株式会社ナレッジセンスは、生成AIやRAGを使ったプロダクトを、エンタープライズ向けに開発提供しているスタートアップです。本記事では、RAGの性能を高めるための「REAPER」という手法について、ざっくり理解します。
この記事は何
この記事は、RAGを活用したAIエージェントの回答速度を10倍速くする「REAPER」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は以下の記事もご参考下さい。
本題
ざっくりサマリー
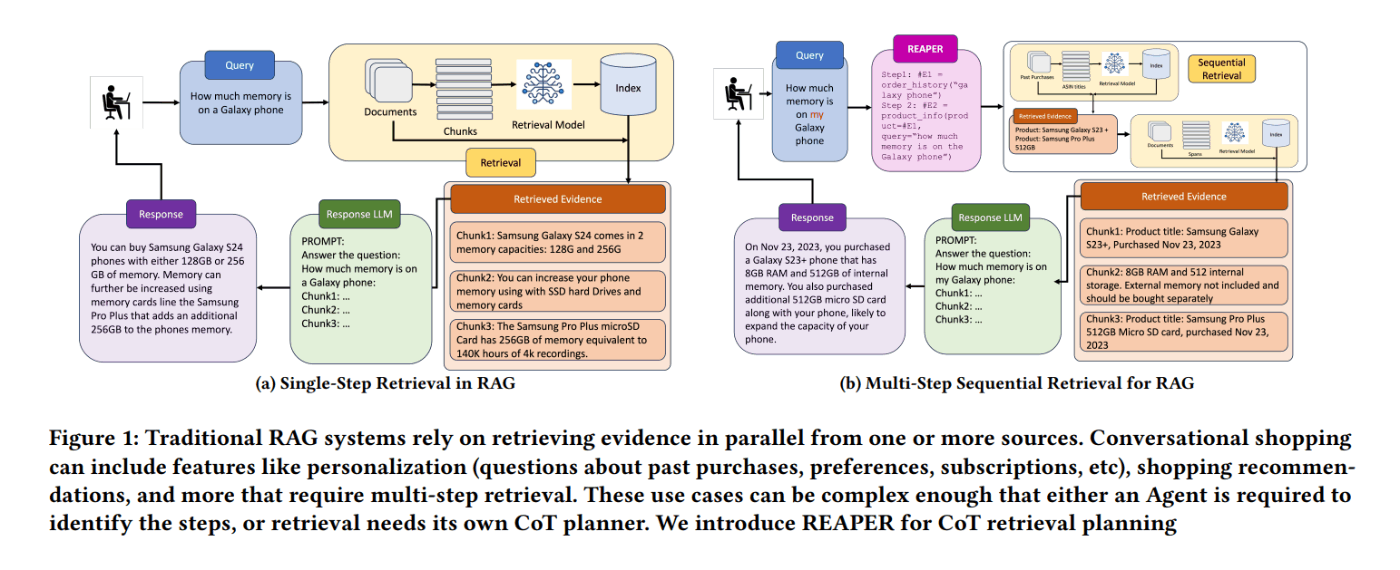
REAPER は、ユーザーからの複雑な質問に対して、高速で回答できるようにするためのRAGの手法です。Amazonの研究者らによって2024年7月に提案されました。AmazonのようなECサイトのチャットボットでは、まさに、REAPERのようなRAG手法が大活躍します。「複雑な質問がくる上に、正確に最速で回答しなければならない」みたいな場所でRAGを活用するための手法だと言えます。
通常のRAGでは、ユーザーから複雑な質問が来た場合、CoT[2]します。(※複雑な質問について、LLMがステップバイステップで考えて、「生成」と「振り返り」を繰り返しながら正解にたどり着く手法)。逆に、REAPERではCoTをしません。ユーザーから複雑な質問が来た場合、CoTせず、最初に1回だけ「計画」を作成します。「どのDBからどのデータを取得すれば良さそうか」の計画を、最初の1回で生成します。
REAPERのメリットは、LLMへの問い合わせが1回で済むので非常に速いことです。しかも、そのLLM自体、とても小さいモデルを利用しているので更に速いです。(※ファインチューニングしてハルシネーション対策を実施した上で活用)
問題意識
Retrieval-Augmented Generation (RAG) は便利ですが、複雑な質問に回答するのはあまり得意ではありません。例えば、「昨日注文したタイヤはいつ届く?」という質問が来た場合。LLMはまず、「昨日」がいつなのか分かりません。これを克服する手法としてまずポピュラーなのは、Langchainでも採用されている、いわゆる「AIエージェント型」のアプローチです。
AIエージェントとは
ここでいうAIエージェントとは、目標を与えられたLLMが、複数の「Tool」を自分で活用して、自律的に正解にたどり着けるようにする手法です。
つまり、①ユーザーが質問する→②LLMが外部のAPIを自分で叩く→③APIのレスポンスに基づいて回答→④LLMが「これでユーザーの回答に十分か?」と内省→⑤足りなければ別のAPIを叩く... と繰り返していく手法です。上の例で言えば、 date_math("昨日") みたいに、関数をLLM自身が叩けるようにします
ただし、AIエージェントは、回答が遅いというデメリットがあります。遅い理由は、Chain of Thought (CoT)という手法を利用することで、質問に回答するのに必要な手順をステップバイステップで処理していくからです。
手法
REAPERは、ユーザーから質問が来た際、「どのツールを使ってどのような情報収集をすれば正解に導けるか」ということを、LLMへの問い合わせ1回だけで計画する手法です。
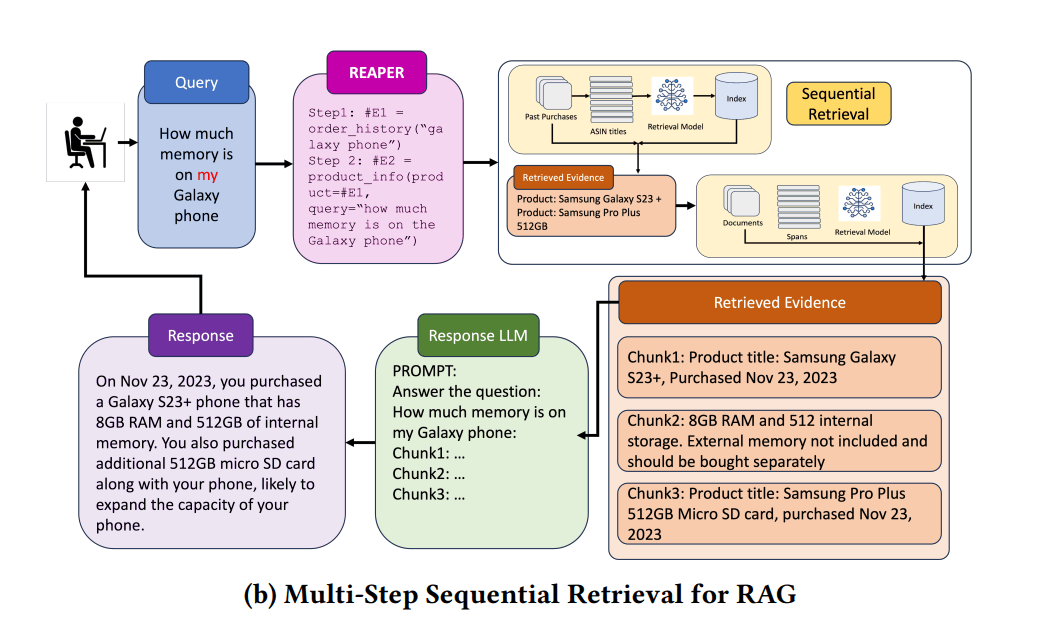
【事前にやっておくこと】
REAPERでは、事前に小さい言語モデル(Mistral 7B)をファインチューニングしておきます。このモデルを使って計画を生成させます。なので、どんな質問が来たとしても、なるべくハルシネーションを起こさないよう、モデルを調整します。
【ユーザーが質問を入力して来たとき】
-
情報収集の計画をLLMに生成させる
例: 「昨日注文したタイヤはいつ届く?」という質問が来たとすると、これに回答するには①「昨日」が何月何日なのか知るための関数、②直近の注文履歴を取得する関数を使う必要がある、という計画を作成 - 1の計画をもとに、それぞれの関数を並列で実行
- 2の内容をもとに、LLMが最終的な回答を生成
このREAPERという手法のキモは、小型LLMをファインチューニングしている部分です。通常、小さくてモデルに「計画」みたいな複雑なことをやらせると、必ずハルシネーションします。今回は、上手くファインチューニングしたことで、小さいモデルを実用レベルに引き上げることに成功。結果として高速な回答が実現しています。
成果
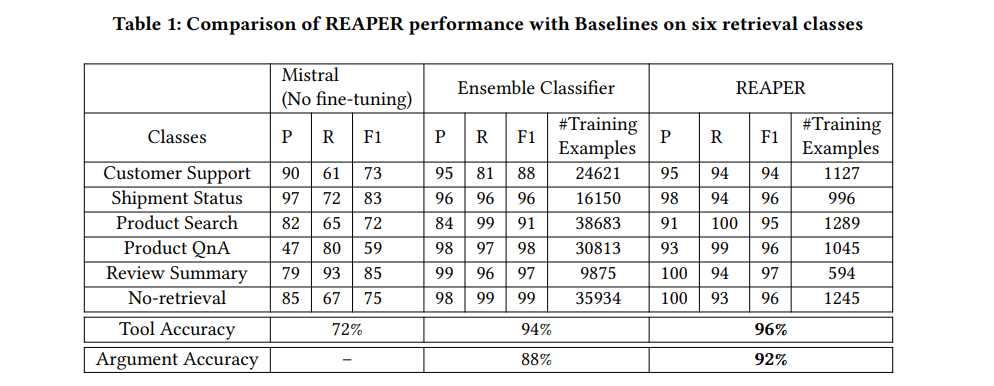
- ツール選択で96%の正確性。引数抽出で92%の正確性
- 新しい「ツール」を追加する際も、286のサンプルを追加するだけで対応可能だった
- Agent型システムと比較して、計画生成の速度が10倍以上高速に(2秒に対して207ミリ秒)
まとめ
弊社では多くの企業向けに、RAGシステムの開発をしていますが、そのほとんどが「社内向け」のRAGです。逆に、ECサイトのチャットボットのような「社外向け」な場面でRAGシステムを提供しづらい理由は、回答精度・回答速度の問題があるからです。しかし、今回のREAPERという手法を利用することで、回答速度の問題が大きく解消される可能性があります。
また最近は、「小さいモデルを活用してRAGを高速化しよう」という研究がホットなように見えます(例えば「Speculative RAG」)。なので、「Google検索に比べて遅い」というRAG(というかLLMを使った検索システム)のデメリットがますます解消されていきそうです。
みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion