はじめに
Kotoba Technologiesでインターンをしている東京工業大学 B4 横田研究室の藤井(@okoge_kaz)です。
Kotoba TechnologiesはNLPと分散並列学習に関する技術を用いて、日本及び非英語圏におけるLLMやマルチモーダルモデルの実運用に向けた研究開発を行っています。
本日(2024/2/19) 2つのmambaモデルをリリースさせて頂きました。
1つは、from scratchから日本語と英語のコーパスにて学習を行ったkotomamba-2.8B-v1.0、もう1つはstate-spaces/mamba-2.8b-slimpjから日本語と英語で継続事前学習を行ったkotomamba-2.8b-CL-v1.0です。
両方のモデルとも、同規模のTransformerモデルと並ぶ性能を示しました。
本記事では、kotomambaモデルの性能と、モデル開発の中で得られた知見について紹介します。
なお、状態空間モデル(State Space Model)やMamba自体について知りたい方は以下の弊社インターンの栗田さんのスライドをご覧ください。
プロジェクト概要
本プロジェクトのうち、kotomamba-2.8b-CTの学習はABCI GrandChallenge V-weekの計算資源を利用して行われました。(kotomamba-2.8bはKotoba Technologiesの計算資源を利用して学習されました)
またプロジェクトは、東京工業大学 岡崎研究室、東京工業大学 横田研究室、東北大学 坂口研究室とKotoba Technologiesによって行われました。
以下にプロジェクトメンバーを記します。
-
東京工業大学 岡崎研
-
東京工業大学 横田研
-
東北大学 TohokuNLP group
-
Kotoba Technologies
Kotomamba とは

(Kotomambaモデルイメージ)
Kotomambaとは、state-spaces/mamba 2.8Bと同じアーキテクチャを用いて日英混合のデータセット約200B Tokenで学習したkotomamba-2.8B-v1.0と、state-spaces/mamba-2.8b-slimpjから日本語データを中心とするデータにより継続事前学習を行ったkotomamba-2.8B-CL-v1.0モデルの総称です。
我々が採用した言語理解を測る評価タスクにおいて同規模のTransformerモデルと遜色ない性能を発揮しています。(なお採用している評価タスクはSwallowのプロジェクトで使用されているものと同様です。)
| モデル名 | 日本語スコア(NLI除く平均) |
|---|---|
| state-spaces/mamba-2.8b-slimpj | 0.1312 |
| kotomamba-2.8B-CL-v1.0 | 0.2123 |
| cyberagent/open-calm-3b | 0.1819 |
| kotomamba-2.8B-v1.0 | 0.2089 |
モデル評価
言語理解タスクにて日本語、英語の評価を行いました。
| モデル名 | 日本語平均 | 英語平均 |
|---|---|---|
| state-spaces/mamba-2.8b | 0.2025 | 0.3614 |
| state-spaces/mamba-2.8b-slimpj | 0.1312 | 0.4063 |
| kotomamba-2.8B-v1.0 | 0.2089 | 0.2812 |
| kotomamba-2.8B-CL-v1.0 | 0.2123 | 0.3901 |
| cyberagent/open-calm-3b | 0.1819 | 0.1821 |
| openlm-research/open_llama_3b_v2 | 0.1772 | 0.3991 |
上図のようにTransformerとは異なるモデルであるState Space Model Mambaにおいても継続事前学習は有効であることが判明しました。mamba-2.8b-slimpjはslimpajamaにより学習されていることから日本語をほぼ学習していないと思われますが、そのモデルから日本語を中心としたデータにより継続事前学習を行うことで日本語性能を向上させることができました。
また、学習トークン数などの点で公平な比較というわけではありませんが、同等のモデルサイズであるcyberagent/open-calm-3bと比較して日本語、英語ともに高いスコアをfrom scratchからの学習により達成することができました。
学習曲線と知見
以下にLossの推移を示します。
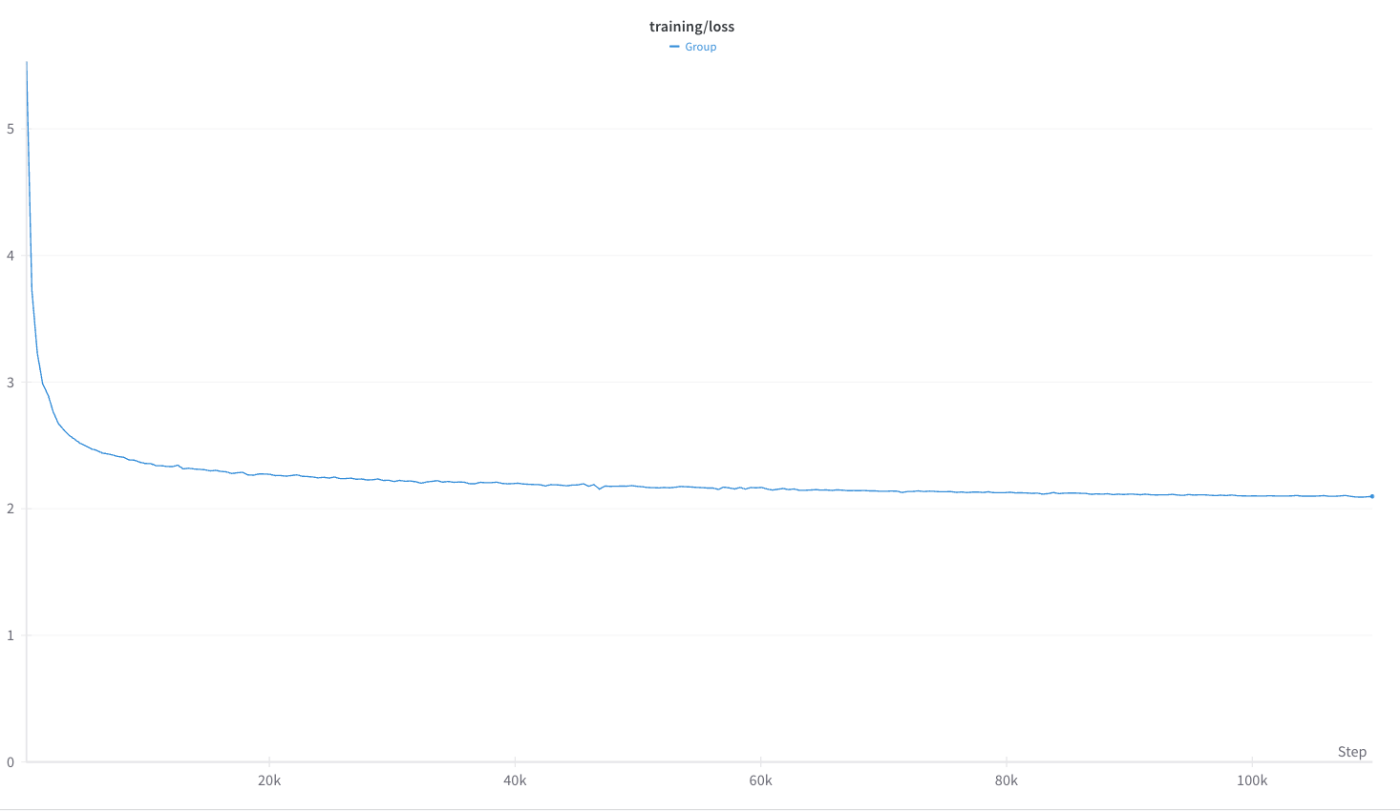
kotomamba-2.8B-v1.0のLoss Curve
事前学習にはBF16を利用しました。
そのため、GitHubのIssue等で報告されている学習の不安定には直面しませんでした。
実際FP16で事前学習を行うと学習が不安定になりLoss Spikeが発生しました。
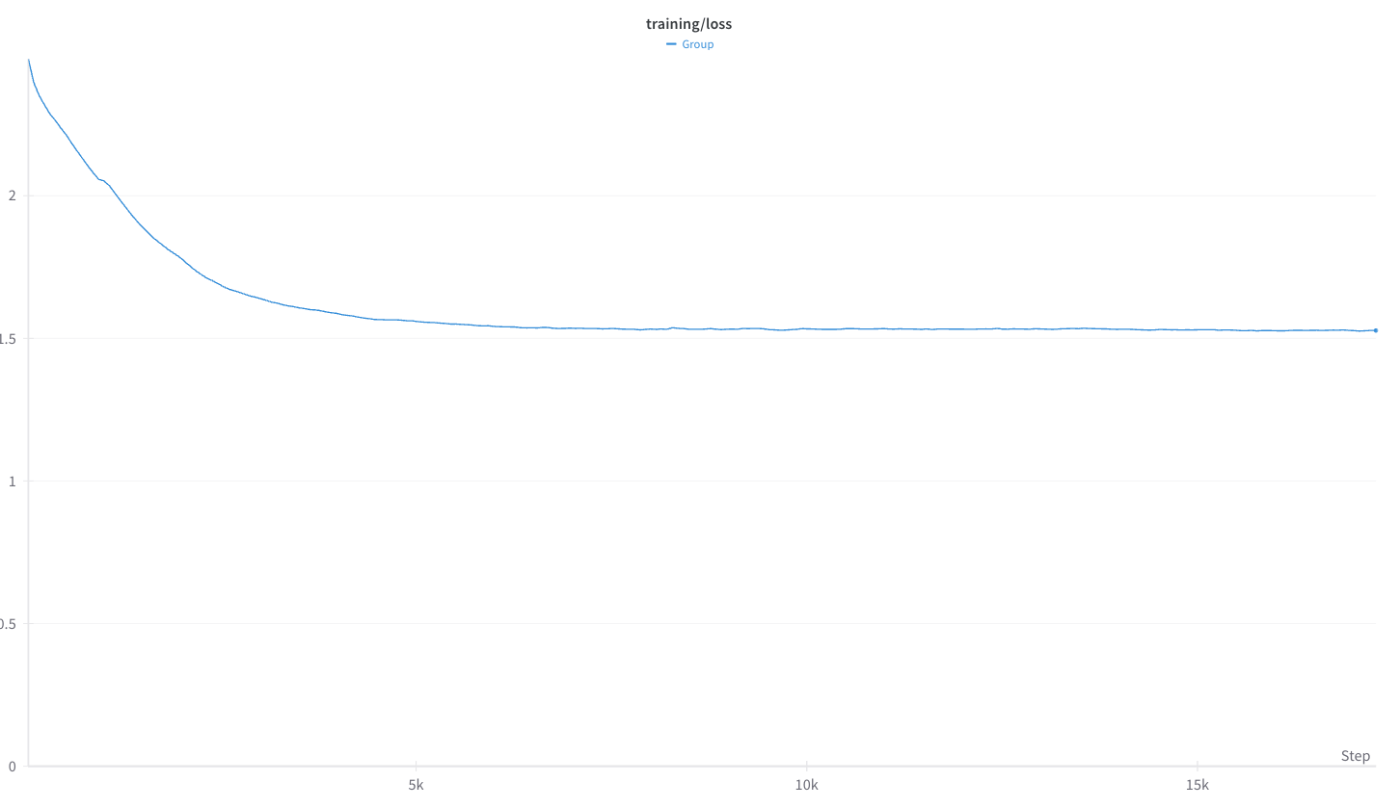
kotomamba-2.8B-CL-v1.0のLoss Curve
継続事前学習にはV100を利用したため、BF16を利用することはできません。しかし、FP16を利用して学習を進めるとLoss Spikeが発生してしまい、うまく学習を進めることができません。
実際公式リポジトリには以下のような記述があります。
We've observed that higher precision for the main model parameters may be necessary, because SSMs are sensitive to their recurrent dynamics. If you are experiencing instabilities, as a first step please try a framework storing parameters in fp32 (such as AMP).
これを受けて、我々は以下の形のMixedPrecisionを利用することで対応しました。
fpSixteen_mixed = MixedPrecision(
param_dtype=torch.float32,
# Gradient communication precision.
reduce_dtype=torch.float16,
# Buffer precision.
buffer_dtype=torch.float16,
)
これにより学習を安定化しつつも、学習速度を大きく損なわずに学習が可能です。
使用ライブラリ
学習には、kotomambaという独自ライブラリを開発し、利用しました。以下の記事にて紹介していますので、使い方等はそちらを参照いただけますと幸いです。
分散並列学習
分散並列学習にはPyTorch FSDPを利用しました。
FSDPであれば、mambaのようなState Space Modelをはじめとする非Transformerアーキテクチャのモデルであっても問題なく分散並列学習が可能なため、選択しました。
このときちょうどLLMの継続事前学習(Continual Pre-Training)と指示チューニング(Instruction Tuning)を行うためのライブラリであるkotoba-recipesを開発していたので、こちらの機能を導入することにしました。
学習詳細
以下に、kotomamba-2.8B-v1.0, kotomamba-2.8B-CL-v1.0 で用いていたハイパーパラメータ等を示します。
事前学習モデル
A100 (40GB)を利用して学習を行ったfrom scratchからの事前学習には以下のハイパーパラメータを利用しました。
- LR: 8e-4
- min LR: 1e-5
- Adam (
\beta_1 \beta_2 - Weight Decay: 0.1
- Gradient Clipping: 1.0
- global batch size: 1024
- sequence length: 2048
sequence lengthは2048としたのは、mambaの論文では2048としていたためです。
Mambaの強みを引き出すにはLong Sequenceである方が良いので、実用的にはLong Sequenceでの学習が妥当かと思われます。ただし、今回のプロジェクトでは、そもそも2048のsequence lengthでさえ上手く学習できるか不明であったため、安全策をとり2048での学習を行いました。
なお、LR, global batch size等の値は、mambaの論文とGPT-3の論文を参考に決定しました。
継続事前学習モデル
V100(16GB)を利用して継続事前学習を行った際のハイパーパラメータは以下のとおりです。
- LR: 6e-5
- min LR: 6e-6
- Adam (
\beta_1 \beta_2 - Weight Decay: 0.1
- Gradient Clipping: 1.0
- global batch size: 1024
- sequence length: 2048
学習に使用したscriptはこちらに公開しています。
おわりに
この記事では、State Space ModelのMambaを実際に学習したことについて説明してきました。
我々が学習を行う中で得られた知見や、実際に学習に使用したコードについて詳細な説明を試みました。
我々は本取り組みをオープンにしていく方針であり、この記事と学習コードを読んでも判然としない点については遠慮なく質問いただけますと幸いです。
本取り組みの知見をもとに、さらに大きなMambaモデルを学習したり、本モデルから継続事前学習を施すのも良いかと思います。
Kotoba Technologiesでは、Mambaを始め最新の技術を取り入れた研究開発を今後も行っていきます。

Discussion