Multivector Retrieverで検索用のチャンクとLLMに渡すドキュメントを分離することでRAGの精度向上を目指す
今回は、RAGにおいて、ベクトル検索に利用するチャンクと、LLMに渡すコンテキストのドキュメントを分離する方法を試してみます。Langchainの MultiVector Retriever を利用します。結果として、それなりの精度向上が実現できました。
MultiVector Retriever でRAGの検索精度向上を目指す
前回は、ブログ記事のテキストを<h2>タグでチャンク分割することでRAGの精度改善が実現できるかを試しました。元の文章の構造を意識してチャンクを分割することで、Retrieverの精度が向上することを目指したわけです。結果としては、適当に文字数でチャンク分割するのと比べて、多少の精度向上は見られましたが、まだ十分ではありませんでした。
今回は、クエリ(ユーザの質問)から関連する文章を検索するときに利用するチャンク(埋め込みベクトルにより検索されるチャンク)と、LLMにコンテキストとして渡すドキュメントを分けることで、検索の精度向上を目指してみます。
実装としては、LangchainのMultiVectorRetrieverを利用してみます。
ベクトル検索のチャンクとLLMに渡すドキュメントをを分ける
RAGにおけるベクトル検索では、クエリ(質問)の埋め込みベクトルと、Vector Store(これまでの例ではChroma)に格納されているチャンクの埋め込みベクトルを比較して、その類似度が高いものを検索結果として出力します。
これまでは、Retrieverが出力したチャンクをそのままLLMにコンテキストとして渡していましたが、今回はここにひと工夫します。
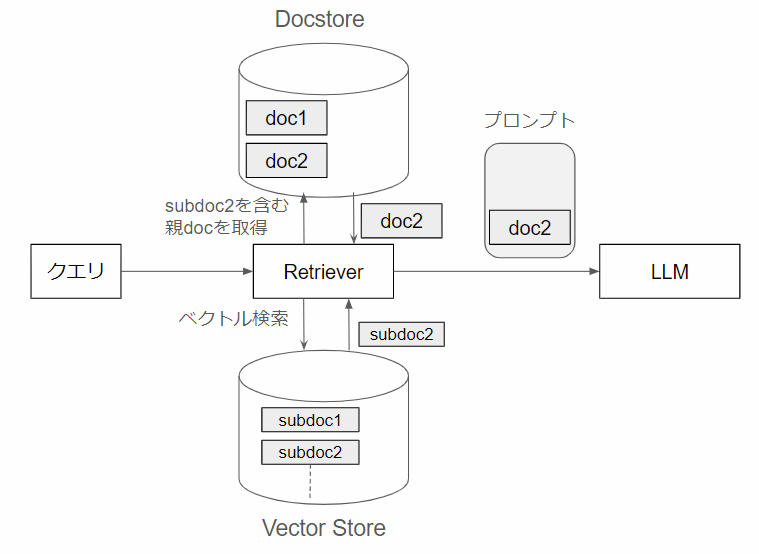
RAGにおけるベクトル検索用チャンクとLLMに渡すドキュメントの分離の概要
一般に、RAGにおいて、LLMに渡すコンテキストは、LLMが回答を作成するうえで参考になる情報や周辺知識が多く含まれるように、長めの文章を渡すほうが良いとされています。一方で、Vector Store からクエリに関連するチャンクを検索する場合には、その特徴を目立たせるために、短めの文章のほうがよいとされています。
そこで、短めの文章でVector Storeを検索し、その検索結果のチャンク(上の図ではsubdoc2)が含まれる長めの親ドキュメント(上の図ではdoc2)をLLMに渡すことができれば、Retrieverの検索精度向上と、LLMの質問回答の正確性の向上が図れるのではないかという考え方があります。
今回は、これをLangchainのMultiVectorRetrieverを用いて実装し、その性能を確かめてみます。全体のコードは、以下のリポジトリに置いてあります。basic_qabot3.pyです。
<h3>セクションを検索用のチャンクとして利用する
今回は、ブログ記事のHTMLファイルをデータとして利用していますので、その構造に沿った形で、検索用のチャンクとLLMにコンテキストとして渡すドキュメント(親ドキュメント)を作成します。
具体的には、以下のようにします。
-
<h2>セクション全体をLLMに渡す親ドキュメントとする(Docstoreにそのまま格納) - 上記
<h2>セクション内に含まれる個々の<h3>セクションをRAGの検索用チャンクとする(Vector Store に埋め込みベクトルとともに格納) -
<h3>セクションを含まない<h2>セクションは、そのまま検索用チャンクとする
前回の記事で、<h2>タグでチャンクを分割する部分を実装していましたので、今回はそれを流用して、さらに<h3>で分割するようにしました。
def create_docs_from_html(contents: list[str]):
docs = []
doc_ids = []
sub_docs = []
metadatas = []
for content in contents:
# bs4 for html parser
soup = BeautifulSoup(content, 'lxml')
# docs
doc = soup.get_text()
docs.append(doc)
uid = str(uuid.uuid4())
doc_ids.append(uid)
texts = []
# <h3>タグを全て見つける
tags = soup.find_all(['h2', 'h3'])
for tag in tags:
# セクションのテキストを取得
tmp = [tag.text + '\n']
for sibling in tag.next_siblings:
if sibling.name == 'h3':
break
if isinstance(sibling, NavigableString):
tmp.append(str(sibling).strip())
elif sibling.name:
tmp.append(sibling.get_text(strip=True, separator="\n"))
# <h3>セクションのテキストを追加
texts.append(''.join(tmp))
sub_docs.extend(texts)
metadatas += [{'doc_id': uid} for _ in texts]
return {'docs': docs,
'doc_ids': doc_ids,
'sub_docs': sub_docs,
'metadatas': metadatas}
create_docs_from_html()に<h2>で分割されたHTML(文字列)のリストを渡すと、さらに<h3>単位で分割してsub_docsを作成します。具体的には、以下のリストを作成して返します。
-
docs: LLMにコンテキストとして渡す親ドキュメントのリスト(<h2>単位のHTMLからテキストだけを抽出したもの) -
doc_ids:docsと一緒に格納するドキュメントID(uuidで作成)のリスト -
sub_docs:<h3>タグ単位で分割したチャンクのリスト -
metadatas:sub_docsとともにVector Storeに格納するときのmedatada
後述しますが、LangchainのMultiVector Retrieverでは、チャンクや親ドキュメントに付与されたID(doc_id)をもとに、チャンクと親ドキュメントを紐づけます。doc_idsとmetadatasはそのIDを格納しています。
Vector Store (Chroma) と Docstore を作成
前項で作成したチャンクなどを適切なデータストアに格納していきます。関数create_store()の引数dataは、前述のcreate_docs_from_html()の戻り値そのものです。
# Chroma DB, Docstore
persist_directory = './sampledb3'
vectordb_collection_name = 'wordpress'
docstore_filename = './wordpress_docstore.bin'
# Models
EMBEDDING_MODEL = "text-embedding-ada-002"
'''
sub_docsからVectore Store(ChromaDB)を、
docsからdocstoreを作成
'''
def create_store(data: dict):
# Chroma Vectore Store を生成
# embedding model を設定(OpenAIのtext-embedding-ada-002を利用)
embeddings = OpenAIEmbeddings(model=EMBEDDING_MODEL)
# path=persist_directoryを指定するとファイルとしてDB内容が永続化される
client = chromadb.PersistentClient(path=persist_directory)
# Vectore store としてChromaDBを作成
vectordb = Chroma(
collection_name=vectordb_collection_name,
embedding_function=embeddings,
client=client,
)
# sub_docsとmetadataをChromaDBに格納する
vectordb.add_texts(data['sub_docs'], data['metadatas'])
# Docstoreを生成
docstore = InMemoryStore()
docstore.mset(list(zip(data['doc_ids'], data['docs'])))
# DocstoreをPickle形式で保存
pickle.dump(docstore, open(docstore_filename, 'wb'))
Vector Store として利用する Chroma のほうは、前回までと同様です。ただし、格納するデータは、<h3>タグで分割したチャンクと対応するdoc_idを含むメタデータです。
vectordb.add_texts(data['sub_docs'], data['metadatas'])
前回同様、PersistentClient(path=persist_directory)を指定して永続化しておきます。
一方、<h2>タグ単位で分割された親ドキュメントdocsは、対応するdoc_idsとともにInMemoryStoreに格納します。InMemoryStoreは、Key-Value-pair をメモリ上に格納するデータベースで、ほぼdictのように動作します。mset()メソッドに、(Key, Value)の配列を渡すと、それをそのまま格納します。
docstore = InMemoryStore()
docstore.mset(list(zip(data['doc_ids'], data['docs'])))
InMemoryStoreについては、LangchainのAPIドキュメントをご覧ください。
InMemoryStoreを永続化するため、今回はPickleでそのままファイルとして保存しています。
MultiVector Retriever を作成
前項で作成したVector StoreとDocstoreを利用して、MultiVector Retriever を作成します。
LangchainのMultiVectorRetrieverの概要
今回利用したLangchainのMultiVectorRetrieverは、一つのドキュメントに対して、複数の埋め込みベクトルを用いて検索することができるRetrieverです。
具体的には、ベクトル検索に利用するチャンクと埋め込みベクトルを格納するVector Storeと、その元のドキュメント(親ドキュメント)を格納するDocstoreという2つのストアを用います。Docstoreに格納されている親ドキュメントにIDを付与し、親ドキュメントを分割したチャンクにも同一のIDを付与することで、2つのデータベース間で紐づけをします。
詳しくは、Langchainのドキュメントをご参照ください。
MultiVectorRetrieverを利用したRetrieverの作成
それでは、LangchainのMultiVectorRetrieverを利用して、Retrieverを作成してみます。
前項まででファイルとして保存されたVector Store (Chroma) と Docstore (Pickleで保存したInMemoryStore)を読み込む前提です。
# TOP_K for retriever
TOP_K = 10
'''
MultivectorRetrieverを作成
'''
def create_retriever():
# chrome db
embeddings = OpenAIEmbeddings()
client = chromadb.PersistentClient(path=persist_directory)
vectordb = Chroma(
collection_name=vectordb_collection_name,
embedding_function=embeddings,
client=client,
)
# docstoreをpickleから読み込む
docstore = pickle.load(open(docstore_filename, 'rb'))
# MultivectoreRetrieverを設定
# vectorestoreにはChromaで作成したVectore Storeを、
# docstoreにはInMemoryStoreで作成したDocstoreを指定
retriever = MultiVectorRetriever(
vectorstore=vectordb,
docstore=docstore,
id_key='doc_id',
search_kwargs={"K": TOP_K},
)
return retriever
LangchainのMultiVectorRetrieverは、vectorstoreにベクトル検索用のVector Storeを、docstoreにLLMに渡す親ドキュメントを含むストアを、id_keyにvectorstoreとdocstoreの文章を紐づけるためのIDとして利用する識別子(Vector Storeのmetadataに含まれる識別子)を渡します。
なお、search_kwargs={"K": TOP_K}は、通常のRetrieverであれば、Vector Store を検索して出力するドキュメントの数になりますが、MultiVectorRetrieverの場合は少し注意が必要です。MultiVectorRetrieverでは、最初にVector Storeを検索してチャンクをK個取り出しますが、複数のチャンクが同じ親ドキュメント(docstoreのほうに含まれる最終的に出力されるドキュメント)に含まれることがよくあります。この場合、MultiVectorRetrieverが最終的に出力する親ドキュメントの数は、K個より少なくなります。実際に出力してほしいドキュメントの数よりも、Kを少し大きめに設定しておく必要があります。
作成したMultiVector Retrieverを用いてクエリに回答する
最後に、先ほどcreate_retriever()で作成した MutlVector Retriever を用いてチェインを構成し、クエリに回答します。
RetrieverがMutlVector Retrieverになる以外は、前回とほとんど変わりません。今回もLCEL記法でチェインを構成しています。
# Models
LLM_MODEL = "gpt-3.5-turbo-1106"
'''
作成したvector Store と Docstore を用いて、
MultivectorRetrieverで質問に回答する
'''
def query(query: str):
# Multivector Retriever
retriever = create_retriever()
# model
# クエリに利用するOpenAIのモデルを設定
model = ChatOpenAI(
temperature=0,
model_name=LLM_MODEL)
# prompt
# プロンプトを設定
prompt = PromptTemplate(
template=my_template_jp,
input_variables=["context", "question"],
)
# output paeser
# LLMの出力を文字列として返すパーサーを設定
output_parser = StrOutputParser()
# Query Chain
# LangchainのLCEL記法でChainを設定
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| output_parser
)
# Chainを実行
#result = chain.invoke(query, config={'callbacks': [ConsoleCallbackHandler()]})
result = chain.invoke(query)
# 結果を表示
print('回答:\n', result)
動作確認&検証
動作確認と検証をしてみます。動作確認は、MultiVectorRetrieverがきちんと長い方のドキュメントを返しているのかを確認します。検証では、これまで作成したRAGとの比較をしてみます。
MultiVectorRetrieverの動作確認
MultiVectorRetrieverの動作確認として、クエリに対して検索されたドキュメントを表示してみます。
'''
MultivectorRetrieverでドキュメントを検索
'''
def retrieve(query: str):
# Multivector Retriever
retriever = create_retriever()
# retrieve
result = retriever.get_relevant_documents(query)
for item in result:
print('-----')
print(item)
MultiVectorRetrieverで文章を検索するには、get_relevant_documents(query)メソッドを実行するだけです。戻り値として、検索されたドキュメントの配列が返ってきます。
前述のKを10に設定して、試してみます。-rオプションは、上に掲載したretrieve()だけを実行するものです。
$ python .\basic_qabot3.py -r 青春18きっぷで本州から北海道へ渡るには?
-----
【結論】青春18きっぷ 本州~北海道 移動手段の使い分け
鉄道、フェリーを利用した、本州~北海道の移動手段を紹介しました。最後に、主な使い分けをまとめておきます。
(省略)
-----
【まとめ】行程・予算別 青春18きっぷ旅での本州~北海道の移動手段
青春18きっぷ旅での本州~北海道の移動手段を下の表にまとめてみます。それぞれについては、このあとで一つずつ詳しく紹介していきます。
(省略)
-----
北海道新幹線の一部区間に乗車できる「青春18きっぷ北海道新幹線オプション券」
青函トンネルを挟む区間については、北海道新幹線が開業したことにより、在来線の列車がなくなり、新幹線のみの運転となってしまいました。この区間を青春18きっぷで乗車したい場合には、「青春18きっぷ北海道新幹線オプション券」(2,490円)を別途購入する ことで乗車できます。
(省略)
-----
本州~北海道の移動はフェリーも便利!
青春18きっぷの旅で本州~北海道を移動する場合には、フェリーも候補になります。
(省略)
長いので省略しましたが、元のHTMLと比較してみると、<h3>タグで分けられた<h2>セクション全体の文章が出力されています。ベクトル検索で使われた<h3>セクションのみの短い文章ではなく、Docstoreのほうに格納されている<h2>セクション全体のドキュメントが返されているということが確認できました。
なお、Kを10に設定していますが、出力されたドキュメントは4個のみです。詳しく見てはいませんが、おそらく、ベクトル検索の段階で、同一の<h2>セクション内の異なる<h3>チャンクが複数検索されているものと思われます。
クエリ回答精度の評価
クエリに対する回答が期待するレベルのものに改善されているかを、前回までと同じ質問で評価してみます。前回までと同様に、各質問の回答に対して、次の基準で得点を評価しました。
- 回答が正しい(記事中に含まれる記述と一致する)場合: 1点
- 回答の一部は正しいが、間違っている部分もある場合: 0.5点
- 回答が間違っている場合、または、適切な回答でない場合: 0点
なお、親ドキュメント数(<h2>セクションの数)は538、検索用チャンク数(<h3>セクション数)は1,026です。ベクトル検索に用いるチャンクの文字数の分布は以下の図のとおりです。
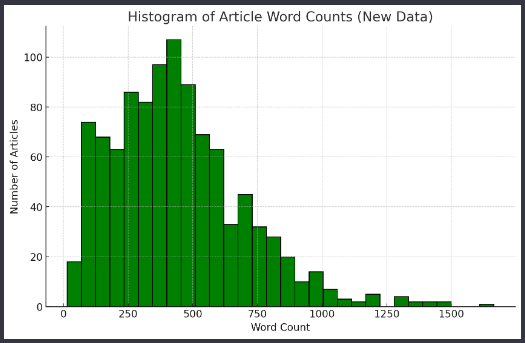
ベクトル検索用チャンクの文字数分布
以下が結果になります。qabot3が今回のMultiVectorRetrieverを利用したものになります。
| No. | 質問(クエリ) | qabot1 | qabot2 | qabot3 |
|---|---|---|---|---|
| 1 | 冬の青春18きっぷの利用期間は? | 1 | 0 | 1 |
| 2 | 青春18きっぷで乗車できる列車種別は? | 1 | 1 | 1 |
| 3 | 1枚の青春18きっぷを二人で使うには? | 0 | 1 | 1 |
| 4 | 青春18きっぷで本州から北海道へ渡るには? | 0.5 | 1 | 1 |
| 5 | 青春18きっぷで特例で乗車できる特急列車は? | 0 | 0 | 0 |
| 6 | 青春18きっぷの旅でおすすめの東京発日帰りルートは? | 1 | 1 | 1 |
| 7 | 青春18きっぷの旅でおすすめの海の車窓が素晴らしい路線は? | 1 | 1 | 1 |
| 8 | 冬の青春18きっぷでおすすめの路線は? | 0 | 1 | 1 |
| 9 | 青春18きっぷで東海道本線を快適に移動するには? | 1 | 0 | 1 |
| 10 | 青春18きっぷの旅でワープにおすすめの区間は? | 0 | 1 | 1 |
| - | 合計点 | 5.5 | 7.0 | 9.0 |
※qabot1: 単純に2000文字でチャンク分割し埋め込みベクトルで検索する方式
※qabot2: <h2>タグ単位でチャンク分割し埋め込みベクトルで検索する方式
かなり精度が向上しました。クエリ10個という少ない数での評価ですので、その分を差し引いてみる必要はありますが、かなりの割合で期待している回答が得られています。
上記以外の質問項目についてもいくつか試していますが、こちらも期待通りの回答が得られる頻度が、体感的にもわかるレベルで向上しています。
また、HTMLの構造を意識した形で周辺情報をLLMに与えられているせいか、回答の正誤だけでなく、回答に含まれる情報量も全般的に増えています。具体例として、No.2の質問の回答例を示します。
qabot1:
青春18きっぷで乗車できる列車種別は、普通列車や快速列車です。新幹線や特急列車には乗れません。
qabot2:
青春18きっぷで乗車できる列車種別は、普通列車(快速列車含む)です。特急列車や新幹線を含む特急列車には乗車できません。また、一部の観光列車やSL列車にも乗車できますが、指定席券が必要です。
qabot3:
青春18きっぷで乗車できる列車種別は、全国のJR線の普通・快速列車の普通車自由席、BRT(バス高速輸送システム)、JR西日本宮島フェリーです。特急列車や新幹線を含む急行列車には乗車できません。また、観光列車やSL列車にも乗車できますが、一部の観光列車やSL列車は特急や急行列車として運行されているため、乗車できない場合があります。
どの回答も正しいのですが、情報量がだいぶ違いますね。LLMに対して、質問に関係の深いコンテキストを適切に提示できれば、LLMの回答も詳細なものになっていくようです。
【まとめ】回答の精度向上と情報量の増加が見られた
ベクトル検索用のチャンクとLLMに渡す文章(親ドキュメント)を分離することで、回答の精度向上が見られました。また、回答に含まれる情報量も増えることが確認できました。
もちろん、今回はブログ記事のHTMLでの検証ということで、どのような文章でも同じような結果が得られるかはわかりません。特に、<h2>セクションと<h3>セクションでチャンクを構成する方法は、もともとこのような構成になっていないドキュメントには適用できません。
また、今回は<h3>タグで分割されていない<h2>セクションはそのまま検索用チャンクとしてしまいましたが、これを他のチャンクと同じくらいの長さにまで分割することも考えられそうです。
とはいえ、「ベクトル検索用のチャンクとLLMに渡す文章を分離する」というコンセプト自体は有効だと思われます。それをどのような実装に落とし込むかは、RAGを実用化するうえでの一つのポイントになりそうです。
Discussion