Vertex AIでテキストとマルチモーダルのEmbeddingを使う
Vertex AIというかGoogleが提供するEmbeddingをほとんど使ったことがなかった。ドキュメントをいろいろ探してたのだけども、たぶんこのあたり。
テキストのEmbedddings
マルチモーダル(テキスト・画像・動画)のEmbeddings
で、色々調べてたら以下のnotebookが良さげに思えるので、これをやってみる。
とりあえずどういうモデルがあるのかは上のこのあたりっぽい。
- テキスト向け
- 英語
textembedding-gecko@001textembedding-gecko@003text-embedding-004
- 多言語
text-multilingual-embedding-002textembedding-gecko-multilingual@001
- 英語
- マルチモーダル向け
multimodalembedding@001
よくわかってないけど、テキスト向けの場合、
- 日本語の場合は
multilingualとあるものを使う -
geckoがつくものとつかないものがあるけど、新しいモデルはどうやらgeckoがつかなくなったっぽい?なのでうしろのバージョン番号で判断すれば良さそう
という感じみたい。一番新しい日本語向けで使うならば、text-multilingual-embedding-002を使っておけば良いととりあえず考える。
ということでnotebookを進めていく。
事前準備
セットアップ回りは過去記事を参考に。詳細は割愛。
パッケージインストール
!pip install --upgrade --user --quiet google-cloud-aiplatform
ColaboratoryからGCPを使えるように認証を行う。
from google.colab import auth
auth.authenticate_user()
Vertex AIへの接続
import vertexai
PROJECT_ID="YOUR_PROJECT_ID"
REGION="asia-northeast1"
vertexai.init(
project=PROJECT_ID,
location=REGION
)
テキストのEmbeddings生成
モデルはtext-multilingual-embedding-002を使う。
from typing import List
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
def embed_text(
texts: List[str] = ["バナナマフィンですか?", "バナナブレッドですか?それともバナナマフィンですか?"],
model_name: str = "text-multilingual-embedding-002",
) -> List[List[float]]:
"""事前学習済みの基礎モデルを使ってテキストを埋め込む"""
model = TextEmbeddingModel.from_pretrained(model_name)
inputs = [TextEmbeddingInput(text) for text in texts]
embeddings = model.get_embeddings(inputs)
return [embedding.values for embedding in embeddings]
TextEmbeddingModel.from_pretrained()でモデルを定義するのはわかるけど、TextEmbeddingInputは何してるんだろう?リファレンスはこちら。
Vertex AIにおけるEmbeddings APIは、シンプルなテキストを投げるというだけではなくて、タスクタイプの指定とか、(コンテキストとして使う?ための)テキストなども付与することができるみたい。で、これらをAPIが受け取れる形式に変えるのがTextEmbeddingInputなんだろうと推測する。
タスクタイプは以下を参照。
ではEmbeddingsを生成する。
tex_embeddings = embed_text(texts=["人生とはなにか?"])
print("次元数: ", len(tex_embeddings[0]))
print("最初の5つのベクトル: ", tex_embeddings[0][:5])
次元数: 768
最初の5つのベクトル: [-0.02345004864037037, -0.013124588876962662, 0.020080478861927986, 0.058531247079372406, 0.06588069349527359]
768次元。これはtextembedding-gecko-multilingual@001でも同じ。
tex_embedding = embed_text(texts=["人生とはなにか?"], model_name="textembedding-gecko-multilingual@001")
print("次元数: ", len(tex_embedding[0]))
print("最初の5つのベクトル: ", tex_embedding[0][:5])
次元数: 768
最初の5つのベクトル: [0.04941846802830696, -0.058661121875047684, 0.03444116562604904, 0.01983124203979969, -0.04570037126541138]
次に複数のEmbeddingsの比較をやってみる。
pandasのデータフレームのテキストからまるっとEmbeddingsを作成する。
import pandas as pd
text = [
"昨夜の映画は本当に面白かった。",
"昨日は映画のような素晴らしいシーンがたくさんあった。",
"数日前、Pythonスクリプトを書くのがとても楽しかった。",
"私の.pyスクリプトがエラーなしで実行されたとき、すごく安心した。",
"ああロミオ、あなたはなぜロミオなの。",
]
df = pd.DataFrame(text, columns=["text"])
df
df["embeddings"] = df.apply(lambda x: embed_text([x.text])[0], axis=1)
df
各テキストについては、最初の2つは「映画」に関するもの、次の2つは「プログラミング」に関するもの、最後の1つはそのどちらとも関係ないものとなっている。同じ意味ならばコサイン類似度のスコアは高くなるはず。
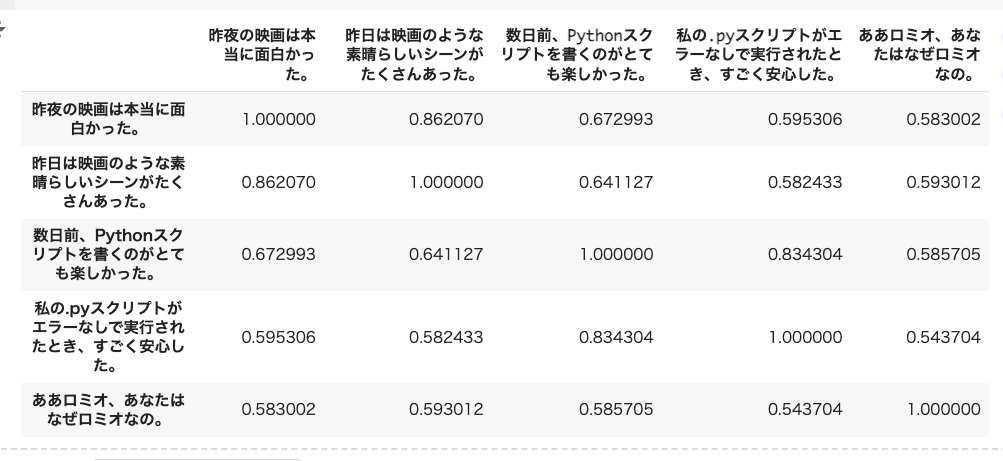
各テキスト同士のコサイン類似度スコアのマトリックスを作成する。
from sklearn.metrics.pairwise import cosine_similarity
cos_sim_array = cosine_similarity(list(df.embeddings.values))
df = pd.DataFrame(cos_sim_array, index=text, columns=text)
df
ヒートマップにしてみる。
!pip install japanize-matplotlib
import japanize_matplotlib
import seaborn as sns
ax = sns.heatmap(df, annot=True, cmap="crest")
ax.xaxis.tick_top()
ax.set_xticklabels(text, rotation=90)
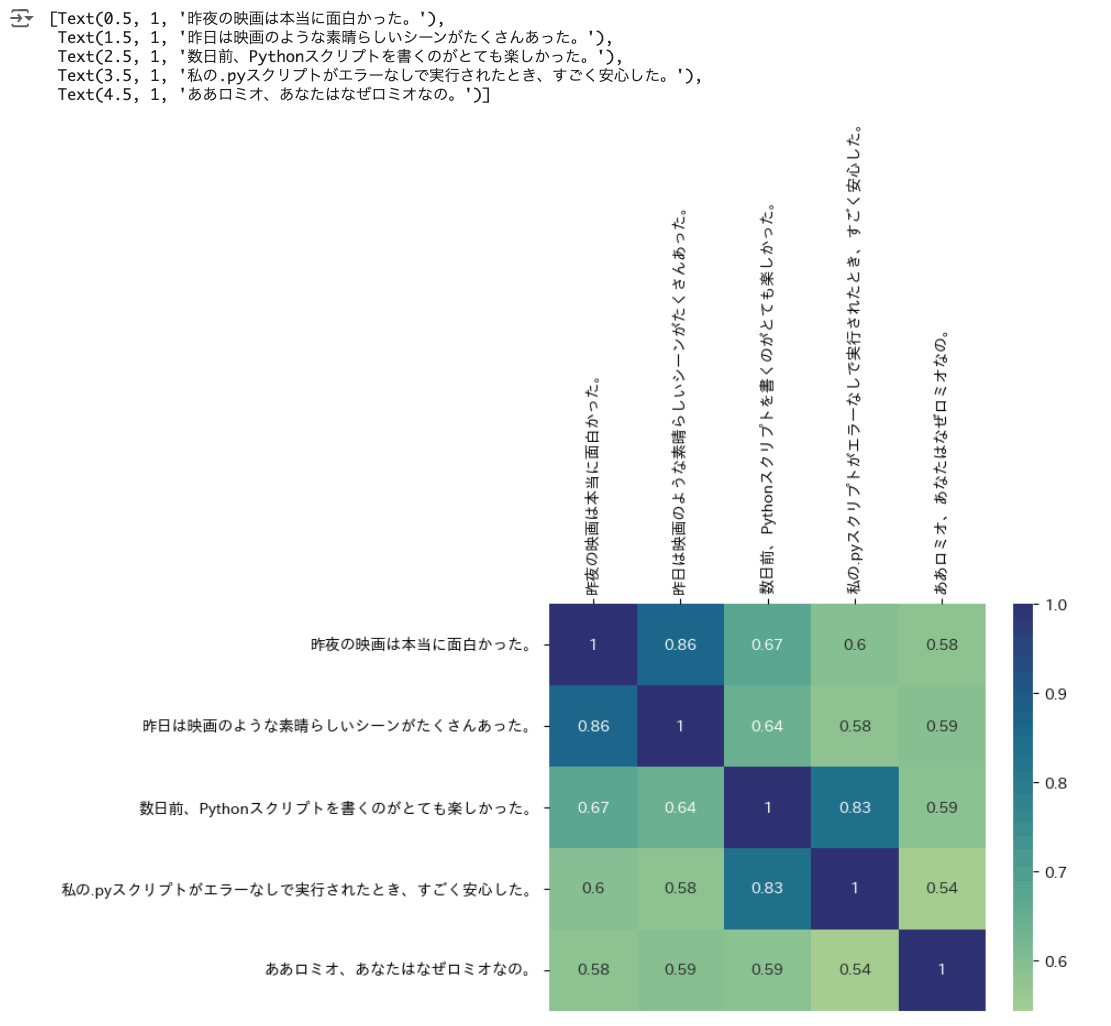
わかりやすい。
マルチモーダルのEmbeddings生成
次にマルチモーダルなデータからのEmbeddingsを生成する。notebookのサンプルコードだと、画像・動画・テキストをまるっと全部処理できるような関数が用意されているけど、個人的には細かくステップバイステップで見ていきたいので、以下のドキュメントのほうをまず進めてみる。
画像とテキスト
notebook中にサンプルとして使用されている以下の画像を使ってやってみる。

- URL:
https://storage.googleapis.com/github-repo/embeddings/getting_started_embeddings/gms_images/GGOEACBA104999.jpg - Cloud Storage URI:
gs://github-repo/embeddings/getting_started_embeddings/gms_images/GGOEACBA104999.jpg
ドキュメントのコードをちょっといじった。
from typing import Optional
from vertexai.vision_models import (
Image,
MultiModalEmbeddingModel,
MultiModalEmbeddingResponse,
)
def get_image_embeddings(
image_path: Optional[str] = None,
contextual_text: Optional[str] = None,
dimension: Optional[int] = 1408,
) -> MultiModalEmbeddingResponse:
"""画像とテキストからマルチモーダル埋め込みを生成するサンプル
引数:
image_path: Embeddingsを生成したい画像へのパス(ローカルまたはGoogle Cloud Storage)。
contextual_text: Embeddingsを生成したいテキスト
"""
# 入力チェック
if not any([image_path, contextual_text]):
raise ValueError(
"image_path、contextual_textのうち少なくとも1つを指定しなければならない。"
)
model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
image = Image.load_from_file(image_path)
embeddings = model.get_embeddings(
image=image,
contextual_text=contextual_text,
dimension=dimension,
)
if image_path:
print(f"画像のEmbeddings(最初の5つ): {embeddings.image_embedding[:5]}")
print(f"画像のEmbeddingの次元数: {len(embeddings.image_embedding)}")
result["image_embedding"] = embeddings.image_embedding
if contextual_text:
print(f"テキストのEmbeddings(最初の5つ): {embeddings.text_embedding[:5]}")
print(f"テキストのEmbeddingの次元数: {len(embeddings.text_embedding)}")
result["text_embedding"] = embeddings.image_embedding
return embeddings
サンプル画像をダウンロードしておく。これはローカル画像のパスおよびGCSのURIの両方で生成できることを確認するため。
!wget https://storage.googleapis.com/github-repo/embeddings/getting_started_embeddings/gms_images/GGOEACBA104999.jpg
まずローカルでの指定。
result = get_image_embeddings(image_path="./GGOEACBA104999.jpg")
画像のEmbeddings(最初の5つ): [-0.0019787054, 0.0347966328, -0.013123326, 0.019116506, -0.00567689398]
画像のEmbeddingの次元数: 1408
Cloud Storage URIの場合
result_from_gcs = get_image_embeddings(image_path="gs://github-repo/embeddings/getting_started_embeddings/gms_images/GGOEACBA104999.jpg")
画像のEmbeddings(最初の5つ): [-0.000501200848, 0.0334769525, -0.0165630654, 0.0210420564, -0.00548546249]
画像のEmbeddingの次元数: 1408
微妙に違うのだけど、これはファイルのパスが違うというよりは、そもそも決定論的な生成にはならないということだと思う。例えば、同じローカルファイルに対して何度か実行しても異なる結果が返ってくる場合が見られる。
result_from_local = get_image_embeddings(image_path="./GGOEACBA104999.jpg")
画像のEmbeddings(最初の5つ): [-0.00197869935, 0.0347966291, -0.0131233269, 0.019116506, -0.00567689491]
画像のEmbeddingの次元数: 1408
画像のEmbeddings(最初の5つ): [-0.00197872613, 0.0347953774, -0.0131245879, 0.019115936, -0.00567569211]
画像のEmbeddingの次元数: 1408
ただし、コサイン類似度を見るとかなり近似ではある。
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity([result_from_local.image_embedding], [result_from_gcs.image_embedding])
array([[0.9971872]])
なので、全く同じではないけど限りなく近い、ってのが自分の理解。ただねぇ、テキストモデルだと毎回同じ値が返ってくるように見えるんだよね。。。まあとりあえずそういうものだと思うことにする。
contextual_textの役割がよくわからないのだけど、
マルチモーダル エンベディング モデルを使用する場合は、入力時の次のことを考慮してください。
画像内のテキスト - このモデルは、光学式文字認識(OCR)と同様に、画像内のテキストを認識できます。画像コンテンツの説明と画像内のテキストを区別する必要がある場合は、プロンプト エンジニアリングを使用してターゲット コンテンツを指定することを検討してください。たとえば、ユースケースに応じて単に「cat」ではなく「picture of a cat」または「the text 'cat'」と指定します。
インタフェースだけ見ると、画像とテキストで別々にEmbeddingsが返ってくるだけ、に見えるんだけど、テキストの指定の仕方で何かしら画像のEmbeddingsに違いが出てくる、ということを言ってるのかな???
result_from_local = get_image_embeddings(image_path="./GGOEACBA104999.jpg", contextual_text="Google Official Merchandise Storeのロゴ" )
画像のEmbeddings(最初の5つ): [-0.00197867909, 0.0347970575, -0.0131232375, 0.0191165507, -0.00567663927]
画像のEmbeddingの次元数: 1408
テキストのEmbeddings(最初の5つ): [0.0354781933, -0.00838512462, 0.0484448671, 0.0228634682, -0.0095236944]
テキストのEmbeddingの次元数: 1408
なお、次元数は1408がデフォルト。画像とテキストを両方指定した場合はそれぞれ1408次元で生成されている。次元数は128、256、512、1408から選択できる。
result_from_local = get_image_embeddings(image_path="./GGOEACBA104999.jpg", contextual_text="Google Official Merchandise Storeのロゴ画像", dimension=128)
画像のEmbeddings(最初の5つ): [0.131704286, -0.0571240336, 0.0709968135, 0.0199303664, -0.436987]
画像のEmbeddingの次元数: 128
テキストのEmbeddings(最初の5つ): [0.254867524, -0.215968519, 0.0942107812, 0.105873935, -0.128779545]
テキストのEmbeddingの次元数: 128
インタフェースだけ見ると、画像とテキストで別々にEmbeddingsが返ってくるだけ、に見えるんだけど、テキストの指定の仕方で何かしら画像のEmbeddingsに違いが出てくる、ということを言ってるのかな???
についてだけど、ドキュメントには、
画像エンベディング ベクトルとテキスト エンベディング ベクトルは、同じ次元を持つ同じセマンティック空間にあります。そのため、これらのベクトルは、テキストによる画像の検索や画像による動画の検索などのユースケースでも使用できます。
とある。「同じ次元を持つ同じセマンティック空間にある」ということが重要なのかもしれない。notebookの下の方にそれっぽいものがあるので、実際に試してみて確認する。
画像と動画とテキスト
ここは少しハマった。notebookでは画像・動画・テキストをまるっと受け取るコードが書かれているが、一旦動画とテキストだけにする。
from typing import Optional
from vertexai.vision_models import (
MultiModalEmbeddingModel,
MultiModalEmbeddingResponse,
Image,
Video,
VideoSegmentConfig,
)
def get_video_text_embeddings(
video_path: Optional[str] = None,
contextual_text: Optional[str] = None,
video_segment_config: Optional[VideoSegmentConfig] = None,
) -> MultiModalEmbeddingResponse:
"""動画とテキストからマルチモーダルEmbeddingsを生成するサンプル
引数:
video_path: 動画へのパス(ローカルまたはGoogle Cloud Storage).
contextual_text: Embeddingsを生成するテキスト。
video_segment_config: 動画の特定のセグメントのembeddingsを指定する場合に定義
戻り値:
MultiModalEmbeddingResponse: 生成されたembeddings
例外:
ValueError: video_path、contextual_textのいずれも指定されていない場合。
"""
# 入力チェック
if not any([video_path, contextual_text]):
raise ValueError(
"video_path、contextual_textのうち少なくとも1つを指定しなければならない。"
)
video = VMVideo.load_from_file(video_path) if video_path else None
model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
embeddings = model.get_embeddings(
video=video,
video_segment_config=video_segment_config,
contextual_text=contextual_text,
# 注: 動画のembeddingは1408次元のみのサポートとなるらしく、その場合に
# dimensionを渡すと以下のエラーとなった
# "400 Parameter dimension is not supported with video input."
#dimension=dimension,
)
if video_path:
print("動画のEmbeddings:")
for video_embedding in embeddings.video_embeddings:
print(
f"動画のセグメント: {video_embedding.start_offset_sec} - {video_embedding.end_offset_sec}"
)
print(f"動画のEmbedding (最初の5つ): {video_embedding.embedding[:5]}")
print(f"動画のEmbeddingの次元数: {len(video_embedding.embedding)}")
if contextual_text:
print(f"\n\テキストのEmbedding (最初の5つ):\n{embeddings.text_embedding[:5]}")
print(f"テキストのEmbeddingの次元数: {len(embeddings.text_embedding)}")
return embeddings
まず、コメントにもある通り、動画を入力として渡す場合、生成されるベクトルの次元数は1408次元固定となる。この時、get_embeddings()にdimensionを渡しただけでエラーとなってしまう。公式のドキュメントでもnotebookでもdimensionを渡しているのだけど、何かしら変わったのだろうか。。。とりあえずパラメータを渡さなければ問題にはならないので、上記のとおりコメントアウトしてある。
あと、動画の場合は返ってくるEmbeddingsが複数になる場合があり、少しややこしくなっている。その点については後述する。
ではサンプル動画でEmbeddingsを生成してみる。4秒程度の短い動画が使用されていた。
result = get_video_text_embeddings(
video_path="gs://github-repo/embeddings/getting_started_embeddings/UCF-101-subset/BrushingTeeth/v_BrushingTeeth_g01_c02.mp4",
)
動画のEmbeddings:
動画のセグメント: 0.0 - 4.0
動画のEmbedding (最初の5つ): [-0.0114297699, 0.0216636304, -0.00484452536, -0.0174836554, -0.0042092572]
動画のEmbeddingの次元数: 1408
ここまでは問題なし。
では次にすこし長めの動画ファイルを食わせてみる。notebook内ではGeminiの発表動画をサンプルとして使用しているようだが、ファイルのパスが間違っているのかアクセスが出来ない。そこで、前回Geminiのマルチモーダルのnotebookで使用されていたPixel 8の動画を使用する。約57秒の動画となっている。
result = get_video_text_embeddings(
video_path="https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/pixel8.mp4",
)
動画のEmbeddings:
動画のセグメント: 16.0 - 32.0
動画のEmbedding (最初の5つ): [-0.00973161496, 0.0111130653, 0.00665146811, -0.0556553118, 0.0174725112]
動画のEmbeddingの次元数: 1408
動画のセグメント: 32.0 - 48.0
動画のEmbedding (最初の5つ): [0.00299568451, 0.022847509, 0.016756935, -0.0245801918, 0.00889374595]
動画のEmbeddingの次元数: 1408
動画のセグメント: 48.0 - 57.0
動画のEmbedding (最初の5つ): [-0.02092891, 0.021230761, 0.0158218574, -0.0362376273, -0.0115748961]
動画のEmbeddingの次元数: 1408
動画のセグメント: 0.0 - 16.0
動画のEmbedding (最初の5つ): [-0.00696331589, 0.0332052819, -0.00987485703, -0.0436796248, 0.0252755061]
動画のEmbeddingの次元数: 1408
上記の通り、15秒きざみでベクトルが生成されているのがわかる。これについてはドキュメントに記載されている。
動画エンベディングでは、Essentials、Standard、Plus の 3 つのモードを使用できます。モードは、生成されるエンベディングの密度に対応します。これは、リクエストの interval_sec 構成で指定できます。動画の間隔(interval_sec)ごとにエンベディングが生成されます。動画の最小間隔は 4 秒です。間隔が 120 秒を超えると、生成されたエンベディングの品質に悪影響を及ぼす可能性があります。
モード 1 分あたりの最大エンベディング数 動画のエンベディング間隔(最小値) Essential 4 15
これは intervalSec >= 15 に対応しますStandard 8 8
これは 8 <= intervalSec < 15 に対応しますPlus 15 4
これは 4 <= intervalSec < 8 に対応します。
どうやらデフォルトはEssentialになるため、15秒単位で分割されてそれぞれのベクトルが生成されている模様。この設定はVideoSegmentConfigで渡すことができる。
result = get_video_text_embeddings(
video_path="https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/pixel8.mp4",
video_segment_config=VideoSegmentConfig(interval_sec=30)
)
動画のEmbeddings:
動画のセグメント: 0.0 - 30.0
動画のEmbedding (最初の5つ): [-0.00747315772, 0.0231392253, -0.00478377566, -0.0500261262, 0.0244251676]
動画のEmbeddingの次元数: 1408
動画のセグメント: 30.0 - 57.0
動画のEmbedding (最初の5つ): [-0.00670166919, 0.0220944714, 0.0124308355, -0.0309892967, 0.00155757496]
動画のEmbeddingの次元数: 1408
VideoSegmentConfigでinterval_secを指定するとその秒数で分割される様子。最小は4秒、最大はないみたいだけど、120秒を超えるとEmbedding品質が悪くなる可能性があるらしいので、実質120秒が最大になるのだろうと思う。2分を超えるような動画の場合には開始時間と終了時間を指定して別々のリクエストとして送信するのが良いらしい。
開始時間と終了時間の指定はVideoSegmentConfigにstart_offset_sec/end_offset_secを渡す。以下の例だと、0:10〜0:30の間で10秒単位でベクトルを生成するということになる。
result = get_video_text_embeddings(
video_path="https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/pixel8.mp4",
video_segment_config=VideoSegmentConfig(
start_offset_sec=10, end_offset_sec=30, interval_sec=10
)
)
動画のEmbeddings:
動画のセグメント: 20.0 - 30.0
動画のEmbedding (最初の5つ): [-0.0154926768, 0.0217329264, 0.00186536461, -0.0545654707, 0.016511837]
動画のEmbeddingの次元数: 1408
動画のセグメント: 10.0 - 20.0
動画のEmbedding (最初の5つ): [0.00588851515, 0.000817522, -0.00122922356, -0.0472423211, 0.0320140608]
動画のEmbeddingの次元数: 1408
ということで、画像・動画・テキストをすべて扱うような関数を少し修正してみた。
from typing import Optional
from vertexai.vision_models import (
MultiModalEmbeddingModel,
MultiModalEmbeddingResponse,
Image,
Video,
VideoSegmentConfig,
)
def get_image_video_text_embeddings(
image_path: Optional[str] = None,
video_path: Optional[str] = None,
contextual_text: Optional[str] = None,
dimension: Optional[int] = 1408,
video_segment_config: Optional[VideoSegmentConfig] = None,
debug: bool = False,
) -> MultiModalEmbeddingResponse:
"""画像、動画、テキストからマルチモーダルEmbeddingsを生成する。
引数:
image_path: 画像へのパス(ローカルまたはGoogle Cloud Storage).
video_path: 動画へのパス(ローカルまたはGoogle Cloud Storage).
contextual_text: Embeddingsを生成するテキスト。最大: 32トークン(~32語) ※日本語の場合どうなるかは不明
dimension: 生成されるEmbeddingsの次元数(128, 256, 512, 1408).
注: ただし動画を指定した場合は1408固定となり、このオプションしては無視する
video_segment_config: 動画の特定のセグメントのembeddingsを指定する場合に定義
debug: Trueの場合はデバッグ情報を出力する
戻り値:
MultiModalEmbeddingResponse: 生成されたembeddings
例外:
ValueError: image_path、video_path、contextual_textのいずれも指定されていない場合。
"""
# 入力チェック
if not any([image_path, video_path, contextual_text]):
raise ValueError(
"image_path、video_path、contextual_textのうち少なくとも1つを指定しなければならない。"
)
image = Image.load_from_file(image_path) if image_path else None
video = Video.load_from_file(video_path) if video_path else None
model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
if video_path:
if debug:
print("[WARN] video_pathが指定されているため、次元数は1408固定とする(dimensionパラメータは指定されても無視する)")
embeddings = model.get_embeddings(
image=image,
video=video,
video_segment_config=video_segment_config,
contextual_text=contextual_text,
# 注: 動画のembeddingは1408次元しかサポートしていないらしく、その場合に
# dimensionを渡すと以下のエラーとなったため、video_path定義の有無
# で振り分けている
# "400 Parameter dimension is not supported with video input."
#dimension=dimension,
)
else:
embeddings = model.get_embeddings(
image=image,
contextual_text=contextual_text,
dimension=dimension,
)
if image_path:
if debug:
print(
f"\n画像のEmbedding (最初の5つ):\n{embeddings.image_embedding[:5]}"
)
print(f"画像のEmbeddingの次元数: {len(embeddings.image_embedding)}")
if video_path:
if debug:
print("\n動画のEmbeddings:")
for video_embedding in embeddings.video_embeddings:
print(
f"動画のセグメント: {video_embedding.start_offset_sec} - {video_embedding.end_offset_sec}"
)
print(f"動画のEmbedding (最初の5つ): {video_embedding.embedding[:5]}")
print(f"動画のEmbeddingの次元数: {len(video_embedding.embedding)}")
if contextual_text:
if debug:
print(f"\nテキストのEmbedding (最初の5つ): {embeddings.text_embedding[:5]}")
print(f"テキストのEmbeddingの次元数: {len(embeddings.text_embedding)}")
return embeddings
フルで指定するとこんな感じ。
result = get_image_video_text_embeddings(
image_path="gs://github-repo/embeddings/getting_started_embeddings/gms_images/GGOEAFKA194799.jpg",
video_path="https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/pixel8.mp4",
video_segment_config=VideoSegmentConfig(
start_offset_sec=0, end_offset_sec=30, interval_sec=10
),
contextual_text="これはサンプルのテキストです",
dimension=256,
debug=True,
)
[WARN] video_pathが指定されているため、次元数は1408固定とする(dimensionパラメータは指定されても無視する)
画像のEmbedding (最初の5つ):
[-0.0197034124, -0.00681778695, 0.0384943374, 0.0452300571, -0.0138596185]
画像のEmbeddingの次元数: 1408
動画のEmbeddings:
動画のセグメント: 10.0 - 20.0
動画のEmbedding (最初の5つ): [0.00596320396, 0.00104989228, -0.00201187539, -0.0476508811, 0.0321316347]
動画のEmbeddingの次元数: 1408
動画のセグメント: 20.0 - 30.0
動画のEmbedding (最初の5つ): [-0.0164193157, 0.0222128425, 0.00168441981, -0.0541103818, 0.0162441041]
動画のEmbeddingの次元数: 1408
動画のセグメント: 0.0 - 10.0
動画のEmbedding (最初の5つ): [-0.00799866114, 0.0416130796, -0.0151198022, -0.039856147, 0.022488011]
動画のEmbeddingの次元数: 1408
テキストのEmbedding (最初の5つ): [-0.0217833128, 0.0271377545, -0.00984447636, -0.00390860206, 0.0133147221]
テキストのEmbeddingの次元数: 1408
マルチモーダルEmbeddingを使った検索
notebookを続けていくと、マルチモーダルEmbeddingを使った検索のサンプルがあるので、これをやってみる。
テキスト・画像
ここではテキスト・画像と動画の2パターンが用意されているのだが、残念ながらサンプルデータは英語が前提になっていて、テキストtextembedding-gecko@003で用意されている模様。
そこはやっぱり日本語でやりたい、ということで、テキスト部分をGoogle翻訳で日本語化してやってみた。
CSVからpandasのデータフレームを作成。
import pandas as pd
data_url = "https://gist.githubusercontent.com/kun432/72e75999da3c593250246d492aa07f92/raw/40f55dcfe5f89d0ef85ec5023d2d280e11b34fbd/image_data_without_embeddings_jp.csv"
image_data_without_embeddings = pd.read_csv(data_url)
image_data_without_embeddings.head(10)
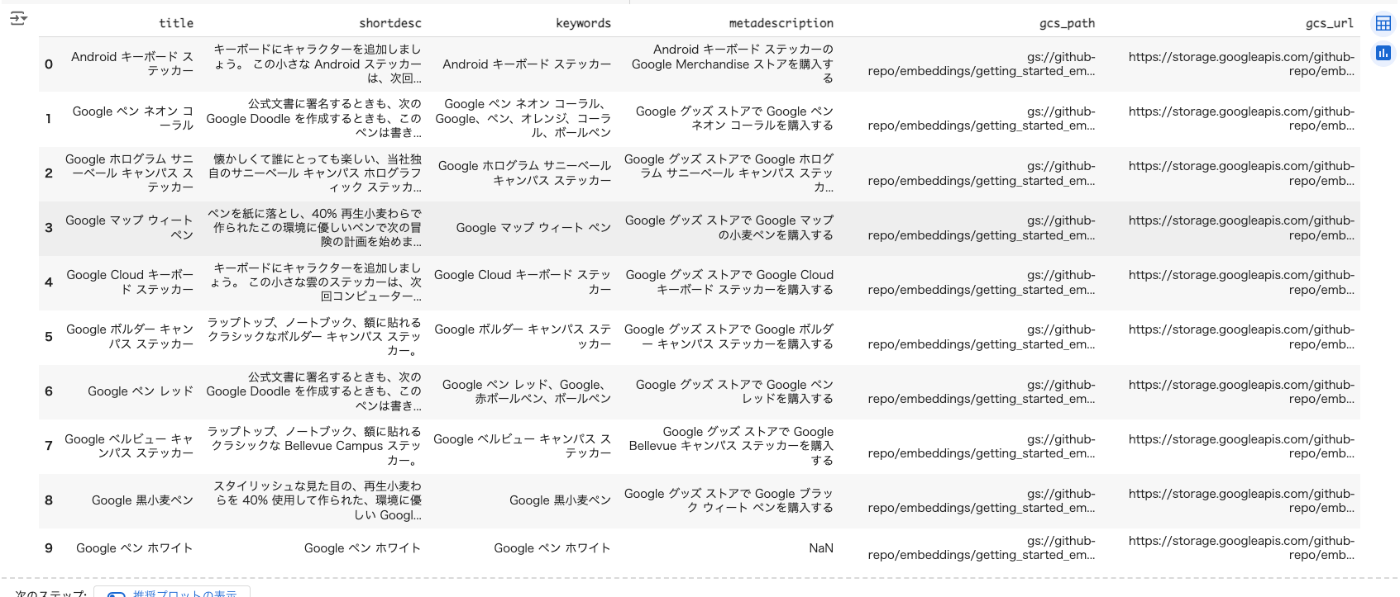
上の方で作成したEmbeddings生成用関数を使用して、画像とテキストのEmbeddingsをそれぞれ生成する。画像はmultimodalembedding、テキストはtext-multilingual-embedding-002を使用した。
from tqdm.notebook import tqdm
from typing import Optional, List
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
from vertexai.vision_models import (
MultiModalEmbeddingModel,
MultiModalEmbeddingResponse,
Image,
Video,
VideoSegmentConfig,
)
def embed_text(
texts: List[str] = ["バナナマフィンですか?", "バナナブレッドですか?それともバナナマフィンですか?"],
model_name: str = "text-multilingual-embedding-002",
) -> List[List[float]]:
"""事前学習済みの基礎モデルを使ってテキストを埋め込む"""
model = TextEmbeddingModel.from_pretrained(model_name)
inputs = [TextEmbeddingInput(text) for text in texts]
embeddings = model.get_embeddings(inputs)
return [embedding.values for embedding in embeddings]
def get_image_video_text_embeddings(
image_path: Optional[str] = None,
video_path: Optional[str] = None,
contextual_text: Optional[str] = None,
dimension: Optional[int] = 1408,
video_segment_config: Optional[VideoSegmentConfig] = None,
debug: bool = False,
) -> MultiModalEmbeddingResponse:
"""画像、動画、テキストからマルチモーダルEmbeddingsを生成する。
引数:
image_path: 画像へのパス(ローカルまたはGoogle Cloud Storage).
video_path: 動画へのパス(ローカルまたはGoogle Cloud Storage).
contextual_text: Embeddingsを生成するテキスト。最大: 32トークン(~32語) ※日本語の場合どうなるかは不明
dimension: 生成されるEmbeddingsの次元数(128, 256, 512, 1408).
注: ただし動画を指定した場合は1408固定となり、このオプションしては無視する
video_segment_config: 動画の特定のセグメントのembeddingsを指定する場合に定義
debug: Trueの場合はデバッグ情報を出力する
戻り値:
MultiModalEmbeddingResponse: 生成されたembeddings
例外:
ValueError: image_path、video_path、contextual_textのいずれも指定されていない場合。
"""
# 入力チェック
if not any([image_path, video_path, contextual_text]):
raise ValueError(
"image_path、video_path、contextual_textのうち少なくとも1つを指定しなければならない。"
)
image = Image.load_from_file(image_path) if image_path else None
video = Video.load_from_file(video_path) if video_path else None
model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
if video_path:
if debug:
print("[WARN] video_pathが指定されているため、次元数は1408固定とする(dimensionパラメータは指定されても無視する)")
embeddings = model.get_embeddings(
image=image,
video=video,
video_segment_config=video_segment_config,
contextual_text=contextual_text,
# 注: 動画のembeddingは1408次元しかサポートしていないらしく、その場合に
# dimensionを渡すと以下のエラーとなったため、video_path定義の有無
# で振り分けている
# "400 Parameter dimension is not supported with video input."
#dimension=dimension,
)
else:
embeddings = model.get_embeddings(
image=image,
video=video,
video_segment_config=video_segment_config,
contextual_text=contextual_text,
dimension=dimension,
)
if image_path:
if debug:
print(
f"\n画像のEmbedding (最初の5つ):\n{embeddings.image_embedding[:5]}"
)
print(f"画像のEmbeddingの次元数: {len(embeddings.image_embedding)}")
if video_path:
if debug:
print("\n動画のEmbeddings:")
for video_embedding in embeddings.video_embeddings:
print(
f"動画のセグメント: {video_embedding.start_offset_sec} - {video_embedding.end_offset_sec}"
)
print(f"動画のEmbedding (最初の5つ): {video_embedding.embedding[:5]}")
print(f"動画のEmbeddingの次元数: {len(video_embedding.embedding)}")
if contextual_text:
if debug:
print(f"\nテキストのEmbedding (最初の5つ): {embeddings.text_embedding[:5]}")
print(f"テキストのEmbeddingの次元数: {len(embeddings.text_embedding)}")
return embeddings
tqdm.pandas()
# 元のデータフレームをコピーして新しいデータフレームを作成、そちらにEmbeddingsを追加していく
image_data_with_embeddings = image_data_without_embeddings.copy()
# 複数の列のテキストを連結して新しいカラムに追加
image_data_with_embeddings["combined_text"] = (
image_data_with_embeddings["title"].fillna("")
+ " "
+ image_data_with_embeddings["keywords"].fillna("")
+ " "
+ image_data_with_embeddings["metadescription"].fillna("")
)
# 画像のEmbeddingsを生成して新しい列に追加(1408次元)
image_data_with_embeddings["image_embeddings"] = image_data_with_embeddings[
"gcs_path"
].progress_apply(lambda x: get_image_video_text_embeddings(image_path=x).image_embedding)
# テキストのEmbeddingsを生成して新しい列に追加(768次元)
image_data_with_embeddings["text_embeddings"] = image_data_with_embeddings[
"combined_text"
].progress_apply(lambda x: embed_text([x])[0])
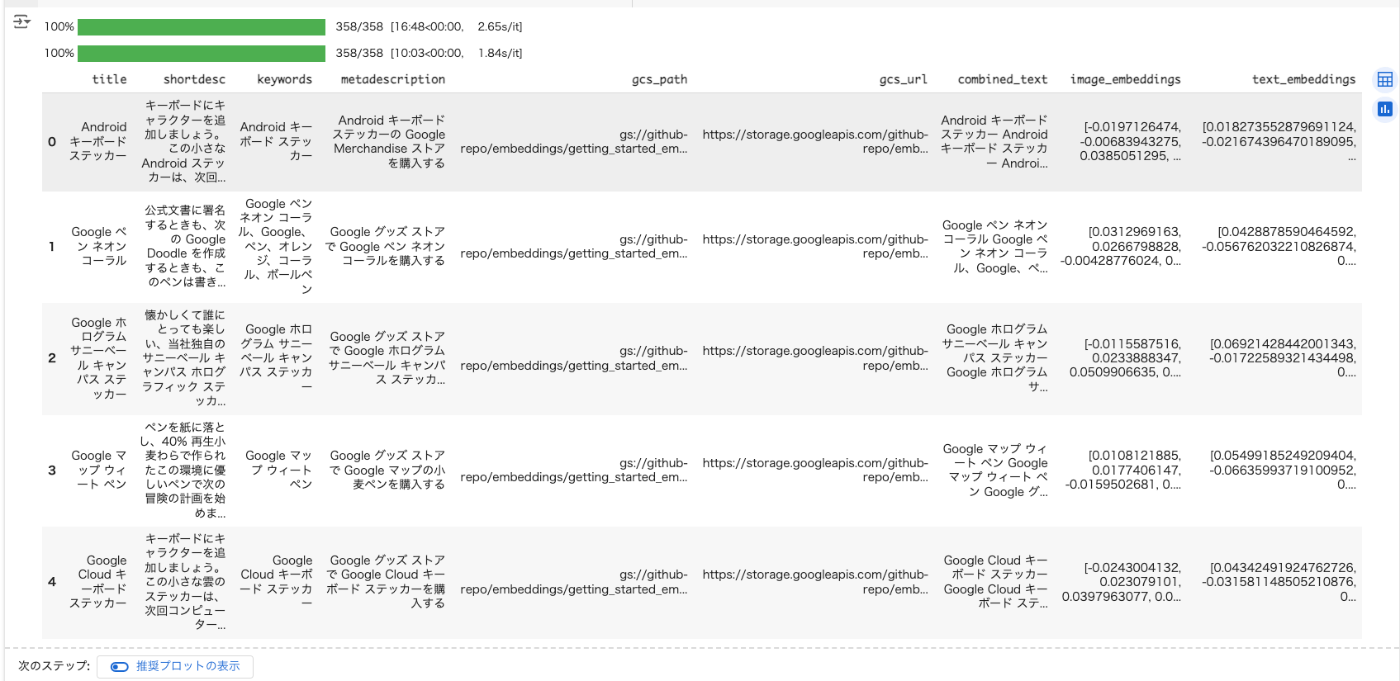
image_data_with_embeddings.head()
結構時間がかかる。自分が試した際は約30分ぐらいかかった。
以下のようにそれぞれのEmbeddingsが作成されればOK。
では検索。まず、notebookで表示用のヘルパー関数を読み込んでおく。
from typing import Union, Dict, Any
from IPython.display import Image as ImageByte, display
from PIL import Image as PIL_Image
import requests
from io import BytesIO
def print_shortlisted_products(
shortlisted_products: Union[Dict, Any], display_flag: bool = False, max_size: int = 300
) -> None:
"""候補に挙がった製品に関する情報を出力し、オプションで画像を表示する。
Args:
shortlisted_products: 'score', 'gcs_path', 'gcs_url'等キーとする商品データを含む辞書のようなオブジェクト。
display_flag: Trueの場合、IPythonを使って商品の画像を表示する。
max_size: 画像の最大サイズ(幅または高さ)。これを超える場合、画像はリサイズされる。
"""
print("認識された類似商品 ---- \n")
for (
index,
product,
) in shortlisted_products.iterrows():
score = product["score"]
gcs_path = product["gcs_path"]
url = product["gcs_url"]
print(f"Product {index + 1}: Confidence Score: {score}")
print(url)
if display_flag:
# 画像をダウンロードし、PILイメージとして開く
response = requests.get(url)
img = PIL_Image.open(BytesIO(response.content))
# 画像が指定サイズより大きい場合、リサイズする
if img.width > max_size or img.height > max_size:
img.thumbnail((max_size, max_size))
# バイトストリームに変換して表示
buffered = BytesIO()
img.save(buffered, format="PNG")
display(ImageByte(data=buffered.getvalue()))
print()
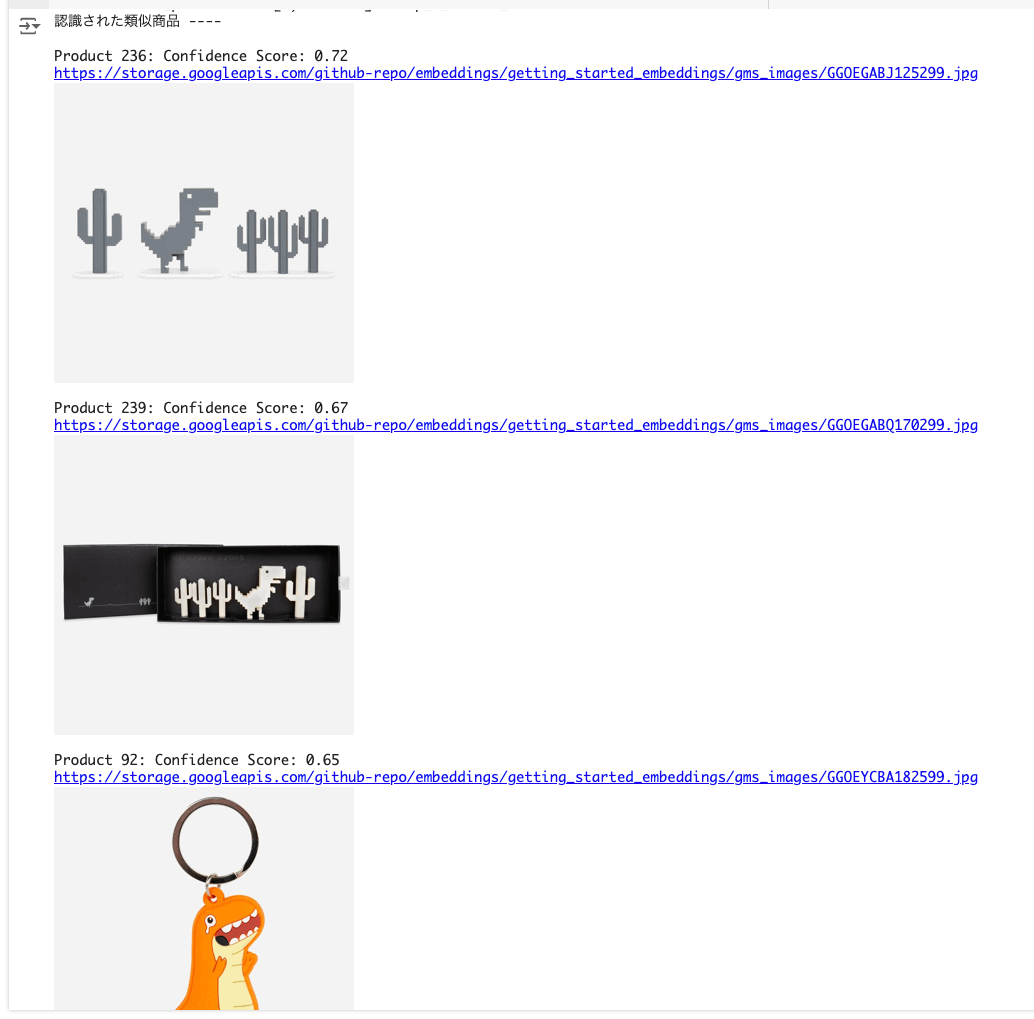
テキストで検索。
import numpy as np
search_query = "恐竜がモチーフのものが欲しいな。"
# ステップ1 - 「検索クエリ」をEmbeddingsに変換
search_query_embedding = embed_text([search_query])[0]
# ステップ2 - search_query_embeddingとimage_data_with_embeddings['text_embeddings']のコサイン類似度(または単にnp.dot)を求める。
cosine_scores = image_data_with_embeddings["text_embeddings"].apply(
lambda x: round(np.dot(x, search_query_embedding), 2)
) # eval is used to convert string of list to list
# ステップ3 - コサインスコア順にソートし、上位3件の結果を選ぶ。
top_3_indices = cosine_scores.nlargest(3).index.tolist()
top_n_cosine_values = cosine_scores.nlargest(3).values.tolist()
# ステップ4 - image_data_with_embeddingsを、候補に挙がったインデックスでフィルタリングし、スコアを追加する。
shortlisted_products = image_data_with_embeddings.iloc[top_3_indices]
shortlisted_products.loc[:, "score"] = top_n_cosine_values
# ステップ5 - 候補に挙がった製品を表示する
print_shortlisted_products(
shortlisted_products,
display_flag=True, # 画像を表示するにはdisplay_flag=Trueを渡す。
)
一連の処理を関数化
def get_similar_products_from_text_query(
search_query: str,
top_n: int = 3,
threshold: float = 0.6,
embeddings_data: pd.DataFrame = image_data_with_embeddings,
) -> Optional[pd.DataFrame]:
"""
指定されたテキストクエリに最も類似した製品を、Embeddingsに基づいて検索する。
Args:
search_query: 類似商品を検索するためのテキストクエリ。
top_n: 返される類似商品の最大数。
threshold: 製品が類似しているとみなされるための最小コサイン類似度スコア。
embeddings_data: 商品のテキストEmbeddingsを含むデータフレーム'text_embeddings'というカラムを想定)。
Returns:
上位n個の類似商品とそのスコアを持つデータフレーム。閾値を満たすものがない場合は None となる。
"""
# ステップ1: 「検索クエリ」をEmbeddingsに変換
search_query_embedding = embed_text([search_query])[0]
# ステップ2: コサイン類似度を計算
cosine_scores = image_data_with_embeddings["text_embeddings"].apply(
lambda x: round(np.dot(x, search_query_embedding), 2)
)
# ステップ3: スコアのフィルタとソート
scores_above_threshold = cosine_scores[cosine_scores >= threshold]
top_n_indices = scores_above_threshold.nlargest(top_n).index.tolist()
# ステップ4: スコアのしきい値に満たない場合の対応
if len(top_n_indices) < top_n:
print(f"Warning: スコアしきい値に該当したのは {len(top_n_indices)} 件だけでした。")
# ステップ5: 商品とスコアを取得
if top_n_indices:
shortlisted_products = embeddings_data.iloc[top_n_indices].copy()
shortlisted_products["score"] = scores_above_threshold.nlargest(
top_n
).values.tolist()
else:
print("No scores meet the threshold. Consider lowering the threshold.")
shortlisted_products = None
return shortlisted_products
いろんなクエリを試してみる。
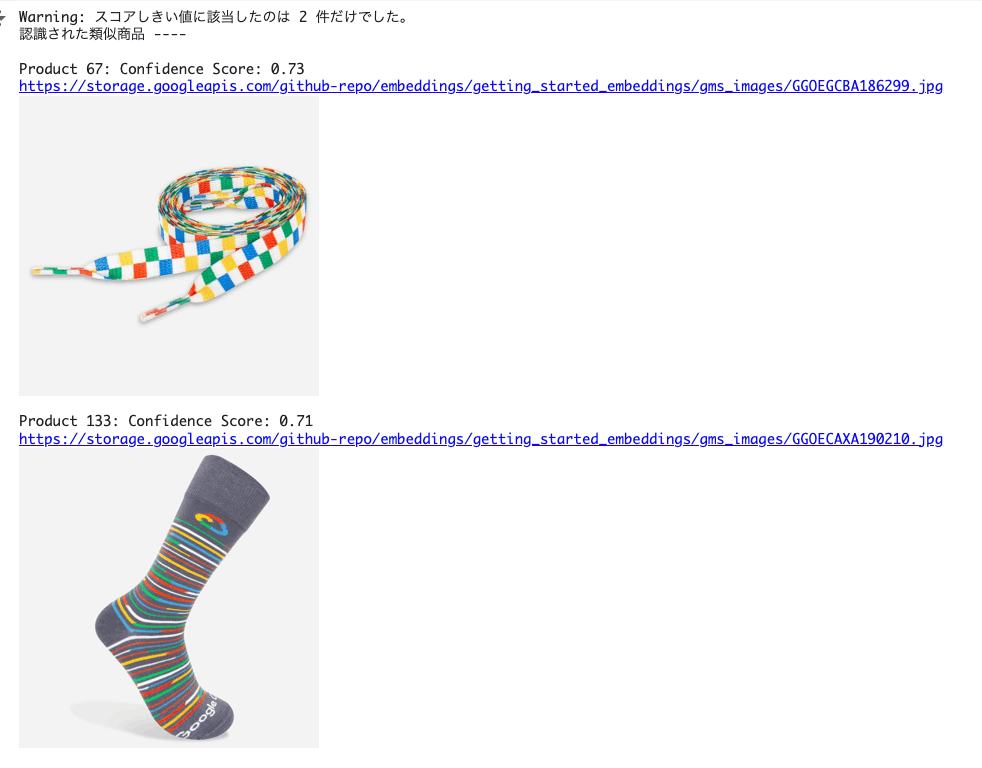
search_query = "チェック柄の靴下はある?"
shortlisted_products = get_similar_products_from_text_query(
search_query, top_n=3, threshold=0.7
)
print_shortlisted_products(
shortlisted_products,
display_flag=True,
)
search_query = "グーグルのロゴ入りのスウェットを探してるんだけど。"
shortlisted_products = get_similar_products_from_text_query(
search_query, top_n=3, threshold=0.6
)
print_shortlisted_products(
shortlisted_products,
display_flag=True,
)

ただ、ここはテキストでEmbeddings検索して、それに紐づいている画像データを引っ張ってきてるだけなので、まあ当然といえば当然。
ではある画像に類似した画像をEmbeddingsで検索する。
まず適当な画像を選択。
random_index = 135
liked_product = image_data_with_embeddings["gcs_path"][random_index]
liked_product_url = image_data_with_embeddings["gcs_url"][random_index]
print("お気に入り商品 ---")
print(liked_product_url)
display(ImageByte(url=liked_product_url))

この商品画像に類似した画像を検索する。
# ステップ1 - お気に入り商品画像('liked_product')をembeddingsに変換
liked_product_embedding = get_image_video_text_embeddings(image_path=liked_product).image_embedding
# ステップ2 - liked_product_embedding と image_data_with_embeddings['image_embeddings'] のコサイン類似度 (または単に np.dot) を計算
cosine_scores = image_data_with_embeddings["image_embeddings"].apply(
lambda x: round(np.dot(x, liked_product_embedding), 2)
)
# ステップ3 - コサイン類似度スコアをソート、しきい値でフィルタ(1.0以下でしきい値よりも高い値)して、上位2件を取得
threshold = 0.6
scores_above_threshold = cosine_scores[
(cosine_scores >= threshold) & (cosine_scores < 1.00)
]
top_2_indices = scores_above_threshold.nlargest(2).index.tolist()
top_2_cosine_values = scores_above_threshold.nlargest(2).values.tolist()
# ステップ4 - image_data_with_embeddingsを上記結果でフィルタ
shortlisted_products = image_data_with_embeddings.iloc[top_2_indices]
shortlisted_products.loc[:, "score"] = top_2_cosine_values
# ステップ5 - 検索結果を表示
print_shortlisted_products(shortlisted_products,display_flag=True)
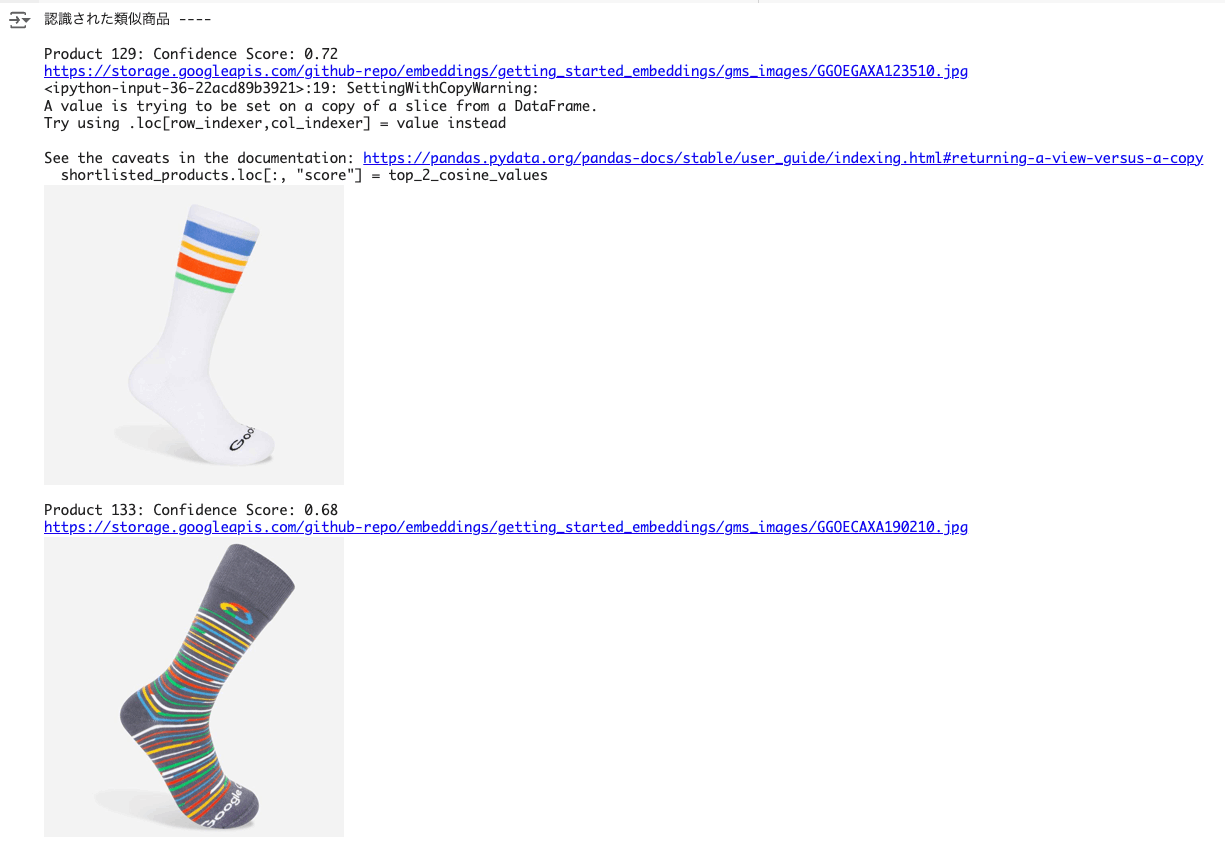
この一連の処理を関数化する。
def get_similar_products_from_image_query(
liked_product: Union[str, np.ndarray], top_n: int = 3, threshold: float = 0.6
) -> Optional[pd.DataFrame]:
"""
Retrieves similar products based on an image query.
This function takes an image path or embedding of a "liked" product, compares it to
a dataset of product embeddings, and returns the top N most similar products
that exceed a specified similarity threshold.
Args:
liked_product: Path to the image file of the liked product or its embedding.
top_n: The maximum number of similar products to return.
threshold: The minimum cosine similarity score for a product to be considered similar.
Returns:
A pandas DataFrame containing the top N similar products and their scores,
or None if no products meet the threshold.
"""
# ステップ1: お気に入り商品画像('liked_product')がembeddingsであることを確認
if isinstance(liked_product, str):
liked_product_embedding = get_image_video_text_embeddings(
image_path=liked_product
).image_embedding
else:
liked_product_embedding = liked_product
# ステップ2: コサイン類似度を計算
if isinstance(image_data_with_embeddings["image_embeddings"].iloc[0], str):
image_data_with_embeddings["image_embeddings"] = image_data_with_embeddings[
"image_embeddings"
].apply(eval)
cosine_scores = image_data_with_embeddings["image_embeddings"].apply(
lambda x: np.dot(x, liked_product_embedding)
)
# ステップ3: しきい値でフィルタして上位スコアのものを取得
scores_above_threshold = cosine_scores[
(cosine_scores >= threshold) & (cosine_scores < 1.0)
]
top_n_indices = scores_above_threshold.nlargest(top_n).index.tolist()
top_n_cosine_values = scores_above_threshold.nlargest(top_n).values.tolist()
# ステップ4: しきい値に満たない場合の対応
if len(top_n_indices) < top_n:
print(f"Warning: スコアしきい値に該当したのは {len(top_n_indices)} 件だけでした。")
# Step 5: スコアが取得できたら結果を返す
if top_n_indices:
shortlisted_products = image_data_with_embeddings.iloc[top_n_indices].copy()
shortlisted_products["score"] = top_n_cosine_values
return shortlisted_products
else:
print("しきい値を満たすものはありませんでした。閾値を下げてみてください。")
return None
いろいろ適当に選んで検索してみる。
random_index = 10
liked_product = image_data_with_embeddings["gcs_path"][random_index]
liked_product_url = image_data_with_embeddings["gcs_url"][random_index]
print("お気に入り商品 ---")
print(liked_product_url)
display(ImageByte(url=liked_product_url))

shortlisted_products = get_similar_products_from_image_query(
liked_product, top_n=3, threshold=0.6
)
print_shortlisted_products(shortlisted_products,display_flag=True)

random_index = 119
liked_product = image_data_with_embeddings["gcs_path"][random_index]
liked_product_url = image_data_with_embeddings["gcs_url"][random_index]
print("お気に入り商品 ---")
print(liked_product_url)
display(ImageByte(url=liked_product_url))

shortlisted_products = get_similar_products_from_image_query(
liked_product, top_n=3, threshold=0.6
)
print_shortlisted_products(shortlisted_products, display_flag=True)

画像でベクトル類似度が近しいものを検索できているのがわかる。
動画
続いて動画。こちらはサンプルデータに動画のカテゴリーがテキストとして含まれているけども、notebookでは使用されていないので、元のサンプルデータのままでもOK。一応、カテゴリーを日本語化したものを以下に用意してある。
CSVからpandasのデータフレームを作成。
import pandas as pd
data_url = "https://gist.githubusercontent.com/kun432/de4b8a8216d45db4c320688aef1188fb/raw/a5cd6b74accd7aaad337efbeb8cfe51121292734/video_data_without_embeddings_jp.csv"
video_data_without_embeddings = pd.read_csv(data_url)
video_data_without_embeddings
上の方で作成したEmbeddings生成用関数を使用して、動画のEmbeddingsを生成する。multimodalembeddingを使用。
from tqdm.notebook import tqdm
from typing import Optional
from vertexai.vision_models import (
MultiModalEmbeddingModel,
MultiModalEmbeddingResponse,
Image,
Video,
VideoSegmentConfig,
)
def get_image_video_text_embeddings(
image_path: Optional[str] = None,
video_path: Optional[str] = None,
contextual_text: Optional[str] = None,
dimension: Optional[int] = 1408,
video_segment_config: Optional[VideoSegmentConfig] = None,
debug: bool = False,
) -> MultiModalEmbeddingResponse:
"""画像、動画、テキストからマルチモーダルEmbeddingsを生成する。
引数:
image_path: 画像へのパス(ローカルまたはGoogle Cloud Storage).
video_path: 動画へのパス(ローカルまたはGoogle Cloud Storage).
contextual_text: Embeddingsを生成するテキスト。最大: 32トークン(~32語) ※日本語の場合どうなるかは不明
dimension: 生成されるEmbeddingsの次元数(128, 256, 512, 1408).
注: ただし動画を指定した場合は1408固定となり、このオプションしては無視する
video_segment_config: 動画の特定のセグメントのembeddingsを指定する場合に定義
debug: Trueの場合はデバッグ情報を出力する
戻り値:
MultiModalEmbeddingResponse: 生成されたembeddings
例外:
ValueError: image_path、video_path、contextual_textのいずれも指定されていない場合。
"""
# 入力チェック
if not any([image_path, video_path, contextual_text]):
raise ValueError(
"image_path、video_path、contextual_textのうち少なくとも1つを指定しなければならない。"
)
image = Image.load_from_file(image_path) if image_path else None
video = Video.load_from_file(video_path) if video_path else None
model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
if video_path:
if debug:
print("[WARN] video_pathが指定されているため、次元数は1408固定とする(dimensionパラメータは指定されても無視する)")
embeddings = model.get_embeddings(
image=image,
video=video,
video_segment_config=video_segment_config,
contextual_text=contextual_text,
# 注: 動画のembeddingは1408次元しかサポートしていないらしく、その場合に
# dimensionを渡すと以下のエラーとなったため、video_path定義の有無
# で振り分けている
# "400 Parameter dimension is not supported with video input."
#dimension=dimension,
)
else:
embeddings = model.get_embeddings(
image=image,
video=video,
video_segment_config=video_segment_config,
contextual_text=contextual_text,
dimension=dimension,
)
if image_path:
if debug:
print(
f"\n画像のEmbedding (最初の5つ):\n{embeddings.image_embedding[:5]}"
)
print(f"画像のEmbeddingの次元数: {len(embeddings.image_embedding)}")
if video_path:
if debug:
print("\n動画のEmbeddings:")
for video_embedding in embeddings.video_embeddings:
print(
f"動画のセグメント: {video_embedding.start_offset_sec} - {video_embedding.end_offset_sec}"
)
print(f"動画のEmbedding (最初の5つ): {video_embedding.embedding[:5]}")
print(f"動画のEmbeddingの次元数: {len(video_embedding.embedding)}")
if contextual_text:
if debug:
print(f"\nテキストのEmbedding (最初の5つ): {embeddings.text_embedding[:5]}")
print(f"テキストのEmbeddingの次元数: {len(embeddings.text_embedding)}")
return embeddings
tqdm.pandas()
# Embeddingsを保持するために元のデータフレームをコピーして新しいデータフレームを作成する
video_data_with_embeddings = video_data_without_embeddings.copy()
# 動画のEmbeddingsを取得
video_data_with_embeddings["video_embeddings"] = (
video_data_without_embeddings["gcs_path"]
.progress_apply(
lambda x: get_image_video_text_embeddings(video_path=x).video_embeddings[0].embedding
)
)
video_data_with_embeddings.head()
こちらもEmbeddings生成には8分ほどかかった。

notebook表示用のヘルパー関数を読み込み。
from IPython.display import HTML
def display_video_gcs(public_gcs_url: str) -> None:
html_code = f"""
<video width="640" height="480" controls>
<source src="{public_gcs_url}" type="video/mp4">
Your browser does not support the video tag.
</video>
"""
display(HTML(html_code))
def print_shortlisted_video(
shortlisted_videos: List[Dict], display_flag: bool = False
) -> None:
"""検索された動画の情報を出力し、オプションで動画を表示する
Args:
shortlisted_videos: 'score'(float)、'gcs_path'(str)、'gcs_url'(str)をキーとして持つ動画の辞書のリスト
display_flag: Trueなら動画を表示
"""
print("Similar videos identified ---- \n")
for i in range(len(shortlisted_videos)):
print(f"Video {i+1}: Confidence Score: {shortlisted_products['score'].iloc[i]}")
url = shortlisted_videos["gcs_url"].values[i]
print(url)
if display_flag:
display_video_gcs(public_gcs_url=url)
print()
では動画の類似検索を行う。適当に動画を選択。
random_index = 1
liked_video = video_data_with_embeddings["gcs_path"][random_index]
liked_video_url = video_data_with_embeddings["gcs_url"][random_index]
print(f"Video {random_index}:")
print(liked_video_url)
display_video_gcs(public_gcs_url=liked_video_url)

上記動画の類似動画を検索する
# Steps to get similar video
# ステップ1 - お気に入り動画('liked_video')のEmbeddingsを生成
liked_video_embedding = get_image_video_text_embeddings(video_path=liked_video).video_embeddings[0].embedding
# ステップ2 - liked_video_embedding と video_data_with_embeddings['video_embeddings'] の余弦類似度 (または単に np.dot) を求める。
cosine_scores = video_data_with_embeddings["video_embeddings"].apply(
lambda x: round(np.dot(x, liked_video_embedding), 2)
)
# ステップ3 - コサインスコアをソートし、しきい値(1.0より小さく、しきい値より大きい値)でフィルターをかけ、上位2つの結果を選ぶ。
threshold = 0.6
scores_above_threshold = cosine_scores[
(cosine_scores >= threshold) & (cosine_scores < 1.00)
]
top_2_indices = scores_above_threshold.nlargest(2).index.tolist()
top_2_cosine_values = scores_above_threshold.nlargest(2).values.tolist()
# ステップ4 - video_data_with_embeddingsを上記結果でフィルタ
shortlisted_videos = video_data_with_embeddings.iloc[top_2_indices]
shortlisted_videos.loc[:, "score"] = top_2_cosine_values
# ステップ5 - 検索された動画を出力
print_shortlisted_video(shortlisted_videos, display_flag=True) # display_flag=True

上記の一連の処理を関数化。コメント等はちょっと割愛。
def get_similar_videos_from_video_query(
liked_video: str, top_n: int = 3, threshold: float = 0.6
) -> pd.DataFrame:
liked_video_embeddings = get_image_video_text_embeddings(video_path=liked_video).video_embeddings[0].embedding
if "video_data_with_embeddings" not in globals():
raise ValueError("video_data_with_embeddings DataFrame is not defined.")
cosine_scores = video_data_with_embeddings["video_embeddings"].apply(
lambda x: round(
np.dot(x, liked_video_embeddings), 2
)
)
scores_above_threshold = cosine_scores[
(cosine_scores >= threshold) & (cosine_scores < 1.00)
]
top_indices = scores_above_threshold.nlargest(top_n).index.tolist()
top_cosine_values = scores_above_threshold.nlargest(top_n).values.tolist()
shortlisted_videos = video_data_with_embeddings.iloc[top_indices].copy()
shortlisted_videos["score"] = top_cosine_values
return shortlisted_videos
ではいろいろ試してみる。
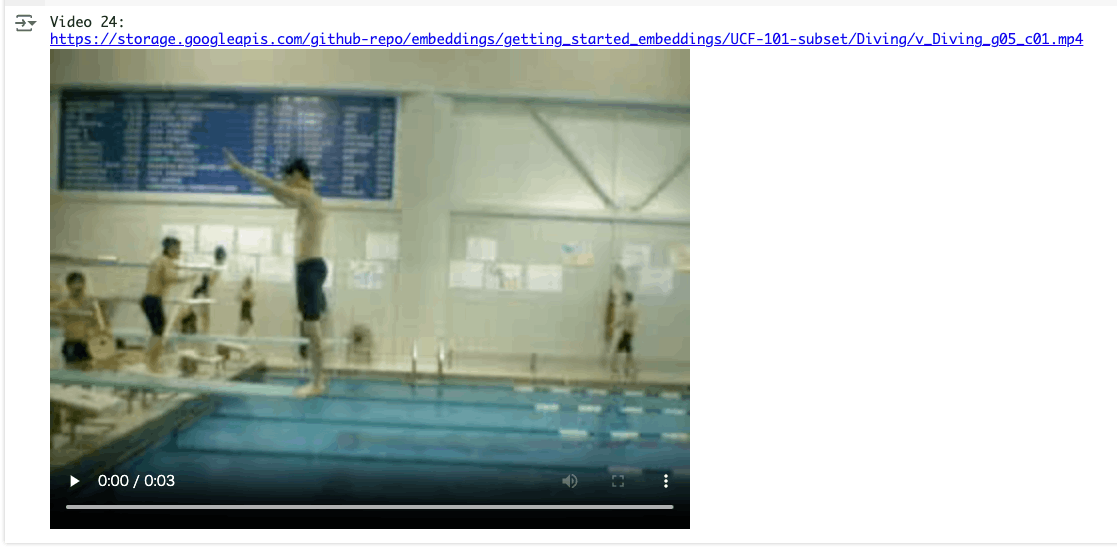
random_index = 24
liked_video = video_data_with_embeddings["gcs_path"][random_index]
liked_video_url = video_data_with_embeddings["gcs_url"][random_index]
print(f"Video {random_index}:")
print(liked_video_url)
display_video_gcs(public_gcs_url=liked_video_url)
shortlisted_videos = get_similar_videos_from_video_query(
liked_video, top_n=3, threshold=0.6
)
print_shortlisted_video(shortlisted_videos, display_flag=True)

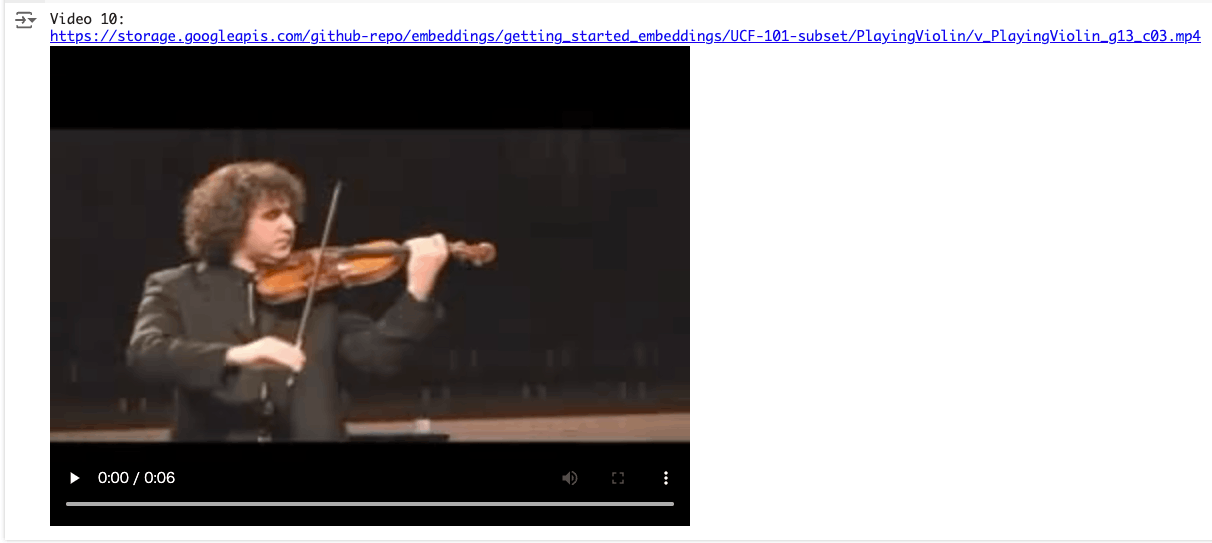
random_index = 10
liked_video = video_data_with_embeddings["gcs_path"][random_index]
liked_video_url = video_data_with_embeddings["gcs_url"][random_index]
print(f"Video {random_index}:")
print(liked_video_url)
display_video_gcs(public_gcs_url=liked_video_url)
shortlisted_videos = get_similar_videos_from_video_query(
liked_video, top_n=3, threshold=0.6
)
print_shortlisted_video(shortlisted_videos, display_flag=True)
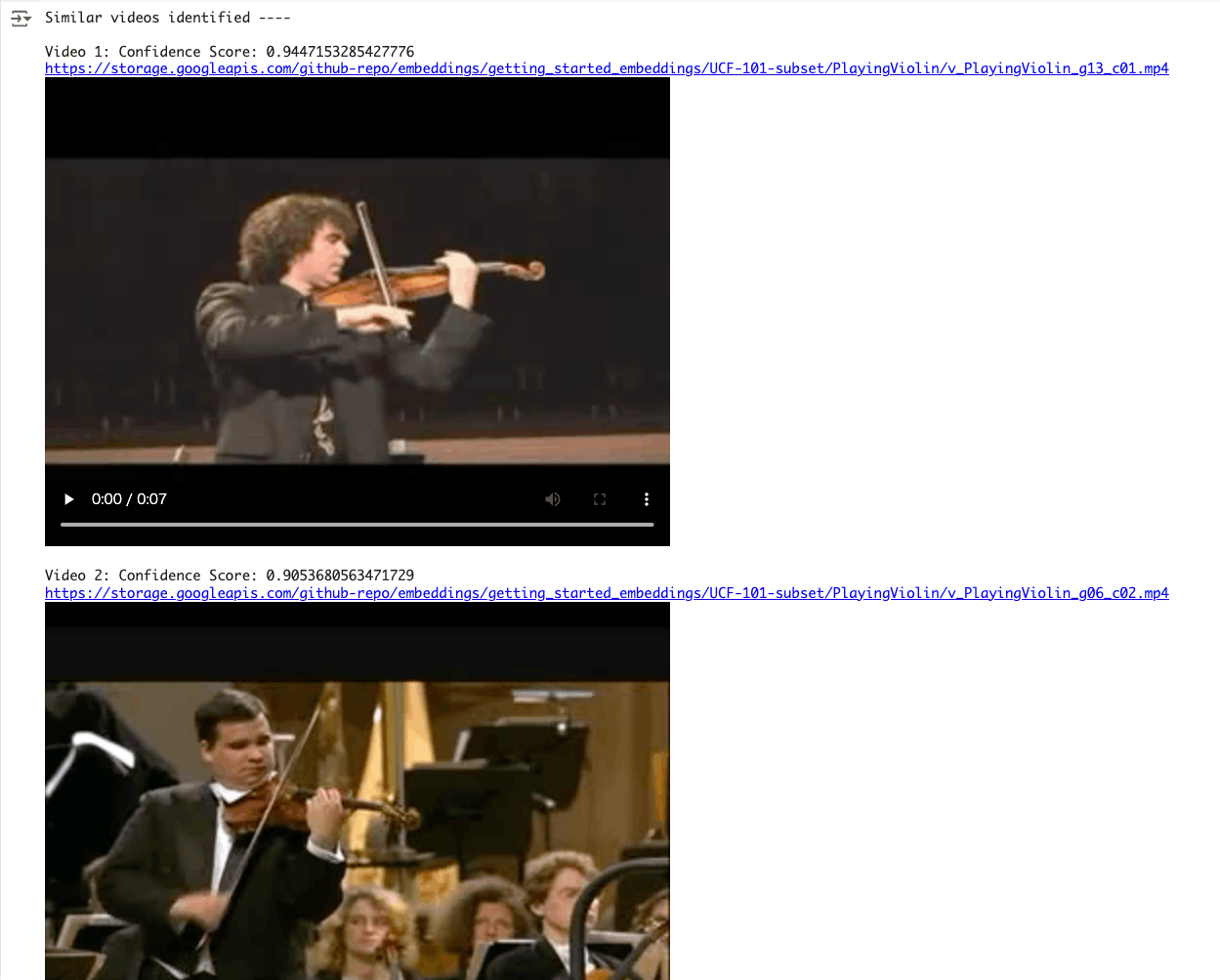
テキスト同士、動画同士、画像同士、でEmbeddings類似度による検索ができることはわかったのだけど、
インタフェースだけ見ると、画像とテキストで別々にEmbeddingsが返ってくるだけ、に見えるんだけど、テキストの指定の仕方で何かしら画像のEmbeddingsに違いが出てくる、ということを言ってるのかな???
についてだけど、ドキュメントには、
画像エンベディング ベクトルとテキスト エンベディング ベクトルは、同じ次元を持つ同じセマンティック空間にあります。そのため、これらのベクトルは、テキストによる画像の検索や画像による動画の検索などのユースケースでも使用できます。
とある。「同じ次元を持つ同じセマンティック空間にある」ということが重要なのかもしれない。notebookの下の方にそれっぽいものがあるので、実際に試してみて確認する。
この点については結局わからなかった。少なくとも今回のnotebookの例だと「同じ次元を持つ同じセマンティック空間にある」とは言えないのではないかな。multimodalembeddingはテキストも扱えるはずなのに、なぜテキストモデルをわざわざ使っているのかがよくわからない。
もうちょっと調べてみるかなぁ、というところ。
以下記事でLlamaIndex経由で試してみた。「同じ次元を持つ同じセマンティック空間にある」という点について少しわかったような気がした。