はじめに
Kotoba Technologiesでインターンをしている東京工業大学 B4 横田研究室の藤井(@okoge_kaz)です。
Kotoba TechnologiesはNLPと分散並列学習に関する技術を用いて、日本及び非英語圏におけるLLMやマルチモーダルモデルの実運用に向けた研究開発を行っています。
今回は、Transformerに代わるアーキテクチャとして注目を集めているMamba(State Space Model: 状態空間モデル)を分散学習するためのライブラリであるkotomambaを開発、公開しました。
本記事は、このライブラリの使用方法と、Mambaについて簡単に説明を行います。
状態空間モデル(State Space Models)
状態空間モデルに関する詳細な説明は、2024年1月に行った弊社インターンの栗田さんのTech Talkスライドを参照ください。
端的に状態空間モデルについて説明すると、系列長
言語モデルやマルチモーダルなモデルを実世界で使用する際には、Long Sequence(=長い系列長)が必要となることがありますが、推論速度の面で問題を抱えています。FlashAttentionなどハードウェア構造を考慮した実装にすることで実測推論時間を短縮するなどの試みが行われていますが、モデルアーキテクチャ自体を変更することで高速に推論を行う手法も検討されています。
そのような中で、状態空間モデルは新しいモデルアーキテクチャとして、注目されています。

Mamba は状態空間モデルの1種であり、S4の問題点であった「入力に対して"動的"な推論が不可能である」という点を克服したモデルとなっています。Mamba は言語モデリングにおいても Transformer に迫る性能を記録しており、3D医用画像のセグメンテーション や Token-freeな言語モデル への応用や Mamba自体のMoE化 が模索されるなど、状態空間モデルの中でも特に注目を集めているモデルとなっています。
Kotomambaとは
kotomambaとは、一言で言うと、Mambaを分散並列学習するためのライブラリです。
公式リポジトリであるstate-spaces/mambaは推論することは可能ですが、学習するためのコードが組み込まれていません。そのため、長い系列長(long sequence)における高速な推論速度を期待して独自のデータで学習しようにも、すぐには学習することができない状態になっています。(2024年1月時点)
そこでKotoba Technologiesでは、PyTorchネイティブのFSDP(Fully Sharded Data Parallel)を利用し、誰でも簡単にMambaモデルを分散学習できるにようにしました。
また、Tri Daoらが開発した公式のリポジトリからモデルのアーキテクチャ部分にはできるだけ手を加えずにライブラリ開発を行ったため、推論速度などは元のままです。
FSDPで利用される Reduce-Scatter, All Gather

(FSDP Tutorilaより)
使用方法
kotomambaの使用方法について説明します。環境構築方法、学習方法等について順に解説を行います。
また、我々がすでに認識している既知の問題については、解決方法を記していますので既知の問題 (troubleshooting)セクションもご確認ください。
Installation
install.mdに記載の内容と同じです。
以下の環境構築では、CUDAToolkit version 11.8を想定しています。
まず、Pythonの仮想環境を作成し、依存関係をinstallします。
git clone git@github.com:kotoba-tech/kotomamba.git
cd kotomamba
python -m venv .env
source .env/bin/activate
pip install -r requirements.txt
次に、mambaの学習に必要なライブラリをinstallします。
こちらのinstallにはGPU環境が必要です。V100, A100, H100などお手元のGPUを使用して環境構築を行ってください。
以下のコマンドで追加の依存関係をインストールしてください。
pip install packaging wheel
pip install causal-conv1d>=1.1.0
pip install -e .
ライブラリのインストールなどはこれで完了です。しかし、これだけでは環境によっては動作しないため以下の変更を行います。
まず、tritonのライブラリ中でldconfigを呼ぶのですが、これが名前解決されないため、こちらをフルパスに変更します。以下はpython3.10の環境における変更例です。
.env/lib/python3.10/site-packages/triton/common/build.py:L21を変更しています。
@functools.lru_cache()
def libcuda_dirs():
- libs = subprocess.check_output(["ldconfig", "-p"]).decode()
+ libs = subprocess.check_output(["/usr/sbin/ldconfig", "-p"]).decode()
さらにデータセットのまわりの動作を効率化するために、Megatron-LMの実装から一部を取り入れている箇所では、C++のコードをcompileする必要があるため、そちらの作業を行います。
まずmegatron_lm/megatron/core/datasets/MakefileのMakefileのpython3-configのパスをフルパスに書き換えます。(以下では、~/.pyenv/versions/3.10.12/bin/python3-configとしていますが、適時環境に合わせて書き換えてください。)
CXXFLAGS += -O3 -Wall -shared -std=c++11 -fPIC -fdiagnostics-color
CPPFLAGS += $(shell python3 -m pybind11 --includes)
LIBNAME = helpers
LIBEXT = $(shell ~/.pyenv/versions/3.10.12/bin/python3-config --extension-suffix)
default: $(LIBNAME)$(LIBEXT)
%$(LIBEXT): %.cpp
$(CXX) $(CXXFLAGS) $(CPPFLAGS) $< -o $@
次にkotobamba/megatron_lm/megatron/core/datasetsにてmakeを行います。
megatron_lm/megatron/core/datasets/helpers.cpython-310-x86_64-linux-gnu.soのようなファイルが新たに生成されていれば成功です。
以上で環境構築は終了です。
推論 (Inference)
mambaは通常のTransformerモデルのようにHuggingFace transformersのAutoModelから読み込むことができません。そのため、inferenceを行う場合もstate-spaces/mambaやkotomambaを利用する必要があります。
kotomamba/scripts/abci/inference に推論を行うためのサンプルスクリプトを用意しました。
scripts/abci/inference/inference_test.shは、すぐにAlbert Gu,Tri Daoが学習したモデルを試すことができるスクリプトです。
試しにinferenceさせてみると以下のような結果が得られます。
きちんとした英語が出力されます。
Tokyo is a great city, but it\'s not the best place to live. It has too many people and there are no trees."\n\n
"I\'m sorry," I said as we walked back toward my apartment building in Shinjuku after our walk through Asakusa together that afternoon—the first time he\'d taken me out since his return from America two weeks earlier—"but you\'re right about Tokyo being crowded; everyone here seems so busy all of their lives!" He laughed at this remark:
学習 (Training)
kotomambaはPyTorch FSDPによるmambaの事前学習(from scratch)と継続事前学習(continual pre-training)をサポートしています。
130m〜2.8Bまでのモデルを学習するためのscriptを用意しているため、すぐに学習を始めることができます。
なお、A100を用いる場合のABCI上でのサンプルスクリプトをscripts/abci/training/A-nodeに、V100などBF16を利用することができない環境で学習を行うためのサンプルスクリプトをscripts/abci/training/V-nodeに用意しています。
以下では、実際に学習を行うまでの流れを説明します。
Tokenize
まず、学習データをトークナイズ(Tokenize)する必要があります。
HuggingFace Tokenizerを利用する場合は、scripts/abci/data/tokenize/tokenize_en_slimpajama_1_3.shなどを参考にしてください。実際にトークナイズする際に使用するコマンドを提示しながら解説を行います。
DATASET_PATH=$DATASET_DIR/slimpajama-627b-1.jsonl
python megatron_lm/tools/preprocess_data.py \
--input $DATASET_PATH \
--output-prefix $OUTPUT_DIR/slimpajama_1 \
--tokenizer-type HuggingFaceTokenizer \
--tokenizer-model EleutherAI/gpt-neox-20b \
--workers 64 \
--append-eod
オプション引数について説明します。
--inputにtokenizeする対象のJSONLファイルのパスを指定してください。
また、--output-prefixには出力されるxxxx_document.idx, xxxx_document.binのxxxxの部分を指定することができます。
--tokenizer-typeには、HuggingFace形式のTokenizerを利用される場合はHuggingFaceTokenizerをllm-jp-tokenizerなどのSentencePieceTokenizerを使用される場合は、--tokenizer-type SentencePieceTokenizerと指定してください。
なお、sentencepiece tokenizerによるtokenize例はscripts/abci/data/tokenize_pile_okazaki_cc.shにあります。
学習 (Pre-Training)
学習準備ができたので、実際に学習scriptを投入して学習を行ってみましょう。
scripts/abci/training/A-node/mambda-2.8b.shをお使いの計算環境に合わせて、変更することで利用することができます。
ABCIをご利用の方は、パスのみ自分の環境に変更することで、学習を始めることができます。
ここではmamba-2.8b.sh(下記)にて使用しているオプションについて簡単に解説します。
mpirun -np $NUM_GPUS \
--npernode $NUM_GPU_PER_NODE \
-hostfile $HOSTFILE_NAME \
-x MASTER_ADDR=$MASTER_ADDR \
-x MASTER_PORT=$MASTER_PORT \
-bind-to none -map-by slot \
-x PATH \
python pretrain.py \
--seq-length ${SEQ_LENGTH} \
--sliding-window-size ${SEQ_LENGTH} \
--micro-batch-size ${MICRO_BATCH_SIZE} \
--global-batch-size ${GLOBAL_BATCH_SIZE} \
--train-iters ${TRAIN_STEPS} \
--tokenizer-type SentencePieceTokenizer \
--tokenizer-model ${TOKENIZER_MODEL} \
--data-path ${DATA_PATH} \
--split 949,50,1 \
--lr ${LR} \
--min-lr ${MIN_LR} \
--lr-decay-style cosine \
--lr-warmup-iters ${LR_WARMUP_STEPS} \
--lr-decay-iters ${LR_DECAY_STEPS} \
--weight-decay ${WEIGHT_DECAY} \
--grad-clip-norm ${GRAD_CLIP} \
--optimizer adam \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--adam-eps 1e-6 \
--save-interval 500 \
--eval-interval 100 \
--eval-iters 10 \
--bf16 \
--mixed-precision \
--base-model ${CHECKPOINT_DIR} \
--save ${CHECKPOINT_SAVE_DIR} \
--load ${CHECKPOINT_SAVE_DIR} \
--low-cpu-fsdp \
--sharding-strategy FULL_SHARD \
--checkpoint-type LOCAL_STATE_DICT \
--fsdp-activation-checkpointing \
--use-mpi \
--from-scratch \
--mamba \
--wandb-entity "prj-jalm" \
--wandb-project "ABCI-mamba" \
--wandb-name "${JOB_NAME}"
-
--seq-length: 系列長(context length)を指定します。公式のmambaでは2048が指定されていましたが、from scratchの場合は好きな値に設定することができます。 -
--micro-batch-size: 1GPUあたりに割り当てるbatch sizeを指定します。CUDA out of memoryが発生した場合は、まずこの値を小さくすることを検討してください。 -
--global-batch-size: グローバルバッチサイズを指定します。この値が大きすぎるとLarge Batch問題が発生し、収束性が悪化します。しかし、あまりにも小さいバッチサイズですと学習が不安定になったり、学習効率が悪くなります。mambaの論文では、512が指定されていました。 -
--train-iters: 学習を行うイテレーション数を指定します。学習データに応じて変更してください。 -
--lr,--min-lr: 最大学習率と最小学習率を指定します。このライブラリでは、線形に学習率を--lr-warmup-itersで指定されたイテレーション数まで増加させ、その後はcosine decayにより学習率を低下させていく実装になっています。 -
--optimizer,--adam-beta1,--adam-beta2,--adam-eps: AdamW Optimizerのハイパーパラメータを設定することができます。 -
--from-scratch: 継続事前学習ではなく、事前学習を最初から行う場合に設定します。
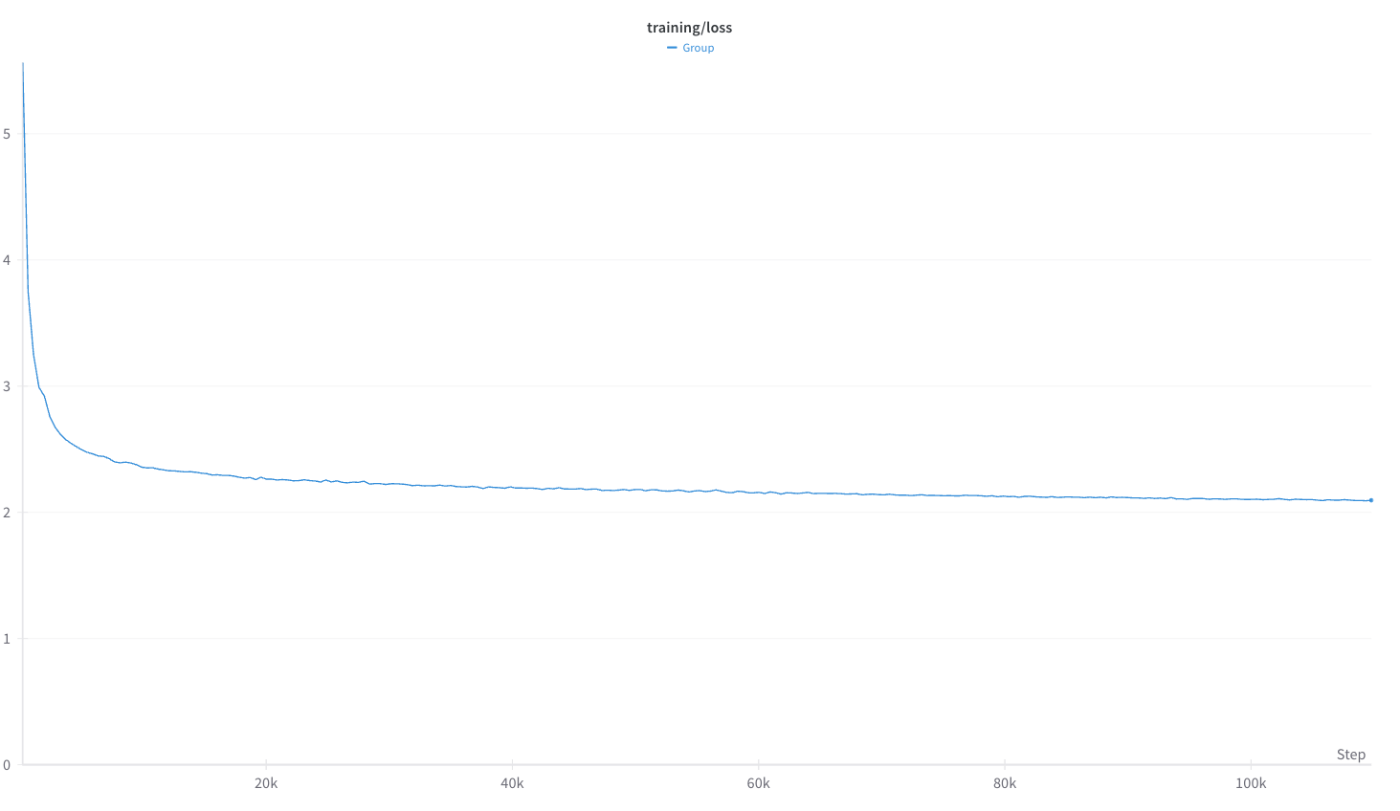
実際に学習を行うと、以下のようなLoss curveが得られます。
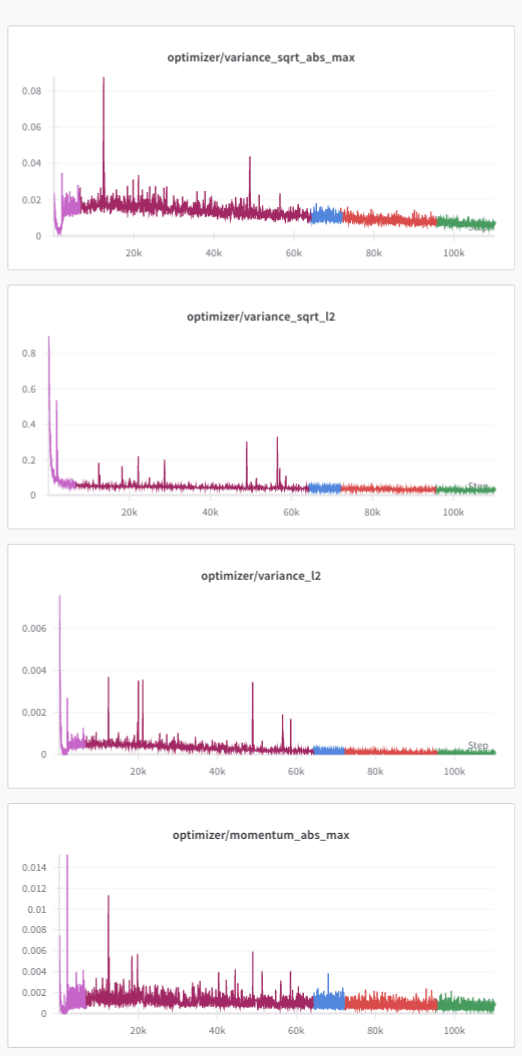
なお、学習が不安定になっていないか観察するためにoptimizer satesを監視する機能も実装済みです。(下図: mamba-2.8B をfrom scratchから学習した際のwandb log)
既知の問題 (troubleshooting)
おわりに
この記事では、mambaの分散並列学習ライブラリであるkotomabaに関する説明を行ってきました。
このライブラリは、実際にKotoba Technologiesにおける研究開発に利用されており、実用に耐えうるように開発、メンテナンスされています。
また、本ライブラリを利用して学習したモデルを近く公開予定ですので、お待ち下さい。
Kotoba Technologiesでは、NLPと分散学習の知見を組み合わせて研究開発を今後も行っていきます。さらに大きな計算機環境での学習等を行っていく予定ですので、共同研究などにご関心をお持ちの方はお気軽にご連絡頂けますと幸いです。

Discussion
大変貴重な記事をありがとうございます.脳波解析に応用できそうですか?