大容量データを継続的にSnowflakeへ取り込む方法'22改良版
この投稿は Snowflake Advent Calendar 2022 の21日目の記事です。
※例によって、内容は個人の見解であり所属する組織の見解ではありません🙏
この記事は、去年公開したこちらの記事を運用してわかった改善点をまとめた改良版になります。今年はZennで書いてみました。
TDからのデータ取り込みを題材としていますが、今回の方法でTD専用となるのは、最初のSnowflake用DDL生成の部分のみです。
その他のシステムからの取り込みにも同様のアプローチは有効かと思います😃
あらためて、TDの大容量データをSnowflakeへ取り込む際のポイントまとめ
- SnowflakeExportIntegrationという機能があるが大量データをSnowflakeへ同期するのには使えない。理由については前回記事にて
- TD→Snowflakeの大量データの取り込みには、S3を経由する方式(TD→ S3 → Snowflake)を使う
- TD→S3の際はjson出力し、S3→Snowflakeの際はSnowflakeのCOPY機能で「MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE」を使う
- TDとSnowflakeの機能をハイブリッドに使うことでスムーズにデータ取り込みが完了する
継続取り込み運用しつつ改良したポイント
-
2.の部分。昨年版ではSnowflakeExportIntegrationを使って1行書き出してからCOPY INTOでロードするとなっていたところを、
SnowflakeExportIntegrationを使わず、TDのクエリ(Presto)で直接SnowflakeのDDLを作る方法にアップデート -
2.~3.の部分。Snowflakeのロードパフォーマンスを最適化するため、TD側のexport処理で出力ファイルの大きさを調整していたを、
AWSbatchを使って、TD側の処理で出力ファイルサイズを調整するのではなく、S3putされたタイミングで適切サイズへ分割されるようアップデート -
3.の部分。SnowflakeへのJsonファイル取り込みをより最適化する方法へアップデート
-
その他、運用してわかったデータ移行のポイント
○ここからは、具体的な改善ポイントの詳細について
1'.TDのクエリ(Presto)で直接SnowflakeのDDLを作る
- 結論、以下のようなクエリをTDで実行することで、SnowflakeのDDLが作成可能。(Prestoで動作確認済み)
with table_column_arr as
(select
concat(table_schema, '.', table_name) as schema_table,
array_agg(concat(column_name, ' ', data_type)) as column_type
from information_schema.columns
where table_schema in ('[TDデータベース名1]','[TDデータベース名2]')
group by 1)
select concat('create or replace table ', schema_table, ' (', array_join (column_type, ','), ');')
from table_column_arr;
ポイント
- infromation_schemaから、指定したdatabase配下のtable名とカラム情報(カラム名と型名)を取得する。
- CTIのTABLE情報をSnowflake構文へ整形する。
ここで生成したDDLをSnowflakeで実行することで、TD側のSnowflakeExportIntegration機能で一旦ダミーデータを作る必要がなくなります。
補足
現状、Apache Parquet、Apache Avro、およびORC ファイルに限定ですが、半構造データファイルから列定義を生成することも可能です。
2'.書き出し側の処理で出力ファイルサイズを調整するのではなく、S3へ置かれたタイミングでロード最適サイズへ分割する(AWSBatchを使う)
- 図のようなイメージ。書き出し側からs3出力されたファイルを任意の大きさ(行数指定)して、最適化サイズ(圧縮済み100〜250MB)へ分割してからSnowflakeへ取り込むようにする cf.docs
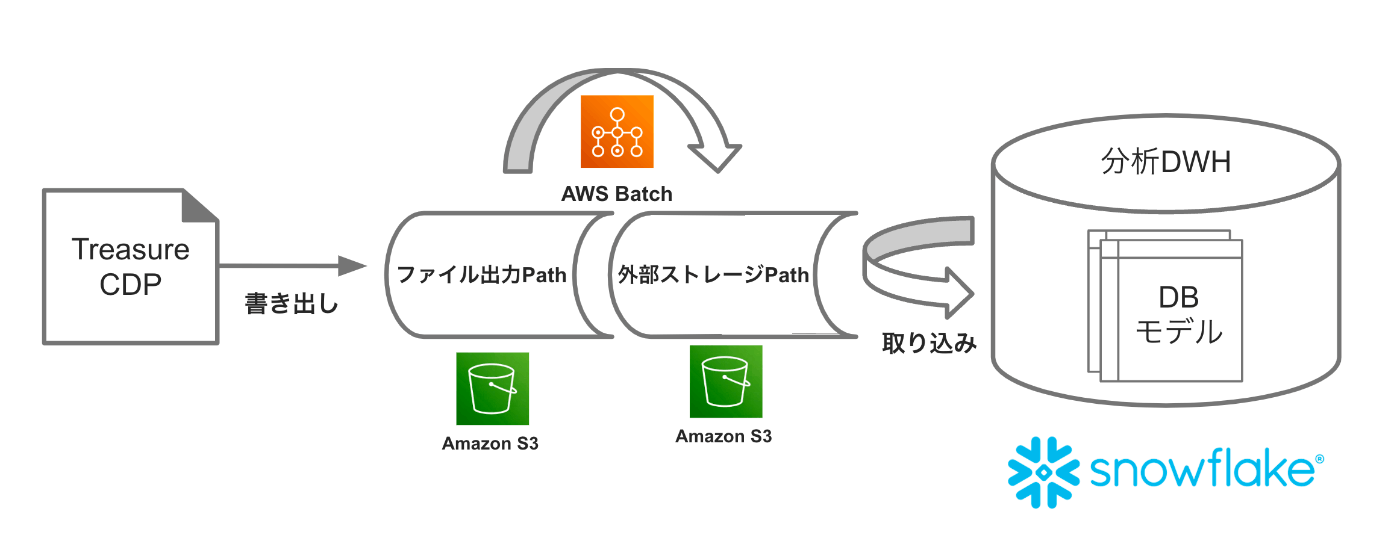
- 利点としては
- 書き出し側で分割サイズを調整する必要がなくなるため、処理がシンプルになる
- 書き出し側で分割するより高速に処理が完了する
- 調整ポイント
- 分割処理のため、小さいファイルが出力される書き出しには適用できない。
※AWSbatchを使った具体的なファイル分割の実装については、こちらにて説明※
3'.SnowflakeへのJsonファイル取り込みをより最適化する
- 結論、Snoflakeのファイルフォーマット設定に「STRIP_NULL_VALUES = TRUE」を加えると劇的にロードコスト(処理時間)が下がる
- 具体的にはFILE FORMATを下記のDDLにて作成する
CREATE OR REPLACE FILE FORMAT JSON_GZ
TYPE = JSON
COMPRESSION = GZIP
STRIP_NULL_VALUES= TRUE;
- 「STRIP_NULL_VALUES = TRUE」とは?
null 値を含むオブジェクトフィールドまたは配列要素を削除するようにJSONパーサーに指示するブール値。cf.docs - 具体的な性能の差
約600MB、4400万件のデータロードに対して、最大2倍程度のロードパフォーマンスアップになった。
| SQLタイプ | Warehouseタイプ | 処理時間 |
|---|---|---|
| STRIP_NULL_VALUES = TRUE | L | 4m38s |
| 指定なし | L | 8m13s |
| STRIP_NULL_VALUES = TRUE | XS | 30m07s |
| 指定なし | XS | 48m56s |
補足
なお、この知見はSnowflakeの技術サポートに相談して得られたものです。
データロードが思ったより高コストになりそうだと悩んでいたところで、Snowflakeサポートに相談してダメなら受け入れようと思って相談したところ、具体的な実証結果までいただいて無事大幅コスト削減をできました。
想像以上のサポート体験でした🙇あらためて感謝いたします🙏
4'.大容量データを効率的に取り込むマクロを自作する
現在推進しているプロジェクトでは、dbtを使ってデータモデルを構築しています。cf.ブログ記事
- dbtを使った標準的なマクロを使ったデータロードでは、insert intoかmerge intoとなりますが、TDの大容量データを継続的に取り込むためにより適したロードを実現するためcopy intoを実行する自作ロードマクロを使っています。この情報を元に作成&運用中です。
※検証・実装に関しては、弊プロジェクトのメンバーが担当してくれました。この内容についても機会あれば別記事にて紹介できればと🙏※
まとめ
大容量データを継続的にSnowflakeへ取り込むには、
- 取り込み元の方(TD)でSnowflake用のDDLを作成する
- Snowflakeの強力な取り込み機能を活用するため、データはクラウドストレージ(S3)へ書き出す
- ロードファイルはの最適化はクラウド側(AWS)で行う
- dbtを使っている場合でもcopy intoが使えるようマクロを作るのをオススメ
- そして、困ったらSnowflakeサポートに相談する。※Snowflakeのサポートは本当に助かるサポートを期待できる※
Discussion