文書データのクリーニングと<h2>タグによるチャンク分けでRAGの精度向上を目指す
前回の記事では、WordpressのブログのデータをXMLファイルでエクスポートし、TextSplitterを用いてチャックに分割したあと、Vector Store のChromaに格納することでRAGを実現しました。性能はそこそこでしたが、文書中に正解がある質問に対して、正しく文書を見つけられていないと思われる挙動もありました。
今回は、前回、適当に2000文字くらいで分割していたHTMLファイルをきちんとクリーニングし、一つのトピックについての話題に閉じるはずに<h2>タグで分割してチャンク分けをしてみました。
前回の記事は以下をご覧ください。
HTMLファイルのクリーニング&適切なチャック分けでRAGの精度向上を目指す
RAGは、クエリに対して関連するデータをDBから検索・取得して、LLMへのプロンプトに含めることで、専門知識が必要な質問に答える方式です。LLMが正確な回答を返せるかどうかは、DBから取得するデータの精度にかかっているといっても過言ではありません。
前回、とりあえずRAGを動かすところまではできましたが、質問によっては、間違った回答をすることもありました。これは、クエリに関連するデータをDBから取得する際に、適切なデータを検索できていないことによるものです。
そこで、今回は、専門知識としてVector Store (DB)に格納してあるテキストデータをクリーニングし、さらに、まとまったトピックの単位となる<h2>タグでチャンク分けをすることで、RAGの精度が向上するかを試してみます。
この記事のコードは、以下のリポジトリで公開しています。
HTMLファイルのクリーニング(不要なタグを削除)
まずは、HTMLファイルのクリーニングをします。クリーニングといっても難しいことはなく、質問の回答に不要なタグとその中身を削除するだけです。
今回は、以下のタグを削除しました。
- <figure>
- <img>
- <a>
- <table>
- <div class="blogcard">
図<figure>と画像<img>は、テキストベースのRAGでは不要ですのでバッサリ削除します。また、リンク<a>も不要です。表<table>は、回答に有用な情報が含まれている場合が多いのですが、表の内容をテキストで説明しているところも多いので、今回はとりあえず削除します。最後の<div class="blogcard">は、Wordpressのブログカードです。いわゆるリンクの一つですので、これも削除します。
# BeautifulSoup4
# content: HTMLタグを含むコンテンツ(文字列)
bs_html = BeautifulSoup(content, 'lxml')
# 図、画像、リンク、テーブルを全て削除
for tag in bs_html.find_all(['figure', 'img', 'a', 'table']):
tag.decompose()
# ブログカード(リンク)を削除
for tag in bs_html.find_all('div', class_='blogcard'):
tag.decompose()
具体的には、BeautifulSoup4のtag.decompose()メソッドで、タグの中身もろとも削除しているだけです。
入力する文書データがHTMLの場合、どのタグを残すかは文書の内容や形式に強く依存します。今回迷ったのは、HTMLファイル中でも多用している<table>タグです。クエリの回答に有用な内容を含むものも多いのですが、タグだけを削除して、表の中身をテキストで羅列してしまうのも良くないだろうということで削除することにしました。
意味的なまとまりとして<h2>タグでチャンクを分割
前回のテキスト分割では、RecursiveCharacterTextSplitterで2000文字を上限に機械的にHTML内のテキストをチャンクに分割していました。
一方で、ブログやネット記事のようなHTMLはタグによる構造を持っています。たいていの記事では、<h2>タグでセクションを分けていて、それぞれのセクションで一つのトピックを扱っていると思います。つまり、<h2>タグによって、意味的にテキストが分割されているということです。
そこで、今回は、機械的にテキストをチャンクに分割するのではなく、<h2>タグで目印にチャンク分割をすることにします。
具体的なコードは以下のようになります。
# <h2>の見出し章ごとにテキストを抽出
sections = []
# 最初の<h2>タグを検索する
h2_tag = bs_html.find('h2')
while h2_tag:
# セクションのタイトルを取得
section_title = h2_tag.text
# セクションの内容を取得
section_content = []
next_sibling = h2_tag.find_next_sibling()
# 次の<h2>タグまでのすべてのテキストを抽出
while next_sibling and next_sibling.name != 'h2':
if next_sibling.string:
section_content.append(next_sibling.string)
next_sibling = next_sibling.find_next_sibling()
# セクションをリストに追加
# 記事最後の「関連記事」のセクションは追加しない
if r'関連記事' not in section_title:
sections.append(section_title + '\n' + ''.join(section_content))
# 次の<h2>タグを検索
h2_tag = next_sibling
ループで<h2>タグを見つけては、そこまでのテキストを配列sectionsに追加する処理をしています。
私のブログ記事では、最後に「関連記事」という<h2>セクションがありますが、ここは除外しています。この記事に関係する別の記事のリンクを載せているセクションですが、クエリの回答に有益なテキストを含まないためです。
また、記事によっては、<h2>セクションの中を、さらに<h3>タグで分割しているものも多いですが、そのまままとめて一つのチャンクとしています。一つの<h2>セクションが長い場合には、<h3>タグで分割するのもありでしょう。
上のコードでsectionsに格納された<h2>セクション単位のテキストを、前回同様、ChromaのVector Storeにembeddingsとともに格納しています。
動作確認
今回作成したテキストクリーニングと<h2>タグでチャンクを分割したデータでの動作確認をしてみます。
チャンク数と文字数の分布
動作確認の前に、<h2>タグでテキストを分割したチャンクの長さを調べてみました。横軸が文字数、縦軸はチャンク数のヒストグラムです。
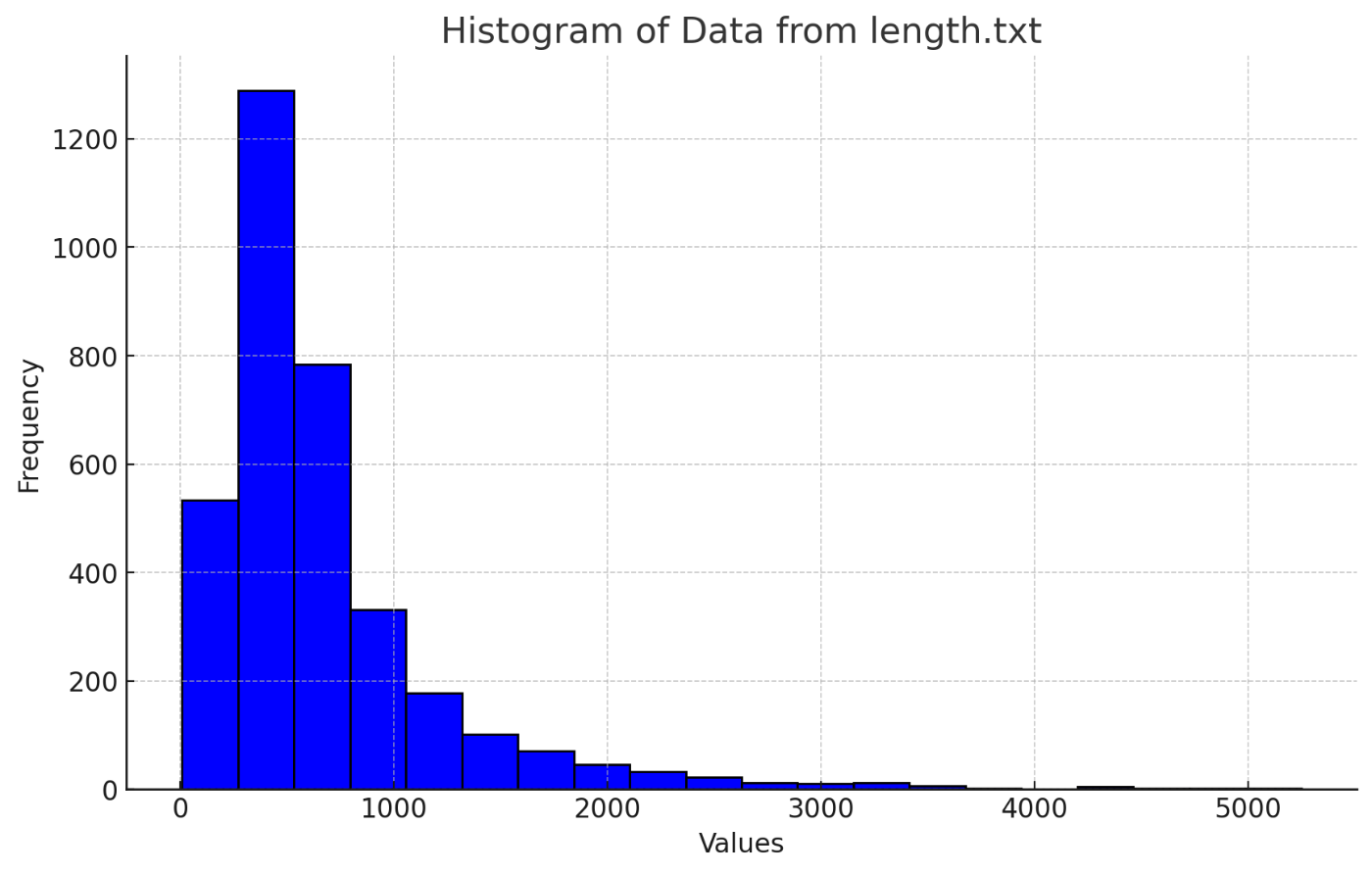
Chunkの文字数
前回は、記事数101に対してチャンク数は451でしたが、<h2>タグで分割した今回は、チャンク数は538となりました。上のヒストグラムのように、おおむね500文字前後に集中しています。2000文字以上という長いチャンクもありますので、長いチャンクはもう少し短くした方がいいかもしれません。
以前は、ChatGPTやOpenAI APIのトークン数の上限が4,097でしたが、現在では16Kや32Kまで扱えますので、2~3,000文字くらいのチャンクがあっても、実用上はそれほど問題はありません。ただし、あまり長いチャンク(今回の場合<h2>セクション)は多岐にわたるトピックやキーワードを含む可能性があるので、検索精度が低下する可能性はあります。
クエリに対する回答の評価
それでは動作確認をしてみます。今回もデータとしては、青春18きっぷに関する記事101個を入力しています。記事中に答えが含まれる以下の10個の質問をしています。10個の質問の内訳は以下のとおりです。
- No.1~5: 青春18きっぷのルールなど正解が明確なもの
- No.6~10: 「おすすめ」をたずねるもの
各質問の回答に対して、次の基準で得点を評価しました。
- 回答が正しい(記事中に含まれる記述と一致する)場合: 1点
- 回答の一部は正しいが、間違っている部分もある場合: 0.5点
- 回答が間違っている場合、または、適切な回答でない場合: 0点
qabot1は前回の機械的に2000文字でチャンク分割したもので、qabot2は今回の<h2>タグでチャンク分割をしたものです。いずれも、前回同様、LLMのモデルとしてはOpenAIのgpt-3.5-turbo-1106を利用しています。
| No. | 質問(クエリ) | qabot1 | qabot2 |
|---|---|---|---|
| 1 | 冬の青春18きっぷの利用期間は? | 1 | 0 |
| 2 | 青春18きっぷで乗車できる列車種別は? | 1 | 1 |
| 3 | 1枚の青春18きっぷを二人で使うには? | 0 | 1 |
| 4 | 青春18きっぷで本州から北海道へ渡るには? | 0.5 | 1 |
| 5 | 青春18きっぷで特例で乗車できる特急列車は? | 0 | 0 |
| 6 | 青春18きっぷの旅でおすすめの東京発日帰りルートは? | 1 | 1 |
| 7 | 青春18きっぷの旅でおすすめの海の車窓が素晴らしい路線は? | 1 | 1 |
| 8 | 冬の青春18きっぷでおすすめの路線は? | 0 | 1 |
| 9 | 青春18きっぷで東海道本線を快適に移動するには? | 1 | 0 |
| 10 | 青春18きっぷの旅でワープにおすすめの区間は? | 0 | 1 |
| - | 合計点 | 5.5 | 7 |
全体的には、テキストをクリーニングして<h2>タグでチャンク分割したqabot2のほうが、回答の精度は上がっています。
ただ、前回は回答できていた質問に対して、今回のqabot2では正しく回答できていなかったものもあります。
No.1の回答を見てみると、以下のようになっています。
Q. 冬の青春18きっぷの利用期間は?
qabot1:
青春18きっぷの利用期間は、2023年12月10日(日)から2024年1月10日(水)までです。
qabot2:
冬の青春18きっぷの利用期間は、毎年発売される春・夏・冬の3シーズンのうちの1つであり、詳しい情報は2023-24年シーズンの青春18きっぷの詳細を確認する必要があります。
qabot2では、記事中に含まれる具体的な期間を回答できていません。
このように、平均的には精度は向上しますが、個々に見ていくと、悪化しているものもあるということがわかります。
<h2>タグが一つのトピックのまとまりだとすると、Retrieverが適切なチャンクを検索できていれば、そのチャンクには余計な情報が含まれていない分、LLMによる回答の精度が上がることは間違いないでしょう。
一方で、適切なチャンクをRetrieverが返せないと、他のチャンクにはクエリに関係する情報が含まれる可能性が低い分、LLMが正しい回答をする確率は低くなってしまいます。前回に比べて、意味的・文脈的にチャンク分割ができている分、適切なチャンクを検索できるかどうかにかかっているということだと考えられます。
【まとめ】一定の精度向上は見られたものの……
ということで、RAGに入力するデータのクリーニングとチャンク分割の改善で、RAGの精度向上が見られるかを試してみました。
結論としては、一定の精度向上は見られたものの、簡単な質問でも答えられないこともあり、まだまだ不十分という印象です。他にも、もう少し短いチャンク、例えば<h3>タグがあれば<h3>タグで分割するなどの方策はありそうです。
とはいえ、これ以上のチューニングは、入力する文書データの特徴に過度の依存してしまう恐れがあります。一般論としてテストする範囲であれば、入力データに関する工夫はこれくらいにしておこうと思います。
RAGの回答精度を向上させる取り組みは、いま盛んに研究されているようですので、他にもいろいろと試してみたいと思います。
Discussion