S3に書き出される大容量ファイルを自動で分割する方法
この投稿は datatec-jp Advent Calendar 2022 の22日目の記事です。
※例によって、内容は個人の見解であり所属する組織の見解ではありません🙏
この記事は、こちらの記事で言及した、外部システムからS3へ書き出されたファイルを自動分割する実装について書いています😃
概要
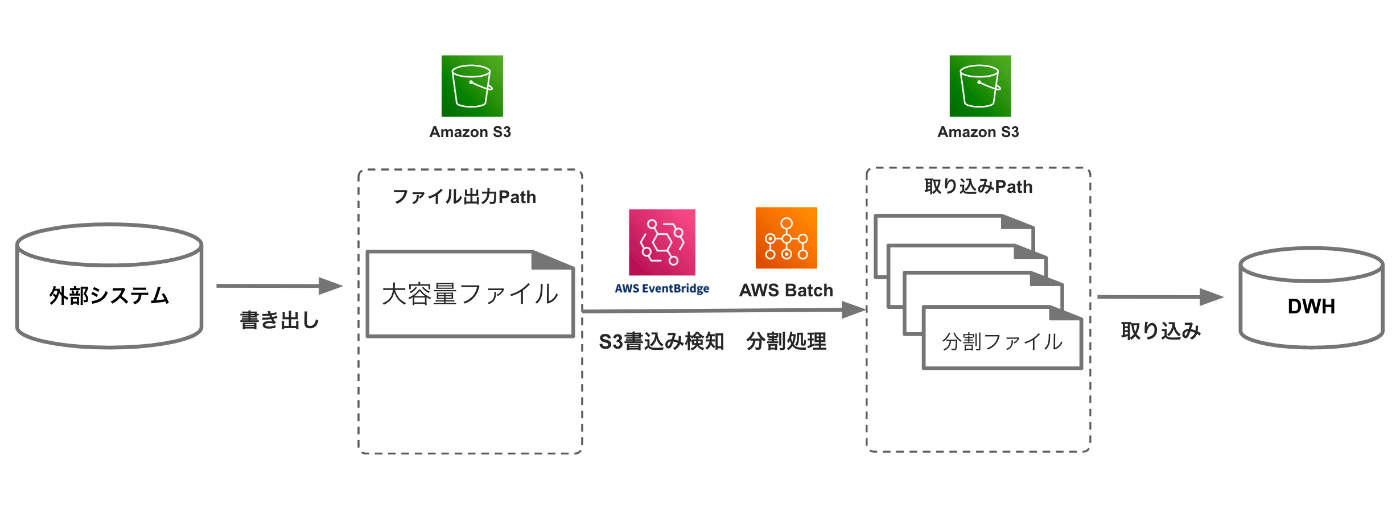
図のように、S3へデータが書き出されると、
EventBrigeがそれを検知し、AWSBatchが起動、ファイル分割処理を実行して、
S3(書き出しとは別の場所)へ書き出すという処理です。
ユースケース
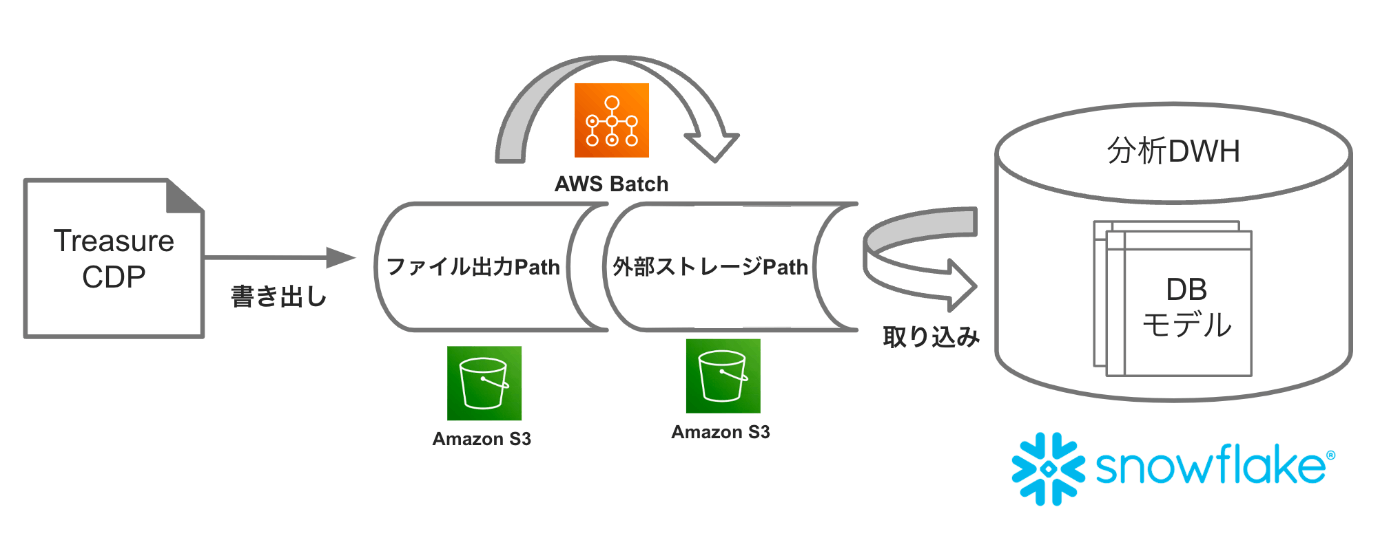
下図のように外部システム(TD等)からデータを書き出して別DWHに取り込むような使い方を想定します。
それぞれDWHではロードに最適なファイル容量が決まっている(Snowflakeの場合は圧縮済み100~250MB)
ところに合わせて、取り込み処理のパフォーマンスを最大化することを想定します。
分割処理のコストについて
現プロジェクトで処理している1日分(4GBx7ファイル)を150MBx190ファイル程度に分割する処理で$0.1/日くらいの課金(ECS)です。
これは分割せずにロードした場合のコストに比べて十分安い金額になります💪
分割前後のロードコスト(時間)の差
| ファイルサイズ | ファイル数 | WHサイズ | 実行時間 |
|---|---|---|---|
| 2.4GB | 1 | XS | 4:16:00 |
| 2.4GB | 1 | S | 4:13:00 |
| 300MB | 12 | XS | 1:10:00 |
| 300MB | 12 | S | 51.3 |
| 100MB | 27 | XS | 1:09:00 |
| 100MB | 27 | S | 39.6 |
(計測:2021/12月頃)
-> XS(~=Snowpipe)で1/4ほどに激減する。
実装について
AWSBatchについては、この記事。
EventBrigeについては、この記事を最初に参照して実装しました。
それぞれについての説明も入れて行くと、ボリュームが大き過ぎてしまうため省略します。
AWSBatch、EventBrigeをまだ使ったことがない方へは、まず上記をお読みいただくことをお勧めします🙏
ここからは、試してみようと思われた方がスムーズに実施できるよう、
試行錯誤しながら辿りついた(サポートにも結構お世話になりながら😅)ポイントも補足しつつ、
具体的な実装を紹介していきます。
ファイル分割処理script
gz圧縮でS3へ置かれるファイルを、指定された行数で分割し、別のパスへ置く処理です。
実装
- 引数として以下を受け、
- 分割数
指定された行数でファイルを分割 - バケット
- バケット以下ファイルパス
- 分割数
- 分割後ファイルを以下へ出力する
- バケット/split/バケット以下ファイルパス
#!/bin/bash echo "Args: $@" if [ ! -z "$1" ] && [ ! -z "$2" ] && [ ! -z "$3" ]; then SPLIT_NUM=$1 S3_BUCKET=$2 S3_KEY=$3 else echo "Usage: args[ {SPLIT_NUM} {S3_BUCKET} {S3_KEY}]" exit 1; fi echo "=== start split" inputFile="s3://${S3_BUCKET}/${S3_KEY}" outputPath="s3://${S3_BUCKET}/split/${S3_KEY}" fileName=`basename ${S3_KEY} .gz` # command for split cmd=$(printf 'gzip -c|aws s3 cp - %s_split-%s/%s_$FILE.gz' ${outputPath} ${SPLIT_NUM} ${fileName}) # for debug echo "inputFile : ${inputFile}" echo "cmd: ${cmd}" aws s3 cp ${inputFile} - | gzip -dc | split -d -l ${SPLIT_NUM} --filter ''"$cmd"'' echo "=== end split"
事前準備
- ECR作成
- この記事参照で基本設定する
- scriptを動かせるようDokerfileを下記へ修正、build&pushしておく
FROM amazonlinux:latest RUN yum -y install which unzip aws-cli gzip ADD fetch_and_run.sh /usr/local/bin/fetch_and_run.sh WORKDIR /tmp USER nobody ENTRYPOINT ["/usr/local/bin/fetch_and_run.sh"] - ロール作成
- 以下をアタッチする
- AmazonS3FullAccess
- AWSBatchServiceRole
- AmazonECSTaskExecutionRolePolicy
- 信頼関係は以下のように設定する
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "ecs-tasks.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } - 以下をアタッチする
- S3(バケットのプロパティ設定)
- 「このバケット内のすべてのイベントについて Amazon EventBridge に通知を送信する」をオンへ
デフォルトオフ。この設定ができないと処理が起動しないためハマりところ
- 「このバケット内のすべてのイベントについて Amazon EventBridge に通知を送信する」をオンへ
AWSBatch
コンピューティング環境
- Fargateを指定
- その他はよしなに
ジョブ定義
- オーケストレーションタイプ
Fargate - パブリックIPを割り当て
ONにする ※デフォルト(OFF)ではバッチ起動時FargateがECRからイメージ取得する際に失敗する - 実行ロール
準備で作ったロールを設定する
(実行ロールは ECS Agent に対して AWS API のコールを行う権限を付与するために使用する。ECRからの Dockerイメージのpullなどは実行ロールの権限を使って行われる。) - コマンドの構文
Bash - コマンド
下記のような起動shellに渡される引数を設定する
"s3eventbridge-split" "2000000" "Ref::S3bucket" "Ref::S3key"
- 環境設定
- ジョブロール
準備で作ったロールを設定する。
(ジョブロールは起動したコンテナにAWS APIのコールを行う権限を付与するために使用される。コンテナ内で稼働しているアプリケーションからのAWS CLIや AWS SDK などによる AWS API コールは、ジョブロールの権限を使って行われる。) - 環境変数
BATCH_FILE_S3_URL = S3上のファイル分割処理ファイルへのパス
BATCH_FILE_TYPE = script
- ジョブロール
ジョブキュー
- コンピューティング環境
- 作成済みのコンピューティング環境を設定する
EventBridge
ルールを作成
- イベントパターンを持つルール
- イベントパターン:その他
- 作成のメソッド:カスタムパターン(JSONエディタ)
以下のように設定
{
"source": ["aws.s3"],
"detail-type": ["Object Created"],
"detail": {
"bucket": {
"name": ["ターゲットバケット"]
},
"object": {
"key": [{
"prefix": "ターゲットパス"
}]
}
}
}
ターゲット
-
バッチのジョブキュー
-
入力トランスフォーマーを設定
S3出力されたファイルの情報をEventBridgeからBatchへ伝えるために設定する。- 入力パス
{"S3BucketValue":"$.detail.bucket.name","S3KeyValue":"$.detail.object.key"}- テンプレート
{"Parameters" : {"S3bucket": <S3BucketValue>, "S3key": <S3KeyValue>}}
一通り正常に動作すると
- s3へのファイルputに対して、

- EventBridgeのモニタリングにデータがあらわれ、

- AWS Batchのジョブが起動し、

- 新しく分割済みファイルが生成されます😃

- 複数ファイルputされた場合はそれぞれにjobが起動して並行動作します
Discussion