LlamaIndexのマルチモーダルを試す
ここのところ少しGemini 1.5やらVertex AIのマルチモーダルEmbeddingsなんかを試してみたのだけど、公式のSDK以外のフレームワークだとどんな感じで書くのかな?というのが気になったので、まずはLlamaIndexで試してみる。
とりあえずこのあたりからかな。
Component Guides: Models - [Beta] Multi-modal models
OpenAIでとりあえず試すには以下のnotebookかな
Examples: Multi-Modal - Multi-Modal LLM using OpenAI GPT-4V model for image reasoning
とりあえずドキュメントをざっとまとめ
- LlamaIndexでの対応状況
- テキスト・画像のみ
- 音声や動画はまだ非対応
- 以下の機能に対応
- 入力クエリ
- データソース
- (マルチモーダル)Embedding
- Retriever
- Query Engine
- 出力(ただし画像生成は除く)
- マルチモーダル対応モデル
- モデルごとにできることの違いがある
- LLM
-
MultiModalLLMクラスが用意されている - 主なモデル
- GPT-4V/Azure GPT-4V/GPT-4o
- Gemini
- Anthropic
- CLIP
- LlaVa
- Qwen-VL
- などなど
-
- Vector Stores
-
MultiModalVectorStoreIndexクラスが用意されている。MultiModalRetrieverやSimpleMultiModalQueryEngineで検索を行う。 - 主なベクトルストア
- LlamaIndexビルトインのインベクトルストア
- Chroma
- Weaviate
- Qdrant(notebook見てる限りはいけそう)
- ※基本的には単なるベクトルストアなのでどれでもできそうな気はするけども。
-
- テキスト・画像のみ
OpenAIで進めてみる
パッケージインストール。llama-index-multi-modal-llms-*みたいなパッケージになる。
!pip install llama-index-multi-modal-llms-openai llama-index-readers-file llama-index-callbacks-arize-phoenix
!pip freeze | grep -e 'llama-'
OpenAI APIキーを読み込み
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
マルチモーダル用のクラスを使って、サンプルで紹介されている以下の画像についてクエリを投げてみる。モデルはgpt-4oにしてみた。

from llama_index.multi_modal_llms.openai import OpenAIMultiModal
from llama_index.core.multi_modal_llms.generic_utils import load_image_urls
from llama_index.core import SimpleDirectoryReader
# 画像をURLから読み込む場合はユーティリティクラスが用意されている
image_urls = [
"https://res.cloudinary.com/hello-tickets/image/upload/c_limit,f_auto,q_auto,w_1920/v1640835927/o3pfl41q7m5bj8jardk0.jpg",
]
image_documents = load_image_urls(image_urls)
# ローカルから読み込む場合はSimpleDirectoryReaderが使える
#image_documents = SimpleDirectoryReader("./data").load_data()
# 非ストリーミング
llm = OpenAIMultiModal(
model="gpt-4o",
max_new_tokens=1024,
)
# complete/stream_complete/chat/stream_chatなど
# 非同期用メソッドもある
response = llm.complete(
prompt="画像について説明してください。",
image_documents=image_documents
)
print(response.text)
この画像は、イタリアのローマにあるコロッセオ(コロッセウム)を夜に撮影したものです。コロッセオは古代ローマ時代の円形闘技場で、ローマ帝国の象徴的な建築物の一つです。画像では、コロッセオがイタリアの国旗の色(緑、白、赤)でライトアップされています。背景には夜空が広がり、建物の細部が美しく照らし出されています。前景には工事用のフェンスが見え、修復作業が行われていることが示唆されています。
画像は複数渡すこともできる。Pixabayの以下の画像をダウンロードして、今度はローカルから読み込んでみる。
1枚目: data/horse_race_01.jpg
2枚目: data/horse_race_02.jpg
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
from llama_index.core.multi_modal_llms.generic_utils import load_image_urls
from llama_index.core import SimpleDirectoryReader
# 画像をURLから読み込む場合はユーティリティクラスが用意されている
#image_urls = [
# "https://example.com/sample01.jpg",
# "https://example.com/sample02.jpg",
#]
#image_documents = load_image_urls(image_urls)
# ローカルから読み込む場合はSimpleDirectoryReaderが使える
image_documents = SimpleDirectoryReader("./data").load_data()
print("num_of_image_documents:", len(image_documents), "\n\n=====\n\n")
# 非ストリーミング
llm = OpenAIMultiModal(
model="gpt-4o",
max_new_tokens=1024,
)
# complete/stream_complete/chat/stream_chatなど
# 非同期用メソッドもある
response = llm.complete(
prompt="これらの画像について違いを説明してください。",
image_documents=image_documents
)
print(response.text)
num_of_image_documents: 2
=====
これらの画像は、競馬のスタートシーンを捉えたものです。以下に違いを説明します。
1. **スタートゲートの番号**:
- 最初の画像では、スタートゲートの番号は「3」から「8」までが見えます。
- 二番目の画像では、スタートゲートの番号は「1」から「7」までが見えます。
2. **騎手と馬の配置**:
- 最初の画像では、各ゲートに馬と騎手が配置されており、スタートの瞬間を捉えています。馬がゲートから飛び出す瞬間が見られます。
- 二番目の画像では、馬と騎手がゲートから飛び出している瞬間が捉えられており、特に右端の馬がゲートから出るのに苦労している様子が見られます。
3. **騎手の服装**:
- 最初の画像では、騎手の服装は主に緑色と赤色が目立ちます。
- 二番目の画像では、騎手の服装は多様で、赤、青、白などの色が見られます。
4. **馬の動き**:
- 最初の画像では、馬がゲートから飛び出す瞬間であり、まだ完全にゲートを抜け出していない馬もいます。
- 二番目の画像では、馬がゲートを抜け出して走り始めている瞬間が捉えられています。
これらの違いにより、二つの画像は競馬のスタートの異なる瞬間を捉えたものであることがわかります。
completeメソッドはCompletionで、ストリーミングさせたい場合はstream_completeメソッドを使う。
stream_complete_response = llm.stream_complete(
prompt="2枚目の画像について、なにか気になることはありますか?",
image_documents=image_documents,
)
for r in stream_complete_response:
print(r.delta, end="")
2枚目の画像について、気になる点があります。7番の馬がゲートから出る際に、騎手が落馬しているように見えます。これは競馬において非常に危険な状況であり、騎手や馬の安全が心配されます。競馬のレース中にこのような事故が発生すると、レースの進行や結果にも影響を与える可能性があります。
chatメソッドでチャットもできる。テキストベースだとChatMessageクラスを使ってメッセージを組み立てるけど、マルチモーダルの場合は、画像も処理した上でChatMessageオブジェクトを作るユーティリティが用意されているっぽい。OpenAIの場合はgenerate_openai_multi_modal_chat_messageを使う。
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
from llama_index.core import SimpleDirectoryReader
from llama_index.multi_modal_llms.openai.utils import (
generate_openai_multi_modal_chat_message,
)
image_doc_1 = SimpleDirectoryReader(input_files=["./data/horse_race_01.jpg"]).load_data()
image_doc_2 = SimpleDirectoryReader(input_files=["./data/horse_race_02.jpg"]).load_data()
chat_msg_1 = generate_openai_multi_modal_chat_message(
prompt=(
"あなたは、与えられた画像を元にユーザからの質問に答える日本語のアシスタントです。"
"事前知識を使わずに、与えられた画像のみを使用すること。画像から読み取れること以外は回答しないこと。"
),
role="system",
)
chat_msg_2 = generate_openai_multi_modal_chat_message(
prompt="この画像について説明してください。",
role="user",
image_documents=image_doc_1,
)
chat_messages = [chat_msg_1, chat_msg_2]
chat_response = llm.chat(
messages=chat_messages,
)
print(chat_response)
assistant: この画像は、競馬のスタートシーンを捉えたものです。馬と騎手がスタートゲートから一斉に飛び出している瞬間が写されています。スタートゲートには番号が振られており、各馬がそれぞれのゲートから出発しています。騎手たちはカラフルなユニフォームを着ており、馬もそれぞれ異なる装飾が施されています。背景には観客席や競馬場の風景が見えます。
もう一つの画像を追加して会話を続けてみる。
chat_messages.append(chat_response.message)
chat_messages.append(
generate_openai_multi_modal_chat_message(
prompt="先ほどの画像の続きです。何が違いますか?",
role="user",
image_documents=image_doc_2,
)
)
chat_response = llm.chat(
messages=chat_messages,
)
print(chat_response)
assistant: この画像も競馬のスタートシーンを捉えたものですが、先ほどの画像と比較していくつかの違いがあります。
1. **スタートゲートの番号**: 今回の画像では、スタートゲートの番号が1から7まで表示されています。前の画像では3から8まででした。
2. **馬と騎手の配置**: 馬と騎手の配置が異なります。特に、ゲート番号1から7の馬と騎手が異なる位置にいます。
3. **スタートの瞬間**: 前の画像では馬がスタートゲートから飛び出している瞬間が捉えられていましたが、この画像ではまだスタート直後の状態で、いくつかの馬がまだ完全にゲートを出ていないように見えます。
4. **騎手の動き**: 騎手たちの動きや姿勢も異なります。特に、ゲート番号7の騎手が馬から落ちかけているように見えます。
これらの違いから、同じ競馬のスタートシーンでも異なる瞬間が捉えられていることがわかります。
会話履歴は以下で確認できる。
chat_messages.append(chat_response.message)
for msg in chat_messages:
print(msg.role, msg.content)
長いので割愛するけども、ローカルファイルを使った場合はBASE64にエンコードされる。URLの場合はそのままURLが入る。
MessageRole.SYSTEM あなたは、与えられた画像を元にユーザからの質問に答える日本語のアシスタントです。事前知識を使わずに、与えられた画像のみを使用すること。画像から読み取れること以外は回答しないこと。
MessageRole.USER [{'type': 'text', 'text': 'この画像について説明してください。'}, {'type': 'image_url', 'image_url': {'url': 'data:image/jpeg;base64,/9j/4AAQSk(snip)BYL//2Q==', 'detail': 'low'}}]
こちらもストリーミングの場合はstream_chatメソッドが用意されている。あとはそれぞれのメソッドの先頭にaをつけると非同期になる。
マルチモーダルなインデックスとretireverの作成。
上記のnotebookでは以下を使用している様子。
- テキストEmbeddings: OpenAI
text-embedding-ada-002 - マルチモーダル(画像)Embedding: OpenAI CLIP
- ベクトルストア: Qdrant(ローカル)
パッケージインストール
!pip install llama_index llama-index-vector-stores-qdrant llama-index-embeddings-clip wikipedia git+https://github.com/openai/CLIP.git
ここでセッションの再起動が必要になるのでダイアログが出たら再起動して、続きを進める。
インストールされたパッケージのバージョン
!pip freeze| grep -e 'llama-'
llama-cloud==0.0.6
llama-index==0.10.53
llama-index-agent-openai==0.2.8
llama-index-callbacks-arize-phoenix==0.1.6
llama-index-cli==0.1.12
llama-index-core==0.10.53.post1
llama-index-embeddings-clip==0.1.5
llama-index-embeddings-openai==0.1.10
llama-index-indices-managed-llama-cloud==0.2.4
llama-index-legacy==0.9.48
llama-index-llms-openai==0.1.25
llama-index-multi-modal-llms-openai==0.1.7
llama-index-program-openai==0.1.6
llama-index-question-gen-openai==0.1.3
llama-index-readers-file==0.1.29
llama-index-readers-llama-parse==0.1.6
llama-index-vector-stores-qdrant==0.2.11
llama-parse==0.4.6
openinference-instrumentation-llama-index==2.0.0
コンテンツの準備。Wikipediaの特定のページからテキストと画像をダウンロードする。
from pathlib import Path
import requests
import wikipedia
import urllib.request
wiki_titles = [
"ビートルズ",
"ローリング・ストーンズ",
"レッド・ツェッペリン",
"クイーン (バンド)",
"ジャーニー (バンド)",
"BTS (音楽グループ)",
]
data_path = Path("data_wiki")
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = page["extract"]
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
# colaboratoryでの確認用: image_metadata_dict には、画像の uuid、ファイル名、パスなどのメタデータが格納される
image_metadata_dict = {}
image_uuid = 0
MAX_IMAGES_PER_WIKI = 30
# カスタムヘッダーを定義
headers = {"User-Agent": "urllib3/2.0.7 (kun432@xxxxx) urllib3/2.0.7"}
wikipedia.set_lang("ja")
# 画像をダウンロードして、各画像にはUUIDを割り当てる
for title in wiki_titles:
images_per_wiki = 0
print(title)
try:
page_py = wikipedia.page(title)
list_img_urls = page_py.images
for url in list_img_urls:
if url.endswith(".jpg") or url.endswith(".jpeg"):
image_uuid += 1
image_file_name = title + "_" + url.split("/")[-1]
image_metadata_dict[image_uuid] = {
"filename": image_file_name,
"img_path": "./" + str(data_path / f"{image_uuid}.jpg"),
}
# カスタムヘッダー付きのリクエストを作成
req = urllib.request.Request(url, headers=headers)
# URLを開いてコンテンツを取得
with urllib.request.urlopen(req) as response:
img_data = response.read()
# 画像データをファイルに保存
with open(data_path / f"{image_uuid}.jpg", 'wb') as f:
f.write(img_data)
images_per_wiki += 1
# 1ページあたりの画像のダウンロード数を30枚に制限する。
if images_per_wiki > MAX_IMAGES_PER_WIKI:
break
except Exception as e:
print(f"Error processing Wikipedia page '{title}': {str(e)}")
continue
data_wikiディレクトリに以下のように保存された。
$ tree data_wiki
data_wiki
├── 10.jpg
├── 11.jpg
├── 12.jpg
├── 13.jpg
├── 14.jpg
├── 15.jpg
├── 16.jpg
├── 17.jpg
├── 18.jpg
├── 19.jpg
├── 1.jpg
├── 20.jpg
├── 21.jpg
├── 22.jpg
├── 23.jpg
├── 24.jpg
├── 25.jpg
├── 26.jpg
├── 27.jpg
├── 28.jpg
├── 29.jpg
├── 2.jpg
├── 30.jpg
├── 31.jpg
├── 32.jpg
├── 33.jpg
├── 34.jpg
├── 35.jpg
├── 36.jpg
├── 37.jpg
├── 38.jpg
├── 39.jpg
├── 3.jpg
├── 40.jpg
├── 41.jpg
├── 42.jpg
├── 43.jpg
├── 44.jpg
├── 45.jpg
├── 46.jpg
├── 47.jpg
├── 48.jpg
├── 49.jpg
├── 4.jpg
├── 50.jpg
├── 51.jpg
├── 52.jpg
├── 53.jpg
├── 54.jpg
├── 55.jpg
├── 56.jpg
├── 57.jpg
├── 58.jpg
├── 59.jpg
├── 5.jpg
├── 60.jpg
├── 61.jpg
├── 62.jpg
├── 63.jpg
├── 64.jpg
├── 65.jpg
├── 66.jpg
├── 67.jpg
├── 6.jpg
├── 7.jpg
├── 8.jpg
├── 9.jpg
├── BTS (音楽グループ).txt
├── クイーン (バンド).txt
├── ジャーニー (バンド).txt
├── ビートルズ.txt
├── レッド・ツェッペリン.txt
└── ローリング・ストーンズ.txt
0 directories, 73 files
画像も確認してみる。
from PIL import Image
import matplotlib.pyplot as plt
import os
def plot_images(image_metadata_dict):
original_images_urls = []
images_shown = 0
for image_id in image_metadata_dict:
img_path = image_metadata_dict[image_id]["img_path"]
if os.path.isfile(img_path):
filename = image_metadata_dict[image_id]["filename"]
image = Image.open(img_path).convert("RGB")
plt.subplot(8, 8, len(original_images_urls) + 1)
plt.imshow(image)
plt.xticks([])
plt.yticks([])
original_images_urls.append(filename)
images_shown += 1
if images_shown >= 64:
break
plt.tight_layout()
plot_images(image_metadata_dict)
ではインデックスとretrieverを作成していく。
上に書いた通りテキストのEmbeddingsはOpenAIのものを使うので、APIキーを読み込んでおく。
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
Qdrantをローカルで起動、テキスト・画像それぞれのコレクションを作成して、MultiModalVectorStoreIndexでダウンロードしたデータをまるっとインデックス化する。なかなかにシンプルに書けてしまうのだなぁ。。。
import qdrant_client
from llama_index.core import SimpleDirectoryReader
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.core.indices import MultiModalVectorStoreIndex
# ローカルのQdrantベクトルストアを作成
client = qdrant_client.QdrantClient(path="qdrant_db")
text_store = QdrantVectorStore(
client=client, collection_name="text_collection"
)
image_store = QdrantVectorStore(
client=client, collection_name="image_collection"
)
storage_context = StorageContext.from_defaults(
vector_store=text_store,
image_store=image_store
)
# マルチモーダルインデックスを作成
documents = SimpleDirectoryReader("./data_wiki/").load_data()
index = MultiModalVectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
)
# インデックスからretrieverを作成
retriever = index.as_retriever(similarity_top_k=5, image_similarity_top_k=5)
で早速クエリを投げたいところだけども、colaboratoryでretrieval結果を確認し易いようにヘルパー関数を読み込んでおく。
def plot_images(image_paths):
images_shown = 0
plt.figure(figsize=(16, 9))
for img_path in image_paths:
if os.path.isfile(img_path):
image = Image.open(img_path)
plt.subplot(2, 3, images_shown + 1)
plt.imshow(image)
plt.xticks([])
plt.yticks([])
images_shown += 1
if images_shown >= 9:
break
ではクエリを投げてみる。
retrieval_results = retriever.retrieve("BTSのメンバーは誰?")
retrievalの結果を見てみる。これはちょっとベタに書いている。
for r in retrieval_results:
print("ID:", r.id_)
print("Score:", r.score)
if r.metadata["file_type"] == "text/plain":
print("Text:", r.text.replace("\n","")[:100] + "...")
else:
print("File:", r.metadata["file_path"])
plt.show(plot_images([r.metadata["file_path"]]))
print("---")


テキスト検索と画像検索の結果がそれぞれ表示されている。テキストと画像でスコアに開きがあるのは、テキストからテキスト、テキストから画像、で検索しているからなんだろう。
他にもクエリを投げてみる。
from llama_index.core.response.notebook_utils import display_source_node
from llama_index.core.schema import ImageNode
retrieval_results = retriever.retrieve("ビートルズのデビュー曲は?")
retrieved_image = []
for res_node in retrieval_results:
if isinstance(res_node.node, ImageNode):
retrieved_image.append(res_node.node.metadata["file_path"])
else:
display_source_node(res_node, source_length=200)
plot_images(retrieved_image)

retrieval_results = retriever.retrieve("レッド・ツェッペリンのギタリストは誰")
retrieved_image = []
for res_node in retrieval_results:
if isinstance(res_node.node, ImageNode):
retrieved_image.append(res_node.node.metadata["file_path"])
else:
display_source_node(res_node, source_length=200)
plot_images(retrieved_image)


なんとなく特定のキーワードにやや引っ張られている感があるような印象があるし、違う画像が参照sされている場合もあるけども、それっぽくは動いているかな。
どうせならQuery Engineも使ってみたいなーということで、以下を参考にSimpleMultiModalQueryEngineを使ってgpt-4oで回答させるようにしてみた。
!pip install llama-index-multi-modal-llms-openai
from llama_index.core import PromptTemplate
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
from llama_index.core.query_engine import SimpleMultiModalQueryEngine
llm = OpenAIMultiModal(
model="gpt-4o",
max_new_tokens=1500
)
qa_tmpl_str = (
"コンテキスト情報は以下です。\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"事前知識を使わずに、与えられたコンテキスト情報を元に、以下の質問に回答してください。\n"
"質問: {query_str}\n"
"回答: "
)
qa_tmpl = PromptTemplate(qa_tmpl_str)
query_engine = index.as_query_engine(
llm=llm,
text_qa_template=qa_tmpl,
similarity_top_k=5,
image_similarity_top_k=5
)
query_str = "ローリング・ストーンズの歴代ギタリストをリストアップして。"
response = query_engine.query(query_str)
print(str(response))
ローリング・ストーンズの歴代ギタリストは以下の通りです:
1. キース・リチャーズ
2. ブライアン・ジョーンズ
3. ミック・テイラー
4. ロン・ウッド
これらのギタリストは、ローリング・ストーンズの音楽に大きな影響を与えました。


Arize Phoenixでトレース取ってみたら、どうやら画像もコンテキストとして投げてるっぽい。
OpenAI CLIPだとちょっと使い勝手が悪い。Vertex AIのマルチモーダルEmbeddingモデル使いたいなーと思ってnotebook探してみたのだけどドキュメントサイトにはない。。。。
と思ったら、GitHubレポジトリにはあった。どうやらインテグレーションパッケージの中にしかないのでドキュメント化されていないっぽい。
ちなみにテキストモデルの方はこちら。
Embedding単体での使い方だけだけど試してみる。
パッケージインストール
!pip install llama-index-embeddings-vertex
ColaboratyでGCPの認証。
from google.colab import auth
auth.authenticate_user()
まずはテキストEmbeddingモデルから。本語で使いたいので、text-multilingual-embedding-002で。
from llama_index.embeddings.vertex import (
VertexTextEmbedding,
VertexEmbeddingMode,
)
embed_model = VertexTextEmbedding(
model_name="text-multilingual-embedding-002",
project="YOUR_PROJECT_NAME",
location="asia-northeast1",
embed_mode=VertexEmbeddingMode.DEFAULT_MODE,
)
ここのembed_modeは以下がベースになる。
2023 年 8 月以降にリリースされたモデルの API の変更
textembedding-gecko@003 や textembedding-gecko-multilingual@001 など、2023 年 8 月以降にリリースされたモデル バージョンを使用する場合、新しいタスク タイプ パラメータとオプションのタイトルがあります(task_type=RETRIEVAL_DOCUMENT でのみ有効)。これらの新しいパラメータは、これらの公開プレビュー モデルと、今後のすべての安定版のモデルに適用されます。
(snip)
task_typeパラメータは、モデルが質の高いエンベディングを生成できるように、対象となるダウンストリーム アプリケーションとして定義されます。これは次のいずれかの値を取る文字列です。
task_type 説明 RETRIEVAL_QUERY 指定したテキストが検索または取得設定のクエリであることを指定します。 RETRIEVAL_DOCUMENT 指定したテキストが検索または取得設定のドキュメントであることを指定します。 SEMANTIC_SIMILARITY 指定したテキストが意味的テキスト類似性(STS)で使用されることを指定します。 CLASSIFICATION エンベディングが分類に使用されることを指定します。 CLUSTERING エンベディングがクラスタリングに使用されることを指定します。 QUESTION_ANSWERING クエリエンベディングが質問への回答に使用されることを指定します。ドキュメント側には RETRIEVAL_DOCUMENT を使用します。 FACT_VERIFICATION クエリ エンベディングが事実確認に使用されることを指定します。
これは比較する2つのもの(例えば検索だとクエリとドキュメント)でそれぞれ変えてやる必要がある。
| 使い方(タスク) | 文字列1 or クエリのタスクタイプ | 文字列2 or ドキュメントのタスクタイプ |
|---|---|---|
| 検索・文書取得 | RETRIEVAL_QUERY | RETRIEVAL_DOCUMENT |
| 意味的テキスト類似性 | SEMANTIC_SIMILARITY | SEMANTIC_SIMILARITY |
| 分類 | CLASSIFICATION | CLASSIFICATION |
| クラスタリング | CLUSTERING | CLUSTERING |
| 質問回答 | QUESTION_ANSWERING | RETRIEVAL_DOCUMENT |
| 事実確認 | FACT_VERIFICATION | 不明 |
LlamaIndexではこの組み合わせをあらかじめ「モード」として定義されている。例えば、Query EngineでRAGを作る場合はRETRIEVAL_MODEを選択しておけば、インデックス作成時はRETRIEVAL_DOCUMENT、Query Engineに渡されたクエリの場合はRETRIEVAL_QUERYでEmbeddingsが生成される。
| 使い方(タスク) | VertexEmbeddingMode | 文字列1 or クエリのタスクタイプ | 文字列2 or ドキュメントのタスクタイプ | 備考 |
|---|---|---|---|---|
| 検索・文書取得 | RETRIEVAL_MODE | RETRIEVAL_QUERY | RETRIEVAL_DOCUMENT | |
| 意味的テキスト類似性 | SEMANTIC_SIMILARITY_MODE | SEMANTIC_SIMILARITY | SEMANTIC_SIMILARITY | |
| 分類 | CLASSIFICATION_MODE | CLASSIFICATION | CLASSIFICATION | |
| クラスタリング | CLUSTERING_MODE | CLUSTERING | CLUSTERING | |
| 質問回答 | - | QUESTION_ANSWERING | RETRIEVAL_DOCUMENT | ※2024/07/11時点 LamaIndexでは非対応 |
| 事実確認 | - | FACT_VERIFICATION | 不明 | ※2024/07/11時点 LamaIndexでは非対応 |
なお、DEFAULT_MODEは2023/08以前にリリースされたモデル向けとなる(タスクタイプがない)
このあたりの設定は以下で確認できる。
embed_model.dict()
{'model_name': 'text-multilingual-embedding-002',
'embed_batch_size': 10,
'num_workers': None,
'embed_mode': <VertexEmbeddingMode.DEFAULT_MODE: 'default'>,
'additional_kwargs': {},
'class_name': 'VertexTextEmbedding'}
ではベタにEmbeddingsを生成してみる。基本的には2つのメソッドがある。get_query_embeddingとget_text_embedding。それぞれが上の表でいうところのクエリとドキュメントに多分相当する。
embed_text_result1 = embed_model.get_text_embedding("昨夜の映画は本当に面白かった。")
embed_text_result1[:5]
[-0.030451912432909012,
-0.02044023387134075,
0.028476683422923088,
0.059152744710445404,
-0.04403100535273552]
embed_query_result1 = embed_model.get_query_embedding("昨夜の映画は本当に面白かった。")
embed_query_result1[:5]
[-0.030451912432909012,
-0.02044023387134075,
0.028476683422923088,
0.059152744710445404,
-0.04403100535273552]
DEFAULT_MODEだとどちらも全く同じEmbeddingsが生成される。
RETRIEVAL_MODEに変えてみる。
embed_model = VertexTextEmbedding(
model_name="text-multilingual-embedding-002",
project="YOUR_PROJECT_NAME",
location="asia-northeast1",
embed_mode=VertexEmbeddingMode.RETRIEVAL_MODE,
)
embed_query_result1 = embed_model.get_query_embedding("昨夜の映画は本当に面白かった。")
embed_query_result1[:5]
[-0.030451912432909012,
-0.02044023387134075,
0.028476683422923088,
0.059152744710445404,
-0.04403100535273552]
embed_text_result1 = embed_model.get_text_embedding("昨夜の映画は本当に面白かった。")
embed_text_result1[:5]
[-0.01852559670805931,
-0.018582995980978012,
0.02182803489267826,
0.07315292209386826,
-0.02685074508190155]
RETRIEVAL_MODEではクエリとドキュメントで異なるEmbeddingsが生成されているのがわかる。実際にRAGで使うときにはこのあたりはVectorIndexとかQueryEngineがよしなにやってくれるので、こういうふうにメソッドを使い分けるということは意識しなくてよくて、せいぜいモードだけ気にしておけばいいということになると思う。
一旦DEFAULT_MODEに戻す。
embed_model = VertexTextEmbedding(
model_name="text-multilingual-embedding-002",
project="YOUR_PROJECT_NAME",
location="asia-northeast1",
embed_mode=VertexEmbeddingMode.RETRIEVAL_MODE,
)
では以下でやったのと同じように複数のテキストの組み合わせの類似度を見てみる。
!pip install japanize-matplotlib
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
import japanize_matplotlib
import seaborn as sns
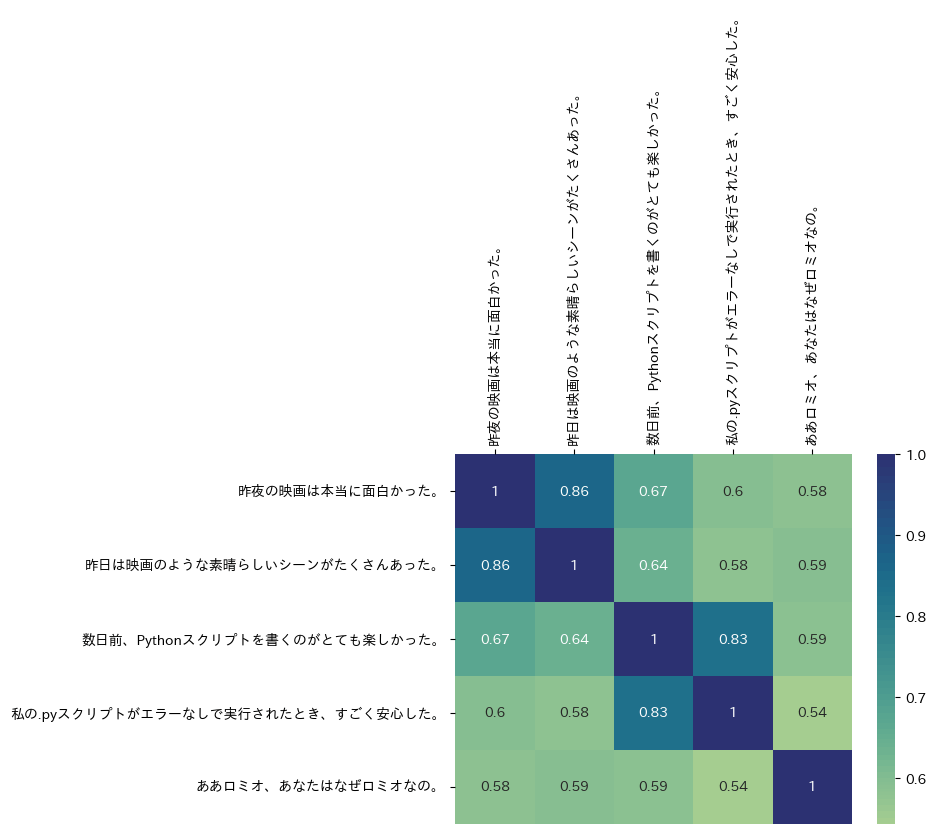
text = [
"昨夜の映画は本当に面白かった。",
"昨日は映画のような素晴らしいシーンがたくさんあった。",
"数日前、Pythonスクリプトを書くのがとても楽しかった。",
"私の.pyスクリプトがエラーなしで実行されたとき、すごく安心した。",
"ああロミオ、あなたはなぜロミオなの。",
]
# 上記テキストからデータフレーム作成
df = pd.DataFrame(text, columns=["text"])
# 各テキストのEmbeddingsを生成
df["embeddings"] = df.apply(lambda x: embed_model.get_text_embedding(x.text), axis=1)
# 各テキスト同士のコサイン類似度スコアのマトリックスを作成する。
cos_sim_array = cosine_similarity(list(df.embeddings.values))
df = pd.DataFrame(cos_sim_array, index=text, columns=text)
display(df)
# マトリックスをヒートマップにする
ax = sns.heatmap(df, annot=True, cmap="crest")
ax.xaxis.tick_top()
ax.set_xticklabels(text, rotation=90)

続けてマルチモーダルEmbeddings。
VertexMultiModalEmbeddingを使ってモデルを定義。モデルはmultimodalembedding。
from llama_index.embeddings.vertex import VertexMultiModalEmbedding
embed_model = VertexMultiModalEmbedding(
model_name="multimodalembedding",
project="YOUR_PROJECT_NAME",
location="asia-northeast1",
)
サンプルはWikipediaの以下の画像を使う。


あとはnotebookで紹介されている以下の画像。

ダウンロード
!wget https://upload.wikimedia.org/wikipedia/commons/8/8d/Symboli_rudolf.jpg -O rudolf.jpg
!wget https://upload.wikimedia.org/wikipedia/commons/7/74/Narita_Brian_19960309R1.jpg -O brian.jpg
!wget https://upload.wikimedia.org/wikipedia/commons/4/43/Cute_dog.jpg -O dog.jpg
画像のEmbeddingsはget_image_embeddingを使う。
rudolf_embeddings = embed_model.get_image_embedding("rudolf.jpg")
brian_embeddings = embed_model.get_image_embedding("brian.jpg")
dog_embeddings = embed_model.get_image_embedding("dog.jpg")
print(rudolf_embeddings[:5])
print(brian_embeddings[:5])
print(dog_embeddings[:5])
[0.0160660129, 0.00281131198, -0.00642865896, -0.0297996365, -0.00424705213]
[0.00083564152, -0.0291390624, -0.0153733995, -0.0307805, -0.00352832465]
[-0.0062195207, 0.0184064154, 0.0190772656, 0.0119439, 0.00718822284]
比較してみる。テキストのときの比較ではscikit-learnのコサイン類似度関数を使用したが、LlamaIndexのEmbeddingモデルにはsimilarityメソッドが用意されているので、これを使えば直接比較できる。similarityメソッドはデフォルトはコサイン類似度での比較となる。 モードを指定すれば、ドット積やユークリッド距離での比較もできる。
今回はコサイン類似度で比較してみる。
print(embed_model.similarity(rudolf_embeddings, brian_embeddings))
print(embed_model.similarity(rudolf_embeddings, dog_embeddings))
print(embed_model.similarity(brian_embeddings, dog_embeddings))
0.8723662091274855
0.40401914774868697
0.3924954872571773
馬の画像同士の比較だと高くなり、馬と犬野画像同士の比較だと低くなっているのがわかる。
Vertex AIのマルチモーダルEmbeddingモデルはテキストからのEmbeddings生成もできる。
rudolf_description_embeddings = embed_model.get_text_embedding("競走馬が今からレースに出走しようとしている。")
dog_description_embeddings = embed_model.get_text_embedding("茶色と白の子犬が芝生に寝そべり、背景には紫のデイジーが咲いている。")
テキストと画像で比較してみる。
print(embed_model.similarity(rudolf_embeddings, rudolf_description_embeddings))
print(embed_model.similarity(rudolf_embeddings, dog_description_embeddings))
0.1095246418967371
0.03309866852447707
馬の画像と馬のテキスト、馬の画像と犬のテキスト、だと前者のほうが類似度は高いことがわかる。
print(embed_model.similarity(dog_embeddings, dog_description_embeddings))
print(embed_model.similarity(dog_embeddings, rudolf_description_embeddings))
0.019859465682001365
0.008306685283085561
犬の画像と犬のテキスト、犬の画像と馬のテキスト、だとこちらも前者のほうが類似度は高い。
とはいえ、画像同士を比較した場合のスコアからすると画像・テキストのスコアはかなり低く見える。
あと、multimodalembeddingはマルチリンガルなのか、と言うところも気になったので少し試してみた。
rudolf_description_embeddings_en = embed_model.get_text_embedding("A racehorse is about to enter a race.")
dog_description_embeddings_en = embed_model.get_text_embedding("a brown and white puppy laying in the grass with purple daisies in the background")
print(embed_model.similarity(rudolf_embeddings, rudolf_description_embeddings_en))
print(embed_model.similarity(rudolf_embeddings, dog_description_embeddings_en))
0.13703784729805432
0.006565511176004419
print(embed_model.similarity(dog_embeddings, dog_description_embeddings_en))
print(embed_model.similarity(dog_embeddings, rudolf_description_embeddings_en))
0.19929498085694378
-0.04168650172640866
英語のほうがスコアの開きが大きい。んー、日本語の場合でもある程度スコア差は出てるので、非対応とまでは言わないけども、英語のほうが類似性を明確に出せる、ような印象。
以下記事でLlamaIndexではなくVertex AIの公式SDKでEmbeddingsを試した際に、
テキスト同士、動画同士、画像同士、でEmbeddings類似度による検索ができることはわかったのだけど、
インタフェースだけ見ると、画像とテキストで別々にEmbeddingsが返ってくるだけ、に見えるんだけど、テキストの指定の仕方で何かしら画像のEmbeddingsに違いが出てくる、ということを言ってるのかな???
についてだけど、ドキュメントには、
画像エンベディング ベクトルとテキスト エンベディング ベクトルは、同じ次元を持つ同じセマンティック空間にあります。そのため、これらのベクトルは、テキストによる画像の検索や画像による動画の検索などのユースケースでも使用できます。
とある。「同じ次元を持つ同じセマンティック空間にある」ということが重要なのかもしれない。
この点については結局わからなかった。
と書いたのだけど、今回の最後のところで少し理解出来たような気がする。あくまでも個人の理解。
- 今回のサンプルでは同じマルチモーダルEmbeddingモデルを使って、テキストと画像それぞれのEmbeddingsを生成して比較した(同じセマンティック空間)
- テキストと画像で比較した場合、「絶対的」なスコアは低いとしても、その空間内で「相対的」に類似性の高いものを抽出することはできる。
自分は「同じ次元を持つ同じセマンティック空間にある」というところから、テキストと画像の比較も、画像同士の比較も、関連していれば両方まるっと一律のスコア指標で比較できると勝手に思い込んでいたけども、元のデータの質というか情報量が違うのだから、スコアの出方に違いがあるのは当然。スコアを絶対指標的に認識してた自分が間違っていた。