株式会社ナレッジセンスは、生成AIやRAGを使ったプロダクトを、エンタープライズ向けに開発提供しているスタートアップです。本記事では、RAGの性能を高めるための「Router Retriever」という手法について、ざっくり理解します。
この記事は何
RAGを実装するエンジニアが困りがちなのは、大量の文書から「いかに、ソースとなる正しい文書を検索してくるか」という検索部分です。この記事では、そういった文書検索の精度を上げるための手法である「RouterRetriever」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は以下の記事もご参考下さい。
(注:前提として、今回の手法はちょっとディープです。これまでRAGをやってきたエンジニアで、「RAGの文書検索って難しい」と感じたことがある方にだけ刺さる内容です。)
本題
ざっくりサマリー
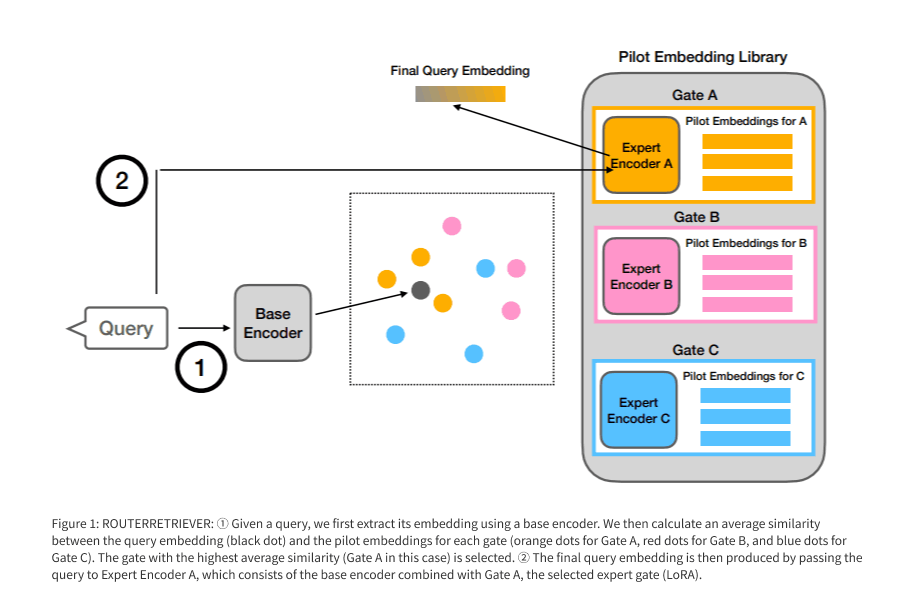
RouterRetrieverは、RAGで複数の埋め込みモデルを使うことで、文書検索の精度を向上させる手法です。KAISTとアレン人工知能研究所の研究者らによって2024年9月に提案されました。
通常のRAGでは、文書検索する際、埋め込みモデル(エンべディングモデル)を1つだけ利用して、ベクトル検索します。つまり、「ユーザーの質問」と「ソースとなる大量の文書」を、同じ埋め込みモデルでベクトル化して、マッチングしています。
また、この「1つだけ」使う埋め込みモデルについても、OpenAIが公開している「text-embedding」のような、汎用的なモデルが使われることが一般的です。しかし、こういう汎用的な埋め込みモデルよりも、そのドメインに特化したモデルを利用した方が検索精度が高くなることが知られています。(例えば損保ジャパンさんのRAG精度向上もこのパターン)
そこで、RouterRetrieverは、ユーザーの質問のジャンルに応じて、複数の埋め込みモデルを使い分けるという手法です。例えば、医学系の質問だったら医学系に特化した埋め込みモデルを利用して、ユーザーの質問をベクトル化。こうすることで、より精度の高い文書検索を実現します。
問題意識
従来のRAGの課題として、ユーザーの質問に専門的な内容が入っていると、文書検索が適切に出来ないという点がありました。
どういうことかと言うと、RAGの文書検索には、以下のジレンマがあります。
- RAGで、ある分野の検索に強くするには、その分野に特化した埋め込みモデルにするのが一番いい
- しかし、その分野に特化すると、それ以外の質問には、弱くなってしまう
→これらをクリアするため、これまでは、全ての分野に平均的に強い「バランス型」の埋め込みモデルを1つだけ使う、という解決策が主流でした。しかし、これでは平均的な性能しか出ません。
手法
RouterRetrieverは、複数の埋め込みモデルを動的に使い分ける手法です。ユーザーから質問が来た際、まず「どの埋め込みモデルを使うの最適か」を判断し、そのモデルで検索を行います。
【事前にやっておくこと】
- 専門家モデル(例えば、医学特化の埋め込みモデルなど)を複数作成しておく。
- 「Contriever」という汎用的な埋め込みモデルをLoRA(Low-Rank Adaptation)して複数作成。
- ちなみに、ユーザーの質問には複数のモデルを使い分けますが、ドキュメントの埋め込みには、通常通り1つの埋め込みモデル(Contriever)のみを利用。
- 「どの埋め込みモデルを使うの最適か」を、動的に判断するための仕組みも事前に構築。
- (詳細は割愛。ざっくりいうと、「その専門家モデルが得意なタイプの質問」を測るためのベクトルを用意しておく感じ)
【ユーザーが質問を入力して来たとき】
- ユーザーの質問を汎用的なモデル(Contriever)でベクトル化
-
このベクトルと、事前に用意した「各専門家モデルが得意なタイプの質問のベクトル」を比較
上記画像の①の部分 -
2で最もスコアが高かったモデルを利用して、もう一度ユーザーの質問をベクトル化
上記画像の②の部分 - このベクトルを利用して、検索対象である、大量の文書を検索(ここは通常のRAGと同じ)
RouterRetrieverという手法のキモは、「どの埋め込みモデルを使うの最適か」を、動的に判断するための仕組みです。こうすることで、例えばユーザーの質問が医療関連のときはこのモデル、金融関連のときはこのモデル、という形で、常に一番精度の高いモデルを使うことが可能になります。
成果

- BEIRベンチマークにおいて、MSMARCOで訓練された単一モデルに比べて+2.1、マルチタスク訓練モデルに比べて+3.2のnDCG@10スコア向上を達成
- ゲート(専門家モデル)の数を増やすにつれて、一貫して性能が向上
- ドメインに特化した専門家モデルがないデータセットに対しても汎用性を持つことが確認された
(注:下2つの手法に劣っているように見えますが問題ないです。下2つの手法は、「どの埋め込みモデルを使うの最適か」という選択をせず、総当たり的に全てのパターンを試した手法。比較のためだけに用意されたもの。)
まとめ
弊社では普段から、法人向けにRAGシステムを提供しています。その中で、「企業に蓄積された専門的な文書には、汎用的な埋め込みモデルでは上手く検索できない」という現象をよく目にします。そういう問題に対しては、RouterRetrieverが活躍します。
RouterRetrieverは少し複雑で手間もかかる手法ですが、埋め込みモデルに着目している手法はあまりないので、紹介しました。RAGが専門領域に弱いという問題を解決しようとする手法は、他にもありますがのでご参考ください。[2][3]
みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion