【RAG】CohereのRerankerをLangchainで試す
RAGの性能改善手法の一つとして、比較的手軽に実装できるCohereのRerankerを試してみました。いったん、通常のベクトル検索で抽出したチャンクをRerankモデルに入力して、関連度の高い順にRerankする手法です。LangchainのContextual Compression Retrieverを利用すればすぐに実装できます。
RAGの性能改善手法 Rerank とは?
RerankはRAGの性能改善手法の一つです。
Rerankでは、通常のベクトル検索による検索結果に対して再評価を行い、よりクエリとの関連度の高い順序で並べ替えます。ベクトル検索では、大量の候補文書(チャンク)の中から関連度だけを元に検索を実施しますが、実施には関連度の低いものや、ベクトル距離は近くても文脈が異なるものが含まれます。Rerankはこれらのチャンクを再評価し、最も関連性が高いものを上位に配置することで、最終的な応答の品質を向上させることができます。
まとめると、以下の順で実施します。
- 通常のベクトル検索で広範な候補文書を取得
- Rerankにより候補文書を関連度順に並び替える
Rerankを実行するには、それに適したモデルが必要になります。2024年7月現在、CohereがRerankモデルとして rerank-multilingual-v3.0 を提供しています。このモデルはマルチリンガルに対応していて、日本語にも対応しているので、これを利用することにします。
CohereのRerankモデルについては、以下のCohereのページもご覧ください。
実装の概要
LangchainからCohereのRerankモデルを使うことができるので、いつものようにLangchainで実装してみます。今回、動作確認に用いた各種バージョンは以下のとおりです。
- Windows 10
- Python 3.11.6
- Langchain 0.2.7
- chromadb 0.5.4
ベクトルDBにはChromaを利用します。
コードはGithubの以下のリポジトリに置いておきます。
動作させるには、requirements.txtにあるPythonパッケージをインストールし、.envにOpenAIとCohereのAPIキーを設定してください。また、今回はLangSmithを利用して動作を確認しています。LangSmithを利用する場合には、LangchainのAPIキーが必要です。
OPENAI_API_KEY=<OpenAI API Key>
COHERE_API_KEY=<Cohere API Key>
LANGCHAIN_API_KEY=<Langchain API key>
CohereのRerankモデルは、お試し程度であれば無料のプランで利用できます。また、Langsmithも同様です。
実装の詳細
それでは、実装の詳細について、コードを参照しながらポイントを解説していきます。
ベクトル検索Retrieverの作成
まず、通常のベクトル検索を実施するためのRetrieverを作成します。
TOP_K_VECTOR = 10
def vector_retriever():
"""Create base vector retriever
Returns:
Vector Retriever
"""
# load and split document
documents = load_and_split_document(DOCUMENT_URL)
# chroma db
embeddings = OpenAIEmbeddings(model=EMBEDDING_MODEL)
vectordb = Chroma.from_documents(documents, embeddings)
# base retriever (vector retriever)
vector_retriever = vectordb.as_retriever(
search_kwargs={"k": TOP_K_VECTOR},
)
return vector_retriever
load_and_split_document()は、LangchainのWebBaseLoaderで取得したWebページをチャンクに分割して、LangchainのDocumentに格納するための自作関数です。(詳細はGithubのリポジトリのコードをご覧ください)
チャンク (documents) をベクトルDBのChromaに入れますが、EmbeddingモデルとしてOpenAIのtext-embedding-3-smallを利用しています。
最後にretrieverを作成しますが、search_kwargs={"k": TOP_K_VECTOR}のオプションで、候補文書を10個取得するように設定しています。(TOP_K_VECTORは10)
ここまでは、いたって普通のLangchainによるベクトル検索のコードです。
Rerankerの作成
次に、Rerankに用いるRerankerを作成します。Rerankerは、Langchainに用意されているContextualCompressionRetrieverのモデルにCohereRerankを適用して作成します。
TOP_K_RERANK = 3
def retriever_with_rerank():
"""
Retrieve documents using Multivactor retriever with Rerank
"""
# base retriever
base_retriever = vector_retriever()
# Reranker
cohere_reranker = CohereRerank(
top_n=TOP_K_RERANK,
cohere_api_key=COHERE_API_KEY)
compression_retriever = ContextualCompressionRetriever(
base_compressor = cohere_reranker,
base_retriever = base_retriever,
)
return compression_retriever
Contextual Compression Retriever は、大規模な文書コレクションから関連性の高い情報を効率的に取得するための手法です。
"Compression"とあるように、関連性の低い部分を排除し、クエリに対する応答に必要な情報だけを抽出することで、全体のコンテキストを圧縮します。
cohere_reranker = CohereRerank(
top_n=TOP_K_RERANK,
cohere_api_key=COHERE_API_KEY)
CohereのRerankerの定義はこのようになっています。top_nには取得したい文書の数を指定します。今回はTOP_K_RERANKを3に設定していますので、通常のベクトル検索で取得した10個の候補文書をRerankして、関連度の高い3個を取得します。
compression_retriever = ContextualCompressionRetriever(
base_compressor = cohere_reranker,
base_retriever = base_retriever,
)
LangchainではContextualCompressionRetrieverに対して、base_compressorにCohereのRerankerを、base_retrieverに先ほど作成したベクトル検索retrieverを与えると、前述のようなマルチステージの検索を実現できます。
すなわち、base_retriever(ベクトル検索)で取得した候補文書をbase_compressor(CohereのReranker)に与えて、最終的な検索結果を出力します。
RAGの実施
RAGを実行する部分のコードは以下のとおりです。
def rag(retriever, query: str):
# LLM model
llm_model = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo")
# RAG chain
chain = RetrievalQA.from_chain_type(
llm=llm_model,
retriever=retriever)
# invoke
result = chain.invoke({"query": query})
return result.get('result')
retrieverに先ほど作成したcompression_retrieverを渡せば、Rerank付きのRAGを実行できます。RAGのクエリに用いるLLMは何でもいいですが、ここではgpt-3.5-turboを利用しています。
動作確認(LangSmith利用)
それでは、さっそく動作確認をしてみます。
LangSmithの設定
retrieverで取得したドキュメントをprint文でコンソールに表示してもよいのですが、今回はLangchainの動作をWeb上で確認できるLangSmithを利用してみます。
LangSmithを利用するには、LangChainのAPIキーが必要となります。以下のリンクからサインアップし、APIキーを取得し、.envに設定しておいてください。お試しやちょっとした個人開発レベルであれば、無料プランでそれなりに利用できます。
LangSmithをPython上から利用するには、以下のように環境変数を設定します。
# Langchain LangSmith
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = LANGCHAIN_API_KEY
LANGCHAIN_PROJECTには、実行毎に異なるプロジェクトの識別子を指定しますが、ここではuuidを用いて識別できるようにしています。
たったこれだけで、LangSmithのWeb上で動作を確認できるようになります。
Rerankの動作確認
ナレッジとしては、Wikipediaの北陸新幹線のページを利用します。
上記のWikipedeiaから取得したテキストをsize=500で分割(overlap=24)した結果、278個のドキュメントが生成されました。これをナレッジとして利用します。
クエリとして「北陸新幹線の建設主体と営業主体は?」と聞いてみます。その結果をLangSmithで表示させたものが以下です。
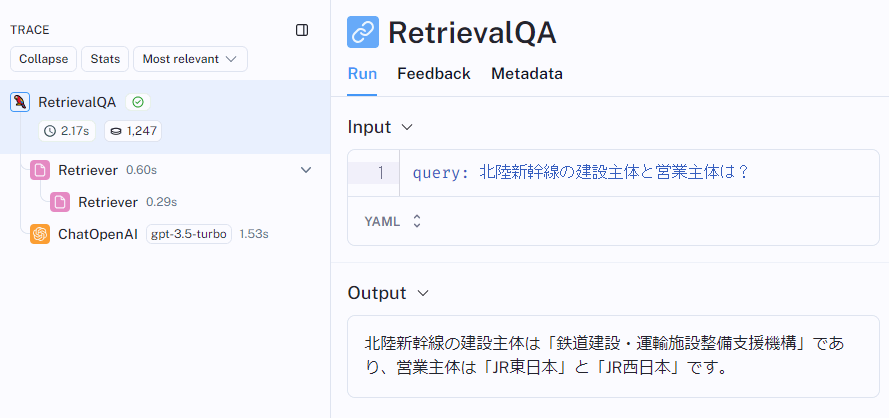
LangSmithでのトレース結果
LangChainで実行したとおりにトレースが表示されています。Retrieverが2つ表示されているのは、ベクトル検索とRerankingの2段階で検索を実施しているためです。

ベクトル検索で抽出された10個の候補文書一覧
Retrieverの2つ目に表示されているのが、最初のベクトル検索の結果です。10個の候補文書が取得されているのがわかります。
ここでは詳しくは述べませんが、取得された候補文書を見てみると、キーワード的にはクエリと合致しているものの、文脈としてはクエリと関連の薄いものも含まれています。
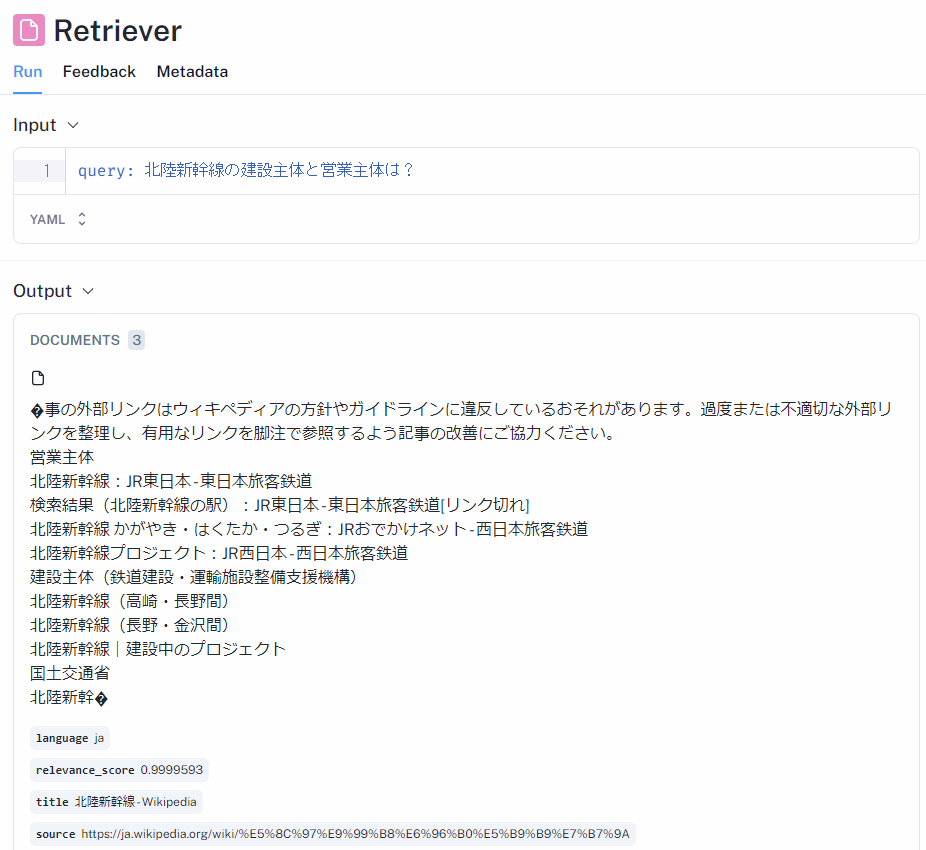
Rerankにより抽出された関連性の高い3つの候補文書
次に、1つ目のRetrieverの結果を見てみます。これはRerankにより最終的に抽出された候補文書です。上の画面キャプチャでは3つ取得された候補文書のうち、もっとも関連性の高いものを開いています。
営業主体、建設主体それぞれの会社名・組織名が記載されていて、クエリの回答が見事に含まれていることがわかります。残りの2つの候補文書にも、営業主体の情報が含まれていました。
ということで、ベクトル検索で取得した10個の候補文書のうち、クエリに関連の深いものをきちんと抽出できていることがわかりました。
RAGの回答
RAGの最終的な回答を、通常のベクトル検索のみの場合と、Rerankを利用した場合とで比較してみます。今回のプログラムでは、-vオプションでベクトル検索のみ、-rでベクトル検索+Rerankで検索できるようにしています。
# ベクトル検索のみ
$ python .\retriever.py 北陸新幹線の建設主体と営業主体は? -q -v
北陸新幹線の建設主体は鉄道建設・運輸施設整備支援機構であり、営業主体は東日本旅客鉄道(JR東日本)と西日本旅客鉄道(JR西日本)です。
# ベクトル検索+Rerank
$ python .\retriever.py 北陸新幹線の建設主体と営業主体は? -q -r
北陸新幹線の建設主体は「鉄道建設・運輸施設整備支援機構」であり、営業主体は「JR東日本」と「JR西日本」です。
どちらもほぼ同じ回答となりました。いずれも正解ですね。
別の質問で試してみます。
# ベクトル検索のみ
$ python .\retriever.py 北陸新幹線の雪対策は? -q -v
北陸新幹線の雪対策には、高架橋の軌道下に雪を貯める貯雪方式や、スプリンクラーによる散水消雪方式、消雪パネルの開発などが含まれています。さらに、雪払い列車や排雪列車を運行して除雪作業を行ったり、高架橋を拡幅して貯雪量を増やすなど、 周辺環境に合わせた様々な対策が取られています。
# ベクトル検索+Rerank
$ python .\retriever.py 北陸新幹線の雪対策は? -q -r
北陸新幹線の雪対策には、消雪パネルの開発や貯雪方式、散水消雪方式などが採用されています。また、周波数に応じて切り替えるATC装置や電気設備も設けられています。これらの対策は、北陸地方の豪雪地帯での安定輸送を維持するために行われています。
北陸新幹線の雪対策についての質問ですが、これはベクトル検索のみのほうが正解です。ベクトル検索+Rerankのほうに含まれる「また、周波数に応じて切り替えるATC装置や電気設備も設けられています。」は、Wikipediaの雪対策の前の章に記載されている異周波数対応の内容です。
Rerankした結果、候補文書を3つのみに絞っていることと、文章の構造を無視して500文字という文字数だけで分割をしていることで、Rerankをしたほうが結果が悪くなっているようです。
まとめ
CohereのRerankerを利用して、Rerankingの効果を確かめてみました。
ベクトル検索で取得できた候補文書のうち、クエリに関連の深いものを抽出するというRerankの効果は確認できました。
一方で、RerankでLLMに与える文書を絞ってしまうことによる弊害もありそうです。今のLLMはトークン数の上限がかなり大きくなっていますし、賢くもなっていますので、10個くらいの文書であればば丸ごと渡してしまうのもアリでしょう。多少関係のない情報が混ざっていても、LLM側でクエリと関連の深い情報を利用して回答してくれます。
それでは、Rerankの使いどころは……と考えてみると、大規模なドキュメントを対象として、ベクトル検索で数十~100件くらいを抽出したあと、Rerankで関連性の高いものを10件ほど抽出する……という使い方かなと思います。ドキュメント全体から幅広く関連する部分をピックアップし、その中からさらにクエリに関連性の高いものに絞るというユースケースに適していると考えます。
関連記事
RAG関連の記事です。
↓クエリに関連する質問をいくつか作成したうえで、それぞれに対してベクトル検索を実施する RAG Fusion という手法を試した記事です。
↓ベクトル検索用の小さいチャンクと、LLMに渡す用の大きなチャンクを分離する MultiVector Retriever というRAG手法を試した記事です。
↓RAGに入力するナレッジを作成する際に、元のドキュメントの構造を意識してチャンクに分割する手法を試した記事です。これだけでかなり精度の向上が見られました。
Discussion