4でも動作します!
詳しくはこちらをご覧ください:
https://github.com/tonywu71/colpali-cookbooks
(1/N)
アダプターのホットスワッピング 🔄 とは、タスクに応じてモデル内でタスク固有のアダプターをリアルタイムでロードおよびアンロードできる機能を指します。これによりVRAMを節約でき、特にオンエッジモデルにおいて重要な利点となります。
(2/N)
ColQwen2は、Qwen2-VL-2B VLMをベースにLoRAを使用してトレーニングされています。そのため、アダプターのホットスワッピングによって以下が可能になります:
1️⃣ 埋め込みの作成(アダプター有効化 + フォワードパス)
2️⃣ 画像に基づく生成(アダプター無効化 + 生成モード)
(3/N)
⚠️ Qwen2-VL-2Bは多くのドキュメントに対して優れた性能を発揮しますが、ChartQAやInfoVQAのような視覚的に複雑なタスクでは、より大きなモデルに比べて効果が低い場合があります(Qwen2-VL論文のメトリクス表を参照してください)。
そのため、そのようなドキュメントではハルシネーションの可能性に注意してください!
(4/N)
📑 このクックブックの別の用途:100ページを超えるレポートのような、VLM(視覚言語モデル)に収まらない長文ドキュメントに対処する方法です。
1️⃣ ドキュメントの各ページとクエリを埋め込み、
2️⃣ トップkのページを取得し、
3️⃣ {クエリ + トップkのページ} を生成モードでモデルに入力します。
(5/N)
😍 さらにColVisionのユースケースを知りたい方は、ColPaliリポジトリのコミュニティセクションにアクセスしてください。コミュニティが私たちのモデルを活用して作り上げた素晴らしいプロジェクトやリソースを探索できます!
https://github.com/illuin-tech/colpali#community-projects (6/N)
でどうやらこの方はColPali論文の著者のお一人のようで、ColPaliのGitHubレポジトリにColPali Cookbooksという形でノートブックを公開されている様子。
TonyさんのGitHubレポジトリ
公開されているのは以下の4つ。
タスク ノートブック 説明 解釈可能性 ColPali: 自分の類似マップを生成 👀 ColPaliの予測を解釈するための類似マップを自分で生成する。 ファインチューニング ColPaliをファインチューニング 🛠️ LoRAを使用し、オプションで4bit/8bit量子化を用いてColPaliをファインチューニングする方法を学ぶ。 解釈可能性 ColQwen2: 自分の類似マップを生成 👀 ColQwen2の予測を解釈するための類似マップを自分で生成する。 RAG ColQwen2: アダプターのホットスワッピングによるRAGパイプライン 🔥 RAGパイプライン全体にユニークなVLMを使用し、VRAMを節約する方法を学ぶ。Colabの無料T4 GPUでも動作可能!
他も気になるが、このXのポストで紹介されているアダプターホットスワッピング、VRAM節約できるという点は魅力的なので、まずはこれから試してみる。
ColQwen2: One model for your whole RAG pipeline with adapter hot-swapping 🔥
ノートブックはこちら
上記を日本語化したノートブックを用意した。ノートブック内で使用されているドキュメント画像についても日本語化してある。
Colaboratoryでやってみる。ランタイムは記載の通りT4。
ライブラリをインストール
!pip install -q -U "colpali-engine>=0.3.1,<0.4.0" requests
ライブラリをインポート
from io import BytesIO
from typing import Any, List, cast
import requests
import torch
from colpali_engine.models import ColQwen2, ColQwen2Processor
from colpali_engine.utils.torch_utils import get_torch_device
from IPython.display import display
from peft import LoraConfig
from PIL import Image
from transformers.models.qwen2_vl import Qwen2VLForConditionalGeneration, Qwen2VLProcessor
画像を扱うためのユーティリティ関数を定義
def load_image_from_url(url: str) -> Image.Image:
"""
有効なURLからPILイメージをロードする
"""
response = requests.get(url)
return Image.open(BytesIO(response.content))
def scale_image(image: Image.Image, new_height: int = 1024) -> Image.Image:
"""
アスペクト比を維持しながら画像を新しい高さにスケーリングする
"""
width, height = image.size
aspect_ratio = width / height
new_width = int(new_height * aspect_ratio)
scaled_image = image.resize((new_width, new_height))
return scaled_image
ColQwen2をRAGで利用するためのクラスが用意されているのでこれを使う。
class ColQwen2ForRAG(ColQwen2):
"""
ColQwen2モデルは、検索と生成の両方で使用できる実装です。
検索モードと生成モードの切り替えが可能です。
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._is_retrieval_enabled = True
def forward(self, *args, **kwargs) -> Any:
"""
現在のモードに基づいて、Qwen2VLForConditionalGeneration.forward(生成用)
またはColQwen2.forward(検索用)を呼び出すフォワードパス。
"""
if self.is_retrieval_enabled:
return ColQwen2.forward(self, *args, **kwargs)
else:
return Qwen2VLForConditionalGeneration.forward(self, *args, **kwargs)
def generate(self, *args, **kwargs):
"""
Qwen2VLForConditionalGeneration.generateを使用してテキストを生成
"""
if not self.is_generation_enabled:
raise ValueError(
"generate()を呼び出す前に、enable_generation()を呼び出してモデルを生成モードに設定してください。"
)
return super().generate(*args, **kwargs)
@property
def is_retrieval_enabled(self) -> bool:
return self._is_retrieval_enabled
@property
def is_generation_enabled(self) -> bool:
return not self.is_retrieval_enabled
def enable_retrieval(self) -> None:
"""
検索モードに切り替え
"""
self.enable_adapters()
self._is_retrieval_enabled = True
def enable_generation(self) -> None:
"""
生成モードに切り替え
"""
self.disable_adapters()
self._is_retrieval_enabled = False
ColQwen2をロード
model_name = "vidore/colqwen2-v1.0"
device = get_torch_device("auto")
print(f"Using device: {device}")
# 事前学習済みの検索モデルからLoRA設定を取得
lora_config = LoraConfig.from_pretrained(model_name)
# プロセッサをロード
processor_retrieval = cast(ColQwen2Processor, ColQwen2Processor.from_pretrained(model_name))
processor_generation = cast(Qwen2VLProcessor, Qwen2VLProcessor.from_pretrained(lora_config.base_model_name_or_path))
# 事前学習済みのアダプターを検索用にロードしてモデルを読み込み
model = cast(
ColQwen2ForRAG,
ColQwen2ForRAG.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map=device,
),
)
説明などにも書いてあるとおり、ColQwen2はLoRAを使用してトレーニングされている。自分はLoRAについてちゃんと理解ができていないのだが、
- LoRAは、モデルの特定の層に低ランク行列を追加してチューニングを行う仕組み
- 元のモデルの重み全体を変更しなくて済むので計算効率・ストレージ効率良くチューニングすることができる
- この追加される低ランク行列を「アダプター」という
- タスクに応じてチューニングされたアダプターを切り替えることで、モデルの使い方を変えることができる
というものらしい。で、どうやらColQwen2はQwen2-VLに検索用アダプターを追加したものであり、つまり、このアダプタを無効化するとQwen2−VLが本来持っている生成用途に利用できる、ということらしい。
では、まずColQwenで検索を行う。元のノートブックで用意されていた画像を日本語化した。
画像1

画像2
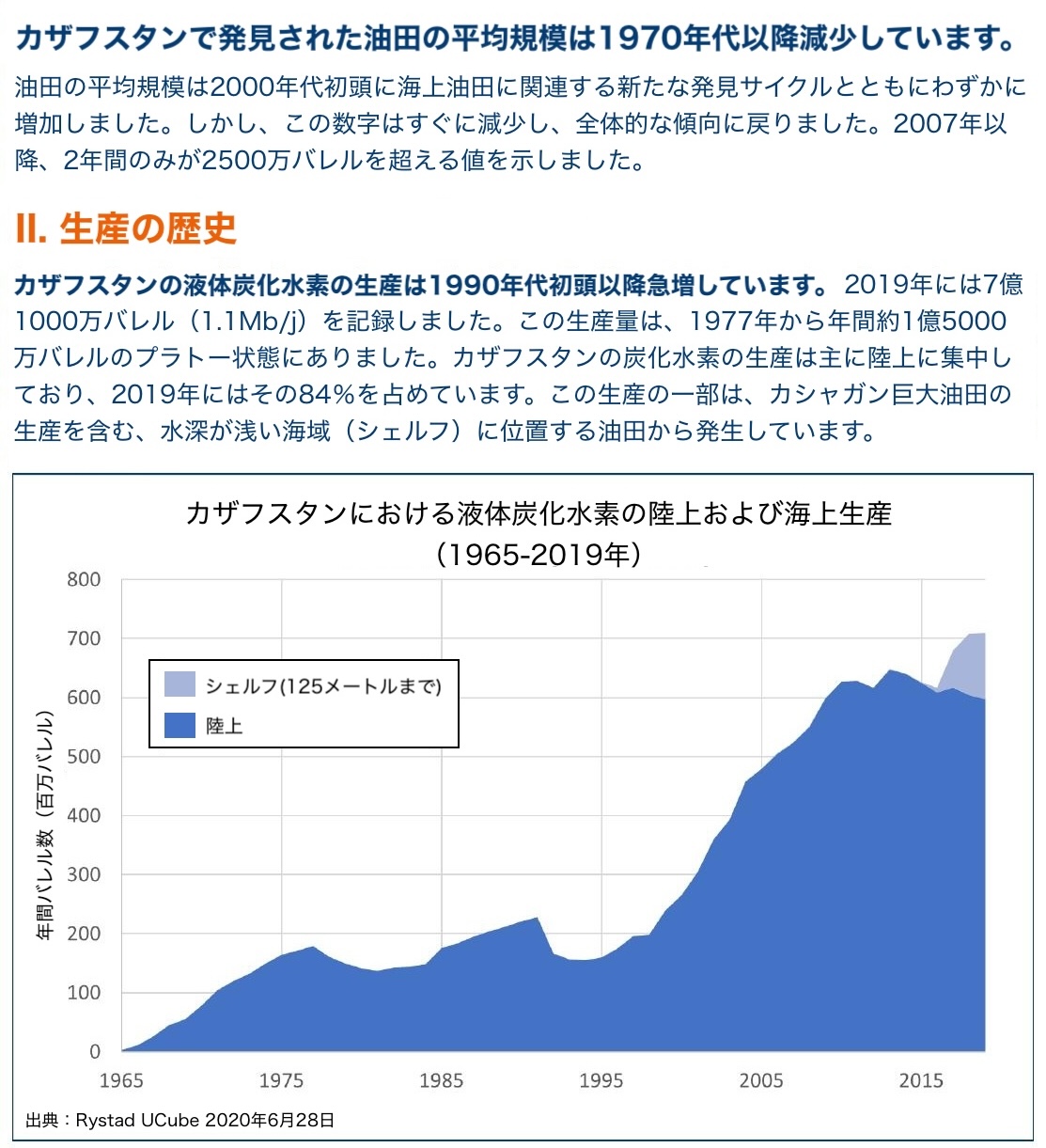
query = "カザフスタンの石油生産量のうち、海底油田の占める割合は?"
images: List[Image.Image] = [
load_image_from_url(
"https://raw.githubusercontent.com/kun432/colpali-cookbooks-jp-files/refs/heads/main/data/energy_electricity_generation_ja.jpg"
),
load_image_from_url(
"https://raw.githubusercontent.com/kun432/colpali-cookbooks-jp-files/refs/heads/main/data/shift_kazakhstan_ja.jpg"
),
]
images = [scale_image(image, new_height=512) for image in images]
for image in images:
display(scale_image(image, new_height=256))
検索。今回は2つしか画像がないので1件だけ取得する。
# 入力を処理
batch_images = processor_retrieval.process_images(images).to(model.device)
batch_queries = processor_retrieval.process_queries([query]).to(model.device)
# フォワードパス
model.enable_retrieval()
with torch.no_grad():
image_embeddings = model.forward(**batch_images)
query_embeddings = model.forward(**batch_queries)
# 類似度スコアを計算
scores = processor_retrieval.score_multi_vector(query_embeddings, image_embeddings)
# 1位のページ画像を取得
retrieved_image_index = scores.argmax().item()
retrieved_image = images[retrieved_image_index]
print(f"次のクエリに対して取得された画像: `{query}`")
display(scale_image(retrieved_image, new_height=256))
検索結果

今度はこれを元に回答を生成させる。ここで検索アダプターが無効化される。
# 入力を処理
conversation = [
{
"role": "user",
"content": [
{
"type": "image",
},
{
"type": "text",
"text": f"入力画像を使って次の質問に答えてください: {query}",
},
],
}
]
text_prompt = processor_generation.apply_chat_template(conversation, add_generation_prompt=True)
inputs_generation = processor_generation(
text=[text_prompt],
images=[image],
padding=True,
return_tensors="pt",
).to(device)
# RAGのレスポンスを生成
model.enable_generation()
output_ids = model.generate(**inputs_generation, max_new_tokens=128)
# 生成された`output_ids`から新たに生成されたトークンIDのみが保持されていることを確認
generated_ids = [output_ids[len(input_ids) :] for input_ids, output_ids in zip(inputs_generation.input_ids, output_ids)]
# RAGのレスポンスをデコード
output_text = processor_generation.batch_decode(
generated_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=True,
)
print(output_text)
正解!
['カザフスタンの石油生産量のうち、海底油田の占める割合は約84%を占めています。']
このときのリソース使用量はこんな感じ。

ColQwen2ではQwen2-VL-2B-Instructを使用しているらしい。自分が過去にQwen2-VL-2B-Instructを試した際には、画像サイズにもよっても変わるが、単体でもこれぐらいVRAM消費してたと思うので、RAGでColQwen2+Qwen2-VL-2Bの両方を使用することを考えるとほぼ半分で済むのではないかと思う。
ちなみに別のクエリも試してみた。
query = "2019年に最も多くの電力が生成された時間帯はどの時間ですか?"
検索結果

生成結果
['2019年に最も多くの電力が生成された時間帯は、午前8時から午前10時です。']
検索はあっているが、生成は間違っている。これについては一番下に補足がある。
- 以前のセルを再実行し、以下のクエリを使用してみてください:
"2019年に最も多くの電力が生成された時間帯はどの時間ですか?"
ColQwen2が正しいページを取得できることがわかるでしょう。ただし、生成部分では幻覚的な(誤った)回答を得るはずです。これは、Qwen2-VL-2Bが比較的「小さな」パラメーター数を持っており、12Bや72Bといった大きなモデルに比べてチャートの理解が制限されているためです。
まとめ
ColQwen2、日本語も使えて精度も良い感じなので、RAGで使っていきたいところなのだけど、VRAM足りるか?は常に悩ましいところ(ColQwen2に限らずね)だと思うので、こういう例が提供されるのはとても良い。
個人的にはLoRAってこういう風に使えるということを知って、とても勉強になった。反面、モデルのチューニングについてはきちんと試せていないし理解も足りないので、改めてやっていかないとなーという必要性を感じている。
他にもノートブックが用意されているので、そちらも試していきたい。
ColQwen2ではQwen2-VL-2B-Instructを使用しているらしい
Qwen2-VL-2Bが比較的「小さな」パラメーター数を持っており、12Bや72Bといった大きなモデルに比べてチャートの理解が制限されているためです。
検索に求められる精度と生成に求められる精度は異なるかもしれない。よりよい回答精度となると、やはり別のモデルを組み合わせて使うか、よりパラメータサイズの大きなモデルがベースになってるColQwenモデルが欲しくなりそう。