Vertex AI(Gemini API)でGemini Proを試す
はじめに
はじめまして。機械学習エンジニアをしています、原です。
Google Cloud Champion Innovators(AI/ML)として選出いただき、活動しています。Google Cloud Innovatorsは、Google Cloud開発者/技術者のためのメンバーシッププログラムです。誰でも参加可能ですので、Google Cloudユーザーの方はぜひ参加をおすすめします!
この記事では、2023年12月13日にVertex AIで利用可能になったGemini Proを使います。これから試してみる方の参考になれば幸いです。
Geminiとは
この記事を読んでいる方は既にご存知かもしれませんが、Geminiとは何かを軽く説明します。VertexAI Gemini APIに関してのみをキャッチアップしたい方は「Vertex AI での Gemini Proの概要」からお読みいただければと思います。
Geminiとは、2023年12月6日にGoogleから発表されたマルチモーダルモデルです。テキストおよび画像、音声などのマルチモーダルなデータを同時に認識して理解が可能とされています。最初のバージョンであるGemini1.0では、パラメータ規模が異なるGemini Ultra, Gemini Pro, Gemini Nano の3つのモデルが発表されました。
また、モデルの学習にはTPU v4および、v5eが活用されているようです。これらTPUは既にGoogle Cloudで利用可能です。そして、Geminiの発表とともに、さらにハイパフォーマンスなTPU v5pが発表されました。
3つのモデルの中でも特にGemini Ultraは、多くのベンチマークにて最高精度を出している、OpenAIのGPT-4やGPT-4Vを多くの項目で上回っており、期待が高まっています。Geminiに関しての詳細は、下記の記事やテクニカルレポートから確認出来ます。
Gemini Ultra
3つのモデルをそれぞれ見ていきましょう。
Gemini UltraはGeminiの中で最も大規模なモデルであり、複雑なタスクをこなすことが出来るとされています。
こちらは、2023/12/13時点では利用することは出来ませんが、来年の初めには一部のユーザーが利用可能になる予定のようです。加えて、BardのBard Advancedという形で利用できるようになるようです。
Gemini Pro
こちらが今回の記事のメイントピックです。
Gemini Proは幅広いタスクに対応するモデルと説明されています。Ultraを使うほど複雑なタスクではないが、生成速度とコストを重視したいケースでの選択肢になると考えています。
発表があった2023年12月6日からBardでは利用可能になっています。
また、テクニカルレポートによると、テキストベンチマークの8件中、6件でGPT-3.5を上回っていると報告がされています(結果はAPIを通して2023年11月に収集がされたもののようです)。
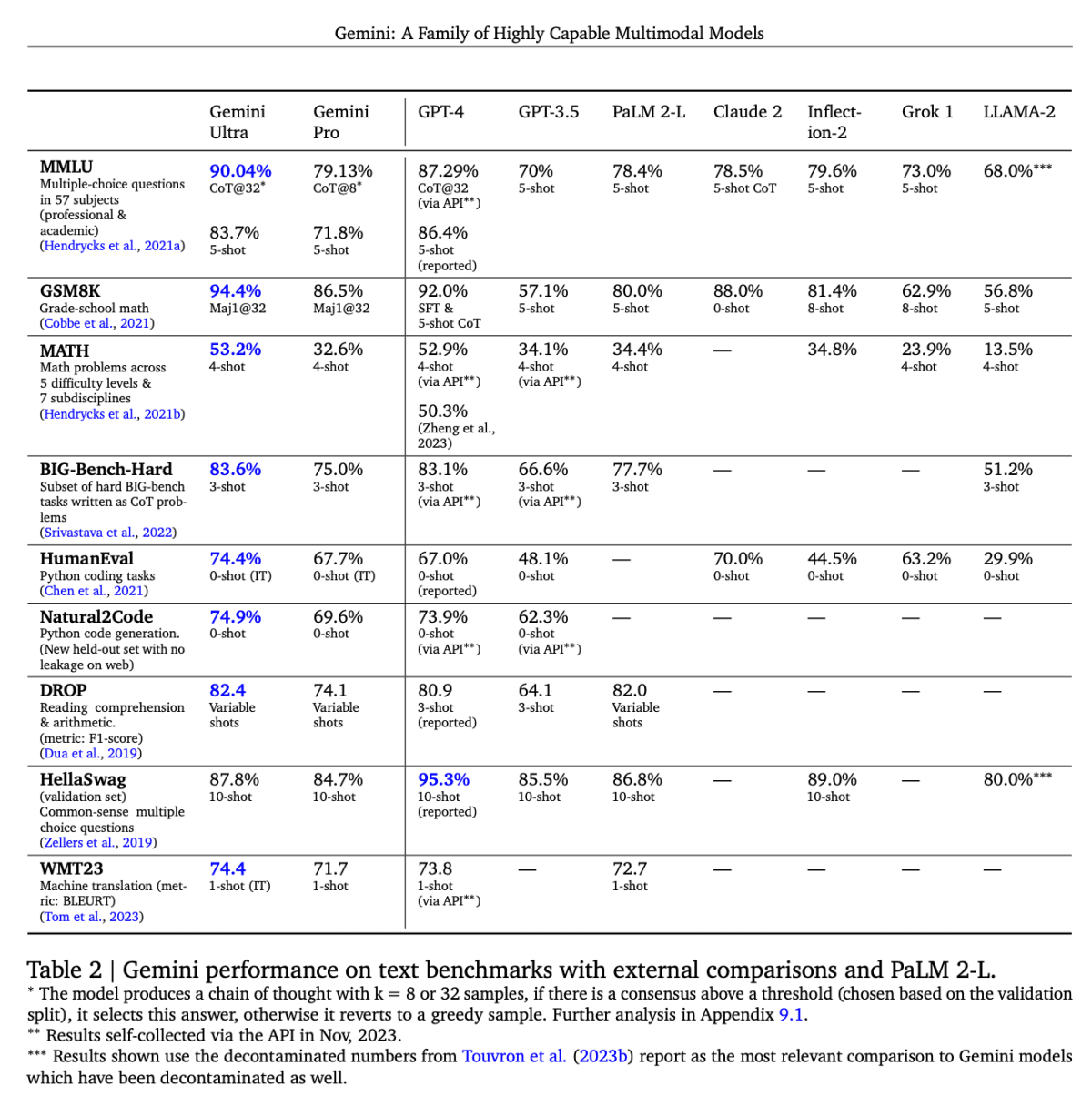
Google DeepMind テクニカルレポート「Gemini: A Family of Highly Capable Multimodal Models」より引用
現在、GPT-3.5の利用で十分なタスクにおいては、こちらで置き換えが可能かもしれません。加えて、GPT-3.5では出来ないマルチモーダルの入力にも対応しています。
そして、執筆時点の2023年12月13日から、Vertex AI Gemini API および Google AI Studioで利用可能となりました。こちらをVertex AIで使ってみるのが、今回のブログの目的です。
Gemini Nano
こちらは、Gemini1.0の中で最も軽量なモデルとなっており、デバイス上でのタスクに最も効率的なモデルと説明されています。Google Pixel 8 Proでは、既に利用可能なようで、レコーダーアプリでの要約やGboardのスマートリプライなどで利用可能になっています(英語版のみ)。
Vertex AI での Gemini Proの概要
それでは今回の本題である、Vertex AI での Gemini Proに話を移します。
モデル
Vertex AI Gemini APIで提供されているGemini Proでは、用途に合わせた2種類のモデルが提供されています。テキストのみを扱うのか、もしくは画像や動画も追加で扱うかによって選択するモデルが異なります。ともに、東京リージョンで利用可能です。
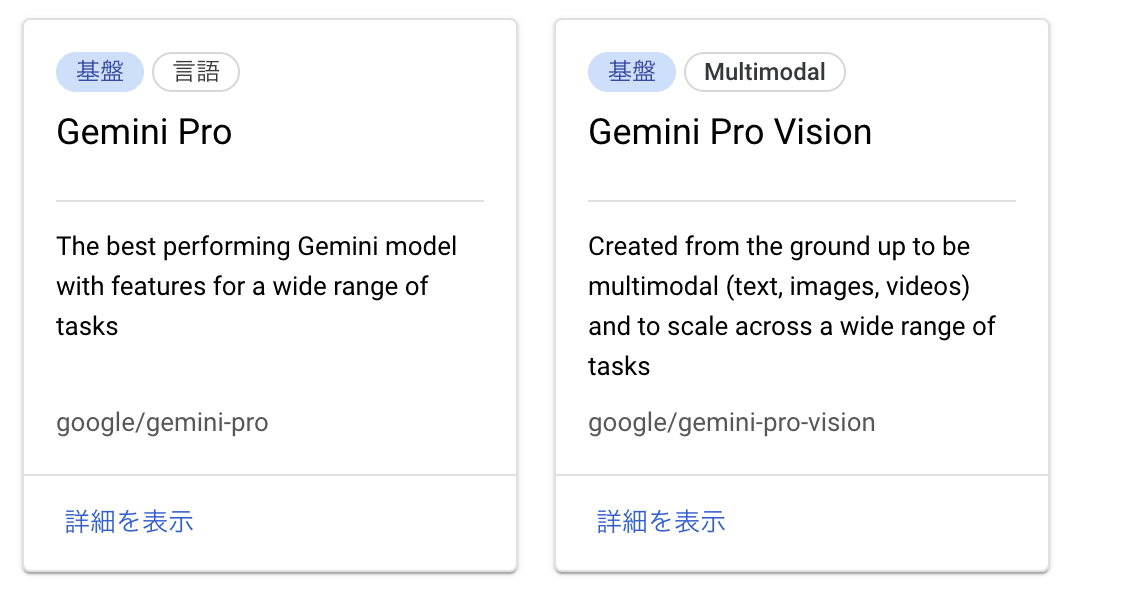
Vertex AI Model Gardenより
Gemini Pro
テキスト生成または、チャットでの利用が想定されたモデルであり、コード生成も可能です。gemini-pro@001のResource IDで提供されています。
- フォーマット: PNG, JPEG, WEBP, HEIC, HEIF
- 枚数: 最大16件
- 容量: 最大4MB(画像とテキストを含む),
- 解像度: ピクセル数に制限はなく、解像度が3072x3072に収まるように縮小される
- トークン: 各画像は、258トークンとして処理される
入力データの要件に関しては下記を参考にしています。入力画像のベストプラクティスについても記載があります。
Gemini Pro Vision
テキスト、画像、動画を扱うことが可能なモデル。gemini-pro-vision@001のResource IDで提供されています。
- フォーマット: MOV, MPEG, MP4, MPG, AVI, WMV, MPEGPS, FLS
- 枚数: 1つの動画が推奨
- 容量: 最大10MB, 最初の2分間のみが処理
- トークン: 1動画あたり1,032トークンとして処理される
※ 注意点として、動画を不連続な画像フレームとして認識するため、音声やタイムスタンプなどは認識対象に含まれないようです。
こちらの要件に関しても下記のドキュメントを参考にしています。
マルチモーダルモデルのプロンプトを設計する際にはこちらのドキュメントを参考にするとよいでしょう。few-shotとして画像と応答の例を与えることや、単一画像を入力する際には画像を最初に配置することが重要などといった、ベストプラクティスが記載されています。
その他の機能について
安全性の設定を行うことも可能であり、有害コンテンツブロックの強度を設定することが出来ます。これらResponsible AIに関しては、こちらのドキュメントにまとまっています。
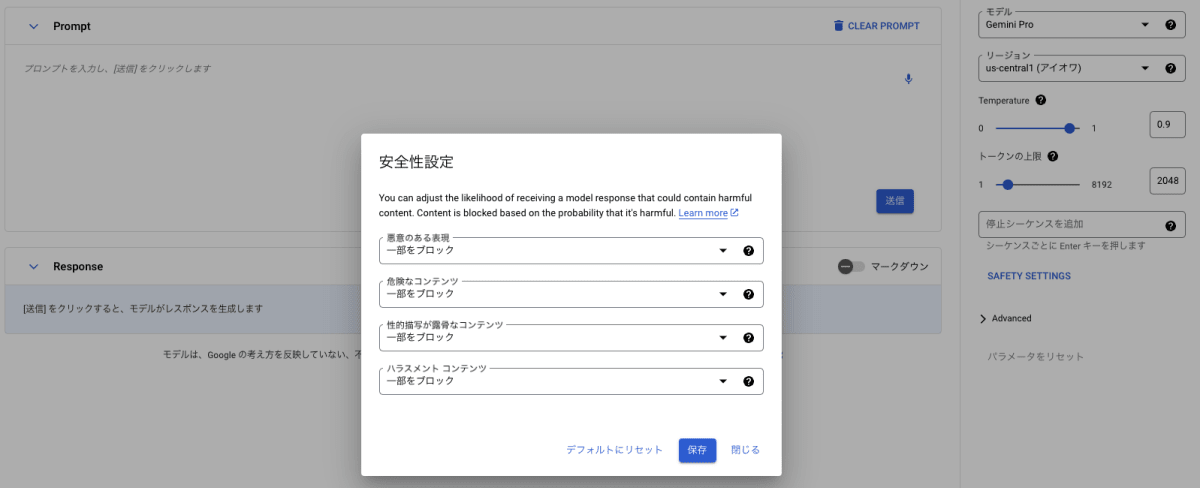
chat-bisonとtext-bisonで利用可能(プレビュー)なVertex AI Searchのデータストアによるグラウンディングは2023/12/13時点では対応していません。
料金
2023/12/13現在の料金は下記のようになっています。
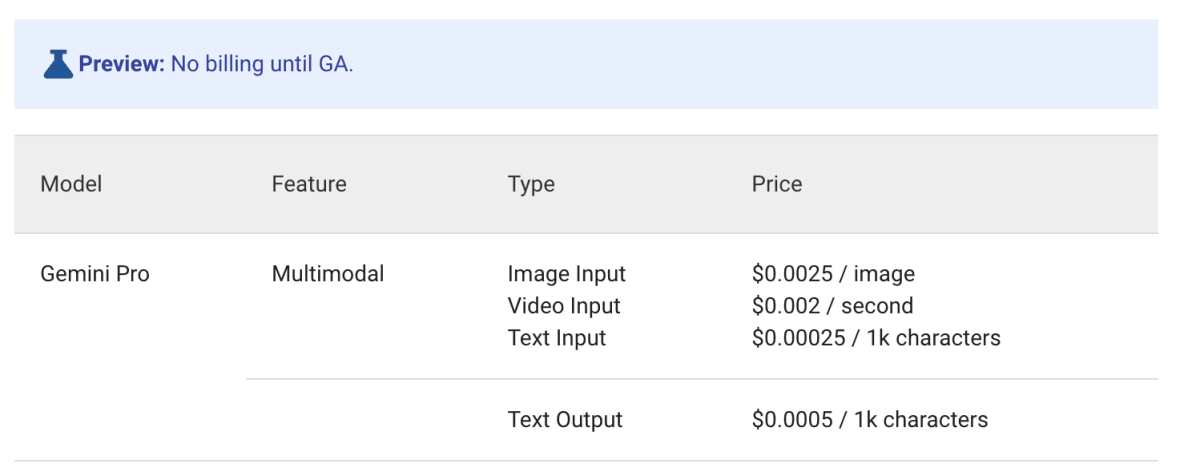
PaLM2と同様に1000文字ごとの課金体系になっています。また、Text Inputに関しては、PaLM2(Text Bison)と同様の金額です。
最新の料金に関しては、公式のPricingページを確認してください。
実装ガイド
それではいよいよ、Vertex AIでGemini Proを使ってみます。
下記のバージョンで実行をしました。
python = "3.11"
google-cloud-aiplatform = "1.38.0"
下記の2つの方法で利用することが出来ます。
- Vertex AI Studio
- Vertex AI SDK
今回は、Vertex AI SDKでの利用を主に試します。
Vertex AI Studioからの使用
Vertex AI Studio とはGoogle Cloudのコンソールから利用可能なツールです。
テキストプロンプトやパラメーター、画像や動画をGUIから入力して、気軽にプロトタイピングをすることが出来ます。
Gemini Pro Visionが利用可能なマルチモーダルの項目が新規で追加されており、こちらから試すことが出来ます。
また、マルチモーダル用のサンプルプロンプトも用意されているため、気軽に動作を確認することが出来ます。
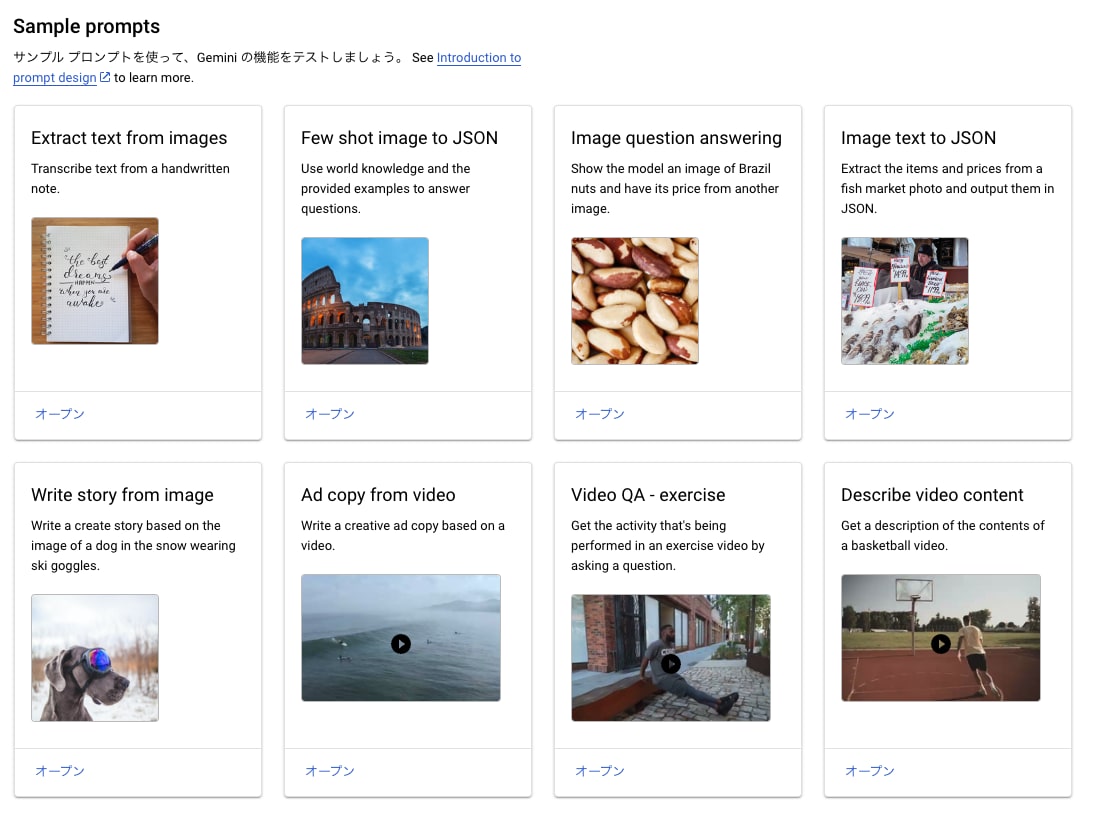
Vertex AI SDKから使用
今回は、Python SDKを使用して検証しますが、他にもNode.js, Java, Golang, RESTでのリクエストをサポートしています。
まずはじめに、テキストチャットです。こちらは下記のドキュメントを参考にして実装を行いました。
import vertexai
from vertexai.preview.generative_models import GenerativeModel
PROJECT_ID = "project-id"
LOCATION = "asia-northeast1"
RESOURCE_ID = "gemini-pro"
vertexai.init(project=PROJECT_ID, location=LOCATION)
def initiate_chat_session():
model = GenerativeModel(RESOURCE_ID)
chat = model.start_chat()
return chat
def multiturn_generate_content(chat, user_input):
config = {"max_output_tokens": 2048, "temperature": 0.9, "top_p": 1}
response = chat.send_message(user_input, generation_config=config)
return response
chat = initiate_chat_session()
while True:
user_input = input(">> ")
chat_response = multiturn_generate_content(chat, user_input)
print(chat_response)
「こんにちは。私の名前は原です。これからよろしくお願いします!」の入力に対する、出力結果は下記のようになります。
candidates {
content {
role: "model"
parts {
text: "初めまして、原さん。これからよろしくお願いします。私は人工知能アシスタントです。私は、さまざまなトピックに関する情報を提供したり、質問に答えたり、タスクを完了させたりするお手伝いをします。\n\nあなたは私をどのように使用したいですか?"
}
}
finish_reason: STOP
safety_ratings {
category: HARM_CATEGORY_HARASSMENT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_HATE_SPEECH
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_SEXUALLY_EXPLICIT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_DANGEROUS_CONTENT
probability: NEGLIGIBLE
}
}
usage_metadata {
prompt_token_count: 11
candidates_token_count: 61
total_token_count: 72
}
最初の会話を考慮出来ているかを確認しましょう。そのために、「質問に答えて欲しいです。私の名前を覚えていますか?」と入力してみます。
candidates {
content {
role: "model"
parts {
text: "はい、あなたの名前は原さんです。私はあなたの名前を覚えています。\n\n他に何か質問はありますか?"
}
}
finish_reason: STOP
safety_ratings {
category: HARM_CATEGORY_HARASSMENT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_HATE_SPEECH
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_SEXUALLY_EXPLICIT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_DANGEROUS_CONTENT
probability: NEGLIGIBLE
}
}
usage_metadata {
prompt_token_count: 86
candidates_token_count: 22
total_token_count: 108
}
ちゃんと私の名前を回答できています。過去の会話も考慮できました。
レスポンスでは生成結果であるテキストに加えて、安全性評価であるsafety_ratingsや、消費したトークン数が算出されたusage_metadataのフィールドも返却されています。今回出力におけるsafety_ratingsは最も危険性が低い、NEGLIGIBLEとなっているため問題はなさそうです。有害コンテンツ評価の各フィールドに関してはこちらのドキュメントから確認出来ます。
それでは、次に画像入力を試してみましょう。下記のドキュメントを参考にして実装を行いました。
例として、筆者が一緒に暮らしている猫の画像を使います。かわいいです。

実行コードは下記のようになります。入力画像はGCSへと事前にアップロードしておきます。画像に写っているものを箇条書きで3つ、列挙してもらいます。
import vertexai
from vertexai.preview.generative_models import GenerativeModel, Part
PROJECT_ID = "project-id"
LOCATION = "asia-northeast1"
RESOURCE_ID = "gemini-pro-vision"
vertexai.init(project=PROJECT_ID, location=LOCATION)
IMAGE_FILE = "gs://bucket-name/images/cat.jpg"
generative_multimodal_model = GenerativeModel(RESOURCE_ID)
response = generative_multimodal_model.generate_content(
[
"""この画像には何が写っていますか?\
箇条書きで3つ教えて下さい。詳細に説明をお願いします。
""",
Part.from_uri(
IMAGE_FILE,
mime_type="image/jpeg",
),
],
generation_config={
"max_output_tokens": 2048,
"temperature": 0.4,
"top_p": 1,
"top_k": 32,
},
)
print(response)
出力結果はこちらです。猫を認識していることはもちろん、三毛猫であることや写真がアップであること、表情なども捉えることが出来ています。
candidates {
content {
role: "model"
parts {
text: " 1. この画像には、猫の顔のアップが写っています。猫は、こちらを向いており、カメラ目線ではありません。\n\n2. 猫の毛並みは、白、茶色、黒の3色で、目の色は緑です。\n\n3. 猫は、何かを考え事をしているようで、とてもリラックスしているように見えます。"
}
}
finish_reason: STOP
safety_ratings {
category: HARM_CATEGORY_HARASSMENT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_HATE_SPEECH
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_SEXUALLY_EXPLICIT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_DANGEROUS_CONTENT
probability: NEGLIGIBLE
}
}
usage_metadata {
prompt_token_count: 284
candidates_token_count: 74
total_token_count: 358
}
最後に動画入力を試してみましょう。
私が動物園で撮影した、おやつをもらっている熊の動画を使用します。
実行するコードは下記です。どのような動画なのかを説明してもらいます。先ほどの画像入力でのコードと同様に、入力動画はGCSへとアップロードしておきます。
import vertexai
from vertexai.preview.generative_models import GenerativeModel, Part
PROJECT_ID = "project-id"
LOCATION = "asia-northeast1"
RESOURCE_ID = "gemini-pro-vision"
vertexai.init(project=PROJECT_ID, location=LOCATION)
VIDEO_FILE = "gs://bucket-name/videos/bear.mp4"
model = GenerativeModel(RESOURCE_ID)
response = model.generate_content(
[
"""この動画は私が動物園で撮影した動画です。どのような動画ですか?\
箇条書きで教えて下さい。""",
Part.from_uri(
VIDEO_FILE,
mime_type="video/mp4",
),
],
generation_config={
"max_output_tokens": 2048,
"temperature": 0.4,
"top_p": 1,
"top_k": 32,
},
)
print(response)
ちゃんと熊の動画であること、そして、餌をもらうまでの過程が説明されています。動画データの特徴量化が捗りそうです。
candidates {
content {
role: "model"
parts {
text: " ・動物園で撮影した動画です。\n・檻の中にいるヒグマが、餌をもらおうとしている様子です。\n・飼育員さんが長い棒の先に餌をつけて、ヒグマに与えています。\n・ヒグマは餌をもらうと、美味しそうに食べています。\n・動画は、ヒグマが餌をもらうところから、食べ終わるところまでを撮影しています。"
}
}
finish_reason: STOP
safety_ratings {
category: HARM_CATEGORY_HARASSMENT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_HATE_SPEECH
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_SEXUALLY_EXPLICIT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_DANGEROUS_CONTENT
probability: NEGLIGIBLE
}
}
usage_metadata {
prompt_token_count: 1055
candidates_token_count: 83
total_token_count: 1138
}
終わりに
今回は、VertexAIでのGemini APIを使用して、Gemini Pro/Visionを使ってみました。今回は簡単なユースケースの検証でしたが、今後はより複雑なタスクに取り組んでいこうと思います。また、他のモデルとの比較や、Google Cloudプロダクトとの連携、LangChainとの連携などを深堀りしていければと思います。
LangChainは既に対応したようです。
また、PaLM2と同様にリーズナブルな料金で利用出来るのがメリットだと感じました。画像や動画の認識精度に関しても、今回の検証の範囲では、十分高精度だと感じました。
参考文献
Discussion