ColQwen2(Colpali)による日本語PDFのページ検索(上位スコアの抽出とフィルタリング)+ Qwen2-VLでQ&A
はじめに
今回はColQwen2を使った日本語PDFのページ検索を試してみます。
具体的には以下を(個別のpythonスクリプトで)実装してます。
- create_embedding.py : 日本語PDFをベクトル化してインデックスを作成
- search_pdf.py : 作成したインデックスを用いて検索クエリからPDFの検索を実行後、検索結果として上位スコア5件(ページ)を出力
- search_pdf_normalize.py : 作成したインデックスを用いて検索クエリからPDFのページ検索を実行後、検索結果のスコアを正規化(Min-Max法)して0.6以上の結果をフィルタリングして出力
- search_pdf_qa.py : 上位スコア1件を検索後、Qwen2-VLを用いてQ&Aを実行
ColQwen2とは
ColQwen2は、画像からインデックスを作成して検索可能にするColPaliというモデルのベースを「PaliGemma」から「Qwen2-VL」に変更したものです。ColPaliは日本語には(ほとんど)対応していませんが、ColQwen2では日本語にも対応できるようになっています(実際は、ColQwen2自体は英語でしか学習されていません。日本語に対応できるのはベースの「Qwen2-VL」が多言語モデルとして日本語に対応しているためかと思われます。)。[1]
ColQwen2(ColPali)ではドキュメントを画像として扱うため、事前にOCRによるテキストの抽出をしておく必要ありません。
この手法によるメリットは、(ざっくりいうと)画像として扱っているため、テキストの抽出が難しい場合(絵の中やグラフ内のテキストなど)でも視覚情報から単語をとらえて検索できることです。
※ 今回は、ColQwen2を使うのに「colpali-engine」というライブラリを使用しますが「Byaldi」という扱いやすいラッパーも存在します。
- 参考:
使用したPDF
今回読み込ませる資料は、「観光庁ウェブサイト」が出している以下のPDFを使用しました。
出典:「観光DX(デジタルトランスフォーメーション)の推進」(観光庁ウェブサイト)(https://www.mlit.go.jp/kankocho/seisaku_seido/kihonkeikaku/jizoku_kankochi/kanko-dx.html)
作業環境
OS: WSL2 Ubuntu22.04
GPU: GeForce RTX 2080 SUPER(8GB)
CPU: Corei9-9900KF
使用したライブラリ
PDFを画像に変換する処理を行うため「poppler」のインストールが必要です。
自分の環境(WSL2 Ubuntu22.04)では以下のコマンドでインストールしました。
$ sudo apt install poppler-utils
次にコード内で使用する、以下のライブラリをインストールします。
$ pip install pdf2image==1.17.0
$ pip install colpali-engine==0.3.2
$ pip install torch==2.4.1
$ pip install tqdm==4.66.5
$ pip install transformers==4.45.2
$ pip install Pillow==10.4.0
$ pip install flash_attn==2.6.3
インデックスの作成と保存
以下のコードでPDFをインデックス化して保存を行います。
作成したインデックスは、この後のPDFのページ検索で使用します。
コーディング(全体)
import torch
from tqdm import tqdm
from pdf2image import convert_from_path
from torch.utils.data import DataLoader
from colpali_engine.models import ColQwen2, ColQwen2Processor
# ColQwen2のリポジトリID
repo_id = "vidore/colqwen2-v0.1"
# PDFのパス
pdf_path = "./001767167.pdf"
# インデックスの保存先パス
emb_path ="./embedding.pt"
# PDFを画像に変換
images = convert_from_path(pdf_path)
# モデルの読み込み
model = ColQwen2.from_pretrained(
repo_id,
torch_dtype=torch.bfloat16,
device_map="cuda"
)
# プロセッサの読み込み
processor = ColQwen2Processor.from_pretrained(repo_id)
# データローダーの作成
dataloader = DataLoader(
images,
batch_size=2, # インデックス作成時のバッチ数(一度に処理するページ数)
shuffle=False, # PDFのページ(画像)の順序を維持
collate_fn=lambda x: processor.process_images(x)
)
# インデックスの作成
embedding = []
for batch_doc in tqdm(dataloader):
with torch.no_grad():
batch_doc = {k: v.to("cuda") for k, v in batch_doc.items()} # バッチデータをGPUに配置
embeddings_doc = model(**batch_doc) # ColQwen2モデルを使用して画像のベクトルを生成
embedding.extend(list(torch.unbind(embeddings_doc))) # 生成したベクトルをリストに追加
# インデックスを保存
torch.save(embedding, emb_path)
print(f"\n保存先のパス: {emb_path}\n")
上記の内、ポイントとなる箇所を確認します。
ポイントとなる箇所
設定パラメータ
# ColQwen2のリポジトリID
repo_id = "vidore/colqwen2-v0.1"
# PDFのパス
pdf_path = "./r4_doukou.pdf"
# インデックスの保存先パス
emb_path ="./embedding.pt"
「repo_id」については"vidore/colqwen2-v0.1"としていますが、新しいバージョンが出ることもあります。その際は以下で確認できます(他のバージョンも確認できます)。
「pdf_path」にはPDFを配置したパスを設定してください。
コードを実行後は「emb_path」に設定したパスにインデックスが保存されます。
PDFを画像に変換
# PDFを画像に変換
images = convert_from_path(pdf_path)
PDFを1ページごとに1枚の画像に変換します。例えばPDFが36ページあるとすれば36枚の画像になります。
「images」にはPDFのページ分、画像化されたリストが入ります。
ColQwen2のモデルとプロセッサの準備
# モデルの読み込み
model = ColQwen2.from_pretrained(
repo_id,
torch_dtype=torch.bfloat16,
device_map="cuda"
)
# プロセッサの読み込み
processor = ColQwen2Processor.from_pretrained(repo_id)
モデルとプロセッサの準備を行います。
「device_map="cuda"」についてはCPUの場合は"cpu"に変更するなど適宜変更してください。
データローダーの作成
# データローダーの作成
dataloader = DataLoader(
images,
batch_size=2, # インデックス作成時のバッチ数(一度に処理するページ数)
shuffle=False, # PDFのページ(画像)の順序を維持
collate_fn=lambda x: processor.process_images(x)
)
ColQwen2に読み込ませる形式に画像を変換するデータローダーを準備します。
「batch_size」は5などにすれば処理速度は上がりますが、大きすぎるとメモリ不足となるため注意してください。
「collate_fn」にはプロセッサを用いて画像の形式を変換する処理を設定します。
インデックスの作成
embedding = []
for batch_doc in tqdm(dataloader):
with torch.no_grad():
batch_doc = {k: v.to("cuda") for k, v in batch_doc.items()} # バッチデータをGPUに配置
embeddings_doc = model(**batch_doc) # ColQwen2モデルを使用して画像のベクトルを生成
embedding.extend(list(torch.unbind(embeddings_doc))) # 生成したベクトルをリストに追加
上で準備したデータローダーを用いてPDFのページ(画像)をインデックスに変換します。
tqdmを使用しているためプログレスバーが表示されます。
インデックスの保存と保存先のパスの出力
# インデックスを保存
torch.save(embedding, emb_path)
print(f"\n保存先のパス: {emb_path}\n")
作成したインデックスを「emb_path」で設定したパスに保存します。
PDFのページ(上位スコア5件)を検索
作成したインデックスを用いて検索を実行します。
クエリで検索したページをスコアの高いものから5ページ分出力します。
コーディング(全体)
import os
import torch
from pdf2image import convert_from_path
from colpali_engine.models import ColQwen2, ColQwen2Processor
# 検索クエリ
query = "あなたの知らない山形への旅"
# 上位5件の検索結果を出力
top_k = 5
# ColQwen2のリポジトリID
repo_id = "vidore/colqwen2-v0.1"
# インデックスの取得先パス
emb_path ="./embedding.pt"
# PDFのパス
pdf_path = "./001767167.pdf"
# 保存するPDFページのパス
page_dir_path = "./"
# モデルの読み込み
model = ColQwen2.from_pretrained(
repo_id,
torch_dtype=torch.bfloat16,
device_map="cuda"
)
# プロセッサの読み込み
processor = ColQwen2Processor.from_pretrained(repo_id)
# プロセッサを用いてクエリの形式を変換
processed_query = processor.process_queries([query])
# 変換したクエリをGPUに配置
processed_query = {k: v.to("cuda") for k, v in processed_query.items()}
# クエリのベクトルを作成
with torch.no_grad():
query_embedding = model(**processed_query)
# 作成したPDFのインデックスを取得
embedding = torch.load(emb_path, weights_only=True)
# クエリのベクトルとPDFのインデックスで類似度を計算
scores = processor.score_multi_vector(query_embedding, embedding)[0]
# 上位スコアのページを取得
scores_indices = scores.argsort().tolist()[-top_k:][::-1]
# PDFを画像に変換
images = convert_from_path(pdf_path)
print(f"\n検索クエリ: {query}")
print(f"\nスコア(ページ順):\n{scores}")
print(f"\n抽出したページ(スコア上位{top_k}件)")
print("-------------------------------------------------------------------")
for index in scores_indices:
# 上位スコアのページとスコアを出力
print(f"ページ: {index+1} スコア: {scores[index]}")
# ページ(画像)を取得
page_image = images[index]
# ページ(画像)を保存
page_image_path = os.path.join(page_dir_path, f"page_{index+1}.png")
page_image.save(page_image_path)
print("-------------------------------------------------------------------")
上記の内、ポイントとなる箇所を確認します。
ポイントとなる箇所
設定パラメータ
# 検索クエリ
query = "あなたの知らない山形への旅"
# 上位5件の検索結果を出力
top_k = 5
# ColQwen2のリポジトリID
repo_id = "vidore/colqwen2-v0.1"
# インデックスの取得先パス
emb_path ="./embedding.pt"
# PDFのパス
pdf_path = "./001767167.pdf"
# 保存するPDFページのパス
page_dir_path = "./"
「query」は検索クエリです。ここで設定した文にマッチするPDFのページを探します。
「top_k」は検索結果として出力するページ数です(コード上では上位5件を設定しています)。
「repo_id」にはColQwen2のリポジトリを設定します。
「emb_path」には作成したインデックスのパスを設定します。
「pdf_path」はPDFが配置してあるパスです。
「page_dir_path」には検索されたページ画像の保存先ディレクトリを設定します。
ColQwen2のモデルとプロセッサの準備
# モデルの読み込み
model = ColQwen2.from_pretrained(
repo_id,
torch_dtype=torch.bfloat16,
device_map="cuda"
)
# プロセッサの読み込み
processor = ColQwen2Processor.from_pretrained(repo_id)
モデルとプロセッサの準備を行います。
「device_map="cuda"」についてはCPUの場合は"cpu"に変更するなど適宜変更してください。
クエリの前処理
# プロセッサを用いてクエリの形式を変換
processed_query = processor.process_queries([query])
# 変換したクエリをGPUに配置
processed_query = {k: v.to("cuda") for k, v in processed_query.items()}
クエリの形式をColQwen2の入力に適した形式に変換してGPUに配置します。
クエリのベクトルを作成
# クエリのベクトルを作成
with torch.no_grad():
query_embedding = model(**processed_query)
ColQwen2にクエリを渡してベクトルに変換します。
作成したインデックスを読み込んで取得
# 作成したPDFのインデックスを取得
embedding = torch.load(emb_path, weights_only=True)
先ほど作成したインデックスを読み込んで取得します。
スコアを計算して上位スコア5件を取得
# クエリのベクトルとPDFのインデックスで類似度を計算
scores = processor.score_multi_vector(query_embedding, embedding)[0]
# 上位スコアのページを取得
scores_indices = scores.argsort().tolist()[-top_k:][::-1]
"score_multi_vector"関数にクエリのベクトルとPDF(画像)のインデックスを渡すことでスコアを出力することができます。
"scores.argsort().tolist()[-top_k:][::-1]"で「top_k」に設定した件数分、上位スコアのページを抽出します。
PDFを画像に変換
# PDFを画像に変換
images = convert_from_path(pdf_path)
PDFを1ページごとに1枚の画像に変換します。
「images」にはPDFのページ分、画像化されたリストが入ります。
スコアとページの出力
print(f"\n検索クエリ: {query}")
print(f"\nスコア(ページ順):\n{scores}")
print(f"\n抽出したページ(スコア上位{top_k}件)")
print("-------------------------------------------------------------------")
for index in scores_indices:
# 上位スコアのページとスコアを出力
print(f"ページ: {index+1} スコア: {scores[index]}")
# ページ(画像)を取得
page_image = images[index]
# ページ(画像)を保存
page_image_path = os.path.join(page_dir_path, f"page_{index+1}.png")
page_image.save(page_image_path)
print("-------------------------------------------------------------------")
検索クエリ、スコア(ページ順)、抽出したページ(スコア上位{top_k}件)を出力します。
また、「page_dir_path」で設定したパスにページの画像(スコア上位{top_k}件)が保存されます。
実行結果
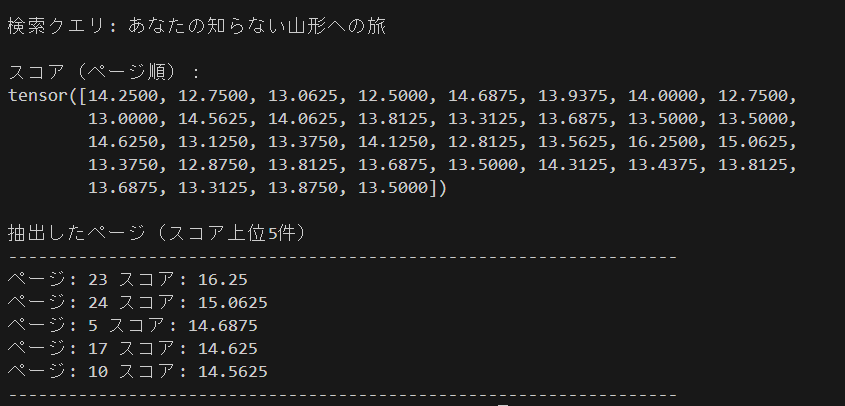
実行結果より一番スコアの高いページは23ページ目であることがわかります。
コードを実行するとページが保存されるため確認してみます。
- 23ページ目 スコア 16.25

上記、左下画像内の「あなたの知らない山形への旅~」がクエリの「あなたの知らない山形への旅」と一致しています。画像内のテキスト(背景あり)でも問題なく検索出来ているようです。
※ PDF右下のページ数には22と記載されていますが表紙がカウントされていないため、実際の枚数としては23ページ目となります。
スコア2位の24ページには山形の情報が記載されています。3位の5ページには各地方での実証事業の概要が記載されており、その中に山形の項目が確認できます。
4位の17ページと5位の10ページはどちらも「旅」の文字(やそれに関連した情報)はありますが、クエリとはあまり関係がありません(山形の情報は載っていません)。
PDFのページ(フィルタリングしてスコア0.6以上)を検索
先ほどは単純に上位スコアの5件を取得しましたが検索ページをRAGのコンテキストとして用いる場合などは、余分な情報(先ほどの場合だと4位と5位のページ)が混ざってしまうことが多いです。
今回はそのような検索結果と関係ないページの取得を抑えるために正規化(Min-Max法)してフィルタリングを行います。
上位スコア3件としてもいいですが、正規化を用いることでスコアに閾値を用いてフィルタリングできるため、件数に縛られずスコアの分布に応じて重要なページを抽出できます。
正規化(Min-Max法)について
今回は単純なMin-Max法を使った正規化です。
Min-Max正規化は、全データのスコアを最小値0から最大値1の範囲に変換します。
- 数式は以下のようになります。
スコアの計算に当てはめると以下のようになります。
正規化されたスコア = (元のスコア - スコアの最小値) / (スコアの最大値 - スコアの最小値)
上記で正規化されたスコアのリストに対して閾値(今回は0.6以上)でフィルターをかけて検索結果を抽出します。
コーディング(全体)
import os
import torch
from pdf2image import convert_from_path
from colpali_engine.models import ColQwen2, ColQwen2Processor
# 検索クエリ
query = "あなたの知らない山形への旅"
# スコアの閾値
threshold = 0.6
# ColQwen2のリポジトリID
repo_id = "vidore/colqwen2-v0.1"
# インデックスの取得先パス
emb_path ="./embedding.pt"
# PDFのパス
pdf_path = "./001767167.pdf"
# 保存するPDFページのパス
page_dir_path = "./"
# モデルの読み込み
model = ColQwen2.from_pretrained(
repo_id,
torch_dtype=torch.bfloat16,
device_map="cuda"
)
# プロセッサの読み込み
processor = ColQwen2Processor.from_pretrained(repo_id)
# プロセッサを用いてクエリの形式を変換
processed_query = processor.process_queries([query])
# 変換したクエリをGPUに配置
processed_query = {k: v.to("cuda") for k, v in processed_query.items()}
# クエリのベクトルを作成
with torch.no_grad():
query_embedding = model(**processed_query)
# 作成したPDFのインデックスを取得
embedding = torch.load(emb_path, weights_only=True)
# クエリのベクトルとPDFのインデックスで類似度を計算
scores = processor.score_multi_vector(query_embedding, embedding)[0]
# スコアを正規化(0から1の範囲に変換)
normalized_scores = (scores - scores.min()) / (scores.max() - scores.min())
# 閾値以上のスコアとそのインデックスを抽出
filter = normalized_scores >= threshold
# データのフィルタリングを実行
filtered_scores_indices = torch.nonzero(filter).squeeze().tolist()
# フィルタリング後のスコアが一つしかない場合のエラー回避用
if isinstance(filtered_scores_indices, int):
filtered_scores_indices = [filtered_scores_indices]
# PDFを画像に変換
images = convert_from_path(pdf_path)
print(f"\n検索クエリ: {query}")
print(f"\n正規化スコア(ページ順):\n{normalized_scores}")
print(f"\n抽出したページ(スコア{threshold}以上)")
print("-------------------------------------------------------------------")
for index in filtered_scores_indices:
# 上位スコアのページとスコアを出力
print(f"ページ: {index+1} スコア: {normalized_scores[index]:.3f}")
# ページ(画像)を取得
page_image = images[index]
# ページ(画像)を保存
page_image_path = os.path.join(page_dir_path, f"page_{index+1}.png")
page_image.save(page_image_path)
print("-------------------------------------------------------------------")
上記の内、ポイントとなる箇所を確認します。
ポイントとなる箇所
設定パラメータ
# スコアの閾値
threshold = 0.6
先ほどは「top_k = 5」でしたが、今回はフィルタリングするための閾値「threshold = 0.6」をパラメータに設定しています。
スコアを正規化してフィルタリング
# スコアを正規化(0から1の範囲に変換)
normalized_scores = (scores - scores.min()) / (scores.max() - scores.min())
スコアを正規化してすべてのデータ(テンソル)を0~1にの範囲に変換します。
tensor([14.3125, 13.0625, 13.3125, 12.7500, 14.8125, 14.0625, 14.2500, 12.9375,
13.2500, 14.6250, 14.3125, 13.9375, 13.6250, 13.8750, 13.7500, 13.6250,
14.6250, 13.3125, 13.5625, 14.2500, 13.0625, 13.8750, 16.2500, 15.1250,
13.6250, 13.0000, 14.0000, 14.0000, 13.6250, 14.3750, 13.7500, 13.9375,
14.0625, 13.5625, 14.1250, 13.5625])
↓正規化
tensor([0.4464, 0.0893, 0.1607, 0.0000, 0.5893, 0.3750, 0.4286, 0.0536, 0.1429,
0.5357, 0.4464, 0.3393, 0.2500, 0.3214, 0.2857, 0.2500, 0.5357, 0.1607,
0.2321, 0.4286, 0.0893, 0.3214, 1.0000, 0.6786, 0.2500, 0.0714, 0.3571,
0.3571, 0.2500, 0.4643, 0.2857, 0.3393, 0.3750, 0.2321, 0.3929, 0.2321])
フィルタリングを実行
# 閾値以上のスコアとそのインデックスを抽出
filter = normalized_scores >= threshold
# データのフィルタリングを実行
filtered_scores_indices = torch.nonzero(filter).squeeze().tolist()
# フィルタリング後のスコアが一つしかない場合のエラー回避用
if isinstance(filtered_scores_indices, int):
filtered_scores_indices = [filtered_scores_indices]
正規化したスコアを閾値(0.6)でフィルタリングします。
フィルタリング後のスコアが一つしかない場合は(int型になるため)for文で回す際にエラーになってまいます。そのため、int型の場合はリストに変換する処理を行っています。
スコアとページの出力
print(f"\n検索クエリ: {query}")
print(f"\n正規化スコア(ページ順):\n{normalized_scores}")
print(f"\n抽出したページ(スコア{threshold}以上)")
print("-------------------------------------------------------------------")
for index in filtered_scores_indices:
# 上位スコアのページとスコアを出力
print(f"ページ: {index+1} スコア: {normalized_scores[index]:.3f}")
# ページ(画像)を取得
page_image = images[index]
# ページ(画像)を保存
page_image_path = os.path.join(page_dir_path, f"page_{index+1}.png")
page_image.save(page_image_path)
print("-------------------------------------------------------------------")
検索クエリ、正規化スコア(ページ順)、抽出したページ(スコア{threshold}以上)を出力します。
また、「page_dir_path」で設定したパスにページの画像(スコア{threshold}以上)が保存されます
実行結果
- 検索クエリ「あなたの知らない山形への旅」
- 閾値(threshold)0.6
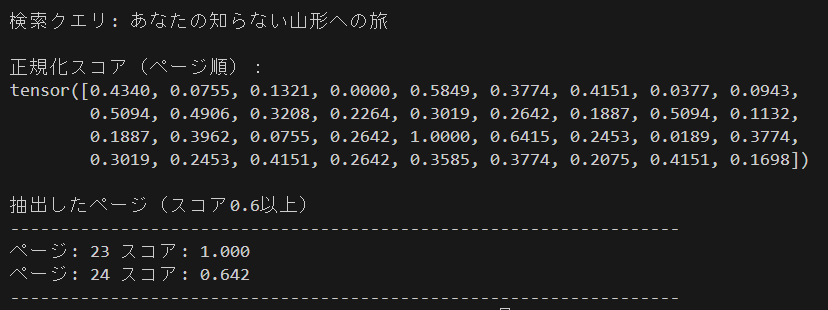
正規化されたスコアの中で0.6以上の23ページ(スコア1.000)と24ページ(スコア0.642)が抽出されているのが確認できます。
閾値(threshold)を0.5など低い値にしていくことで(関係性の薄いページも増えますが)より幅広い範囲でデータ(ページ)を抽出することもできます。
もし、スコアが最大値のデータのみを抽出したい場合は、閾値(threshold)を1.0とすることで抽出できます(データの中で必ず最大値1.0と最小値0.0が存在するため)。
次に検索クエリと閾値を変えて試してみます。
- 検索クエリ「観光DXはどのように推進すればよいのか」
- 閾値(threshold)0.9
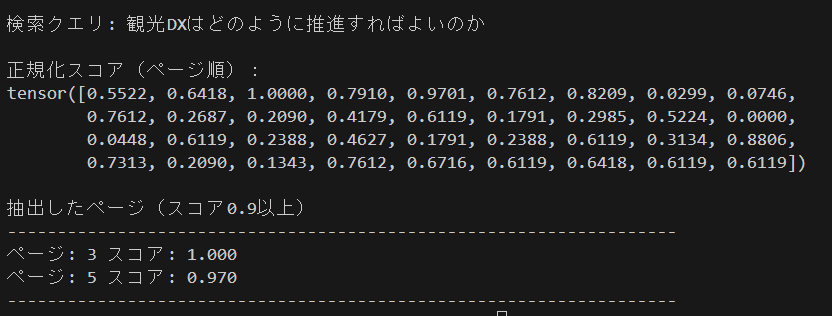
- 3ページ目 スコア 1.000

3ページ目には観光DXの概要が記載されており、本PDFにて観光DX推進のための実証事業などのノウハウ集をまとめている旨が確認できます。
- 5ページ目 スコア 0.970
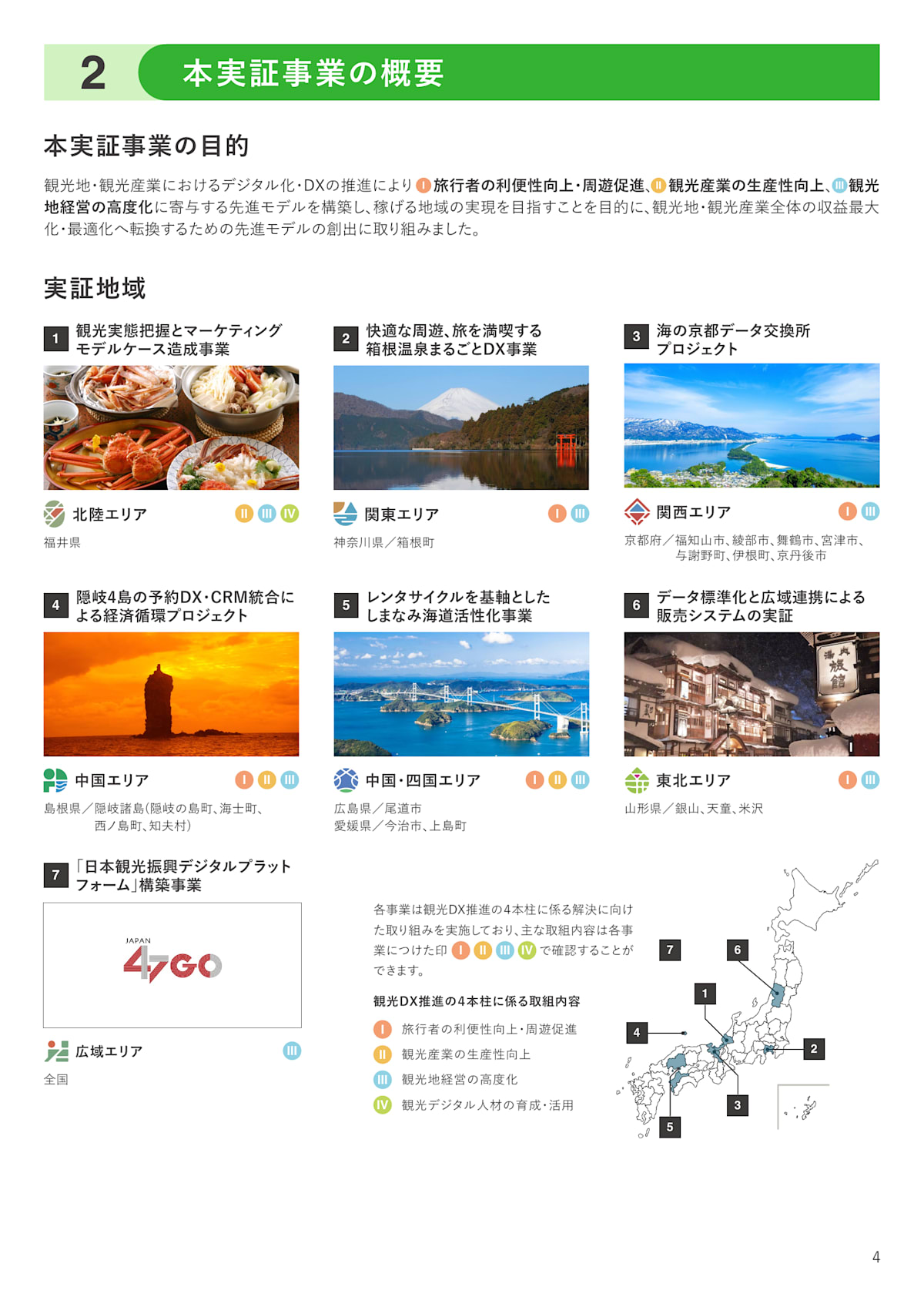
5ページ目には、各地方におけるDX推進の実証事業が記載されています。
検索クエリ「観光DXはどのように推進すればよいのか」に対しての検索結果(参考ページ)としてはよさそうです。
- 検索クエリ「箱根DMO観光診断書」
- 閾値(threshold)1.0
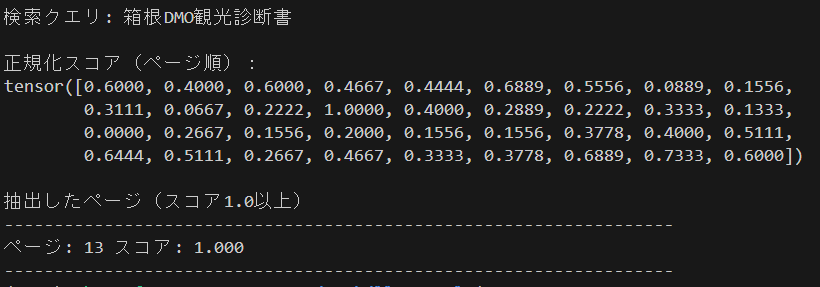
- 13ページ目 スコア 1.000

ページ内の上画像に「箱根DMO観光診断書 国内版」の記載されているのが確認できます。いい感じに検索出来てそうです。
PDFのページを検索後、Qwen2-VLでQ&Aを実行
次にColQwen2で検索したページに対してQwen2-VL-2B-InstructでQ&Aを試してみます。
処理としては、クエリとColQwen2で検索されたページ(画像)をQwen2-VL-2B-Instructに渡すことで回答を出力する流れになります(ColQwen2による検索とQwen2-VL-2B-Instructによる画像を入力とした応答を連結します)。
Qwen2-VLとは
Qwen2-VLは「Alibaba Cloud」がリリースした視覚言語モデルです。多言語をサポートしており日本語にも対応しています。
今回は2Bの指示モデル「Qwen2-VL-2B-Instruct」を使用します。
コーディング(全体)
import os
import torch
from pdf2image import convert_from_path
from colpali_engine.models import ColQwen2, ColQwen2Processor
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
# 検索クエリ
query = "山形ではデータ連携基盤の整備はどのように行いましたか?"
# 上位5件の検索結果を出力
top_k = 1
# ColQwen2のリポジトリID
repo_id = "vidore/colqwen2-v0.1"
# インデックスの取得先パス
emb_path ="./embedding.pt"
# PDFのパス
pdf_path = "./001767167.pdf"
# 保存するPDFページのパス
page_dir_path = "./"
# モデルの読み込み
model = ColQwen2.from_pretrained(
repo_id,
torch_dtype=torch.bfloat16,
device_map="cuda"
)
# プロセッサの読み込み
processor = ColQwen2Processor.from_pretrained(repo_id)
# プロセッサを用いてクエリの形式を変換
processed_query = processor.process_queries([query])
# 変換したクエリをGPUに配置
processed_query = {k: v.to("cuda") for k, v in processed_query.items()}
# クエリのベクトルを作成
with torch.no_grad():
query_embedding = model(**processed_query)
# 作成したPDFのインデックスを取得
embedding = torch.load(emb_path, weights_only=True)
# クエリのベクトルとPDFのインデックスで類似度を計算
scores = processor.score_multi_vector(query_embedding, embedding)[0]
# 上位スコアのページを取得
scores_indices = scores.argsort().tolist()[-top_k:][::-1]
# PDFを画像に変換
images = convert_from_path(pdf_path)
print(f"\n検索クエリ: {query}")
print(f"\nスコア(ページ順):\n{scores}")
print(f"\n抽出したページ(スコア上位{top_k}件)")
print("-------------------------------------------------------------------")
for index in scores_indices:
# 上位スコアのページとスコアを出力
print(f"ページ: {index+1} スコア: {scores[index]}")
# ページ(画像)を取得
page_image = images[index]
# ページ(画像)を保存
page_image_path = os.path.join(page_dir_path, f"page_{index+1}.png")
page_image.save(page_image_path)
print("-------------------------------------------------------------------")
# ColQwen2モデルとプロセッサをメモリから削除
del model
del processor
torch.cuda.empty_cache()
# Qwen2-VL-2B-InstructのリポジトリID
repo_id = "Qwen/Qwen2-VL-2B-Instruct"
# モデルの読み込み
model = Qwen2VLForConditionalGeneration.from_pretrained(
repo_id,
torch_dtype=torch.float16,
device_map="cuda",
)
# プロセッサの読み込み
processor = AutoProcessor.from_pretrained(
repo_id,
min_pixels=256 * 28 * 28,
max_pixels=1024 * 28 * 28,
)
# タスクの指示文
text = """画像から読み取れる情報を元に以下の質問に対してわかりやすく回答してください。
質問: {query}
""".format(query=query)
# メッセージの準備
messages = [
{
"role": "user",
"content": [
{
"type": "image",
},
{"type": "text", "text": text},
],
}
]
# プロンプトの作成
text_prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
# 入力の準備
inputs = processor(
text=[text_prompt],
images=[page_image],
padding=True,
return_tensors="pt"
).to("cuda")
# 推論の実行
output_ids = model.generate(
**inputs,
max_new_tokens=1024
)
# 生成された出力から回答を抽出
generated_ids = [
output_ids[len(input_ids) :]
for input_ids, output_ids in zip(inputs.input_ids, output_ids)
]
# 出力テンソルをテキストにデコード
response = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=True
)[0]
print(f"\n回答: {response}")
※ 今回は上位スコア1件のページ(画像)をQwen2-VL-2B-Instructに渡して処理するようにしています(自分の環境ではメモリの都合上、複数枚の画像を処理するのが難しいため・・・)。
複数枚の処理に対応させる場合は、コード内の以下の部分を変更することで処理できるかと思います。
- messages内の「"type": "image"」を画像の枚数分追加
messages = [
{
"role": "user",
"content": [
{
"type": "image",
},
{"type": "text", "text": text},
],
}
]
↓変更(画像3枚の場合)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
},
{
"type": "image", # 追加
},
{
"type": "image", # 追加
},
{"type": "text", "text": text},
],
}
]
- プロセッサの「images」に画像を追加
# 入力の準備
inputs = processor(
text=[text_prompt],
images=[page_image],
padding=True,
return_tensors="pt"
).to("cuda")
↓変更(画像3枚の場合)
# 入力の準備
inputs = processor(
text=[text_prompt],
images=[page_image1, page_image2, page_image3], # 画像を追加
padding=True,
return_tensors="pt"
).to("cuda")
参考:
次にコーディング(全体)の中からポイントとなる箇所を確認します
ポイントとなる箇所
ColQwen2モデルとプロセッサをメモリから削除
# ColQwen2モデルとプロセッサをメモリから削除
del model
del processor
torch.cuda.empty_cache()
(自分の環境では)そのままQwen2-VLを読み込むとメモリ不足になってしまったため、ColQwen2のモデルとプロセッサを(この後の処理では使わないため)メモリから削除しました。
Qwen2-VL-2B-Instructのモデルとプロセッサの読み込み
# モデルの読み込み
model = Qwen2VLForConditionalGeneration.from_pretrained(
repo_id,
torch_dtype=torch.float16,
device_map="cuda",
)
# プロセッサの読み込み
processor = AutoProcessor.from_pretrained(
repo_id,
min_pixels=256 * 28 * 28,
max_pixels=1024 * 28 * 28,
)
モデルとプロセッサの準備を行います。
プロセッサに「min_pixels」と「max_pixels」を設定することで画像がその範囲に収まるようにリサイズされます。
サイズが大きいとそれだけメモリの消費量が大きくなるため、(特に「max_pixels」には)適切な値を設定することをお勧めします。
参考:
プロンプトの作成
# タスクの指示文
text = """画像から読み取れる情報を元に以下の質問に対してわかりやすく回答してください。
質問: {query}
""".format(query=query)
# メッセージの準備
messages = [
{
"role": "user",
"content": [
{
"type": "image",
},
{"type": "text", "text": text},
],
}
]
# プロンプトの作成
text_prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
Qwen2-VL-2B-Instructに渡すプロンプトを作成します。
今回、タスクの指示文は単純なものを設定しています。うまくいかない場合は状況(PDFの内容など)に応じて適切に書き換えることで改善するかもしれません。
プロンプトと画像を渡して推論を実行
# 入力の準備
inputs = processor(
text=[text_prompt],
images=[page_image],
padding=True,
return_tensors="pt"
).to("cuda")
# 推論の実行
output_ids = model.generate(
**inputs,
max_new_tokens=1024
)
Qwen2-VL-2B-Instructに先ほど設定したプロンプトと検索されたページ(画像)を渡して推論を実行します。
推論結果から回答を抽出して出力
# 生成された出力から回答を抽出
generated_ids = [
output_ids[len(input_ids) :]
for input_ids, output_ids in zip(inputs.input_ids, output_ids)
]
# トークンIDを文字列に変換
response = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=True
)[0]
print(f"\n回答: {response}")
推論結果から生成された部分のみを抽出後、トークンID(テンソル)から文字列に変換して出力します。
実行結果
-
検索クエリ「山形ではデータ連携基盤の整備はどのように行いましたか?」
-
回答: 山形では、従来は銀山・天童・米沢の各地域において入湯税ベースでの入込客数しか把握できており、それ以外の地域のデータは把握できていなかった。本事業で、3つの地域の宿泊施設のPMSを連携させた地域PMSを構築したことで、属性データ等が統一されたフォーマットで収集できるようになり、実態を簡単にかつ正確に把握できるようになりました。
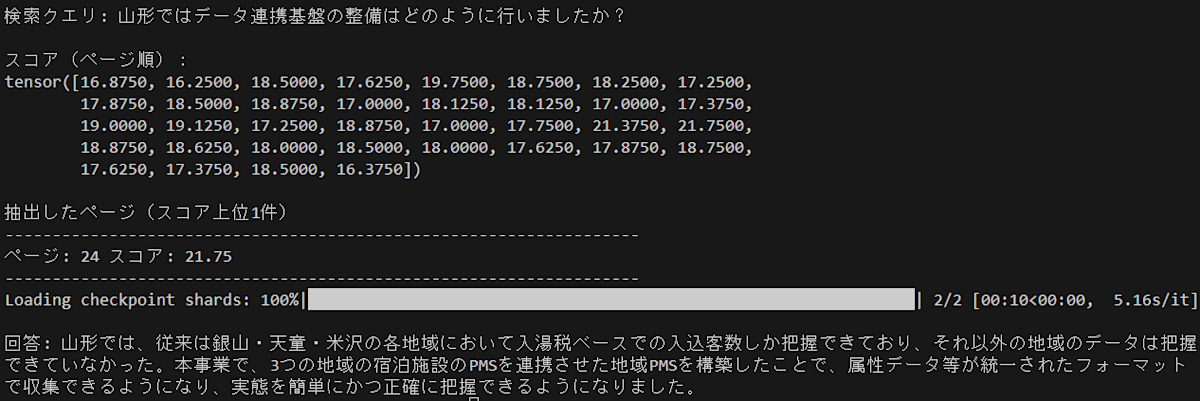
-
24ページ目 スコア 21.75

24ページ目の下方にある「実証内容2」の文章(ほぼそのままですが)で正しく説明されています。
-
検索クエリ「デジタルマップはどのように活用されていますか?」
-
回答: デジタルマップは、旅行者に対して渋滞予測や駐車場の満空状況、飲食店の混雑状況等の情報を提供し、周遊ルートの案内を通じて、需要の分散・平準化や地域の周遊促進に向けて行動変容を促し、消費の拡大を目指す。
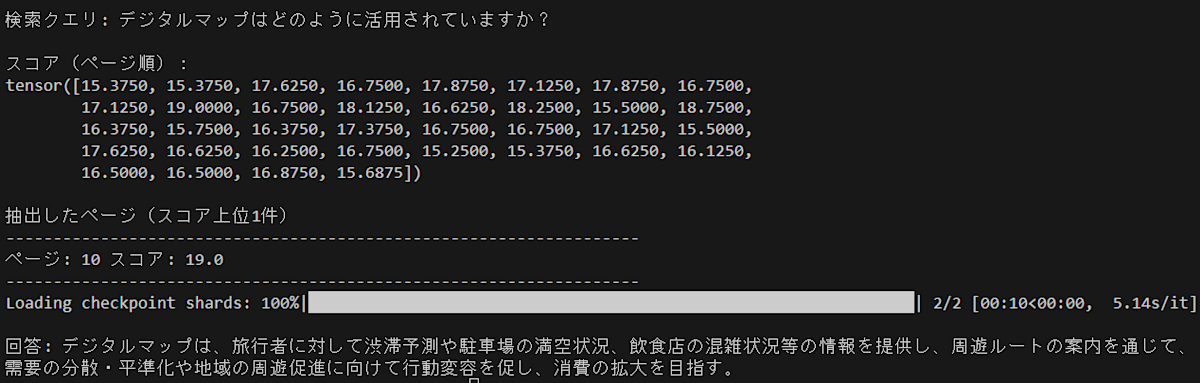
-
10ページ目 スコア 19.0
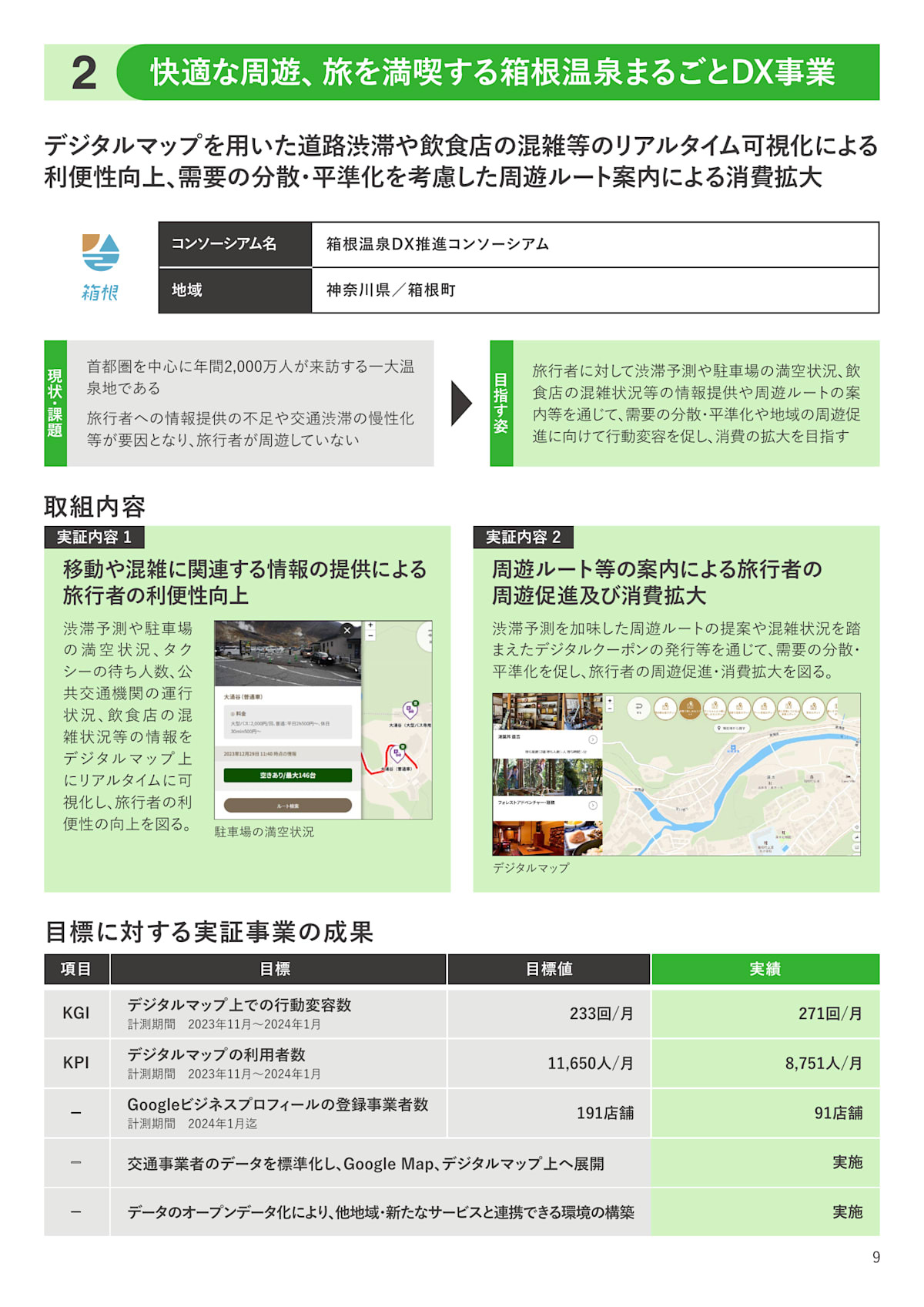
10ページ目の「実証内容1」、「実証内容2」の内容からうまく要約して回答されており問題なさそうです。
※ 今回は1ページ分の内容からしか回答しないため、複数のページを横断する質問には対応できません・・・。対応させる場合は複数ページをQwen2-VLに渡すか、1ページずつ渡して最後に回答をまとめるなどの方法が考えられます。
おわりに
ColQwen2は、英語のみの学習ということでしたが日本語PDFもいい感じに検索出来ました(日本語性能を上げたい場合は追加で学習させることもできます)。日本語PDFの検索はテキスト抽出が難しい場合も多いため、需要が高そうです。
Qwen2-VLに関しては2Bの一番小さいものを使いましたが、それでもページの簡単な質問や要約であれば問題なさそうです。より精度が必要な場合は、(メモリ使用量は増加しますが)7B以上に変更して試すこともできます。
今回、4スクリプト分のコードがあるため長くなりましたが、一つ一つのコードは短めなため試しやすいかとは思います・・・。ご興味あればお試しください。
また機会があればよろしくお願いします。
参考
-
ColQwen2の学習データは英語のみです。
日本語性能をさらに上げたい場合は、以下のkun432さんがまとめてくださったリンクを参考に日本語データを用いた学習を試すことができます。
https://x.com/kun432/status/1843693682068963554 ↩︎
Discussion