WordpressのブログでRAGを試してみる
生成AIに専門知識を与えて質問に回答させるRAG(Retrieval-augmented generation)をいじっています。個人的にWordpressで運営しているブログの記事を与えて、RAGによる簡易なQAボットを作ってみましたので、紹介したいと思います。
Wordpressのエクスポートデータを読み込ませてRAGを実現する
RAG(Retrieval-augmented generation)は、大規模言語モデル(LLM)のプロンプトに、コンテキストとして関連する情報を含めることで、専門知識を必要とする質問に答えさせる手法です。
専門知識の集合体をデータベースに保存しておき、質問(クエリ)に関係する文書だけを検索で抜き出してコンテキストとしてプロンプトに含めます。

今回は、Wordpressで運営しているブログの記事を専門知識として与えることでRAGを実現する手法を試してみました。
なお、以下の環境を前提とします。
- ライブラリとしてLangchainを利用
- Embedding、LLMとしてはOpenAI APIを利用(OpenAIのAPI KEYが必要)
- Vector store として Chroma を利用
以下のバージョンで動作確認をしています。
- Python 3.11
- Langchian 0.0.350
- Wordpress 6.4.2
WordpressからエクスポートしたXMLファイルをChunkに分割
まず、Worpdressから記事ファイルをエクスポートします。Wordpressの記事やコメントなどをローカルに保存するXMLファイルは、WordPress eXtended RSS もしくは WXRと呼ばれています。
WordpressからエクスポートしたXMLファイルでは、1記事(一つの投稿)ごとに<item>タグで分けられていて、その中に記事内容や各種のメタデータ(タイトル、URL、投稿日時、カテゴリなど)が格納されています。記事内容は<content:encoded>タグ内に格納されています。
from bs4 import BeautifulSoup
from langchain.text_splitter import RecursiveCharacterTextSplitter
with open(xmlfile, 'r', encoding="utf-8") as f:
texts = []
# BeautifulSoup4でXMLファイルを解析する
soup = BeautifulSoup(f, "lxml-xml")
# 記事が格納されている<item>タグを取得
for article in soup.find_all('item'):
# 記事本体は<content:encoded>にHTMLとして格納されている
content_html = article.find('content:encoded').get_text()
# 記事本体をからテキストのみを抽出
content_soup = BeautifulSoup(content_html, 'lxml')
content_text = content_soup.get_text()
# テキストをChunkに分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 2000,
chunk_overlap = 0,
length_function = len,
)
splitted_text = text_splitter.split_text(content_text)
# textsに追加
texts.extend(splitted_text)
Beautifulsoup4を用いてXMLファイル内から<item>タグを取得し、その中に含まれる<content:encoded>のテキストのみを取得します。
<content:encoded>内のコンテンツはHTMLのまま格納されていますので、再びBeautifulsoup4でテキストのみを取得します(上のコード中のcontent_text)。
取得したテキストを、RecursiveCharacterTextSplitterを用いて適切な長さのChunkに分割します。RecursiveCharacterTextSplitterは、chunk_sizeの下限を下回るまで再帰的に分割をするテキストスプリッタです。
OpenAIのGPT-3.5-turboでは16Kトークンまでサポートしていますが、プロンプトには複数(例えば5つ)のChunkを含めますので、ここでは2000文字を上限に分割します。
これで、textsに、XMLファイルに含まれるすべての記事を2000文字を上限に分割したテキストが配列として保存されます。
Chroma Vector Storeを作成
Wordpressの記事をエクスポートしたXMLファイルから作成したChunkから、Vector Store を作成します。今回は、Vector DBとしてChromaを利用します。
embeddingにはOpenAIのtext-embedding-ada-002を利用します。Vector Store作成時に、内部でOpenAI APIを介してembeddingの作成が行われるため、OpenAIのAPI KEYを環境変数OPENAI_API_KEYに設定しておいてください。
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import OpenAIEmbeddings
import chromadb
# Chroma DB
persist_directory = './sampledb'
vectordb_collection_name = 'wordpress'
EMBEDDING_MODEL = "text-embedding-ada-002"
# embedding model を設定(OpenAIのtext-embedding-ada-002を利用)
embeddings = OpenAIEmbeddings(model=EMBEDDING_MODEL)
# clientをPersistentClientで指定するとファイルとしてDBが永続化される
client = chromadb.PersistentClient(path=persist_directory)
# Vectore store としてChromaDBを作成
vectordb = Chroma(
collection_name=vectordb_collection_name,
embedding_function=embeddings,
client=client,
)
# textsを一つずつEmbeddingしてChromaDBに格納する
# ここでOpenAI API経由でemneddingsし、
# text本体とともにvectordbに格納される
vectordb.add_texts(texts)
Chroma client を作成するときには、以下のようにPersistentClientを指定すると、DB内容がpathで指定されたフォルダに保存されるようになります。つまりは永続化されます。
client = chromadb.PersistentClient(path=persist_directory)
ここで作成したclientを指定して、Chroma DBを作成する。
vectordb = Chroma(
collection_name=vectordb_collection_name,
embedding_function=embeddings,
client=client,
)
ChromaはCollectionという単位でデータベースを管理します。ここで指定したcollection_nameはそのCollectionの識別子となります。Collectionの識別名は何でも構いませんが、作成したChroma Vectore StoreからChunkを検索するさいに指定することになりますので、わかりやすい名称にしておきましょう。
Chromaについては、本家の Usage Guide がわかりやすいです。
最後に、作成したVectore Store vectoredbにテキストを追加していきます。
vectordb.add_texts(texts)
add_text()メソッドに、文字列の配列を渡すと、内部でOpenAI APIに問い合わせてembeddingsを作成し、そのembeddingsとともにテキストがDBに格納されます。
Chroma Vector Store を利用してRAGを実現
先ほど作成した Chroma Vector Store を利用して、RAGを実現します。
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
import chromadb
# Template
my_template_jp = """以下の情報を使って、ユーザの質問に日本語で答えてください。回答にあたっては、質問に関係する情報だけを用いて、できるだけわかりやすく回答してください。
情報: {context}
質問: {question}
最終的な回答:"""
# retriever
# VectorDBからクエリに関係するテキストを検索するretrieverを設定
# search_type="simirality"はコサイン類似度による検索
retriever = vectordb.as_retriever(
search_type="similarity",
search_kwargs={"K": 5}
)
# model
# クエリに利用するOpenAIのモデルを設定
model = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo-1106")
# prompt
# プロンプトを設定
prompt = PromptTemplate(
template=my_template_jp,
input_variables=["context", "question"],
)
# output paeser
# LLMの出力を文字列として返すパーサーを設定
output_parser = StrOutputParser()
# Query Chain
# LangchainのLCEL記法でChainを設定
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| output_parser
)
# Chainを実行
# query: 質問内容
result = chain.invoke(query)
# 結果を表示
print('回答:\n', result)
まず、RAGに必要なモジュールとして、retriever、model、prompt、output_parserを個別に作成します。
Retriever
Retrieverは、作成した Vector Store から、クエリ内容に関係の深い文書(テキスト)を検索する機能を提供します。Chromaで Vector Store を作成してあれば、以下のようにas_retriever()メソッドで簡単にRetrieverを作成できます。
retriever = vectordb.as_retriever(
search_type="similarity",
search_kwargs={"K": 5}
)
search_typeはコサイン類似度で検索するsimilarityを指定します。search_kwargsには検索時のオプションがいろいろ指定できますが、ここでは文書をいくつ出力するかを指定するパラメータKのみを指定しています。
LLM Model
次に、クエリの質問内容に回答するためのモデルを設定します。
model = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo-1106")
ここでは、OpenAIのgpt-3.5-turbo-1106を指定しています。もちろん、GPT-4(gpt-4-1106-previewなど)を指定しても構いませんが、さくっと試すだけならお安いGPT-3.5のモデルで十分でしょう。
Prompt
Promptは、クエリに含める質問内容を指定します。Langchainでは、プロンプト内にユーザのクエリ内容や、Retrieverが出力した文書(テキスト)を含めることができるテンプレートを提供しています。
prompt = PromptTemplate(
template=my_template_jp,
input_variables=["context", "question"],
)
templateに指定したmy_template_jp内では、{context}や{question}といった変数が埋め込まれていて、実際にクエリを作成する際には、Vector Storeが出力した文書やユーザの質問内容を埋め込みます。
Output parser
Output parser は、LLMの出力を適切な形式に変換して出力するモジュールです。今回は、LLMの回答を文字列として出力するだけのシンプルなStrOutputParserを利用します。
output_parser = StrOutputParser()
これで、LLMの出力を文字列をして受け取ることができます。
各モジュールをパイプで連結
最後に、ここまで作成した各モジュールをパイプ|で連結してChainを作成します。今回のようなシンプルなRAGでは、以下のようになります。
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| output_parser
)
具体的には、以下の処理になります。
- 1行目:
retrieverの出力をcontextに、ユーザ入力はquestionとしてそのまま次に受け渡す- 次の
promptの入力はdict形式なので、dict形式でcontextとquestionを渡す
- 次の
- 2行目: dict形式で
contetとquestionを受け取り、promptを実行(テンプレートに埋め込む)-
promptの出力はPromptValue形式
-
- 3行目:
promptの出力をそのままmodelに入力、modelはOpenAI APIにプロンプトを送信して、LLMからの回答を受け取る - 4行目:
modelからの回答を文字列形式にして出力する
1行目で {"context": retriever, "question": RunnablePassthrough()} となっているのは、retrieverを動作させるのと同時に、ユーザからの入力をそのまま次に受け渡すという2つの動作を並行して行うという意味です。正式には、以下のようにRunnableParallel()を利用するようです。
RunnableParallel({"context": retriever, "question": RunnablePassthrough()})
詳しくは、Langchainの以下のページでRAGの例が解説されていますので、詳しく知りたい方はご覧ください。
動作確認
動作確認をしてみます。
今回、専門知識の文書として読み込ませたのは、個人的な趣味で恐縮ですが、Wordpressで運営している鉄道関連のブログの青春18きっぷ関連の記事です。
記事数は101で、RecursiveCharacterTextSplitterで分割したあとのChunk数は451でした。各Chunkの文字数をヒストグラムにすると、以下のようになりました。
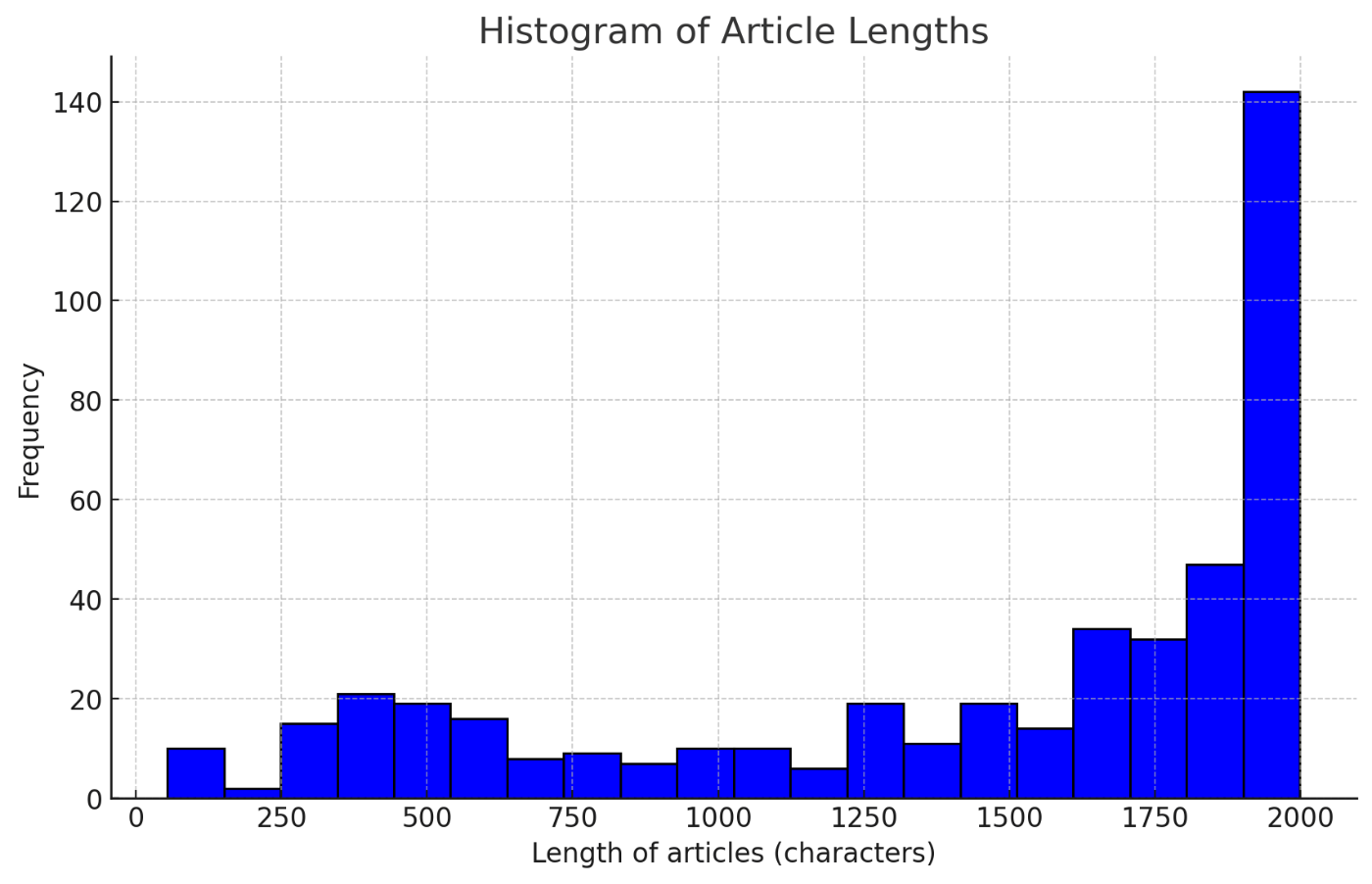
Chunkの文字数
chunk_sizeを2000にしているので、おおむねその通りになっているようです。たまに短いChunkがあるのは、一つの記事を読み込んだあと、その記事をRecursiveCharacterTextSplitterで分割するということを繰り返しているせいです。記事の最後に残った部分が短いChunkになっているのだと思います。
ちなみに、embeddingsにかかったコストは0.1~0.2ドル(15~30円)程度でした。
それでは、いくつか実際に質問をしてみます。いずれも、正しい回答が Vector Store に格納したテキストに含まれるものです。
$ python .\basic_qabot.py -q 青春18きっぷの利用期間は?
回答:
青春18きっぷの利用期間は、2023年12月10日(日)から2024年1月10日(水)までです。
$ python .\basic_qabot.py -q 青春18きっぷで乗車できる列車種別は?
回答:
青春18きっぷで乗車できる列車種別は、普通列車や快速列車です。新幹線や特急列車には乗れません。
$ python .\basic_qabot.py -q 1枚の青春18きっぷを二人で使うには?
回答:
1枚の青春18きっぷを二人で使うことはできません。青春18きっぷを利用する日の利用開始から終了まで、常に同一行程である必要があります。複数人で利用する場合、別々のJR線の駅から乗車してどこかの駅で待ち合わせをする場合には、最寄り駅から待ち合わせ駅までのきっぷを別途購入する必要があります。
$ python .\basic_qabot.py -q 青春18きっぷで本州から北海道へ渡るには?
回答:
青春18きっぷで本州から北海道へ渡るには、青春18きっぷ北海道新幹線オプション券を購入して北海道新幹線で移動することができ ます。ただし、北海道新幹線に乗れる区間は奥津軽いまべつ~木古内間のみで、その前後はJR津軽線や道南いさりび鉄道との乗り継ぎが必要です。また、特定特急券を購入すれば北海道新幹線の新青森~新函館北斗相互間にも乗車できます。さらに、フェリーを利用する手段もあります。
最初の2つは正解ですが、残りの2つが怪しいです。3番目は「1枚の青春18きっぷを二人で使うことはできません」と言いつつ、「常に同一行程である必要があります」と二人で1枚の青春18きっぷを使うときの注意事項を回答しています。
4番目の「また、特定特急券を購入すれば北海道新幹線の新青森~新函館北斗相互間にも乗車できます。」は別のきっぷ(北海道&東日本パス)の説明が混ざってしまっています。
他にもいくつか試していますが、正しく回答できているものもあれば、間違っているもの、半分正しくて半分間違っているものなどさまざまでした。
今回は、適当に2000文字くらいで記事のテキストをぶった切ってしまったので、4番目の例のように、別の情報が紛れ込んで正しい回答がされていない可能性もあります。このあたりは、Chunkの切り方を工夫すれば改善するかもしれません。
まとめ
まずはWordpressの記事をエクスポートしたXMLファイルを用いてVector Storeを作成し、簡単なRAGを実現するところまでを作成してみました。
ただ、回答の精度はイマイチで、Chunkの切り方などにもう少し工夫の余地がありそうです。別途、いろいろと試していきたいと思います。
Discussion