LlamaParseを試してみる
今更ながらLlamaIndexのドキュメントパース用クラウドサービス、LlamaParseを試してみる。
ドキュメント
LlamaParseはLlamaCloudのコンポーネントで、PDFを構造化データにパースすることができる。スタンドアロンのREST API、Pythonパッケージ、ウェブUIとして提供されている。現在パブリックベータ中で、サインアップして試すか、オンボーディングドキュメントを読むことができる。
概要
LlamaIndexが提供する世界最高のドキュメント解析サービス、LlamaParseへようこそ。 LlamaParseはLlamaCloudのコンポーネントで、PDF、パワーポイント、Wordドキュメント、スプレッドシートなどの複雑なドキュメントを構造化されたデータに解析することができます。 スタンドアロンのREST API、Pythonパッケージ、TypeScript SDK、Web UIとして提供されています。 サインアップして試したり、オンボーディングドキュメントを読むことができます。
なぜLlamaParseなのか?
LlamaIndexでは、あなたのデータをLLMにつなげることを使命としています。 お客様のデータをLLMに提示する際に重要なのは、そのデータがモデルによって容易に理解されることです。 私たちの実験によると、高品質な構文解析は生成AIアプリケーションの結果に大きな違いをもたらします。 そこで私たちは、LlamaParseに文書構文解析の専門知識をすべて集約し、LLMのためにデータを可能な限り最適な形に簡単に変換できるようにしました。
クイックスタート
ウェブUIを使用する
LlamaParseを試す一番早い方法は、ウェブUIを使うことです。 PDF、PowerPoint、Word文書、スプレッドシートをLlamaCloudにドラッグ&ドロップするだけで、結果をリアルタイムで見ることができます。 これは、あなたのコードに統合する前に、LlamaParseで何ができるかを知るのに最適です。
APIキーを取得する
コーディングを始める準備ができたら、APIキーを取得して、LlamaParseをPython、TypeScript、またはスタンドアロンのREST APIとして使用してください。
ライブラリを利用する
PythonとTypeScript用のライブラリを用意しています。 まずはPythonクイックスタートまたはTypeScriptクイックスタートをチェックしてください。
REST APIを使用する
異なる言語を使用している場合は、LlamaParse REST APIを使用してドキュメントを解析することができます。
あとLlamaCloudというものがある。LlamaParseはLlamaCloudの一部、という位置づけになる模様。
LlamaCloudは現在プレビュー中です。アクセスするにはこちらのウェイティングリストにサインアップしてください。
概要
LlamaCloudを使用すると、RAGのユースケースに対応したカスタマイズ可能なデータ取り込みパイプラインを簡単にセットアップすることができます。 スケーリング、ドキュメント管理、複雑なファイル解析などの問題を心配する必要はありません。
LlamaCloudは、コードなしのUI、REST API/クライアント、そして人気のあるpython & typescriptフレームワークとのシームレスな統合を通じて、これらすべてを提供します。
LlamaCloud上のインデックスをデータソースに接続し、解析パラメータと埋め込みモデルを設定すると、LlamaCloudは自動的にベクトルデータベースへのデータの同期を処理します。 そこから、私たちは、あなたのインデックスを照会し、あなたの入力文書から関連するグランドトゥルース情報を取得するための使いやすいインターフェイスを提供します。
クイックスタートガイドでUIからインデックスを設定し、RAG/エージェントアプリケーションと統合してください。
料金
- 無料プラン
- 1日あたり1000ページまで
- 有料プラン
- 1週あたり7000ページまで
- それ以上は1ページあたり$0.003
有料プランは月額みたいなのが見当たらないのだけど、書いてあることがそのままだとすると、無料・有料の差はほとんどなくて、上限を超えるような使い方をしなければ、違いが出ないような感があるけども、果たして。。。。
Getting Startedに従ってやってみる。WebUIとPython SDK(colaboratory上)で試してみようと思う。
なお、パースに使用するドキュメントについては、農林水産省公式サイト内で、畜産・競馬に関する各種PDFが公開されている。これらの中から 「馬産地をめぐる情勢(令和6年6月)」 というPDFを使わせていただく。
Web UI
LlamaParseにログインして、左上のParseをクリック。
以下のような画面が出てくるので、ここで設定してファイルをアップロードすればいいだけっぽい。
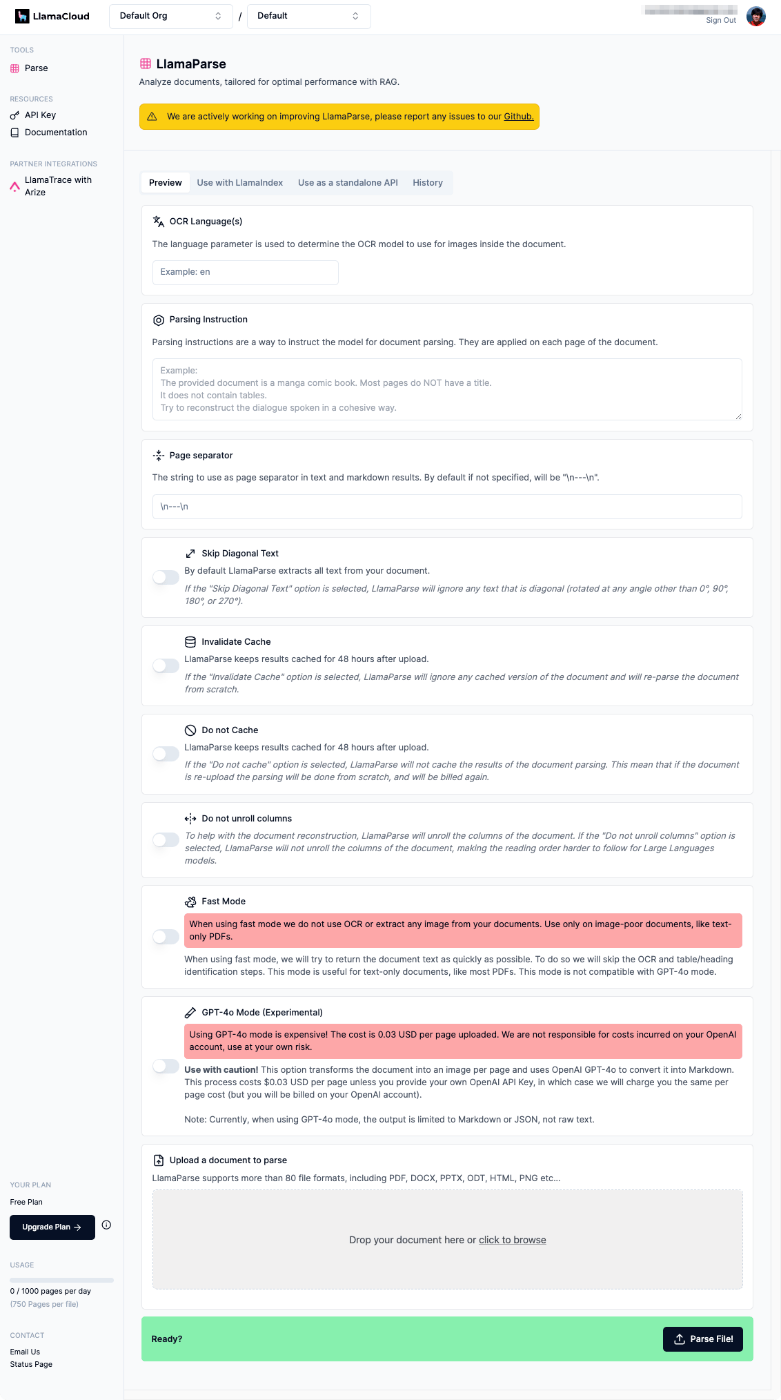
各設定項目を見ていく。
-
OCR Language(s)
- ドキュメントをOCRする際の言語を設定する。
- 複数選択も可能。
- 今回は
jaを指定。
-
Parsing Instruction
- ドキュメントをパースする際の「プロンプト」を設定する。モデルはこれに従ってパースを行う。
- 例で書かれているのは以下のような内容
The provided document is a manga comic book. Most pages do NOT have a title. It does not contain tables. Try to reconstruct the dialogue spoken in a cohesive way.- 日本語訳:
提供された文書はマンガ本である。ほとんどのページにはタイトルがなく、表もない。まとまりのある話し方をする台詞を再構成するようにしなさい。
- 今回は以下とした。果たしてここで日本語が使えるのか?も含めて試してみる。
提供された文書はスライドである。1ページにはファイルのタイトル、2ページは目次となっており、それ以降のページは各ページごとの副題を持つ。資料は、テキスト、図、表、グラフ、イラストを含む。
-
Page Separator
- 結果はテキストまたはMarkdownで出力される様子。その際に各ページ間の区切り文字列を指定する。
- 今回はデフォルトのまま
\n---\n
-
Skip Diagonal Text
- デフォルトではLlamaParseはドキュメントからすべてのテキストを抽出する。
- この設定を有効にすると、斜めになっている(0°、90°、180°、270°以外の角度で回転している)テキストをスキップする。
- 今回はデフォルトのまま
無効
-
Invalidate Cache
- デフォルトではパース結果はアップロード後48時間キャッシュとして保持される。
- この設定を有効にすると、キャッシュを無視して常に再パースする。
- あとで色々試すつもりなので今回は
有効にした
-
Do not Cache
- デフォルトではパース結果はアップロード後48時間キャッシュとして保持される。
- この設定を有効にすると、パース結果をキャッシュしない。
- つまり、再アップロード時に再度パースされ再度課金されることになる。
- Invalidate Cacheとの違いがいまいちわからない・・・
- あとで色々試すつもりなので今回は
有効にした
-
Do not unroll columns
- 文書を再構成しやすくするために文書中の列を展開する。
- この設定を有効にすると、列を展開しない。
- 今回はデフォルトのまま
無効
-
Fast Mode
- 高速モードを使用すると以下がスキップされる。
- OCR
- 画像やイメージの抽出
- 表・見出しの認識
- テキストのみの文書に有用
- GPT-4oモードとは互換性なし
- 今回はデフォルトのまま
無効
- 高速モードを使用すると以下がスキップされる。
-
GPT-4o Mode (Experimental)
- ドキュメントをページごとに画像に変換し、OpenAI GPT-4oを使ってMarkdownに変換する。
- 注意
- 1ページあたり$0.03コストが発生する
- OpenAIのAPIキーを持ち込むことも可能、その場合はOpenAIアカウント側で請求される
- 今回はデフォルトのまま
無効
ではPDFファイルをアップロードして、パースさせてみる。
しばらく待つと以下のように結果が下に出力される。USAGEが減っているのもわかる。
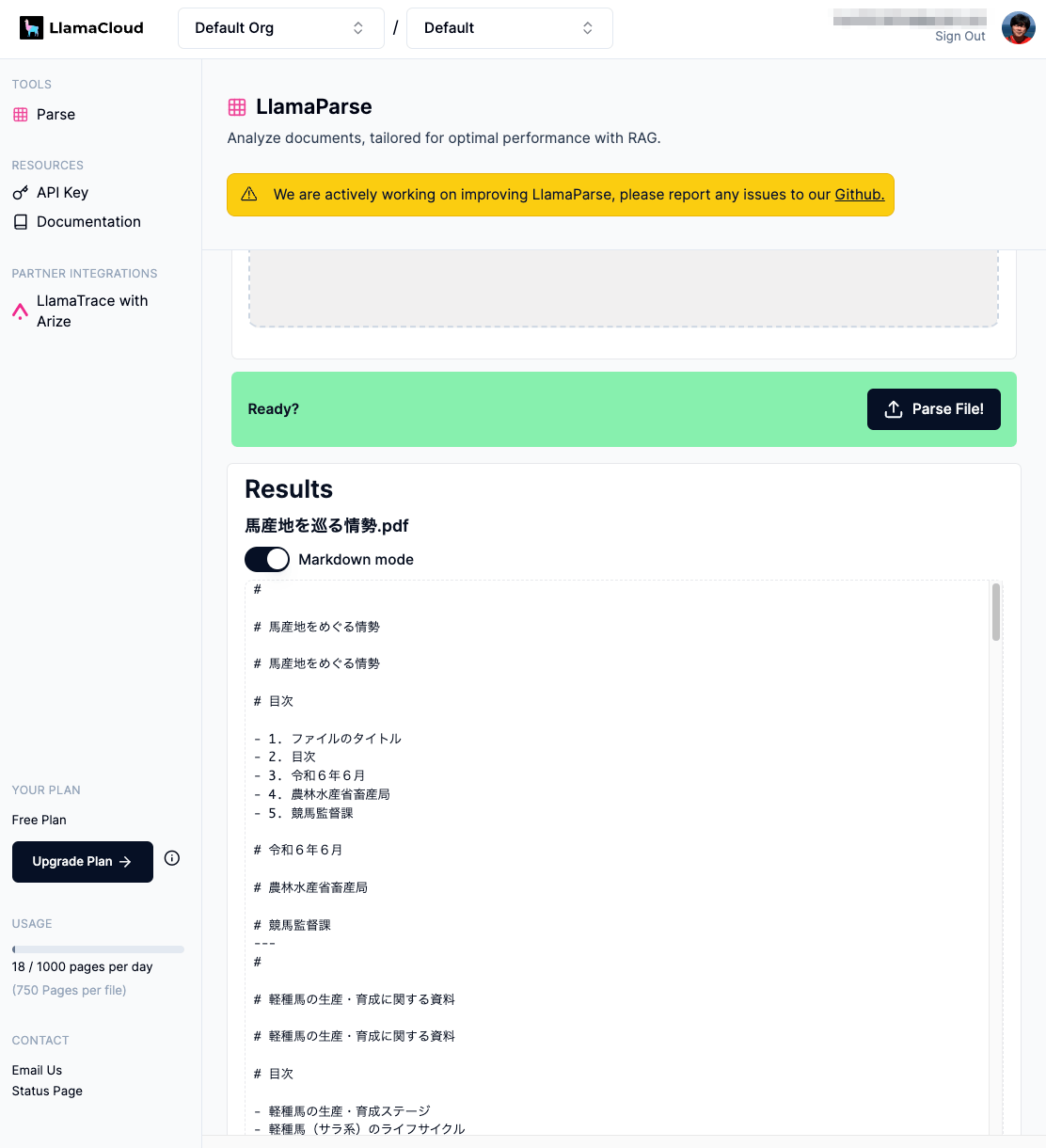
少しピックアップしてみたいと思う。「3 馬の飼養頭数の推移」(P3)あたりのパース結果は以下となっていた。
---
#
# 馬の飼養頭数の推移
# 馬の飼養頭数の推移
# 目次
- 馬の総飼養頭数の推移
# 馬の総飼養頭数の推移
馬は品種や体格等により、競走用、乗馬用あるいは肥育用等の様々な目的で飼養。
馬の総飼養頭数は、近年減少傾向で推移していたが、令和5年は74,287頭となり増加。
競走用軽種馬の飼養頭数は増加傾向で推移しており、令和5年は47,831頭で、総飼養頭数の約64%を占める。
このうち競走用に登録されている頭数は、令和5年で21,707頭と総飼養頭数の約29%を占める。
資料:種雄馬、繁殖雌馬は(公財) ジャパン・スタッドブック・インターナショナル、(公社)日本軽種馬協会「軽種馬統計」、競走馬は日本中央競馬会及び地方競馬全国協会調べ、
育成馬は「軽種馬統計」の生産頭数及び前年生産頭数に育成率(0.95)を乗じた数の合計値(数値は各年末現在)。
馬全体の総飼養頭数は農林水産省動物衛生課調べ「家畜の頭羽数及び家畜の飼養に係る衛生管理の状況(各年2月1日現在)」とし、
その他は総飼養頭数から競走用軽種馬を除いた頭数。
---
MarkdownといいつつあまりMarkdownっぽい構造にはなっておらず、無駄な重複も見られる。あと、図についてはどう処理されているのかがわからない感がある。
設定が結果に影響した可能性はあるので、少し設定を変えてみる。まずはプロンプトを全部消してデフォルトでお任せしてみた場合の同じページのパース結果。
---
# 馬の飼養頭数の推移
馬は品種や体格等により、競走用、乗馬用あるいは肥育用等の様々な目的で飼養。
馬の総飼養頭数は、近年減少傾向で推移していたが、令和5年は74,287頭となり増加。
競走用軽種馬の飼養頭数は増加傾向で推移しており、令和5年は47,831頭で、総飼養頭数の約64%を占める。
このうち競走用に登録されている頭数は、令和5年で21,707頭と総飼養頭数の約29%を占める。
|馬の総飼養頭数の推移|80,000|75,199|74,302|74,660|75,597|78,247|77,762|
|---|---|---|---|---|---|---|---|
| |73,977|74,092| |73,271|74,287| | | | |
| | |69,041| | | |68,263| | | |
|70,000| | |31,933|33,421|31,621|26,192|26,456|その他(乗用馬、肥育馬、在来馬等)|
| |33,054|32,992|33,264|32,687|32,298| |20,891| | |
| | |28,275| | | | | | | |
|50,000| | | | | | |競走馬| | |
|40,000| | | |20,261|21,060|21,543|21,458|21,707|育成馬|
| |18,982|18,420|17,806|17,719|18,258|18,807|19,528|競走用軽種馬|47,831頭|
|30,000| | | | | | |繁殖雌馬| | |
|20,000| | |14,580|14,920|15,146|15,201| | | |
| |13,574|13,338|13,405|13,416|13,421|13,650|13,984|14,280| |
|10,000| | | | | | |種雄馬| | |
| |9,349|9,322|9,272|9,404|9,492|9,653|9,911|10,029|10,231|10,349|10,514|10,653|
|0|240|230|230|227|234|252|241|257|270|267|254|270|
| |H24|25|26|27|28|29|30|R1|2|3|4|5|
資料:種雄馬、繁殖雌馬は(公財) ジャパン・スタッドブック・インターナショナル、(公社)日本軽種馬協会「軽種馬統計」、競走馬は日本中央競馬会及び地方競馬全国協会調べ、育成馬は「軽種馬統計」の生産頭数及び前年生産頭数に育成率(0.95)を乗じた数の合計値(数値は各年末現在)。
馬全体の総飼養頭数は農林水産省動物衛生課調べ「家畜の頭羽数及び家畜の飼養に係る衛生管理の状況(各年2月1日現在)」とし、その他は総飼養頭数から競走用軽種馬を除いた頭数。
---
こちらのほうが無駄な重複もなく良さげ。なるほど、プロンプトが与える影響は結構大きそうに思える。ただ流石にグラフは無理やりテーブルにしたような感がある。
次にGPT-4o Mode を有効にしてみた場合。
---
# 3 馬の飼養頭数の推移
- 馬は品種や体格等により、競走用、乗馬用あるいは肥育用等の様々な目的で飼養。
- 馬の総飼養頭数は、近年減少傾向で推移していたが、令和5年は74,287頭となり増加。
- 競走用軽種馬の飼養頭数は増加傾向で推移しており、令和5年は47,831頭で、総飼養頭数の約64%を占める。
- このうち競走用に登録されている頭数は、令和5年で21,707頭と総飼養頭数の約29%を占める。
## 馬の総飼養頭数の推移
| 年度 | 総飼養頭数 | 競走馬 | 育成馬 | 繁殖牝馬 | 種雄馬 | その他(乗用馬、肥育馬、在来馬等) |
|------|------------|--------|--------|----------|--------|----------------------------------|
| H24 | 75,199 | 33,054 | 18,982 | 13,574 | 9,349 | 240 |
| H25 | 74,302 | 32,992 | 18,420 | 13,338 | 9,322 | 230 |
| H26 | 73,977 | 33,264 | 17,806 | 13,416 | 9,272 | 227 |
| H27 | 69,041 | 28,275 | 17,719 | 13,421 | 9,404 | 222 |
| H28 | 74,092 | 32,687 | 18,258 | 13,650 | 9,492 | 234 |
| H29 | 74,660 | 32,928 | 17,807 | 14,280 | 9,653 | 234 |
| H30 | 75,597 | 31,993 | 19,528 | 14,580 | 9,911 | 240 |
| R1 | 68,247 | 33,421 | 15,920 | 10,231 | 8,940 | 235 |
| R2 | 77,762 | 31,630 | 21,060 | 10,349 | 10,231 | 492 |
| R3 | 73,271 | 26,192 | 21,601 | 10,349 | 10,231 | 3,898 |
| R4 | 68,263 | 20,891 | 21,458 | 10,231 | 10,231 | 5,452 |
| R5 | 74,287 | 26,456 | 20,891 | 10,653 | 10,231 | 6,056 |
**資料**: 種雄馬、繁殖牝馬は(公財)ジャパン・スタッドブック・インターナショナル、(公社)日本軽種馬協会の種雄馬及び繁殖牝馬の登録頭数及び地方競馬全国協会の在来馬の生産頭数及び繁殖牝馬の生産頭数に基づく。競走馬は日本中央競馬会及び地方競馬全国協会の各年の登録頭数に基づく。その他は軽種馬協会及び最先用軽種馬協会等に基づく。
---
テキストはもちろんだが、グラフについてもかなり頑張って読み取ろうとしているのがわかる。GPT-4oならではなところ。ただしグラフの解釈は間違っているのだけども(列と数字がマッチしていない)。
あと、GPT-4o ModeでUSAGEが激減したので、OCR的な処理に比べるとやはりモデルを使うのはコスト高なんだろうと思う。
とりあえず、お手軽には使えるが、設定によって結果は結構変わりそうだし、パースしたいファイルの特徴なんかによっても変わってきそうな感がある。
Python SDK
Python SDKを使ってコードでLlamaParseを使ってみる。Colaboratory上でやってみる。
まず以下にしたがってLlamaParseでAPIキーを取得して、ColaboratoryのシークレットにLLAMA_CLOUD_API_KEYとして登録しておく。
パッケージをインストール。llama-parseは独立したパッケージになっている。
!pip install llama-index-core llama-parse llama-index-readers-file
APIキーを読み込み
import os
from google.colab import userdata
os.environ["LLAMA_CLOUD_API_KEY"] = userdata.get('LLAMA_CLOUD_API_KEY')
notebookなのでイベントループのネストを有効化しておく。
import nest_asyncio
nest_asyncio.apply()
Colaboratoryに先ほどのPDFファイルをアップロードする。dataディレクトリを作成してそこに配置した。
これをコードで読み込む。
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
parser = LlamaParse(
result_type="markdown" # "markdown" または "text" が選択可能
)
# SimpleDirectoryReaderを使ってパースする
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(input_files=['data/馬産地を巡る情勢.pdf'], file_extractor=file_extractor).load_data()
print(len(documents))
print(documents[4])
18
Doc ID: 60ab9d2d-bc09-4525-96ff-d1355df80170
Text: # 馬の飼養頭数の推移 馬は品種や体格等により、競走用、乗馬用あるいは肥育用等の様々な目的で飼養。
馬の総飼養頭数は、近年減少傾向で推移していたが、令和5年は74,287頭となり増加。
競走用軽種馬の飼養頭数は増加傾向で推移しており、令和5年は47,831頭で、総飼養頭数の約64%を占める。
このうち競走用に登録されている頭数は、令和5年で21,707頭と総飼養頭数の約29%を占める。
|馬の総飼養頭数の推移|80,000|75,199|74,302|74,660|75,597|78,247|77,762|
|---|---|---|---|---|---|---|---| | |73,977|74,092| |73,271|74,287| |
| | | | | |69,0...
ページごとにドキュメントが作成されているのがわかる。
あとはこれを元にインデックスとクエリエンジンを作成すればOK。
GUIで設定したようなオプションは以下にある。
たとえば日本語でパースじにプロンプト設定するとかだとこんな感じ。
parser = LlamaParse(
language="ja",
parsing_instruction = "提供された文書はスライドである。1ページにはファイルのタイトル、2ページは目次となっており、それ以降のページは各ページごとの副題を持つ。資料は、テキスト、図、表、グラフ、イラストを含む。",
)
マルチモーダルなパースについては以下。
ここにクレジットについて記載されていた。
| モデル | モデル名の指定 | 価格 |
|---|---|---|
| OpenAI GPT-4o(デフォルト) | openai-gpt4o |
10クレジット/ページ (3セント/ページ) |
| Sonnect 3.5 | anthropic-sonnet-3.5 |
20クレジット/ページ (6セント/ページ) |
マルチモーダルモードを使用する場合、文書を解析するために、あなた自身のベンダーキーを提供することができます。 その場合、LlamaParseは1ページにつき1クレジット(0.3セント)のみ課金します。
以下のような感じ。
parser = LlamaParse(
use_vendor_multimodal_model=True,
vendor_multimodal_model_name="openai-gpt4o",
vendor_multimodal_api_key="sk-XXXXXXXXXX",
)
あと上記がGPT−4oモードなのかなと思いきや、gpt4o_modeはDeprecatedとある。。。。なるほど、ここはLlamaParseのWebUIでも今後修正されるのかもしれない。
サポートされているドキュメントのタイプは以下。
とりあえず今更ながら使ってみたけど、テキストベースの資料なら色々使い勝手は悪くはないのではなかろうかと思うが、画像・グラフ・表・図などを含むようなケースについてはLlamaParseの外側でもう少し工夫が必要なのかなと感じた。
特に以下でやってるようなマルチモーダルインデックス+retrieverみたいな感じとか、
あと、ちょっと前にポストされていた以下とか
この辺を見ていると、単に画像→テキスト化してインデックスを作る、だけじゃなくて、もう少し直接的に画像を扱う(会話に画像を追加するとか、画像を検索で引っ張ってくるとか)アプローチのほうがいいのかなと感じている。Gemini単体でもマルチモーダルはとても使いやすく感じたのもある。
LlamaCloudだと、LlamaParseのようなパースだけじゃなくて、インデックス作成のパイプラインそのものをどうやら動かせるような雰囲気があるので、そっちならもうちょっと突っ込んだことができるのかもしれない。
表の解釈が改善されたらしい。
notebookを見る限り、
- LlamaParseのデフォルト設定でPDFをパースしているっぽい(マルチモーダルなLLMは使っていない)
- パースされたMarkdownをノード化、さらにそれをMarkdownElementNodeparserを使ってテキストとテーブルを紐づけてノード化、みたいなことをやってインデックスを作成している。
で普通にSimpleDirectoryReaderでPDFをそのままチャンク分割して作成したインデックスと比較してるんだけど、LlamaParseを使った方は単なるパースだけじゃなくてインデックスも工夫しているので、やや恣意的な感じを受けた。単に表の解釈が良くなっただけなら、パースした結果を比較すればいいだけだし。
まあ、表を正しく解釈できれば、こういうふうな精度を上げるインデックスの作り方があるよ、という風に解釈すればよいかと思う。
上で使用した「馬産地をめぐる情勢(令和6年6月)」のPDFに置き換えてやってみた。日本語なので以下を変更している。
- LlamaParseのパラメータに
language="ja"を追加 - リランカーを
BAAI/bge-reranker-large(英中対応)からBAAI/bge-reranker-v2-m3(マルチリンガル対応)に変更
「7 <規模別>軽種馬生産農家戸数・繁殖雌馬飼養頭数(令和5年)」の箇所の表がどのように解釈されているのかを見てみる。
SimpleDirectoryReaderで読んでチャンク分割しただけのものはこう
○飼養規模10頭以下の生産者戸数は463戸で、全体の約61%。
○飼養規模10頭以下の生産者における繁殖雌馬飼養頭数は2,261頭で全体の約21%。
飼養規模21頭以上の生産者における繁殖雌馬飼養頭数は5,883頭で全体の約55%。
資料:(公財)ジャパン・スタッドブック ・インターナショナル 、(公社)日本軽種馬協会「 2023軽種馬統計」(令和5年 12月31日時点)
「(2)飼養頭数別繁殖雌馬飼養頭数」は(1)により頭数×戸数で算出。
ただし、21 頭以上は繁殖雌馬合計頭数から推計。(1)繁殖雌馬飼養頭数別軽種馬生産者戸数
(2)飼養頭数規模別繁殖雌馬飼養頭数1~10頭
61% 11~15頭
16%16~20頭
7%21頭以上
16%
全国
761戸
1~10頭
21%
11~15頭
15%
16~20頭
9%21頭以上
55%全国
10,653頭(単位:戸)
飼養規模 1~10頭11~15頭 16~20頭 21頭以上 合計項目 1~5頭 6~10頭
全国463 276 187 121 55 122 761
61% 36% 25% 16% 7% 16% 100%
北
海道日高366 196 170 110 53 113 642
57% 31% 26% 17% 8% 18% 100%
胆振20 14 6 4 1 8 33
61% 42% 18% 12% 3% 24% 100%
(単位:頭)
飼養規模 1~10頭11~15頭 16~20頭 21頭以上 合計項目 1~5頭 6~10頭
全国2,261 771 1,490 1,537 972 5,883 10,653
21% 7% 14% 14% 9% 55% 100%
北海道日高
1,943 589 1,354 1,398 936 4,087 8,364
23% 7% 16% 17% 11% 49% 100%
胆振80 28 52 52 16 1,838 1,986
4% 1% 3% 3% 1% 93% 100%
77<規模別>軽種馬生産農家戸数・繁殖雌馬飼養頭数(令和5年)
まあしょうがない。
LlamaParseでパースしたほう。
# <規模別>軽種馬生産農家戸数・繁殖雌馬飼養頭数(令和5年)
○ 飼養規模10頭以下の生産者戸数は463戸で、全体の約61%。
○ 飼養規模10頭以下の生産者における繁殖雌馬飼養頭数は2,261頭で全体の約21%。
飼養規模21頭以上の生産者における繁殖雌馬飼養頭数は5,883頭で全体の約55%。
**(1)繁殖雌馬飼養頭数別軽種馬生産者戸数(単位:戸)**
|項目|1~5頭|6~10頭|11~15頭|16~20頭|21頭以上|合計|
|---|---|---|---|---|---|---|
|全国|463|276|187|121|55|122|
|全国|61%|36%|25%|16%|7%|16%|
|北海道|20|14|6|4|1|8|
|北海道|61%|42%|18%|12%|3%|24%|
**(2)飼養頭数規模別繁殖雌馬飼養頭数(単位:頭)**
|項目|1~5頭|6~10頭|11~15頭|16~20頭|21頭以上|合計|
|---|---|---|---|---|---|---|
|全国|2,261|771|1,490|1,537|972|5,883|
|全国|21%|7%|14%|14%|9%|55%|
|北海道|80|28|52|52|16|1,838|
|北海道|4%|1%|3%|3%|1%|93%|
資料:(公財)ジャパン・スタッドブック・インターナショナル、(公社)日本軽種馬協会「2023軽種馬統計」(令和5年12月31日時点)
「(2)飼養頭数別繁殖雌馬飼養頭数」は(1)により頭数×戸数で算出。
ただし、21頭以上は繁殖雌馬合計頭数から推計。
惜しい。表の見出しがちょっと複雑なのだよね。ただ以前よりも結構頑張ってる感は感じた。
あと、表の解釈は良くなったのかもしれないけど、グラフの読み取りまで良くなったわけではなさそう。グラフのようなビジュアルはやっぱりLLMを使うほうが精度を上げれると思う。
Sonnet−3.5使うと良さそう。
上のツイートで紹介されている、LlamaParseでマルチモーダルLLMを使ったパースのnotebook
Anthropic Claude-3.5-SonnetとOpenAI GPT-4oで試してみた。LlamaParseでマルチモーダルLLMを使う場合は、use_vendor_multimodal_modelを有効にしてモデルを定義する。APIキーを自分で指定すると、LlamaParseのUsageは単にページ数だけが減るだけになる(代わりに自分のAPIキーで課金される)。
parser = LlamaParse(
result_type="markdown",
language="ja",
use_vendor_multimodal_model=True,
vendor_multimodal_model_name="anthropic-sonnet-3.5",
vendor_multimodal_api_key=os.environ["ANTHROPIC_API_KEY"],
)
上と同じ「7 <規模別>軽種馬生産農家戸数・繁殖雌馬飼養頭数(令和5年)」のページのパース結果。まずClaude-3.5-Sonnet。
# 7 <規模別>軽種馬生産農家戸数・繁殖雌馬飼養頭数(令和5年)
○ 飼養規模10頭以下の生産者戸数は463戸で、全体の約61%。
○ 飼養規模10頭以下の生産者における繁殖雌馬飼養頭数は2,261頭で全体の約21%。
飼養規模21頭以上の生産者における繁殖雌馬飼養頭数は5,883頭で全体の約55%。
## (1) 繁殖雌馬飼養頭数別軽種馬生産者戸数
(単位:戸)
| 項目 | 飼養規模 1~10頭 | | | 11~15頭 | 16~20頭 | 21頭以上 | 合計 |
|------|------------------|--------|--------|-----------|-----------|-----------|------|
| | 1~5頭 | 6~10頭 | | | | | |
| 全国 | 463 | 276 | 187 | 121 | 55 | 122 | 761 |
| | 61% | 36% | 25% | 16% | 7% | 16% | 100% |
| 北海道 | 日高 | 366 | 196 | 170 | 110 | 53 | 113 | 642 |
| | | 57% | 31% | 26% | 17% | 8% | 18% | 100% |
| | 胆振 | 20 | 14 | 6 | 4 | 1 | 8 | 33 |
| | | 61% | 42% | 18% | 12% | 3% | 24% | 100% |
## (2) 飼養頭数規模別繁殖雌馬飼養頭数
(単位:頭)
| 項目 | 飼養規模 1~10頭 | | | 11~15頭 | 16~20頭 | 21頭以上 | 合計 |
|------|------------------|--------|--------|-----------|-----------|-----------|------|
| | 1~5頭 | 6~10頭 | | | | | |
| 全国 | 2,261 | 771 | 1,490 | 1,537 | 972 | 5,883 | 10,653 |
| | 21% | 7% | 14% | 14% | 9% | 55% | 100% |
| 北海道 | 日高 | 1,943 | 589 | 1,354 | 1,398 | 936 | 4,087 | 8,364 |
| | | 23% | 7% | 16% | 17% | 11% | 49% | 100% |
| | 胆振 | 80 | 28 | 52 | 52 | 16 | 1,838 | 1,986 |
| | | 4% | 1% | 3% | 3% | 1% | 93% | 100% |
資料:(公社)ジャパン・スタッドブック・インターナショナル「日本軽種馬協会2023軽種馬統計」(令和5年12月31日時点)
(2)「飼養頭数別繁殖雌馬飼養頭数」は(1)により頭数×戸数で算出。
ただし、21頭以上は繁殖雌馬合計頭数から推計。
GPT-4o
# 7 <規模別>軽種馬生産農家戸数・繁殖牝馬飼養頭数(令和5年)
○ 飼養規模10頭以下の生産者戸数は463戸で、全体の約61%。
○ 飼養規模10頭以下の生産者における繁殖牝馬飼養頭数は2,261頭で全体の約21%。
○ 飼養規模21頭以上の生産者における繁殖牝馬飼養頭数は5,883頭で全体の約55%。
## (1) 繁殖牝馬飼養頭数別軽種馬生産者戸数
| 項目 | 飼養規模 | ~10頭 | 1~5頭 | 6~10頭 | 11~15頭 | 16~20頭 | 21頭以上 | 合計 |
|--------|------------|--------|--------|---------|----------|----------|----------|------|
| 全国 | 戸数 | 463 | 276 | 187 | 121 | 55 | 122 | 761 |
| | 割合 | 61% | 36% | 25% | 16% | 7% | 16% | 100% |
| 北海道 | 日高 | 366 | 196 | 170 | 53 | 34 | 53 | 632 |
| | 割合 | 57% | 31% | 27% | 8% | 5% | 8% | 100% |
| | 胆振 | 40 | 24 | 16 | 8 | 2 | 3 | 65 |
| | 割合 | 61% | 42% | 25% | 12% | 3% | 5% | 100% |
## (2) 飼養頭数規模別繁殖牝馬飼養頭数
| 項目 | 飼養規模 | ~10頭 | 1~5頭 | 6~10頭 | 11~15頭 | 16~20頭 | 21頭以上 | 合計 |
|--------|------------|--------|--------|---------|----------|----------|----------|------|
| 全国 | 頭数 | 2,261 | 771 | 1,490 | 1,572 | 776 | 5,883 | 10,653 |
| | 割合 | 21% | 7% | 14% | 15% | 9% | 55% | 100% |
| 北海道 | 日高 | 1,943 | 589 | 1,354 | 1,354 | 936 | 4,981 | 8,364 |
| | 割合 | 23% | 7% | 16% | 16% | 11% | 49% | 100% |
| | 胆振 | 48 | 32 | 16 | 16 | 16 | 1,838 | 1,980 |
| | 割合 | 2% | 2% | 1% | 1% | 1% | 93% | 100% |
資料:(公財)ジャパン・スタッドブック・インターナショナル、(公社)日本軽種馬協会「2023年(令和5年)日本の軽種馬統計」(令和5年12月31日時点)
「(2)飼養頭数規模別繁殖牝馬飼養頭数」は(1)により頭数×戸数で算出。ただし、21頭以上は繁殖牝馬合計頭数から推計。
テキストの見え方はGPT-4oのほうが良いように見えるけど、少し複雑な表の見出し部分についてはClaude-3.5 だと解釈されているように見える。
インデックスを作ってそれぞれにクエリを投げてみた結果。ここで問い合わせているのはともにgpt-4o。
繁殖雌馬の飼養頭数について、全国における規模ごとの内訳を教えて。回答は日本語で。
Claude-3.5-Sonnetでパースしたインデックスでの結果
全国における繁殖雌馬の飼養頭数の規模ごとの内訳は以下の通りです。
- 飼養規模1~10頭: 2,261頭 (全体の21%)
- 1~5頭: 771頭 (7%)
- 6~10頭: 1,490頭 (14%)
- 飼養規模11~15頭: 1,537頭 (14%)
- 飼養規模16~20頭: 972頭 (9%)
- 飼養規模21頭以上: 5,883頭 (55%)
合計で10,653頭となります。
GPT-4oのほう
全国における繁殖雌馬の飼養頭数の規模ごとの内訳は以下の通りです。
- 飼養規模10頭以下: 2,261頭 (全体の21%)
- 飼養規模1~5頭: 771頭 (全体の7%)
- 飼養規模6~10頭: 1,490頭 (全体の14%)
- 飼養規模11~15頭: 1,572頭 (全体の15%)
- 飼養規模16~20頭: 776頭 (全体の9%)
- 飼養規模21頭以上: 5,883頭 (全体の55%)
合計で10,653頭となります。
たしかにClaude-3.5のほうが見出しの部分を理解してパースしていると言えそう。