導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、LLMを使用したチャットのサービスを提供しており、とりわけRAGシステムの改善は日々の課題になっています。
本記事では、画像の情報をそのままベクトルデータにして検索する手法、ColPaliについて解説します。
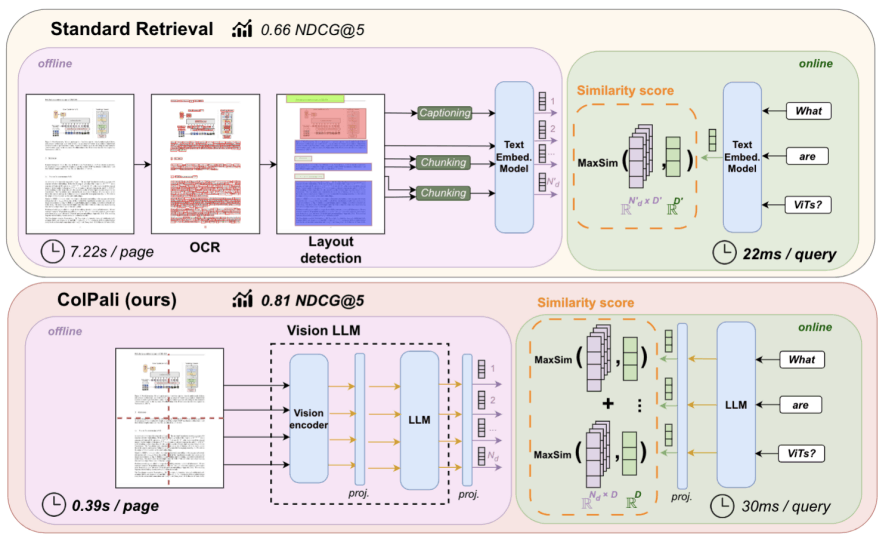
サマリー
通常、RAGでは文書データからテキストを抽出して、その文字をベクトルデータに変換します。しかしColPaliは、文書データを画像として認識してベクトル化を行います。画像として保管することでテキスト化できない情報を扱うことができます。他にもベクトルを複数に分解することで精度を改善し、テキストの抽出が必要ないことからデータ保管時のコストの大幅な低減などのメリットを享受できます。
PDFのデータを保管する際には、ColPaliモデルに正規化したPDF画像を入力として渡し1024個の128次元ベクトルを生成します。検索時には、クエリごとにColPaliモデルのテキストエンコーダーに入力し、類似度の合計値の高いPDFのページデータを取得します。
問題意識
PDFのRAG利用の難しさ
一般的なRAGでは、文書内のテキストデータを細かい単位で切り分けてベクトルデータベースに保管されます。PDFの場合ファイルからテキストデータを抜き出す必要があるのですが、実はこの工程がかなり難しいタスクで、精度を出すためにもかなりの計算時間を要します。これはPDFファイルのデータの保持の方法に起因するため、改善の難しいものとなっています。
手法
ColPaliは、画像データを1024個のパッチに分割しそれぞれをメタデータと結びつけた状態でベクトルデータベースに保管します。検索の際にはテキストをトークン化し、それぞれのColPaliのテキストエンコーダに入力。そしてベクトルデータの類似度を元に検索し、合計点が最も高い画像を順に取得します。
これらの手順の詳細は以下のようになります。
事前準備
ColPaliでは独自のEmbedingモデルを使用します。PaliGemma-3Bモデルをベースに、1024個の128次元ベクトルデータを出力するように調整しています。このモデルは公開されており、ここからさらなるファインチューニングを行っても精度として大きな変化はないと言及されています。
保存方法
- PDFの各ページごとに画像に変換
- PDFを入力サイズに合わせてリサイズ
- ColPaliモデルを使用して、ページごとに1024個の128次元ベクトルに変換
- すべてのベクトルデータをPDF本体とページ番号のメタデータと結びつけて保存
検索方法
- 検索クエリ用の文字列をトークンに変換
- ColPaliモデルのテキストエンコード機能を利用して、ベクトルデータをトークンごとに作成
- ColBertを使用してトークンごとに類似度の高いベクトルを検索、ページ単位でスコアを集計
- スコアの高い順にPDFのページを並び替える
成果
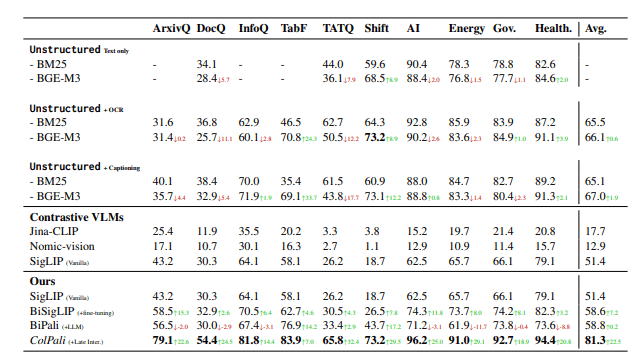
- ArxivQ DocQ InfoQ TabF TATQなどの既存のベンチマーク手法すべてで、従来手法以上の成果
- Shift AI Energy Gov. Healthなどの独自に作成した、より現実のタスクに即したベンチマーク手法であっても従来手法以上の成果

- Embeddingの保存サイズは従来の手法と比較して圧倒的に容量が大きい
- 最適化の余地があり最終的には数倍程度の差に収まるとしている
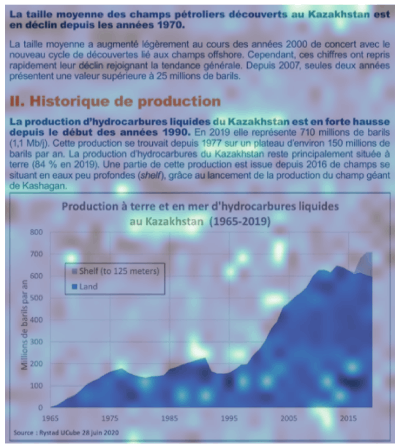
- パッチ情報との類似度を元に画像内のどの場所に着目したかを可視化できる
まとめ
ColPaliは、PDFの検索に焦点を当てていましたが、実際には画像全般に応用が利くので非常に使いやすい手法かなと思います。加えてベクトル化するスピードも非常に早く、これはPDFをRAGで利用するための既存の手法と比較すると大きなアドバンテージかと思います。
また個人的に特に面白いと感じたのは、一つのページを1024個のベクトルデータに分解するという点です。通常テキストデータをベクトル化する際には、一つのチャンクに対して一つのベクトルデータを割り当てます。Embeddingモデルもその想定で学習を進めているので基本的にそれで問題なく精度が出せると思います。一方でクエリのコンテキストごとに、テキストデータの持つ意味というのはすこしずつ変わって来るはずなので、本当に最適化するのであればそういった想定も必要なのではと考えていました。そういった点で、一つの画像を1024個のベクトルデータに変換しそれぞれが別々の意味を持つというのは応用が利きそうな考え方に感じます。
話をColPaliに戻して、この手法で気になった点としてはEmbeddingを用いた検索の一般的な弱点である、固有の単語に弱いという問題が解消しづらいことです。ただしこの点は、PDFの解析時に構造を把握せず単語だけ把握すれば良くなった、と捉えてBM25等の手法とハイブリッド検索することで弱点を補えるのではと考えています。
PDFをRAGで使ってもなかなか成果が出ない。PDFのデータ保存に時間がかかって困っている。という方は一度利用を検討してみても良いのかなと思います。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion