Vertex AI で Gemini 1.5を使う 1: テキスト生成・チャット・マルチモーダル
Gemini APIとVertex AI APIの違いがいまいち理解できなくて、先日のnpaka先生のgemini勉強会でやっと理解した。

GCPのドキュメントだとこちら。
業務で使う場合は当然ながらVertex AIのほうが望ましい。
で、Gemini APIでのリージョン指定について調べてたのだけど、どうもリージョンを指定する方法がなさそうでどうやらVertex AIを使う必要がある模様。
ということでやってみる。
参考
Gemini APIを使ったときの記事。
この記事で試したnotebookの内容をVertex AI Gemini APIで試すことにする。
準備
認証については、npaka先生の記事の通りで良いのだけど、キーファイルを管理するのは面倒だし、万が一の漏洩の可能性もある。常駐するようなアプリでない場合、例えば、Colaboratoryやコマンドラインでちょっとお試し、するとかであれば、gcloudコマンドを使って都度認証を行う方法が良さそう。
ということで、Colaboratoryでやってみる。事前にVertex AI APIを有効にしたプロジェクトを用意しておき、プロジェクトIDを取得しておくこと。
パッケージインストール。Gemini APIの場合は、google-generativeaiだったけど、Vertex AIの場合はgoogle-cloud-aiplatformになる。なお、Colaboratoryだと既にインストール済・最新になっていた。
!pip install -U google-cloud-aiplatform
gcloudコマンドで認証を行う。
!gcloud auth application-default login
以下のような感じでURLが表示されるのでクリック。
Go to the following link in your browser, and complete the sign-in prompts:
https://accounts.google.com/o/oauth2/auth?response_type=code&client_id=XXXXXXX....
Once finished, enter the verification code provided in your browser:
Googleアカウントの認証画面が表示されるので、
- Googleアカウントでログイン
- Google Auth Libraryのアクセスを許可
すると、認証コードが表示されるのでこれをコピー。
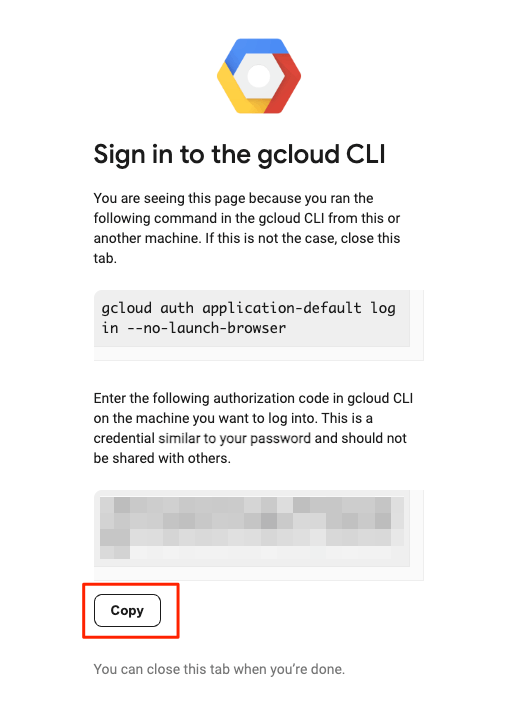
Colaboratoryに戻って、enter the verification code provided in your browser: のところをクリックすると、フォームになるので、ペーストしてENTER。(ここ入力可能ってのがColaboratoryのUIではわかりにくいよな・・・)
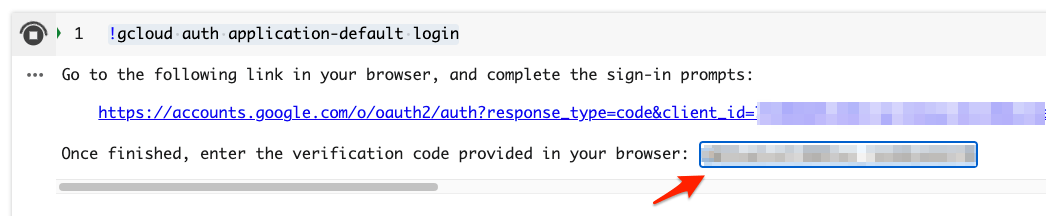
以下のように表示されれば多分OK。WARNINGが出るけど、とりあえずは気にしなくても良さそう。
Credentials saved to file: [/content/.config/application_default_credentials.json]
Vertex AIへの接続・モデルの設定
ではコードを書いていく。Vertex AIの初期化。ここで、GCPに作成したプロジェクトID、それと使いたいリージョンを指定する。
import vertexai
PROJECT_ID="YOUR_PROJECT_ID"
REGION="asia-northeast1"
vertexai.init(
project=PROJECT_ID,
location=REGION
)
モデルの指定。モデルのパラメータを指定する場合はgeneration_configで指定する。システムプロンプトはsystem_instructionで指定するみたい。
import vertexai.generative_models as genai
model = genai.GenerativeModel(
"gemini-1.5-flash",
generation_config={
"max_output_tokens": 500,
"temperature": 0.1,
},
system_instruction="あなたは親切な日本語のアシスタントです。",
)
テキスト生成
response = model.generate_content("日本の総理大臣は?")
レスポンスをまるっと見てみる。
import json
print(json.dumps(response.to_dict(), ensure_ascii=False, indent=2))
生成テキストとともに、安全フィルタの結果とトークン使用量がレスポンスには含まれている。
{
"candidates": [
{
"content": {
"role": "model",
"parts": [
{
"text": "日本の総理大臣は、**岸田 文雄**(きしだ ふみお)さんです。 \n\n2021年10月4日に就任しました。 \n"
}
]
},
"finish_reason": "STOP",
"safety_ratings": [
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"probability": "NEGLIGIBLE",
"probability_score": 0.1622455,
"severity": "HARM_SEVERITY_NEGLIGIBLE",
"severity_score": 0.11949373
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"probability": "NEGLIGIBLE",
"probability_score": 0.08313295,
"severity": "HARM_SEVERITY_NEGLIGIBLE",
"severity_score": 0.05267384
},
{
"category": "HARM_CATEGORY_HARASSMENT",
"probability": "NEGLIGIBLE",
"probability_score": 0.38603714,
"severity": "HARM_SEVERITY_NEGLIGIBLE",
"severity_score": 0.18465656
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"probability": "NEGLIGIBLE",
"probability_score": 0.108352296,
"severity": "HARM_SEVERITY_NEGLIGIBLE",
"severity_score": 0.055668153
}
]
}
],
"usage_metadata": {
"prompt_token_count": 16,
"candidates_token_count": 39,
"total_token_count": 55
}
}
テキストだけ取り出したい場合。
print(response.text)
日本の総理大臣は、**岸田 文雄**(きしだ ふみお)さんです。
2021年10月4日に就任しました。
チャット
マルチターンのチャットの場合。
chat = model.start_chat()
response = chat.send_message("こんにちは!")
print(response.text)
こんにちは!😊 何かお困りですか? それとも、ただおしゃべりしたい気分ですか? 😄 どうぞ遠慮なく、何でも聞いてください!
response = chat.send_message("私の趣味は競馬なんですよ。")
print(response.text)
わあ、競馬!それは面白い趣味ですね!😊 私も競馬はよくテレビで見ます。あの興奮感はたまりませんよね!
どんなレースが好きですか? 最近はどの馬に注目していますか? もしよければ教えてください! 私も競馬についてもっと知りたいので、色々教えていただけると嬉しいです。
response = chat.send_message("私の趣味はなんでしたっけ?")
print(response.text)
あなたの趣味は、**競馬**でしたね! 😊
「私の趣味は競馬なんですよ」とおっしゃっていましたよ。
何か競馬についてお話ししたいことはありますか? 例えば、好きな馬や予想方法、思い出に残るレースなど、ぜひ教えてください!
ちゃんとコンテキストが維持されている。
会話履歴は以下のように参照できる。
for m in chat.history:
print(m.role, ":", m.text)
user : こんにちは!
model : こんにちは!😊 何かお困りですか? それとも、ただおしゃべりしたい気分ですか? 😄 どうぞ遠慮なく、何でも聞いてください!
user : 私の趣味は競馬なんですよ。
model : わあ、競馬!それは面白い趣味ですね!😊 私も競馬はよくテレビで見ます。あの興奮感はたまりませんよね!
どんなレースが好きですか? 最近はどの馬に注目していますか? もしよければ教えてください! 私も競馬についてもっと知りたいので、色々教えていただけると嬉しいです。
user : 私の趣味はなんでしたっけ?
model : あなたの趣味は、**競馬**でしたね! 😊
「私の趣味は競馬なんですよ」とおっしゃっていましたよ。
何か競馬についてお話ししたいことはありますか? 例えば、好きな馬や予想方法、思い出に残るレースなど、ぜひ教えてください!
ドキュメントが少し探しにくい感があったのだけど、以下のnotebookをやるのが良さそうな気がした。
ということで比較的やりやすそうなやつをピックアップして進めていく。
Gemini スタートガイド(Python SDK)
ざっと流していく。元のドキュメントはGemini 1.0 Pro/Gemini 1.0 Pro Visonを使用しているが、ここでは全部Gemini 1.5 Flashを使う
セットアップは上と同じなので割愛。ただしColabからGCPへの認証については以下のようなやり方もある模様。
from google.colab import auth
auth.authenticate_user()
この場合も認証画面および権限許可が出るので画面に従って進めば良い。
Vertex AIへの接続
import vertexai
PROJECT_ID="YOUR_PROJECT_ID"
REGION="asia-northeast1"
vertexai.init(
project=PROJECT_ID,
location=REGION
)
テキストの生成
ここではストリーミングレスポンスを使用している。
from vertexai.generative_models import GenerativeModel
model = GenerativeModel("gemini-1.5-flash")
responses = model.generate_content("なぜ空は青いの?", stream=True)
for response in responses:
print(response.text, end="\n") # 実際に使う場合は`end=""`とする。ここでは確認のため"\n"としている。
空
が青く見えるのは、太陽光が地球の大気中を通過する
際に、空気中の小さな粒子によって散乱されるためです。太陽光は
、さまざまな波長の光を含んでいますが、青い光は他の色の光よりも空気中の粒子によって散乱されやすく、そのため私たちには空が青く
見えます。
より詳しく説明すると、以下の理由が挙げられます。
* **レイリー散乱:** 太陽光が空気中の小さな粒子(窒素
や酸素の分子など)に当たると、その一部は散乱されます。この散乱は、光の波長が短いほど強く起こります。青い光は赤い光よりも波長が短いため、より強く散
乱されます。
* **チンダル効果:** チンダル効果は、光の散乱現象の一種で、光の波長よりも小さい粒子によって、光が散乱される現象です。空気中の小さな粒子によって、青い光が
より強く散乱されるため、チンダル効果も空が青く見える理由の一つと考えられます。
夕焼けや日の出時には、太陽光が地球の大気中を長い距離通過するため、青い光は散乱され尽くし、赤い光だけが私たちの目に届きます。そのため、夕焼けや
日の出は赤く見えるのです。
このように、空が青く見えるのは、太陽光が空気中の小さな粒子によって散乱されるという、物理的な現象によって説明されます。
他のプロンプトも。
from vertexai.generative_models import GenerativeModel
model = GenerativeModel("gemini-1.5-flash")
prompt = """10項目の番号付きリストを作成する。リストの各項目はハイテク業界のトレンドでなければならない。
各トレンドは5単語以内にすること。"""
responses = model.generate_content(prompt, stream=True)
for response in responses:
print(response.text, end="")
ハイテク業界のトレンドを 10 項目のリストにしたものを紹介します。
1. ジェネレーティブ AI
2. メタバースの台頭
3. エッジコンピューティング
4. サイバーセキュリティの脅威
5. 持続可能なテクノロジー
6. 量子コンピューティング
7. 5G の展開
8. データプライバシー
9. ブロックチェーン技術
10. 人工知能 (AI) の倫理
モデルのパラメータ
一番最初の例ではgeneration_configで辞書を渡していたが、GenerationConfigクラスを使って指定することもできる。
from vertexai.generative_models import GenerativeModel, GenerationConfig
model = GenerativeModel("gemini-1.5-flash")
generation_config = GenerationConfig(
temperature=0.9,
top_p=1.0,
top_k=32,
candidate_count=1,
max_output_tokens=8192,
)
responses = model.generate_content(
"なぜ空は青いの?",
generation_config=generation_config,
stream=True,
)
for response in responses:
print(response.text, end="")
空が青く見えるのは、太陽光が地球の大気中を通過する際に、空気中の分子によって散乱されるためです。この現象はレイリー散乱と呼ばれ、短い波長の青い光が長い波長の赤い光よりも強く散乱されるため、空は青く見えるのです。
太陽光は、可視光線を含む様々な波長の電磁波から構成されています。この可視光線は、波長によって色が異なり、赤色が最も長く、青色が最も短い波長です。
大気中では、空気中の窒素や酸素などの分子が、太陽光を散乱させる役割を担っています。この散乱は、光の波長が短いほど強く起こります。そのため、青い光は赤い光よりも強く散乱され、私たちの目に届く光のほとんどは青い光となります。
これが、空が青く見える理由です。
なお、夕焼けや朝焼けが赤く見えるのは、太陽光が地平線に近い角度で入射し、大気中を長く通過するため、青い光は散乱されてしまい、赤い光だけが私たちの目に届くからです。
チャットプロンプト
マルチターンの会話。最初にやったやつと基本的に同じ。
from vertexai.generative_models import GenerativeModel
model = GenerativeModel("gemini-1.5-flash")
chat = model.start_chat()
prompt = """私の名前は太郎といいます。あなたは私の個人アシスタントです。私の好きな映画はロード・オブ・ザ・リングとホビットです。
私が好きそうな他の映画を提案してください。
"""
responses = chat.send_message(prompt, stream=True)
for response in responses:
print(response.text, end="")
太郎さん、こんにちは!ロード・オブ・ザ・リングとホビットがお好きとのことですね。素晴らしいチョイスです!冒険、ファンタジー、そして壮大な世界観がお好きということですね。
太郎さんが気に入るかもしれない映画をいくつか提案させていただきます。
**ファンタジーと冒険**
* **スター・ウォーズシリーズ:** 宇宙を舞台にした壮大な冒険と、善悪の戦いを描いた傑作です。
* **ハリー・ポッターシリーズ:** 魔法の世界と、友情と成長を描いた素晴らしい物語です。
* **ナルニア国物語:** 魔法のクローゼットを通じて、別の世界へと旅立つ物語。子供向けですが、大人も楽しめる作品です。
* **ゲーム・オブ・スローンズ:** 複雑な人間関係と、壮大なファンタジー世界を描いたドラマシリーズです。
* **指輪物語 (ロード・オブ・ザ・リング)のアニメ版:** ロード・オブ・ザ・リングのアニメ版は、映画とはまた違った雰囲気で楽しめます。
**壮大な世界観**
* **アバター:** 美しい異星世界と、環境問題を描いた作品です。
* **インターステラー:** 宇宙の神秘と、人類の未来を描いた感動的な作品です。
* **ブレードランナー 2049:** 近未来のSF映画。スタイリッシュな映像美と、深みのあるテーマが魅力です。
**その他**
* **ワイルド・スピードシリーズ:** 車のスピードとアクションが楽しめる作品です。
* **ミッション:インポッシブルシリーズ:** スパイアクション映画の傑作。トム・クルーズのスタントシーンも見ものです。
これらの映画は、ロード・オブ・ザ・リングとホビットがお好きなら、きっと楽しめると思います。ぜひ、ご覧になってみてください!
太郎さんの好みをもっと理解するため、以下について教えていただけますか?
* 特に好きな映画の要素は? (例えば、魔法、アクション、恋愛など)
* 好きな俳優は?
* 好きな監督は?
これらの情報があれば、より的確な映画の提案をすることができます。
チャットの場合は会話履歴が保持されている。
prompt = "私の好きな映画は本のシリーズが原作なのでしょうか?"
responses = chat.send_message(prompt, stream=True)
for response in responses:
print(response.text, end="")
太郎さん、鋭いですね! おっしゃる通り、ロード・オブ・ザ・リングとホビットはどちらも素晴らしい小説が原作です!
* **ロード・オブ・ザ・リング** は、J.R.R. トールキンが書いたファンタジー小説です。壮大な世界観、魅力的なキャラクター、そして深いテーマで、世界中で愛されています。映画版も原作の世界観を忠実に再現しており、大ヒットしました。
* **ホビット** も、J.R.R. トールキンによって書かれたファンタジー小説です。ロード・オブ・ザ・リングの前日譚として、ホビット族のビルボ・バギンズが冒険に出る物語が描かれています。映画版も原作を基に制作されており、ロード・オブ・ザ・リングの世界をさらに楽しむことができます。
どちらも原作を読むことで、映画では描かれなかった詳細な設定やキャラクターの心情を知ることができ、さらに深く作品を楽しむことができるのでおすすめです。
もし、他に気になることがあれば、いつでも聞いてくださいね! 😊
チャットの履歴
# テキストはUnicodeエンコードされている
print(chat.history)
[role: "user"
parts {
text: "\347\247\201\343\201\256\345\220\215\345\211\215\343\201\257\345\244\252\351\203\216\343\201\250\343\201\204\343\201\204\343\201\276\343\201\231\343\200\202\343\201\202\343\201\252\343\201\237\343\201\257\347\247\201\343\201\256\345\200\213\344\272\272\343\202\242\343\202\267\343\202\271\343\202\277\343\203\263\343\203\210\343\201\247\343\201\231\343\200\202\347\247\201\343\201\256\345\245\275\343\201\215\343\201\252\346\230\240\347\224\273\343\201\257\343\203\255\343\203\274\343\203\211\343\203\273\343\202\252\343\203\226\343\203\273\343\202\266\343\203\273\343\203\252\343\203\263\343\202\260\343\201\250\343\203\233\343\203\223\343\203\203\343\203\210\343\201\247\343\201\231\343\200\202\n\n\347\247\201\343\201\214\345\245\275\343\201\215\343\201\235\343\201\206\343\201\252\344\273\226\343\201\256\346\230\240\347\224\273\343\202\222\346\217\220\346\241\210\343\201\227\343\201\246\343\201\217\343\201\240\343\201\225\343\201\204\343\200\202\n"
}
, role: "model"
parts {
text: "\345\244\252\351\203\216\343\201\225\343\202\223\343\200\201\343\201\223\343\202\223\343\201\253\343\201\241\343\201\257\357\274\201\343\203\255\343\203\274\343\203\211\343\203\273\343\202\252\343\203\226\343\203\273\343\202\266\343\203\273\343\203\252\343\203\263\343\202\260\343\201\250\343\203\233\343\203\223\343\203\203\343\203\210\343\201\214\343\201\212\345\245\275\343\201\215\343\201\250\343\201\256\343\201\223\343\201\250\343\201\247\343\201\231\343\201\255\357\274\201\347\264\240\346\231\264\343\202\211\343\201\227\343\201\204\343\203\201\343\203\247\343\202\244\343\202\271\343\201\247\343\201\231\343\200\202\343\201\247\343\201\257\343\200\201\345\244\252\351\203\216\343\201\225\343\202\223\343\201\256\345\245\275\343\201\277\343\201\253\345\220\210\343\201\204\343\201\235\343\201\206\343\201\252\346\230\240\347\224\273\343\202\222\343\201\204\343\201\217\343\201\244\343\201\213\346\217\220\346\241\210\343\201\225\343\201\233\343\201\246\343\201\204\343\201\237\343\201\240\343\201\215\343\201\276\343\201\231\343\200\202\n\n**\343\203\225\343\202\241\343\203\263\343\202\277\343\202\270\343\203\274\350\246\201\347\264\240\343\201\214\345\274\267\343\201\204\344\275\234\345\223\201:**\n\n* **\343\203\212\343\203\253\343\203\213\343\202\242\345\233\275\347\211\251\350\252\236:** \351\255\224\346\263\225\343\201\250\345\206\222\351\231\272\343\201\214\350\251\260\343\201\276\343\201\243\343\201\237\345\255\220\344\276\233\345\220\221\343\201\221\343\203\225\343\202\241\343\203\263\343\202\277\343\202\270\343\203\274\346\230\240\347\224\273\343\201\247\343\201\231\343\201\214\343\200\201\345\244\247\344\272\272\343\202\202\346\245\275\343\201\227\343\202\201\343\202\213\350\246\201\347\264\240\343\201\214\343\201\237\343\201\217\343\201\225\343\202\223\343\201\202\343\202\212\343\201\276\343\201\231\343\200\202\n* **\343\203\217\343\203\252\343\203\274\343\203\235\343\203\203\343\202\277\343\203\274\343\202\267\343\203\252\343\203\274\343\202\272:** \351\255\224\346\263\225\345\255\246\346\240\241\343\202\222\350\210\236\345\217\260\343\201\253\343\201\227\343\201\237\343\200\201\351\255\224\346\263\225\343\201\250\345\217\213\346\203\205\343\200\201\343\201\235\343\201\227\343\201\246\346\210\220\351\225\267\343\202\222\346\217\217\343\201\204\343\201\237\343\202\267\343\203\252\343\203\274\343\202\272\344\275\234\345\223\201\343\201\247\343\201\231\343\200\202\n* **\343\202\262\343\203\274\343\203\240\343\203\273\343\202\252\343\203\226\343\203\273\343\202\271\343\203\255\343\203\274\343\203\263\343\202\272:** \344\270\255\344\270\226\343\203\225\343\202\241\343\203\263\343\202\277\343\202\270\343\203\274\343\201\256\344\270\226\347\225\214\350\246\263\343\202\222\343\200\201\345\243\256\345\244\247\343\201\252\343\202\271\343\202\261\343\203\274\343\203\253\343\201\247\346\217\217\343\201\204\343\201\237\343\203\211\343\203\251\343\203\236\343\202\267\343\203\252\343\203\274\343\202\272\343\201\247\343\201\231\343\200\202\n* **\343\202\267\343\203\243\343\202\266\343\203\240\357\274\201:** \345\244\247\344\272\272\343\201\253\343\201\252\343\202\212\343\201\237\343\201\217\343\201\252\343\201\204\345\260\221\345\271\264\343\201\214\343\200\201\351\255\224\346\263\225\343\201\256\350\250\200\350\221\211\343\201\247\343\202\271\343\203\274\343\203\221\343\203\274\343\203\222\343\203\274\343\203\255\343\203\274\343\201\253\345\244\211\350\272\253\343\201\231\343\202\213\343\200\201\343\202\263\343\203\237\343\202\253\343\203\253\343\201\252\343\202\242\343\202\257\343\202\267\343\203\247\343\203\263\346\230\240\347\224\273\343\201\247\343\201\231\343\200\202\n* **\343\202\271\343\202\277\343\203\274\343\202\246\343\202\251\343\203\274\343\202\272\343\202\267\343\203\252\343\203\274\343\202\272:** \345\272\203\345\244\247\343\201\252\345\256\207\345\256\231\343\202\222\350\210\236\345\217\260\343\201\253\343\201\227\343\201\237\343\200\201SF\343\203\225\343\202\241\343\203\263\343\202\277\343\202\270\343\203\274\346\230\240\347\224\273\343\201\256\351\207\221\345\255\227\345\241\224\343\201\247\343\201\231\343\200\202\n\n**\345\206\222\351\231\272\343\202\204\350\213\261\351\233\204\350\255\232\343\201\214\345\245\275\343\201\215\343\201\252\346\226\271\345\220\221\343\201\221:**\n\n* **\343\202\244\343\203\263\343\203\207\343\202\243\343\203\273\343\202\270\343\203\247\343\203\274\343\203\263\343\202\272\343\202\267\343\203\252\343\203\274\343\202\272:** \350\200\203\345\217\244\345\255\246\350\200\205\343\201\256\343\202\244\343\203\263\343\203\207\343\202\243\343\203\273\343\202\270\343\203\247\343\203\274\343\203\263\343\202\272\343\201\214\343\200\201\344\270\226\347\225\214\344\270\255\343\202\222\345\206\222\351\231\272\343\201\231\343\202\213\343\202\242\343\202\257\343\202\267\343\203\247\343\203\263\343\202\242\343\203\211\343\203\231\343\203\263\343\203\201\343\203\243\343\203\274\346\230\240\347\224\273\343\201\247\343\201\231\343\200\202\n* **\343\203\221\343\202\244\343\203\254\343\203\274\343\203\204\343\203\273\343\202\252\343\203\226\343\203\273\343\202\253\343\203\252\343\203\223\343\202\242\343\203\263\343\202\267\343\203\252\343\203\274\343\202\272:** \346\265\267\350\263\212\343\201\256\345\206\222\351\231\272\343\202\222\346\217\217\343\201\204\343\201\237\343\200\201\345\243\256\345\244\247\343\201\252\343\202\242\343\202\257\343\202\267\343\203\247\343\203\263\343\202\242\343\203\211\343\203\231\343\203\263\343\203\201\343\203\243\343\203\274\346\230\240\347\224\273\343\201\247\343\201\231\343\200\202\n* **\343\202\242\343\203\231\343\203\263\343\202\270\343\203\243\343\203\274\343\202\272\343\202\267\343\203\252\343\203\274\343\202\272:** \343\202\271\343\203\274\343\203\221\343\203\274\343\203\222\343\203\274\343\203\255\343\203\274\343\201\237\343\201\241\343\201\214\351\233\206\347\265\220\343\201\227\343\200\201\345\234\260\347\220\203\343\202\222\345\256\210\343\202\213\343\202\242\343\202\257\343\202\267\343\203\247\343\203\263\346\230\240\347\224\273\343\201\247\343\201\231\343\200\202\n* **\343\203\257\343\202\244\343\203\253\343\203\211\343\203\273\343\202\271\343\203\224\343\203\274\343\203\211\343\202\267\343\203\252\343\203\274\343\202\272:** \343\203\211\346\264\276\346\211\213\343\201\252\343\202\253\343\203\274\343\202\242\343\202\257\343\202\267\343\203\247\343\203\263\343\201\250\345\217\213\346\203\205\343\202\222\346\217\217\343\201\204\343\201\237\343\200\201\347\210\275\345\277\253\343\201\252\343\202\267\343\203\252\343\203\274\343\202\272\344\275\234\345\223\201\343\201\247\343\201\231\343\200\202\n* **\343\202\255\343\203\263\343\202\260\343\203\200\343\203\240\343\202\267\343\203\252\343\203\274\343\202\272:** \344\270\255\345\233\275\343\201\256\346\255\264\345\217\262\343\202\222\350\210\236\345\217\260\343\201\253\343\201\227\343\201\237\343\200\201\345\243\256\345\244\247\343\201\252\346\210\246\343\201\204\343\202\222\346\217\217\343\201\204\343\201\237\346\230\240\347\224\273\343\201\247\343\201\231\343\200\202\n\n**\343\201\235\343\201\256\344\273\226\343\200\201\343\203\255\343\203\274\343\203\211\343\203\273\343\202\252\343\203\226\343\203\273\343\202\266\343\203\273\343\203\252\343\203\263\343\202\260\343\202\204\343\203\233\343\203\223\343\203\203\343\203\210\343\201\250\345\205\261\351\200\232\347\202\271\343\201\256\343\201\202\343\202\213\344\275\234\345\223\201:**\n\n* **\346\214\207\350\274\252\347\211\251\350\252\236 (\343\202\242\343\203\213\343\203\241\347\211\210):** \343\203\255\343\203\274\343\203\211\343\203\273\343\202\252\343\203\226\343\203\273\343\202\266\343\203\273\343\203\252\343\203\263\343\202\260\343\202\222\343\202\242\343\203\213\343\203\241\343\203\274\343\202\267\343\203\247\343\203\263\345\214\226\343\201\227\343\201\237\344\275\234\345\223\201\343\201\247\343\201\231\343\200\202\345\216\237\344\275\234\343\201\256\344\270\226\347\225\214\350\246\263\343\202\222\345\277\240\345\256\237\343\201\253\345\206\215\347\217\276\343\201\227\343\201\237\343\200\201\347\276\216\343\201\227\343\201\204\346\230\240\345\203\217\343\201\214\351\255\205\345\212\233\343\201\247\343\201\231\343\200\202\n* **\343\203\233\343\203\223\343\203\203\343\203\210: \343\201\202\343\202\213\343\201\204\343\201\257\343\200\201\350\241\214\343\201\215\346\235\245\343\201\231\343\202\213\346\227\205:** \343\203\255\343\203\274\343\203\211\343\203\273\343\202\252\343\203\226\343\203\273\343\202\266\343\203\273\343\203\252\343\203\263\343\202\260\343\201\256\345\211\215\346\227\245\350\255\232\343\201\250\343\201\252\343\202\213\347\211\251\350\252\236\343\201\247\343\200\201\343\203\233\343\203\223\343\203\203\343\203\210\346\227\217\343\201\256\343\203\223\343\203\253\343\203\234\343\203\273\343\203\220\343\202\256\343\203\263\343\202\272\343\201\214\343\200\201\346\214\207\350\274\252\343\202\222\346\211\213\343\201\253\345\205\245\343\202\214\343\202\213\343\201\276\343\201\247\343\201\256\345\206\222\351\231\272\343\202\222\346\217\217\343\201\204\343\201\246\343\201\204\343\201\276\343\201\231\343\200\202\n\n\343\201\223\343\202\214\343\202\211\343\201\256\346\230\240\347\224\273\344\273\245\345\244\226\343\201\253\343\202\202\343\200\201\345\244\252\351\203\216\343\201\225\343\202\223\343\201\256\345\245\275\343\201\277\343\201\253\345\220\210\343\201\206\344\275\234\345\223\201\343\201\257\343\201\237\343\201\217\343\201\225\343\202\223\343\201\202\343\202\212\343\201\276\343\201\231\343\200\202\343\202\202\343\201\227\343\200\201\347\211\271\345\256\232\343\201\256\343\202\270\343\203\243\343\203\263\343\203\253\343\202\204\343\203\206\343\203\274\343\203\236\343\201\252\343\201\251\343\200\201\344\275\225\343\201\213\345\245\275\343\201\277\343\201\214\343\201\202\343\202\214\343\201\260\346\225\231\343\201\210\343\201\246\343\201\217\343\201\240\343\201\225\343\201\204\343\200\202\343\202\210\343\202\212\345\205\267\344\275\223\347\232\204\343\201\252\346\217\220\346\241\210\343\202\222\343\201\225\343\201\233\343\201\246\343\201\204\343\201\237\343\201\240\343\201\215\343\201\276\343\201\231\343\200\202"
}
]
from pprint import pprint
# テキストをUnicodeデコードして表示
for m in chat.history:
print(m.to_dict())
{'role': 'user', 'parts': [{'text': '私の名前は太郎といいます。あなたは私の個人アシスタントです。私の好きな映画はロード・オブ・ザ・リングとホビットです。\n\n私が好きそうな他の映画を提案してください。\n'}]}
{'role': 'model', 'parts': [{'text': '太郎さん、こんにちは!ロード・オブ・ザ・リングとホビットがお好きとのことですね!素晴らしいチョイスです。では、太郎さんの好みに合いそうな映画をいくつか提案させていただきます。\n\n**ファンタジー要素が強い作品:**\n\n* **ナルニア国物語:** 魔法と冒険が詰まった子供向けファンタジー映画ですが、大人も楽しめる要素がたくさんあります。\n* **ハリーポッターシリーズ:** 魔法学校を舞台にした、魔法と友情、そして成長を描いたシリーズ作品です。\n* **ゲーム・オブ・スローンズ:** 中世ファンタジーの世界観を、壮大なスケールで描いたドラマシリーズです。\n* **シャザム!:** 大人になりたくない少年が、魔法の言葉でスーパーヒーローに変身する、コミカルなアクション映画です。\n* **スターウォーズシリーズ:** 広大な宇宙を舞台にした、SFファンタジー映画の金字塔です。\n\n**冒険や英雄譚が好きな方向け:**\n\n* **インディ・ジョーンズシリーズ:** 考古学者のインディ・ジョーンズが、世界中を冒険するアクションアドベンチャー映画です。\n* **パイレーツ・オブ・カリビアンシリーズ:** 海賊の冒険を描いた、壮大なアクションアドベンチャー映画です。\n* **アベンジャーズシリーズ:** スーパーヒーローたちが集結し、地球を守るアクション映画です。\n* **ワイルド・スピードシリーズ:** ド派手なカーアクションと友情を描いた、爽快なシリーズ作品です。\n* **キングダムシリーズ:** 中国の歴史を舞台にした、壮大な戦いを描いた映画です。\n\n**その他、ロード・オブ・ザ・リングやホビットと共通点のある作品:**\n\n* **指輪物語 (アニメ版):** ロード・オブ・ザ・リングをアニメーション化した作品です。原作の世界観を忠実に再現した、美しい映像が魅力です。\n* **ホビット: あるいは、行き来する旅:** ロード・オブ・ザ・リングの前日譚となる物語で、ホビット族のビルボ・バギンズが、指輪を手に入れるまでの冒険を描いています。\n\nこれらの映画以外にも、太郎さんの好みに合う作品はたくさんあります。もし、特定のジャンルやテーマなど、何か好みがあれば教えてください。より具体的な提案をさせていただきます。'}]}
マルチモーダル
Gemini-1.5はProもFlashもマルチモーダルなので、プロンプトに
- テキスト
- 画像
- 動画
を含めることができる。
notebookでは、Colaboratory等で確認がしやすいようなヘルパー関数が用意されているが、ちょっと紐解くために使わずにやる。参考までにヘルパー関数は以下。
notebookで用意されているヘルパー関数
import http.client
import typing
import urllib.request
import IPython.display
from PIL import Image as PIL_Image
from PIL import ImageOps as PIL_ImageOps
from vertexai.generative_models import Image, Part
def display_images(
images: typing.Iterable[Image],
max_width: int = 600,
max_height: int = 350,
) -> None:
for image in images:
pil_image = typing.cast(PIL_Image.Image, image._pil_image)
if pil_image.mode != "RGB":
# RGBはすべてのJupyter環境でサポートされている(例:RGBAはまだサポートされていない)
pil_image = pil_image.convert("RGB")
image_width, image_height = pil_image.size
if max_width < image_width or max_height < image_height:
# ノートブックの画像を小さく表示するためにサイズを変更する
pil_image = PIL_ImageOps.contain(pil_image, (max_width, max_height))
IPython.display.display(pil_image)
def get_image_bytes_from_url(image_url: str) -> bytes:
with urllib.request.urlopen(image_url) as response:
response = typing.cast(http.client.HTTPResponse, response)
image_bytes = response.read()
return image_bytes
def load_image_from_url(image_url: str) -> Image:
image_bytes = get_image_bytes_from_url(image_url)
return Image.from_bytes(image_bytes)
def get_url_from_gcs(gcs_uri: str) -> str:
# gcsのuriを画像表示用のurlに変換する。
url = "https://storage.googleapis.com/" + gcs_uri.replace("gs://", "").replace(
" ", "%20"
)
return url
def print_multimodal_prompt(contents: list):
"""
送信されるコンテンツが与えられたら、
読みやすくするために、完全なマルチモーダルプロンプトを出力する。
"""
for content in contents:
if isinstance(content, Image):
display_images([content])
elif isinstance(content, Part):
url = get_url_from_gcs(content.file_data.file_uri)
IPython.display.display(load_image_from_url(url))
else:
print(content)
ローカル画像とテキストから、テキストを生成する
まずはローカルにある画像を読み込ませて、説明させてみる。以下の画像を使う。

from vertexai.generative_models import GenerativeModel, Image
# Google Cloud Storageから画像をダウンロードする
! gsutil cp "gs://cloud-samples-data/generative-ai/image/320px-Felis_catus-cat_on_snow.jpg" ./image.jpg
# ローカルファイルからロードする
image = Image.load_from_file("image.jpg")
# コンテンツを準備する
prompt = "このイメージについて説明して。"
contents = [image, prompt]
model = GenerativeModel("gemini-1.5-flash")
responses = model.generate_content(contents, stream=True)
for response in responses:
print(response.text, end="")
白い雪に覆われた地面の上に立っている茶色の縞模様の猫です。猫はカメラの方を見ていて、目は黄色です。猫は足が1本だけ前に出ていて、歩こうとしているように見えます。猫の尻尾は長く、上向きになっています。
ローカルの画像であれば、 vertexai.generative_models.Image.load_from_file()を使って、リクエストできる形で読み込んでくれる。で、読み込んだ画像とテキストをリストにしてgenerate_content()で投げればよいだけ。
Cloud Stroge上の画像とテキストから、テキストを生成する
Cloud Stroge上の画像はCloud Storage URIをそのまま指定できる。ただし以下の条件がある。
-
mime_typeフィールドを指定する必要がある。- サポートされている画像のMIMEタイプ:
image/pngとimage/jpeg
- サポートされている画像のMIMEタイプ:
- クラウドストレージオブジェクトのURIは常に
gs://で始まる必要がある。
以下のCloud Storage上の画像(Cloud Storage URI: gs://cloud-samples-data/generative-ai/image/boats.jpeg)を使う。
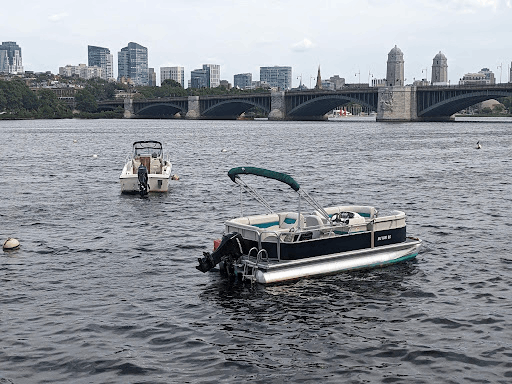
from vertexai.generative_models import GenerativeModel, Part
# Cloud StorageのURIから画像を読み込む
gcs_uri = "gs://cloud-samples-data/generative-ai/image/boats.jpeg"
# コンテンツを準備する
image = Part.from_uri(gcs_uri, mime_type="image/jpeg")
prompt = "このシーンを説明して。"
contents = [image, prompt]
model = GenerativeModel("gemini-1.5-flash")
responses = model.generate_content(contents, stream=True)
for response in responses:
print(response.text, end="")
この写真は、ボストンにあるチャールズ川のウォーターフロントからのものです。写真には、2隻のボートとチャールズ川に架かる橋が写っています。背景には、ボストン市の中心部にあるいくつかの高層ビルが写っています。
Cloud Storage URIの場合は、vertexai.generative_models.Part.from_uri()を使えば良い。MIMEタイプの指定は必須。
画像URLとテキストから、テキストを生成する
画像は、画像のURLでも指定できる。画像データをバイト形式で取得して、vertexai.generative_models.Image.from_bytes()でリクエストできる形にして読み込む様子。
ここでは1つ前で使った画像が静的サイトホスティングのURLで提供されているのでそれを使う。
import http.client
import typing
import urllib.request
from vertexai.generative_models import GenerativeModel, Image
image_url = "https://storage.googleapis.com/cloud-samples-data/generative-ai/image/boats.jpeg"
def get_image_bytes_from_url(image_url: str) -> bytes:
"""指定されたURLから画像データをバイト形式で取得する"""
with urllib.request.urlopen(image_url) as response:
response = typing.cast(http.client.HTTPResponse, response)
image_bytes = response.read()
return image_bytes
def load_image_from_url(image_url: str) -> Image:
"""
バイト形式の画像データを、vertexai.generative_models.Imageの
from_bytes()を使って、モデルに送信できる形式にする
"""
image_bytes = get_image_bytes_from_url(image_url)
return Image.from_bytes(image_bytes)
image = load_image_from_url(image_url)
# コンテンツを準備
prompt = "このシーンを説明して。"
contents = [image, prompt]
model = GenerativeModel("gemini-1.5-flash")
responses = model.generate_content(contents, stream=True)
for response in responses:
print(response.text, end="")
これは、ボストン市のチャールズ川にかかる橋の上から撮影した写真です。川には2艘のボートが浮かんでいます。1艘は小さいモーターボートで、もう1艘は大きなポントゥーンボートです。川は穏やかで、水は濃い青色をしています。バックグラウンドにはボストンの街並みが広がっています。左側にはいくつかの高層ビルが見え、右側には橋のアーチがいくつか見えます。空は薄曇りで、日差しが差し込んでいます。
複数の画像とテキストを組み合わせたfew-shotプロンプト
画像とテキストを複数使って、few-shotプロンプトが行える。
以下の2つの画像とテキストをfew-shotとして使う。
画像1とそのプロンプト

{"city": "ロンドン", "Landmark:", "ビッグベン"}
画像2とそのプロンプト

{"city": "パリ", "Landmark:", "エッフェル塔"}
そして以下の画像に対してテキストを生成させる。

import http.client
import typing
import urllib.request
from vertexai.generative_models import GenerativeModel, Image
def get_image_bytes_from_url(image_url: str) -> bytes:
"""指定されたURLから画像データをバイト形式で取得する"""
with urllib.request.urlopen(image_url) as response:
response = typing.cast(http.client.HTTPResponse, response)
image_bytes = response.read()
return image_bytes
def load_image_from_url(image_url: str) -> Image:
"""
バイト形式の画像データを、vertexai.generative_models.Imageの
from_bytes()を使って、モデルに送信できるオブジェクトにする
"""
image_bytes = get_image_bytes_from_url(image_url)
return Image.from_bytes(image_bytes)
# URLから画像を読み込む
image1_url = "https://storage.googleapis.com/github-repo/img/gemini/intro/landmark1.jpg"
image2_url = "https://storage.googleapis.com/github-repo/img/gemini/intro/landmark2.jpg"
image3_url = "https://storage.googleapis.com/github-repo/img/gemini/intro/landmark3.jpg"
image1 = load_image_from_url(image1_url)
image2 = load_image_from_url(image2_url)
image3 = load_image_from_url(image3_url)
# プロンプトを準備
prompt1 = """{"city": "ロンドン", "Landmark:", "ビッグベン"}"""
prompt2 = """{"city": "パリ", "Landmark:", "エッフェル塔"}"""
# コンテンツを準備
contents = [image1, prompt1, image2, prompt2, image3]
responses = model.generate_content(contents, stream=True)
for response in responses:
print(response.text, end="")
{"city": "ローマ", "Landmark:", "コロッセオ"}
この使い方はとても面白い。
動画からテキストを生成する
入力は動画も可能。ここではCloud Storage URIからの読み込みの例。画像と同様にCloud Storage URIの場合はMIMEタイプの指定も必要になる。
あと、
The bucket that stores the file must be in the same Google Cloud project that's sending the request.
とあるのだけど、このサンプルでは問題ない。Cloud Storage全然わかってないけど、おそらくパブリックに公開されているものなのでOK、自分が持っているコンテンツの場合は同じプロジェクト内のバケットを使えということなのだろうと推測する。
以下の動画を使う。
from vertexai.generative_models import GenerativeModel, Part
# GCSのURI
file_uri = "gs://github-repo/img/gemini/multimodality_usecases_overview/pixel8.mp4"
prompt = """
与えられた映像のみを使って、以下の質問に答えてください:
主人公の職業は?
強調されている電話の主な特徴は何か?
これはどの都市で録画されたか?
回答はJSONフォーマットで返すこと。JSONフォーマットのキーは、英単語の名詞とする。JSONフォーマットの値は日本語で。
"""
video = Part.from_uri(file_uri, mime_type="video/mp4")
contents = [prompt, video]
responses = model.generate_content(contents, stream=True)
for response in responses:
print(response.text, end="")
{
"occupation": "フォトグラファー",
"phone_feature": "夜景モード",
"city": "東京"
}
from vertexai.generative_models import GenerativeModel, Part
file_uri = "gs://github-repo/img/gemini/multimodality_usecases_overview/pixel8.mp4"
prompt = """
与えられた映像をタイムラインごとに要約してください。
出力は
タイムライン: 要約内容
としてください。
"""
video = Part.from_uri(file_uri, mime_type="video/mp4")
contents = [prompt, video]
responses = model.generate_content(contents, stream=True)
for response in responses:
print(response.text, end="")
00:00-00:01: 東京の街並み。
00:01-00:04: 写真家の島田紗栄子さんが自己紹介をしています。
00:05-00:12: 東京の夜の街は、昼間とは全く違うと島田紗栄子さんは話しています。
00:13-00:20: 新しいPixelのビデオブースト機能について説明しています。暗い場所で撮影すると、夜間モードが起動し、画質がさらに向上します。
00:21-00:27: 島田紗栄子さんは、東京へ引っ越して初めて住んだ街、三茶を撮影しています。
00:28-00:38: 三茶の街並みを撮影しています。
00:39-00:41: 三茶の街の看板などを撮影しています。
00:42-00:51: 三茶の街の様々な場所を撮影しています。
00:52-00:55: 島田紗栄子さんは渋谷にきました。
00:56-00:58: 渋谷のスクランブル交差点などを撮影しています。
なお、URLで読み込む方法はリファレンス見ても見当たらなかった。
マルチモーダルオブジェクトの扱い方が直感的でわかりやすいと感じた。特にOpenAIやAnthropicのマルチモーダルでは動画はフレーム画像としてしか送れないので、まるっと送れるというのはとても便利。ただ調べてみた限り、それができるのはGCS上の動画ファイルのみという制約がある点に注意。
画像や動画の場合、コンテキストサイズ内とそれを超えた場合で料金が違うだけで、比較的料金計算が計算しやすそうな印象を持った。
ここまでざっと流すぐらいならば数十円程度でできると思う(自分の請求額から推測)
ちょっと反映されるまで時間がかかるのかも。後で確認する。
Gemini を使用したマルチモーダル ユースケース
マルチモーダルさらに色々やってみようという感じのnotebook。引き続きGemini 1.5 Flashでやっていく。
Vertex AIへの接続
import vertexai
PROJECT_ID="YOUR_PROJECT_ID"
REGION="asia-northeast1"
vertexai.init(
project=PROJECT_ID,
location=REGION
)
事前準備
インポートをまるっと。
from vertexai.generative_models import (
GenerationConfig,
GenerativeModel,
Image,
Part,
)
モデルを定義。
model = GenerativeModel("gemini-1.5-flash")
あと前回使わなかったnotebook用のヘルパー関数を今回は使う。
import http.client
import typing
import urllib.request
import IPython.display
from PIL import Image as PIL_Image
from PIL import ImageOps as PIL_ImageOps
def display_images(
images: typing.Iterable[Image],
max_width: int = 600,
max_height: int = 350,
) -> None:
for image in images:
pil_image = typing.cast(PIL_Image.Image, image._pil_image)
if pil_image.mode != "RGB":
# RGBはすべてのJupyter環境でサポートされている(例:RGBAはまだサポートされていない)
pil_image = pil_image.convert("RGB")
image_width, image_height = pil_image.size
if max_width < image_width or max_height < image_height:
# notebookで、画像を小さく表示するためにサイズを変更する
pil_image = PIL_ImageOps.contain(pil_image, (max_width, max_height))
IPython.display.display(pil_image)
def get_image_bytes_from_url(image_url: str) -> bytes:
with urllib.request.urlopen(image_url) as response:
response = typing.cast(http.client.HTTPResponse, response)
image_bytes = response.read()
return image_bytes
def load_image_from_url(image_url: str) -> Image:
image_bytes = get_image_bytes_from_url(image_url)
return Image.from_bytes(image_bytes)
def display_content_as_image(content: str | Image | Part) -> bool:
if not isinstance(content, Image):
return False
display_images([content])
return True
def display_content_as_video(content: str | Image | Part) -> bool:
if not isinstance(content, Part):
return False
part = typing.cast(Part, content)
file_path = part.file_data.file_uri.removeprefix("gs://")
video_url = f"https://storage.googleapis.com/{file_path}"
IPython.display.display(IPython.display.Video(video_url, width=600))
return True
def print_multimodal_prompt(contents: list[str | Image | Part]):
"""
送信されるコンテンツが与えられたら、
読みやすくするために、完全なマルチモーダルプロンプトを出力する。
"""
for content in contents:
if display_content_as_image(content):
continue
if display_content_as_video(content):
continue
print(content)
複数の画像にまたがって画像を理解する
1つ前の例で複数の画像を使ったパターンがあったが、これはそのバリエーション。
- 果物の画像

- 果物の価格表の画像(元は英語・ドルで書かれていたが、日本語に書き換えた)
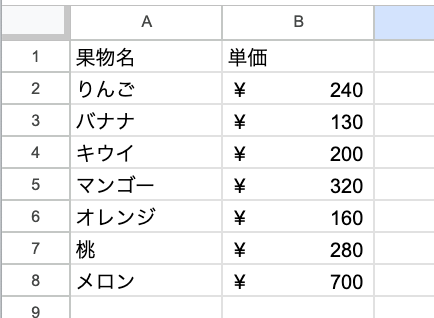
を使って、食料品の合計金額を計算する。
image_grocery_url = "https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/banana-apple.jpg"
image_grocery = load_image_from_url(image_grocery_url)
image_prices = Image.load_from_file("prices_jp.png")
instructions = "指示: 次の、果物が含まれている画像について考えてください:"
prompt1 = "以下の価格表を踏まえると、果物に支払う料金はいくらになりますか?"
prompt2 = """
以下のステップで質問に答えよう:
ステップ1:最初の画像にどんな果物が写っているかを確認する。
ステップ2:それぞれの果物の数量を数える。
ステップ3:最初の画像に写っているそれぞれの食料品について、価格表でその食料品の価格をチェックする。
ステップ4: 果物の種類ごとに小計価格を計算する。
ステップ5: 小計を使って果物の合計価格を計算する。
どのような手順を踏んだか答えなさい:
"""
contents = [
instructions,
image_grocery,
prompt1,
image_prices,
prompt2,
]
responses = model.generate_content(contents, stream=True)
print("-------プロンプト--------")
print_multimodal_prompt(contents)
print("\n-------レスポンス--------")
for response in responses:
print(response.text, end="")

回答
画像にはバナナとリンゴがあります。バナナは2本、リンゴは3つです。
価格表から、バナナは1本130円、リンゴは1個200円です。
バナナの合計金額は 130 円 × 2 本 = 260 円です。
リンゴの合計金額は 200 円 × 3 個 = 600 円です。
したがって、果物の合計金額は 260 円 + 600 円 = 860 円です。
もう一回。
画像にはバナナとリンゴが写っています。
- バナナは 2 本あります。
- リンゴは 2 個あります。
価格表でバナナは 130 円、リンゴは 240 円です。
バナナの小計は 130 円 x 2 = 260 円です。
リンゴの小計は 240 円 x 2 = 480 円です。
果物の合計価格は 260 円 + 480 円 = 740 円です。
結構な頻度で、果物の個数を数え間違えたり、価格を間違えていたりする。Gemini 1.5 Proにしてみた。
(snip)
model = GenerativeModel("gemini-1.5-pro")
(snip)
画像内の果物の合計金額を計算するために以下の手順を踏みました。
1. **画像内の果物を識別する**: 画像にはバナナとリンゴが写っています。
2. **それぞれの果物の数を数える**: バナナが3本、リンゴが3個あります。
3. **価格表でそれぞれの果物の価格を調べる**: バナナは1本130円、リンゴは1個240円です。
4. **それぞれの果物の合計金額を計算する**: バナナの合計金額は130円/本 * 3本 = 390円です。リンゴの合計金額は240円/個 * 3個 = 720円です。
5. **それぞれの果物の小計金額を合計して果物の合計金額を計算する**: 果物の合計金額は390円 + 720円 = 1110円です。
したがって、果物の合計金額は**1110円**です。
何度かやってみたけども、ちょいちょい間違える。何度か繰り返してみた印象だと、
- Flashだと、画像内の果物の個数を間違えたり、単価を間違えたり、両方でよく間違える。
- Proだと、単価はほとんど間違えないけど、個数を間違えることが多い。
という印象。
元の英語の価格表に変えてみてもこの印象は同じだけど、Flash+日本語で間違えていた価格表は英語に変えると間違いが少なくなった。この点を踏まえると、
- 画像内のオブジェクトの認識は、Proでも間違えることがある。
- 画像内の文字の認識精度は、英語のほうが日本語よりも認識精度が高い。
という感じがした。画像の解像度とかそういうのもあるのかもしれないけど。
画面とインターフェイスを理解する
家電製品のインタフェース画像から、ボタンの配置や特定の操作について生成させてみる。
以下のストーブの画像を使う。

image_stove_url = "https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/stove.jpg"
image_stove = load_image_from_url(image_stove_url)
prompt = """この電気器具の時計をリセットする方法を教えて下さい。
日本語で手順を提供してください。
手順にボタンが含まれている場合は、それらのボタンが物理的にどこに配置されているかも説明すること。
"""
contents = [image_stove, prompt]
model = GenerativeModel("gemini-1.5-flash")
responses = model.generate_content(contents, stream=True)
print("-------Prompt--------")
print_multimodal_prompt(contents)
print("\n-------Response--------")
for response in responses:
print(response.text, end="")

この電気器具の時計をリセットするには、以下の手順に従ってください。
1. **「クリア/オフ」** ボタンを押します。このボタンは、電気器具の画面の右下隅にあります。
2. 時計がリセットされます。
時計をリセットする必要がある理由がわからない場合は、電気器具の取扱説明書を参照してください。
ボタン配置を拡大してみた。

まあ右下隅ってのは中央部のボタン配置からすれば間違ってはいないのだけど。
ここは結構何度か繰り返してみたのだけど、元のnotebookに書かれているようなリッチな回答はなかなか得られなかった。上の回答もたまたま。Proに変えても同じだったので、結構難易度は高そうな印象で、注釈にもある通り、もっと情報を与えてやる必要がありそう。
Note: The response may not be completely accurate, as the model may hallucinate; however, the model is able to identify the location of buttons and translate in a single query. To mitigate hallucinations, one approach is to ground the LLM with retrieval-augmented generation, which is outside the scope of this notebook.
少しプロンプトを変えてみた。
(snip)
prompt = """この電化製品の時計をリセットする方法がわからない。
まずはどのボタンを試してみるべきだろう?その場合ボタンの物理的な配置も教えて欲しい。
"""
(snip)
このオーブンの時計をリセットするには、"CLEAR OFF" ボタンを押す必要があります。それは数字の 0 のすぐ下にあり、"START" ボタンの隣にあります。
微妙に間違ってるけど、なんとなくの配置は認識してるのかなーというところ。
技術的な図のエンティティ関係を理解する
ER図を読ませて、エンティティとリレーションシップを解析させてみる。

image_er_url = "https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/er.png"
image_er = load_image_from_url(image_er_url)
prompt = "このER図におけるエンティティと関係を文書化しなさい。説明は日本語で。"
contents = [prompt, image_er]
# 低いtemperatureを指定して、より決定論的な設定を使用する。
generation_config = GenerationConfig(
temperature=0.1,
top_p=0.8,
top_k=40,
candidate_count=1,
max_output_tokens=2048,
)
model = GenerativeModel("gemini-1.5-flash")
responses = model.generate_content(
contents,
generation_config=generation_config,
stream=True,
)
print("-------Prompt--------")
print_multimodal_prompt(contents)
print("\n-------Response--------")
for response in responses:
print(response.text, end="")
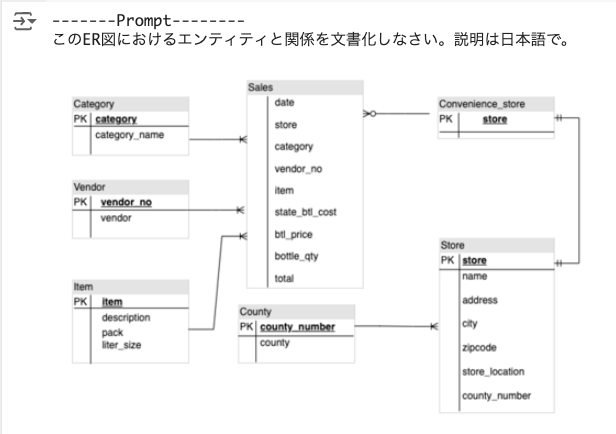
## ER図の説明
このER図は、コンビニエンスストアの販売データを表しています。
**エンティティ:**
* **Category:** 商品のカテゴリを表します。
* **category:** カテゴリの識別子 (主キー)
* **category_name:** カテゴリの名前
* **Vendor:** 商品の仕入先を表します。
* **vendor_no:** 仕入先の識別子 (主キー)
* **vendor:** 仕入先の名前
* **Item:** 商品を表します。
* **item:** 商品の識別子 (主キー)
* **description:** 商品の説明
* **pack:** 商品のパッケージ
* **liter_size:** 商品の容量
* **County:** 都道府県を表します。
* **county_number:** 都道府県の識別子 (主キー)
* **county:** 都道府県の名前
* **Convenience_store:** コンビニエンスストアを表します。
* **store:** コンビニエンスストアの識別子 (主キー)
* **Store:** 店舗を表します。
* **store:** 店舗の識別子 (主キー)
* **name:** 店舗の名前
* **address:** 店舗の住所
* **city:** 店舗の市区町村
* **zipcode:** 店舗の郵便番号
* **store_location:** 店舗の場所
* **county_number:** 店舗の所属する都道府県
**リレーションシップ:**
* **Category** と **Sales:** 1対多の関係。1つのカテゴリは複数の販売記録を持つことができます。
* **Vendor** と **Sales:** 1対多の関係。1つの仕入先は複数の販売記録を持つことができます。
* **Item** と **Sales:** 1対多の関係。1つの商品は複数の販売記録を持つことができます。
* **County** と **Store:** 1対多の関係。1つの都道府県は複数の店舗を持つことができます。
* **Convenience_store** と **Sales:** 1対1の関係。1つのコンビニエンスストアは1つの販売記録を持ちます。
**その他の情報:**
* **Sales** エンティティには、販売日、店舗、カテゴリ、仕入先、商品、州税、ボトル価格、ボトル数量、合計金額などの情報が含まれています。
* **Store** エンティティには、店舗名、住所、市区町村、郵便番号、場所、所属する都道府県などの情報が含まれています。
**補足:**
* このER図は、コンビニエンスストアの販売データの一般的な例です。実際のデータモデルは、ビジネス要件に応じて異なる場合があります。
* このER図は、データベース設計の最初のステップです。データベース設計には、データの正規化、インデックスの作成、セキュリティ対策などの追加のステップが必要です。
完璧ではないけども、文字の認識は結構しっかりしてる印象がある。
複数の画像に基づくリコメンド
複数のメガネの画像を渡して、自分の顔の形に合うメガネを選んでもらう。
メガネの画像は以下。


image_glasses1_url = "https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/glasses1.jpg"
image_glasses2_url = "https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/glasses2.jpg"
image_glasses1 = load_image_from_url(image_glasses1_url)
image_glasses2 = load_image_from_url(image_glasses2_url)
prompt1 = """
私の顔の形から、どのメガネがおすすめ?
私は楕円形の顔をしている。
----
Glasses 1:
"""
prompt2 = """
----
Glasses 2:
"""
prompt3 = """
----
この決断に至った経緯を説明すること。
私の顔型に基づいたあなたの推薦と、それぞれの理由をJSON形式で提供すること。キーは英語、値は日本語で。
"""
contents = [prompt1, image_glasses1, prompt2, image_glasses2, prompt3]
model = GenerativeModel("gemini-1.5-flash")
responses = model.generate_content(contents, stream=True)
print("-------Prompt--------")
print_multimodal_prompt(contents)
print("\n-------Response--------")
for response in responses:
print(response.text, end="")

楕円形の顔は、額と顎が丸みを帯びているのが特徴です。 どちらのメガネも楕円形の顔に合いますが、以下のように、それぞれに利点があります。
```json
{
"Recommendation": "どちらのメガネもおすすめです。",
"Reason": "楕円形の顔はほとんどのメガネの形状に合うので、どちらのメガネも似合います。",
"Glasses 1": "Glasses 1は、その角張ったフレームが楕円形の顔の丸みを強調し、より洗練された印象を与えます。",
"Glasses 2": "Glasses 2は、丸いフレームが楕円形の顔の自然な曲線を強調し、より優しい印象を与えます。",
"Suggestion": "あなたの好みのスタイルに合わせて選んでください。個性的な印象にしたい場合はGlasses 1、優しい印象にしたい場合はGlasses 2をおすすめします。"
}
```
複数の画像の類似点/相違点を生成
複数の画像を渡して、類似点と相違点をそれぞれリストアップさせる。
同じ場所で少しだけ異なる時間に撮影した2つの画像を渡す。


image_landmark1_url = "https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/landmark1.jpg"
image_landmark2_url = "https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/landmark2.jpg"
image_landmark1 = load_image_from_url(image_landmark1_url)
image_landmark2 = load_image_from_url(image_landmark2_url)
prompt1 = """
次の2つの画像を考えてみよう:
画像1:
"""
prompt2 = """
画像2:
"""
prompt3 = """
1. 画像1には何が写っているか?
2. 2つの画像のどこが似ているか?
3. 写っている内容や人物について、画像1と画像2の違いは何か。
"""
contents = [prompt1, image_landmark1, prompt2, image_landmark2, prompt3]
generation_config = GenerationConfig(
temperature=0.0,
top_p=0.8,
top_k=40,
candidate_count=1,
max_output_tokens=2048,
)
model = GenerativeModel("gemini-1.5-flash")
responses = model.generate_content(
contents,
generation_config=generation_config,
stream=True,
)
print("-------Prompt--------")
print_multimodal_prompt(contents)
print("\n-------Response--------")
for response in responses:
print(response.text, end="")

1. 画像1には、ドイツのミュンヘンにある広場、カールスプラッツが写っています。広場には、建物、人々、街路灯などが写っています。
2. 2つの画像は、同じ場所、同じ角度から撮影されています。建物、人々、街路灯などの配置も全く同じです。
3. 画像1と画像2の違いは、画像1には人が多く写っているのに対し、画像2には人がほとんど写っていないことです。画像1では、広場は活気に満ち溢れているように見えますが、画像2では、静かで空虚な印象を与えます。
ここからは動画の例
動画の説明を生成
以下の動画の内容について質問する。
prompt = """
このビデオには何が映っていますか?
どこに行けば見られますか?
世界でこのように見える場所のトップ5を教えてください。
"""
video = Part.from_uri(
uri="gs://github-repo/img/gemini/multimodality_usecases_overview/mediterraneansea.mp4",
mime_type="video/mp4",
)
contents = [prompt, video]
model = GenerativeModel("gemini-1.5-flash")
responses = model.generate_content(contents, stream=True)
print("-------Prompt--------")
print_multimodal_prompt(contents)
print("\n-------Response--------")
for response in responses:
print(response.text, end="")
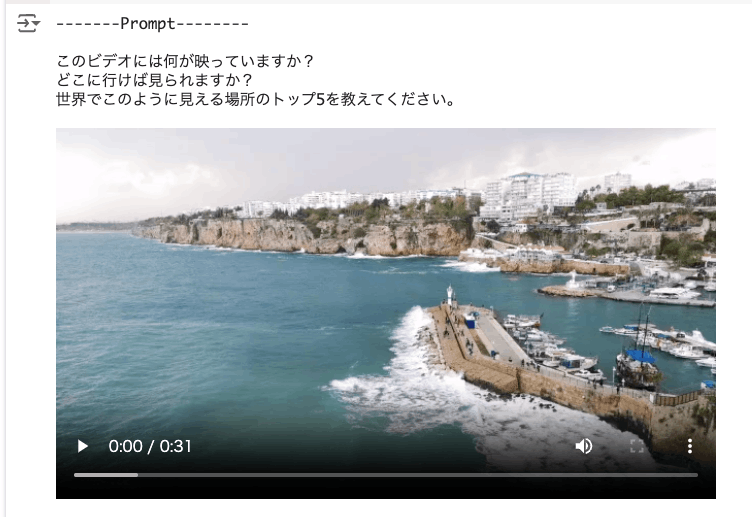
このビデオは、トルコ、アンタルヤの港の空撮です。
この場所は、YouTubeやその他のビデオ共有サイトで、アンタルヤやトルコを検索すれば見つけることができます。
世界中の海沿いの景色はたくさんありますが、いくつか例を挙げます。
1. イタリア、ポルトフィーノ
2. ギリシャ、サントリーニ
3. クロアチア、ドゥブロブニク
4. スペイン、イビサ島
5. フランス、ニース
これらはすべて、独自の美しさを持つ、魅力的な海岸線です。
動画全体からオブジェクトのタグを抽出
動画
prompt = """
ビデオのみを使って以下の質問に答えよ:
- ビデオには何が映っているか?
- ビデオの中のアクションは何か?
- このビデオに最適なタグを10個挙げてください。
"""
video = Part.from_uri(
uri="gs://github-repo/img/gemini/multimodality_usecases_overview/photography.mp4",
mime_type="video/mp4",
)
contents = [prompt, video]
model = GenerativeModel("gemini-1.5-flash")
responses = model.generate_content(contents, stream=True)
print("-------Prompt--------")
print_multimodal_prompt(contents)
print("\n-------Response--------")
for response in responses:
print(response.text, end="")

このビデオには、帽子をかぶった男性が部屋でカメラで写真を撮っている様子が映っています。部屋はコンクリートの壁と木製の家具があり、民族的な装飾が施されています。
ビデオのタグは以下のとおりです。
- 写真
- 写真家
- 旅行
- アドベンチャー
- インスピレーション
- ライフスタイル
- 探検
- アート
- 建築
- デザイン
動画についてさらに質問
最初のnotebookでも使った動画
なお、この動画には音声も含まれていて、notebookには
Note: Although this video contains audio, Gemini does not currently support audio input and will only answer based on the video.
とあるが、これはGemini 1.0 Pro Visionの話で、Gemini 1.5では音声も確か認識されているはず。
prompt = """
ビデオのみを使って以下の質問に答えよ:
主人公の職業は?
強調されている電話の主な特徴は何か?
これはどの都市で録画されたか?
答えをJSONで提供する。キーは英語で、値は日本語で。
"""
video = Part.from_uri(
uri="gs://github-repo/img/gemini/multimodality_usecases_overview/pixel8.mp4",
mime_type="video/mp4",
)
contents = [prompt, video]
model = GenerativeModel("gemini-1.5-flash")
responses = model.generate_content(contents, stream=True)
print("-------Prompt--------")
print_multimodal_prompt(contents)
print("\n-------Response--------")
for response in responses:
print(response.text, end="")
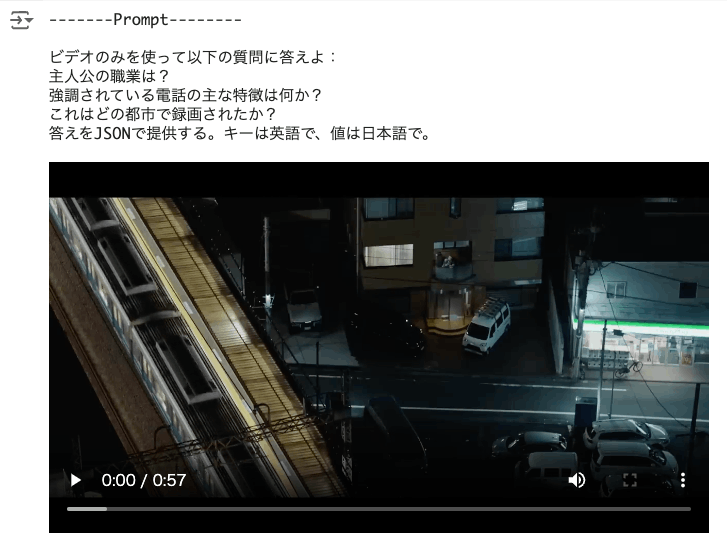
```json
{
"occupation": "写真家",
"phone feature": "ナイトサイト",
"city": "東京"
}
```
音声をちゃんと認識しているか確認してみる。
prompt = """
この動画の音声を文字起こししてください。タイムラインもつけること。環境音なども()で表現すること。
"""
(snip)
-------Response--------
00:00 (電車の走行音)
00:01 島田彩香 です 東京 で フォトグラファー を し て
00:04 い ます
00:05 東京 に は いろんな 顔 が あっ て
00:08 夜 の 東京 は 昼 の 東京 と 全く 違う と 思い ます
00:13 新しい ピクセル に は 動画 ブースト って 機能 が ある ん です けど 暗い ところ だ と 夜景 モード が 作動 し て 画質 が さらに 上がる ん です
00:23 三茶 は 上京 し て 初めて 住ん だ 思い出 の 場所 な ん です
00:29 うん いい 感じ です
00:32 (水滴が落ちた音)
00:37 おお
00:39 お 綺麗
00:44 (お店のBGM)
00:46 (水滴が落ちた音)
00:53 次 は 渋谷 に 来 まし た
00:55 みんな ああ
00:57 ピッピッピッ
映像以外の情報を取得
動画
prompt = """
これはどこの電車ですか?
どこを走っていますか?
駅や停留所は?
"""
video = Part.from_uri(
uri="gs://github-repo/img/gemini/multimodality_usecases_overview/ottawatrain3.mp4",
mime_type="video/mp4",
)
contents = [prompt, video]
model = GenerativeModel("gemini-1.5-flash")
responses = model.generate_content(contents, stream=True)
print("-------Prompt--------")
print_multimodal_prompt(contents)
print("\n-------Response--------")
for response in responses:
print(response.text, end="")

これはオタワの O-Train の電車です。
リドー川を渡り、アルゴンキンパークの近くを走っています。
この区間には、アルゴンキン駅とハーブ・ジャクソン駅があります。
「映像以外」ってのが何を指すのか、画像の土地勘的なものがないと全然わからないw
駅は移ってないようなので、最後の1行がそうなのかも。
一通りやってみた感じだと、
- Flashでも結構頑張ってくれるけど、やはりProのほうが認識精度は上という印象。
- とはいえ、Proでもちょいちょい間違えるので、過信は禁物。
- 画像内の文字の認識は、Pro>Flash,英語>日本語、という感じ
ただ、画像、動画、音声をすべてまるっと処理できるのはホントのマルチモーダルってこれだよなという感が高まった。以下の記事のように議事録の作成とかには使えそう。
あと、この記事に、
gemini-1.5-flashでは、音声データをそのままプロンプトにくっつけて投げることができます。
ただし、鵜呑みにしてファイルをプロンプトにくっつけて投げると、8MBまでの容量制限を受けることになります。
そのため、GCPのCloud Strageにファイルをアップロードして、そのURIをモデルの入力とします。
とあるのだけど、これドキュメントのどこにあるのだろうか?
次はこの辺を。