株式会社ナレッジセンスは、生成AIやRAGを使ったプロダクトを、エンタープライズ向けに開発提供しているスタートアップです。本記事では、「Speculative RAG」という手法について、ざっくり理解します。
この記事は何
この記事は、複数の言語モデルを利用してRAGの回答精度を上げる手法である「Speculative RAG」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は以下の記事もご参考下さい。
本題
ざっくりサマリー
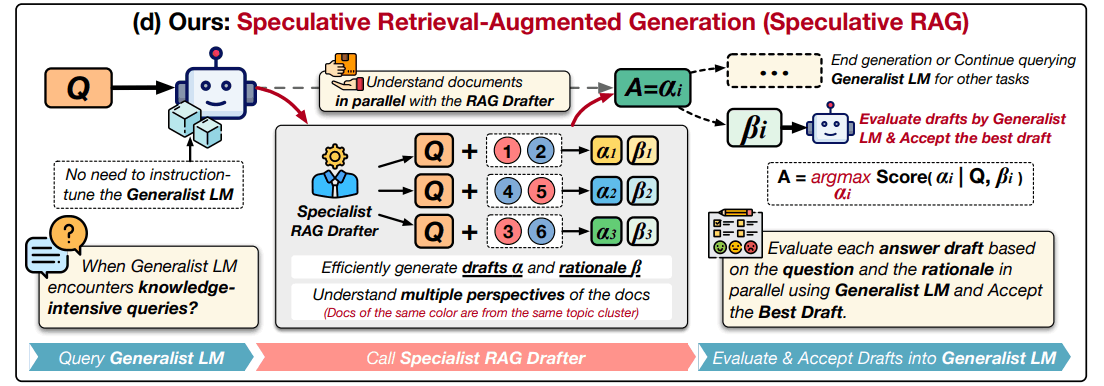
Speculative RAG は、複数の言語モデルで回答生成&最良の回答を選別する手法です。Google DeepMindの研究者らによって2024年7月に提案されました。Speculative RAGを使うメリットは、小さいモデルでも回答精度を高く保てること、それにより、回答速度を速くすることができることです。
Speculative RAGでは、まず、ファインチューニングした小さい言語モデル(Mistral 7B)のインスタンスを複数用意します。RAGをするときは、それぞれのインスタンスに別々のドキュメントを渡し、それぞれ回答を生成させます(上の図の中央、「Specialist RAG Drafter」に当たる部分)。
その後、大きいLLM(Mixtral 8x7B)を使ってそれぞれの回答を評価して、ベストなものを最終回答とします。
問題意識
Retrieval-Augmented Generation (RAG) は便利ですが、大きい言語モデルを利用しつつ関連する文書全体をプロンプトに入れ込むため、回答速度が遅くなってしまうという問題があります。この論文では、小さいモデルを利用してRAGの回答を高速化しながら、そこそこの回答精度も担保することはできないか、ということに挑戦しています。(類似手法に「CRAG」という手法もあります)
手法
Speculative RAGの全体像としては、小さい言語モデル複数で回答生成→大きい言語モデルで評価。という形です。
【事前にやっておくこと】
Speculative RAGでは、事前に小さい言語モデル(Mistral 7B)をファインチューニングしておきます。(少し細かい話なので、スルーでもOKです)
【ユーザーが質問を入力して来たとき】
- ユーザーの質問を基に、関連するドキュメントを取得(ここは通常のRAGと同じ)
- 1のドキュメント群を、関連度が近い複数のクラスタに分ける
- それぞれのクラスタからランダムにドキュメントを取得して、小さい言語モデル(Mistral 7B)に渡し、回答生成させる
- 3を複数のインスタンスで同時並行で実施
- 4で生まれた複数の回答を、大きいLLMが評価。最良の回答を選択
個人的には、この手法のキモは、「ドキュメント群を、類似度が近い複数のクラスタに分ける」部分だと思います。クラスタに分けるという処理を挟むことで、「似たようなドキュメントを言語モデルに渡してしまう」というムダを無くすことができます。
成果
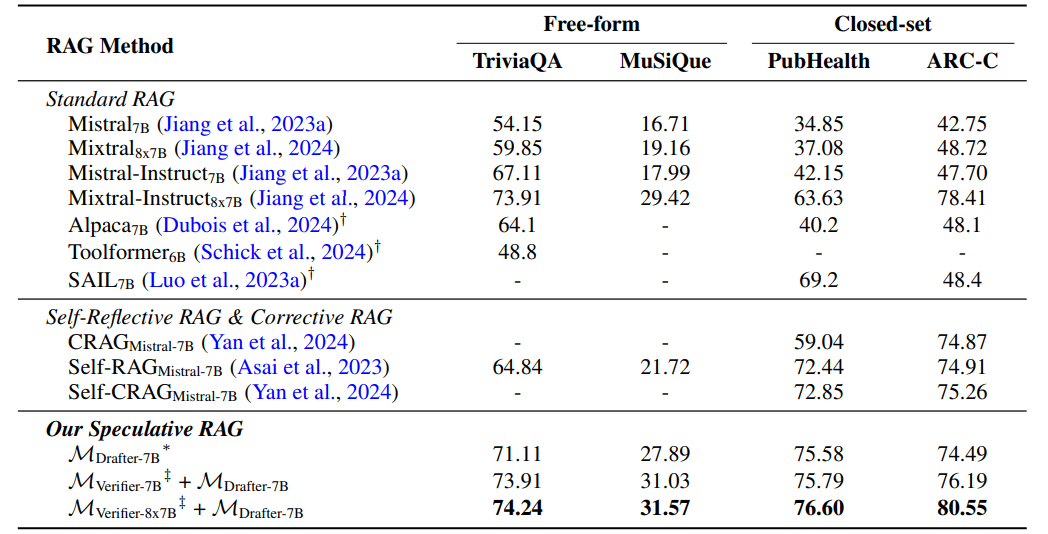
- 4つのベンチマークで最先端の性能を達成。特にPubHealthでは従来手法と比べて12.97%の精度向上
- 従来のRAGシステムと比較して最大51%の遅延を削減
ただし、実際のプロダクトで利用することを考えると、ファインチューニングが必要な点は、やはりネックです。サクッと試すには少しコストが掛かります。
まとめ
弊社では多くの企業向けにRAGシステムを提供しています。その際、回答速度の相談をいただくことがあります(例:「RAGを使った社内データAIも、Google検索くらいの速度にできないか?」)。Speculative RAGを使うことで、そこそこの回答精度を保ちながら、約2倍の速度で回答生成できることが分かりました。これだけではGoogle検索の速度にはなりませんが(笑)、RAGにおいて回答生成の時間は明確なボトルネックなので、この点を削減する研究は今後も多く登場しそうです。(「xRAG」もこの方向性です)
みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion