株式会社ナレッジセンスは、生成AIやRAGを使ったプロダクトを、エンタープライズ向けに開発提供しているスタートアップです。
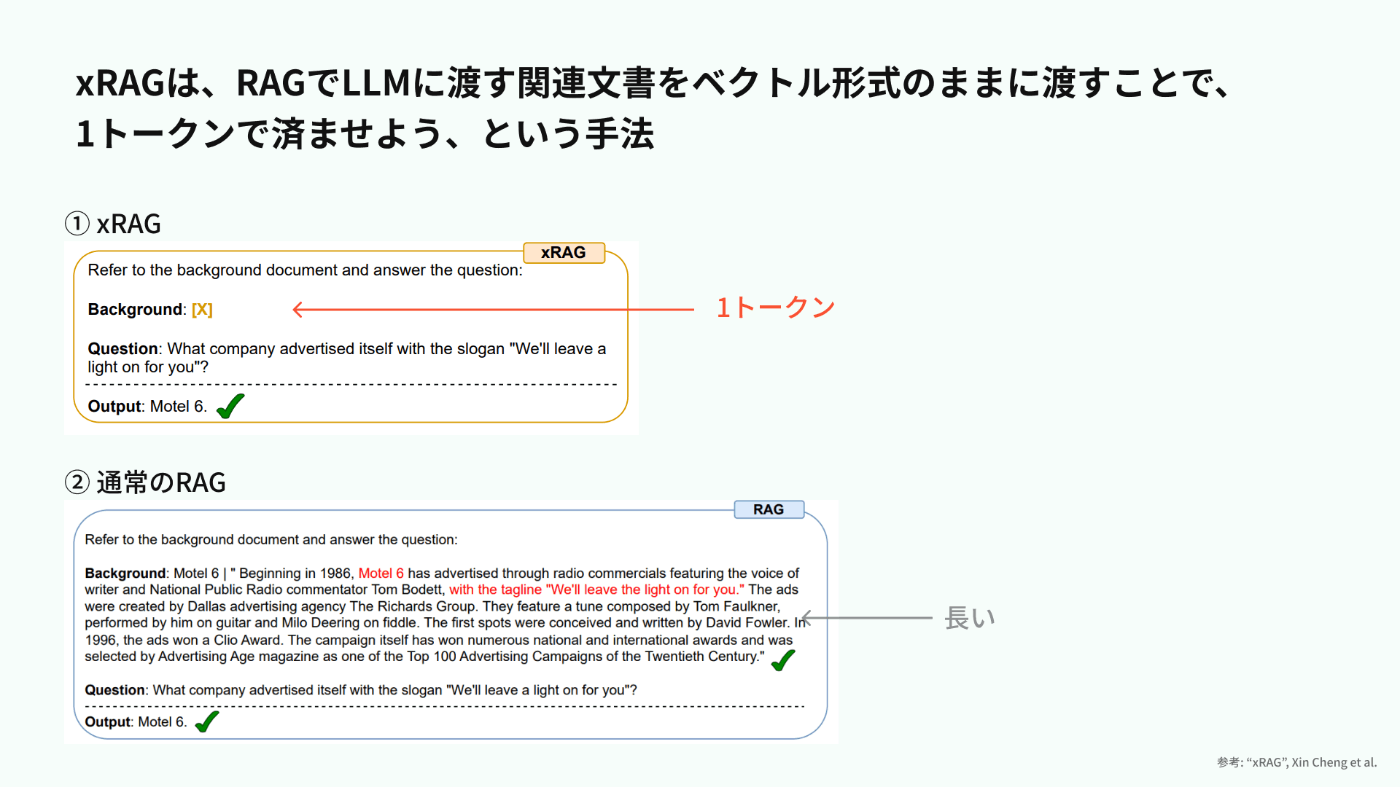
本記事では、「xRAG」という手法について、ざっくり理解します。xRAGとは、RAGシステムでLLMに投げるドキュメント(通常、数千文字ほどですよね。)を、1トークンに圧縮できるのでは?という手法です。
この記事は何
この記事は、RAGをする際にLLMに渡すドキュメントを1トークンまで圧縮できる手法「xRAG」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は以下の記事もご参考下さい。
本題
ざっくりサマリー
xRAGは、RAGで渡すコンテキストを極限まで圧縮する手法です。北京大学/Microsoftの研究者らによって2024年5月に提案されました。xRAGを使うメリットは、コンテキストを圧縮できるのでRAGの回答速度が早くなること、トークン数を節約できるので安くなることです。しかも従来の圧縮手法と違って、LLMをファインチューニングする必要のない外付けのシステムなので、扱いやすいです。
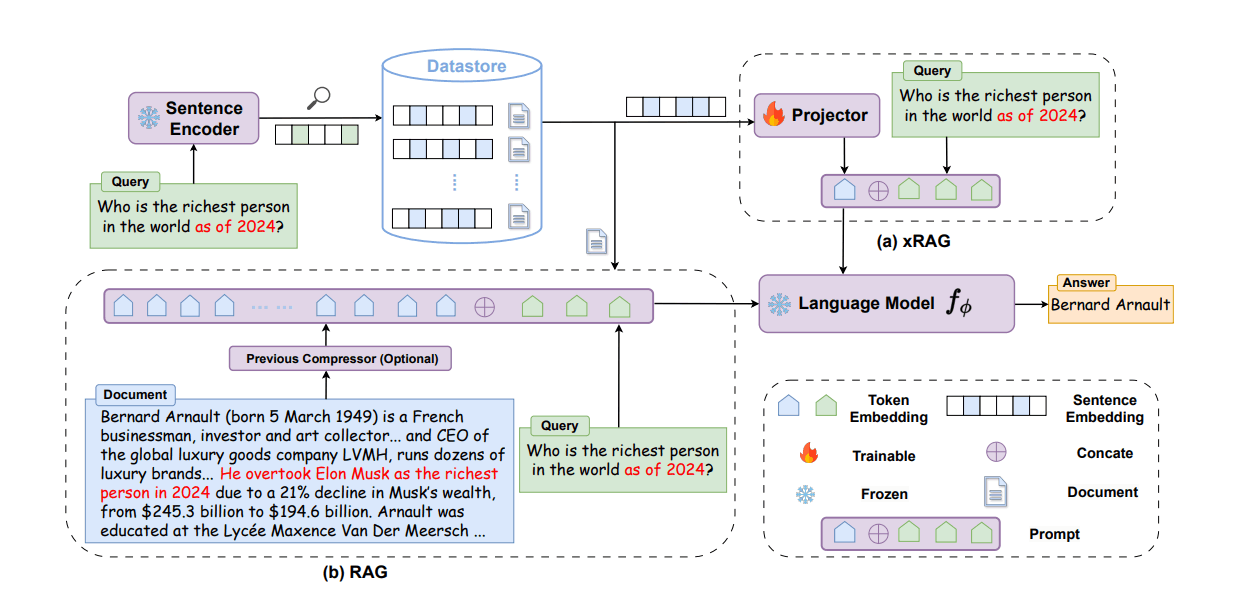
xRAGでやっていることは、GPT-4oのようなLLMで「画像読み込み」を可能にしている手法と似ています。ざっくりいうと、RAGで取得してきた文書のベクトルデータを、「LLMが解釈しやすい別のベクトルデータ」に変換してから、LLMに渡すという手法です。この「変換」というところがキモであり、どうやってこの変換器を作るのかが、論文で説明されています。
※ここで言っている「変換器」というのは、上の画像で言うところの右上。「Projector」に当たる部分です
問題意識
Retrieval-Augmented Generation (RAG) は便利ですが、関連する文書全体をプロンプトに入れ込むため、かなりトークン数を食います。また、RAGで文書を圧縮する手法は、他にも登場していますが、大量にメモリが必要だったり、圧縮率が低いなどの課題がありました。(例えば、以前このブログでもプロンプトを5倍圧縮できる「LLMLingua-2」を紹介しています)
手法
xRAGでは、LLMをファインチューニングしません。これも大きな特徴です。xRAGでは、通常のRAGのようにユーザーの質問に関連したドキュメントを取得したあと、その取得したドキュメントのベクトルを「変換」し、別のベクトルデータを生成します。そのベクトルデータを、ユーザーの質問とともにLLMに渡し、回答を生成させます。なので、この変換器を作成する事前準備が大切です。
【事前にやっておくこと~変換器の作成~】
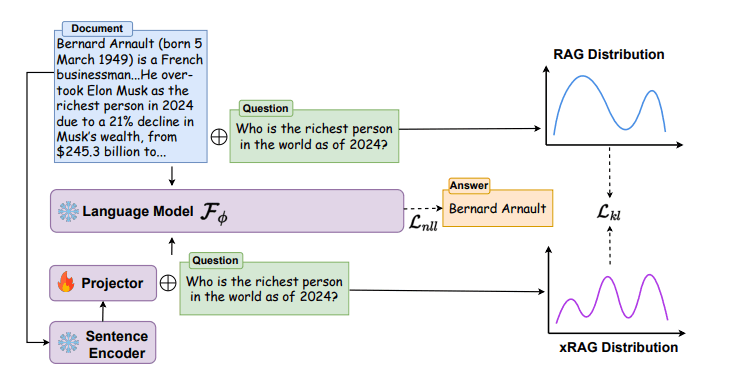
※先程から僕が言っている「変換器」とは、この画像で言うところのProjectorです。
「変換器」の作り方を説明します。簡単のため多少、省略します。ざっくり言うと、
①普通のRAGの通り「関連テキスト+質問」をLLMに渡した場合のLLMの回答
②「関連テキストをProjectorで変換したベクトル+質問」をLLMに渡した場合のLLMの回答
この2つで違いがなるべく出ないように、Projectorモデル(変換器)を構築します。
【ユーザーが質問を入力して来たとき】
- ユーザーの質問を基に、関連するドキュメントを取得(ここは通常のRAGと同じです)
- 1のドキュメントのベクトルを、Projectorを利用して別のベクトルに変換
- 2のベクトルとユーザーの質問を併せてLLMに入力し、回答を生成
このように、最終的にLLMに渡すドキュメントのデータがベクトルデータなので、1トークンで済む、ということです。
この手法のキモは、「ドキュメントのベクトルをLLM向けに別のベクトルに変換する」ためのProjector(変換器)です。このProjectorは、2層のMLP(ニューラルネットワーク)で設計されていて、シンプルではあるものの、スクラッチから学習して構築されています。
成果
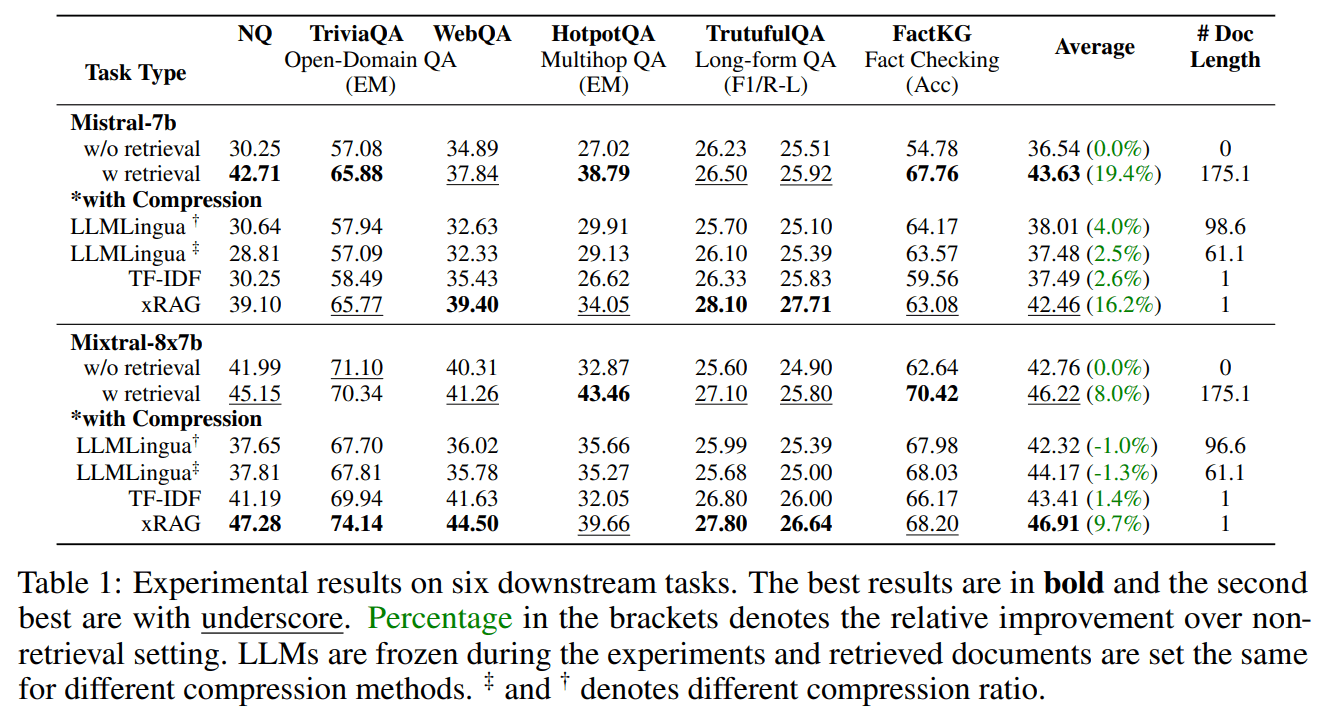
- 素のLLMだけで回答する場合に比べ、平均10%以上の性能向上
- 一部のデータセットでは、従来のRAGと比較しても性能向上
- 全体のFLOPsを3.53倍削減
- 取得した文書が誤解を招く内容だった場合でも、xRAGはLLMが元から持っている知識を活用して対処できることが確認された(ロバスト性)
ただし、複数の知識を活用して回答する必要があるようなマルチホップなタスク(HotpotQA)では、従来のRAGには劣ってしまうようです。
まとめ
弊社では多くの企業向けにRAGシステムを提供しています。その際、コスト面の相談をいただくことは少なくありません(例えば、「社員RAGを使いすぎるとLLMの利用費用がかかりすぎてしまう」など)。今回のxRAGを使うことで、RAGの利用料金が大きく安くなる可能性があり、しかも回答の高速化にも繋がります。
苦手なタスクもあるので一長一短ですが...みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion